
ESP32_AI_LLM
本项目使用esp32、esp32s3接入讯飞星火、豆包、chatgpt等大模型,实现语音对话聊天功能,支持语音唤醒、连续对话、音乐播放等功能,同时外接了一块显示屏实时显示对话的内容。
Stars: 82
ESP32_AI_LLM is a project that uses ESP32 to connect to Xunfei Xinghuo, Dou Bao, and Tongyi Qianwen large models to achieve voice chat functions, supporting online voice wake-up, continuous conversation, music playback, and real-time display of conversation content on an external screen. The project requires specific hardware components and provides functionalities such as voice wake-up, voice conversation, convenient network configuration, music playback, volume adjustment, LED control, model switching, and screen display. Users can deploy the project by setting up Xunfei services, cloning the repository, configuring necessary parameters, installing drivers, compiling, and burning the code.
README:
本项目使用esp32接入讯飞星火大模型、豆包大模型(流式调用)、通义千问大模型实现语音对话聊天功能,支持在线语音唤醒、连续对话、音乐播放等功能,同时外接了一块显示屏实时显示对话的内容。
1.进入讯飞开发平台主页(https://www.xfyun.cn),注册账号,然后进入控制台,创建新应用。
2.开通相关服务:
- llm大模型服务:
- stt语音转文字服务:
进入火山引擎主页(https://console.volcengine.com),注册账号,实名认证。 主页->产品->豆包大模型(火山方舟)->立即体验->API Key管理->创建API Key->开通管理->开通你想使用的大模型服务->在线推理->创建推理接入点
进入阿里云百炼大模型服务平台(https://bailian.console.aliyun.com),支付宝扫码登录,或者注册账号。
使用vscode中的platformIO插件
ESP-WROOM-32、INMP441全向麦克风、MAX98357 I2S音频放大器模块、喇叭、1.8寸(128x160)RGB_TFT屏幕、面包板(400孔85x55mm)两块、面包板跳线若干、数据线一条、led灯一个(可选)
- 注意事项:其中ESP32需要安装相应的驱动程序
麦克风:
- VDD -> 3.3v
- GND -> GND
- SD -> GPIO22
- WS -> GPIO15
- SCK -> GPIO4
音频放大模块:
- Vin -> VIN
- GND -> GND
- LRC -> GPIO27
- BCLK -> GPIO26
- DIN -> GPIO25
1.8寸OLED屏幕:
- VDD -> VIN
- GND -> GND
- SCL -> GPIO18
- SDA -> GPIO23
- RST -> GPIO12
- DC -> GPIO32
- CS -> GPIO5
led灯:
- 正极 -> GPIO33
- 负极 -> GND
连接成品图在最后
- 设置参考:

setup初始化:
- 初始化串口通信、引脚配置、屏幕显示、录音模块Audio1、音频输出模块Audio2。
- 初始化Preferences,调用wifiConnect()连接网络。
- 调用getTimeFromServer()从百度服务器获取当前日期和时间,然后调用getUrl()生成url和url1(分别用于星火大模型和语音识别的鉴权)。
- 如果网络连接成功,则开始对话;如果连接失败,esp32启动热点和web服务器。
loop循环:
- 轮询处理WebSocket客户端消息,检查和处理从服务器接收的消息、发送等待发送的数据,维护与服务器的连接。
- 如果有多段语音需要播放,调用voiceplay()函数播放后续的语音。
- 调用audio2.loop()确保音频流的连续和稳定播放。
- 没有音频播放时,熄灭板载LED;有音频播放时,点亮板载LED。
- 进入待机模式,启动唤醒词识别,可在onMessageCallback1()中自定义唤醒词。
- 检测到板载boot按键被按下时,连接WebSocket服务器1(语音转文字)并开启录音,在8秒内没有说话就会结束本轮对话,然后进入待机模式,启动唤醒词识别。如果有说话,录音结束后调用讯飞STT服务API接口将语音转文本。如果文本内容为空,回复“对不起,我没有听清,可以再说一遍吗?”;不为空时连接WebSocket服务器(大模型),将文本发送给星火大模型(可选豆包大模型),然后接收大模型回复文本,并发送给百度的TTS服务转语音播放,同时在屏幕上显示对话内容。
- 检测到AI说话完毕后,自动连接WebSocket服务器1(语音转文字)并开启录音,后面的与上一条相同,实现连续对话功能。
设备启动连接网络后会直接进入待机状态,开启录音并连接讯飞的stt服务进行唤醒词识别,如果长时间不使用,请断开设备电源,防止讯飞stt服务量的大量耗费。唤醒词可在main.cpp的第999行修改。
ESP32连接网络后,进行语音唤醒或者按下板载的boot键即可开始对话。项目使用INMP441全向麦克风模块接受用户的语音输入,然后调用科大讯飞的STT服务API接口,将语音数据发送进行语音识别,接收返回的信息并提取出识别结果。接收到识别结果后,调用科大讯飞的星火大模型(可选豆包大模型)的API接口,将识别结果发送至大模型,由大模型给出回答后,从返回的信息中提取出回答内容,并发送给百度的TTS服务,最终输出语音回答。
- 注意:没有屏幕也能正常进行对话
网络连接通过读取ESP32 flash的NVS中存储的Wi-Fi信息实现。设备启动后开始联网时,板载LED会闪烁,屏幕显示相应的连接状态信息。esp32处于断网状态时,ESP32启动AP模式,创建临时网络热点ESP32-Setup(初始密码为12345678)。手机或电脑连接此网络后,浏览器访问(http://192.168.4.1),出现配置网页界面,通过该网页界面,即可进行网络的配置。
配置界面包含以下功能:
- 输入目标Wi-Fi的SSID和密码后,点击Save按钮提交。如果Wi-Fi不存在,则添加到ESP32 flash的NVS中;如果存在,则修改密码。操作完成后,屏幕显示信息。
- 输入目标Wi-Fi的SSID后,按下Delete按钮,从ESP32 flash的NVS中删除Wi-Fi信息。操作完成后,屏幕显示信息。
- 点击List Wi-Fi Networks按钮,查看NVS中已存储的所有Wi-Fi信息。
音乐播放白嫖了网易云的音乐服务器,通过("https://music.163.com/song/media/outer/url?id=音乐数字id.mp3")即可访问音乐文件(vip音乐不支持)。
 音乐播放通过读取ESP32 flash的NVS中存储的音乐信息实现。esp32处于断网状态时,ESP32启动AP模式,创建临时网络热点ESP32-Setup(初始密码为12345678)。手机或电脑连接此网络后,浏览器访问(http://192.168.4.1),出现配置网页界面,通过该网页界面,即可进行音乐信息的添加与删除。
音乐播放通过读取ESP32 flash的NVS中存储的音乐信息实现。esp32处于断网状态时,ESP32启动AP模式,创建临时网络热点ESP32-Setup(初始密码为12345678)。手机或电脑连接此网络后,浏览器访问(http://192.168.4.1),出现配置网页界面,通过该网页界面,即可进行音乐信息的添加与删除。
配置界面包含以下功能:
- 输入目标音乐的名称和数字id后,点击Save按钮提交。如果音乐不存在,则添加到ESP32 flash的NVS中;如果存在,则修改数字id。操作完成后,屏幕显示信息。
需要注意的点:比较长的音乐名建议不要写全,因为stt不一定识别的出来,可能只能识别出一部分,然后就是尽量不要写英文名称,因为英文识别准确率太烂了。还有就是部分音乐播放到中间会重新开始播放,好像是网易云的问题。
- 输入目标音乐的名称后,按下Delete按钮,从ESP32 flash的NVS中删除音乐信息。操作完成后,屏幕显示信息。
- 点击List Saved Music按钮,查看NVS中已存储的所有音乐信息。
通过相关的语音指令,可以实现音量的调节与显示,led灯的开关。在AI说话时,按下boot键说出调节音量和开关灯的指令,esp32做出对应的反应后会继续刚才没说完的话。
在音乐正在播放时,按下boot键说出”暂停播放”指令,即可暂停播放,再按下boot键说出”恢复播放”指令,即可恢复播放。
在和AI进行对话时,通过说出“切换模型”指令(要具体的说出切换为第几个大模型或者大模型具体的名字),目前可以在豆包,星火,通义千问三个大模型之间进行切换。
使用一块1.8寸(128x160)RGB_TFT屏幕显示用户与大模型的对话内容等信息
- 下载vscode和platformIO插件
- 开通讯飞相关服务(可选:开通豆包大模型服务)
- 将项目克隆到本地,在vscode中打开整个文件夹,然后等待依赖库下载完毕(右下角的状态栏显示下载进度)
- 找到.pio\libdeps\upesy_wroom\TFT_eSPI路径下的User_Setup.h文件,删除它,然后将根目录下的User_Setup.h文件剪切粘贴过去
- 填写main.cpp中要求填写的讯飞账号参数(可选:填写豆包大模型的参数)
- 安装esp32的驱动
- 编译、烧录


For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for ESP32_AI_LLM
Similar Open Source Tools
ESP32_AI_LLM
ESP32_AI_LLM is a project that uses ESP32 to connect to Xunfei Xinghuo, Dou Bao, and Tongyi Qianwen large models to achieve voice chat functions, supporting online voice wake-up, continuous conversation, music playback, and real-time display of conversation content on an external screen. The project requires specific hardware components and provides functionalities such as voice wake-up, voice conversation, convenient network configuration, music playback, volume adjustment, LED control, model switching, and screen display. Users can deploy the project by setting up Xunfei services, cloning the repository, configuring necessary parameters, installing drivers, compiling, and burning the code.
VideoChat
VideoChat is a real-time voice interaction digital human tool that supports end-to-end voice solutions (GLM-4-Voice - THG) and cascade solutions (ASR-LLM-TTS-THG). Users can customize appearance and voice, support voice cloning, and achieve low first-packet delay of 3s. The tool offers various modules such as ASR, LLM, MLLM, TTS, and THG for different functionalities. It requires specific hardware and software configurations for local deployment, and provides options for weight downloads and customization of digital human appearance and voice. The tool also addresses known issues related to resource availability, video streaming optimization, and model loading.
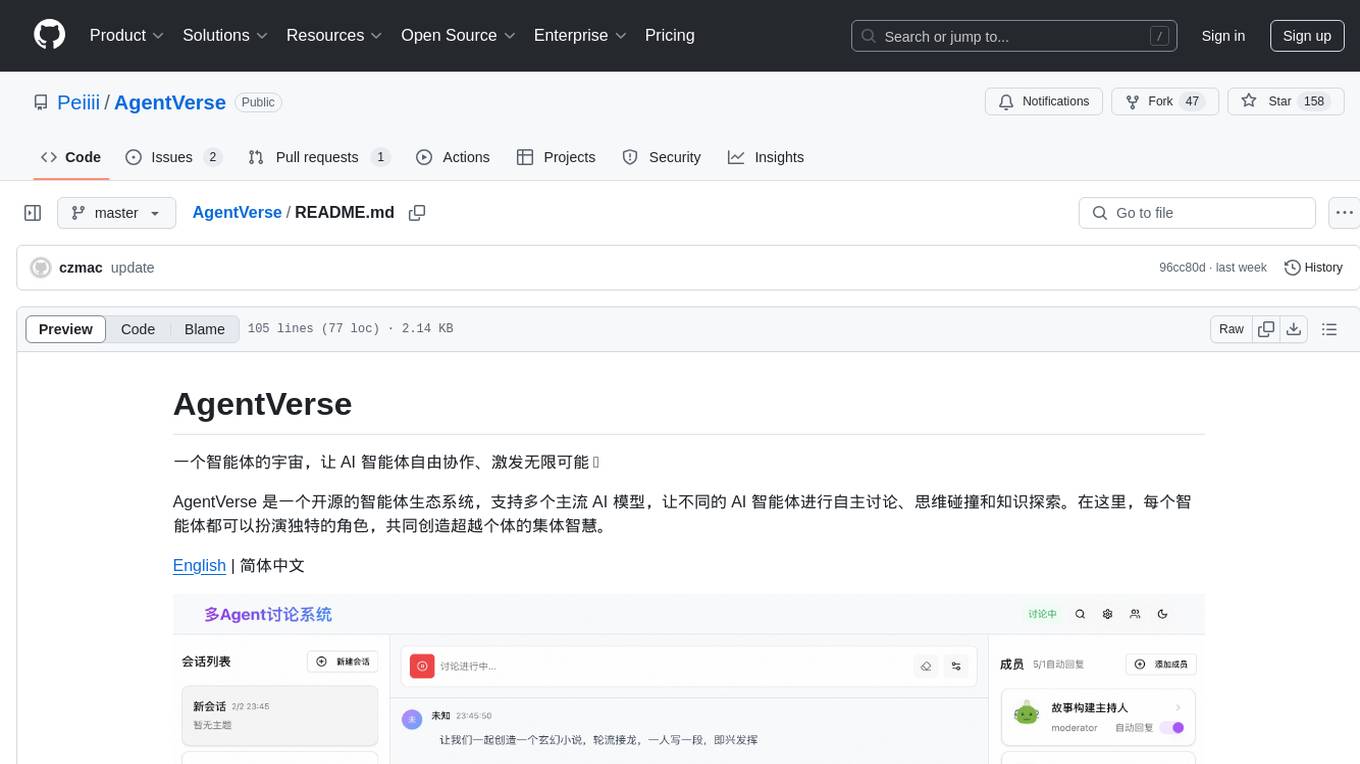
AgentVerse
AgentVerse is an open-source ecosystem for intelligent agents, supporting multiple mainstream AI models to facilitate autonomous discussions, thought collisions, and knowledge exploration. Each intelligent agent can play a unique role here, collectively creating wisdom beyond individuals.
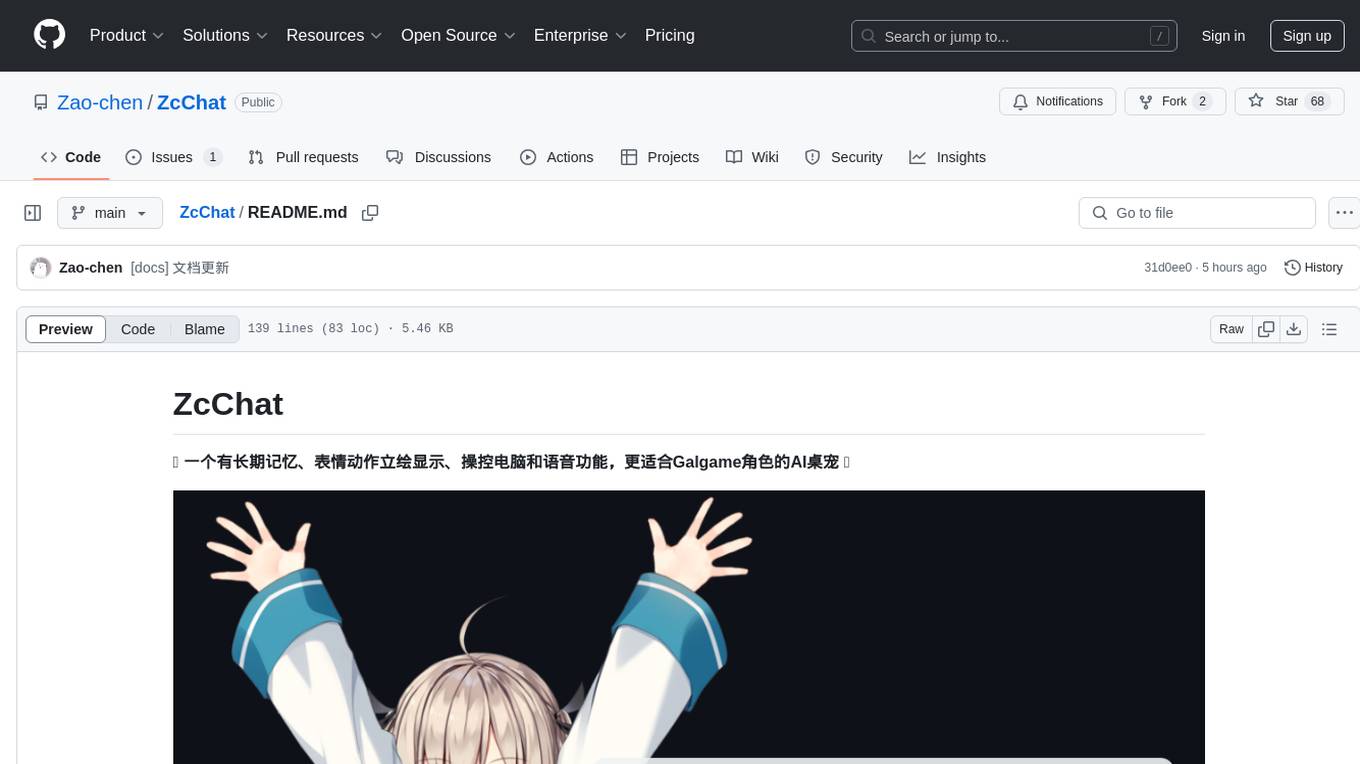
ZcChat
ZcChat is an AI desktop pet suitable for Galgame characters, featuring long-term memory, expressive actions, control over the computer, and voice functions. It utilizes Letta for AI long-term memory, Galgame-style character illustrations for more actions and expressions, and voice interaction with support for various voice synthesis tools like Vits. Users can configure characters, install Letta, set up voice synthesis and input, and control the pet to interact with the computer. The tool enhances visual and auditory experiences for users interested in AI desktop pets.

AI-YinMei
AI-YinMei is an AI virtual anchor Vtuber development tool (N card version). It supports fastgpt knowledge base chat dialogue, a complete set of solutions for LLM large language models: [fastgpt] + [one-api] + [Xinference], supports docking bilibili live broadcast barrage reply and entering live broadcast welcome speech, supports Microsoft edge-tts speech synthesis, supports Bert-VITS2 speech synthesis, supports GPT-SoVITS speech synthesis, supports expression control Vtuber Studio, supports painting stable-diffusion-webui output OBS live broadcast room, supports painting picture pornography public-NSFW-y-distinguish, supports search and image search service duckduckgo (requires magic Internet access), supports image search service Baidu image search (no magic Internet access), supports AI reply chat box [html plug-in], supports AI singing Auto-Convert-Music, supports playlist [html plug-in], supports dancing function, supports expression video playback, supports head touching action, supports gift smashing action, supports singing automatic start dancing function, chat and singing automatic cycle swing action, supports multi scene switching, background music switching, day and night automatic switching scene, supports open singing and painting, let AI automatically judge the content.
LLMForEverybody
LLMForEverybody is a comprehensive repository covering various aspects of large language models (LLMs) including pre-training, architecture, optimizers, activation functions, attention mechanisms, tokenization, parallel strategies, training frameworks, deployment, fine-tuning, quantization, GPU parallelism, prompt engineering, agent design, RAG architecture, enterprise deployment challenges, evaluation metrics, and current hot topics in the field. It provides detailed explanations, tutorials, and insights into the workings and applications of LLMs, making it a valuable resource for researchers, developers, and enthusiasts interested in understanding and working with large language models.
awesome-chatgpt-zh
The Awesome ChatGPT Chinese Guide project aims to help Chinese users understand and use ChatGPT. It collects various free and paid ChatGPT resources, as well as methods to communicate more effectively with ChatGPT in Chinese. The repository contains a rich collection of ChatGPT tools, applications, and examples.
qiaoqiaoyun
Qiaoqiaoyun is a new generation zero-code product that combines an AI application development platform, AI knowledge base, and zero-code platform, helping enterprises quickly build personalized business applications in an AI way. Users can build personalized applications that meet business needs without any code. Qiaoqiaoyun has comprehensive application building capabilities, form engine, workflow engine, and dashboard engine, meeting enterprise's normal requirements. It is also an AI application development platform based on LLM large language model and RAG open-source knowledge base question-answering system.
AIBotPublic
AIBotPublic is an open-source version of AIBotPro, a comprehensive AI tool that provides various features such as knowledge base construction, AI drawing, API hosting, and more. It supports custom plugins and parallel processing of multiple files. The tool is built using bootstrap4 for the frontend, .NET6.0 for the backend, and utilizes technologies like SqlServer, Redis, and Milvus for database and vector database functionalities. It integrates third-party dependencies like Baidu AI OCR, Milvus C# SDK, Google Search, and more to enhance its capabilities.
FisherAI
FisherAI is a Chrome extension designed to improve learning efficiency. It supports automatic summarization, web and video translation, multi-turn dialogue, and various large language models such as gpt/azure/gemini/deepseek/mistral/groq/yi/moonshot. Users can enjoy flexible and powerful AI tools with FisherAI.
LLMLanding
LLMLanding is a repository focused on practical implementation of large models, covering topics from theory to practice. It provides a structured learning path for training large models, including specific tasks like training 1B-scale models, exploring SFT, and working on specialized tasks such as code generation, NLP tasks, and domain-specific fine-tuning. The repository emphasizes a dual learning approach: quickly applying existing tools for immediate output benefits and delving into foundational concepts for long-term understanding. It offers detailed resources and pathways for in-depth learning based on individual preferences and goals, combining theory with practical application to avoid overwhelm and ensure sustained learning progress.
prose-polish
prose-polish is a tool for AI interaction through drag-and-drop cards, focusing on editing copy and manuscripts. It can recognize Markdown-formatted documents, automatically breaking them into paragraph cards. Users can create prefabricated prompt cards and quickly connect them to the manuscript for editing. The modified manuscript is still presented in card form, allowing users to drag it out as a new paragraph. To use it smoothly, users just need to remember one rule: 'Plug the plug into the socket!'
weixin-dyh-ai
WeiXin-Dyh-AI is a backend management system that supports integrating WeChat subscription accounts with AI services. It currently supports integration with Ali AI, Moonshot, and Tencent Hyunyuan. Users can configure different AI models to simulate and interact with AI in multiple modes: text-based knowledge Q&A, text-to-image drawing, image description, text-to-voice conversion, enabling human-AI conversations on WeChat. The system allows hierarchical AI prompt settings at system, subscription account, and WeChat user levels. Users can configure AI model types, providers, and specific instances. The system also supports rules for allocating models and keys at different levels. It addresses limitations of WeChat's messaging system and offers features like text-based commands and voice support for interactions with AI.
claude-pro
Claude Pro is a powerful AI conversational model that excels in handling complex instructions, understanding context, and generating natural text. It is considered a top alternative to ChatGPT Plus, offering high-quality content with almost no AI traces. The article provides detailed information on what Claude is, how to access it in China, how to register, and how to subscribe using a foreign credit card. It also covers topics like using a stable VPN, obtaining a foreign virtual credit card, and a foreign phone number for registration. The process of purchasing a Claude Pro account in China is explained step by step, emphasizing the importance of following the platform's policies to avoid account suspension.

LLM-And-More
LLM-And-More is a one-stop solution for training and applying large models, covering the entire process from data processing to model evaluation, from training to deployment, and from idea to service. In this project, users can easily train models through this project and generate the required product services with one click.
For similar tasks
ESP32_AI_LLM
ESP32_AI_LLM is a project that uses ESP32 to connect to Xunfei Xinghuo, Dou Bao, and Tongyi Qianwen large models to achieve voice chat functions, supporting online voice wake-up, continuous conversation, music playback, and real-time display of conversation content on an external screen. The project requires specific hardware components and provides functionalities such as voice wake-up, voice conversation, convenient network configuration, music playback, volume adjustment, LED control, model switching, and screen display. Users can deploy the project by setting up Xunfei services, cloning the repository, configuring necessary parameters, installing drivers, compiling, and burning the code.
py-xiaozhi
py-xiaozhi is a Python-based XiaoZhi voice client designed for learning through code and experiencing AI XiaoZhi's voice functions without hardware conditions. The repository is based on the xiaozhi-esp32 port. It supports AI voice interaction, visual multimodal capabilities, IoT device integration, online music playback, voice wake-up, automatic conversation mode, graphical user interface, command-line mode, cross-platform support, volume control, session management, encrypted audio transmission, automatic captcha handling, automatic MAC address retrieval, code modularization, and stability optimization.
whisplay-ai-chatbot
Whisplay-AI-Chatbot is a pocket-sized AI chatbot device built using a Raspberry Pi Zero 2w. It features a PiSugar Whisplay HAT with an LCD screen, on-board speaker, and microphone. Users can interact with the chatbot by pressing a button, speaking, and receiving responses, similar to a futuristic walkie-talkie. The tool supports various functionalities such as adjusting volume autonomously, resetting conversation history, local ASR and TTS capabilities, image generation, and integration with APIs like Google Gemini and Grok. It also offers support for LLM8850 AI Accelerator for offline capabilities like ASR, TTS, and LLM API. The chatbot saves conversation history and generated images in a data folder, and users can customize the tool with different enclosure cases available for Pi02 and Pi5 models.
trinityX
TrinityX is an open-source HPC, AI, and cloud platform designed to provide all services required in a modern system, with full customization options. It includes default services like Luna node provisioner, OpenLDAP, SLURM or OpenPBS, Prometheus, Grafana, OpenOndemand, and more. TrinityX also sets up NFS-shared directories, OpenHPC applications, environment modules, HA, and more. Users can install TrinityX on Enterprise Linux, configure network interfaces, set up passwordless authentication, and customize the installation using Ansible playbooks. The platform supports HA, OpenHPC integration, and provides detailed documentation for users to contribute to the project.
home-llm
Home LLM is a project that provides the necessary components to control your Home Assistant installation with a completely local Large Language Model acting as a personal assistant. The goal is to provide a drop-in solution to be used as a "conversation agent" component by Home Assistant. The 2 main pieces of this solution are Home LLM and Llama Conversation. Home LLM is a fine-tuning of the Phi model series from Microsoft and the StableLM model series from StabilityAI. The model is able to control devices in the user's house as well as perform basic question and answering. The fine-tuning dataset is a custom synthetic dataset designed to teach the model function calling based on the device information in the context. Llama Conversation is a custom component that exposes the locally running LLM as a "conversation agent" in Home Assistant. This component can be interacted with in a few ways: using a chat interface, integrating with Speech-to-Text and Text-to-Speech addons, or running the oobabooga/text-generation-webui project to provide access to the LLM via an API interface.
Linguflex
Linguflex is a project that aims to simulate engaging, authentic, human-like interaction with AI personalities. It offers voice-based conversation with custom characters, alongside an array of practical features such as controlling smart home devices, playing music, searching the internet, fetching emails, displaying current weather information and news, assisting in scheduling, and searching or generating images.
M.I.L.E.S
M.I.L.E.S. (Machine Intelligent Language Enabled System) is a voice assistant powered by GPT-4 Turbo, offering a range of capabilities beyond existing assistants. With its advanced language understanding, M.I.L.E.S. provides accurate and efficient responses to user queries. It seamlessly integrates with smart home devices, Spotify, and offers real-time weather information. Additionally, M.I.L.E.S. possesses persistent memory, a built-in calculator, and multi-tasking abilities. Its realistic voice, accurate wake word detection, and internet browsing capabilities enhance the user experience. M.I.L.E.S. prioritizes user privacy by processing data locally, encrypting sensitive information, and adhering to strict data retention policies.
leon
Leon is an open-source personal assistant who can live on your server. He does stuff when you ask him to. You can talk to him and he can talk to you. You can also text him and he can also text you. If you want to, Leon can communicate with you by being offline to protect your privacy.
For similar jobs

Qwen-TensorRT-LLM
Qwen-TensorRT-LLM is a project developed for the NVIDIA TensorRT Hackathon 2023, focusing on accelerating inference for the Qwen-7B-Chat model using TRT-LLM. The project offers various functionalities such as FP16/BF16 support, INT8 and INT4 quantization options, Tensor Parallel for multi-GPU parallelism, web demo setup with gradio, Triton API deployment for maximum throughput/concurrency, fastapi integration for openai requests, CLI interaction, and langchain support. It supports models like qwen2, qwen, and qwen-vl for both base and chat models. The project also provides tutorials on Bilibili and blogs for adapting Qwen models in NVIDIA TensorRT-LLM, along with hardware requirements and quick start guides for different model types and quantization methods.

dl_model_infer
This project is a c++ version of the AI reasoning library that supports the reasoning of tensorrt models. It provides accelerated deployment cases of deep learning CV popular models and supports dynamic-batch image processing, inference, decode, and NMS. The project has been updated with various models and provides tutorials for model exports. It also includes a producer-consumer inference model for specific tasks. The project directory includes implementations for model inference applications, backend reasoning classes, post-processing, pre-processing, and target detection and tracking. Speed tests have been conducted on various models, and onnx downloads are available for different models.

joliGEN
JoliGEN is an integrated framework for training custom generative AI image-to-image models. It implements GAN, Diffusion, and Consistency models for various image translation tasks, including domain and style adaptation with conservation of semantics. The tool is designed for real-world applications such as Controlled Image Generation, Augmented Reality, Dataset Smart Augmentation, and Synthetic to Real transforms. JoliGEN allows for fast and stable training with a REST API server for simplified deployment. It offers a wide range of options and parameters with detailed documentation available for models, dataset formats, and data augmentation.

ai-edge-torch
AI Edge Torch is a Python library that supports converting PyTorch models into a .tflite format for on-device applications on Android, iOS, and IoT devices. It offers broad CPU coverage with initial GPU and NPU support, closely integrating with PyTorch and providing good coverage of Core ATen operators. The library includes a PyTorch converter for model conversion and a Generative API for authoring mobile-optimized PyTorch Transformer models, enabling easy deployment of Large Language Models (LLMs) on mobile devices.

awesome-RK3588
RK3588 is a flagship 8K SoC chip by Rockchip, integrating Cortex-A76 and Cortex-A55 cores with NEON coprocessor for 8K video codec. This repository curates resources for developing with RK3588, including official resources, RKNN models, projects, development boards, documentation, tools, and sample code.

cl-waffe2
cl-waffe2 is an experimental deep learning framework in Common Lisp, providing fast, systematic, and customizable matrix operations, reverse mode tape-based Automatic Differentiation, and neural network model building and training features accelerated by a JIT Compiler. It offers abstraction layers, extensibility, inlining, graph-level optimization, visualization, debugging, systematic nodes, and symbolic differentiation. Users can easily write extensions and optimize their networks without overheads. The framework is designed to eliminate barriers between users and developers, allowing for easy customization and extension.

TensorRT-Model-Optimizer
The NVIDIA TensorRT Model Optimizer is a library designed to quantize and compress deep learning models for optimized inference on GPUs. It offers state-of-the-art model optimization techniques including quantization and sparsity to reduce inference costs for generative AI models. Users can easily stack different optimization techniques to produce quantized checkpoints from torch or ONNX models. The quantized checkpoints are ready for deployment in inference frameworks like TensorRT-LLM or TensorRT, with planned integrations for NVIDIA NeMo and Megatron-LM. The tool also supports 8-bit quantization with Stable Diffusion for enterprise users on NVIDIA NIM. Model Optimizer is available for free on NVIDIA PyPI, and this repository serves as a platform for sharing examples, GPU-optimized recipes, and collecting community feedback.

depthai
This repository contains a demo application for DepthAI, a tool that can load different networks, create pipelines, record video, and more. It provides documentation for installation and usage, including running programs through Docker. Users can explore DepthAI features via command line arguments or a clickable QT interface. Supported models include various AI models for tasks like face detection, human pose estimation, and object detection. The tool collects anonymous usage statistics by default, which can be disabled. Users can report issues to the development team for support and troubleshooting.