
pipecat-flows
Open source conversation framework and visual editor for structured Pipecat dialogues
Stars: 443
Pipecat Flows is a framework designed for building structured conversations in AI applications. It allows users to create both predefined conversation paths and dynamically generated flows, handling state management and LLM interactions. The framework includes a Python module for building conversation flows and a visual editor for designing and exporting flow configurations. Pipecat Flows is suitable for scenarios such as customer service scripts, intake forms, personalized experiences, and complex decision trees.
README:



Pipecat Flows is an add-on framework for Pipecat that allows you to build structured conversations in your AI applications. It enables you to create both predefined conversation paths and dynamically generated flows while handling the complexities of state management and LLM interactions.
The framework consists of:
- A Python module for building conversation flows with Pipecat
- A visual editor for designing and exporting flow configurations
- Python 3.10 or higher
- Pipecat
-
Install uv
curl -LsSf https://astral.sh/uv/install.sh | shNeed help? Refer to the uv install documentation.
-
Install the module
# For new projects uv init my-pipecat-flows-app cd my-pipecat-flows-app uv add pipecat-ai-flows # Or for existing projects uv add pipecat-ai-flows
Using pip? You can still use
pip install pipecat-ai-flowsto get set up.
See Quick Start README.
For more detailed examples and guides, visit our documentation.
The repository includes several complete example implementations demonstrating various features of Pipecat Flows.
- Static Flows: Pre-defined conversation paths including food ordering, movie exploration, patient intake, and travel planning
- Dynamic Flows: Runtime-generated flows including insurance quotes, restaurant reservations, and warm transfers
Each example is available in multiple LLM provider formats (OpenAI, Anthropic, Google Gemini, AWS Bedrock) to demonstrate cross-platform compatibility.
For detailed setup instructions, configuration, and running examples, see the Examples README.
Quick start:
# Install dependencies
uv sync
uv pip install "pipecat-ai[daily,openai,deepgram,cartesia,silero,examples]"
# Configure environment
cp env.example .env # Add your API keys
# Run an example
uv run python examples/static/food_ordering.py -u YOUR_DAILY_ROOM_URL-
Clone the repository and navigate to it:
git clone https://github.com/pipecat-ai/pipecat-flows.git cd pipecat-flows -
Install development dependencies:
uv sync --group dev
-
Install the git pre-commit hooks (these help ensure your code follows project rules):
uv run pre-commit install
The package is automatically installed in editable mode when you run
uv sync.
The package includes a comprehensive test suite covering the core functionality.
-
Install Dependencies:
uv sync --group dev uv add "pipecat-ai[google,aws,openai,anthropic]"
Run all tests:
uv run pytest tests/Run specific test file:
uv run pytest tests/test_state.pyRun specific test:
uv run pytest tests/test_state.py -k test_initializationRun with coverage report:
uv run pytest tests/ --cov=pipecat_flowsThe Flows Editor is deprecated and will be removed along with Static Flows.
We have future plans to introduce a new editor capability that supports dynamic flows, but we don't have a timeline yet. We're open to collaborating with any developers or teams who have an interesting in building out this type of UI! Reach out to us on Discord if you're interested.
A visual editor for creating and managing Pipecat conversation flows.
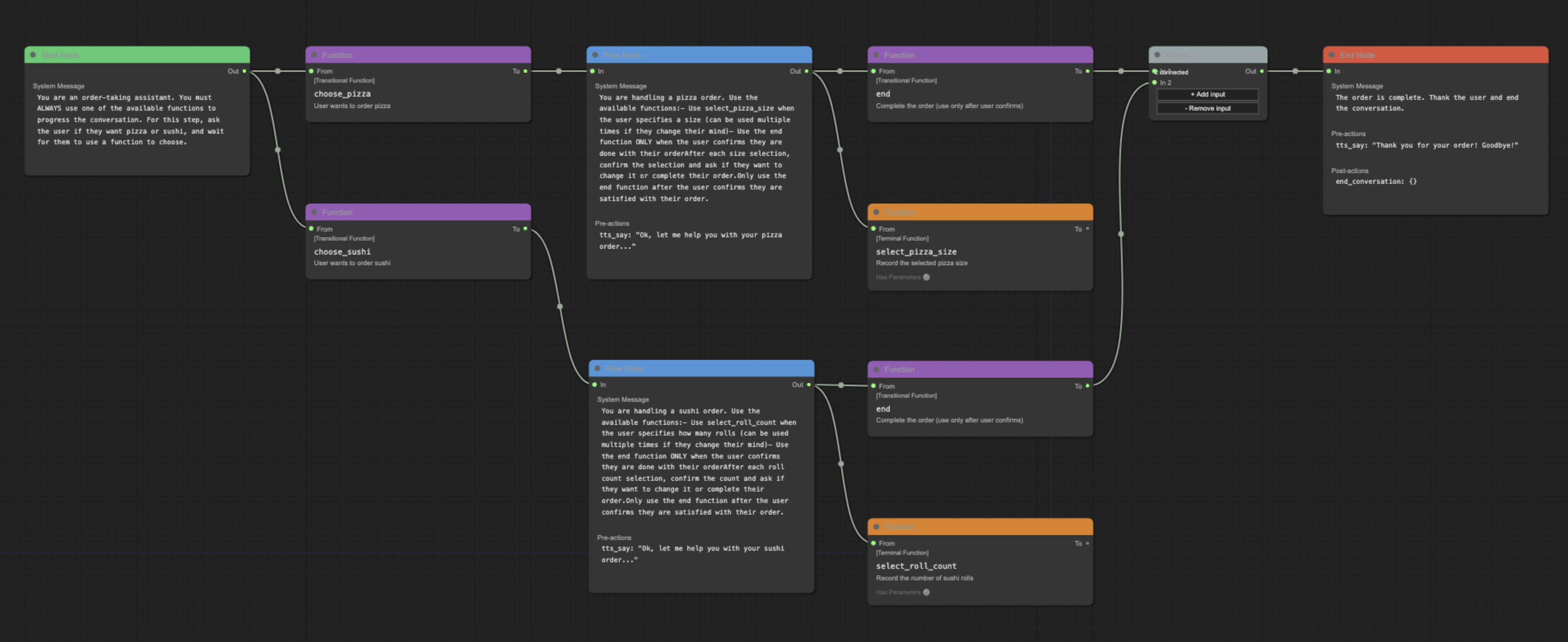
- Visual flow creation and editing
- Import/export of flow configurations
- Support for node and edge functions
- Merge node support for complex flows
- Real-time validation
While the underlying system is flexible with node naming, the editor follows these conventions for clarity:
- Start Node: Named after your initial conversation state (e.g., "greeting", "welcome")
- End Node: Conventionally named "end" for clarity, though other names are supported
- Flow Nodes: Named to reflect their purpose in the conversation (e.g., "get_time", "confirm_order")
These conventions help maintain readable and maintainable flows while preserving technical flexibility.
The editor is available online at flows.pipecat.ai.
- Node.js (v14 or higher)
- npm (v6 or higher)
Clone the repository
git clone [email protected]:pipecat-ai/pipecat-flows.gitNavigate to project directory
cd pipecat-flows/editorInstall dependencies
npm installStart development server
npm run devOpen the page in your browser: http://localhost:5173.
- Create a new flow using the toolbar buttons
- Add nodes by right-clicking in the canvas
- Start nodes can have descriptive names (e.g., "greeting")
- End nodes are conventionally named "end"
- Connect nodes by dragging from outputs to inputs
- Edit node properties in the side panel
- Export your flow configuration using the toolbar
The editor/examples/ directory contains sample flow configurations:
food_ordering.jsonmovie_explorer.pypatient_intake.jsonrestaurant_reservation.jsontravel_planner.json
To use an example:
- Open the editor
- Click "Import Flow"
- Select an example JSON file
See the examples directory for the complete files and documentation.
-
npm start- Start production server -
npm run dev- Start development server -
npm run build- Build for production -
npm run preview- Preview production build locally -
npm run preview:prod- Preview production build with base path -
npm run lint- Check for linting issues -
npm run lint:fix- Fix linting issues -
npm run format- Format code with Prettier -
npm run format:check- Check code formatting -
npm run docs- Generate documentation -
npm run docs:serve- Serve documentation locally
The Pipecat Flows Editor project uses JSDoc for documentation. To generate and view the documentation:
Generate documentation:
npm run docsServe documentation locally:
npm run docs:serveView in browser by opening: http://localhost:8080
We welcome contributions from the community! Whether you're fixing bugs, improving documentation, or adding new features, here's how you can help:
- Found a bug? Open an issue
- Have a feature idea? Start a discussion
- Want to contribute code? Check our CONTRIBUTING.md guide
- Documentation improvements? Docs PRs are always welcome
Before submitting a pull request, please check existing issues and PRs to avoid duplicates.
We aim to review all contributions promptly and provide constructive feedback to help get your changes merged.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for pipecat-flows
Similar Open Source Tools
pipecat-flows
Pipecat Flows is a framework designed for building structured conversations in AI applications. It allows users to create both predefined conversation paths and dynamically generated flows, handling state management and LLM interactions. The framework includes a Python module for building conversation flows and a visual editor for designing and exporting flow configurations. Pipecat Flows is suitable for scenarios such as customer service scripts, intake forms, personalized experiences, and complex decision trees.

gitingest
GitIngest is a tool that allows users to turn any Git repository into a prompt-friendly text ingest for LLMs. It provides easy code context by generating a text digest from a git repository URL or directory. The tool offers smart formatting for optimized output format for LLM prompts and provides statistics about file and directory structure, size of the extract, and token count. GitIngest can be used as a CLI tool on Linux and as a Python package for code integration. The tool is built using Tailwind CSS for frontend, FastAPI for backend framework, tiktoken for token estimation, and apianalytics.dev for simple analytics. Users can self-host GitIngest by building the Docker image and running the container. Contributions to the project are welcome, and the tool aims to be beginner-friendly for first-time contributors with a simple Python and HTML codebase.
manifold
Manifold is a powerful platform for workflow automation using AI models. It supports text generation, image generation, and retrieval-augmented generation, integrating seamlessly with popular AI endpoints. Additionally, Manifold provides robust semantic search capabilities using PGVector combined with the SEFII engine. It is under active development and not production-ready.

company-research-agent
Agentic Company Researcher is a multi-agent tool that generates comprehensive company research reports by utilizing a pipeline of AI agents to gather, curate, and synthesize information from various sources. It features multi-source research, AI-powered content filtering, real-time progress streaming, dual model architecture, modern React frontend, and modular architecture. The tool follows an agentic framework with specialized research and processing nodes, leverages separate models for content generation, uses a content curation system for relevance scoring and document processing, and implements a real-time communication system via WebSocket connections. Users can set up the tool quickly using the provided setup script or manually, and it can also be deployed using Docker and Docker Compose. The application can be used for local development and deployed to various cloud platforms like AWS Elastic Beanstalk, Docker, Heroku, and Google Cloud Run.
BuildCLI
BuildCLI is a command-line interface (CLI) tool designed for managing and automating common tasks in Java project development. It simplifies the development process by allowing users to create, compile, manage dependencies, run projects, generate documentation, manage configuration profiles, dockerize projects, integrate CI/CD tools, and generate structured changelogs. The tool aims to enhance productivity and streamline Java project management by providing a range of functionalities accessible directly from the terminal.
xlang
XLang™ is a cutting-edge language designed for AI and IoT applications, offering exceptional dynamic and high-performance capabilities. It excels in distributed computing and seamless integration with popular languages like C++, Python, and JavaScript. Notably efficient, running 3 to 5 times faster than Python in AI and deep learning contexts. Features optimized tensor computing architecture for constructing neural networks through tensor expressions. Automates tensor data flow graph generation and compilation for specific targets, enhancing GPU performance by 6 to 10 times in CUDA environments.

agnai
Agnaistic is an AI roleplay chat tool that allows users to interact with personalized characters using their favorite AI services. It supports multiple AI services, persona schema formats, and features such as group conversations, user authentication, and memory/lore books. Agnaistic can be self-hosted or run using Docker, and it provides a range of customization options through its settings.json file. The tool is designed to be user-friendly and accessible, making it suitable for both casual users and developers.
AirCasting
AirCasting is a platform for gathering, visualizing, and sharing environmental data. It aims to provide a central hub for environmental data, making it easier for people to access and use this information to make informed decisions about their environment.
codepair
CodePair is an open-source real-time collaborative markdown editor with AI intelligence, allowing users to collaboratively edit documents, share documents with external parties, and utilize AI intelligence within the editor. It is built using React, NestJS, and LangChain. The repository contains frontend and backend code, with detailed instructions for setting up and running each part. Users can choose between Frontend Development Only Mode or Full Stack Development Mode based on their needs. CodePair also integrates GitHub OAuth for Social Login feature. Contributors are welcome to submit patches and follow the contribution workflow.
middleware
Middleware is an open-source engineering management tool that helps engineering leaders measure and analyze team effectiveness using DORA metrics. It integrates with CI/CD tools, automates DORA metric collection and analysis, visualizes key performance indicators, provides customizable reports and dashboards, and integrates with project management platforms. Users can set up Middleware using Docker or manually, generate encryption keys, set up backend and web servers, and access the application to view DORA metrics. The tool calculates DORA metrics using GitHub data, including Deployment Frequency, Lead Time for Changes, Mean Time to Restore, and Change Failure Rate. Middleware aims to provide DORA metrics to users based on their Git data, simplifying the process of tracking software delivery performance and operational efficiency.
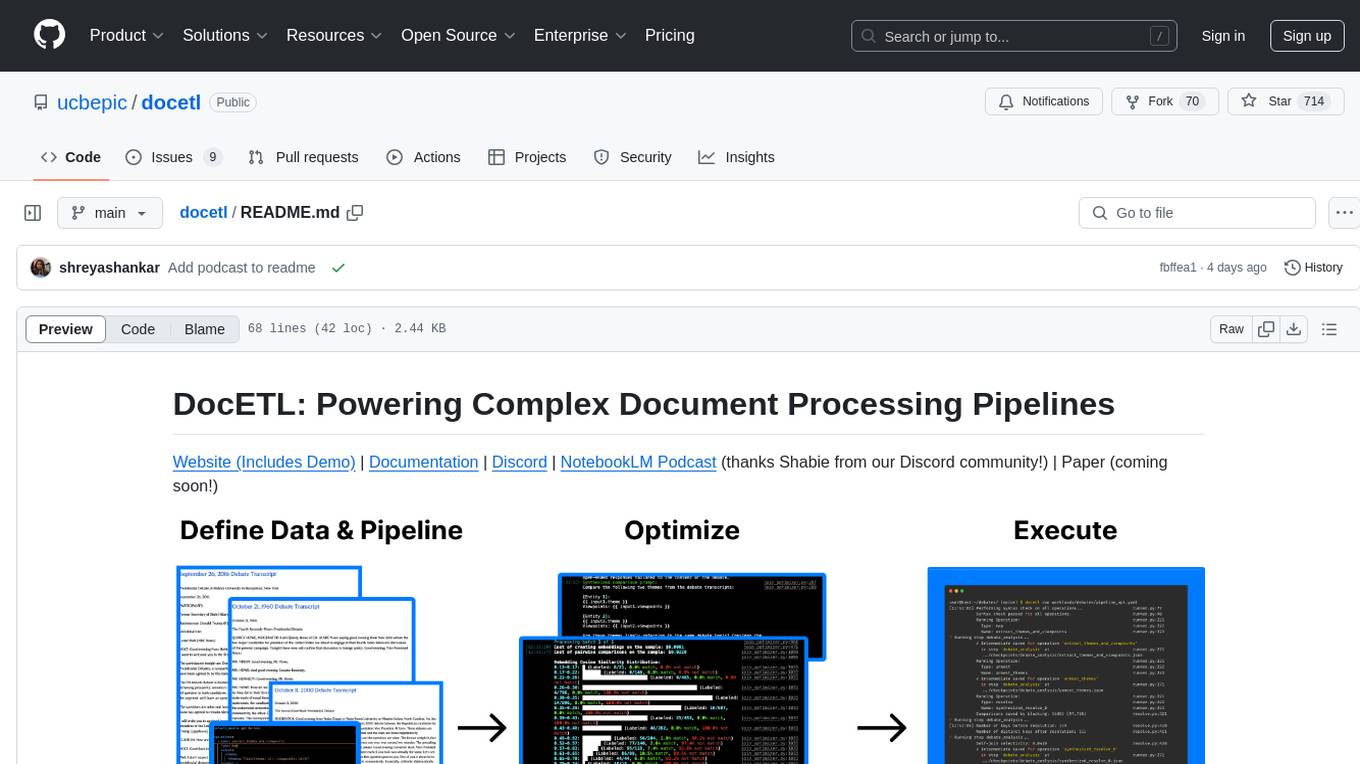
docetl
DocETL is a tool for creating and executing data processing pipelines, especially suited for complex document processing tasks. It offers a low-code, declarative YAML interface to define LLM-powered operations on complex data. Ideal for maximizing correctness and output quality for semantic processing on a collection of data, representing complex tasks via map-reduce, maximizing LLM accuracy, handling long documents, and automating task retries based on validation criteria.
NeoGPT
NeoGPT is an AI assistant that transforms your local workspace into a powerhouse of productivity from your CLI. With features like code interpretation, multi-RAG support, vision models, and LLM integration, NeoGPT redefines how you work and create. It supports executing code seamlessly, multiple RAG techniques, vision models, and interacting with various language models. Users can run the CLI to start using NeoGPT and access features like Code Interpreter, building vector database, running Streamlit UI, and changing LLM models. The tool also offers magic commands for chat sessions, such as resetting chat history, saving conversations, exporting settings, and more. Join the NeoGPT community to experience a new era of efficiency and contribute to its evolution.

extension-gen-ai
The Looker GenAI Extension provides code examples and resources for building a Looker Extension that integrates with Vertex AI Large Language Models (LLMs). Users can leverage the power of LLMs to enhance data exploration and analysis within Looker. The extension offers generative explore functionality to ask natural language questions about data and generative insights on dashboards to analyze data by asking questions. It leverages components like BQML Remote Models, BQML Remote UDF with Vertex AI, and Custom Fine Tune Model for different integration options. Deployment involves setting up infrastructure with Terraform and deploying the Looker Extension by creating a Looker project, copying extension files, configuring BigQuery connection, connecting to Git, and testing the extension. Users can save example prompts and configure user settings for the extension. Development of the Looker Extension environment includes installing dependencies, starting the development server, and building for production.

opencode
Opencode is an AI coding agent designed for the terminal. It is a tool that allows users to interact with AI models for coding tasks in a terminal-based environment. Opencode is open source, provider-agnostic, and focuses on a terminal user interface (TUI) for coding. It offers features such as client/server architecture, support for various AI models, and a strong emphasis on community contributions and feedback.

LLMinator
LLMinator is a Gradio-based tool with an integrated chatbot designed to locally run and test Language Model Models (LLMs) directly from HuggingFace. It provides an easy-to-use interface made with Gradio, LangChain, and Torch, offering features such as context-aware streaming chatbot, inbuilt code syntax highlighting, loading any LLM repo from HuggingFace, support for both CPU and CUDA modes, enabling LLM inference with llama.cpp, and model conversion capabilities.
openmeter
OpenMeter is a real-time and scalable usage metering tool for AI, usage-based billing, infrastructure, and IoT use cases. It provides a REST API for integrations and offers client SDKs in Node.js, Python, Go, and Web. OpenMeter is licensed under the Apache 2.0 License.
For similar tasks
pipecat-flows
Pipecat Flows is a framework designed for building structured conversations in AI applications. It allows users to create both predefined conversation paths and dynamically generated flows, handling state management and LLM interactions. The framework includes a Python module for building conversation flows and a visual editor for designing and exporting flow configurations. Pipecat Flows is suitable for scenarios such as customer service scripts, intake forms, personalized experiences, and complex decision trees.
burr
Burr is a Python library and UI that makes it easy to develop applications that make decisions based on state (chatbots, agents, simulations, etc...). Burr includes a UI that can track/monitor those decisions in real time.
llama_deploy
llama_deploy is an async-first framework for deploying, scaling, and productionizing agentic multi-service systems based on workflows from llama_index. It allows building workflows in llama_index and deploying them seamlessly with minimal changes to code. The system includes services endlessly processing tasks, a control plane managing state and services, an orchestrator deciding task handling, and fault tolerance mechanisms. It is designed for high-concurrency scenarios, enabling real-time and high-throughput applications.
agentscript
AgentScript is an open-source framework for building AI agents that think in code. It prompts a language model to generate JavaScript code, which is then executed in a dedicated runtime with resumability, state persistence, and interactivity. The framework allows for abstract task execution without needing to know all the data beforehand, making it flexible and efficient. AgentScript supports tools, deterministic functions, and LLM-enabled functions, enabling dynamic data processing and decision-making. It also provides state management and human-in-the-loop capabilities, allowing for pausing, serialization, and resumption of execution.
agents
Cloudflare Agents is a framework for building intelligent, stateful agents that persist, think, and evolve at the edge of the network. It allows for maintaining persistent state and memory, real-time communication, processing and learning from interactions, autonomous operation at global scale, and hibernating when idle. The project is actively evolving with focus on core agent framework, WebSocket communication, HTTP endpoints, React integration, and basic AI chat capabilities. Future developments include advanced memory systems, WebRTC for audio/video, email integration, evaluation framework, enhanced observability, and self-hosting guide.
dify-google-cloud-terraform
This repository provides Terraform configurations to automatically set up Google Cloud resources and deploy Dify in a highly available configuration. It includes features such as serverless hosting, auto-scaling, and data persistence. Users need a Google Cloud account, Terraform, and gcloud CLI installed to use this tool. The configuration involves setting environment-specific values and creating a GCS bucket for managing Terraform state. The tool allows users to initialize Terraform, create Artifact Registry repository, build and push container images, plan and apply Terraform changes, and cleanup resources when needed.

exospherehost
Exosphere is an open source infrastructure designed to run AI agents at scale for large data and long running flows. It allows developers to define plug and playable nodes that can be run on a reliable backbone in the form of a workflow, with features like dynamic state creation at runtime, infinite parallel agents, persistent state management, and failure handling. This enables the deployment of production agents that can scale beautifully to build robust autonomous AI workflows.

xpander.ai
xpander.ai is a Backend-as-a-Service for autonomous agents that abstracts the ops layer, allowing AI engineers to focus on behavior and outcomes. It provides managed agent hosting with version control and CI/CD, a fully managed PostgreSQL memory layer, and a library of 2,000+ functions. The platform features an AI native triggering system that processes inputs from various sources and delivers unified messages to agents. With support for any agent framework or SDK, including Agno and OpenAI, xpander.ai enables users to build intelligent, production-ready AI agents without dealing with infrastructure complexity.
For similar jobs

promptflow
**Prompt flow** is a suite of development tools designed to streamline the end-to-end development cycle of LLM-based AI applications, from ideation, prototyping, testing, evaluation to production deployment and monitoring. It makes prompt engineering much easier and enables you to build LLM apps with production quality.

deepeval
DeepEval is a simple-to-use, open-source LLM evaluation framework specialized for unit testing LLM outputs. It incorporates various metrics such as G-Eval, hallucination, answer relevancy, RAGAS, etc., and runs locally on your machine for evaluation. It provides a wide range of ready-to-use evaluation metrics, allows for creating custom metrics, integrates with any CI/CD environment, and enables benchmarking LLMs on popular benchmarks. DeepEval is designed for evaluating RAG and fine-tuning applications, helping users optimize hyperparameters, prevent prompt drifting, and transition from OpenAI to hosting their own Llama2 with confidence.

MegaDetector
MegaDetector is an AI model that identifies animals, people, and vehicles in camera trap images (which also makes it useful for eliminating blank images). This model is trained on several million images from a variety of ecosystems. MegaDetector is just one of many tools that aims to make conservation biologists more efficient with AI. If you want to learn about other ways to use AI to accelerate camera trap workflows, check out our of the field, affectionately titled "Everything I know about machine learning and camera traps".

leapfrogai
LeapfrogAI is a self-hosted AI platform designed to be deployed in air-gapped resource-constrained environments. It brings sophisticated AI solutions to these environments by hosting all the necessary components of an AI stack, including vector databases, model backends, API, and UI. LeapfrogAI's API closely matches that of OpenAI, allowing tools built for OpenAI/ChatGPT to function seamlessly with a LeapfrogAI backend. It provides several backends for various use cases, including llama-cpp-python, whisper, text-embeddings, and vllm. LeapfrogAI leverages Chainguard's apko to harden base python images, ensuring the latest supported Python versions are used by the other components of the stack. The LeapfrogAI SDK provides a standard set of protobuffs and python utilities for implementing backends and gRPC. LeapfrogAI offers UI options for common use-cases like chat, summarization, and transcription. It can be deployed and run locally via UDS and Kubernetes, built out using Zarf packages. LeapfrogAI is supported by a community of users and contributors, including Defense Unicorns, Beast Code, Chainguard, Exovera, Hypergiant, Pulze, SOSi, United States Navy, United States Air Force, and United States Space Force.

llava-docker
This Docker image for LLaVA (Large Language and Vision Assistant) provides a convenient way to run LLaVA locally or on RunPod. LLaVA is a powerful AI tool that combines natural language processing and computer vision capabilities. With this Docker image, you can easily access LLaVA's functionalities for various tasks, including image captioning, visual question answering, text summarization, and more. The image comes pre-installed with LLaVA v1.2.0, Torch 2.1.2, xformers 0.0.23.post1, and other necessary dependencies. You can customize the model used by setting the MODEL environment variable. The image also includes a Jupyter Lab environment for interactive development and exploration. Overall, this Docker image offers a comprehensive and user-friendly platform for leveraging LLaVA's capabilities.

carrot
The 'carrot' repository on GitHub provides a list of free and user-friendly ChatGPT mirror sites for easy access. The repository includes sponsored sites offering various GPT models and services. Users can find and share sites, report errors, and access stable and recommended sites for ChatGPT usage. The repository also includes a detailed list of ChatGPT sites, their features, and accessibility options, making it a valuable resource for ChatGPT users seeking free and unlimited GPT services.

TrustLLM
TrustLLM is a comprehensive study of trustworthiness in LLMs, including principles for different dimensions of trustworthiness, established benchmark, evaluation, and analysis of trustworthiness for mainstream LLMs, and discussion of open challenges and future directions. Specifically, we first propose a set of principles for trustworthy LLMs that span eight different dimensions. Based on these principles, we further establish a benchmark across six dimensions including truthfulness, safety, fairness, robustness, privacy, and machine ethics. We then present a study evaluating 16 mainstream LLMs in TrustLLM, consisting of over 30 datasets. The document explains how to use the trustllm python package to help you assess the performance of your LLM in trustworthiness more quickly. For more details about TrustLLM, please refer to project website.

AI-YinMei
AI-YinMei is an AI virtual anchor Vtuber development tool (N card version). It supports fastgpt knowledge base chat dialogue, a complete set of solutions for LLM large language models: [fastgpt] + [one-api] + [Xinference], supports docking bilibili live broadcast barrage reply and entering live broadcast welcome speech, supports Microsoft edge-tts speech synthesis, supports Bert-VITS2 speech synthesis, supports GPT-SoVITS speech synthesis, supports expression control Vtuber Studio, supports painting stable-diffusion-webui output OBS live broadcast room, supports painting picture pornography public-NSFW-y-distinguish, supports search and image search service duckduckgo (requires magic Internet access), supports image search service Baidu image search (no magic Internet access), supports AI reply chat box [html plug-in], supports AI singing Auto-Convert-Music, supports playlist [html plug-in], supports dancing function, supports expression video playback, supports head touching action, supports gift smashing action, supports singing automatic start dancing function, chat and singing automatic cycle swing action, supports multi scene switching, background music switching, day and night automatic switching scene, supports open singing and painting, let AI automatically judge the content.