
aiavatarkit
🥰 Building AI-based conversational avatars lightning fast ⚡️💬
Stars: 538
AIAvatarKit is a tool for building AI-based conversational avatars quickly. It supports various platforms like VRChat and cluster, along with real-world devices. The tool is extensible, allowing unlimited capabilities based on user needs. It requires VOICEVOX API, Google or Azure Speech Services API keys, and Python 3.10. Users can start conversations out of the box and enjoy seamless interactions with the avatars.
README:
🥰 Building AI-based conversational avatars lightning fast ⚡️💬
![]()
-
🌏 Live anywhere: AIAvatarKit is a general-purpose Speech-to-Speech framework with multimodal input/output support. It can serve as the backend for a wide range of conversational AI systems.
- Metaverse Platforms: Compatible with VRChat, cluster, Vket Cloud, and other platforms
- Standalone Apps: Enables ultra-low latency real-time interaction via WebSocket or HTTP (SSE), with a unified interface that abstracts differences between LLMs
- Channels and Devices: Supports edge devices like Raspberry Pi and telephony services like Twilio
-
🧩 Modular architecture: Components such as VAD, STT, LLM, and TTS are modular and easy to integrate via lightweight interfaces. Supported modules include:
- VAD: Built-in standard VAD (silence-based end-of-turn detection), SileroVAD
- STT: Google, Azure, OpenAI, AmiVoice
- LLM: ChatGPT, Gemini, Claude, and any model supported by LiteLLM or Dify
- TTS: VOICEVOX / AivisSpeech, OpenAI, SpeechGateway (including Style-Bert-VITS2 and NijiVoice)
- ⚡️ AI Agent native: Designed to support agentic systems. In addition to standard tool calls, it offers Dynamic Tool Calls for extensibility and supports progress feedback for high-latency operations.
Requirements: Python 3.11+, OpenAI API key, and a running VOICEVOX instance for TTS
Install AIAvatarKit.
pip install aiavatarNOTE: If the steps in technical blogs don’t work as expected, the blog may be based on a version prior to v0.6. Some features may be limited, but you can try downgrading with pip install aiavatar==0.5.8 to match the environment described in the blog.
Make the script as run.py.
import asyncio
from aiavatar import AIAvatar
aiavatar_app = AIAvatar(
openai_api_key=OPENAI_API_KEY,
debug=True
)
asyncio.run(aiavatar_app.start_listening())Start AIAvatar. Also, don't forget to launch VOICEVOX beforehand.
$ python run.pyConversation will start when you say the wake word "こんにちは" (or "Hello" when language is not ja-JP).
Feel free to enjoy the conversation afterwards!
Install AIAvatarKit and additional dependencies.
pip install aiavatar fastapi uvicorn websocketsMake the script as ws.py.
from fastapi import FastAPI
from fastapi.staticfiles import StaticFiles
from aiavatar.adapter.websocket.server import AIAvatarWebSocketServer
from aiavatar.util import download_example
# Download example UI if not exists
download_example("websocket/html")
# Build Speech-to-Speech pipeline with WebSocket adapter
aiavatar_app = AIAvatarWebSocketServer(
openai_api_key=OPENAI_API_KEY
)
# Build websocket server
app = FastAPI()
router = aiavatar_app.get_websocket_router()
app.include_router(router)
app.mount("/static", StaticFiles(directory="html"), name="static")
# Setup admin panel (Optional)
from aiavatar.admin import setup_admin_panel
setup_admin_panel(app, adapter=aiavatar_app)Start server. Also, don't forget to launch VOICEVOX beforehand.
$ python -m uvicorn ws:appOpen following URLs and enjoy the conversation!
- Character icon (dynamic expression, lip sync, blinking): http://127.0.0.1:8000/static/index.html
- MotionPNGTuber: http://127.0.0.1:8000/static/mpt.html
You can also access the Admin Panel at http://127.0.0.1:8000/admin.
You can set model and system prompt when instantiate AIAvatar.
aiavatar_app = AIAvatar(
openai_api_key="YOUR_OPENAI_API_KEY",
openai_model="gpt-4o",
system_prompt="You are my cat."
)If you want to configure in detail, create instance of ChatGPTService with custom parameters and set it to AIAvatar.
# Create ChatGPTService
from aiavatar.sts.llm.chatgpt import ChatGPTService
llm = ChatGPTService(
openai_api_key=OPENAI_API_KEY,
model="gpt-4o",
temperature=0.0,
system_prompt="You are my cat."
)
# Create AIAvatar with ChatGPTService
aiavatar_app = AIAvatar(
llm=llm,
openai_api_key=OPENAI_API_KEY # API Key for STT
)Create instance of ClaudeService with custom parameters and set it to AIAvatar. The default model is claude-sonnet-4-5.
# Create ClaudeService
from aiavatar.sts.llm.claude import ClaudeService
llm = ClaudeService(
anthropic_api_key=ANTHROPIC_API_KEY,
model="claude-sonnet-4-5",
temperature=0.0,
system_prompt="You are my cat."
)
# Create AIAvatar with ClaudeService
aiavatar_app = AIAvatar(
llm=llm,
openai_api_key=OPENAI_API_KEY # API Key for STT
)NOTE: We support Claude on Anthropic API, not Amazon Bedrock for now. Use LiteLLM or other API Proxies.
Create instance of GeminiService with custom parameters and set it to AIAvatar. The default model is gemini-2.0-flash-exp.
# Create GeminiService
# pip install google-genai
from aiavatar.sts.llm.gemini import GeminiService
llm = GeminiService(
gemini_api_key=GEMINI_API_KEY,
model="gemini-2.0-pro-latest",
temperature=0.0,
system_prompt="You are my cat."
)
# Create AIAvatar with GeminiService
aiavatar_app = AIAvatar(
llm=llm,
openai_api_key=OPENAI_API_KEY # API Key for STT
)NOTE: We support Gemini on Google AI Studio, not Vertex AI for now. Use LiteLLM or other API Proxies.
You can use the Dify API instead of a specific LLM's API. This eliminates the need to manage code for tools or RAG locally.
# Create DifyService
from aiavatar.sts.llm.dify import DifyService
llm = DifyService(
api_key=DIFY_API_KEY,
base_url=DIFY_URL,
user="aiavatarkit_user",
is_agent_mode=True
)
# Create AIAvatar with DifyService
aiavatar_app = AIAvatar(
llm=llm,
openai_api_key=OPENAI_API_KEY # API Key for STT
)ChatGPTService supports OpenAI-compatible APIs, such as Grok, Gemini, and Claude.
By specifying the model, openai_api_key, and base_url, these models can now be used with a non-reasoning configuration out of the box.
# Grok
MODEL = "grok-4-1-fast-non-reasoning"
OPENAI_API_KEY = "YOUR_XAI_API_KEY"
BASE_URL = "https://api.x.ai/v1"
# Gemini on Google AI Studio
MODEL = "gemini-2.5-flash"
OPENAI_API_KEY = "YOUR_GEMINI_API_KEY"
BASE_URL = "https://generativelanguage.googleapis.com/v1beta/openai/"
# Claude on Anthropic
LLM_MODEL = "claude-haiku-4-5"
OPENAI_API_KEY = "YOUR_ANTHROPIC_API_KEY"
BASE_URL = "https://api.anthropic.com/v1/"
# Configure ChatGPTService
from aiavatar.sts.llm.chatgpt import ChatGPTService
llm = ChatGPTService(
openai_api_key=OPENAI_API_KEY,
base_url=BASE_URL,
model=MODEL,
system_prompt=SYSTEM_PROMPT,
# extra_body={"thinking": { "type": "disabled"}}, # Claude
)You can use other LLMs by using LiteLLMService or implementing LLMService interface.
See the details of LiteLLM here: https://github.com/BerriAI/litellm
You can set speaker id and the base url for VOICEVOX server when instantiate AIAvatar.
aiavatar_app = AIAvatar(
openai_api_key="YOUR_OPENAI_API_KEY",
# 46 is Sayo. See http://127.0.0.1:50021/speakers to get all ids for characters
voicevox_speaker=46
)If you want to configure in detail, create instance of VoicevoxSpeechSynthesizer with custom parameters and set it to AIAvatar.
Here is the example for AivisSpeech.
# Create VoicevoxSpeechSynthesizer with AivisSpeech configurations
from aiavatar.sts.tts.voicevox import VoicevoxSpeechSynthesizer
tts = VoicevoxSpeechSynthesizer(
base_url="http://127.0.0.1:10101", # Your AivisSpeech API server
speaker="888753761" # Anneli
)
# Create AIAvatar with VoicevoxSpeechSynthesizer
aiavatar_app = AIAvatar(
tts=tts,
openai_api_key=OPENAI_API_KEY # API Key for LLM and STT
)You can also set speech controller that uses alternative Text-to-Speech services. We support Azure, Google, OpenAI and any other TTS services supported by SpeechGateway such as Style-Bert-VITS2 and NijiVoice.
from aiavatar.sts.tts.azure import AzureSpeechSynthesizer
from aiavatar.sts.tts.google import GoogleSpeechSynthesizer
from aiavatar.sts.tts.openai import OpenAISpeechSynthesizer
from aiavatar.sts.tts.speech_gateway import SpeechGatewaySpeechSynthesizerFor quick setup of custom TTS services with HTTP API endpoints, use create_instant_synthesizer. This allows you to create a TTS synthesizer with just HTTP request parameters.
Examples:
from aiavatar.sts.tts import create_instant_synthesizer
# Style-Bert-VITS2 API
sbv2_tts = create_instant_synthesizer(
method="POST",
url="http://127.0.0.1:5000/voice",
json={
"model_id": "0",
"speaker_id": "0",
"text": "{text}" # Placeholder for processed text
}
)
# ElevenLabs
elevenlabs_tts = create_instant_synthesizer(
method="POST",
url=f"https://api.elevenlabs.io/v1/text-to-speech/{voice_id}",
headers={
"xi-api-key": ELEVENLABS_API_KEY
},
json={
"text": "{text}",
"model_id": "eleven_v3",
"output_format": "pcm_16000"
}
)
# Aivis Cloud API
from aiavatar.sts.tts import AudioConverter
aivis_tts = create_instant_synthesizer(
method="POST",
url="https://api.aivis-project.com/v1/tts/synthesize",
headers={
"Content-Type": "application/json",
"Authorization": f"Bearer {AIVIS_API_KEY}"
},
json={
"model_uuid": "22e8ed77-94fe-4ef2-871f-a86f94e9a579", # Kohaku
"text": "{text}"
},
response_parser=AudioConverter(debug=True).convert
)
# Kotodama API (Implement `make_request` to apply style or language.)
import base64
async def base64_to_bytes(http_response) -> bytes:
response_json = http_response.json()
b64audio = response_json["audios"][0]
return base64.b64decode(b64audio)
kotodama_tts = create_instant_synthesizer(
method="POST",
url=f"https://tts3.spiral-ai-app.com/api/tts_generate",
headers={
"Content-Type": "application/json",
"X-API-Key": KOTODAMA_API_KEY
},
json={
"text": "{text}",
"speaker_id": "Marlo",
"decoration_id": "neutral",
"audio_format": "wav"
},
response_parser=base64_to_bytes
)
# Coefont
import hmac
import hashlib
def make_coefont_request(text: str, style_info: dict, language: str):
date = str(int(datetime.now(tz=timezone.utc).timestamp()))
data = json.dumps({
"coefont": "33e0a2ff-5050-434c-9506-defe97e52f15", # Yuko Goto
"text": text
})
signature = hmac.new(
key=bytes(COEFONT_ACCESS_SECRET, "utf-8"),
msg=(date+data).encode("utf-8"),
digestmod=hashlib.sha256
).hexdigest()
return httpx.Request(
method="post",
url="https://api.coefont.cloud/v2/text2speech",
headers={
"Content-Type": "application/json",
"Authorization": COEFONT_ACCESS_KEY,
"X-Coefont-Date": date,
"X-Coefont-Content": signature
},
data=data
)
tts = create_instant_synthesizer(
request_maker=make_coefont_request,
follow_redirects=True
)The {text} and {language} placeholders in params, headers, and json will be automatically replaced with the processed text and language values during synthesis.
You can also make custom tts components by impelemting SpeechSynthesizer interface.
AIAvatarKit provides text preprocessing functionality that transforms text before Text-to-Speech processing. This enables improved speech quality and conversion of specific text patterns.
A preprocessor that converts alphabet text to katakana using LLM. Supports kana_map for storing word-to-reading mappings to reduce latency on repeated words.
from aiavatar.sts.tts.preprocessor.alphabet2kana import AlphabetToKanaPreprocessor
# Create preprocessor with kana_map for pre-registered word-reading mappings
alphabet2kana_preproc = AlphabetToKanaPreprocessor(
openai_api_key=OPENAI_API_KEY,
model="gpt-4o-mini", # Model to use (default: gpt-4.1-mini)
alphabet_length=3, # Minimum alphabet length to convert (default: 3)
special_chars=".'-'−–", # Characters that connect words (default: ".'-'−–")
use_kana_map=True, # Enable kana_map mode (default: True)
kana_map={"GitHub": "ギットハブ"}, # Pre-registered word-reading mappings (optional)
debug=True, # Enable debug logging (default: False)
)
# Add to TTS
tts.preprocessors.append(alphabet2kana_preproc)
# Words converted by LLM are automatically added to kana_map
# You can persist and restore kana_map for future sessions:
import json
# Save
with open("kana_map.json", "w") as f:
json.dump(alphabet2kana_preproc.kana_map, f, ensure_ascii=False)
# Load
with open("kana_map.json") as f:
kana_map = json.load(f)Key features:
- kana_map: Pre-register known word-reading mappings and automatically add LLM results to avoid repeated API calls
-
special_chars: Words containing these characters (e.g.,
Mr.,You're,Wi-Fi) are always processed regardless ofalphabet_length -
Case-insensitive: Matches
API,api, andApiwith a single kana_map entry -
debug mode: Logs
[KanaMap]for cached hits and[LLM]for new readings with elapsed time
You can also use regular expressions and string patterns for conversion:
from aiavatar.sts.tts.preprocessor.patternmatch import PatternMatchPreprocessor
# Create pattern match preprocessor
pattern_preproc = PatternMatchPreprocessor(patterns=[
("API", "エーピーアイ"), # Fixed string replacement
("URL", "ユーアールエル"),
(r"\d+", lambda m: "number"), # Regex replacement with function
])
# Add common patterns
pattern_preproc.add_number_dash_pattern() # Number-dash patterns (e.g., 12-34 → イチニの サンヨン)
pattern_preproc.add_phonenumber_pattern() # Phone number patterns
# Add to TTS
tts.preprocessors.append(pattern_preproc)You can create your own preprocessors by implementing the TTSPreprocessor interface:
from aiavatar.sts.tts.preprocessor import TTSPreprocessor
class CustomPreprocessor(TTSPreprocessor):
def __init__(self, custom_dict: dict = None):
self.custom_dict = custom_dict or {}
async def process(self, text: str, style_info: dict = None, language: str = None) -> str:
# Custom conversion logic
processed_text = text
# Dictionary-based replacement
for original, replacement in self.custom_dict.items():
processed_text = processed_text.replace(original, replacement)
# Language-specific conversions
if language == "ja-JP":
processed_text = processed_text.replace("OK", "オーケー")
return processed_text
# Use custom preprocessor
custom_preproc = CustomPreprocessor(custom_dict={
"GitHub": "ギットハブ",
"Python": "パイソン",
"Docker": "ドッカー"
})
tts.preprocessors.append(custom_preproc)Multiple preprocessors can be used together. They are executed in the order they were registered:
# Combine multiple preprocessors
tts.preprocessors.extend([
pattern_preproc, # 1. Pattern match conversion
alphabet2kana_preproc, # 2. Alphabet to katakana conversion
custom_preproc # 3. Custom conversion
])With SpeechGatewaySpeechSynthesizer, you can change the speech speed per session by setting the speed either on the entire instance or in style_info.
Here is an example of storing the speech speed as tts_speed in session data when using WebSocketAdapter.
# Apply speech speed per session
from aiavatar.sts.llm import LLMResponse
@aiavatar_app.sts.process_llm_chunk
async def process_llm_chunk(llm_stream_chunk: LLMResponse, session_id: str, user_id: str) -> dict:
if session_data := aiavatar_app.sessions.get(session_id):
if speed := session_data.data.get("tts_speed"):
return {"speed": float(speed)}NOTE: To configure tts_speed, you can either set up a REST API endpoint to update it directly, or use control tags included in responses to update it.
If you want to configure in detail, create instance of SpeechRecognizer with custom parameters and set it to AIAvatar. We support Azure, Google and OpenAI Speech-to-Text services.
NOTE: AzureSpeechRecognizer is much faster than Google and OpenAI(default).
# Create AzureSpeechRecognizer
from aiavatar.sts.stt.azure import AzureSpeechRecognizer
stt = AzureSpeechRecognizer(
azure_api_key=AZURE_API_KEY,
azure_region=AZURE_REGION
)
# Create AIAvatar with AzureSpeechRecognizer
aiavatar_app = AIAvatar(
stt=stt,
openai_api_key=OPENAI_API_KEY # API Key for LLM
)You can also make custom STT components by implementing SpeechRecognizer interface.
You can add custom preprocessing and postprocessing to any SpeechRecognizer implementation. This is useful for tasks like speaker verification, audio filtering, or text normalization.
from aiavatar.sts.stt.openai import OpenAISpeechRecognizer
# Create recognizer
recognizer = OpenAISpeechRecognizer(openai_api_key="your-api-key")
# Add preprocessing - e.g., speaker verification
@recognizer.preprocess
async def verify_speaker(session_id: str, audio_data: bytes):
# Perform speaker verification
is_valid_speaker = await check_speaker_identity(audio_data)
if not is_valid_speaker:
# Return empty bytes to skip transcription
return b"", {"rejected": True, "reason": "speaker_mismatch"}
# Return processed audio and metadata
filtered_audio = apply_noise_filter(audio_data)
return filtered_audio, {"speaker_verified": True, "session_id": session_id}
# Add postprocessing - e.g., text formatting
@recognizer.postprocess
async def format_text(session_id: str, text: str, audio_data: bytes, preprocess_metadata: dict):
# Format transcribed text
formatted_text = text.strip().capitalize()
# Add punctuation if missing
if formatted_text and formatted_text[-1] not in '.!?':
formatted_text += '.'
# Return formatted text and metadata
return formatted_text, {
"original_text": text,
"formatting_applied": True,
"preprocess_info": preprocess_metadata
}
# Use the recognizer with preprocessing and postprocessing
result = await recognizer.recognize(
session_id="user-123",
data=audio_bytes
)
print(f"Text: {result.text}")
print(f"Preprocess metadata: {result.preprocess_metadata}")
print(f"Postprocess metadata: {result.postprocess_metadata}")The preprocessing and postprocessing functions can return either:
- Just the processed data (bytes for preprocess, string for postprocess)
- A tuple of (processed_data, metadata_dict) for additional information
If preprocessing returns empty bytes, the transcription is skipped and the result will have text=None.
AIAvatarKit provides speaker diarization functionality to suppress responses to voices other than the main speaker. This prevents interruptions from surrounding conversations or venue announcements at events.
The MainSpeakerGate provides the following features:
- Calculates voice embeddings from request audio
- Registers a voice as the main speaker when similarity exceeds threshold for 2 consecutive requests (per session)
- Returns
accepted=Truewhen request audio similarity exceeds threshold after main speaker registration - Returns
accepted=Truewhen no main speaker is registered yet
NOTE: While mechanically ignoring non-main speaker voices (Example 1) is simplest, it risks stopping conversation due to misidentification and cannot handle speaker changes. Consider context-aware handling (Example 2) as well.
from aiavatar.sts.stt.speaker_gate import MainSpeakerGate
speaker_gate = MainSpeakerGate()
# Example 1: Drop request when the voice is not from main speaker
@aiavatar_app.sts.stt.preprocess
async def stt_preprocess(session_id: str, audio_bytes: bytes):
# Compare with main speaker's voice embedding
gate_response = await speaker_gate.evaluate(session_id, audio_bytes, aiavatar_app.sts.vad.sample_rate)
# Branch processing based on similarity with main speaker's voice
if not gate_response.accepted:
logger.info(f"Ignore other speaker's voice: confidence={gate_response.confidence}")
return None, gate_response.to_dict()
else:
return audio_bytes, gate_response.to_dict()
# Example 2: Add annotation for LLM that the voice is not from main speaker
@aiavatar_app.sts.stt.postprocess
async def stt_postprocess(session_id: str, text: str, audio_bytes: bytes, preprocess_metadata: dict):
# Compare with main speaker's voice embedding
gate_response = await speaker_gate.evaluate(session_id, audio_bytes, aiavatar_app.sts.vad.sample_rate)
# Branch processing based on similarity with main speaker's voice
if not gate_response.accepted:
logger.info(f"Adding note that this may be from a different speaker: confidence={gate_response.confidence}")
return f"$The following request may not be from the main speaker (similarity: {gate_response.confidence}). Determine from the content whether to respond. If you should not respond, output just[wait:user] as the answer:\n\n{text}", gate_response.to_dict()
else:
return text, gate_response.to_dict()AIAvatarKit includes Voice Activity Detection (VAD) components to automatically detect when speech starts and ends in audio streams. This enables seamless conversation flow without manual input controls.
The default Speech Detector is SileroSpeechDetector, which employs AI-based voice activity detection using the Silero VAD model:
from aiavatar.sts.vad.silero import SileroSpeechDetector
vad = SileroSpeechDetector(
speech_probability_threshold=0.5, # AI model confidence threshold (0.0-1.0)
silence_duration_threshold=0.5, # Seconds of silence to end recording
volume_db_threshold=None, # Optional: filter by volume in dB (e.g., -30.0)
max_duration=10.0, # Maximum recording duration
min_duration=0.2, # Minimum recording duration
sample_rate=16000, # Audio sample rate
channels=1, # Audio channels
chunk_size=512, # Audio processing chunk size
model_pool_size=1, # Number of parallel AI models
debug=True
)
aiavatar_app = AIAvatar(vad=vad, openai_api_key=OPENAI_API_KEY)For high-concurrency applications:
vad = SileroSpeechDetector(
speech_probability_threshold=0.6, # Stricter threshold for noisy environments
model_pool_size=4, # 4 parallel AI models for load balancing
debug=False
)SileroStreamSpeechDetector extends SileroSpeechDetector with segment-based speech recognition. It performs partial transcription during recording, allowing you to receive intermediate results before the final transcription.
from aiavatar.sts.vad.stream import SileroStreamSpeechDetector
from aiavatar.sts.stt.google import GoogleSpeechRecognizer
vad = SileroStreamSpeechDetector(
speech_recognizer=GoogleSpeechRecognizer(...),
segment_silence_threshold=0.2, # Silence duration to trigger segment recognition
silence_duration_threshold=0.5, # Silence duration to finalize recording
# Inherits all SileroSpeechDetector parameters
)The on_speech_detecting callback is triggered when a speech segment is recognized:
@vad.on_speech_detecting
async def on_speech_detecting(text, session):
print(f"Partial text: {text}")
# For WebSocket apps, send partial text to client via info message
# resp = STSResponse(
# type="info",
# session_id=session.session_id,
# metadata={"partial_request_text": text}
# )
# await ws_app.handle_response(resp)Use validate_recognized_text to filter out invalid recognition results:
@vad.validate_recognized_text
def validate(text):
if len(text) < 2:
return "Text too short" # Return error message to reject
return None # Return None to acceptAzureStreamSpeechDetector uses Azure's streaming speech recognition service for both speech detection and transcription. Audio is continuously streamed to Azure, and speech boundaries are determined by Azure's recognition events.
pip install azure-cognitiveservices-speechfrom aiavatar.sts.vad.azure_stream import AzureStreamSpeechDetector
vad = AzureStreamSpeechDetector(
azure_subscription_key=AZURE_API_KEY,
azure_region=AZURE_REGION
)This detector also supports the on_speech_detecting callback for partial transcription results:
@vad.on_speech_detecting
async def on_speech_detecting(text, session):
print(f"Partial text: {text}")
# For WebSocket apps, send partial text to client via info message
# resp = STSResponse(
# type="info",
# session_id=session.session_id,
# metadata={"partial_request_text": text}
# )
# await ws_app.handle_response(resp)The on_recording_started callback is triggered when recording has been active long enough to be considered meaningful speech. This is useful for stopping AI speech when the user starts talking.
# Option 1: Pass callback in constructor
async def my_recording_started_handler(session_id: str):
print(f"Recording started for session: {session_id}")
await stop_ai_speech()
vad = SileroSpeechDetector(
on_recording_started=my_recording_started_handler,
on_recording_started_min_duration=1.5, # Trigger after 1.5 sec of speech (default)
# other parameters...
)
# Option 2: Use decorator
@vad.on_recording_started
async def on_recording_started(session_id):
await stop_ai_speech()For stream-based detectors (SileroStreamSpeechDetector, AzureStreamSpeechDetector), the callback can also be triggered by recognized text length:
vad = SileroStreamSpeechDetector(
speech_recognizer=speech_recognizer,
on_recording_started_min_duration=1.5, # Trigger after 1.5 sec of speech
on_recording_started_min_text_length=2, # OR trigger when text >= 2 chars
)You can customize when on_recording_started fires using the should_trigger_recording_started decorator:
@vad.should_trigger_recording_started
def custom_trigger(text, session):
# text: Recognized text (None for non-stream detectors)
# session: Recording session object
# Return True to trigger the callback
return text and len(text) >= 5StandardSpeechDetector uses simple volume-based detection. Consider using SileroSpeechDetector for better accuracy. This detector is suitable for environments with limited computing resources:
from aiavatar.sts.vad.standard import StandardSpeechDetector
vad = StandardSpeechDetector(
volume_db_threshold=-30.0, # Voice detection threshold in dB
silence_duration_threshold=0.5, # Seconds of silence to end recording
max_duration=10.0, # Maximum recording duration
min_duration=0.2, # Minimum recording duration
sample_rate=16000, # Audio sample rate
channels=1, # Audio channels
preroll_buffer_count=5, # Pre-recording buffer size
debug=True
)To control facial expressions within conversations, set the facial expression names and values in FaceController.faces as shown below, and then include these expression keys in the response message by adding instructions to the prompt.
aiavatar_app.face_controller.faces = {
"neutral": "🙂",
"joy": "😀",
"angry": "😠",
"sorrow": "😞",
"fun": "🥳"
}
aiavatar_app.sts.llm.system_prompt = """# Face Expression
* You have the following expressions:
- joy
- angry
- sorrow
- fun
* If you want to express a particular emotion, please insert it at the beginning of the sentence like [face:joy].
Example
[face:joy]Hey, you can see the ocean! [face:fun]Let's go swimming.
"""This allows emojis like 🥳 to be autonomously displayed in the terminal during conversations. To actually control the avatar's facial expressions in a metaverse platform, instead of displaying emojis like 🥳, you will need to use custom implementations tailored to the integration mechanisms of each platform. Please refer to our VRChatFaceController as an example.
Now writing... ✍️
CharacterService provides functionality for managing AI character settings and generating dynamic content such as schedules and diaries based on character personalities.
Schedules and diaries are generated as if by the character's own will. By updating these daily and incorporating them into prompts, you can make the character feel like they are actually living in real-world time.
Note: This feature requires PostgreSQL as the database backend.
Register a new character using a character setting prompt. At this time, both the weekly schedule and today's schedule are also generated.
from datetime import date
from aiavatar.character import CharacterService
# Initialize service
character_service = CharacterService(
openai_api_key="YOUR_API_KEY"
)
# Initialize a new character with weekly and daily schedules
character, weekly, daily = await character_service.initialize_character(
name="Alice",
character_prompt="You are Alice, a cheerful high school student who loves reading..."
)
print(f"Character ID: {character.id}")To use the registered and generated content as a system prompt, implement LLMService.get_system_prompt as follows:
@llm.get_system_prompt
async def get_system_prompt(context_id: str, user_id: str, system_prompt_params: dict):
return await character_service.get_system_prompt(
character_id="YOUR_CHARACTER_ID",
system_prompt_params=system_prompt_params
)This system prompt includes not only the character settings from character_prompt, but also the schedule for the day.
Diaries can be automatically generated using create_diary_with_generation. The following information is used:
- Character settings
- Today's schedule
- Today's news (retrieved via web search)
- Previous day's diary
# Generate diary from daily activities
diary = await character_service.create_diary_with_generation(
character_id=character.id,
diary_date=date.today()
)The generated diary can be used as context for the LLM using GetDiaryTool. By setting include_schedule=True, the schedule information for the day is also retrieved (default is True).
from aiavatar.character.tools import GetDiaryTool
llm.add_tool(
GetDiaryTool(
character_service=character_service,
character_id=YOUR_CHARACTER_ID,
include_schedule=True
)
)Daily schedules can be automatically generated using create_daily_schedule_with_generation. The following information is used:
- Character settings
- Weekly schedule
- Previous day's schedule
daily_schedule = await character_service.create_daily_schedule_with_generation(
character_id=character.id,
schedule_date=date.today()
)For a more realistic character experience, use a scheduler service (such as cron) to automatically update schedules and diaries:
- Daily schedule: Generate at the beginning of each day (e.g., 0:00 or 6:00)
- Diary: Generate at the end of each day (e.g., 23:00)
Example cron configuration:
# Generate daily schedule at 6:00 AM
0 6 * * * /usr/bin/python3 /path/to/generate_schedule.py
# Generate diary at 11:00 PM
0 23 * * * /usr/bin/python3 /path/to/generate_diary.py
Example script for generate_schedule.py:
import asyncio
from datetime import date
from aiavatar.character import CharacterService
async def main():
character_service = CharacterService(
openai_api_key="YOUR_API_KEY"
)
await character_service.create_daily_schedule_with_generation(
character_id="YOUR_CHARACTER_ID",
schedule_date=date.today()
)
asyncio.run(main())You can batch generate daily schedules and diaries for a date range using create_activity_range_with_generation.
await character_service.create_activity_range_with_generation(
character_id=YOUR_CHARACTER_ID,
start_date=date(2026, 1, 8),
end_date=date(2026, 1, 16), # Defaults to today if omitted
overwrite=False,
)This is useful for recovering data when automatic updates were stopped, or for building up initial data when creating a new character.
This feature is optional. If you want to make diaries searchable as long-term memory, you can integrate with an external memory service by configuring MemoryClient:
from aiavatar.character import CharacterService, MemoryClient
memory_client = MemoryClient(base_url="http://memory-service:8000")
character_service = CharacterService(
openai_api_key="YOUR_API_KEY",
memory_client=memory_client
)Registered diaries can be included in search results using the search method.
# In addition to diaries, conversation history with users and other knowledge are searched comprehensively
result = await character_service.memory.search(
character_id="YOUR_CHARACTER_ID",
user_id="YOUR_USER_ID",
query="travel summer 2026"
)The default MemoryClient uses ChatMemory as its backend, but you can also use other long-term memory services by inheriting from MemoryClientBase.
The bind_character function provides a convenient way to integrate character management with your AIAvatar application. It automatically configures the system prompt, user management, and character-related tools in a single call.
from aiavatar.character import CharacterService
from aiavatar.character.binding import bind_character
character_service = CharacterService(
openai_api_key="YOUR_API_KEY"
)
bind_character(
adapter=aiavatar_app,
character_service=character_service,
character_id="YOUR_CHARACTER_ID",
default_user_name="You"
)This single function call sets up:
- System prompt: Automatically retrieves the character's system prompt with user-specific parameters
-
User management: Creates a new user with
default_user_nameif the user doesn't exist - Username sync: Sends the username and character name to the client on connection, and updates when changed
-
Tools: Registers the following tools automatically:
-
UpdateUsernameTool: Allows the character to update the user's name during conversation -
GetDiaryTool: Retrieves the character's diary and schedule -
MemorySearchTool: Searches long-term memory (only ifmemory_clientis configured)
-
You can host AIAvatarKit on a server to enable multiple clients to have independent context-aware conversations via RESTful API with streaming responses (Server-Sent Events) and WebSocket.
Below is the simplest example of a server program:
from fastapi import FastAPI
from aiavatar.adapter.http.server import AIAvatarHttpServer
# AIAvatar
aiavatar_app = AIAvatarHttpServer(
openai_api_key=OPENAI_API_KEY,
debug=True
)
# Setup FastAPI app with AIAvatar components
app = FastAPI()
router = aiavatar_app.get_api_router()
app.include_router(router)Save the above code as server.py and run it using:
uvicorn server:appNext is the simplest example of a client program:
import asyncio
from aiavatar.adapter.http.client import AIAvatarHttpClient
aiavatar_app = AIAvatarHttpClient(
debug=True
)
asyncio.run(aiavatar_app.start_listening(session_id="http_session", user_id="http_user"))Save the above code as client.py and run it using:
python client.pyYou can now perform voice interactions just like when running locally.
When using the streaming API via HTTP, clients communicate with the server using JSON-formatted requests.
Below is the format for initiating a session:
{
"type": "start", // Always `start`
"session_id": "6d8ba9ac-a515-49be-8bf4-cdef021a169d",
"user_id": "user_id",
"context_id": "c37ac363-5c65-4832-aa25-fd3bbbc1b1e7", // Set null or provided id in `start` response
"text": "こんにちは", // If set, audio_data will be ignored
"audio_data": "XXXX", // Base64 encoded audio data
"files": [
{
"type": "image", // Only `image` is supported for now
"url": "https://xxx",
}
],
"metadata": {}
}The server returns responses as a stream of JSON objects in the following structure.
The communication flow typically consists of:
{
"type": "chunk", // start -> chunk -> final
"session_id": "6d8ba9ac-a515-49be-8bf4-cdef021a169d",
"user_id": "user01",
"context_id": "c37ac363-5c65-4832-aa25-fd3bbbc1b1e7",
"text": "[face:joy]こんにちは!", // Response text with info
"voice_text": "こんにちは!", // Response text for voice synthesis
"avatar_control_request": {
"animation_name": null, // Parsed animation name
"animation_duration": null, // Parsed duration for animation
"face_name": "joy", // Parsed facial expression name
"face_duration": 4.0 // Parsed duration for the facial expression
},
"audio_data": "XXXX", // Base64 encoded. Playback this as the character's voice.
"metadata": {
"is_first_chunk": true
}
}You can test the streaming API using a simple curl command:
curl -N -X POST http://127.0.0.1:8000/chat \
-H "Content-Type: application/json" \
-d '{
"type": "start",
"session_id": "6d8ba9ac-a515-49be-8bf4-cdef021a169d",
"user_id": "user01",
"text": "こんにちは"
}'
Sample response (streamed from the server):
data: {"type": "start", "session_id": "6d8ba9ac-a515-49be-8bf4-cdef021a169d", "user_id": "user01", "context_id": "c37ac363-5c65-4832-aa25-fd3bbbc1b1e7", "text": null, "voice_text": null, "avatar_control_request": null, "audio_data": "XXXX", "metadata": {"request_text": "こんにちは"}}
data: {"type": "chunk", "session_id": "6d8ba9ac-a515-49be-8bf4-cdef021a169d", "user_id": "user01", "context_id": "c37ac363-5c65-4832-aa25-fd3bbbc1b1e7", "text": "[face:joy]こんにちは!", "voice_text": "こんにちは!", "avatar_control_request": {"animation_name": null, "animation_duration": null, "face_name": "joy", "face_duration": 4.0}, "audio_data": "XXXX", "metadata": {"is_first_chunk": true}}
data: {"type": "chunk", "session_id": "6d8ba9ac-a515-49be-8bf4-cdef021a169d", "user_id": "user01", "context_id": "c37ac363-5c65-4832-aa25-fd3bbbc1b1e7", "text": "今日はどんなことをお手伝いしましょうか?", "voice_text": "今日はどんなことをお手伝いしましょうか?", "avatar_control_request": {"animation_name": null, "animation_duration": null, "face_name": null, "face_duration": null}, "audio_data": "XXXX", "metadata": {"is_first_chunk": false}}
data: {"type": "final", "session_id": "6d8ba9ac-a515-49be-8bf4-cdef021a169d", "user_id": "user01", "context_id": "c37ac363-5c65-4832-aa25-fd3bbbc1b1e7", "text": "[face:joy]こんにちは!今日はどんなことをお手伝いしましょうか?", "voice_text": "こんにちは!今日はどんなことをお手伝いしましょうか?", "avatar_control_request": null, "audio_data": "XXXX", "metadata": {}}To continue the conversation, include the context_id provided in the start response in your next request.
NOTE: When using the RESTful API, voice activity detection (VAD) must be performed client-side.
NOTE: To protect API with API Key, set api_key=API_KEY_YOU_MAKE to AIAvatarHttpServer and send Authorization: Bearer {API_KEY_YOU_MAKE} as HTTP header from client.
AIAvatarHttpServer provides a Dify-compatible /chat-messages endpoint (SSE streaming only).
This allows you to connect frontend applications that use Dify as their backend.
For more details, refer to the Dify API Guide or the API documentation of your self-hosted Dify application.
Below is the simplest example of a server program:
from fastapi import FastAPI
from aiavatar.adapter.websocket.server import AIAvatarWebSocketServer
# Create AIAvatar
aiavatar_app = AIAvatarWebSocketServer(
openai_api_key=OPENAI_API_KEY,
volume_db_threshold=-30, # <- Adjust for your audio env
debug=True
)
# Set router to FastAPI app
app = FastAPI()
router = aiavatar_app.get_websocket_router()
app.include_router(router)Save the above code as server.py and run it using:
uvicorn server:appNOTE: When you specify response_audio_chunk_size in the AIAvatarWebSocketServer instance, the audio response will be streamed as PCM data chunks of the specified byte size. In this case, no WAVE header will be included in the response - you'll receive raw PCM audio data only.
Next is the simplest example of a client program:
import asyncio
from aiavatar.adapter.websocket.client import AIAvatarWebSocketClient
client = AIAvatarWebSocketClient()
asyncio.run(client.start_listening(session_id="ws_session", user_id="ws_user"))Save the above code as client.py and run it using:
python client.pyYou can now perform voice interactions just like when running locally.
NOTE: When using the WebSocket API, voice activity detection (VAD) is performed on the server side, so clients can simply stream microphone input directly to the server.
You can register callbacks to handle WebSocket connection and disconnection events. This is useful for logging, session management, or custom initialization/cleanup logic.
@aiavatar_app.on_connect
async def on_connect(request, session_data):
print(f"Client connected: {session_data.id}")
print(f"User ID: {session_data.user_id}")
print(f"Session ID: {session_data.session_id}")
# Custom initialization logic
# e.g., load user preferences, initialize resources, etc.
@aiavatar_app.on_disconnect
async def on_disconnect(session_data):
print(f"Client disconnected: {session_data.id}")
# Custom cleanup logic
# e.g., save session data, release resources, etc.The session_data object contains information about the WebSocket session:
-
id: Unique session identifier -
user_id: User identifier from the connection request -
session_id: Session identifier from the connection request - Additional metadata passed during connection
You can build a LINE Bot using the LINE Messaging API.
# NOTE: Register https://{your.domain}/webhook as the "Webhook URL" in LINE Developers Console
# Create LINE Bot adapter
from aiavatar.adapter.linebot.server import AIAvatarLineBotServer
aiavatar_app = AIAvatarLineBotServer(
openai_model="gpt-5.1",
system_prompt="You are a cat.",
openai_api_key=OPENAI_API_KEY,
channel_access_token=LINEBOT_CHANNEL_ACCESS_TOKEN,
channel_secret=LINEBOT_CHANNEL_SECRET,
image_download_url_base="https://{your.domain}",
debug=True
)
# Create FastAPI app
from fastapi import FastAPI
app = FastAPI()
# Set adapter endpoints
router = aiavatar_app.get_api_router()
app.include_router(router)By default, the LINE Messaging API user ID is used as the AIAvatarKit user ID. If you want to map it to your own AIAvatarKit user IDs, implement edit_linebot_session as shown below to update the session data.
from aiavatar.adapter.linebot import LineBotSession
@aiavatar_app.edit_linebot_session
async def edit_linebot_session(linebot_session: LineBotSession):
# Get user_id by LINE Bot user id
aiavatar_user_id = map_user_id(linebot_session.linebot_user_id)
# Set user_id to LINE Bot session
linebot_session.user_id = aiavatar_user_idOther customization hooks are below.
@aiavatar_app.preprocess_request
async def preprocess_request(request: STSRequest):
# Pre-process request before sending to LLM
# e.g. edit request text
request.text = "Pre-processed: " + request.text
@aiavatar_app.preprocess_response
async def preprocess_response(response: STSResponse):
# Pre-process response before sending to LINE API
# e.g. edit response voice_text (not text)
response.voice_text = "Pre-processed: " + response.voice_text
@aiavatar_app.process_avatar_control_request
async def process_avatar_control_request(avatar_control_request: AvatarControlRequest, reply_message_request: ReplyMessageRequest):
# Process facial expression
# e.g. set `sender` to the message in reply_message_request to change icon
face = avatar_control_request.face_name
if face:
reply_message_request.messages[0].sender = Sender(iconUrl=f"https://your_domain/path/to/icon/{face}.png")
@aiavatar_app.on_send_error_message
async def on_send_error_message(reply_message_request: ReplyMessageRequest, linebot_session: LineBotSession, event: Event, ex: Exception):
# Pre-process error message
# e.g. edit error response
text = make_user_friendly_error_message(event, ex)
reply_message_request.messages[0] = TextMessage(text=text)
@aiavatar_app.event("postback")
async def handle_postback_event(event: Event, linebot_session: LineBotSession):
# Process event
# e.g. Register postback data
await register_data(linebot_session.user_id, event.postback.data)Session data is stored in aiavatar.db via SQLite by default. To use PostgreSQL, create a PostgreSQLLineBotSessionManager and pass it to AIAvatarLineBotServer as session_manager.
# Create PostgreSQLLineBotSessionManager
from aiavatar.adapter.linebot.session_manager.postgres import PostgreSQLLineBotSessionManager
linebot_session_manager = PostgreSQLLineBotSessionManager(
host=DB_HOST,
port=DB_PORT,
dbname=DB_NAME,
user=DB_USER,
password=DB_PASSWORD
)
aiavatar_app = AIAvatarLineBotServer(
openai_model="gpt-5.1",
system_prompt="You are a cat.",
openai_api_key=OPENAI_API_KEY,
channel_access_token=LINEBOT_CHANNEL_ACCESS_TOKEN,
channel_secret=LINEBOT_CHANNEL_SECRET,
image_download_url_base="https://{your.domain}",
session_manager=linebot_session_manager, # <- Set PostgresSQL session manager
debug=True
)AIAvatarHttpServer provides REST API endpoints for Speech-to-Text (STT) and Text-to-Speech (TTS) functionality:
POST /stt - Converts audio to text.
import requests
# Read audio file
with open("audio.wav", "rb") as f:
audio_data = f.read()
# Send to STT endpoint
response = requests.post(
"http://localhost:8000/stt",
data=audio_data,
headers={"Content-Type": "audio/wav"}
)
print(response.json()) # {"text": "recognized speech"}POST /tts - Converts text to speech.
import requests
# Send text to TTS endpoint
response = requests.post(
"http://localhost:8000/tts",
json={"text": "Hello, this is AI Avatar speaking"}
)
# Save audio response
with open("output.wav", "wb") as f:
f.write(response.content)You can apply guardrails to both requests and responses. Guardrails are custom implementations created by developers, and can block or replace an incoming request, or replace an outgoing response when certain conditions are met.
Below is the implementation method and how to apply guardrails.
from aiavatar.sts.llm import Guardrail, GuardrailRespose
# Define guardrails
class RequestGuardrail(Guardrail):
async def apply(self, context_id, user_id, text, files = None, system_prompt_params = None):
if text.lower() == "problematic input":
return GuardrailRespose(
guardrail_name=self.name,
is_triggered=True,
action="block",
text="The problematic input has been blocked." # Immediately returns this message to the user
)
elif text.lower() == "hello":
return GuardrailRespose(
guardrail_name=self.name,
is_triggered=True,
action="replace",
text="こんにちは" # Replaces the original request text with this value
)
else:
return GuardrailRespose(
guardrail_name=self.name,
is_triggered=False
)
class ResponseGuardrail(Guardrail):
async def apply(self, context_id, user_id, text, files = None, system_prompt_params = None):
if "ramen" in text.lower():
return GuardrailRespose(
guardrail_name=self.name,
is_triggered=True,
action="replace",
text="The problematic output has been blocked." # Emits an additional replacement chunk for the response
)
else:
return GuardrailRespose(
guardrail_name=self.name,
is_triggered=False
)
# Apply guardrails
service.guardrails.append(RequestGuardrail(applies_to="request"))
service.guardrails.append(ResponseGuardrail(applies_to="response"))NOTE: When multiple guardrails are defined, they run in parallel.
Processing stops when all guardrails have finished evaluating or when the first guardrail returns a response with is_triggered=True.
NOTE: Response guardrails are evaluated only after the LLM response stream finishes.
This means the problematic output may be briefly visible to the user.
When a response is received with metadata.is_guardrail_triggered = true, the client should handle this by replacing or modifying the output accordingly.
AIAvatarKit is capable of operating on any platform that allows applications to hook into audio input and output. The platforms that have been tested include:
- VRChat
- cluster
- Vket Cloud
In addition to running on PCs to operate AI avatars on these platforms, you can also create a communication robot by connecting speakers, a microphone, and, if possible, a display to a Raspberry Pi.
- 2 Virtual audio devices (e.g. VB-CABLE) are required.
- Multiple VRChat accounts are required to chat with your AIAvatar.
First, run the commands below in python interpreter to check the audio devices.
$ python
>>> from aiavatar import AudioDevice
>>> AudioDevice().list_audio_devices()
0: Headset Microphone (Oculus Virt
:
6: CABLE-B Output (VB-Audio Cable
7: Microsoft サウンド マッパー - Output
8: SONY TV (NVIDIA High Definition
:
13: CABLE-A Input (VB-Audio Cable A
:In this example,
- To use
VB-Cable-Afor microphone for VRChat, index foroutput_deviceis13(CABLE-A Input). - To use
VB-Cable-Bfor speaker for VRChat, index forinput_deviceis6(CABLE-B Output). Don't forget to setVB-Cable-B Inputas the default output device of Windows OS.
Then edit run.py like below.
# Create AIAvatar
aiavatar_app = AIAvatar(
openai_api_key=OPENAI_API_KEY,
input_device=6, # Listen sound from VRChat
output_device=13, # Speak to VRChat microphone
)Run it.
$ run.pyLaunch VRChat as desktop mode on the machine that runs run.py and log in with the account for AIAvatar. Then set VB-Cable-A to microphone in VRChat setting window.
That's all! Let's chat with the AIAvatar. Log in to VRChat on another machine (or Quest) and go to the world the AIAvatar is in.
AIAvatarKit controls the face expression by Avatar OSC.
LLM(ChatGPT/Claude/Gemini)
↓ response with face tag [face:joy]Hello!
AIAvatarKit(VRCFaceExpressionController)
↓ osc FaceOSC=1
VRChat(FX AnimatorController)
↓
😆
So at first, setup your avatar the following steps:
- Add avatar parameter
FaceOSC(type: int, default value: 0, saved: false, synced: true). - Add
FaceOSCparameter to the FX animator controller. - Add layer and put states and transitions for face expression to the FX animator controller.
- (option) If you use the avatar that is already used in VRChat, add input parameter configuration to avatar json.
Next, use VRChatFaceController.
from aiavatar.face.vrchat import VRChatFaceController
# Setup VRChatFaceContorller
vrc_face_controller = VRChatFaceController(
faces={
"neutral": 0, # always set `neutral: 0`
# key = the name that LLM can understand the expression
# value = FaceOSC value that is set to the transition on the FX animator controller
"joy": 1,
"angry": 2,
"sorrow": 3,
"fun": 4
}
)Lastly, add face expression section to the system prompt.
# Make system prompt
system_prompt = """
# Face Expression
* You have following expressions:
- joy
- angry
- sorrow
- fun
* If you want to express a particular emotion, please insert it at the beginning of the sentence like [face:joy].
Example
[face:joy]Hey, you can see the ocean! [face:fun]Let's go swimming.
"""
# Set them to AIAvatar
aiavatar_app = AIAvatar(
openai_api_key=OPENAI_API_KEY,
face_controller=vrc_face_controller,
system_prompt=system_prompt
)You can test it not only through the voice conversation but also via the REST API.
Now writing... ✍️
AIAvatarKit provides a built-in admin panel for monitoring, controlling, and evaluating your AI avatar from a web browser.
Set up the admin panel with a single function call. Once configured, access it at /admin on your server.
from aiavatar.admin import setup_admin_panel
setup_admin_panel(
app,
adapter=aiavatar_app,
evaluator=evaluator, # Optional: If omitted, the pipeline LLM settings are used
character_service=character_service, # Optional: If using CharacterService
character_id=YOUR_CHARACTER_ID, # Optional: Required if character_service is set
api_key="your-api-key" # Optional: If omitted, no authentication is required
)The admin panel includes:
- Metrics — Real-time performance metrics for the STS pipeline
- Logs — Conversation logs with voice playback
- Control — Send speech and conversation messages to the avatar
- Config — Adjust pipeline, VAD, STT, LLM, TTS, and adapter settings at runtime
- Evaluation — Run dialog evaluation scenarios
-
Character — Manage character info, weekly schedule, daily schedules, diaries, and users (requires
character_service)
To protect the admin panel with Basic authentication:
setup_admin_panel(
app,
adapter=aiavatar_app,
api_key="your-api-key",
basic_auth_username="admin",
basic_auth_password="your-password",
)You can also supply your own HTML to fully customize the admin page:
custom_html = open("my_admin.html").read()
setup_admin_panel(
app,
adapter=aiavatar_app,
html=custom_html, # Use your own HTML instead of the built-in template
)All admin panel features are also available as REST API endpoints. See the interactive API documentation at /docs on your server for full details on request/response schemas.
You can monitor the entire sequence - what requests are sent to the LLM, how they are interpreted, which tools are invoked, and what responses are generated from specific results or data - to support AIAvatar quality improvements and governance.
Since AIAvatarKit lets you replace the OpenAI client module with an alternative, you can leverage that capability to integrate with Langfuse.
pip install langfuseexport LANGFUSE_SECRET_KEY=sk-lf-XXXXXXXX
export LANGFUSE_PUBLIC_KEY=pk-lf-XXXXXXXX
export LANGFUSE_HOST=http://localhost:3000from langfuse.openai import openai as langfuse_openai
llm = ChatGPTService(
openai_api_key=OPENAI_API_KEY,
system_prompt="You are a helpful assistant.",
model="gpt-4.1",
custom_openai_module=langfuse_openai, # Set langfuse OpenAI compatible client module
)AIAvatarKit is not just a framework for creating chatty AI characters — it is designed to support agentic characters that can interact with APIs and external data sources (RAG).
Register tool with spec by @aiavatar_app.sts.llm.tool. The spec should be in the format for each LLM.
# Spec (for ChatGPT)
weather_tool_spec = {
"type": "function",
"function": {
"name": "get_weather",
"parameters": {
"type": "object",
"properties": {
"location": {"type": "string"}
},
},
}
}
# Implement tool and register it with spec
@aiavatar_app.sts.llm.tool(weather_tool_spec)
async def get_weather(location: str = None):
weather = await weather_api(location=location) # Call weather API
return weather # {"weather": "clear", "temperature": 23.4}Alternatively, register the same tool programmatically:
aiavatar_app.sts.llm.add_tool(
Tool("get_weather", weather_tool_spec, get_weather)
)Note: When you register a tool with add_tool, the spec is automatically converted to the correct format for GPT, Gemini, or Claude, so you can define it once and use it everywhere.
Before creating your own tools, start with the example tools:
# Google Search
from examples.tools.gemini_websearch import GeminiWebSearchTool
aiavatar_app.sts.llm.add_tool(GeminiWebSearchTool(gemini_api_key=GEMINI_API_KEY))
# Web Scraper
from examples.tools.webscraper import WebScraperTool
aiavatar_app.sts.llm.add_tool(WebScraperTool())Sometimes you may want to provide feedback to the user when a tool takes time to execute. AIAvatarKit supports tools that return stream responses (via AsyncGenerator), which allows you to integrate advanced and costly operations — such as interactions with AI Agent frameworks — into real-time voice conversations without compromising the user experience.
Here’s an example implementation. Intermediate progress is yielded with the second return value set to False, and the final result is yielded with True.
@service.tool(weather_tool_spec)
async def get_weather_stream(location: str):
# Progress: Geocoding
yield {"message": "Resolving location"}, False
geocode = await geocode_api(location=location)
# Progress: Weather
yield {"message": "Calling weather api"}, False
weather = await weather_api(geocode=geocode) # Call weather API
# Final result (yield with `True`)
yield {"weather": "clear", "temperature": 23.4}, TrueOn the user side, the first value in each yield will be streamed as a progress response under the ToolCall response type.
Additionally, you can yield string values directly to provide immediate voice feedback to the user during processing:
@service.tool(weather_tool_spec)
async def get_weather_stream(location: str):
# Provide voice feedback during processing
yield "Converting locaton to geo code. Please wait a moment."
geocode = await geocode_api(location=location)
yield "Getting weather information."
weather = await weather_api(geocode=geocode)
# Final result
yield {"weather": "clear", "temperature": 23.4}, TrueWhen you yield a string (str) value, the AI avatar will speak that text while continuing to process the request.
AIAvatarKit supports dynamic Tool Calls. When many tools are loaded up-front, it becomes harder to make the model behave as intended and your system instructions explode in size. With AIAvatarKit’s Dynamic Tool Call mechanism you load only the tools that are actually needed at the moment, eliminating that complexity.
The overall flow is illustrated below.

(exactly the same as with ordinary tools)
# Weather
get_weather_spec = {
"type": "function",
"function": {
"name": "get_weather",
"description": "Get weather info at the specified location",
"parameters": {
"type": "object",
"properties": {
"location": {"type": "string"}
}
},
}
}
async def get_weather(location: str):
resp = await weather_api(location)
return resp.json() # e.g. {"weather": "clear", "temperature": 23.4}
# Web Search
search_web_spec = {
"type": "function",
"function": {
"name": "search_web",
"description": "Search info from the internet websites",
"parameters": {
"type": "object",
"properties": {
"query": {"type": "string"}
}
},
}
}
async def search_web(query: str) -> str:
resp = await web_search_api(query)
return resp.json() # e.g. {"results": [{...}]}Setting is_dynamic=True tells the framework not to expose the tool by default;
AIAvatarKit will inject it only when the Trigger Detection Tool decides the tool is relevant.
You can also supply an instruction string that will be spliced into the system prompt on-the-fly.
from aiavatar.sts.llm import Tool
llm = aiavatar_app.sts.llm
# Turn on Dynamic Tool Mode
llm.use_dynamic_tools = True
# Register as Dynamic Tools
llm.tools["get_weather"] = Tool(
"get_weather",
get_weather_spec,
get_weather,
instruction=(
"## Use of `get_weather`\n\n"
"Call this tool to obtain current weather or a forecast. "
"Argument:\n"
"- `location`: city name or geo-hash."
),
is_dynamic=True,
)
llm.tools["search_web"] = Tool(
"search_web",
search_web_spec,
search_web,
instruction=(
"## Use of `search_web`\n\n"
"Call this tool to look up information on the public internet. "
"Argument:\n"
"- `query`: keywords describing what you want to find."
),
is_dynamic=True,
)Or, register via add_tool.
# Difine tool without `is_dynamic` for other use cases
weather_tool = Tool("get_weather", get_weather_spec, get_weather, instruction="...")
# Register tool via `add_tool` with `is_dynamic`
llm.add_tool(weather_tool, is_dynamic=True)Append a concise “How to use external tools” section (example below). Replace the example tools with those your application actually relies on for smoother behaviour.
## Use of External Tools
When external tools, knowledge, or data are required to process a user's request, use the appropriate tools.
The following rules **must be strictly followed** when using tools.
### Arguments
- Use only arguments that are **explicitly specified by the user** or that can be **reliably inferred from the conversation history**.
- **If information is missing**, ask the user for clarification or use other tools to retrieve the necessary data.
- **It is strictly forbidden** to use values as arguments that are not based on the conversation.
### Tool Selection
When a specialized tool is available for a specific purpose, use that tool.
If you can use only `execute_external_tool`, use it.
Examples where external tools are needed:
- Retrieving weather information
- Retrieving memory from past conversations
- Searching for, playing, or otherwise controlling music
- Performing web searches
- Accessing real-world systems or data to provide better solutionsWith these three steps, your AI agent stays lean—loading only what it needs—while still having immediate access to a rich arsenal of capabilities whenever they’re truly required.
By default AIAvatarKit simply hands the entire list of dynamic tools to the LLM and lets the model decide which ones match the current context. This approach works for a moderate number of tools, but the size of the prompt places a hard limit on how many candidates you can include.
For larger-scale systems, pair AIAvatarKit with a retrieval layer (e.g., a vector-search index) so that, out of thousands of available tools, only the handful that are truly relevant are executed.
AIAvatarKit supports this pattern through the get_dynamic_tools hook.
Register an async function decorated with @llm.get_dynamic_tools; it should return a list of tool specification objects for the current turn.
@llm.get_dynamic_tools
async def my_get_dynamic_tools(messages: list, metadata: dict) -> list:
# Retrieve candidate tools from your vector database (or any other store)
tools = await search_tools_from_vector_db(messages, metadata)
# Extract and return the spec objects (not the implementations)
return [t.spec for t in tools]AIAvatarKit supports tools provided as MCP.
First, install the required FastMCP dependency.
pip install fastmcpThe following steps show how to retrieve tools from MCP servers and register them to LLMService.
Both Streamable HTTP and standard I/O are supported. The simplest approach is shown in mcp1 and mcp3, but you can also add authentication headers as in mcp2, filter tools to only what you need, or customize parts of the schema or execution logic.
from aiavatar.sts.llm.chatgpt import ChatGPTService
llm = ChatGPTService(openai_api_key=OPENAI_API_KEY)
from aiavatar.sts.llm.tools.mcp import StreamableHttpMCP, StdioMCP
# MCP Server
mcp1 = StreamableHttpMCP(url=MCP1_URL)
mcp1.for_each_tool = llm.add_tool
# MCP Server with Auth
mcp2 = StreamableHttpMCP(url=MCP2_URL, headers={"Authorization": f"Bearer {MCP_JWT}"})
@mcp2.for_each_tool
def mcp2_tools(tool: Tool):
# Do something here (e.g. edit schema or func)
llm.add_tool(tool)
# MCP Server (Std I/O)
mcp3 = StdioMCP(server_script="weather.py") # supports .py and .js
mcp3.for_each_tool = llm.add_toolYou can use the following tools out of the box 📦.
- 🔍 Web Search
- Gemini Search
- OpenAI Search
- Grok Search
- 🌏 Web Scraper
- 🖼️ Image Generation
- 🍌 Nano Banana
- 🐓 Selfie
# Web Search
from aiavatar.sts.llm.tools.gemini_websearch import GeminiWebSearchTool
google_search_tool = GeminiWebSearchTool(gemini_api_key=GEMINI_API_KEY)
llm.add_tool(google_search_tool)
from aiavatar.sts.llm.tools.openai_websearch import OpenAIWebSearchTool
web_search_tool = OpenAIWebSearchTool(openai_api_key=OPENAI_API_KEY)
llm.add_tool(web_search_tool)
from aiavatar.sts.llm.tools.grok_search import GrokSearchTool
grok_web_search_tool = GrokSearchTool(xai_api_key=XAI_API_KEY)
llm.add_tool(grok_web_search_tool)
# Web Scraper
from aiavatar.sts.llm.tools.webscraper import WebScraperTool
webscraper_tool = WebScraperTool()
# webscraper_tool = WebScraperTool(openai_api_key=OPENAI_API_KEY, return_summary=True) # Provides summary instead of full innerText (recommended)
llm.add_tool(webscraper_tool)
# Image Generation
from aiavatar.sts.llm.tools.nanobanana import NanoBananaTool
nanobanana_tool = NanoBananaTool(gemini_api_key=GEMINI_API_KEY)
llm.add_tool(nanobanana_tool)
from aiavatar.sts.llm.tools.nanobanana import NanoBananaSelfieTool
selfie_tool = NanoBananaSelfieTool(gemini_api_key=GEMINI_API_KEY, reference_image=image_bytes_or_image_url_of_file_api)
llm.add_tool(selfie_tool)AIAvatarKit includes a comprehensive evaluation framework for testing and assessing AI avatar conversations. The DialogEvaluator enables scenario-based conversation execution with automatic evaluation capabilities.
- Scenario Execution: Run predefined dialog scenarios against your AI system
- Turn-by-Turn Evaluation: Evaluate each conversation turn against specific criteria
- Goal Assessment: Evaluate overall scenario objective achievement
- Result Management: Save, load, and display evaluation results
import asyncio
from aiavatar.eval.dialog import DialogEvaluator, Scenario, Turn
from aiavatar.sts.llm.chatgpt import ChatGPTService
async def main():
# Initialize LLM services
llm = ChatGPTService(api_key="your_api_key")
evaluation_llm = ChatGPTService(api_key="your_api_key")
# Create evaluator
evaluator = DialogEvaluator(
llm=llm, # LLM for conversation
evaluation_llm=evaluation_llm # LLM for evaluation
)
# Define scenario
scenario = Scenario(
name="Order tracking support",
goal="Provide efficient and helpful customer service for order tracking inquiries",
turns=[
Turn(
input_text="Hello, I need help with my order",
evaluation_criteria="Responds politely and shows willingness to help"
),
Turn(
input_text="My order number is 12345",
evaluation_criteria="Acknowledges the order number and proceeds appropriately"
)
]
)
# Run evaluation
results = await evaluator.run(
dataset=[scenario],
detailed=True, # Enable turn-by-turn evaluation
overwrite_execution=False, # Skip if already executed
overwrite_evaluation=False # Skip if already evaluated
)
# Display results
evaluator.print_results(results)
# Save results
evaluator.save_results(results, "evaluation_results.json")
if __name__ == "__main__":
asyncio.run(main())Example Output:
=== Scenario 1 ===
Goal: Provide helpful customer support
Turn 1:
Input: Hello, I need help with my order
Actual Output: Hello! I'd be happy to help you with your order. Could you please provide your order number?
Result: ✓ PASS
Reason: The response is polite, helpful, and appropriately asks for the order number.
Turn 2:
Input: My order number is 12345
Actual Output: Thank you for providing order number 12345. Let me look that up for you.
Result: ✓ PASS
Reason: Acknowledges the order number and shows willingness to help.
Summary: 2/2 turns passed (100.0%)
=== Overall Scenario Evaluation ===
Goal Achievement: ✓ SUCCESS
Reason: The AI successfully provided helpful customer support by responding politely and efficiently handling the order inquiry.
Load scenarios from JSON files:
{
"scenarios": [
{
"goal": "Basic greeting and assistance",
"turns": [
{
"input_text": "Hello",
"expected_output": "Friendly greeting",
"evaluation_criteria": "Responds warmly and appropriately"
}
]
}
]
}# Load and evaluate from file
results = await evaluator.run(dataset="test_scenarios.json")
# Save results back to file
evaluator.save_results(results, "results.json")# Execution modes
results = await evaluator.run(
dataset=scenarios,
detailed=True, # Turn-by-turn evaluation
overwrite_execution=True, # Re-run conversations
overwrite_evaluation=True # Re-evaluate results
)
# Simple mode (scenario-level evaluation only)
results = await evaluator.run(
dataset=scenarios,
detailed=False
)You can evaluate scenario on the fly via Config API:
# Make evaluator
from aiavatar.eval.dialog import DialogEvaluator
eval_llm = ChatGPTService(openai_api_key=OPENAI_API_KEY)
evaluator = DialogEvaluator(llm=aiavatar_app.sts.llm, evaluation_llm=eval_llm)
# Activate Config API
from aiavatar.admin.config import ConfigAPI
config_router = ConfigAPI(aiavatar_app.sts, evaluator=evaluator).get_router() # Set evaluator here
app.include_router(config_router)In addition to LLM-based evaluation using evaluation_criteria, you can evaluate more explicitly using custom logic functions.
# Make evaluation function(s)
def evaluate_weather_tool_call(output_text, tool_call, evaluation_criteria, result, eval_result_text):
if tool_call is not None and tool_call.name != "get_weather":
# Overwrite result and reason
return False, f"Incorrect tool call: {tool_call.name}"
else:
# Pass through
return result, eval_result_text
# Register evaluation function(s)
evaluator = DialogEvaluator(
llm=aiavatar_app.sts.llm,
evaluation_llm=eval_llm,
evaluation_functions={"evaluate_weather_tool_call_func": evaluate_weather_tool_call}
)
# Use evaluation function in scenario
scenario = Scenario(
turns=[
Turn(input_text="Hello", expected_output_text="Hi", evaluation_criteria="Greeting"),
Turn(input_text="What is the weather in Tokyo?", expected_output_text="It's sunny.", evaluation_criteria="Answer the weather based on the result of calling get_weather tool.", evaluation_function_name="evaluate_weather_tool_call_func"),
],
goal="Answer the weather in Tokyo based on the result of get_weather."
)Advanced usases.
You can use PostgreSQL instead of the default SQLite. We strongly recommend using PostgreSQL in production environments for its scalability and performance benefits from asynchronous processing.
To use PostgreSQL, install asyncpg and create a PostgreSQLPoolProvider to manage the shared connection pool. Then pass it to the constructors of the components that need database access.
pip install asyncpg# DB_CONNECTION_STR = "postgresql://{user}:{password}@{host}:{port}/{databasename}"
DB_CONNECTION_STR = "postgresql://postgres:[email protected]:5432/aiavatar"
# PoolProvider
from aiavatar.database.postgres import PostgreSQLPoolProvider
pool_provider = PostgreSQLPoolProvider(
connection_str=DB_CONNECTION_STR,
# max_size=20, # Max connection count (default: 20)
# min_size=5 # Min connection count (default: 5)
)
# Character
from aiavatar.character import CharacterService
character_service = CharacterService(
openai_api_key=OPENAI_API_KEY,
db_pool_provider=pool_provider, # Creates PostgreSQLCharacterRepository and PostgreSQLActivityRepository internally
)
# LLM
from aiavatar.sts.llm.context_manager.postgres import PostgreSQLContextManager
llm = ChatGPTService(
openai_api_key=OPENAI_API_KEY,
system_prompt=SYSTEM_PROMPT,
context_manager=PostgreSQLContextManager(
get_pool=pool_provider.get_pool # Set `get_pool` to PostgreSQLContextManager
)
)
# Adapter (Create pipeline internally)
ws_app = AIAvatarWebSocketServer(
vad=vad,
stt=stt,
llm=llm,
tts=tts,
db_pool_provider=pool_provider, # Creates PostgreSQLSessionStateManager and PostgreSQLPerformanceRecorder internally
)NOTE: You can also pass PostgreSQL connection settings directly to each component's constructor to manage and use individual connections separately from the shared connection pool. However, this makes it difficult to manage the total number of connections, especially when using multiple workers. We recommend using the shared pool unless you have a specific reason not to.
NOTE: PerformanceRecorder runs in a separate thread from the main thread, so it does not use the shared connection pool. Instead, it retrieves only the connection information from the PoolProvider and creates its own dedicated connection pool. It writes performance information serially as it receives it through a queue, so it basically uses only a single connection. We recommend not changing this unless you have a specific reason.
You can handle errors that occur during LLM API calls by using the on_error decorator. This is useful for customizing avatar responses when content filters are triggered or when API errors occur.
from aiavatar.sts.llm import LLMResponse
@llm.on_error
async def on_error(llm_response: LLMResponse):
ex = llm_response.error_info.get("exception") # Get exception
error_json = llm_response.error_info.get("response_json", {}) # Get response JSON from OpenAI
# Make response
if error_json.get("error", {}).get("code") == "content_filter":
llm_response.text = "[face:angry]You shouldn't say that!"
llm_response.voice_text = "You shouldn't say that!"
else:
llm_response.text = "[face:sorrow]An error occurred"
llm_response.voice_text = "An error occurred"NOTE: When an error occurs, the conversation context is not updated. This is intentional because including the programmatically overwritten response in the context may cause unexpected LLM behavior in subsequent conversations.
Use the print_chat decorator to customize how user/AI conversation turns are logged.
@llm.print_chat
def print_chat(role, context_id, user_id, text, files):
if role == "user":
logger.info(f"\033[1;32mUser:\033[0m {text}")
else:
think_match = re.search(r"<think>(.*?)</think>", text, re.DOTALL)
answer_match = re.search(r"<answer>(.*?)</answer>", text, re.DOTALL)
if think_match or answer_match:
if think_match:
logger.info(f"\033[3;38;5;246mThinking: {think_match.group(1).strip()}\033[0m")
logger.info(f"\033[1;35mAI:\033[0m {answer_match.group(1).strip() if answer_match else text}")
else:
logger.info(f"\033[1;35mAI:\033[0m {text}")NOTE: This example uses ANSI escape sequences optimized for console output. These escape codes will appear as noise in log files.
AIAvatarKit captures and sends image to AI dynamically when the AI determine that vision is required to process the request. This gives "eyes" to your AIAvatar in metaverse platforms like VRChat.
# Instruct vision tag in the system message
SYSTEM_PROMPR = """
## Using Vision
If you need an image to process a user's request, you can obtain it using the following methods:
- screenshot
- camera
If an image is needed to process the request, add an instruction like [vision:screenshot] to your response to request an image from the user.
By adding this instruction, the user will provide an image in their next utterance. No comments about the image itself are necessary.
Example:
user: Look! This is the sushi I had today.
assistant: [vision:screenshot] Let me take a look.
"""
# Create AIAvatar with the system prompt
aiavatar_app = AIAvatar(
system_prompt=SYSTEM_PROMPT,
openai_api_key=OPENAI_API_KEY
)
# Implement get_image_url
import base64
import io
import pyautogui # pip install pyautogui
from aiavatar.device.video import VideoDevice # pip install opencv-python
default_camera = VideoDevice(device_index=0, width=960, height=540)
@aiavatar_app.get_image_url
async def get_image_url(source: str) -> str:
image_bytes = None
if source == "camera":
# Capture photo by camera
image_bytes = await default_camera.capture_image("camera.jpg")
elif source == "screenshot":
# Capture screenshot
buffered = io.BytesIO()
image = pyautogui.screenshot(region=(0, 0, 1280, 720))
image.save(buffered, format="PNG")
image_bytes = buffered.getvalue()
if image_bytes:
# Upload and get url, or, make base64 encoded url
b64_encoded = base64.b64encode(image_bytes).decode('utf-8')
b64_url = f"data:image/jpeg;base64,{b64_encoded}"
return b64_urlTo recall information from past conversations across different contexts, a long-term memory service is used.
To store conversation history, define a function decorated with @aiavatar_app.sts.on_finish. To retrieve memories from the conversation history, call the search function of the long-term memory service as a tool.
Below is an example using ChatMemory.
# Create client for ChatMemory
from aiavatar.character.memory import MemoryClient
memory_client = MemoryClient(
base_url="http://localhost:8000"
)
# Add messages to ChatMemory service
@aiavatar_app.sts.on_finish
async def on_finish(request, response):
await memory_client.add_messages(
character_id=YOUR_CHARACTER_ID, # Character ID registered via CharacterService, or any value to separate memory spaces
request=request,
response=response
)
# Add MemorySearchTool to recall past events, conversations, or information about the user.
from aiavatar.character.tools import MemorySearchTool
llm.add_tool(
MemorySearchTool(
memory_client=memory_client,
character_id=YOUR_CHARACTER_ID,
debug=True
)
)Set wakewords when instantiating AIAvatar. Conversation will start when the AIAvatar recognizes one of the words in this list. You can also set wakeword_timeout, after which the AIAvatar will return to listening for the wakeword again.
aiavatar_app = AIAvatar(
openai_api_key=OPENAI_API_KEY,
wakewords=["Hello", "こんにちは"],
wakeword_timeout=60,
)You can embed parameters into your system prompt dynamically.
First, define your AIAvatar instance with a system prompt containing placeholders:
aiavatar_app = AIAvatar(
openai_api_key="YOUR_OPENAI_API_KEY",
model="gpt-4o",
system_prompt="User's name is {name}."
)When invoking, pass the parameters as a dictionary using system_prompt_params:
aiavatar_app.sts.invoke(STSRequest(
# (other fields omitted)
system_prompt_params={"name": "Nekochan"}
))Placeholders in the system prompt, such as {name}, will be replaced with the corresponding values at runtime.
You can insert timestamps into requests at regular intervals. This keeps AIAvatar responses anchored to real-world time.
aiavatar_app = AIAvatar(
vad=vad,
stt=stt,
llm=llm,
tts=tts,
timestamp_interval_seconds=600.0, # Inserts a timestamp to the request every 600 seconds (10 minutes). Default is 0.
timestamp_timezone="Asia/Tokyo", # Default is 'UTC'
)For example, a request of "Hello!" with timestamp insertion enabled becomes:
$Current date and time: 2025-12-24
Hello!
When timestamp_interval_seconds is set to 0, no timestamp is inserted (default).
Request merging helps prevent conversation breakdown when speech recognition produces fragmented results. When enabled, consecutive requests within a specified time window are automatically merged into a single request, improving conversation continuity and user experience.
Example without request merging:
User: I'm feeling hungry...
AI: Would you... (interrupted mid-sentence while saying "Would you like me to book a restaurant? The place from last time has availability")
User: Uh-huh (misrecognized from "Um..." - a hesitant sound)
AI: Booking completed. (responded to "Uh-huh" and executed restaurant booking)
User: What are you talking about??
Example with request merging:
User: I'm feeling hungry...
AI: Would you... (interrupted mid-sentence while saying "Would you like me to book a restaurant? The place from last time has availability")
User: Uh-huh (misrecognized from "Um..." - a hesitant sound)
AI: Would you like me to book a restaurant? The place from last time has availability (responding to merged request "I'm feeling hungry... Uh-huh...")
User: Yes, please!
To enable this feature, set merge_request_threshold > 0.
aiavatar_app.sts.merge_request_threshold = 2.0 # Merge requests within 2 secondsYou can also customize the merge prefix message. Here's an example of setting the prefix in Japanese:
aiavatar_app.sts.merge_request_prefix = "$直前のユーザーの要求とあなたの応答はキャンセルされました。以下の要求に対して、あらためて応答しなおしてください:\n\n"NOTE: Files from the previous request are preserved in the merged request
AIAvatarKit provides three invoke modes for handling concurrent requests. By default, new requests interrupt any ongoing response. With queue mode enabled, you can control whether requests wait in line or still interrupt.
| Mode | Settings | Behavior |
|---|---|---|
| Direct (default) | use_invoke_queue=False |
New requests immediately interrupt the current response. Suitable for most use cases. |
| Queued (Interrupt) |
use_invoke_queue=True, wait_in_queue=False
|
Requests are queued but clear previous pending requests. The current response is interrupted. Default behavior when queue mode is enabled. |
| Queued (Wait) |
use_invoke_queue=True, wait_in_queue=True
|
Requests wait in queue until previous ones complete. No interruption occurs. Useful when you need sequential processing, such as sending a follow-up request (e.g., with an image requested by the server) without interrupting the current response. |
Enable queue mode on the pipeline:
from aiavatar.sts import STSPipeline
pipeline = STSPipeline(
# ... other settings ...
use_invoke_queue=True, # Enable queue mode
invoke_queue_idle_timeout=10.0, # Worker stops after 10s of inactivity
invoke_timeout=60.0, # Maximum time for a single invoke
)Or on the AIAvatar instance:
aiavatar_app = AIAvatar(
openai_api_key=OPENAI_API_KEY,
use_invoke_queue=True,
)When queue mode is enabled, control per-request behavior via wait_in_queue:
from aiavatar.sts import STSRequest
# Interrupt mode (default): clears queue and interrupts current response
request = STSRequest(
session_id="session1",
text="Hello!",
wait_in_queue=False # default
)
# Wait mode: queues and waits for previous requests to complete
request = STSRequest(
session_id="session1",
text="What's next?",
wait_in_queue=True
)-
Python 3.11+ required: Queue mode uses
asyncio.timeout()which is only available in Python 3.11 and later. - Session-based queues: Each session has its own independent queue. Requests from different sessions do not affect each other.
-
Do not mix modes: The
use_invoke_queuesetting should remain consistent for a pipeline instance. Changing it at runtime is not supported. -
Cancelled responses: When a queued request is cleared (by a non-waiting request), it receives a response with
type="cancelled".
Context is typically shared only between an individual user and the AI character. With AIAvatarKit, you can manage histories that define how broadly the context is shared, for example, making it common to every user.
This lets you inject context with general events that are independent of any single user interaction, such as public news or actions the AI character has taken.
# Add character-wide shared messages identified by context_id="shared_context_id"
now = datetime.now(ZoneInfo(self.timezone))
await self.llm.context_manager.add_histories(
context_id="shared_context_id",
data_list=[
{
"role": "user",
"content": f"$Current datetime: {now.strftime('%Y/%m/%d %H:%M:%S')}\nToday's news: {news}"
},
{
"role": "assistant",
"content": "I recognized current datetime and today's news."
},
],
context_schema="chatgpt"
)# Pass "shared_context_id" via `shared_context_ids` to load the shared history
llm = ChatGPTService(
openai_api_key=OPENAI_API_KEY,
system_prompt="You are a helpful virtual assistant.",
model="gpt-4.1",
shared_context_id=["shared_context_id"]
)You can specify the audio devices to be used in components by device index.
First, check the device indexes you want to use.
$ python
>>> from aiavatar import AudioDevice
>>> AudioDevice().list_audio_devices()
{'index': 0, 'name': '外部マイク', 'max_input_channels': 1, 'max_output_channels': 0, 'default_sample_rate': 44100.0}
{'index': 1, 'name': '外部ヘッドフォン', 'max_input_channels': 0, 'max_output_channels': 2, 'default_sample_rate': 44100.0}
{'index': 2, 'name': 'MacBook Airのマイク', 'max_input_channels': 3, 'max_output_channels': 0, 'default_sample_rate': 44100.0}
{'index': 3, 'name': 'MacBook Airのスピーカー', 'max_input_channels': 0, 'max_output_channels': 2, 'default_sample_rate': 44100.0}Set indexes to AIAvatar.
aiavatar_app = AIAvatar(
input_device=2, # MacBook Airのマイク
output_device=3, # MacBook Airのスピーカー
openai_api_key=OPENAI_API_KEY
)You can invoke custom implementations on_response(response_type). In the following example, show "thinking" face expression while processing request to enhance the interaction experience with the AI avatar.
# Set face when the character is thinking the answer
@aiavatar_app.on_response("start")
async def on_start_response(response):
await aiavatar_app.face_controller.set_face("thinking", 3.0)
# Reset face before answering
@aiavatar_app.on_response("chunk")
async def on_chunk_response(response):
if response.metadata.get("is_first_chunk"):
aiavatar_app.face_controller.reset()You can filter out unwanted requests before they reach the LLM by implementing a validate_request hook. Return a reason string to cancel the request, or None to proceed.
from aiavatar.sts.models import STSRequest
@aiavatar_app.sts.validate_request
async def validate_request(request: STSRequest):
# Reject text that is too short
if len(request.text) < 3:
return "Text too short"
# Reject requests with too many files
if request.files and len(request.files) > 5:
return "Too many files attached"
# Reject specific users
if request.user_id == "blocked_user":
return "User is blocked"
return None # Proceed with the requestThis is useful for:
- Filtering out noise or accidental triggers (e.g., coughs, short utterances)
- Limiting file attachments
- Implementing user-based access control
- Any custom validation logic based on
STSRequestfields
When using AzureStreamSpeechDetector, you can validate recognized text even earlier—before the STS pipeline is invoked. This is more efficient for filtering out short or invalid utterances since it skips the entire pipeline processing.
from aiavatar.sts.vad.azure_stream import AzureStreamSpeechDetector
speech_detector = AzureStreamSpeechDetector(
azure_subscription_key=AZURE_SUBSCRIPTION_KEY,
azure_region=AZURE_REGION,
azure_language="ja-JP",
)
@speech_detector.validate_recognized_text
def validate_recognized_text(text: str) -> str | None:
# Reject text that is too short
if len(text) < 3:
return "Text too short"
# Reject specific patterns (e.g., filler words)
if text in ["えーと", "あの", "うーん"]:
return "Filler word detected"
return None # Proceed with the requestNote: This decorator uses a synchronous function (not async) because it runs within the Azure Speech SDK's callback thread.
AIAvatarKit automatically adjusts the noise filter for listeners when you instantiate an AIAvatar object. To manually set the noise filter level for voice detection, set auto_noise_filter_threshold to False and specify the volume_threshold_db in decibels (dB).
aiavatar_app = AIAvatar(
openai_api_key=OPENAI_API_KEY,
auto_noise_filter_threshold=False,
volume_threshold_db=-40 # Set the voice detection threshold to -40 dB
)In version v0.7.0, the internal Speech-to-Speech pipeline previously provided by the external LiteSTS library has been fully integrated into AIAvatarKit.
- The functionality remains the same — no API behavior changes.
- However, import paths have been updated.
All imports from litests should now be updated to aiavatar.sts.
For example:
# Before
from litests import STSRequest, STSResponse
from litests.llm.chatgpt import ChatGPTService
# After
from aiavatar.sts import STSRequest, STSResponse
from aiavatar.sts.llm.chatgpt import ChatGPTServiceThis change ensures compatibility with the new internal structure and removes the need for LiteSTS as a separate dependency.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for aiavatarkit
Similar Open Source Tools
aiavatarkit
AIAvatarKit is a tool for building AI-based conversational avatars quickly. It supports various platforms like VRChat and cluster, along with real-world devices. The tool is extensible, allowing unlimited capabilities based on user needs. It requires VOICEVOX API, Google or Azure Speech Services API keys, and Python 3.10. Users can start conversations out of the box and enjoy seamless interactions with the avatars.

langchainrb
Langchain.rb is a Ruby library that makes it easy to build LLM-powered applications. It provides a unified interface to a variety of LLMs, vector search databases, and other tools, making it easy to build and deploy RAG (Retrieval Augmented Generation) systems and assistants. Langchain.rb is open source and available under the MIT License.

promptic
Promptic is a tool designed for LLM app development, providing a productive and pythonic way to build LLM applications. It leverages LiteLLM, allowing flexibility to switch LLM providers easily. Promptic focuses on building features by providing type-safe structured outputs, easy-to-build agents, streaming support, automatic prompt caching, and built-in conversation memory.

instructor
Instructor is a popular Python library for managing structured outputs from large language models (LLMs). It offers a user-friendly API for validation, retries, and streaming responses. With support for various LLM providers and multiple languages, Instructor simplifies working with LLM outputs. The library includes features like response models, retry management, validation, streaming support, and flexible backends. It also provides hooks for logging and monitoring LLM interactions, and supports integration with Anthropic, Cohere, Gemini, Litellm, and Google AI models. Instructor facilitates tasks such as extracting user data from natural language, creating fine-tuned models, managing uploaded files, and monitoring usage of OpenAI models.

instructor
Instructor is a Python library that makes it a breeze to work with structured outputs from large language models (LLMs). Built on top of Pydantic, it provides a simple, transparent, and user-friendly API to manage validation, retries, and streaming responses. Get ready to supercharge your LLM workflows!

sparkle
Sparkle is a tool that streamlines the process of building AI-driven features in applications using Large Language Models (LLMs). It guides users through creating and managing agents, defining tools, and interacting with LLM providers like OpenAI. Sparkle allows customization of LLM provider settings, model configurations, and provides a seamless integration with Sparkle Server for exposing agents via an OpenAI-compatible chat API endpoint.

FlashLearn
FlashLearn is a tool that provides a simple interface and orchestration for incorporating Agent LLMs into workflows and ETL pipelines. It allows data transformations, classifications, summarizations, rewriting, and custom multi-step tasks using LLMs. Each step and task has a compact JSON definition, making pipelines easy to understand and maintain. FlashLearn supports LiteLLM, Ollama, OpenAI, DeepSeek, and other OpenAI-compatible clients.

ruby-openai
Use the OpenAI API with Ruby! 🤖🩵 Stream text with GPT-4, transcribe and translate audio with Whisper, or create images with DALL·E... Hire me | 🎮 Ruby AI Builders Discord | 🐦 Twitter | 🧠 Anthropic Gem | 🚂 Midjourney Gem ## Table of Contents * Ruby OpenAI * Table of Contents * Installation * Bundler * Gem install * Usage * Quickstart * With Config * Custom timeout or base URI * Extra Headers per Client * Logging * Errors * Faraday middleware * Azure * Ollama * Counting Tokens * Models * Examples * Chat * Streaming Chat * Vision * JSON Mode * Functions * Edits * Embeddings * Batches * Files * Finetunes * Assistants * Threads and Messages * Runs * Runs involving function tools * Image Generation * DALL·E 2 * DALL·E 3 * Image Edit * Image Variations * Moderations * Whisper * Translate * Transcribe * Speech * Errors * Development * Release * Contributing * License * Code of Conduct

LightRAG
LightRAG is a repository hosting the code for LightRAG, a system that supports seamless integration of custom knowledge graphs, Oracle Database 23ai, Neo4J for storage, and multiple file types. It includes features like entity deletion, batch insert, incremental insert, and graph visualization. LightRAG provides an API server implementation for RESTful API access to RAG operations, allowing users to interact with it through HTTP requests. The repository also includes evaluation scripts, code for reproducing results, and a comprehensive code structure.
langchain-decorators
LangChain Decorators is a layer on top of LangChain that provides syntactic sugar for writing custom langchain prompts and chains. It offers a more pythonic way of writing code, multiline prompts without breaking code flow, IDE support for hinting and type checking, leveraging LangChain ecosystem, support for optional parameters, and sharing parameters between prompts. It simplifies streaming, automatic LLM selection, defining custom settings, debugging, and passing memory, callback, stop, etc. It also provides functions provider, dynamic function schemas, binding prompts to objects, defining custom settings, and debugging options. The project aims to enhance the LangChain library by making it easier to use and more efficient for writing custom prompts and chains.
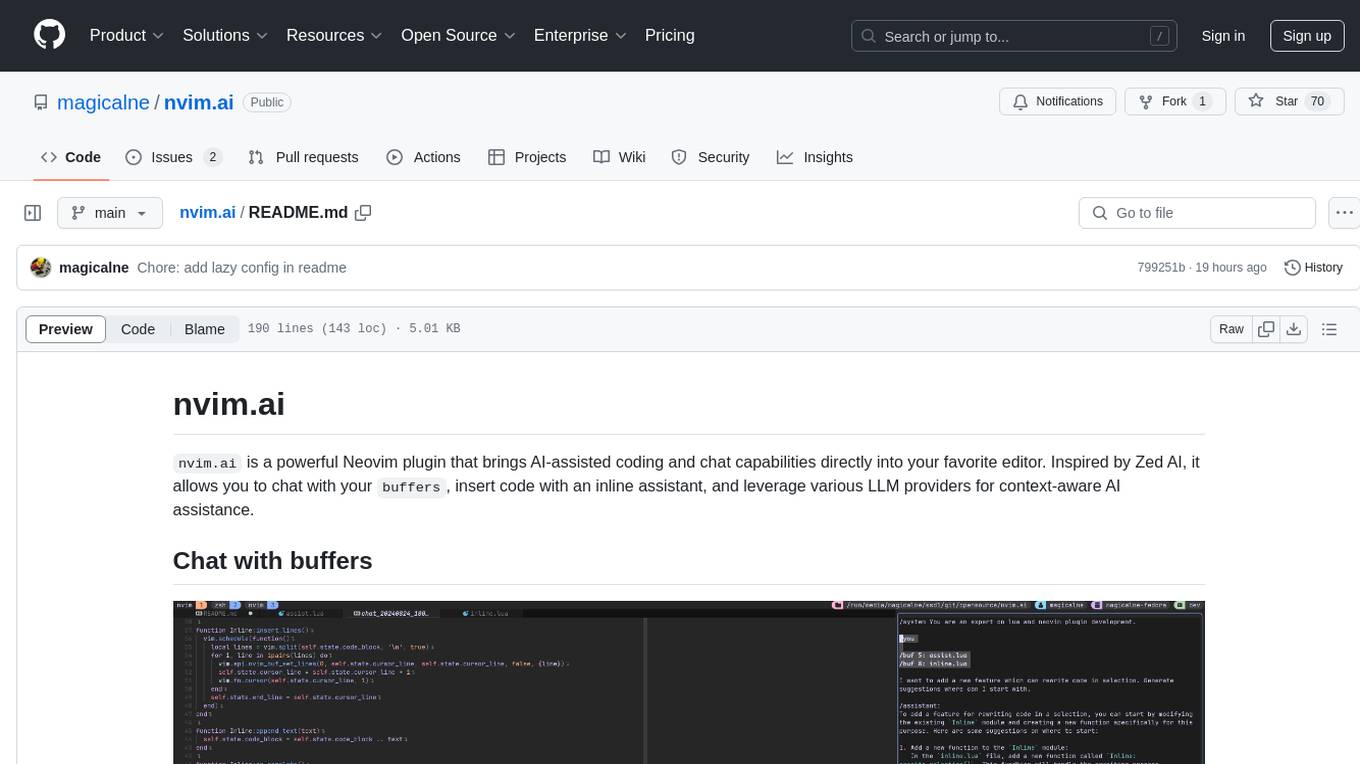
nvim.ai
nvim.ai is a powerful Neovim plugin that enables AI-assisted coding and chat capabilities within the editor. Users can chat with buffers, insert code with an inline assistant, and utilize various LLM providers for context-aware AI assistance. The plugin supports features like interacting with AI about code and documents, receiving relevant help based on current work, code insertion, code rewriting (Work in Progress), and integration with multiple LLM providers. Users can configure the plugin, add API keys to dotfiles, and integrate with nvim-cmp for command autocompletion. Keymaps are available for chat and inline assist functionalities. The chat dialog allows parsing content with keywords and supports roles like /system, /you, and /assistant. Context-aware assistance can be accessed through inline assist by inserting code blocks anywhere in the file.

deep-searcher
DeepSearcher is a tool that combines reasoning LLMs and Vector Databases to perform search, evaluation, and reasoning based on private data. It is suitable for enterprise knowledge management, intelligent Q&A systems, and information retrieval scenarios. The tool maximizes the utilization of enterprise internal data while ensuring data security, supports multiple embedding models, and provides support for multiple LLMs for intelligent Q&A and content generation. It also includes features like private data search, vector database management, and document loading with web crawling capabilities under development.

clarifai-python
The Clarifai Python SDK offers a comprehensive set of tools to integrate Clarifai's AI platform to leverage computer vision capabilities like classification , detection ,segementation and natural language capabilities like classification , summarisation , generation , Q&A ,etc into your applications. With just a few lines of code, you can leverage cutting-edge artificial intelligence to unlock valuable insights from visual and textual content.

neocodeium
NeoCodeium is a free AI completion plugin powered by Codeium, designed for Neovim users. It aims to provide a smoother experience by eliminating flickering suggestions and allowing for repeatable completions using the `.` key. The plugin offers performance improvements through cache techniques, displays suggestion count labels, and supports Lua scripting. Users can customize keymaps, manage suggestions, and interact with the AI chat feature. NeoCodeium enhances code completion in Neovim, making it a valuable tool for developers seeking efficient coding assistance.

python-tgpt
Python-tgpt is a Python package that enables seamless interaction with over 45 free LLM providers without requiring an API key. It also provides image generation capabilities. The name _python-tgpt_ draws inspiration from its parent project tgpt, which operates on Golang. Through this Python adaptation, users can effortlessly engage with a number of free LLMs available, fostering a smoother AI interaction experience.

Lumos
Lumos is a Chrome extension powered by a local LLM co-pilot for browsing the web. It allows users to summarize long threads, news articles, and technical documentation. Users can ask questions about reviews and product pages. The tool requires a local Ollama server for LLM inference and embedding database. Lumos supports multimodal models and file attachments for processing text and image content. It also provides options to customize models, hosts, and content parsers. The extension can be easily accessed through keyboard shortcuts and offers tools for automatic invocation based on prompts.
For similar tasks
aiavatarkit
AIAvatarKit is a tool for building AI-based conversational avatars quickly. It supports various platforms like VRChat and cluster, along with real-world devices. The tool is extensible, allowing unlimited capabilities based on user needs. It requires VOICEVOX API, Google or Azure Speech Services API keys, and Python 3.10. Users can start conversations out of the box and enjoy seamless interactions with the avatars.
discollama
Discollama is a Discord bot powered by a local large language model backed by Ollama. It allows users to interact with the bot in Discord by mentioning it in a message to start a new conversation or in a reply to a previous response to continue an ongoing conversation. The bot requires Docker and Docker Compose to run, and users need to set up a Discord Bot and environment variable DISCORD_TOKEN before using discollama.py. Additionally, an Ollama server is needed, and users can customize the bot's personality by creating a custom model using Modelfile and running 'ollama create'.
Muice-Chatbot
Muice-Chatbot is an AI chatbot designed to proactively engage in conversations with users. It is based on the ChatGLM2-6B and Qwen-7B models, with a training dataset of 1.8K+ dialogues. The chatbot has a speaking style similar to a 2D girl, being somewhat tsundere but willing to share daily life details and greet users differently every day. It provides various functionalities, including initiating chats and offering 5 available commands. The project supports model loading through different methods and provides onebot service support for QQ users. Users can interact with the chatbot by running the main.py file in the project directory.
TerminalGPT
TerminalGPT is a terminal-based ChatGPT personal assistant app that allows users to interact with OpenAI GPT-3.5 and GPT-4 language models. It offers advantages over browser-based apps, such as continuous availability, faster replies, and tailored answers. Users can use TerminalGPT in their IDE terminal, ensuring seamless integration with their workflow. The tool prioritizes user privacy by not using conversation data for model training and storing conversations locally on the user's machine.
ESP32_AI_LLM
ESP32_AI_LLM is a project that uses ESP32 to connect to Xunfei Xinghuo, Dou Bao, and Tongyi Qianwen large models to achieve voice chat functions, supporting online voice wake-up, continuous conversation, music playback, and real-time display of conversation content on an external screen. The project requires specific hardware components and provides functionalities such as voice wake-up, voice conversation, convenient network configuration, music playback, volume adjustment, LED control, model switching, and screen display. Users can deploy the project by setting up Xunfei services, cloning the repository, configuring necessary parameters, installing drivers, compiling, and burning the code.
gemini-multimodal-playground
Gemini Multimodal Playground is a basic Python app for voice conversations with Google's Gemini 2.0 AI model. It features real-time voice input and text-to-speech responses. Users can configure settings through the GUI and interact with Gemini by speaking into the microphone. The application provides options for voice selection, system prompt customization, and enabling Google search. Troubleshooting tips are available for handling audio feedback loop issues that may occur during interactions.
alexa-skill-llm-intent
An Alexa Skill template that provides a ready-to-use skill for starting a conversation with an AI. Users can ask questions and receive answers in Alexa's voice, powered by ChatGPT or other llm. The template includes setup instructions for configuring the AI provider API and model, as well as usage commands for interacting with the skill. It serves as a starting point for creating custom Alexa Skills and should be used at the user's own risk.

chatless
Chatless is a modern AI chat desktop application built on Tauri and Next.js. It supports multiple AI providers, can connect to local Ollama models, supports document parsing and knowledge base functions. All data is stored locally to protect user privacy. The application is lightweight, simple, starts quickly, and consumes minimal resources.
For similar jobs

promptflow
**Prompt flow** is a suite of development tools designed to streamline the end-to-end development cycle of LLM-based AI applications, from ideation, prototyping, testing, evaluation to production deployment and monitoring. It makes prompt engineering much easier and enables you to build LLM apps with production quality.

deepeval
DeepEval is a simple-to-use, open-source LLM evaluation framework specialized for unit testing LLM outputs. It incorporates various metrics such as G-Eval, hallucination, answer relevancy, RAGAS, etc., and runs locally on your machine for evaluation. It provides a wide range of ready-to-use evaluation metrics, allows for creating custom metrics, integrates with any CI/CD environment, and enables benchmarking LLMs on popular benchmarks. DeepEval is designed for evaluating RAG and fine-tuning applications, helping users optimize hyperparameters, prevent prompt drifting, and transition from OpenAI to hosting their own Llama2 with confidence.

MegaDetector
MegaDetector is an AI model that identifies animals, people, and vehicles in camera trap images (which also makes it useful for eliminating blank images). This model is trained on several million images from a variety of ecosystems. MegaDetector is just one of many tools that aims to make conservation biologists more efficient with AI. If you want to learn about other ways to use AI to accelerate camera trap workflows, check out our of the field, affectionately titled "Everything I know about machine learning and camera traps".

leapfrogai
LeapfrogAI is a self-hosted AI platform designed to be deployed in air-gapped resource-constrained environments. It brings sophisticated AI solutions to these environments by hosting all the necessary components of an AI stack, including vector databases, model backends, API, and UI. LeapfrogAI's API closely matches that of OpenAI, allowing tools built for OpenAI/ChatGPT to function seamlessly with a LeapfrogAI backend. It provides several backends for various use cases, including llama-cpp-python, whisper, text-embeddings, and vllm. LeapfrogAI leverages Chainguard's apko to harden base python images, ensuring the latest supported Python versions are used by the other components of the stack. The LeapfrogAI SDK provides a standard set of protobuffs and python utilities for implementing backends and gRPC. LeapfrogAI offers UI options for common use-cases like chat, summarization, and transcription. It can be deployed and run locally via UDS and Kubernetes, built out using Zarf packages. LeapfrogAI is supported by a community of users and contributors, including Defense Unicorns, Beast Code, Chainguard, Exovera, Hypergiant, Pulze, SOSi, United States Navy, United States Air Force, and United States Space Force.

llava-docker
This Docker image for LLaVA (Large Language and Vision Assistant) provides a convenient way to run LLaVA locally or on RunPod. LLaVA is a powerful AI tool that combines natural language processing and computer vision capabilities. With this Docker image, you can easily access LLaVA's functionalities for various tasks, including image captioning, visual question answering, text summarization, and more. The image comes pre-installed with LLaVA v1.2.0, Torch 2.1.2, xformers 0.0.23.post1, and other necessary dependencies. You can customize the model used by setting the MODEL environment variable. The image also includes a Jupyter Lab environment for interactive development and exploration. Overall, this Docker image offers a comprehensive and user-friendly platform for leveraging LLaVA's capabilities.

carrot
The 'carrot' repository on GitHub provides a list of free and user-friendly ChatGPT mirror sites for easy access. The repository includes sponsored sites offering various GPT models and services. Users can find and share sites, report errors, and access stable and recommended sites for ChatGPT usage. The repository also includes a detailed list of ChatGPT sites, their features, and accessibility options, making it a valuable resource for ChatGPT users seeking free and unlimited GPT services.

TrustLLM
TrustLLM is a comprehensive study of trustworthiness in LLMs, including principles for different dimensions of trustworthiness, established benchmark, evaluation, and analysis of trustworthiness for mainstream LLMs, and discussion of open challenges and future directions. Specifically, we first propose a set of principles for trustworthy LLMs that span eight different dimensions. Based on these principles, we further establish a benchmark across six dimensions including truthfulness, safety, fairness, robustness, privacy, and machine ethics. We then present a study evaluating 16 mainstream LLMs in TrustLLM, consisting of over 30 datasets. The document explains how to use the trustllm python package to help you assess the performance of your LLM in trustworthiness more quickly. For more details about TrustLLM, please refer to project website.

AI-YinMei
AI-YinMei is an AI virtual anchor Vtuber development tool (N card version). It supports fastgpt knowledge base chat dialogue, a complete set of solutions for LLM large language models: [fastgpt] + [one-api] + [Xinference], supports docking bilibili live broadcast barrage reply and entering live broadcast welcome speech, supports Microsoft edge-tts speech synthesis, supports Bert-VITS2 speech synthesis, supports GPT-SoVITS speech synthesis, supports expression control Vtuber Studio, supports painting stable-diffusion-webui output OBS live broadcast room, supports painting picture pornography public-NSFW-y-distinguish, supports search and image search service duckduckgo (requires magic Internet access), supports image search service Baidu image search (no magic Internet access), supports AI reply chat box [html plug-in], supports AI singing Auto-Convert-Music, supports playlist [html plug-in], supports dancing function, supports expression video playback, supports head touching action, supports gift smashing action, supports singing automatic start dancing function, chat and singing automatic cycle swing action, supports multi scene switching, background music switching, day and night automatic switching scene, supports open singing and painting, let AI automatically judge the content.