
py-llm-core
A pythonic library providing light-weighted interface with LLMs
Stars: 118

PyLLMCore is a light-weighted interface with Large Language Models with native support for llama.cpp, OpenAI API, and Azure deployments. It offers a Pythonic API that is simple to use, with structures provided by the standard library dataclasses module. The high-level API includes the assistants module for easy swapping between models. PyLLMCore supports various models including those compatible with llama.cpp, OpenAI, and Azure APIs. It covers use cases such as parsing, summarizing, question answering, hallucinations reduction, context size management, and tokenizing. The tool allows users to interact with language models for tasks like parsing text, summarizing content, answering questions, reducing hallucinations, managing context size, and tokenizing text.
README:
PyLLMCore is a lightweight Python library designed to provide a simple and efficient interface for interacting with Large Language Models (LLMs). It supports a variety of models, including:
- OpenAI: Access state-of-the-art models like GPT-4o.
- MistralAI: Use models optimized for specific tasks.
- Anthropic: Engage with Claude.
- Google AI (Gemini): Leverage the largest context window of Google's Gemini serie.
-
Open-Weights Models (GGUF): Use a wide range of open-source models via
llama-cpp-pythonbindings.
- Pythonic API: Designed to be intuitive and easy to use for Python developers.
- Minimal dependencies: Built with as few dependencies as possible to ensure ease of installation and integration.
- Flexible model switching: Easily swap between different models to suit your needs.
-
Standard library integration: Uses Python's
dataclassesfor structured data handling.
- Python 3.8 or higher is required to use PyLLMCore.
- Ease of use: Simple setup and usage make it accessible for developers of all levels.
- Versatility: Supports a wide range of models and use cases, from parsing text to function calling.
- Customization: Offers the ability to extend and customize functionality with minimal effort.
- If you need a comprehensive framework, consider LangChain.
- For high-performance requirements, explore vllm.
- If you prefer using Pydantic over
dataclasses, PyLLMCore might not be the best fit.
PyLLMCore is versatile and can be used in various scenarios involving Large Language Models (LLMs). Here are some common use cases:
-
Parsing raw content:
- Use the
parsersmodule to extract structured information from unstructured text. This is useful for applications like data extraction, content analysis, and information retrieval.
- Use the
-
Tool and function calling:
- Leverage the
assistantsmodule to enable LLMs to interact with external tools and functions. This can enhance the model's capabilities by integrating with APIs or performing specific tasks.
- Leverage the
-
Context window size management:
- Utilize the
splittersmodule to manage large text inputs by splitting them into manageable chunks. This is particularly useful when dealing with small models that have context window limitations.
- Utilize the
-
Custom model integration:
- Easily switch between different LLMs, including OpenAI, MistralAI, Anthropic, Google AI, and open-weights models, to suit specific requirements or preferences.
-
Advanced tasks:
- Implement advanced functionalities such as structured output generation, classification tasks, and more by customizing the library's features.
- Ensure you have Python 3.8 or higher installed on your system.
- It's recommended to use a virtual environment to manage dependencies.
-
Set up a virtual environment (optional but recommended):
python -m venv venv source venv/bin/activate -
Install PyLLMCore:
Use
pipto install the library:pip install py-llm-core
-
Configure API keys:
If you plan to use OpenAI models, set your API key as an environment variable:
export OPENAI_API_KEY=sk-<replace with your actual api key>
For Azure OpenAI, set the following environment variables:
export AZURE_OPENAI_API_KEY=<your-azure-api-key> export AZURE_OPENAI_ENDPOINT=<your-azure-endpoint> export AZURE_OPENAI_API_VERSION=<api-version>
For MistralAI set the respective API keys:
export MISTRAL_API_KEY=<your-mistral-api-key>
For Anthropic set the respective API keys:
export ANTHROPIC_API_KEY=<your-anthropic-api-key>
For Google AI set the respective API keys:
export GOOGLE_API_KEY=<your-google-api-key>
-
Download local models (Optional):
If you want to use local open-weights models offline, download and store them in the specified directory:
mkdir -p ~/.cache/py-llm-core/models wget -O ~/.cache/py-llm-core/models/llama-8b-3.1-q4 \ https://huggingface.co/lmstudio-community/Meta-Llama-3.1-8B-Instruct-GGUF/resolve/main/Meta-Llama-3.1-8B-Instruct-Q4_K_M.gguf?download=true wget -O ~/.cache/py-llm-core/models/mistral-7b-v0.3-q4 \ https://huggingface.co/lmstudio-community/Mistral-7B-Instruct-v0.3-GGUF/resolve/main/Mistral-7B-Instruct-v0.3-Q4_K_M.gguf?download=true
Explore the Jupyter notebook in the /notebooks/ directory for executable examples to get started quickly.
The py-llm-core library provides a straightforward way to parse and extract structured information from unstructured text using various Large Language Models (LLMs). Below are examples of how to use the OpenAIParser and how to switch between different parsers.
To parse text using OpenAI models, you can use the OpenAIParser. Here's a simple example:
from dataclasses import dataclass
from typing import List
from llm_core.parsers import OpenAIParser
@dataclass
class Book:
title: str
summary: str
author: str
published_year: int
@dataclass
class BookCollection:
books: List[Book]
text = """The Foundation series is a science fiction book series written by
American author Isaac Asimov. First published as a series of short
stories and novellas in 1942–50, and subsequently in three books in
1951–53, for nearly thirty years the series was widely known as The
Foundation Trilogy: Foundation (1951), Foundation and Empire (1952),
and Second Foundation (1953)."""
with OpenAIParser(BookCollection) as parser:
books_collection = parser.parse(text)
for book in books_collection.books:
print(book)For more complex parsing tasks, you can define a more detailed schema:
from dataclasses import dataclass
from typing import List, Dict
from llm_core.parsers import OpenAIParser
@dataclass
class Book:
title: str
summary: str
author: str
published_year: int
awards: List[str]
genres: List[str]
@dataclass
class BookCollection:
books: List[Book]
text = """The Foundation series by Isaac Asimov includes several award-winning books
such as Foundation (1951), which won the Hugo Award. The series spans genres like
science fiction and speculative fiction."""
with OpenAIParser(BookCollection) as parser:
books_collection = parser.parse(text)
for book in books_collection.books:
print(book)You can easily switch between different parsers to use models from other providers:
-
MistralAIParser: For MistralAI models.
from llm_core.parsers import MistralAIParser with MistralAIParser(BookCollection) as parser: books_collection = parser.parse(text)
-
OpenWeightsParser: For open-weights models.
from llm_core.parsers import OpenWeightsParser with OpenWeightsParser(BookCollection) as parser: books_collection = parser.parse(text)
-
AnthropicParser: For Anthropic models.
from llm_core.parsers import AnthropicParser with AnthropicParser(BookCollection) as parser: books_collection = parser.parse(text)
-
GoogleAIParser: For Google AI models.
from llm_core.parsers import GoogleAIParser with GoogleAIParser(BookCollection) as parser: books_collection = parser.parse(text)
PyLLMCore allows you to work with open weights models, providing flexibility to use models offline. To use these models, follow these steps:
-
Model Location: By default, models are stored in the
~/.cache/py-llm-core/modelsdirectory. You can change this location by setting theMODELS_CACHE_DIRenvironment variable. -
Model Selection: To select an open weights model, specify the model name when initializing the
OpenWeightsModelclass. Ensure the model file is present in the specified directory. For example:
from llm_core.llm import OpenWeightsModel
model_name = "llama-8b-3.1-q4" # Replace with your model's name
with OpenWeightsModel(name=model_name) as model:
# Use the model for your tasks
passEnsure that the model file, such as llama-8b-3.1-q4, is downloaded and stored in the MODELS_CACHE_DIR.
- Downloading Models: You can download models from sources like Hugging Face. Use the following command to download a model:
wget -O ~/.cache/py-llm-core/models/llama-8b-3.1-q4 \
https://huggingface.co/lmstudio-community/Meta-Llama-3.1-8B-Instruct-GGUF/resolve/main/Meta-Llama-3.1-8B-Instruct-Q4_K_M.gguf?download=trueThe py-llm-core library offers advanced capabilities to enhance the functionality of Large Language Models (LLMs). Below are some key features and examples to help you leverage these capabilities effectively.
Enhance LLM responses by integrating external tools. Define a tool using a dataclass with a __call__ method to implement the desired logic.
Here's an example of retrieving one's public IP address:
import requests
from decouple import config
from dataclasses import dataclass
from llm_core.llm import OpenAIChatModel
@dataclass
class PublicIPProvider:
def __call__(self):
url = "https://ipv4.jsonip.com"
response = requests.get(url).json()['ip']
return response
providers = [PublicIPProvider]
with OpenAIChatModel(name="gpt-4o-mini") as llm:
response = llm.ask(prompt="What's my IP ?", tools=providers)
print(response.choices[0].message.content)Here's an example of adding web search capabilities using the Brave Search API:
import requests
from decouple import config
from dataclasses import dataclass
from llm_core.llm import OpenAIChatModel
@dataclass
class WebSearchProvider:
query: str
def __call__(self):
url = "https://api.search.brave.com/res/v1/web/search"
headers = {"X-Subscription-Token": config("BRAVE_AI_API_KEY")}
response = requests.get(url, headers=headers, params={"q": self.query})
return response.json()["web"]["results"][0:5]
providers = [WebSearchProvider]
with OpenAIChatModel(name="gpt-4o-mini") as llm:
response = llm.ask(prompt="Who won the 400m men individual medley at the 2024 Olympics?", tools=providers)
print(response.choices[0].message.content)You can combine tool usage with structured output generation. This allows the LLM to use a tool and produce a structured response simultaneously. Here's an example of adding computational capabilities:
import hashlib
from enum import Enum
from dataclasses import dataclass
from llm_core.assistants import OpenAIAssistant
HashFunction = Enum("HashFunction", ["sha512", "sha256", "md5"])
@dataclass
class HashProvider:
hash_function: HashFunction
content: str
def __call__(self):
hash_fn = getattr(hashlib, self.hash_function.name)
return hash_fn(self.content.encode('utf-8')).hexdigest()
@dataclass
class Hash:
system_prompt = "You are a helpful assistant"
prompt = "{prompt}"
hashed_content: str
hash_algorithm: HashFunction
hash_value: str
@classmethod
def ask(cls, prompt):
with OpenAIAssistant(cls, tools=[HashProvider]) as assistant:
response = assistant.process(prompt=prompt)
return response
Hash.ask('Compute the sha256 for the string `py-llm-core`')py-llm-core uses Tiktoken to estimate the length of strings in tokens. It is registered as a codec within the Python codecs registry :
from llm_core.splitters import TokenSplitter
import codecs
text = """Foundation is a science fiction novel by American writer
Isaac Asimov. It is the first published in his Foundation Trilogy (later
expanded into the Foundation series). Foundation is a cycle of five
interrelated short stories, first published as a single book by Gnome Press
in 1951. Collectively they tell the early story of the Foundation,
an institute founded by psychohistorian Hari Seldon to preserve the best
of galactic civilization after the collapse of the Galactic Empire.
"""
# You can encode the text into tokens like that:
tokens = codecs.encode(text, 'tiktoken')
token_length = len(tokens)
# Chunking and splitting
splitter = TokenSplitter(
chunk_size=50,
chunk_overlap=0
)
for chunk in splitter.chunkify(text):
print(chunk)One useful use case when interacting with LLMs is their ability to understand what a user wants to achieve using natural language.
Here's a simplified example :
from enum import Enum
from dataclasses import dataclass
from llm_core.assistants import OpenWeightsAssistant
class TargetItem(Enum):
PROJECT = 1
TASK = 2
COMMENT = 3
MEETING = 4
class CRUDOperation(Enum):
CREATE = 1
READ = 2
UPDATE = 3
DELETE = 4
@dataclass
class UserQuery:
system_prompt = "You are a helpful assistant."
prompt = """
Analyze the user's query and convert his intent to:
- an operation (among CRUD)
- a target item
Query: {prompt}
"""
operation: CRUDOperation
target: TargetItem
def ask(prompt):
with OpenWeightsAssistant(UserQuery, model="llama-8b-3.1-q4", loader_kwargs={"n_ctx": 4_000}) as assistant:
user_query = assistant.process(prompt=prompt)
return user_query
ask('Cancel all my meetings for the week')-
3.4.13: Disabled parallel_tool_calls (improved)
-
3.4.12: Fixed export of AzureOpenAIAssistant
-
3.4.11: Updated loader_kwargs override
-
3.4.10: Added helpers for Azure OpenAI models
-
3.4.9: Added suppport for Google AI Gemini
-
3.4.8: Removed unsupported attributes for Usage
-
3.4.7: Added support for
completion_tokens_details -
3.4.6: Fixed a bug appearing when the LLM does not want to use any tool
-
3.4.5:
- Fixed parallel_tool_calls bug
- Added support for
raw_tool_resultsargument inaskto stop generation and output unprocessed tool results.
-
3.4.4: Improved the tool use prompting and structure
-
3.4.3: Disabled parallel_tool_calls
-
3.4.2: Fixed bug when using more than one tool
-
3.4.1: Fixed bug when building field type name
-
3.4.0: Fixed prompt when using tools
-
3.3.0: Added support for Python 3.8
-
3.2.0: Added support for Anthropic models
-
3.1.0:
- Added back support for Azure OpenAI
- Unified the way to load language models (API or Open Weights)
-
3.0.0:
- Simplified the code and the documentation
- Upgraded Mistral AI dependencies (Use
MistralAIModelclass) - Simplified management of tokens
- Dropped Azure AI support
- Dropped LLaVACPPModel support
- Dropped NuExtract support
- Moved assistant implementations to a separate package
- Refactored API gated model code
- Renamed llama_cpp_compatible to open_weights
-
2.8.15: Fixed a bug when using only one tool
-
2.8.13: Rewrite of the function calling to add support for tools (OpenAI and LLaMA compatible)
-
2.8.11: Add support for NuExtract models
-
2.8.10: Add gpt-4o-2024-05-13
-
2.8.5: Fix model path building
-
2.8.4: Added support for Mistral Large
-
2.8.3: Raised timeout
-
2.8.1: Fixed bug when deserializing instances
-
2.8.0: Added support for native type annotation (pep585) for lists and sets
-
2.7.0: Fixed bug when function_call was set at None
-
2.6.1: Add dynamic max_tokens computation for OpenAI
-
2.6.0: Add support for Azure OpenAI
-
2.5.1: Fix bug on system prompt format
-
2.5.0: Add support for LLaVA models
-
2.4.0:
- Set timeouts on OpenAI API
-
2.2.0:
- Default settings on ARM64 MacOS modified (1 thread / offloading everything on the GPU)
- Added
completion_kwargsfor Assistants to set temperature
-
2.1.0:
- Added support for Enum to provide better support for classification tasks
- Added example in the documentation
-
2.0.0:
- Refactored code
- Dynamically enable GPU offloading on MacOS
- Added configuration option for storing local models (MODELS_CACHE_DIR)
- Updated documentation
-
1.4.0: Free up resources in LLamaParser when exiting the context manager
-
1.3.0: Support for LLaMA based models (llama, llama2, Mistral Instruct)
-
1.2.0: Chain of density prompting implemented with OpenAI
-
1.1.0: Chain of Verification implemented with OpenAI
-
1.0.0: Initial version
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for py-llm-core
Similar Open Source Tools
py-llm-core
PyLLMCore is a light-weighted interface with Large Language Models with native support for llama.cpp, OpenAI API, and Azure deployments. It offers a Pythonic API that is simple to use, with structures provided by the standard library dataclasses module. The high-level API includes the assistants module for easy swapping between models. PyLLMCore supports various models including those compatible with llama.cpp, OpenAI, and Azure APIs. It covers use cases such as parsing, summarizing, question answering, hallucinations reduction, context size management, and tokenizing. The tool allows users to interact with language models for tasks like parsing text, summarizing content, answering questions, reducing hallucinations, managing context size, and tokenizing text.
effective_llm_alignment
This is a super customizable, concise, user-friendly, and efficient toolkit for training and aligning LLMs. It provides support for various methods such as SFT, Distillation, DPO, ORPO, CPO, SimPO, SMPO, Non-pair Reward Modeling, Special prompts basket format, Rejection Sampling, Scoring using RM, Effective FAISS Map-Reduce Deduplication, LLM scoring using RM, NER, CLIP, Classification, and STS. The toolkit offers key libraries like PyTorch, Transformers, TRL, Accelerate, FSDP, DeepSpeed, and tools for result logging with wandb or clearml. It allows mixing datasets, generation and logging in wandb/clearml, vLLM batched generation, and aligns models using the SMPO method.

open-webui-tools
Open WebUI Tools Collection is a set of tools for structured planning, arXiv paper search, Hugging Face text-to-image generation, prompt enhancement, and multi-model conversations. It enhances LLM interactions with academic research, image generation, and conversation management. Tools include arXiv Search Tool and Hugging Face Image Generator. Function Pipes like Planner Agent offer autonomous plan generation and execution. Filters like Prompt Enhancer improve prompt quality. Installation and configuration instructions are provided for each tool and pipe.

exospherehost
Exosphere is an open source infrastructure designed to run AI agents at scale for large data and long running flows. It allows developers to define plug and playable nodes that can be run on a reliable backbone in the form of a workflow, with features like dynamic state creation at runtime, infinite parallel agents, persistent state management, and failure handling. This enables the deployment of production agents that can scale beautifully to build robust autonomous AI workflows.

company-research-agent
Agentic Company Researcher is a multi-agent tool that generates comprehensive company research reports by utilizing a pipeline of AI agents to gather, curate, and synthesize information from various sources. It features multi-source research, AI-powered content filtering, real-time progress streaming, dual model architecture, modern React frontend, and modular architecture. The tool follows an agentic framework with specialized research and processing nodes, leverages separate models for content generation, uses a content curation system for relevance scoring and document processing, and implements a real-time communication system via WebSocket connections. Users can set up the tool quickly using the provided setup script or manually, and it can also be deployed using Docker and Docker Compose. The application can be used for local development and deployed to various cloud platforms like AWS Elastic Beanstalk, Docker, Heroku, and Google Cloud Run.
tinystruct
Tinystruct is a simple Java framework designed for easy development with better performance. It offers a modern approach with features like CLI and web integration, built-in lightweight HTTP server, minimal configuration philosophy, annotation-based routing, and performance-first architecture. Developers can focus on real business logic without dealing with unnecessary complexities, making it transparent, predictable, and extensible.
Groqqle
Groqqle 2.1 is a revolutionary, free AI web search and API that instantly returns ORIGINAL content derived from source articles, websites, videos, and even foreign language sources, for ANY target market of ANY reading comprehension level! It combines the power of large language models with advanced web and news search capabilities, offering a user-friendly web interface, a robust API, and now a powerful Groqqle_web_tool for seamless integration into your projects. Developers can instantly incorporate Groqqle into their applications, providing a powerful tool for content generation, research, and analysis across various domains and languages.
Google_GenerativeAI
Google GenerativeAI (Gemini) is an unofficial C# .Net SDK based on REST APIs for accessing Google Gemini models. It offers a complete rewrite of the previous SDK with improved performance, flexibility, and ease of use. The SDK seamlessly integrates with LangChain.net, providing easy methods for JSON-based interactions and function calling with Google Gemini models. It includes features like enhanced JSON mode handling, function calling with code generator, multi-modal functionality, Vertex AI support, multimodal live API, image generation and captioning, retrieval-augmented generation with Vertex RAG Engine and Google AQA, easy JSON handling, Gemini tools and function calling, multimodal live API, and more.
FileScopeMCP
FileScopeMCP is a TypeScript-based tool for ranking files in a codebase by importance, tracking dependencies, and providing summaries. It analyzes code structure, generates importance scores, maps bidirectional dependencies, visualizes file relationships, and allows adding custom summaries. The tool supports multiple languages, persistent storage, and offers tools for file tree management, file analysis, file summaries, diagram generation, and file watching. It is built with TypeScript/Node.js, implements the Model Context Protocol, uses Mermaid.js for diagram generation, and stores data in JSON format. FileScopeMCP aims to enhance code understanding and visualization for developers.
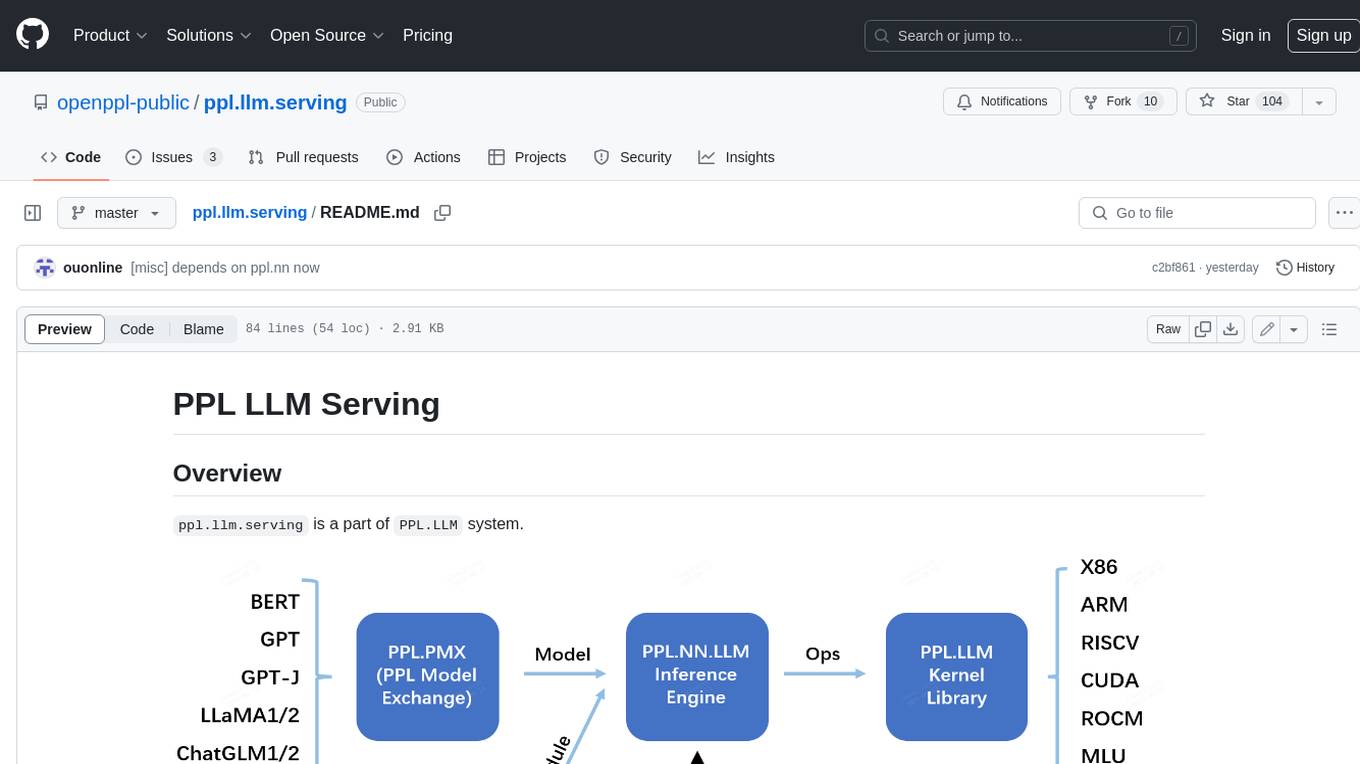
ppl.llm.serving
PPL LLM Serving is a serving based on ppl.nn for various Large Language Models (LLMs). It provides inference support for LLaMA. Key features include: * **High Performance:** Optimized for fast and efficient inference on LLM models. * **Scalability:** Supports distributed deployment across multiple GPUs or machines. * **Flexibility:** Allows for customization of model configurations and inference pipelines. * **Ease of Use:** Provides a user-friendly interface for deploying and managing LLM models. This tool is suitable for various tasks, including: * **Text Generation:** Generating text, stories, or code from scratch or based on a given prompt. * **Text Summarization:** Condensing long pieces of text into concise summaries. * **Question Answering:** Answering questions based on a given context or knowledge base. * **Language Translation:** Translating text between different languages. * **Chatbot Development:** Building conversational AI systems that can engage in natural language interactions. Keywords: llm, large language model, natural language processing, text generation, question answering, language translation, chatbot development
MCPSharp
MCPSharp is a .NET library that helps build Model Context Protocol (MCP) servers and clients for AI assistants and models. It allows creating MCP-compliant tools, connecting to existing MCP servers, exposing .NET methods as MCP endpoints, and handling MCP protocol details seamlessly. With features like attribute-based API, JSON-RPC support, parameter validation, and type conversion, MCPSharp simplifies the development of AI capabilities in applications through standardized interfaces.

DeepPavlov
DeepPavlov is an open-source conversational AI library built on PyTorch. It is designed for the development of production-ready chatbots and complex conversational systems, as well as for research in the area of NLP and dialog systems. The library offers a wide range of models for tasks such as Named Entity Recognition, Intent/Sentence Classification, Question Answering, Sentence Similarity/Ranking, Syntactic Parsing, and more. DeepPavlov also provides embeddings like BERT, ELMo, and FastText for various languages, along with AutoML capabilities and integrations with REST API, Socket API, and Amazon AWS.

sdialog
SDialog is an MIT-licensed open-source toolkit for building, simulating, and evaluating LLM-based conversational agents end-to-end. It aims to bridge agent construction, user simulation, dialog generation, and evaluation in a single reproducible workflow, enabling the generation of reliable, controllable dialog systems or data at scale. The toolkit standardizes a Dialog schema, offers persona-driven multi-agent simulation with LLMs, provides composable orchestration for precise control over behavior and flow, includes built-in evaluation metrics, and offers mechanistic interpretability. It allows for easy creation of user-defined components and interoperability across various AI platforms.

Fabric
Fabric is an open-source framework designed to augment humans using AI by organizing prompts by real-world tasks. It addresses the integration problem of AI by creating and organizing prompts for various tasks. Users can create, collect, and organize AI solutions in a single place for use in their favorite tools. Fabric also serves as a command-line interface for those focused on the terminal. It offers a wide range of features and capabilities, including support for multiple AI providers, internationalization, speech-to-text, AI reasoning, model management, web search, text-to-speech, desktop notifications, and more. The project aims to help humans flourish by leveraging AI technology to solve human problems and enhance creativity.
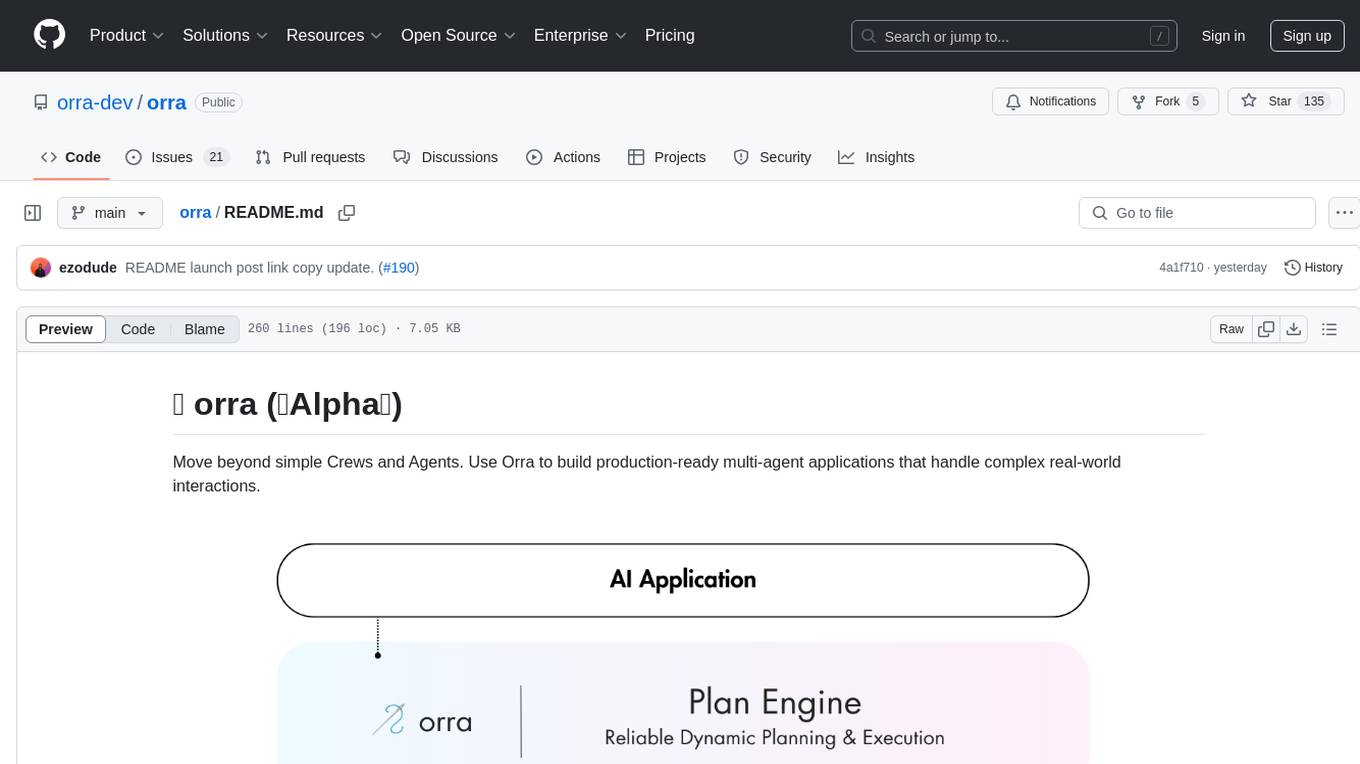
orra
Orra is a tool for building production-ready multi-agent applications that handle complex real-world interactions. It coordinates tasks across existing stack, agents, and tools run as services using intelligent reasoning. With features like smart pre-evaluated execution plans, domain grounding, durable execution, and automatic service health monitoring, Orra enables users to go fast with tools as services and revert state to handle failures. It provides real-time status tracking and webhook result delivery, making it ideal for developers looking to move beyond simple crews and agents.
clearml-serving
ClearML Serving is a command line utility for model deployment and orchestration, enabling model deployment including serving and preprocessing code to a Kubernetes cluster or custom container based solution. It supports machine learning models like Scikit Learn, XGBoost, LightGBM, and deep learning models like TensorFlow, PyTorch, ONNX. It provides a customizable RestAPI for serving, online model deployment, scalable solutions, multi-model per container, automatic deployment, canary A/B deployment, model monitoring, usage metric reporting, metric dashboard, and model performance metrics. ClearML Serving is modular, scalable, flexible, customizable, and open source.
For similar tasks

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

onnxruntime-genai
ONNX Runtime Generative AI is a library that provides the generative AI loop for ONNX models, including inference with ONNX Runtime, logits processing, search and sampling, and KV cache management. Users can call a high level `generate()` method, or run each iteration of the model in a loop. It supports greedy/beam search and TopP, TopK sampling to generate token sequences, has built in logits processing like repetition penalties, and allows for easy custom scoring.

jupyter-ai
Jupyter AI connects generative AI with Jupyter notebooks. It provides a user-friendly and powerful way to explore generative AI models in notebooks and improve your productivity in JupyterLab and the Jupyter Notebook. Specifically, Jupyter AI offers: * An `%%ai` magic that turns the Jupyter notebook into a reproducible generative AI playground. This works anywhere the IPython kernel runs (JupyterLab, Jupyter Notebook, Google Colab, Kaggle, VSCode, etc.). * A native chat UI in JupyterLab that enables you to work with generative AI as a conversational assistant. * Support for a wide range of generative model providers, including AI21, Anthropic, AWS, Cohere, Gemini, Hugging Face, NVIDIA, and OpenAI. * Local model support through GPT4All, enabling use of generative AI models on consumer grade machines with ease and privacy.

khoj
Khoj is an open-source, personal AI assistant that extends your capabilities by creating always-available AI agents. You can share your notes and documents to extend your digital brain, and your AI agents have access to the internet, allowing you to incorporate real-time information. Khoj is accessible on Desktop, Emacs, Obsidian, Web, and Whatsapp, and you can share PDF, markdown, org-mode, notion files, and GitHub repositories. You'll get fast, accurate semantic search on top of your docs, and your agents can create deeply personal images and understand your speech. Khoj is self-hostable and always will be.

langchain_dart
LangChain.dart is a Dart port of the popular LangChain Python framework created by Harrison Chase. LangChain provides a set of ready-to-use components for working with language models and a standard interface for chaining them together to formulate more advanced use cases (e.g. chatbots, Q&A with RAG, agents, summarization, extraction, etc.). The components can be grouped into a few core modules: * **Model I/O:** LangChain offers a unified API for interacting with various LLM providers (e.g. OpenAI, Google, Mistral, Ollama, etc.), allowing developers to switch between them with ease. Additionally, it provides tools for managing model inputs (prompt templates and example selectors) and parsing the resulting model outputs (output parsers). * **Retrieval:** assists in loading user data (via document loaders), transforming it (with text splitters), extracting its meaning (using embedding models), storing (in vector stores) and retrieving it (through retrievers) so that it can be used to ground the model's responses (i.e. Retrieval-Augmented Generation or RAG). * **Agents:** "bots" that leverage LLMs to make informed decisions about which available tools (such as web search, calculators, database lookup, etc.) to use to accomplish the designated task. The different components can be composed together using the LangChain Expression Language (LCEL).

danswer
Danswer is an open-source Gen-AI Chat and Unified Search tool that connects to your company's docs, apps, and people. It provides a Chat interface and plugs into any LLM of your choice. Danswer can be deployed anywhere and for any scale - on a laptop, on-premise, or to cloud. Since you own the deployment, your user data and chats are fully in your own control. Danswer is MIT licensed and designed to be modular and easily extensible. The system also comes fully ready for production usage with user authentication, role management (admin/basic users), chat persistence, and a UI for configuring Personas (AI Assistants) and their Prompts. Danswer also serves as a Unified Search across all common workplace tools such as Slack, Google Drive, Confluence, etc. By combining LLMs and team specific knowledge, Danswer becomes a subject matter expert for the team. Imagine ChatGPT if it had access to your team's unique knowledge! It enables questions such as "A customer wants feature X, is this already supported?" or "Where's the pull request for feature Y?"

infinity
Infinity is an AI-native database designed for LLM applications, providing incredibly fast full-text and vector search capabilities. It supports a wide range of data types, including vectors, full-text, and structured data, and offers a fused search feature that combines multiple embeddings and full text. Infinity is easy to use, with an intuitive Python API and a single-binary architecture that simplifies deployment. It achieves high performance, with 0.1 milliseconds query latency on million-scale vector datasets and up to 15K QPS.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.
LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.