
chat-ui
Open source codebase powering the HuggingChat app
Stars: 9174

A chat interface using open source models, eg OpenAssistant or Llama. It is a SvelteKit app and it powers the HuggingChat app on hf.co/chat.
README:

A chat interface for LLMs. It is a SvelteKit app and it powers the HuggingChat app on hf.co/chat.
[!NOTE] Chat UI only supports OpenAI-compatible APIs via
OPENAI_BASE_URLand the/modelsendpoint. Provider-specific integrations (legacyMODELSenv var, GGUF discovery, embeddings, web-search helpers, etc.) are removed, but any service that speaks the OpenAI protocol (llama.cpp server, Ollama, OpenRouter, etc. will work by default).
[!NOTE] The old version is still available on the legacy branch
Chat UI speaks to OpenAI-compatible APIs only. The fastest way to get running is with the Hugging Face Inference Providers router plus your personal Hugging Face access token.
Step 1 – Create .env.local:
OPENAI_BASE_URL=https://router.huggingface.co/v1
OPENAI_API_KEY=hf_************************
# Fill in once you pick a database option below
MONGODB_URL=OPENAI_API_KEY can come from any OpenAI-compatible endpoint you plan to call. Pick the combo that matches your setup and drop the values into .env.local:
| Provider | Example OPENAI_BASE_URL
|
Example key env |
|---|---|---|
| Hugging Face Inference Providers router | https://router.huggingface.co/v1 |
OPENAI_API_KEY=hf_xxx (or HF_TOKEN legacy alias) |
llama.cpp server (llama.cpp --server --api) |
http://127.0.0.1:8080/v1 |
OPENAI_API_KEY=sk-local-demo (any string works; llama.cpp ignores it) |
| Ollama (with OpenAI-compatible bridge) | http://127.0.0.1:11434/v1 |
OPENAI_API_KEY=ollama |
| OpenRouter | https://openrouter.ai/api/v1 |
OPENAI_API_KEY=sk-or-v1-... |
Check the root .env template for the full list of optional variables you can override.
Step 2 – Choose where MongoDB lives: Either provision a managed cluster (for example MongoDB Atlas) or run a local container. Both approaches are described in Database Options. After you have the URI, drop it into MONGODB_URL (and, if desired, set MONGODB_DB_NAME).
Step 3 – Install and launch the dev server:
git clone https://github.com/huggingface/chat-ui
cd chat-ui
npm install
npm run dev -- --openYou now have Chat UI running against the Hugging Face router without needing to host MongoDB yourself.
Chat history, users, settings, files, and stats all live in MongoDB. You can point Chat UI at any MongoDB 6/7 deployment.
- Create a free cluster at mongodb.com.
- Add your IP (or
0.0.0.0/0for development) to the network access list. - Create a database user and copy the connection string.
- Paste that string into
MONGODB_URLin.env.local. Keep the defaultMONGODB_DB_NAME=chat-uior change it per environment.
Atlas keeps MongoDB off your laptop, which is ideal for teams or cloud deployments.
If you prefer to run MongoDB locally:
docker run -d -p 27017:27017 --name mongo-chatui mongo:latestThen set MONGODB_URL=mongodb://localhost:27017 in .env.local. You can also supply MONGO_STORAGE_PATH if you want Chat UI’s fallback in-memory server to persist under a specific folder.
After configuring your environment variables, start Chat UI with:
npm install
npm run devThe dev server listens on http://localhost:5173 by default. Use npm run build / npm run preview for production builds.
Prefer containerized setup? You can run everything in one container as long as you supply a MongoDB URI (local or hosted):
docker run \
-p 3000 \
-e MONGODB_URL=mongodb://host.docker.internal:27017 \
-e OPENAI_BASE_URL=https://router.huggingface.co/v1 \
-e OPENAI_API_KEY=hf_*** \
-v db:/data \
ghcr.io/huggingface/chat-ui-db:latesthost.docker.internal lets the container reach a MongoDB instance on your host machine; swap it for your Atlas URI if you use the hosted option. All environment variables accepted in .env.local can be provided as -e flags.
You can use a few environment variables to customize the look and feel of chat-ui. These are by default:
PUBLIC_APP_NAME=ChatUI
PUBLIC_APP_ASSETS=chatui
PUBLIC_APP_COLOR=blue
PUBLIC_APP_DESCRIPTION="Making the community's best AI chat models available to everyone."
PUBLIC_APP_DATA_SHARING=-
PUBLIC_APP_NAMEThe name used as a title throughout the app. -
PUBLIC_APP_ASSETSIs used to find logos & favicons instatic/$PUBLIC_APP_ASSETS, current options arechatuiandhuggingchat. -
PUBLIC_APP_COLORCan be any of the tailwind colors. -
PUBLIC_APP_DATA_SHARINGCan be set to 1 to add a toggle in the user settings that lets your users opt-in to data sharing with models creator.
This build does not use the MODELS env var or GGUF discovery. Configure models via OPENAI_BASE_URL only; Chat UI will fetch ${OPENAI_BASE_URL}/models and populate the list automatically. Authorization uses OPENAI_API_KEY (preferred). HF_TOKEN remains a legacy alias.
Chat UI can perform client-side routing using an Arch Router model without running a separate router service. The UI exposes a virtual model alias called "Omni" (configurable) that, when selected, chooses the best route/model for each message.
- Provide a routes policy JSON via
LLM_ROUTER_ROUTES_PATH. No sample file ships with this branch, so you must point the variable to a JSON array you create yourself (for example, commit one in your project likeconfig/routes.chat.json). Each route entry needsname,description,primary_model, and optionalfallback_models. - Configure the Arch router selection endpoint with
LLM_ROUTER_ARCH_BASE_URL(OpenAI-compatible/chat/completions) andLLM_ROUTER_ARCH_MODEL(e.g.router/omni). The Arch call reusesOPENAI_API_KEYfor auth. - Map
otherto a concrete route viaLLM_ROUTER_OTHER_ROUTE(default:casual_conversation). If Arch selection fails, calls fall back toLLM_ROUTER_FALLBACK_MODEL. - Selection timeout can be tuned via
LLM_ROUTER_ARCH_TIMEOUT_MS(default 10000). - Omni alias configuration:
PUBLIC_LLM_ROUTER_ALIAS_ID(defaultomni),PUBLIC_LLM_ROUTER_DISPLAY_NAME(defaultOmni), and optionalPUBLIC_LLM_ROUTER_LOGO_URL.
When you select Omni in the UI, Chat UI will:
- Call the Arch endpoint once (non-streaming) to pick the best route for the last turns.
- Emit RouterMetadata immediately (route and actual model used) so the UI can display it.
- Stream from the selected model via your configured
OPENAI_BASE_URL. On errors, it tries route fallbacks.
To create a production version of your app:
npm run buildYou can preview the production build with npm run preview.
To deploy your app, you may need to install an adapter for your target environment.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for chat-ui
Similar Open Source Tools
chat-ui
A chat interface using open source models, eg OpenAssistant or Llama. It is a SvelteKit app and it powers the HuggingChat app on hf.co/chat.
mods
AI for the command line, built for pipelines. LLM based AI is really good at interpreting the output of commands and returning the results in CLI friendly text formats like Markdown. Mods is a simple tool that makes it super easy to use AI on the command line and in your pipelines. Mods works with OpenAI, Groq, Azure OpenAI, and LocalAI To get started, install Mods and check out some of the examples below. Since Mods has built-in Markdown formatting, you may also want to grab Glow to give the output some _pizzazz_.
ChatSim
ChatSim is a tool designed for editable scene simulation for autonomous driving via LLM-Agent collaboration. It provides functionalities for setting up the environment, installing necessary dependencies like McNeRF and Inpainting tools, and preparing data for simulation. Users can train models, simulate scenes, and track trajectories for smoother and more realistic results. The tool integrates with Blender software and offers options for training McNeRF models and McLight's skydome estimation network. It also includes a trajectory tracking module for improved trajectory tracking. ChatSim aims to facilitate the simulation of autonomous driving scenarios with collaborative LLM-Agents.

gcop
GCOP (Git Copilot) is an AI-powered Git assistant that automates commit message generation, enhances Git workflow, and offers 20+ smart commands. It provides intelligent commit crafting, customizable commit templates, smart learning capabilities, and a seamless developer experience. Users can generate AI commit messages, add all changes with AI-generated messages, undo commits while keeping changes staged, and push changes to the current branch. GCOP offers configuration options for AI models and provides detailed documentation, contribution guidelines, and a changelog. The tool is designed to make version control easier and more efficient for developers.

hash
HASH is a self-building, open-source database which grows, structures and checks itself. With it, we're creating a platform for decision-making, which helps you integrate, understand and use data in a variety of different ways.

ChatDBG
ChatDBG is an AI-based debugging assistant for C/C++/Python/Rust code that integrates large language models into a standard debugger (`pdb`, `lldb`, `gdb`, and `windbg`) to help debug your code. With ChatDBG, you can engage in a dialog with your debugger, asking open-ended questions about your program, like `why is x null?`. ChatDBG will _take the wheel_ and steer the debugger to answer your queries. ChatDBG can provide error diagnoses and suggest fixes. As far as we are aware, ChatDBG is the _first_ debugger to automatically perform root cause analysis and to provide suggested fixes.
k8sgpt
K8sGPT is a tool for scanning your Kubernetes clusters, diagnosing, and triaging issues in simple English. It has SRE experience codified into its analyzers and helps to pull out the most relevant information to enrich it with AI.

chatgpt-cli
ChatGPT CLI provides a powerful command-line interface for seamless interaction with ChatGPT models via OpenAI and Azure. It features streaming capabilities, extensive configuration options, and supports various modes like streaming, query, and interactive mode. Users can manage thread-based context, sliding window history, and provide custom context from any source. The CLI also offers model and thread listing, advanced configuration options, and supports GPT-4, GPT-3.5-turbo, and Perplexity's models. Installation is available via Homebrew or direct download, and users can configure settings through default values, a config.yaml file, or environment variables.


agenticSeek
AgenticSeek is a voice-enabled AI assistant powered by DeepSeek R1 agents, offering a fully local alternative to cloud-based AI services. It allows users to interact with their filesystem, code in multiple languages, and perform various tasks autonomously. The tool is equipped with memory to remember user preferences and past conversations, and it can divide tasks among multiple agents for efficient execution. AgenticSeek prioritizes privacy by running entirely on the user's hardware without sending data to the cloud.
MindSearch
MindSearch is an open-source AI Search Engine Framework that mimics human minds to provide deep AI search capabilities. It allows users to deploy their own search engine using either close-source or open-source language models. MindSearch offers features such as answering any question using web knowledge, in-depth knowledge discovery, detailed solution paths, optimized UI experience, and dynamic graph construction process.
slack-mcp-server
Slack MCP Server is a Model Context Protocol server for Slack Workspaces, offering powerful features like Stealth and OAuth Modes, Enterprise Workspaces Support, Channel and Thread Support, Smart History, Search Messages, Safe Message Posting, DM and Group DM support, Embedded user information, Cache support, and multiple transport options. It provides tools like conversations_history, conversations_replies, conversations_add_message, conversations_search_messages, and channels_list for managing messages, threads, adding messages, searching messages, and listing channels. The server also exposes directory resources for workspace metadata access. The tool is designed to enhance Slack workspace functionality and improve user experience.
orbiton
Orbiton is a text editor and simple IDE designed with minimal annoyance in mind, not highly configurable to help users stay focused, and supports rapid edit-format-compile cycles. It is suitable for writing git commit messages, editing README.md and TODO.md files, writing Markdown and exporting to HTML or PDF, learning programming languages, editing files within larger projects, solving Advent of Code tasks, and providing a distraction-free environment for writing. The tool offers unique features like smart cursor movement, paste and copy shortcuts, portal for copying lines across files, code building and formatting shortcuts, and more.

1.5-Pints
1.5-Pints is a repository that provides a recipe to pre-train models in 9 days, aiming to create AI assistants comparable to Apple OpenELM and Microsoft Phi. It includes model architecture, training scripts, and utilities for 1.5-Pints and 0.12-Pint developed by Pints.AI. The initiative encourages replication, experimentation, and open-source development of Pint by sharing the model's codebase and architecture. The repository offers installation instructions, dataset preparation scripts, model training guidelines, and tools for model evaluation and usage. Users can also find information on finetuning models, converting lit models to HuggingFace models, and running Direct Preference Optimization (DPO) post-finetuning. Additionally, the repository includes tests to ensure code modifications do not disrupt the existing functionality.
please-cli
Please CLI is an AI helper script designed to create CLI commands by leveraging the GPT model. Users can input a command description, and the script will generate a Linux command based on that input. The tool offers various functionalities such as invoking commands, copying commands to the clipboard, asking questions about commands, and more. It supports parameters for explanation, using different AI models, displaying additional output, storing API keys, querying ChatGPT with specific models, showing the current version, and providing help messages. Users can install Please CLI via Homebrew, apt, Nix, dpkg, AUR, or manually from source. The tool requires an OpenAI API key for operation and offers configuration options for setting API keys and OpenAI settings. Please CLI is licensed under the Apache License 2.0 by TNG Technology Consulting GmbH.
tiledesk-dashboard
Tiledesk is an open-source live chat platform with integrated chatbots written in Node.js and Express. It is designed to be a multi-channel platform for web, Android, and iOS, and it can be used to increase sales or provide post-sales customer service. Tiledesk's chatbot technology allows for automation of conversations, and it also provides APIs and webhooks for connecting external applications. Additionally, it offers a marketplace for apps and features such as CRM, ticketing, and data export.
For similar tasks
blog
这是一个程序员关于 ChatGPT 学习过程的记录,其中包括了 ChatGPT 的使用技巧、相关工具和资源的整理,以及一些个人见解和思考。 **使用技巧** * **充值 OpenAI API**:可以通过 https://beta.openai.com/account/api-keys 进行充值,支持信用卡和 PayPal。 * **使用专梯**:推荐使用稳定的专梯,可以有效提高 ChatGPT 的访问速度和稳定性。 * **使用魔法**:可以通过 https://my.x-air.app:666/#/register?aff=32853 访问 ChatGPT,无需魔法即可访问。 * **下载各种 apk**:可以通过 https://apkcombo.com 下载各种安卓应用的 apk 文件。 * **ChatGPT 官网**:ChatGPT 的官方网站是 https://ai.com。 * **Midjourney**:Midjourney 是一个生成式 AI 图像平台,可以通过 https://midjourney.com 访问。 * **文本转视频**:可以通过 https://www.d-id.com 将文本转换为视频。 * **国内大模型**:国内也有很多大模型,如阿里巴巴的通义千问、百度文心一言、讯飞星火、阿里巴巴通义听悟等。 * **查看 OpenAI 状态**:可以通过 https://status.openai.com/ 查看 OpenAI 的服务状态。 * **Canva 画图**:Canva 是一个在线平面设计平台,可以通过 https://www.canva.cn 进行画图。 **相关工具和资源** * **文字转语音**:可以通过 https://modelscope.cn/models?page=1&tasks=text-to-speech&type=audio 找到文字转语音的模型。 * **可好好玩玩的项目**: * https://github.com/sunner/ChatALL * https://github.com/labring/FastGPT * https://github.com/songquanpeng/one-api * **个人博客**: * https://baoyu.io/ * https://gorden-sun.notion.site/527689cd2b294e60912f040095e803c5?v=4f6cc12006c94f47aee4dc909511aeb5 * **srt 2 lrc 歌词**:可以通过 https://gotranscript.com/subtitle-converter 将 srt 格式的字幕转换为 lrc 格式的歌词。 * **5 种速率限制**:OpenAI API 有 5 种速率限制:RPM(每分钟请求数)、RPD(每天请求数)、TPM(每分钟 tokens 数量)、TPD(每天 tokens 数量)、IPM(每分钟图像数量)。 * **扣子平台**:coze.cn 是一个扣子平台,可以提供各种扣子。 * **通过云函数免费使用 GPT-3.5**:可以通过 https://juejin.cn/post/7353849549540589587 免费使用 GPT-3.5。 * **不蒜子 统计网页基数**:可以通过 https://busuanzi.ibruce.info/ 统计网页的基数。 * **视频总结和翻译网页**:可以通过 https://glarity.app/zh-CN 总结和翻译视频。 * **视频翻译和配音工具**:可以通过 https://github.com/jianchang512/pyvideotrans 翻译和配音视频。 * **文字生成音频**:可以通过 https://www.cnblogs.com/jijunjian/p/18118366 将文字生成音频。 * **memo ai**:memo.ac 是一个多模态 AI 平台,可以将视频链接、播客链接、本地音视频转换为文字,支持多语言转录后翻译,还可以将文字转换为新的音频。 * **视频总结工具**:可以通过 https://summarize.ing/ 总结视频。 * **可每天免费玩玩**:可以通过 https://www.perplexity.ai/ 每天免费玩玩。 * **Suno.ai**:Suno.ai 是一个 AI 语言模型,可以通过 https://bibigpt.co/ 访问。 * **CapCut**:CapCut 是一个视频编辑软件,可以通过 https://www.capcut.cn/ 下载。 * **Valla.ai**:Valla.ai 是一个多模态 AI 模型,可以通过 https://www.valla.ai/ 访问。 * **Viggle.ai**:Viggle.ai 是一个 AI 视频生成平台,可以通过 https://viggle.ai 访问。 * **使用免费的 GPU 部署文生图大模型**:可以通过 https://www.cnblogs.com/xuxiaona/p/18088404 部署文生图大模型。 * **语音转文字**:可以通过 https://speech.microsoft.com/portal 将语音转换为文字。 * **投资界的 ai**:可以通过 https://reportify.cc/ 了解投资界的 ai。 * **抓取小视频 app 的各种信息**:可以通过 https://github.com/NanmiCoder/MediaCrawler 抓取小视频 app 的各种信息。 * **马斯克 Grok1 开源**:马斯克的 Grok1 模型已经开源,可以通过 https://github.com/xai-org/grok-1 访问。 * **ChatALL**:ChatALL 是一个跨端支持的聊天机器人,可以通过 https://github.com/sunner/ChatALL 访问。 * **零一万物**:零一万物是一个 AI 平台,可以通过 https://www.01.ai/cn 访问。 * **智普**:智普是一个 AI 语言模型,可以通过 https://chatglm.cn/ 访问。 * **memo ai 下载**:可以通过 https://memo.ac/ 下载 memo ai。 * **ffmpeg 学习**:可以通过 https://www.ruanyifeng.com/blog/2020/01/ffmpeg.html 学习 ffmpeg。 * **自动生成文章小工具**:可以通过 https://www.cognition-labs.com/blog 生成文章。 * **简易商城**:可以通过 https://www.cnblogs.com/whuanle/p/18086537 搭建简易商城。 * **物联网**:可以通过 https://www.cnblogs.com/xuxiaona/p/18088404 学习物联网。 * **自定义表单、自定义列表、自定义上传和下载、自定义流程、自定义报表**:可以通过 https://www.cnblogs.com/whuanle/p/18086537 实现自定义表单、自定义列表、自定义上传和下载、自定义流程、自定义报表。 **个人见解和思考** * ChatGPT 是一个强大的工具,可以用来提高工作效率和创造力。 * ChatGPT 的使用门槛较低,即使是非技术人员也可以轻松上手。 * ChatGPT 的发展速度非常快,未来可能会对各个行业产生深远的影响。 * 我们应该理性看待 ChatGPT,既要看到它的优点,也要意识到它的局限性。 * 我们应该积极探索 ChatGPT 的应用场景,为社会创造价值。
chat-ui
A chat interface using open source models, eg OpenAssistant or Llama. It is a SvelteKit app and it powers the HuggingChat app on hf.co/chat.
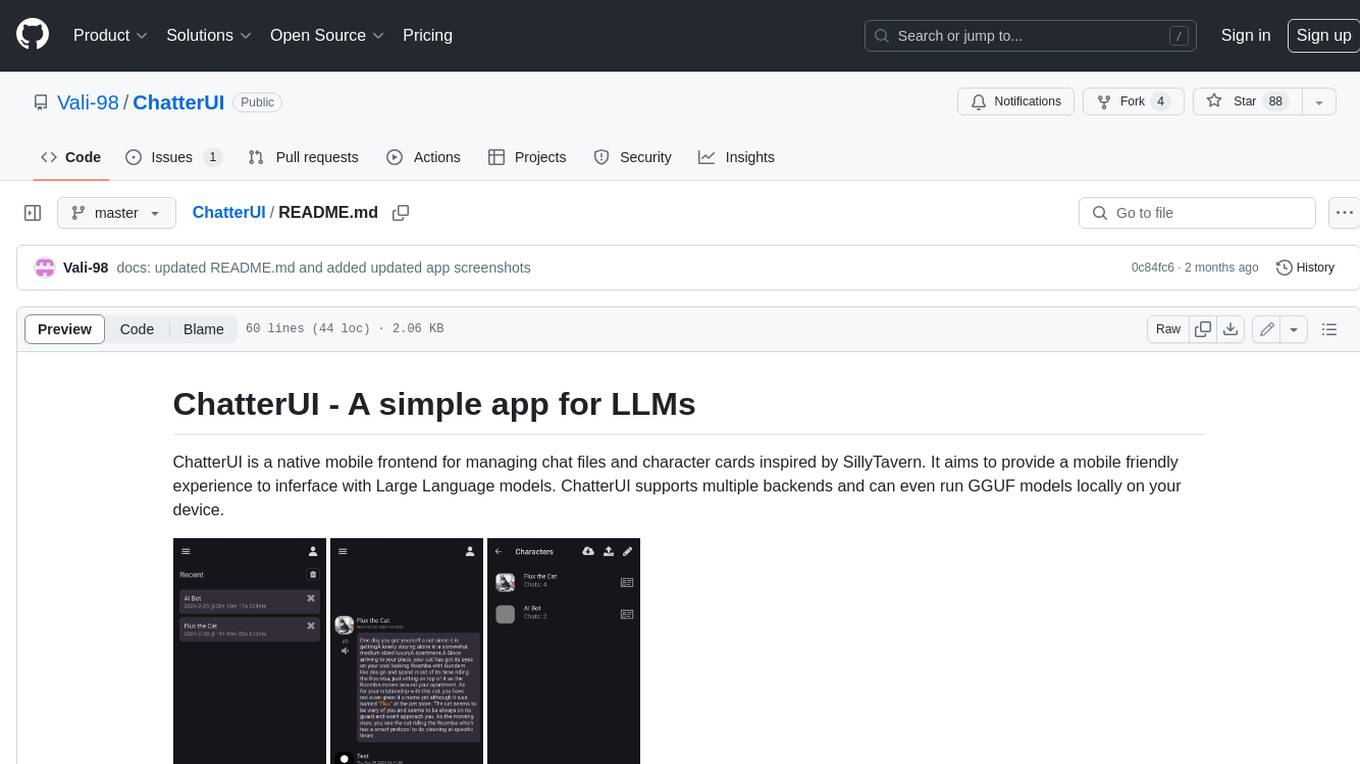
ChatterUI
ChatterUI is a mobile app that allows users to manage chat files and character cards, and to interact with Large Language Models (LLMs). It supports multiple backends, including local, koboldcpp, text-generation-webui, Generic Text Completions, AI Horde, Mancer, Open Router, and OpenAI. ChatterUI provides a mobile-friendly interface for interacting with LLMs, making it easy to use them for a variety of tasks, such as generating text, translating languages, writing code, and answering questions.
99AI
99AI is a commercializable AI web application based on NineAI 2.4.2 (no authorization, no backdoors, no piracy, integrated front-end and back-end integration packages, supports Docker rapid deployment). The uncompiled source code is temporarily closed. Compared with the stable version, the development version is faster.
chatnio
Chat Nio is a next-generation AI one-stop solution that provides a rich and user-friendly interface for interacting with various AI models. It offers features such as AI chat conversation, rich format compatibility, markdown support, message menu support, multi-platform adaptation, dialogue memory, full-model file parsing, full-model DuckDuckGo online search, full-screen large text editing, model marketplace, preset support, site announcements, preference settings, internationalization support, and a rich admin system. Chat Nio also boasts a powerful channel management system that utilizes a self-developed channel distribution algorithm, supports multi-channel management, is compatible with multiple formats, allows for custom models, supports channel retries, enables balanced load within the same channel, and provides channel model mapping and user grouping. Additionally, Chat Nio offers forwarding API services that are compatible with multiple formats in the OpenAI universal format and support multiple model compatible layers. It also provides a custom build and install option for highly customizable deployments. Chat Nio is an open-source project licensed under the Apache License 2.0 and welcomes contributions from the community.

Awesome-LLM-Reasoning
**Curated collection of papers and resources on how to unlock the reasoning ability of LLMs and MLLMs.** **Description in less than 400 words, no line breaks and quotation marks.** Large Language Models (LLMs) have revolutionized the NLP landscape, showing improved performance and sample efficiency over smaller models. However, increasing model size alone has not proved sufficient for high performance on challenging reasoning tasks, such as solving arithmetic or commonsense problems. This curated collection of papers and resources presents the latest advancements in unlocking the reasoning abilities of LLMs and Multimodal LLMs (MLLMs). It covers various techniques, benchmarks, and applications, providing a comprehensive overview of the field. **5 jobs suitable for this tool, in lowercase letters.** - content writer - researcher - data analyst - software engineer - product manager **Keywords of the tool, in lowercase letters.** - llm - reasoning - multimodal - chain-of-thought - prompt engineering **5 specific tasks user can use this tool to do, in less than 3 words, Verb + noun form, in daily spoken language.** - write a story - answer a question - translate a language - generate code - summarize a document

Chinese-LLaMA-Alpaca-2
Chinese-LLaMA-Alpaca-2 is a large Chinese language model developed by Meta AI. It is based on the Llama-2 model and has been further trained on a large dataset of Chinese text. Chinese-LLaMA-Alpaca-2 can be used for a variety of natural language processing tasks, including text generation, question answering, and machine translation. Here are some of the key features of Chinese-LLaMA-Alpaca-2: * It is the largest Chinese language model ever trained, with 13 billion parameters. * It is trained on a massive dataset of Chinese text, including books, news articles, and social media posts. * It can be used for a variety of natural language processing tasks, including text generation, question answering, and machine translation. * It is open-source and available for anyone to use. Chinese-LLaMA-Alpaca-2 is a powerful tool that can be used to improve the performance of a wide range of natural language processing tasks. It is a valuable resource for researchers and developers working in the field of artificial intelligence.
Linly-Talker
Linly-Talker is an innovative digital human conversation system that integrates the latest artificial intelligence technologies, including Large Language Models (LLM) 🤖, Automatic Speech Recognition (ASR) 🎙️, Text-to-Speech (TTS) 🗣️, and voice cloning technology 🎤. This system offers an interactive web interface through the Gradio platform 🌐, allowing users to upload images 📷 and engage in personalized dialogues with AI 💬.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.