
ai-edge-torch
Supporting PyTorch models with the Google AI Edge TFLite runtime.
Stars: 460

AI Edge Torch is a Python library that supports converting PyTorch models into a .tflite format for on-device applications on Android, iOS, and IoT devices. It offers broad CPU coverage with initial GPU and NPU support, closely integrating with PyTorch and providing good coverage of Core ATen operators. The library includes a PyTorch converter for model conversion and a Generative API for authoring mobile-optimized PyTorch Transformer models, enabling easy deployment of Large Language Models (LLMs) on mobile devices.
README:
AI Edge Torch is a python library that supports converting PyTorch models into a .tflite format, which can then be run with TensorFlow Lite and MediaPipe. This enables applications for Android, iOS and IOT that can run models completely on-device. AI Edge Torch offers broad CPU coverage, with initial GPU and NPU support. AI Edge Torch seeks to closely integrate with PyTorch, building on top of torch.export() and providing good coverage of Core ATen operators.
To get started converting PyTorch models to TF Lite, see additional details in the PyTorch converter section. For the particular case of Large Language Models (LLMs) and transformer-based models, the Generative API supports model authoring and quantization to enable improved on device performance.
Although part of the same PyPi package, the PyTorch converter is a Beta release, while the Generative API is an Alpha release. Please see the release notes for additional information.
Here are the steps needed to convert a PyTorch model to a TFLite flatbuffer:
import torch
import torchvision
import ai_edge_torch
# Use resnet18 with pre-trained weights.
resnet18 = torchvision.models.resnet18(torchvision.models.ResNet18_Weights.IMAGENET1K_V1)
sample_inputs = (torch.randn(1, 3, 224, 224),)
# Convert and serialize PyTorch model to a tflite flatbuffer. Note that we
# are setting the model to evaluation mode prior to conversion.
edge_model = ai_edge_torch.convert(resnet18.eval(), sample_inputs)
edge_model.export("resnet18.tflite")The getting started Jupyter notebook gives an initial walkthrough of the conversion process and can be tried out with Google Colab.
Additional technical details of the PyTorch Converter are here.
The AI Edge Torch Generative API is a Torch native library for authoring mobile-optimized PyTorch Transformer models, which can be converted to TFLite, allowing users to easily deploy Large Language Models (LLMs) on mobile devices. Users can convert the models using the AI Edge Torch PyTorch Converter, and run them via the TensorFlow Lite runtime. See here.
Mobile app developers can also use the Edge Generative API to integrate PyTorch LLMs directly with the MediaPipe LLM Inference API for easy integration within their application code. See here.
More detailed documentation can be found here.
The Generative API is currently CPU-only, with planned support for GPU and NPU. A further future direction is to collaborate with the PyTorch community to ensure that frequently used transformer abstractions can be directly supported without reauthoring.
| Build Type | Status |
|---|---|
| Generative API (Linux) | |
| Model Coverage (Linux) | |
| Unit tests (Linux) | |
| Nightly Release |
- Python versions: >=3.10
- Operating system: Linux
- PyTorch:
- TensorFlow:
Set up a Python virtualenv:
python -m venv --prompt ai-edge-torch venv
source venv/bin/activateThe latest stable release can be installed with:
pip install ai-edge-torchAlternately, the nightly version can be installed with:
pip install ai-edge-torch-nightly- The list of versioned releases can be seen here.
- The full list of PyPi releases (including nightly builds) can be seen here.
See our contribution documentation.
Please create a GitHub issue with any questions.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for ai-edge-torch
Similar Open Source Tools
ai-edge-torch
AI Edge Torch is a Python library that supports converting PyTorch models into a .tflite format for on-device applications on Android, iOS, and IoT devices. It offers broad CPU coverage with initial GPU and NPU support, closely integrating with PyTorch and providing good coverage of Core ATen operators. The library includes a PyTorch converter for model conversion and a Generative API for authoring mobile-optimized PyTorch Transformer models, enabling easy deployment of Large Language Models (LLMs) on mobile devices.
AITemplate
AITemplate (AIT) is a Python framework that transforms deep neural networks into CUDA (NVIDIA GPU) / HIP (AMD GPU) C++ code for lightning-fast inference serving. It offers high performance close to roofline fp16 TensorCore (NVIDIA GPU) / MatrixCore (AMD GPU) performance on major models. AITemplate is unified, open, and flexible, supporting a comprehensive range of fusions for both GPU platforms. It provides excellent backward capability, horizontal fusion, vertical fusion, memory fusion, and works with or without PyTorch. FX2AIT is a tool that converts PyTorch models into AIT for fast inference serving, offering easy conversion and expanded support for models with unsupported operators.
AI-Playground
AI Playground is an open-source project and AI PC starter app designed for AI image creation, image stylizing, and chatbot functionalities on a PC powered by an Intel Arc GPU. It leverages libraries from GitHub and Huggingface, providing users with the ability to create AI-generated content and interact with chatbots. The tool requires specific hardware specifications and offers packaged installers for ease of setup. Users can also develop the project environment, link it to the development environment, and utilize alternative models for different AI tasks.

aphrodite-engine
Aphrodite is an inference engine optimized for serving HuggingFace-compatible models at scale. It leverages vLLM's Paged Attention technology to deliver high-performance model inference for multiple concurrent users. The engine supports continuous batching, efficient key/value management, optimized CUDA kernels, quantization support, distributed inference, and modern samplers. It can be easily installed and launched, with Docker support for deployment. Aphrodite requires Linux or Windows OS, Python 3.8 to 3.12, and CUDA >= 11. It is designed to utilize 90% of GPU VRAM but offers options to limit memory usage. Contributors are welcome to enhance the engine.

super-agent-party
A 3D AI desktop companion with endless possibilities! This repository provides a platform for enhancing the LLM API without code modification, supporting seamless integration of various functionalities such as knowledge bases, real-time networking, multimodal capabilities, automation, and deep thinking control. It offers one-click deployment to multiple terminals, ecological tool interconnection, standardized interface opening, and compatibility across all platforms. Users can deploy the tool on Windows, macOS, Linux, or Docker, and access features like intelligent agent deployment, VRM desktop pets, Tavern character cards, QQ bot deployment, and developer-friendly interfaces. The tool supports multi-service providers, extensive tool integration, and ComfyUI workflows. Hardware requirements are minimal, making it suitable for various deployment scenarios.
podman-desktop-extension-ai-lab
Podman AI Lab is an open source extension for Podman Desktop designed to work with Large Language Models (LLMs) on a local environment. It features a recipe catalog with common AI use cases, a curated set of open source models, and a playground for learning, prototyping, and experimentation. Users can quickly and easily get started bringing AI into their applications without depending on external infrastructure, ensuring data privacy and security.

pathway
Pathway is a Python data processing framework for analytics and AI pipelines over data streams. It's the ideal solution for real-time processing use cases like streaming ETL or RAG pipelines for unstructured data. Pathway comes with an **easy-to-use Python API** , allowing you to seamlessly integrate your favorite Python ML libraries. Pathway code is versatile and robust: **you can use it in both development and production environments, handling both batch and streaming data effectively**. The same code can be used for local development, CI/CD tests, running batch jobs, handling stream replays, and processing data streams. Pathway is powered by a **scalable Rust engine** based on Differential Dataflow and performs incremental computation. Your Pathway code, despite being written in Python, is run by the Rust engine, enabling multithreading, multiprocessing, and distributed computations. All the pipeline is kept in memory and can be easily deployed with **Docker and Kubernetes**. You can install Pathway with pip: `pip install -U pathway` For any questions, you will find the community and team behind the project on Discord.
ainodes-engine
aiNodes Engine is a Python-based AI image/motion picture generator node engine with a live execution chain, python code editor node, and plug-in support. It offers full modularity, colored background drop, and easy node creation with IDE annotations. The project is officially supported by Deforum and incorporates various open-source projects like ComfyUI. It is designed to be flexible, with an Unreal-like execution chain, supporting features such as Deforum, Stable Diffusion, Upscalers, Kandinsky, ControlNet, and more. The engine allows for background separation, human matting/masking, compositing, drag and drop, subgraphs, and graph saving/loading from image metadata. It aims to provide a unique, controllable manner of working with a strict user-declared execution chain.

wandb
Weights & Biases (W&B) is a platform that helps users build better machine learning models faster by tracking and visualizing all components of the machine learning pipeline, from datasets to production models. It offers tools for tracking, debugging, evaluating, and monitoring machine learning applications. W&B provides integrations with popular frameworks like PyTorch, TensorFlow/Keras, Hugging Face Transformers, PyTorch Lightning, XGBoost, and Sci-Kit Learn. Users can easily log metrics, visualize performance, and compare experiments using W&B. The platform also supports hosting options in the cloud or on private infrastructure, making it versatile for various deployment needs.
modular
The Modular Platform is a unified suite of AI libraries and tools designed for AI development and deployment. It abstracts hardware complexity to enable running popular open models with high GPU and CPU performance without code changes. The repository contains over 450,000 lines of code from 6000+ contributors, making it one of the largest open-source repositories for CPU and GPU kernels. Key components include the Mojo standard library, MAX GPU and CPU kernels, MAX inference server, MAX model pipelines, and code examples. The repository has main and stable branches for nightly builds and stable releases, respectively. Contributions are accepted for the Mojo standard library, MAX AI kernels, code examples, and Mojo docs.

supervisely
Supervisely is a computer vision platform that provides a range of tools and services for developing and deploying computer vision solutions. It includes a data labeling platform, a model training platform, and a marketplace for computer vision apps. Supervisely is used by a variety of organizations, including Fortune 500 companies, research institutions, and government agencies.
oneAPI-samples
The oneAPI-samples repository contains a collection of samples for the Intel oneAPI Toolkits. These samples cover various topics such as AI and analytics, end-to-end workloads, features and functionality, getting started samples, Jupyter notebooks, direct programming, C++, Fortran, libraries, publications, rendering toolkit, and tools. Users can find samples based on expertise, programming language, and target device. The repository structure is organized by high-level categories, and platform validation includes Ubuntu 22.04, Windows 11, and macOS. The repository provides instructions for getting samples, including cloning the repository or downloading specific tagged versions. Users can also use integrated development environments (IDEs) like Visual Studio Code. The code samples are licensed under the MIT license.
home-llm
Home LLM is a project that provides the necessary components to control your Home Assistant installation with a completely local Large Language Model acting as a personal assistant. The goal is to provide a drop-in solution to be used as a "conversation agent" component by Home Assistant. The 2 main pieces of this solution are Home LLM and Llama Conversation. Home LLM is a fine-tuning of the Phi model series from Microsoft and the StableLM model series from StabilityAI. The model is able to control devices in the user's house as well as perform basic question and answering. The fine-tuning dataset is a custom synthetic dataset designed to teach the model function calling based on the device information in the context. Llama Conversation is a custom component that exposes the locally running LLM as a "conversation agent" in Home Assistant. This component can be interacted with in a few ways: using a chat interface, integrating with Speech-to-Text and Text-to-Speech addons, or running the oobabooga/text-generation-webui project to provide access to the LLM via an API interface.

llm-app
Pathway's LLM (Large Language Model) Apps provide a platform to quickly deploy AI applications using the latest knowledge from data sources. The Python application examples in this repository are Docker-ready, exposing an HTTP API to the frontend. These apps utilize the Pathway framework for data synchronization, API serving, and low-latency data processing without the need for additional infrastructure dependencies. They connect to document data sources like S3, Google Drive, and Sharepoint, offering features like real-time data syncing, easy alert setup, scalability, monitoring, security, and unification of application logic.

spring-ai
The Spring AI project provides a Spring-friendly API and abstractions for developing AI applications. It offers a portable client API for interacting with generative AI models, enabling developers to easily swap out implementations and access various models like OpenAI, Azure OpenAI, and HuggingFace. Spring AI also supports prompt engineering, providing classes and interfaces for creating and parsing prompts, as well as incorporating proprietary data into generative AI without retraining the model. This is achieved through Retrieval Augmented Generation (RAG), which involves extracting, transforming, and loading data into a vector database for use by AI models. Spring AI's VectorStore abstraction allows for seamless transitions between different vector database implementations.
basalt
Basalt is a lightweight and flexible CSS framework designed to help developers quickly build responsive and modern websites. It provides a set of pre-designed components and utilities that can be easily customized to create unique and visually appealing web interfaces. With Basalt, developers can save time and effort by leveraging its modular structure and responsive design principles to create professional-looking websites with ease.
For similar tasks
ai-edge-torch
AI Edge Torch is a Python library that supports converting PyTorch models into a .tflite format for on-device applications on Android, iOS, and IoT devices. It offers broad CPU coverage with initial GPU and NPU support, closely integrating with PyTorch and providing good coverage of Core ATen operators. The library includes a PyTorch converter for model conversion and a Generative API for authoring mobile-optimized PyTorch Transformer models, enabling easy deployment of Large Language Models (LLMs) on mobile devices.
Ollama-Colab-Integration
Ollama Colab Integration V4 is a tool designed to enhance the interaction and management of large language models. It allows users to quantize models within their notebook environment, access a variety of models through a user-friendly interface, and manage public endpoints efficiently. The tool also provides features like LiteLLM proxy control, model insights, and customizable model file templating. Users can troubleshoot model loading issues, CPU fallback strategies, and manage VRAM and RAM effectively. Additionally, the tool offers functionalities for downloading model files from Hugging Face, model conversion with high precision, model quantization using Q and Kquants, and securely uploading converted models to Hugging Face.
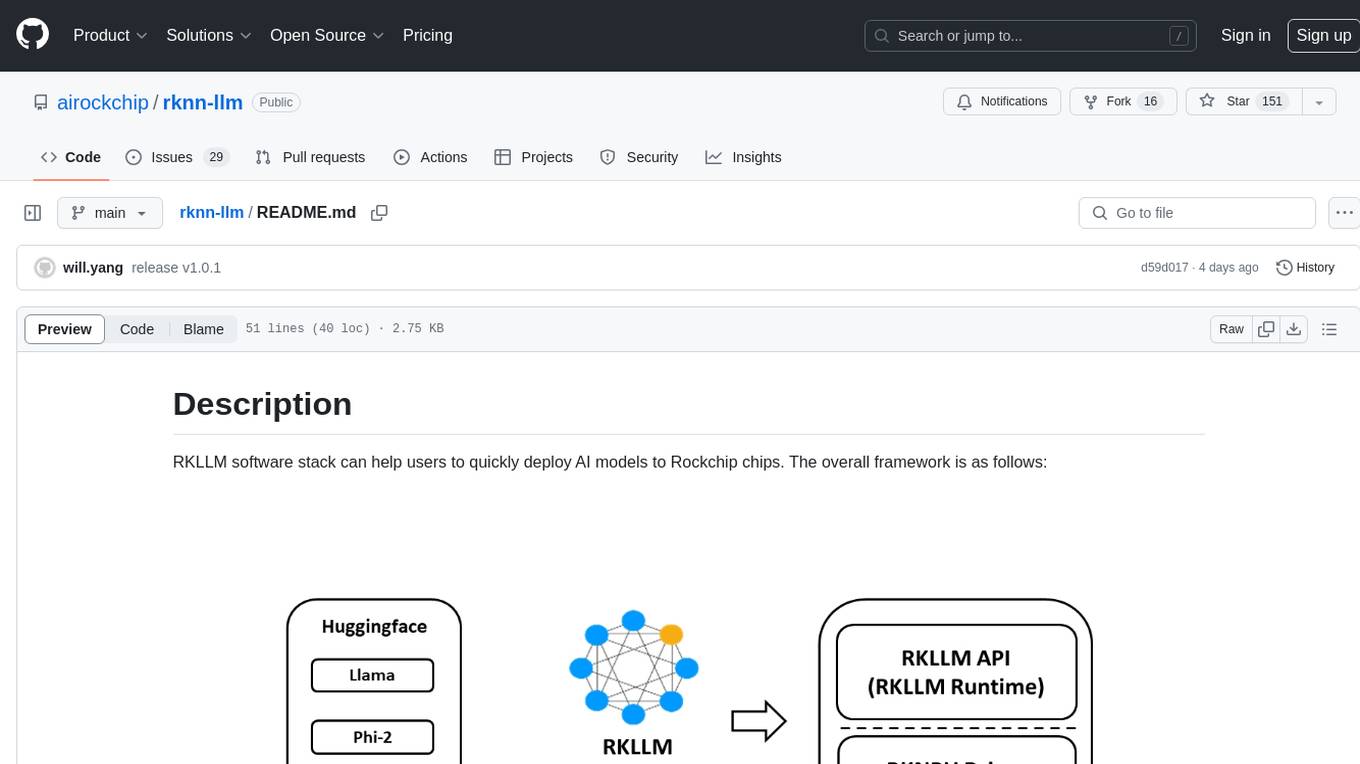
rknn-llm
RKLLM software stack is a toolkit designed to help users quickly deploy AI models to Rockchip chips. It consists of RKLLM-Toolkit for model conversion and quantization, RKLLM Runtime for deploying models on Rockchip NPU platform, and RKNPU kernel driver for hardware interaction. The toolkit supports RK3588 and RK3576 series chips and various models like TinyLLAMA, Qwen, Phi, ChatGLM3, Gemma, InternLM2, and MiniCPM. Users can download packages, docker images, examples, and docs from RKLLM_SDK. Additionally, RKNN-Toolkit2 SDK is available for deploying additional AI models.

LLMinator
LLMinator is a Gradio-based tool with an integrated chatbot designed to locally run and test Language Model Models (LLMs) directly from HuggingFace. It provides an easy-to-use interface made with Gradio, LangChain, and Torch, offering features such as context-aware streaming chatbot, inbuilt code syntax highlighting, loading any LLM repo from HuggingFace, support for both CPU and CUDA modes, enabling LLM inference with llama.cpp, and model conversion capabilities.

xFasterTransformer
xFasterTransformer is an optimized solution for Large Language Models (LLMs) on the X86 platform, providing high performance and scalability for inference on mainstream LLM models. It offers C++ and Python APIs for easy integration, along with example codes and benchmark scripts. Users can prepare models in a different format, convert them, and use the APIs for tasks like encoding input prompts, generating token ids, and serving inference requests. The tool supports various data types and models, and can run in single or multi-rank modes using MPI. A web demo based on Gradio is available for popular LLM models like ChatGLM and Llama2. Benchmark scripts help evaluate model inference performance quickly, and MLServer enables serving with REST and gRPC interfaces.
BodhiApp
Bodhi App runs Open Source Large Language Models locally, exposing LLM inference capabilities as OpenAI API compatible REST APIs. It leverages llama.cpp for GGUF format models and huggingface.co ecosystem for model downloads. Users can run fine-tuned models for chat completions, create custom aliases, and convert Huggingface models to GGUF format. The CLI offers commands for environment configuration, model management, pulling files, serving API, and more.
lm.rs
lm.rs is a tool that allows users to run inference on Language Models locally on the CPU using Rust. It supports LLama3.2 1B and 3B models, with a WebUI also available. The tool provides benchmarks and download links for models and tokenizers, with recommendations for quantization options. Users can convert models from Google/Meta on huggingface using provided scripts. The tool can be compiled with cargo and run with various arguments for model weights, tokenizer, temperature, and more. Additionally, a backend for the WebUI can be compiled and run to connect via the web interface.
LiteRT
LiteRT is Google's open-source high-performance runtime for on-device AI, previously known as TensorFlow Lite. The repository is currently not intended for open-source development, but aims to evolve to allow direct building and contributions. LiteRT supports Python versions 3.9, 3.10, 3.11 on Linux and MacOS. It ensures compatibility with existing .tflite file extension and format, offering conversion tools and continued active development under the name LiteRT.
For similar jobs

Qwen-TensorRT-LLM
Qwen-TensorRT-LLM is a project developed for the NVIDIA TensorRT Hackathon 2023, focusing on accelerating inference for the Qwen-7B-Chat model using TRT-LLM. The project offers various functionalities such as FP16/BF16 support, INT8 and INT4 quantization options, Tensor Parallel for multi-GPU parallelism, web demo setup with gradio, Triton API deployment for maximum throughput/concurrency, fastapi integration for openai requests, CLI interaction, and langchain support. It supports models like qwen2, qwen, and qwen-vl for both base and chat models. The project also provides tutorials on Bilibili and blogs for adapting Qwen models in NVIDIA TensorRT-LLM, along with hardware requirements and quick start guides for different model types and quantization methods.

dl_model_infer
This project is a c++ version of the AI reasoning library that supports the reasoning of tensorrt models. It provides accelerated deployment cases of deep learning CV popular models and supports dynamic-batch image processing, inference, decode, and NMS. The project has been updated with various models and provides tutorials for model exports. It also includes a producer-consumer inference model for specific tasks. The project directory includes implementations for model inference applications, backend reasoning classes, post-processing, pre-processing, and target detection and tracking. Speed tests have been conducted on various models, and onnx downloads are available for different models.

joliGEN
JoliGEN is an integrated framework for training custom generative AI image-to-image models. It implements GAN, Diffusion, and Consistency models for various image translation tasks, including domain and style adaptation with conservation of semantics. The tool is designed for real-world applications such as Controlled Image Generation, Augmented Reality, Dataset Smart Augmentation, and Synthetic to Real transforms. JoliGEN allows for fast and stable training with a REST API server for simplified deployment. It offers a wide range of options and parameters with detailed documentation available for models, dataset formats, and data augmentation.
ai-edge-torch
AI Edge Torch is a Python library that supports converting PyTorch models into a .tflite format for on-device applications on Android, iOS, and IoT devices. It offers broad CPU coverage with initial GPU and NPU support, closely integrating with PyTorch and providing good coverage of Core ATen operators. The library includes a PyTorch converter for model conversion and a Generative API for authoring mobile-optimized PyTorch Transformer models, enabling easy deployment of Large Language Models (LLMs) on mobile devices.

awesome-RK3588
RK3588 is a flagship 8K SoC chip by Rockchip, integrating Cortex-A76 and Cortex-A55 cores with NEON coprocessor for 8K video codec. This repository curates resources for developing with RK3588, including official resources, RKNN models, projects, development boards, documentation, tools, and sample code.

cl-waffe2
cl-waffe2 is an experimental deep learning framework in Common Lisp, providing fast, systematic, and customizable matrix operations, reverse mode tape-based Automatic Differentiation, and neural network model building and training features accelerated by a JIT Compiler. It offers abstraction layers, extensibility, inlining, graph-level optimization, visualization, debugging, systematic nodes, and symbolic differentiation. Users can easily write extensions and optimize their networks without overheads. The framework is designed to eliminate barriers between users and developers, allowing for easy customization and extension.

TensorRT-Model-Optimizer
The NVIDIA TensorRT Model Optimizer is a library designed to quantize and compress deep learning models for optimized inference on GPUs. It offers state-of-the-art model optimization techniques including quantization and sparsity to reduce inference costs for generative AI models. Users can easily stack different optimization techniques to produce quantized checkpoints from torch or ONNX models. The quantized checkpoints are ready for deployment in inference frameworks like TensorRT-LLM or TensorRT, with planned integrations for NVIDIA NeMo and Megatron-LM. The tool also supports 8-bit quantization with Stable Diffusion for enterprise users on NVIDIA NIM. Model Optimizer is available for free on NVIDIA PyPI, and this repository serves as a platform for sharing examples, GPU-optimized recipes, and collecting community feedback.

depthai
This repository contains a demo application for DepthAI, a tool that can load different networks, create pipelines, record video, and more. It provides documentation for installation and usage, including running programs through Docker. Users can explore DepthAI features via command line arguments or a clickable QT interface. Supported models include various AI models for tasks like face detection, human pose estimation, and object detection. The tool collects anonymous usage statistics by default, which can be disabled. Users can report issues to the development team for support and troubleshooting.