
hallucination-leaderboard
Leaderboard Comparing LLM Performance at Producing Hallucinations when Summarizing Short Documents
Stars: 1358
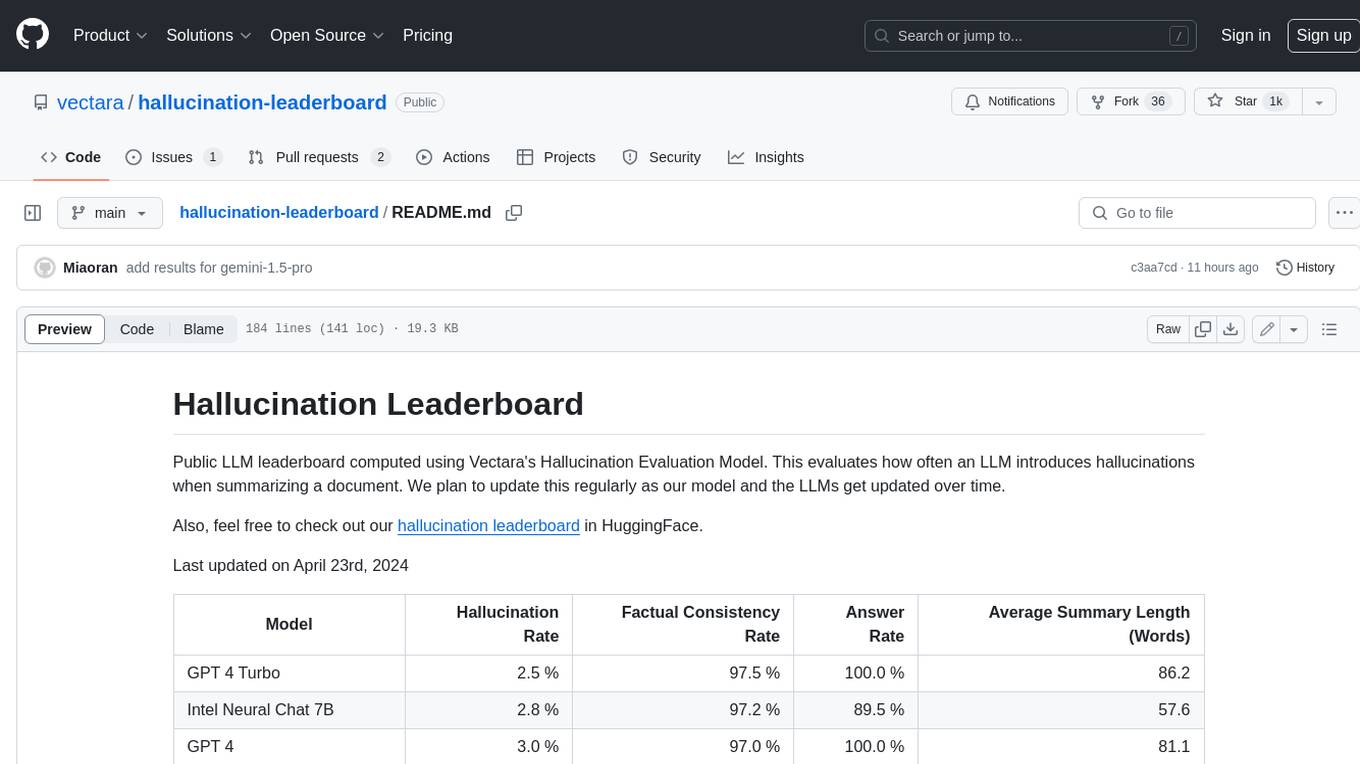
This leaderboard evaluates the hallucination rate of various Large Language Models (LLMs) when summarizing documents. It uses a model trained by Vectara to detect hallucinations in LLM outputs. The leaderboard includes models from OpenAI, Anthropic, Google, Microsoft, Amazon, and others. The evaluation is based on 831 documents that were summarized by all the models. The leaderboard shows the hallucination rate, factual consistency rate, answer rate, and average summary length for each model.
README:
Public LLM leaderboard computed using Vectara's Hughes Hallucination Evaluation Model. This evaluates how often an LLM introduces hallucinations when summarizing a document. We plan to update this regularly as our model and the LLMs get updated over time.
Also, feel free to check out our hallucination leaderboard on Hugging Face.
The rankings in this leaderboard are computed using the HHEM-2.1 hallucination evaluation model. If you are interested in the previous leaderboard, which was based on HHEM-1.0, it is available here

|
In loving memory of Simon Mark Hughes... |
Last updated on January 29th, 2025
![]()
| Model | Hallucination Rate | Factual Consistency Rate | Answer Rate | Average Summary Length (Words) |
|---|---|---|---|---|
| Zhipu AI GLM-4-9B-Chat | 1.3 % | 98.7 % | 100.0 % | 58.1 |
| Google Gemini-2.0-Flash-Exp | 1.3 % | 98.7 % | 99.9 % | 60.0 |
| OpenAI-o1-mini | 1.4 % | 98.6 % | 100.0 % | 78.3 |
| GPT-4o | 1.5 % | 98.5 % | 100.0 % | 77.8 |
| GPT-4o-mini | 1.7 % | 98.3 % | 100.0 % | 76.3 |
| GPT-4-Turbo | 1.7 % | 98.3 % | 100.0 % | 86.2 |
| Google Gemini-2.0-Flash-Thinking-Exp | 1.8 % | 98.2 % | 99.3 % | 73.2 |
| GPT-4 | 1.8 % | 98.2 % | 100.0 % | 81.1 |
| GPT-3.5-Turbo | 1.9 % | 98.1 % | 99.6 % | 84.1 |
| OpenAI-o1 | 2.4 % | 97.6 % | 99.9 % | 73.0 |
| DeepSeek-V2.5 | 2.4 % | 97.6 % | 100.0 % | 83.2 |
| Microsoft Orca-2-13b | 2.5 % | 97.5 % | 100.0 % | 66.2 |
| Microsoft Phi-3.5-MoE-instruct | 2.5 % | 97.5 % | 96.3 % | 69.7 |
| Intel Neural-Chat-7B-v3-3 | 2.6 % | 97.4 % | 100.0 % | 60.7 |
| Qwen2.5-7B-Instruct | 2.8 % | 97.2 % | 100.0 % | 71.0 |
| AI21 Jamba-1.5-Mini | 2.9 % | 97.1 % | 95.6 % | 74.5 |
| Snowflake-Arctic-Instruct | 3.0 % | 97.0 % | 100.0 % | 68.7 |
| Qwen2.5-32B-Instruct | 3.0 % | 97.0 % | 100.0 % | 67.9 |
| Microsoft Phi-3-mini-128k-instruct | 3.1 % | 96.9 % | 100.0 % | 60.1 |
| OpenAI-o1-preview | 3.3 % | 96.7 % | 100.0 % | 119.3 |
| Google Gemini-1.5-Flash-002 | 3.4 % | 96.6 % | 99.9 % | 59.4 |
| 01-AI Yi-1.5-34B-Chat | 3.7 % | 96.3 % | 100.0 % | 83.7 |
| Llama-3.1-405B-Instruct | 3.9 % | 96.1 % | 99.6 % | 85.7 |
| DeepSeek-V3 | 3.9 % | 96.1 % | 100.0 % | 88.2 |
| Microsoft Phi-3-mini-4k-instruct | 4.0 % | 96.0 % | 100.0 % | 86.8 |
| Llama-3.3-70B-Instruct | 4.0 % | 96.0 % | 100.0 % | 85.3 |
| Microsoft Phi-3.5-mini-instruct | 4.1 % | 95.9 % | 100.0 % | 75.0 |
| Mistral-Large2 | 4.1 % | 95.9 % | 100.0 % | 77.4 |
| Llama-3-70B-Chat-hf | 4.1 % | 95.9 % | 99.2 % | 68.5 |
| Qwen2-VL-7B-Instruct | 4.2 % | 95.8 % | 100.0 % | 73.9 |
| Qwen2.5-14B-Instruct | 4.2 % | 95.8 % | 100.0 % | 74.8 |
| Qwen2.5-72B-Instruct | 4.3 % | 95.7 % | 100.0 % | 80.0 |
| Llama-3.2-90B-Vision-Instruct | 4.3 % | 95.7 % | 100.0 % | 79.8 |
| XAI Grok | 4.6 % | 95.4 % | 100.0 % | 91.0 |
| Anthropic Claude-3-5-sonnet | 4.6 % | 95.4 % | 100.0 % | 95.9 |
| Qwen2-72B-Instruct | 4.7 % | 95.3 % | 100.0 % | 100.1 |
| Microsoft Phi-4 | 4.7 % | 95.3 % | 100.0 % | 100.3 |
| Mixtral-8x22B-Instruct-v0.1 | 4.7 % | 95.3 % | 99.9 % | 92.0 |
| Anthropic Claude-3-5-haiku | 4.9 % | 95.1 % | 100.0 % | 92.9 |
| 01-AI Yi-1.5-9B-Chat | 4.9 % | 95.1 % | 100.0 % | 85.7 |
| Cohere Command-R | 4.9 % | 95.1 % | 100.0 % | 68.7 |
| Llama-3.1-70B-Instruct | 5.0 % | 95.0 % | 100.0 % | 79.6 |
| Llama-3.1-8B-Instruct | 5.4 % | 94.6 % | 100.0 % | 71.0 |
| Cohere Command-R-Plus | 5.4 % | 94.6 % | 100.0 % | 68.4 |
| Llama-3.2-11B-Vision-Instruct | 5.5 % | 94.5 % | 100.0 % | 67.3 |
| Llama-2-70B-Chat-hf | 5.9 % | 94.1 % | 99.9 % | 84.9 |
| IBM Granite-3.0-8B-Instruct | 6.5 % | 93.5 % | 100.0 % | 74.2 |
| Google Gemini-1.5-Pro-002 | 6.6 % | 93.7 % | 99.9 % | 62.0 |
| Google Gemini-1.5-Flash | 6.6 % | 93.4 % | 99.9 % | 63.3 |
| Microsoft phi-2 | 6.7 % | 93.3 % | 91.5 % | 80.8 |
| Google Gemma-2-2B-it | 7.0 % | 93.0 % | 100.0 % | 62.2 |
| Qwen2.5-3B-Instruct | 7.0 % | 93.0 % | 100.0 % | 70.4 |
| Llama-3-8B-Chat-hf | 7.4 % | 92.6 % | 99.8 % | 79.7 |
| Google Gemini-Pro | 7.7 % | 92.3 % | 98.4 % | 89.5 |
| 01-AI Yi-1.5-6B-Chat | 7.9 % | 92.1 % | 100.0 % | 98.9 |
| Llama-3.2-3B-Instruct | 7.9 % | 92.1 % | 100.0 % | 72.2 |
| databricks dbrx-instruct | 8.3 % | 91.7 % | 100.0 % | 85.9 |
| Qwen2-VL-2B-Instruct | 8.3 % | 91.7 % | 100.0 % | 81.8 |
| Cohere Aya Expanse 32B | 8.5 % | 91.5 % | 99.9 % | 81.9 |
| IBM Granite-3.1-8B-Instruct | 8.6 % | 91.4 % | 100.0 % | 107.4 |
| IBM Granite-3.0-2B-Instruct | 8.8 % | 91.2 % | 100.0 % | 81.6 |
| Mistral-7B-Instruct-v0.3 | 9.5 % | 90.5 % | 100.0 % | 98.4 |
| Google Gemini-1.5-Pro | 9.1 % | 90.9 % | 99.8 % | 61.6 |
| Anthropic Claude-3-opus | 10.1 % | 89.9 % | 95.5 % | 92.1 |
| Google Gemma-2-9B-it | 10.1 % | 89.9 % | 100.0 % | 70.2 |
| Llama-2-13B-Chat-hf | 10.5 % | 89.5 % | 99.8 % | 82.1 |
| AllenAI-OLMo-2-13B-Instruct | 10.8 % | 89.2 % | 100.0 % | 82.0 |
| AllenAI-OLMo-2-7B-Instruct | 11.1 % | 88.9 % | 100.0 % | 112.6 |
| Mistral-Nemo-Instruct | 11.2 % | 88.8 % | 100.0 % | 69.9 |
| Llama-2-7B-Chat-hf | 11.3 % | 88.7 % | 99.6 % | 119.9 |
| Microsoft WizardLM-2-8x22B | 11.7 % | 88.3 % | 99.9 % | 140.8 |
| Cohere Aya Expanse 8B | 12.2 % | 87.8 % | 99.9 % | 83.9 |
| Amazon Titan-Express | 13.5 % | 86.5 % | 99.5 % | 98.4 |
| Google PaLM-2 | 14.1 % | 85.9 % | 99.8 % | 86.6 |
| DeepSeek-R1 | 14.3 % | 85.7 % | 100.0% | 77.1 |
| Google Gemma-7B-it | 14.8 % | 85.2 % | 100.0 % | 113.0 |
| IBM Granite-3.1-2B-Instruct | 15.7 % | 84.3 % | 100.0 % | 107.7 |
| Qwen2.5-1.5B-Instruct | 15.8 % | 84.2 % | 100.0 % | 70.7 |
| Qwen-QwQ-32B-Preview | 16.1 % | 83.9 % | 100.0 % | 201.5 |
| Anthropic Claude-3-sonnet | 16.3 % | 83.7 % | 100.0 % | 108.5 |
| Google Gemma-1.1-7B-it | 17.0 % | 83.0 % | 100.0 % | 64.3 |
| Anthropic Claude-2 | 17.4 % | 82.6 % | 99.3 % | 87.5 |
| Google Flan-T5-large | 18.3 % | 81.7 % | 99.3 % | 20.9 |
| Mixtral-8x7B-Instruct-v0.1 | 20.1 % | 79.9 % | 99.9 % | 90.7 |
| Llama-3.2-1B-Instruct | 20.7 % | 79.3 % | 100.0 % | 71.5 |
| Apple OpenELM-3B-Instruct | 24.8 % | 75.2 % | 99.3 % | 47.2 |
| Qwen2.5-0.5B-Instruct | 25.2 % | 74.8 % | 100.0 % | 72.6 |
| Google Gemma-1.1-2B-it | 27.8 % | 72.2 % | 100.0 % | 66.8 |
| TII falcon-7B-instruct | 29.9 % | 70.1 % | 90.0 % | 75.5 |
This leaderboard uses HHEM-2.1, Vectara's commercial hallucination evaluation model, to compute the LLM rankings. You can find an open-source variant of that model, HHEM-2.1-Open on Hugging Face and Kaggle.
See this dataset for the generated summaries we used for evaluating the models.
Much prior work in this area has been done. For some of the top papers in this area (factual consistency in summarization) please see here:
- SUMMAC: Re-Visiting NLI-based Models for Inconsistency Detection in Summarization
- TRUE: Re-evaluating Factual Consistency Evaluation
- TrueTeacher: Learning Factual Consistency Evaluation with Large Language Models
- ALIGNSCORE: Evaluating Factual Consistency with A Unified Alignment Function
- MiniCheck: Efficient Fact-Checking of LLMs on Grounding Documents
For a very comprehensive list, please see here - https://github.com/EdinburghNLP/awesome-hallucination-detection. The methods described in the following section use protocols established in those papers, amongst many others.
For a detailed explanation of the work that went into this model please refer to our blog post on the release: Cut the Bull…. Detecting Hallucinations in Large Language Models.
To determine this leaderboard, we trained a model to detect hallucinations in LLM outputs, using various open source datasets from the factual consistency research into summarization models. Using a model that is competitive with the best state of the art models, we then fed 1000 short documents to each of the LLMs above via their public APIs and asked them to summarize each short document, using only the facts presented in the document. Of these 1000 documents, only 831 document were summarized by every model, the remaining documents were rejected by at least one model due to content restrictions. Using these 831 documents, we then computed the overall factual consistency rate (no hallucinations) and hallucination rate (100 - accuracy) for each model. The rate at which each model refuses to respond to the prompt is detailed in the 'Answer Rate' column. None of the content sent to the models contained illicit or 'not safe for work' content but the present of trigger words was enough to trigger some of the content filters. The documents were taken primarily from the CNN / Daily Mail Corpus. We used a temperature of 0 when calling the LLMs.
We evaluate summarization factual consistency rate instead of overall factual accuracy because it allows us to compare the model's response to the provided information. In other words, is the summary provided 'factually consistent' with the source document. Determining hallucinations is impossible to do for any ad hoc question as it's not known precisely what data every LLM is trained on. In addition, having a model that can determine whether any response was hallucinated without a reference source requires solving the hallucination problem and presumably training a model as large or larger than these LLMs being evaluated. So we instead chose to look at the hallucination rate within the summarization task as this is a good analogue to determine how truthful the models are overall. In addition, LLMs are increasingly used in RAG (Retrieval Augmented Generation) pipelines to answer user queries, such as in Bing Chat and Google's chat integration. In a RAG system, the model is being deployed as a summarizer of the search results, so this leaderboard is also a good indicator for the accuracy of the models when used in RAG systems.
You are a chat bot answering questions using data. You must stick to the answers provided solely by the text in the passage provided. You are asked the question 'Provide a concise summary of the following passage, covering the core pieces of information described.' <PASSAGE>'
When calling the API, the <PASSAGE> token was then replaced with the source document (see the 'source' column in this dataset ).
Below is a detailed overview of the models integrated and their specific endpoints:
-
GPT-3.5: Accessed using the model name
gpt-3.5-turbothrough OpenAI's Python client library, specifically via thechat.completions.createendpoint. -
GPT-4: Integrated with the model identifier
gpt-4. -
GPT-4 Turbo: Utilized under the model name
gpt-4-turbo-2024-04-09, in line with OpenAI's documentation. -
GPT-4o: Accessed using the model name
gpt-4o. -
GPT-4o-mini: Accessed using the model name
gpt-4o-mini. -
o1-mini: Accessed using the model name
o1-mini. -
o1-preview: Accessed using the model name
o1-preview. -
o1: Accessed using the model name
o1.
-
Llama 2 7B, 13B, and 70B: These models of varying sizes are accessed through Anyscale hosted endpoints using model
meta-llama/Llama-2-xxb-chat-hf, wherexxbcan be7b,13b, and70b, tailored to each model's capacity. -
Llama 3 8B and 70B: These models are accessed via Together AI
chatendpoint and using the modelmeta-llama/Llama-3-xxB-chat-hf, wherexxBcan be8Band70B. -
Llama 3.1 8B, 70B and 405B: The models meta-llama/Meta-Llama-3.1-70B-Instruct and meta-llama/Meta-Llama-3.1-8B-Instruct are accessed via Hugging Face's checkpoint. The model
Meta-Llama-3.1-405B-Instructis accessed via Replicate's API using the modelmeta/meta-llama-3.1-405b-instruct. -
Llama 3.2 1B and 3B: The model meta-llama/Meta-Llama-3.2-1B-Instruct is accessed via Hugging Face's checkpoint. The model
Meta-Llama-3.2-3B-Instructis accessed via Together AIchatendpoint using modelmeta-llama/Llama-3.2-3B-Instruct-Turbo. -
Llama 3.2 Vision 11B and 90B:The models
Llama-3.2-11B-Vision-InstructandLlama-3.2-90B-Vision-Instructare accessed via Together AIchatendpoint using modelmeta-llama/Llama-3.2-11B-Vision-Instruct-Turboandmeta-llama/Llama-3.2-90B-Vision-Instruct-Turbo. - Llama 3.3 70B: The model meta-llama/Llama-3.3-70B-Instruct is accessed via Hugging Face's checkpoint.
-
Cohere Command R: Employed using the model
command-r-08-2024and the/chatendpoint. -
Cohere Command R Plus: Employed using the model
command-r-plus-08-2024and the/chatendpoint. -
Aya Expanse 8B, 32B: Accessed using models
c4ai-aya-expanse-8bandc4ai-aya-expanse-32b. For more information about Cohere's models, refer to their website.
-
Claude 2: Invoked the model using
claude-2.0for the API call. -
Claude 3 Opus: Invoked the model using
claude-3-opus-20240229for the API call. -
Claude 3 Sonnet: Invoked the model using
claude-3-sonnet-20240229for the API call. -
Claude 3.5 Sonnet: Invoked the model using
claude-3-5-sonnet-20241022for the API call. -
Claude 3.5 Haiku: Invoked the model using
claude-3-5-haiku-20241022for the API call. - Claude 3.5 Haiku: Details on each model can be found on their website.
- Mixtral 8x7B: The Mixtral-8x7B-Instruct-v0.1 model is accessed via Hugging Face's API.
-
Mixtral 8x22B: Accessed via Together AI's API using the model
mistralai/Mixtral-8x22B-Instruct-v0.1and thechatendpoint. -
Mistral Large2: Accessed via Mistral AI's API using the model
mistral-large-latest. - Mistral-7B-Instruct-v0.3: The Mistral-7B-Instruct-v0.3 model is accessed by being loaded from Hugging Face's checkpoint.
- Mistral-Nemo-Instruct The Mistral-Nemo-Instruct-2407 model is accessed via Hugging Face's checkpoint.
-
Google Palm 2: Implemented using the
text-bison-001model, respectively. -
Gemini Pro: Google's
gemini-promodel is incorporated for enhanced language processing, accessible on Vertex AI. -
Gemini 1.5 Pro: Accessed using model
gemini-1.5-pro-001on Vertex AI. -
Gemini 1.5 Flash: Accessed using model
gemini-1.5-flash-001on Vertex AI. -
Gemini 1.5 Pro 002: Accessed using model
gemini-1.5-pro-002on Vertex AI. -
Gemini 1.5 Flase 002: Accessed using model
gemini-1.5-flash-002on Vertex AI. -
Gemini 2.0 Flash Exp: Accessed using model
gemini-2.0-flash-expon Vertex AI. -
Gemini 2.0 Flash Thinking Exp: Accessed using model
gemini-2.0-flash-thinking-expon Vertex AI.
- Google flan-t5-large: The flan-t5-large model is accessed via Hugging Face's API.
- Google gemma-7b-it: The gemma-7b-it model is accessed via Hugging Face's API.
- Google gemma-1.1-7b-it : The gemma-1.1-7b-it model is accessed by being loaded from Hugging Face's checkpoint.
- Google gemma-1.1-2b-it : The gemma-1.1-2b-it model is accessed via being loaded from Hugging Face's checkpoint.
- Google gemma-2-9b-it : The gemma-2-9b-it model is accessed via being loaded from Hugging Face's checkpoint.
- Google gemma-2-2b-it : The gemma-2-2b-it model is accessed via being loaded from Hugging Face's checkpoint.
For an in-depth understanding of each model's version and lifecycle, especially those offered by Google, please refer to Model Versions and Lifecycles on Vertex AI.
-
Amazon Titan Express: The model is accessed on Amazon Bedrock with model identifier of
amazon.titan-text-express-v1.
- Microsoft Phi-2: The phi-2 model is accessed via Hugging Face's API.
- Microsoft Orca-2-13b: The Orca-2-13b model is accessed via Hugging Face's API.
-
Microsoft WizardLM-2-8x22B: Accessed via Together AI's API using the model
microsoft/WizardLM-2-8x22Band thechatendpoint. - Microsoft Phi-3-mini-4k: The phi-3-mini-4k model is accessed via Hugging Face's checkpoint.
- Microsoft Phi-3-mini-128k: The phi-3-mini-128k model is accessed via Hugging Face's checkpoint.
- Microsoft Phi-3.5-mini-instruct: The phi-3.5-mini-instruct model is accessed via Hugging Face's checkpoint.
- Microsoft Phi-3.5-MoE-instruct: The phi-3.5-MoE-instruct model is accessed via Hugging Face's checkpoint.
- Microsoft Phi-4: The phi-4 model is accessed via Hugging Face's checkpoint.
- tiiuae/falcon-7b-instruct: The falcon-7b-instruct model is accessed via Hugging Face's API.
- Intel/neural-chat-7b-v3-3: The Intel/neural-chat-7b-v3-3 model is accessed via Hugging Face's checkpoint.
-
Databricks/dbrx-instruct: Accessed via Together AI's API using the model
databricks/dbrx-instructand thechatendpoint.
-
Snowflake/snowflake-arctic-instruct: Accessed via Replicate's API using the model
snowflake/snowflake-arctic-instruct.
- Apple/OpenELM-3B-Instruct: The OpenELM-3B-Instruct model is accessed via being loaded from Hugging Face's checkpoint. The prompt for this model is the original prompt plus ''\n\nA concise summary is as follows:''
- 01-AI/Yi-1.5-Chat 6B, 9B, 34B: The models 01-ai/Yi-1.5-6B-Chat, 01-ai/Yi-1.5-9B-Chat, and 01-ai/Yi-1.5-34B-Chat are accessed via Hugging Face's checkpoint.
- Zhipu-AI/GLM-4-9B-Chat: The GLM-4-9B-Chat is accessed via Hugging Face's checkpoint.
-
Qwen/Qwen2-72B-Instruct: Accessed via Together AI
chatendpoint with model nameQwen/Qwen2-72B-Instruct. - Qwen/Qwen2-VL-Instruct 2B, 7B: The models Qwen/Qwen2-VL-2B-Instruct and Qwen/Qwen2-VL-7B-Instruct are accessed via Hugging Face's checkpoints.
- Qwen/Qwen2.5-Instruct 0.5B, 1.5B, 3B, 7B, 14B, 32B, 72B: The models Qwen2.5-0.5B-Instruct, Qwen2.5-1.5B-Instruct, Qwen2.5-3B-Instruct, Qwen2.5-7B-Instruct, Qwen2.5-14B-Instruct, Qwen2.5-32B-Instruct, and Qwen2.5-72B-Instruct are accessed via Hugging Face's checkpoints.
- Qwen/QwQ-32B-Preview: The model Qwen/QwQ-32B-Preview is accessed via Hugging Face's checkpoint.
- AI21-Jamba-1.5-Mini: The Jamba-1.5-Mini model is accessed via Hugging Face's checkpoint.
-
DeepSeek V2.5: Accessed via DeepSeek's API using
deepseek-chatmodel and thechatendpoint. -
DeepSeek V3: Accessed via DeepSeek's API using
deepseek-chatmodel and thechatendpoint. -
DeepSeek R1: Accessed via DeepSeek's API using
deepseek-reasonermodel and thereasonerendpoint.
- Granite-3.0-Instruct 2B, 8B: The models ibm-granite/granite-3.0-8b-instruct and ibm-granite/granite-3.0-2b-instruct are accessed via Hugging Face's checkpoints.
- Granite-3.1-Instruct 2B, 8B: The models ibm-granite/granite-3.1-8b-instruct and ibm-granite/granite-3.1-2b-instruct are accessed via Hugging Face's checkpoints.
-
Grok: Accessed via xAI's API using the model
grok-betaand thechat/completionsendpoint.
- OLMo-2 7B, 13B: The models allenai/OLMo-2-1124-7B-Instruct and allenai/OLMo-2-1124-13B-Instruct are accessed via Hugging Face's checkpoints.
-
Qu. Why are you are using a model to evaluate a model?
-
Answer There are several reasons we chose to do this over a human evaluation. While we could have crowdsourced a large human scale evaluation, that's a one time thing, it does not scale in a way that allows us to constantly update the leaderboard as new APIs come online or models get updated. We work in a fast moving field so any such process would be out of data as soon as it published. Secondly, we wanted a repeatable process that we can share with others so they can use it themselves as one of many LLM quality scores they use when evaluating their own models. This would not be possible with a human annotation process, where the only things that could be shared are the process and the human labels. It's also worth pointing out that building a model for detecting hallucinations is much easier than building a generative model that never produces hallucinations. So long as the hallucination evaluation model is highly correlated with human raters' judgements, it can stand in as a good proxy for human judges. As we are specifically targetting summarization and not general 'closed book' question answering, the LLM we trained does not need to have memorized a large proportion of human knowledge, it just needs to have a solid grasp and understanding of the languages it support (currently just english, but we plan to expand language coverage over time).
-
Qu. What if the LLM refuses to summarize the document or provides a one or two word answer?
-
Answer We explicitly filter these out. See our blog post for more information. You can see the 'Answer Rate' column on the leaderboard that indicates the percentage of documents summarized, and the 'Average Summary Length' column detailing the summary lengths, showing we didn't get very short answers for most documents.
-
Qu. What version of model XYZ did you use?
-
Answer Please see the API details section for specifics about the model versions used and how they were called, as well as the date the leaderboard was last updated. Please contact us (create an issue in the repo) if you need more clarity.
-
Qu. Can't a model just score a 100% by providing either no answers or very short answers?
-
Answer We explicitly filtered out such responses from every model, doing the final evaluation only on documents that all models provided a summary for. You can find out more technical details in our blog post on the topic. See also the 'Answer Rate' and 'Average Summary Length' columns in the table above.
-
Qu. Wouldn't an extractive summarizer model that just copies and pastes from the original summary score 100% (0 hallucination) on this task?
-
Answer Absolutely as by definition such a model would have no hallucinations and provide a faithful summary. We do not claim to be evaluating summarization quality, that is a separate and orthogonal task, and should be evaluated independently. We are not evaluating the quality of the summaries, only the factual consistency of them, as we point out in the blog post.
-
Qu. This seems a very hackable metric, as you could just copy the original text as the summary
-
Answer. That's true but we are not evaluating arbitrary models on this approach, e.g. like in a Kaggle competition. Any model that does so would perform poorly at any other task you care about. So I would consider this as quality metric that you'd run alongside whatever other evaluations you have for your model, such as summarization quality, question answering accuracy, etc. But we do not recommend using this as a standalone metric. None of the models chosen were trained on our model's output. That may happen in future but as we plan to update the model and also the source documents so this is a living leaderboard, that will be an unlikely occurrence. That is however also an issue with any LLM benchmark. We should also point out this builds on a large body of work on factual consistency where many other academics invented and refined this protocol. See our references to the SummaC and True papers in this blog post, as well as this excellent compilation of resources - https://github.com/EdinburghNLP/awesome-hallucination-detection to read more.
-
Qu. This does not definitively measure all the ways a model can hallucinate
-
Answer. Agreed. We do not claim to have solved the problem of hallucination detection, and plan to expand and enhance this process further. But we do believe it is a move in the right direction, and provides a much needed starting point that everyone can build on top of.
-
Qu. Some models could hallucinate only while summarizing. Couldn't you just provide it a list of well known facts and check how well it can recall them?
-
Answer. That would be a poor test in my opinion. For one thing, unless you trained the model you don't know the data it was trained on, so you can't be sure the model is grounding its response in real data it has seen on or whether it is guessing. Additionally, there is no clear definition of 'well known', and these types of data are typically easy for most models to accurately recall. Most hallucinations, in my admittedly subjective experience, come from the model fetching information that is very rarely known or discussed, or facts for which the model has seen conflicting information. Without knowing the source data the model was trained on, again it's impossible to validate these sort of hallucinations as you won't know which data fits this criterion. I also think its unlikely the model would only hallucinate while summarizing. We are asking the model to take information and transform it in a way that is still faithful to the source. This is analogous to a lot of generative tasks aside from summarization (e.g. write an email covering these points...), and if the model deviates from the prompt then that is a failure to follow instructions, indicating the model would struggle on other instruction following tasks also.
-
Qu. This is a good start but far from definitive
-
Answer. I totally agree. There's a lot more that needs to be done, and the problem is far from solved. But a 'good start' means that hopefully progress will start to be made in this area, and by open sourcing the model, we hope to involve the community into taking this to the next level.
- We will also be adding a leaderboard on citation accuracy. As a builder of RAG systems, we have noticed that LLMs tend to mis-attribute sources sometimes when answering a question based on supplied search results. We'd like to be able to measure this so we can help mitigate it within our platform.
- We will also look to expand the benchmark to cover other RAG tasks, such as multi-document summarization.
- We also plan to cover more languages than just english. Our current platform covers over 100 languages, and we want to develop hallucination detectors with comparable multi-lingual coverage.

For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for hallucination-leaderboard
Similar Open Source Tools
hallucination-leaderboard
This leaderboard evaluates the hallucination rate of various Large Language Models (LLMs) when summarizing documents. It uses a model trained by Vectara to detect hallucinations in LLM outputs. The leaderboard includes models from OpenAI, Anthropic, Google, Microsoft, Amazon, and others. The evaluation is based on 831 documents that were summarized by all the models. The leaderboard shows the hallucination rate, factual consistency rate, answer rate, and average summary length for each model.
APOLLO
APOLLO is a memory-efficient optimizer designed for large language model (LLM) pre-training and full-parameter fine-tuning. It offers SGD-like memory cost with AdamW-level performance. The optimizer integrates low-rank approximation and optimizer state redundancy reduction to achieve significant memory savings while maintaining or surpassing the performance of Adam(W). Key contributions include structured learning rate updates for LLM training, approximated channel-wise gradient scaling in a low-rank auxiliary space, and minimal-rank tensor-wise gradient scaling. APOLLO aims to optimize memory efficiency during training large language models.

CogVideo
CogVideo is an open-source repository that provides pretrained text-to-video models for generating videos based on input text. It includes models like CogVideoX-2B and CogVideo, offering powerful video generation capabilities. The repository offers tools for inference, fine-tuning, and model conversion, along with demos showcasing the model's capabilities through CLI, web UI, and online experiences. CogVideo aims to facilitate the creation of high-quality videos from textual descriptions, catering to a wide range of applications.
AI-Blueprints
This repository hosts a collection of AI blueprint projects for HP AI Studio, providing end-to-end solutions across key AI domains like data science, machine learning, deep learning, and generative AI. The projects are designed to be plug-and-play, utilizing open-source and hosted models to offer ready-to-use solutions. The repository structure includes projects related to classical machine learning, deep learning applications, generative AI, NGC integration, and troubleshooting guidelines for common issues. Each project is accompanied by detailed descriptions and use cases, showcasing the versatility and applicability of AI technologies in various domains.

siiRL
siiRL is a novel, fully distributed reinforcement learning (RL) framework designed to break the scaling barriers in Large Language Models (LLMs) post-training. Developed by researchers from Shanghai Innovation Institute, siiRL delivers near-linear scalability, dramatic throughput gains, and unprecedented flexibility for RL-based LLM development. It eliminates the centralized controller common in other frameworks, enabling scalability to thousands of GPUs, achieving state-of-the-art throughput, and supporting cross-hardware compatibility. siiRL is extensively benchmarked and excels in data-intensive workloads such as long-context and multi-modal training.
Mooncake
Mooncake is a serving platform for Kimi, a leading LLM service provided by Moonshot AI. It features a KVCache-centric disaggregated architecture that separates prefill and decoding clusters, leveraging underutilized CPU, DRAM, and SSD resources of the GPU cluster. Mooncake's scheduler balances throughput and latency-related SLOs, with a prediction-based early rejection policy for highly overloaded scenarios. It excels in long-context scenarios, achieving up to a 525% increase in throughput while handling 75% more requests under real workloads.
echosharp
EchoSharp is an open-source library designed for near-real-time audio processing, orchestrating different AI models seamlessly for various audio analysis scopes. It focuses on flexibility and performance, allowing near-real-time Transcription and Translation by integrating components for Speech-to-Text and Voice Activity Detection. With interchangeable components, easy orchestration, and first-party components like Whisper.net, SileroVad, OpenAI Whisper, AzureAI SpeechServices, WebRtcVadSharp, Onnx.Whisper, and Onnx.Sherpa, EchoSharp provides efficient audio analysis solutions for developers.

MathCoder
MathCoder is a repository focused on enhancing mathematical reasoning by fine-tuning open-source language models to use code for modeling and deriving math equations. It introduces MathCodeInstruct dataset with solutions interleaving natural language, code, and execution results. The repository provides MathCoder models capable of generating code-based solutions for challenging math problems, achieving state-of-the-art scores on MATH and GSM8K datasets. It offers tools for model deployment, inference, and evaluation, along with a citation for referencing the work.
dapr-agents
Dapr Agents is a developer framework for building production-grade resilient AI agent systems that operate at scale. It enables software developers to create AI agents that reason, act, and collaborate using Large Language Models (LLMs), while providing built-in observability and stateful workflow execution to ensure agentic workflows complete successfully. The framework is scalable, efficient, Kubernetes-native, data-driven, secure, observable, vendor-neutral, and open source. It offers features like scalable workflows, cost-effective AI adoption, data-centric AI agents, accelerated development, integrated security and reliability, built-in messaging and state infrastructure, and vendor-neutral and open source support. Dapr Agents is designed to simplify the development of AI applications and workflows by providing a comprehensive API surface and seamless integration with various data sources and services.

eole
EOLE is an open language modeling toolkit based on PyTorch. It aims to provide a research-friendly approach with a comprehensive yet compact and modular codebase for experimenting with various types of language models. The toolkit includes features such as versatile training and inference, dynamic data transforms, comprehensive large language model support, advanced quantization, efficient finetuning, flexible inference, and tensor parallelism. EOLE is a work in progress with ongoing enhancements in configuration management, command line entry points, reproducible recipes, core API simplification, and plans for further simplification, refactoring, inference server development, additional recipes, documentation enhancement, test coverage improvement, logging enhancements, and broader model support.

MME-RealWorld
MME-RealWorld is a benchmark designed to address real-world applications with practical relevance, featuring 13,366 high-resolution images and 29,429 annotations across 43 tasks. It aims to provide substantial recognition challenges and overcome common barriers in existing Multimodal Large Language Model benchmarks, such as small data scale, restricted data quality, and insufficient task difficulty. The dataset offers advantages in data scale, data quality, task difficulty, and real-world utility compared to existing benchmarks. It also includes a Chinese version with additional images and QA pairs focused on Chinese scenarios.
AI2BMD
AI2BMD is a program for efficiently simulating protein molecular dynamics with ab initio accuracy. The repository contains datasets, simulation programs, and public materials related to AI2BMD. It provides a Docker image for easy deployment and a standalone launcher program. Users can run simulations by downloading the launcher script and specifying simulation parameters. The repository also includes ready-to-use protein structures for testing. AI2BMD is designed for x86-64 GNU/Linux systems with recommended hardware specifications. The related research includes model architectures like ViSNet, Geoformer, and fine-grained force metrics for MLFF. Citation information and contact details for the AI2BMD Team are provided.
TurtleBenchmark
Turtle Benchmark is a novel and cheat-proof benchmark test used to evaluate large language models (LLMs). It is based on the Turtle Soup game, focusing on logical reasoning and context understanding abilities. The benchmark does not require background knowledge or model memory, providing all necessary information for judgment from stories under 200 words. The results are objective and unbiased, quantifiable as correct/incorrect/unknown, and impossible to cheat due to using real user-generated questions and dynamic data generation during online gameplay.

postgresml
PostgresML is a powerful Postgres extension that seamlessly combines data storage and machine learning inference within your database. It enables running machine learning and AI operations directly within PostgreSQL, leveraging GPU acceleration for faster computations, integrating state-of-the-art large language models, providing built-in functions for text processing, enabling efficient similarity search, offering diverse ML algorithms, ensuring high performance, scalability, and security, supporting a wide range of NLP tasks, and seamlessly integrating with existing PostgreSQL tools and client libraries.
Awesome-European-Tech
Awesome European Tech is an up-to-date list of recommended European projects and companies curated by the community to support and strengthen the European tech ecosystem. It focuses on privacy and sustainability, showcasing companies that adhere to GDPR compliance and sustainability standards. The project aims to highlight and support European startups and projects excelling in privacy, sustainability, and innovation to contribute to a more diverse, resilient, and interconnected global tech landscape.

AutoPatent
AutoPatent is a multi-agent framework designed for automatic patent generation. It challenges large language models to generate full-length patents based on initial drafts. The framework leverages planner, writer, and examiner agents along with PGTree and RRAG to craft lengthy, intricate, and high-quality patent documents. It introduces a new metric, IRR (Inverse Repetition Rate), to measure sentence repetition within patents. The tool aims to streamline the patent generation process by automating the creation of detailed and specialized patent documents.
For similar tasks
hallucination-leaderboard
This leaderboard evaluates the hallucination rate of various Large Language Models (LLMs) when summarizing documents. It uses a model trained by Vectara to detect hallucinations in LLM outputs. The leaderboard includes models from OpenAI, Anthropic, Google, Microsoft, Amazon, and others. The evaluation is based on 831 documents that were summarized by all the models. The leaderboard shows the hallucination rate, factual consistency rate, answer rate, and average summary length for each model.

hallucination-index
LLM Hallucination Index - RAG Special is a comprehensive evaluation of large language models (LLMs) focusing on context length and open vs. closed-source attributes. The index explores the impact of context length on model performance and tests the assumption that closed-source LLMs outperform open-source ones. It also investigates the effectiveness of prompting techniques like Chain-of-Note across different context lengths. The evaluation includes 22 models from various brands, analyzing major trends and declaring overall winners based on short, medium, and long context insights. Methodologies involve rigorous testing with different context lengths and prompting techniques to assess models' abilities in handling extensive texts and detecting hallucinations.

llama3_interpretability_sae
This project focuses on implementing Sparse Autoencoders (SAEs) for mechanistic interpretability in Large Language Models (LLMs) like Llama 3.2-3B. The SAEs aim to untangle superimposed representations in LLMs into separate, interpretable features for each neuron activation. The project provides an end-to-end pipeline for capturing training data, training the SAEs, analyzing learned features, and verifying results experimentally. It includes comprehensive logging, visualization, and checkpointing of SAE training, interpretability analysis tools, and a pure PyTorch implementation of Llama 3.1/3.2 chat and text completion. The project is designed for scalability, efficiency, and maintainability.
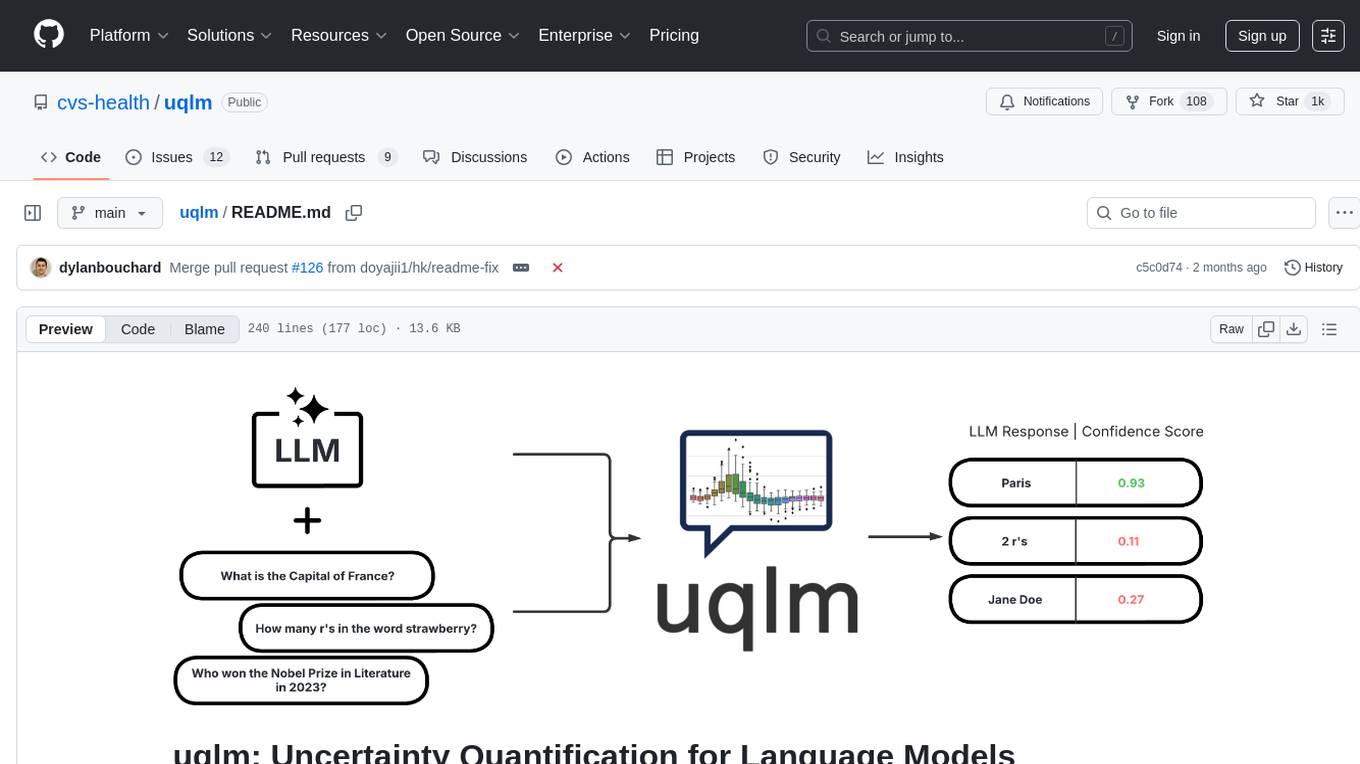
uqlm
UQLM is a Python library for Large Language Model (LLM) hallucination detection using state-of-the-art uncertainty quantification techniques. It provides response-level scorers for quantifying uncertainty of LLM outputs, categorized into four main types: Black-Box Scorers, White-Box Scorers, LLM-as-a-Judge Scorers, and Ensemble Scorers. Users can leverage different scorers to assess uncertainty in generated responses, with options for off-the-shelf usage or customization. The library offers illustrative code snippets and detailed information on available scorers for each type, along with example usage for conducting hallucination detection. Additionally, UQLM includes documentation, example notebooks, and associated research for further exploration and understanding.

h2o-llmstudio
H2O LLM Studio is a framework and no-code GUI designed for fine-tuning state-of-the-art large language models (LLMs). With H2O LLM Studio, you can easily and effectively fine-tune LLMs without the need for any coding experience. The GUI is specially designed for large language models, and you can finetune any LLM using a large variety of hyperparameters. You can also use recent finetuning techniques such as Low-Rank Adaptation (LoRA) and 8-bit model training with a low memory footprint. Additionally, you can use Reinforcement Learning (RL) to finetune your model (experimental), use advanced evaluation metrics to judge generated answers by the model, track and compare your model performance visually, and easily export your model to the Hugging Face Hub and share it with the community.

llm-jp-eval
LLM-jp-eval is a tool designed to automatically evaluate Japanese large language models across multiple datasets. It provides functionalities such as converting existing Japanese evaluation data to text generation task evaluation datasets, executing evaluations of large language models across multiple datasets, and generating instruction data (jaster) in the format of evaluation data prompts. Users can manage the evaluation settings through a config file and use Hydra to load them. The tool supports saving evaluation results and logs using wandb. Users can add new evaluation datasets by following specific steps and guidelines provided in the tool's documentation. It is important to note that using jaster for instruction tuning can lead to artificially high evaluation scores, so caution is advised when interpreting the results.

Awesome-LLM
Awesome-LLM is a curated list of resources related to large language models, focusing on papers, projects, frameworks, tools, tutorials, courses, opinions, and other useful resources in the field. It covers trending LLM projects, milestone papers, other papers, open LLM projects, LLM training frameworks, LLM evaluation frameworks, tools for deploying LLM, prompting libraries & tools, tutorials, courses, books, and opinions. The repository provides a comprehensive overview of the latest advancements and resources in the field of large language models.

bocoel
BoCoEL is a tool that leverages Bayesian Optimization to efficiently evaluate large language models by selecting a subset of the corpus for evaluation. It encodes individual entries into embeddings, uses Bayesian optimization to select queries, retrieves from the corpus, and provides easily managed evaluations. The tool aims to reduce computation costs during evaluation with a dynamic budget, supporting models like GPT2, Pythia, and LLAMA through integration with Hugging Face transformers and datasets. BoCoEL offers a modular design and efficient representation of the corpus to enhance evaluation quality.
For similar jobs

ChatFAQ
ChatFAQ is an open-source comprehensive platform for creating a wide variety of chatbots: generic ones, business-trained, or even capable of redirecting requests to human operators. It includes a specialized NLP/NLG engine based on a RAG architecture and customized chat widgets, ensuring a tailored experience for users and avoiding vendor lock-in.

anything-llm
AnythingLLM is a full-stack application that enables you to turn any document, resource, or piece of content into context that any LLM can use as references during chatting. This application allows you to pick and choose which LLM or Vector Database you want to use as well as supporting multi-user management and permissions.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

mikupad
mikupad is a lightweight and efficient language model front-end powered by ReactJS, all packed into a single HTML file. Inspired by the likes of NovelAI, it provides a simple yet powerful interface for generating text with the help of various backends.

glide
Glide is a cloud-native LLM gateway that provides a unified REST API for accessing various large language models (LLMs) from different providers. It handles LLMOps tasks such as model failover, caching, key management, and more, making it easy to integrate LLMs into applications. Glide supports popular LLM providers like OpenAI, Anthropic, Azure OpenAI, AWS Bedrock (Titan), Cohere, Google Gemini, OctoML, and Ollama. It offers high availability, performance, and observability, and provides SDKs for Python and NodeJS to simplify integration.

onnxruntime-genai
ONNX Runtime Generative AI is a library that provides the generative AI loop for ONNX models, including inference with ONNX Runtime, logits processing, search and sampling, and KV cache management. Users can call a high level `generate()` method, or run each iteration of the model in a loop. It supports greedy/beam search and TopP, TopK sampling to generate token sequences, has built in logits processing like repetition penalties, and allows for easy custom scoring.

firecrawl
Firecrawl is an API service that takes a URL, crawls it, and converts it into clean markdown. It crawls all accessible subpages and provides clean markdown for each, without requiring a sitemap. The API is easy to use and can be self-hosted. It also integrates with Langchain and Llama Index. The Python SDK makes it easy to crawl and scrape websites in Python code.