
BodhiApp
Run Open Source/Open Weight LLMs locally with OpenAI compatible APIs
Stars: 130
Bodhi App runs Open Source Large Language Models locally, exposing LLM inference capabilities as OpenAI API compatible REST APIs. It leverages llama.cpp for GGUF format models and huggingface.co ecosystem for model downloads. Users can run fine-tuned models for chat completions, create custom aliases, and convert Huggingface models to GGUF format. The CLI offers commands for environment configuration, model management, pulling files, serving API, and more.
README:
![]()
![]()
![]()
![]()
Bodhi App allows you to run Open Source LLMs locally. It utilizes the Huggingface ecosystem for accessing open-source LLM weights and information and is powered by llama.cpp.
While many apps that help you run LLMs locally are targeted at technical users, Bodhi App is designed with both technical and non-technical users in mind.
For technical users, it provides OpenAI-compatible chat completions and models API endpoints. It includes comprehensive API documentation following OpenAPI standards and features a built-in SwaggerUI that allows developers to explore and test all API endpoints live.
For non-technical users, it comes with a built-in Chat UI that is quick to start and easy to understand. Users can quickly get started with open-source models and adjust various settings to suit their needs. The app also enables users to discover, explore, and download new open-source models that fit their requirements and are compatible with their local hardware.
- Built-in Chat UI: Enjoy an intuitive, responsive chat interface with real-time streaming, markdown support, and customizable settings
- Model Management: Download and manage GGUF model files directly from HuggingFace
- API Token Management: Securely generate and manage API tokens for external integrations
- Dynamic App Settings: Easily adjust application parameters (like execution variant and idle timeout) on the fly
- Responsive Design: A fully adaptive layout that works seamlessly across desktop and mobile devices
- Robust Error Handling: Comprehensive error logging and troubleshooting guides to help quickly identify and resolve issues
Bodhi App is currently released only for the Mac platform. You can install it either by downloading the release from the GitHub release page or using Homebrew.
Bodhi App hosts its external cask at BodhiSearch/homebrew-apps. Install Bodhi App using this command:
brew install --cask BodhiSearch/apps/bodhiOnce installed, launch Bodhi App.app from the /Applications folder. You should see the Bodhi App icon in your system tray. Launch the homepage from the system tray menu by selecting Open Homepage.
Download the latest release for your platform from the Releases page.
Unzip and move Bodhi.app to your /Applications folder, then launch it. You should see the Bodhi App icon in your system tray. Launch the homepage from the system tray menu by selecting Open Homepage.
Bodhi App is available as Docker images with multiple hardware acceleration variants. Each variant is optimized for specific hardware configurations to provide the best performance.
- CPU Variant: Standard CPU-only inference for maximum compatibility (multi-platform: AMD64 + ARM64)
- CUDA Variant: NVIDIA GPU acceleration for faster inference on NVIDIA hardware
- ROCm Variant: AMD GPU acceleration for AMD graphics cards
- Vulkan Variant: Cross-vendor GPU acceleration supporting multiple GPU vendors
CPU Variant (Most Compatible - Auto-detects AMD64/ARM64):
docker run -p 8080:8080 \
-v ./bodhi_home:/data/bodhi_home \
-v ./hf_home:/data/hf_home \
ghcr.io/bodhisearch/bodhiapp:latest-cpuCUDA Variant (NVIDIA GPU):
docker run --gpus all -p 8080:8080 \
-v ./bodhi_home:/data/bodhi_home \
-v ./hf_home:/data/hf_home \
ghcr.io/bodhisearch/bodhiapp:latest-cudaROCm Variant (AMD GPU):
docker run --device=/dev/kfd --device=/dev/dri --group-add video -p 8080:8080 \
-v ./bodhi_home:/data/bodhi_home \
-v ./hf_home:/data/hf_home \
ghcr.io/bodhisearch/bodhiapp:latest-rocmVulkan Variant (Cross-vendor GPU):
docker run --device=/dev/dri -p 8080:8080 \
-v ./bodhi_home:/data/bodhi_home \
-v ./hf_home:/data/hf_home \
ghcr.io/bodhisearch/bodhiapp:latest-vulkan- CPU: Standard x86_64 (AMD64) or ARM64 processor (auto-detected)
- CUDA: NVIDIA GPU with CUDA 12.4+ support and compatible drivers
- ROCm: AMD GPU with ROCm 6.4+ support and compatible drivers
- Vulkan: GPU with Vulkan API support and compatible drivers
-
/data/bodhi_home: Application data, configuration, and downloaded models -
/data/hf_home: HuggingFace cache directory for model downloads
After starting the container, Bodhi App will be available at http://localhost:8080.
On first launch, Bodhi App starts with a setup flow. Follow this process to configure and install Bodhi App for your local machine and get started.
Bodhi App comes with built-in documentation:
- User Guide: Access at http://localhost:1135/docs/
- Technical Documentation: Available as OpenAPI Swagger UI at http://localhost:1135/swagger-ui/
Bodhi App provides a TypeScript client for easy integration with the API:
npm install @bodhiapp/ts-clientimport { BodhiClient } from "@bodhiapp/ts-client";
// Initialize the client
const client = new BodhiClient({
baseUrl: "http://localhost:1135",
apiKey: "your-api-key",
});
// Create a chat completion
async function chatWithBodhi() {
const response = await client.createChatCompletion({
model: "gpt-3.5-turbo",
messages: [
{ role: "system", content: "You are a helpful assistant." },
{ role: "user", content: "Hello, who are you?" },
],
});
console.log(response.choices[0].message.content);
}For more information, see the ts-client documentation.
 {width=600px}
{width=600px}
(Open up a pull request on README.md to include community integrations)
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for BodhiApp
Similar Open Source Tools
BodhiApp
Bodhi App runs Open Source Large Language Models locally, exposing LLM inference capabilities as OpenAI API compatible REST APIs. It leverages llama.cpp for GGUF format models and huggingface.co ecosystem for model downloads. Users can run fine-tuned models for chat completions, create custom aliases, and convert Huggingface models to GGUF format. The CLI offers commands for environment configuration, model management, pulling files, serving API, and more.
qwery-core
Qwery is a platform for querying and visualizing data using natural language without technical knowledge. It seamlessly integrates with various datasources, generates optimized queries, and delivers outcomes like result sets, dashboards, and APIs. Features include natural language querying, multi-database support, AI-powered agents, visual data apps, desktop & cloud options, template library, and extensibility through plugins. The project is under active development and not yet suitable for production use.
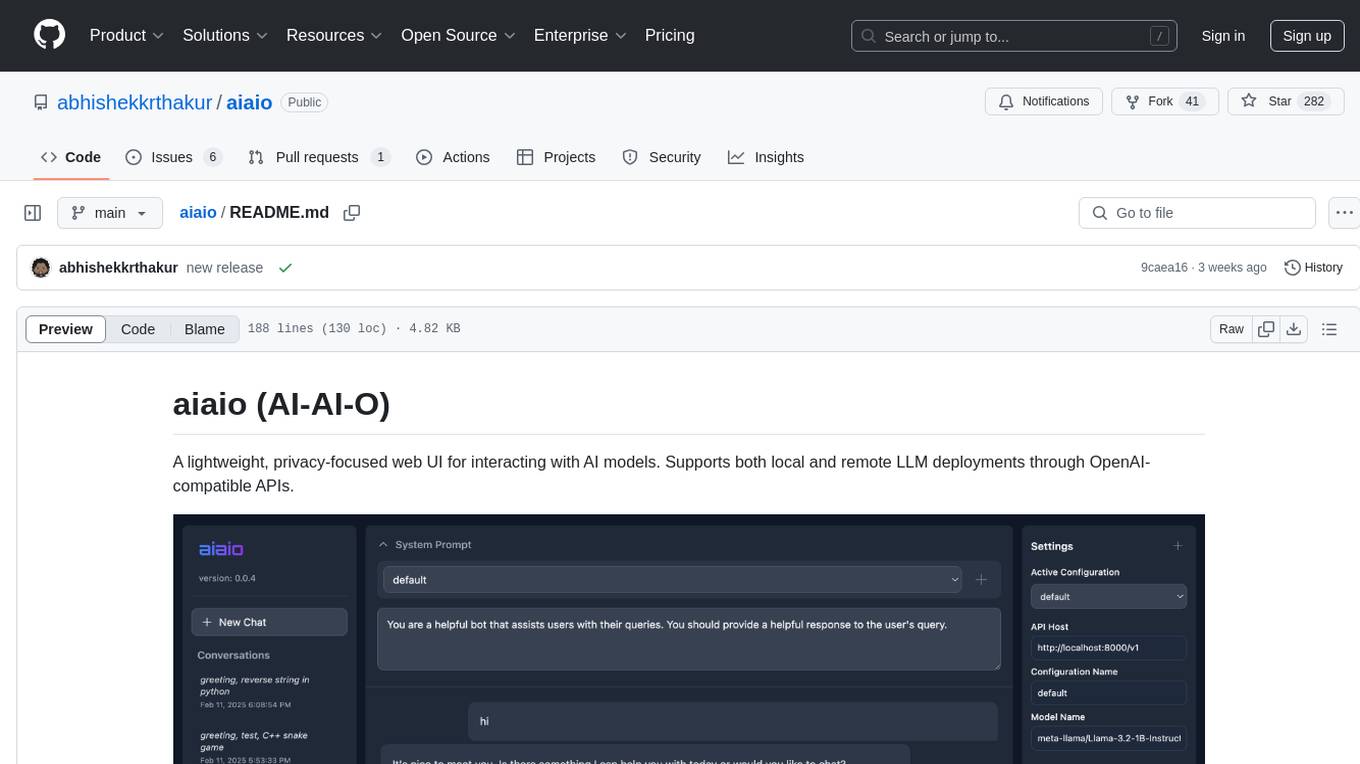
aiaio
aiaio (AI-AI-O) is a lightweight, privacy-focused web UI for interacting with AI models. It supports both local and remote LLM deployments through OpenAI-compatible APIs. The tool provides features such as dark/light mode support, local SQLite database for conversation storage, file upload and processing, configurable model parameters through UI, privacy-focused design, responsive design for mobile/desktop, syntax highlighting for code blocks, real-time conversation updates, automatic conversation summarization, customizable system prompts, WebSocket support for real-time updates, Docker support for deployment, multiple API endpoint support, and multiple system prompt support. Users can configure model parameters and API settings through the UI, handle file uploads, manage conversations, and use keyboard shortcuts for efficient interaction. The tool uses SQLite for storage with tables for conversations, messages, attachments, and settings. Contributions to the project are welcome under the Apache License 2.0.
codewalk
CodeWalk is a native cross-platform client for OpenCode server mode, built with Flutter. It provides an AI chat interface for coding interactions, multi-server profile management, session lifecycle management, worktree management, speech-to-text input, and more. The project follows Clean Architecture with Flutter, Dart, Provider for state management, Dio for HTTP client, SharedPreferences for local storage, GetIt for dependency injection, and Material Design 3 for design system.
Visionatrix
Visionatrix is a project aimed at providing easy use of ComfyUI workflows. It offers simplified setup and update processes, a minimalistic UI for daily workflow use, stable workflows with versioning and update support, scalability for multiple instances and task workers, multiple user support with integration of different user backends, LLM power for integration with Ollama/Gemini, and seamless integration as a service with backend endpoints and webhook support. The project is approaching version 1.0 release and welcomes new ideas for further implementation.
VibeSurf
VibeSurf is an open-source AI agentic browser that combines workflow automation with intelligent AI agents, offering faster, cheaper, and smarter browser automation. It allows users to create revolutionary browser workflows, run multiple AI agents in parallel, perform intelligent AI automation tasks, maintain privacy with local LLM support, and seamlessly integrate as a Chrome extension. Users can save on token costs, achieve efficiency gains, and enjoy deterministic workflows for consistent and accurate results. VibeSurf also provides a Docker image for easy deployment and offers pre-built workflow templates for common tasks.
CrewAI-Studio
CrewAI Studio is an application with a user-friendly interface for interacting with CrewAI, offering support for multiple platforms and various backend providers. It allows users to run crews in the background, export single-page apps, and use custom tools for APIs and file writing. The roadmap includes features like better import/export, human input, chat functionality, automatic crew creation, and multiuser environment support.
minimal-chat
MinimalChat is a minimal and lightweight open-source chat application with full mobile PWA support that allows users to interact with various language models, including GPT-4 Omni, Claude Opus, and various Local/Custom Model Endpoints. It focuses on simplicity in setup and usage while being fully featured and highly responsive. The application supports features like fully voiced conversational interactions, multiple language models, markdown support, code syntax highlighting, DALL-E 3 integration, conversation importing/exporting, and responsive layout for mobile use.
better-chatbot
Better Chatbot is an open-source AI chatbot designed for individuals and teams, inspired by various AI models. It integrates major LLMs, offers powerful tools like MCP protocol and data visualization, supports automation with custom agents and visual workflows, enables collaboration by sharing configurations, provides a voice assistant feature, and ensures an intuitive user experience. The platform is built with Vercel AI SDK and Next.js, combining leading AI services into one platform for enhanced chatbot capabilities.

TokenEater
TokenEater is a native macOS widget and menu bar app designed to monitor your Claude (Anthropic) AI usage in real-time. It provides detailed insights into your session, weekly usage across all models, dedicated Sonnet limits, and pacing information to help you manage your AI usage effectively. The app offers customizable themes, notifications for usage thresholds, automatic token refresh via Claude Code OAuth, automatic updates, SOCKS5 proxy support, and full localization in English and French. TokenEater ensures secure data flow between the menu bar app and desktop widget through a shared JSON file, providing a seamless user experience without compromising security. The tool is licensed under MIT, allowing users to freely use and modify it as needed.

bytebot
Bytebot is an open-source AI desktop agent that provides a virtual employee with its own computer to complete tasks for users. It can use various applications, download and organize files, log into websites, process documents, and perform complex multi-step workflows. By giving AI access to a complete desktop environment, Bytebot unlocks capabilities not possible with browser-only agents or API integrations, enabling complete task autonomy, document processing, and usage of real applications.
next-ai-draw-io
Next AI Draw.io is a next.js web application that integrates AI capabilities with draw.io diagrams. It allows users to create, modify, and enhance diagrams through natural language commands and AI-assisted visualization. Features include LLM-Powered Diagram Creation, Image-Based Diagram Replication, Diagram History, Interactive Chat Interface, and Smart Editing. The application uses Next.js for frontend framework, @ai-sdk/react for chat interface and AI interactions, and react-drawio for diagram representation and manipulation. Diagrams are represented as XML that can be rendered in draw.io, with AI processing commands to generate or modify the XML accordingly.
quests
Quests is an open-source app builder that allows users to build and run apps on their computer using various AI models. It provides a desktop app for local development, supports multiple projects simultaneously, offers version control, and enables exportable apps. Users can bring their own AI models from providers like OpenAI, Anthropic, Google, etc. The tool also includes a coding agent for targeted edits and real-time linting, making it suitable for developers looking to leverage AI in their app development workflow.
morphic
Morphic is an AI-powered answer engine with a generative UI. It utilizes a stack of Next.js, Vercel AI SDK, OpenAI, Tavily AI, shadcn/ui, Radix UI, and Tailwind CSS. To get started, fork and clone the repo, install dependencies, fill out secrets in the .env.local file, and run the app locally using 'bun dev'. You can also deploy your own live version of Morphic with Vercel. Verified models that can be specified to writers include Groq, LLaMA3 8b, and LLaMA3 70b.
chatnio
Chat Nio is a next-generation AIGC one-stop business solution that combines the advantages of frontend-oriented lightweight deployment projects with powerful API distribution systems. It offers rich model support, beautiful UI design, complete Markdown support, multi-theme support, internationalization support, text-to-image support, powerful conversation sync, model market & preset system, rich file parsing, full model internet search, Progressive Web App (PWA) support, comprehensive backend management, multiple billing methods, innovative model caching, and additional features. The project aims to address limitations in conversation synchronization, billing, file parsing, conversation URL sharing, channel management, and API call support found in existing AIGC commercial sites, while also providing a user-friendly interface design and C-end features.
gemini-cli
Gemini CLI is an open-source AI agent that provides lightweight access to Gemini, offering powerful capabilities like code understanding, generation, automation, integration, and advanced features. It is designed for developers who prefer working in the command line and offers extensibility through MCP support. The tool integrates directly into GitHub workflows and offers various authentication options for individual developers, enterprise teams, and production workloads. With features like code querying, editing, app generation, debugging, and GitHub integration, Gemini CLI aims to streamline development workflows and enhance productivity.
For similar tasks
Ollama-Colab-Integration
Ollama Colab Integration V4 is a tool designed to enhance the interaction and management of large language models. It allows users to quantize models within their notebook environment, access a variety of models through a user-friendly interface, and manage public endpoints efficiently. The tool also provides features like LiteLLM proxy control, model insights, and customizable model file templating. Users can troubleshoot model loading issues, CPU fallback strategies, and manage VRAM and RAM effectively. Additionally, the tool offers functionalities for downloading model files from Hugging Face, model conversion with high precision, model quantization using Q and Kquants, and securely uploading converted models to Hugging Face.
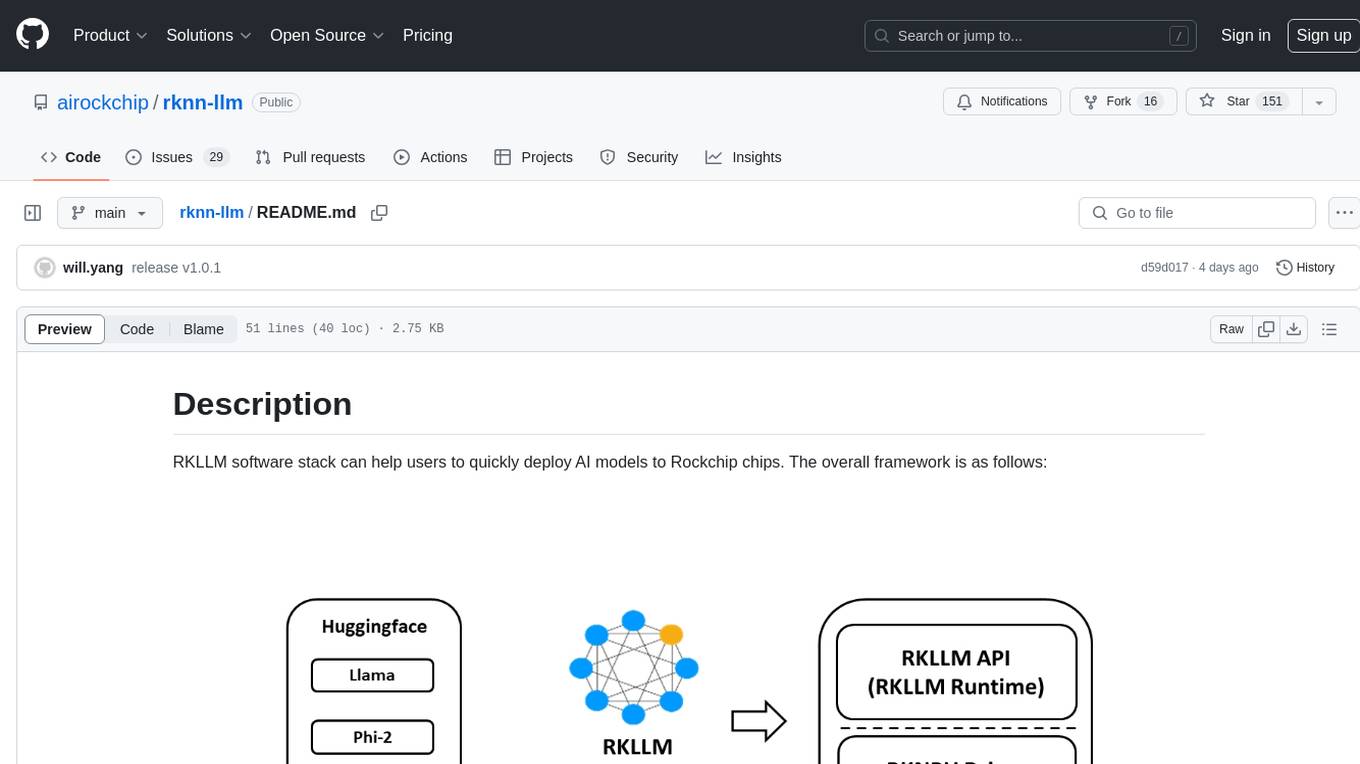
rknn-llm
RKLLM software stack is a toolkit designed to help users quickly deploy AI models to Rockchip chips. It consists of RKLLM-Toolkit for model conversion and quantization, RKLLM Runtime for deploying models on Rockchip NPU platform, and RKNPU kernel driver for hardware interaction. The toolkit supports RK3588 and RK3576 series chips and various models like TinyLLAMA, Qwen, Phi, ChatGLM3, Gemma, InternLM2, and MiniCPM. Users can download packages, docker images, examples, and docs from RKLLM_SDK. Additionally, RKNN-Toolkit2 SDK is available for deploying additional AI models.

LLMinator
LLMinator is a Gradio-based tool with an integrated chatbot designed to locally run and test Language Model Models (LLMs) directly from HuggingFace. It provides an easy-to-use interface made with Gradio, LangChain, and Torch, offering features such as context-aware streaming chatbot, inbuilt code syntax highlighting, loading any LLM repo from HuggingFace, support for both CPU and CUDA modes, enabling LLM inference with llama.cpp, and model conversion capabilities.

xFasterTransformer
xFasterTransformer is an optimized solution for Large Language Models (LLMs) on the X86 platform, providing high performance and scalability for inference on mainstream LLM models. It offers C++ and Python APIs for easy integration, along with example codes and benchmark scripts. Users can prepare models in a different format, convert them, and use the APIs for tasks like encoding input prompts, generating token ids, and serving inference requests. The tool supports various data types and models, and can run in single or multi-rank modes using MPI. A web demo based on Gradio is available for popular LLM models like ChatGLM and Llama2. Benchmark scripts help evaluate model inference performance quickly, and MLServer enables serving with REST and gRPC interfaces.

ai-edge-torch
AI Edge Torch is a Python library that supports converting PyTorch models into a .tflite format for on-device applications on Android, iOS, and IoT devices. It offers broad CPU coverage with initial GPU and NPU support, closely integrating with PyTorch and providing good coverage of Core ATen operators. The library includes a PyTorch converter for model conversion and a Generative API for authoring mobile-optimized PyTorch Transformer models, enabling easy deployment of Large Language Models (LLMs) on mobile devices.
BodhiApp
Bodhi App runs Open Source Large Language Models locally, exposing LLM inference capabilities as OpenAI API compatible REST APIs. It leverages llama.cpp for GGUF format models and huggingface.co ecosystem for model downloads. Users can run fine-tuned models for chat completions, create custom aliases, and convert Huggingface models to GGUF format. The CLI offers commands for environment configuration, model management, pulling files, serving API, and more.
lm.rs
lm.rs is a tool that allows users to run inference on Language Models locally on the CPU using Rust. It supports LLama3.2 1B and 3B models, with a WebUI also available. The tool provides benchmarks and download links for models and tokenizers, with recommendations for quantization options. Users can convert models from Google/Meta on huggingface using provided scripts. The tool can be compiled with cargo and run with various arguments for model weights, tokenizer, temperature, and more. Additionally, a backend for the WebUI can be compiled and run to connect via the web interface.
LiteRT
LiteRT is Google's open-source high-performance runtime for on-device AI, previously known as TensorFlow Lite. The repository is currently not intended for open-source development, but aims to evolve to allow direct building and contributions. LiteRT supports Python versions 3.9, 3.10, 3.11 on Linux and MacOS. It ensures compatibility with existing .tflite file extension and format, offering conversion tools and continued active development under the name LiteRT.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.