
firecrawl
🔥 Turn entire websites into LLM-ready markdown or structured data. Scrape, crawl and extract with a single API.
Stars: 34132

Firecrawl is an API service that takes a URL, crawls it, and converts it into clean markdown. It crawls all accessible subpages and provides clean markdown for each, without requiring a sitemap. The API is easy to use and can be self-hosted. It also integrates with Langchain and Llama Index. The Python SDK makes it easy to crawl and scrape websites in Python code.
README:


Empower your AI apps with clean data from any website. Featuring advanced scraping, crawling, and data extraction capabilities.
This repository is in development, and we’re still integrating custom modules into the mono repo. It's not fully ready for self-hosted deployment yet, but you can run it locally.
Firecrawl is an API service that takes a URL, crawls it, and converts it into clean markdown or structured data. We crawl all accessible subpages and give you clean data for each. No sitemap required. Check out our documentation.
Pst. hey, you, join our stargazers :)

We provide an easy to use API with our hosted version. You can find the playground and documentation here. You can also self host the backend if you'd like.
Check out the following resources to get started:
- [x] API: Documentation
- [x] SDKs: Python, Node, Go, Rust
- [x] LLM Frameworks: Langchain (python), Langchain (js), Llama Index, Crew.ai, Composio, PraisonAI, Superinterface, Vectorize
- [x] Low-code Frameworks: Dify, Langflow, Flowise AI, Cargo, Pipedream
- [x] Others: Zapier, Pabbly Connect
- [ ] Want an SDK or Integration? Let us know by opening an issue.
To run locally, refer to guide here.
To use the API, you need to sign up on Firecrawl and get an API key.
- Scrape: scrapes a URL and get its content in LLM-ready format (markdown, structured data via LLM Extract, screenshot, html)
- Crawl: scrapes all the URLs of a web page and return content in LLM-ready format
- Map: input a website and get all the website urls - extremely fast
- Extract: get structured data from single page, multiple pages or entire websites with AI.
- LLM-ready formats: markdown, structured data, screenshot, HTML, links, metadata
- The hard stuff: proxies, anti-bot mechanisms, dynamic content (js-rendered), output parsing, orchestration
- Customizability: exclude tags, crawl behind auth walls with custom headers, max crawl depth, etc...
- Media parsing: pdfs, docx, images
- Reliability first: designed to get the data you need - no matter how hard it is
- Actions: click, scroll, input, wait and more before extracting data
- Batching (New): scrape thousands of URLs at the same time with a new async endpoint.
You can find all of Firecrawl's capabilities and how to use them in our documentation
Used to crawl a URL and all accessible subpages. This submits a crawl job and returns a job ID to check the status of the crawl.
curl -X POST https://api.firecrawl.dev/v1/crawl \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer fc-YOUR_API_KEY' \
-d '{
"url": "https://docs.firecrawl.dev",
"limit": 10,
"scrapeOptions": {
"formats": ["markdown", "html"]
}
}'Returns a crawl job id and the url to check the status of the crawl.
{
"success": true,
"id": "123-456-789",
"url": "https://api.firecrawl.dev/v1/crawl/123-456-789"
}Used to check the status of a crawl job and get its result.
curl -X GET https://api.firecrawl.dev/v1/crawl/123-456-789 \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer YOUR_API_KEY'{
"status": "completed",
"total": 36,
"creditsUsed": 36,
"expiresAt": "2024-00-00T00:00:00.000Z",
"data": [
{
"markdown": "[Firecrawl Docs home page!...",
"html": "<!DOCTYPE html><html lang=\"en\" class=\"js-focus-visible lg:[--scroll-mt:9.5rem]\" data-js-focus-visible=\"\">...",
"metadata": {
"title": "Build a 'Chat with website' using Groq Llama 3 | Firecrawl",
"language": "en",
"sourceURL": "https://docs.firecrawl.dev/learn/rag-llama3",
"description": "Learn how to use Firecrawl, Groq Llama 3, and Langchain to build a 'Chat with your website' bot.",
"ogLocaleAlternate": [],
"statusCode": 200
}
}
]
}Used to scrape a URL and get its content in the specified formats.
curl -X POST https://api.firecrawl.dev/v1/scrape \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer YOUR_API_KEY' \
-d '{
"url": "https://docs.firecrawl.dev",
"formats" : ["markdown", "html"]
}'Response:
{
"success": true,
"data": {
"markdown": "Launch Week I is here! [See our Day 2 Release 🚀](https://www.firecrawl.dev/blog/launch-week-i-day-2-doubled-rate-limits)[💥 Get 2 months free...",
"html": "<!DOCTYPE html><html lang=\"en\" class=\"light\" style=\"color-scheme: light;\"><body class=\"__variable_36bd41 __variable_d7dc5d font-inter ...",
"metadata": {
"title": "Home - Firecrawl",
"description": "Firecrawl crawls and converts any website into clean markdown.",
"language": "en",
"keywords": "Firecrawl,Markdown,Data,Mendable,Langchain",
"robots": "follow, index",
"ogTitle": "Firecrawl",
"ogDescription": "Turn any website into LLM-ready data.",
"ogUrl": "https://www.firecrawl.dev/",
"ogImage": "https://www.firecrawl.dev/og.png?123",
"ogLocaleAlternate": [],
"ogSiteName": "Firecrawl",
"sourceURL": "https://firecrawl.dev",
"statusCode": 200
}
}
}Used to map a URL and get urls of the website. This returns most links present on the website.
curl -X POST https://api.firecrawl.dev/v1/map \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer YOUR_API_KEY' \
-d '{
"url": "https://firecrawl.dev"
}'Response:
{
"status": "success",
"links": [
"https://firecrawl.dev",
"https://www.firecrawl.dev/pricing",
"https://www.firecrawl.dev/blog",
"https://www.firecrawl.dev/playground",
"https://www.firecrawl.dev/smart-crawl",
]
}Map with search param allows you to search for specific urls inside a website.
curl -X POST https://api.firecrawl.dev/v1/map \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer YOUR_API_KEY' \
-d '{
"url": "https://firecrawl.dev",
"search": "docs"
}'Response will be an ordered list from the most relevant to the least relevant.
{
"status": "success",
"links": [
"https://docs.firecrawl.dev",
"https://docs.firecrawl.dev/sdks/python",
"https://docs.firecrawl.dev/learn/rag-llama3",
]
}Get structured data from entire websites with a prompt and/or a schema.
You can extract structured data from one or multiple URLs, including wildcards:
Single Page: Example: https://firecrawl.dev/some-page
Multiple Pages / Full Domain Example: https://firecrawl.dev/*
When you use /*, Firecrawl will automatically crawl and parse all URLs it can discover in that domain, then extract the requested data.
curl -X POST https://api.firecrawl.dev/v1/extract \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer YOUR_API_KEY' \
-d '{
"urls": [
"https://firecrawl.dev/*",
"https://docs.firecrawl.dev/",
"https://www.ycombinator.com/companies"
],
"prompt": "Extract the company mission, whether it is open source, and whether it is in Y Combinator from the page.",
"schema": {
"type": "object",
"properties": {
"company_mission": {
"type": "string"
},
"is_open_source": {
"type": "boolean"
},
"is_in_yc": {
"type": "boolean"
}
},
"required": [
"company_mission",
"is_open_source",
"is_in_yc"
]
}
}'{
"success": true,
"id": "44aa536d-f1cb-4706-ab87-ed0386685740",
"urlTrace": []
}If you are using the sdks, it will auto pull the response for you:
{
"success": true,
"data": {
"company_mission": "Firecrawl is the easiest way to extract data from the web. Developers use us to reliably convert URLs into LLM-ready markdown or structured data with a single API call.",
"supports_sso": false,
"is_open_source": true,
"is_in_yc": true
}
}Used to extract structured data from scraped pages.
curl -X POST https://api.firecrawl.dev/v1/scrape \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer YOUR_API_KEY' \
-d '{
"url": "https://www.mendable.ai/",
"formats": ["json"],
"jsonOptions": {
"schema": {
"type": "object",
"properties": {
"company_mission": {
"type": "string"
},
"supports_sso": {
"type": "boolean"
},
"is_open_source": {
"type": "boolean"
},
"is_in_yc": {
"type": "boolean"
}
},
"required": [
"company_mission",
"supports_sso",
"is_open_source",
"is_in_yc"
]
}
}
}'{
"success": true,
"data": {
"content": "Raw Content",
"metadata": {
"title": "Mendable",
"description": "Mendable allows you to easily build AI chat applications. Ingest, customize, then deploy with one line of code anywhere you want. Brought to you by SideGuide",
"robots": "follow, index",
"ogTitle": "Mendable",
"ogDescription": "Mendable allows you to easily build AI chat applications. Ingest, customize, then deploy with one line of code anywhere you want. Brought to you by SideGuide",
"ogUrl": "https://mendable.ai/",
"ogImage": "https://mendable.ai/mendable_new_og1.png",
"ogLocaleAlternate": [],
"ogSiteName": "Mendable",
"sourceURL": "https://mendable.ai/"
},
"json": {
"company_mission": "Train a secure AI on your technical resources that answers customer and employee questions so your team doesn't have to",
"supports_sso": true,
"is_open_source": false,
"is_in_yc": true
}
}
}You can now extract without a schema by just passing a prompt to the endpoint. The llm chooses the structure of the data.
curl -X POST https://api.firecrawl.dev/v1/scrape \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer YOUR_API_KEY' \
-d '{
"url": "https://docs.firecrawl.dev/",
"formats": ["json"],
"jsonOptions": {
"prompt": "Extract the company mission from the page."
}
}'Firecrawl allows you to perform various actions on a web page before scraping its content. This is particularly useful for interacting with dynamic content, navigating through pages, or accessing content that requires user interaction.
Here is an example of how to use actions to navigate to google.com, search for Firecrawl, click on the first result, and take a screenshot.
curl -X POST https://api.firecrawl.dev/v1/scrape \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer YOUR_API_KEY' \
-d '{
"url": "google.com",
"formats": ["markdown"],
"actions": [
{"type": "wait", "milliseconds": 2000},
{"type": "click", "selector": "textarea[title=\"Search\"]"},
{"type": "wait", "milliseconds": 2000},
{"type": "write", "text": "firecrawl"},
{"type": "wait", "milliseconds": 2000},
{"type": "press", "key": "ENTER"},
{"type": "wait", "milliseconds": 3000},
{"type": "click", "selector": "h3"},
{"type": "wait", "milliseconds": 3000},
{"type": "screenshot"}
]
}'You can now batch scrape multiple URLs at the same time. It is very similar to how the /crawl endpoint works. It submits a batch scrape job and returns a job ID to check the status of the batch scrape.
curl -X POST https://api.firecrawl.dev/v1/batch/scrape \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer YOUR_API_KEY' \
-d '{
"urls": ["https://docs.firecrawl.dev", "https://docs.firecrawl.dev/sdks/overview"],
"formats" : ["markdown", "html"]
}'The search endpoint combines web search with Firecrawl’s scraping capabilities to return full page content for any query.
Include scrapeOptions with formats: ["markdown"] to get complete markdown content for each search result otherwise it defaults to getting SERP results (url, title, description).
curl -X POST https://api.firecrawl.dev/v1/search \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer YOUR_API_KEY' \
-d '{
"query": "What is Mendable?"
}'{
"success": true,
"data": [
{
"url": "https://mendable.ai",
"title": "Mendable | AI for CX and Sales",
"description": "AI for CX and Sales"
}
]
}pip install firecrawl-pyfrom firecrawl.firecrawl import FirecrawlApp
app = FirecrawlApp(api_key="fc-YOUR_API_KEY")
# Scrape a website:
scrape_status = app.scrape_url(
'https://firecrawl.dev',
params={'formats': ['markdown', 'html']}
)
print(scrape_status)
# Crawl a website:
crawl_status = app.crawl_url(
'https://firecrawl.dev',
params={
'limit': 100,
'scrapeOptions': {'formats': ['markdown', 'html']}
},
poll_interval=30
)
print(crawl_status)With LLM extraction, you can easily extract structured data from any URL. We support pydantic schemas to make it easier for you too. Here is how you to use it:
from firecrawl.firecrawl import FirecrawlApp
app = FirecrawlApp(api_key="fc-YOUR_API_KEY")
class ArticleSchema(BaseModel):
title: str
points: int
by: str
commentsURL: str
class TopArticlesSchema(BaseModel):
top: List[ArticleSchema] = Field(..., max_items=5, description="Top 5 stories")
data = app.scrape_url('https://news.ycombinator.com', {
'formats': ['json'],
'jsonOptions': {
'schema': TopArticlesSchema.model_json_schema()
}
})
print(data["json"])To install the Firecrawl Node SDK, you can use npm:
npm install @mendable/firecrawl-js- Get an API key from firecrawl.dev
- Set the API key as an environment variable named
FIRECRAWL_API_KEYor pass it as a parameter to theFirecrawlAppclass.
import FirecrawlApp, { CrawlParams, CrawlStatusResponse } from '@mendable/firecrawl-js';
const app = new FirecrawlApp({apiKey: "fc-YOUR_API_KEY"});
// Scrape a website
const scrapeResponse = await app.scrapeUrl('https://firecrawl.dev', {
formats: ['markdown', 'html'],
});
if (scrapeResponse) {
console.log(scrapeResponse)
}
// Crawl a website
const crawlResponse = await app.crawlUrl('https://firecrawl.dev', {
limit: 100,
scrapeOptions: {
formats: ['markdown', 'html'],
}
} satisfies CrawlParams, true, 30) satisfies CrawlStatusResponse;
if (crawlResponse) {
console.log(crawlResponse)
}With LLM extraction, you can easily extract structured data from any URL. We support zod schema to make it easier for you too. Here is how to use it:
import FirecrawlApp from "@mendable/firecrawl-js";
import { z } from "zod";
const app = new FirecrawlApp({
apiKey: "fc-YOUR_API_KEY"
});
// Define schema to extract contents into
const schema = z.object({
top: z
.array(
z.object({
title: z.string(),
points: z.number(),
by: z.string(),
commentsURL: z.string(),
})
)
.length(5)
.describe("Top 5 stories on Hacker News"),
});
const scrapeResult = await app.scrapeUrl("https://news.ycombinator.com", {
jsonOptions: { extractionSchema: schema },
});
console.log(scrapeResult.data["json"]);Firecrawl is open source available under the AGPL-3.0 license.
To deliver the best possible product, we offer a hosted version of Firecrawl alongside our open-source offering. The cloud solution allows us to continuously innovate and maintain a high-quality, sustainable service for all users.
Firecrawl Cloud is available at firecrawl.dev and offers a range of features that are not available in the open source version:
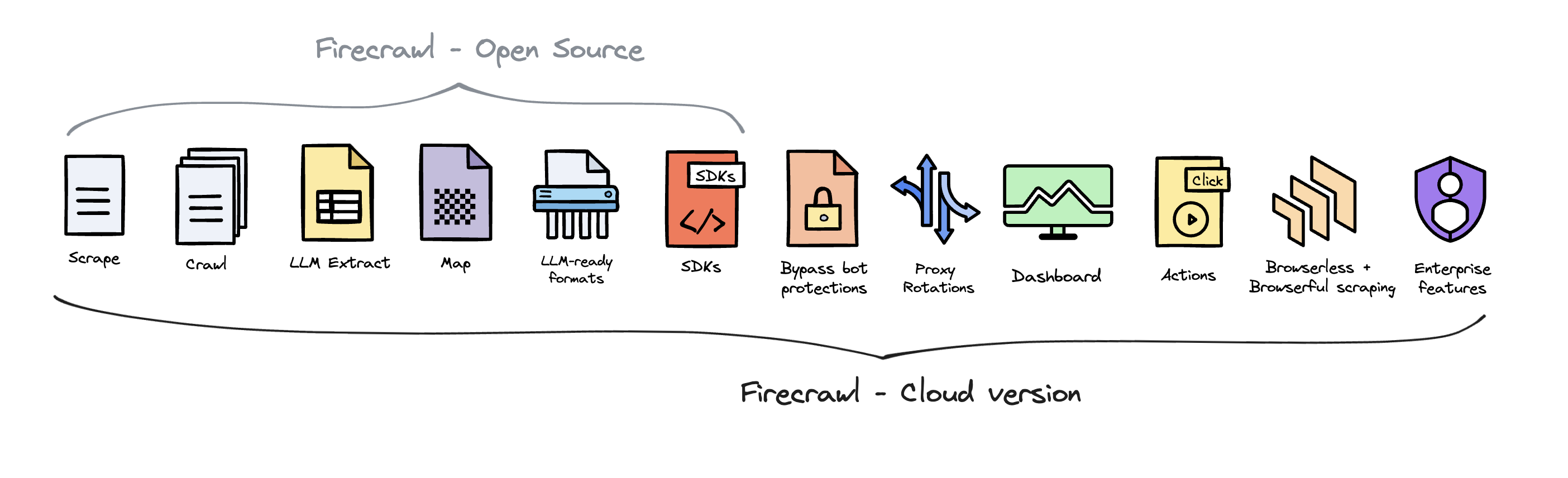
We love contributions! Please read our contributing guide before submitting a pull request. If you'd like to self-host, refer to the self-hosting guide.
It is the sole responsibility of the end users to respect websites' policies when scraping, searching and crawling with Firecrawl. Users are advised to adhere to the applicable privacy policies and terms of use of the websites prior to initiating any scraping activities. By default, Firecrawl respects the directives specified in the websites' robots.txt files when crawling. By utilizing Firecrawl, you expressly agree to comply with these conditions.
This project is primarily licensed under the GNU Affero General Public License v3.0 (AGPL-3.0), as specified in the LICENSE file in the root directory of this repository. However, certain components of this project are licensed under the MIT License. Refer to the LICENSE files in these specific directories for details.
Please note:
- The AGPL-3.0 license applies to all parts of the project unless otherwise specified.
- The SDKs and some UI components are licensed under the MIT License. Refer to the LICENSE files in these specific directories for details.
- When using or contributing to this project, ensure you comply with the appropriate license terms for the specific component you are working with.
For more details on the licensing of specific components, please refer to the LICENSE files in the respective directories or contact the project maintainers.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for firecrawl
Similar Open Source Tools
firecrawl
Firecrawl is an API service that takes a URL, crawls it, and converts it into clean markdown. It crawls all accessible subpages and provides clean markdown for each, without requiring a sitemap. The API is easy to use and can be self-hosted. It also integrates with Langchain and Llama Index. The Python SDK makes it easy to crawl and scrape websites in Python code.

firecrawl
Firecrawl is an API service that empowers AI applications with clean data from any website. It features advanced scraping, crawling, and data extraction capabilities. The repository is still in development, integrating custom modules into the mono repo. Users can run it locally but it's not fully ready for self-hosted deployment yet. Firecrawl offers powerful capabilities like scraping, crawling, mapping, searching, and extracting structured data from single pages, multiple pages, or entire websites with AI. It supports various formats, actions, and batch scraping. The tool is designed to handle proxies, anti-bot mechanisms, dynamic content, media parsing, change tracking, and more. Firecrawl is available as an open-source project under the AGPL-3.0 license, with additional features offered in the cloud version.
AICentral
AI Central is a powerful tool designed to take control of your AI services with minimal overhead. It is built on Asp.Net Core and dotnet 8, offering fast web-server performance. The tool enables advanced Azure APIm scenarios, PII stripping logging to Cosmos DB, token metrics through Open Telemetry, and intelligent routing features. AI Central supports various endpoint selection strategies, proxying asynchronous requests, custom OAuth2 authorization, circuit breakers, rate limiting, and extensibility through plugins. It provides an extensibility model for easy plugin development and offers enriched telemetry and logging capabilities for monitoring and insights.

ruby-openai
Use the OpenAI API with Ruby! 🤖🩵 Stream text with GPT-4, transcribe and translate audio with Whisper, or create images with DALL·E... Hire me | 🎮 Ruby AI Builders Discord | 🐦 Twitter | 🧠 Anthropic Gem | 🚂 Midjourney Gem ## Table of Contents * Ruby OpenAI * Table of Contents * Installation * Bundler * Gem install * Usage * Quickstart * With Config * Custom timeout or base URI * Extra Headers per Client * Logging * Errors * Faraday middleware * Azure * Ollama * Counting Tokens * Models * Examples * Chat * Streaming Chat * Vision * JSON Mode * Functions * Edits * Embeddings * Batches * Files * Finetunes * Assistants * Threads and Messages * Runs * Runs involving function tools * Image Generation * DALL·E 2 * DALL·E 3 * Image Edit * Image Variations * Moderations * Whisper * Translate * Transcribe * Speech * Errors * Development * Release * Contributing * License * Code of Conduct

openmacro
Openmacro is a multimodal personal agent that allows users to run code locally. It acts as a personal agent capable of completing and automating tasks autonomously via self-prompting. The tool provides a CLI natural-language interface for completing and automating tasks, analyzing and plotting data, browsing the web, and manipulating files. Currently, it supports API keys for models powered by SambaNova, with plans to add support for other hosts like OpenAI and Anthropic in future versions.
typst-mcp
Typst MCP Server is an implementation of the Model Context Protocol (MCP) that facilitates interaction between AI models and Typst, a markup-based typesetting system. The server offers tools for converting between LaTeX and Typst, validating Typst syntax, and generating images from Typst code. It provides functions such as listing documentation chapters, retrieving specific chapters, converting LaTeX snippets to Typst, validating Typst syntax, and rendering Typst code to images. The server is designed to assist Language Model Managers (LLMs) in handling Typst-related tasks efficiently and accurately.

crush
Crush is a versatile tool designed to enhance coding workflows in your terminal. It offers support for multiple LLMs, allows for flexible switching between models, and enables session-based work management. Crush is extensible through MCPs and works across various operating systems. It can be installed using package managers like Homebrew and NPM, or downloaded directly. Crush supports various APIs like Anthropic, OpenAI, Groq, and Google Gemini, and allows for customization through environment variables. The tool can be configured locally or globally, and supports LSPs for additional context. Crush also provides options for ignoring files, allowing tools, and configuring local models. It respects `.gitignore` files and offers logging capabilities for troubleshooting and debugging.
firecrawl-mcp-server
Firecrawl MCP Server is a Model Context Protocol (MCP) server implementation that integrates with Firecrawl for web scraping capabilities. It offers features such as web scraping, crawling, and discovery, search and content extraction, deep research and batch scraping, automatic retries and rate limiting, cloud and self-hosted support, and SSE support. The server can be configured to run with various tools like Cursor, Windsurf, SSE Local Mode, Smithery, and VS Code. It supports environment variables for cloud API and optional configurations for retry settings and credit usage monitoring. The server includes tools for scraping, batch scraping, mapping, searching, crawling, and extracting structured data from web pages. It provides detailed logging and error handling functionalities for robust performance.
structured-logprobs
This Python library enhances OpenAI chat completion responses by providing detailed information about token log probabilities. It works with OpenAI Structured Outputs to ensure model-generated responses adhere to a JSON Schema. Developers can analyze and incorporate token-level log probabilities to understand the reliability of structured data extracted from OpenAI models.

ollama-ex
Ollama is a powerful tool for running large language models locally or on your own infrastructure. It provides a full implementation of the Ollama API, support for streaming requests, and tool use capability. Users can interact with Ollama in Elixir to generate completions, chat messages, and perform streaming requests. The tool also supports function calling on compatible models, allowing users to define tools with clear descriptions and arguments. Ollama is designed to facilitate natural language processing tasks and enhance user interactions with language models.

promptic
Promptic is a tool designed for LLM app development, providing a productive and pythonic way to build LLM applications. It leverages LiteLLM, allowing flexibility to switch LLM providers easily. Promptic focuses on building features by providing type-safe structured outputs, easy-to-build agents, streaming support, automatic prompt caching, and built-in conversation memory.

Scrapegraph-ai
ScrapeGraphAI is a Python library that uses Large Language Models (LLMs) and direct graph logic to create web scraping pipelines for websites, documents, and XML files. It allows users to extract specific information from web pages by providing a prompt describing the desired data. ScrapeGraphAI supports various LLMs, including Ollama, OpenAI, Gemini, and Docker, enabling users to choose the most suitable model for their needs. The library provides a user-friendly interface through its `SmartScraper` class, which simplifies the process of building and executing scraping pipelines. ScrapeGraphAI is open-source and available on GitHub, with extensive documentation and examples to guide users. It is particularly useful for researchers and data scientists who need to extract structured data from web pages for analysis and exploration.
lego-ai-parser
Lego AI Parser is an open-source application that uses OpenAI to parse visible text of HTML elements. It is built on top of FastAPI, ready to set up as a server, and make calls from any language. It supports preset parsers for Google Local Results, Amazon Listings, Etsy Listings, Wayfair Listings, BestBuy Listings, Costco Listings, Macy's Listings, and Nordstrom Listings. Users can also design custom parsers by providing prompts, examples, and details about the OpenAI model under the classifier key.

npi
NPi is an open-source platform providing Tool-use APIs to empower AI agents with the ability to take action in the virtual world. It is currently under active development, and the APIs are subject to change in future releases. NPi offers a command line tool for installation and setup, along with a GitHub app for easy access to repositories. The platform also includes a Python SDK and examples like Calendar Negotiator and Twitter Crawler. Join the NPi community on Discord to contribute to the development and explore the roadmap for future enhancements.
ling
Ling is a workflow framework supporting streaming of structured content from large language models. It enables quick responses to content streams, reducing waiting times. Ling parses JSON data streams character by character in real-time, outputting content in jsonuri format. It facilitates immediate front-end processing by converting content during streaming input. The framework supports data stream output via JSONL protocol, correction of token errors in JSON output, complex asynchronous workflows, status messages during streaming output, and Server-Sent Events.
008
008 is an open-source event-driven AI powered WebRTC Softphone compatible with macOS, Windows, and Linux. It is also accessible on the web. The name '008' or 'agent 008' reflects our ambition: beyond crafting the premier Open Source Softphone, we aim to introduce a programmable, event-driven AI agent. This agent utilizes embedded artificial intelligence models operating directly on the softphone, ensuring efficiency and reduced operational costs.
For similar tasks
firecrawl
Firecrawl is an API service that takes a URL, crawls it, and converts it into clean markdown. It crawls all accessible subpages and provides clean markdown for each, without requiring a sitemap. The API is easy to use and can be self-hosted. It also integrates with Langchain and Llama Index. The Python SDK makes it easy to crawl and scrape websites in Python code.

pocketgroq
PocketGroq is a tool that provides advanced functionalities for text generation, web scraping, web search, and AI response evaluation. It includes features like an Autonomous Agent for answering questions, web crawling and scraping capabilities, enhanced web search functionality, and flexible integration with Ollama server. Users can customize the agent's behavior, evaluate responses using AI, and utilize various methods for text generation, conversation management, and Chain of Thought reasoning. The tool offers comprehensive methods for different tasks, such as initializing RAG, error handling, and tool management. PocketGroq is designed to enhance development processes and enable the creation of AI-powered applications with ease.
For similar jobs

ChatFAQ
ChatFAQ is an open-source comprehensive platform for creating a wide variety of chatbots: generic ones, business-trained, or even capable of redirecting requests to human operators. It includes a specialized NLP/NLG engine based on a RAG architecture and customized chat widgets, ensuring a tailored experience for users and avoiding vendor lock-in.

anything-llm
AnythingLLM is a full-stack application that enables you to turn any document, resource, or piece of content into context that any LLM can use as references during chatting. This application allows you to pick and choose which LLM or Vector Database you want to use as well as supporting multi-user management and permissions.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

mikupad
mikupad is a lightweight and efficient language model front-end powered by ReactJS, all packed into a single HTML file. Inspired by the likes of NovelAI, it provides a simple yet powerful interface for generating text with the help of various backends.

glide
Glide is a cloud-native LLM gateway that provides a unified REST API for accessing various large language models (LLMs) from different providers. It handles LLMOps tasks such as model failover, caching, key management, and more, making it easy to integrate LLMs into applications. Glide supports popular LLM providers like OpenAI, Anthropic, Azure OpenAI, AWS Bedrock (Titan), Cohere, Google Gemini, OctoML, and Ollama. It offers high availability, performance, and observability, and provides SDKs for Python and NodeJS to simplify integration.

onnxruntime-genai
ONNX Runtime Generative AI is a library that provides the generative AI loop for ONNX models, including inference with ONNX Runtime, logits processing, search and sampling, and KV cache management. Users can call a high level `generate()` method, or run each iteration of the model in a loop. It supports greedy/beam search and TopP, TopK sampling to generate token sequences, has built in logits processing like repetition penalties, and allows for easy custom scoring.
firecrawl
Firecrawl is an API service that takes a URL, crawls it, and converts it into clean markdown. It crawls all accessible subpages and provides clean markdown for each, without requiring a sitemap. The API is easy to use and can be self-hosted. It also integrates with Langchain and Llama Index. The Python SDK makes it easy to crawl and scrape websites in Python code.