
stable-diffusion-webui
AUTOMATIC1111 (A1111) Stable Diffusion Web UI docker images for use in GPU cloud and local environments. Includes AI-Dock base for authentication and improved user experience.
Stars: 98
Stable Diffusion WebUI Docker Image allows users to run Automatic1111 WebUI in a docker container locally or in the cloud. The images do not bundle models or third-party configurations, requiring users to use a provisioning script for container configuration. It supports NVIDIA CUDA, AMD ROCm, and CPU platforms, with additional environment variables for customization and pre-configured templates for Vast.ai and Runpod.io. The service is password protected by default, with options for version pinning, startup flags, and service management using supervisorctl.
README:
![]()
Run Automatic1111 WebUI in a docker container locally or in the cloud.
[!NOTE]
These images do not bundle models or third-party configurations. You should use a provisioning script to automatically configure your container. You can find examples inconfig/provisioning.
All AI-Dock containers share a common base which is designed to make running on cloud services such as vast.ai as straightforward and user friendly as possible.
Common features and options are documented in the base wiki but any additional features unique to this image will be detailed below.
The :latest tag points to :latest-cuda
Tags follow these patterns:
-
:v2-cuda-[x.x.x]-[base|runtime]-[ubuntu-version] -
:latest-cuda→:v2-cuda-12.1.1-base-22.04
-
:rocm-[x.x.x]-runtime-[ubuntu-version] -
:latest-rocm→:v2-rocm-6.0-core-22.04
-
:cpu-ubuntu-[ubuntu-version] -
:latest-cpu→:v2-cpu-22.04
Browse here for an image suitable for your target environment.
Supported Python versions: 3.10
Supported Platforms: NVIDIA CUDA, AMD ROCm, CPU
| Variable | Description |
|---|---|
AUTO_UPDATE |
Update A1111 Web UI on startup (default false) |
WEBUI_BRANCH |
WebUI branch/commit hash for auto update. (default master) |
WEBUI_ARGS |
Startup arguments. eg. --no-half --api
|
WEBUI_PORT_HOST |
Web UI port (default 7860) |
WEBUI_URL |
Override $DIRECT_ADDRESS:port with URL for Web UI |
See the base environment variables here for more configuration options.
| Environment | Packages |
|---|---|
webui |
AUTOMATIC1111 WebUI and dependencies |
This environment will be activated on shell login.
See the base micromamba environments here.
The following services will be launched alongside the default services provided by the base image.
The service will launch on port 7860 unless you have specified an override with WEBUI_PORT_HOST.
You can set startup arguments by using variable WEBUI_ARGS.
To manage this service you can use supervisorctl [start|stop|restart] webui or via the Service Portal application.
[!NOTE] All services are password protected by default and HTTPS is available optionally. See the security and environment variables documentation for more information.
Vast.ai
The author (@robballantyne) may be compensated if you sign up to services linked in this document. Testing multiple variants of GPU images in many different environments is both costly and time-consuming; This helps to offset costs
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for stable-diffusion-webui
Similar Open Source Tools
stable-diffusion-webui
Stable Diffusion WebUI Docker Image allows users to run Automatic1111 WebUI in a docker container locally or in the cloud. The images do not bundle models or third-party configurations, requiring users to use a provisioning script for container configuration. It supports NVIDIA CUDA, AMD ROCm, and CPU platforms, with additional environment variables for customization and pre-configured templates for Vast.ai and Runpod.io. The service is password protected by default, with options for version pinning, startup flags, and service management using supervisorctl.
comfyui
ComfyUI is a highly-configurable, cloud-first AI-Dock container that allows users to run ComfyUI without bundled models or third-party configurations. Users can configure the container using provisioning scripts. The Docker image supports NVIDIA CUDA, AMD ROCm, and CPU platforms, with version tags for different configurations. Additional environment variables and Python environments are provided for customization. ComfyUI service runs on port 8188 and can be managed using supervisorctl. The tool also includes an API wrapper service and pre-configured templates for Vast.ai. The author may receive compensation for services linked in the documentation.

runpod-worker-comfy
runpod-worker-comfy is a serverless API tool that allows users to run any ComfyUI workflow to generate an image. Users can provide input images as base64-encoded strings, and the generated image can be returned as a base64-encoded string or uploaded to AWS S3. The tool is built on Ubuntu + NVIDIA CUDA and provides features like built-in checkpoints and VAE models. Users can configure environment variables to upload images to AWS S3 and interact with the RunPod API to generate images. The tool also supports local testing and deployment to Docker hub using Github Actions.

mLoRA
mLoRA (Multi-LoRA Fine-Tune) is an open-source framework for efficient fine-tuning of multiple Large Language Models (LLMs) using LoRA and its variants. It allows concurrent fine-tuning of multiple LoRA adapters with a shared base model, efficient pipeline parallelism algorithm, support for various LoRA variant algorithms, and reinforcement learning preference alignment algorithms. mLoRA helps save computational and memory resources when training multiple adapters simultaneously, achieving high performance on consumer hardware.

backend.ai-webui
Backend.AI Web UI is a user-friendly web and app interface designed to make AI accessible for end-users, DevOps, and SysAdmins. It provides features for session management, inference service management, pipeline management, storage management, node management, statistics, configurations, license checking, plugins, help & manuals, kernel management, user management, keypair management, manager settings, proxy mode support, service information, and integration with the Backend.AI Web Server. The tool supports various devices, offers a built-in websocket proxy feature, and allows for versatile usage across different platforms. Users can easily manage resources, run environment-supported apps, access a web-based terminal, use Visual Studio Code editor, manage experiments, set up autoscaling, manage pipelines, handle storage, monitor nodes, view statistics, configure settings, and more.

ragflow
RAGFlow is an open-source Retrieval-Augmented Generation (RAG) engine that combines deep document understanding with Large Language Models (LLMs) to provide accurate question-answering capabilities. It offers a streamlined RAG workflow for businesses of all sizes, enabling them to extract knowledge from unstructured data in various formats, including Word documents, slides, Excel files, images, and more. RAGFlow's key features include deep document understanding, template-based chunking, grounded citations with reduced hallucinations, compatibility with heterogeneous data sources, and an automated and effortless RAG workflow. It supports multiple recall paired with fused re-ranking, configurable LLMs and embedding models, and intuitive APIs for seamless integration with business applications.

text-embeddings-inference
Text Embeddings Inference (TEI) is a toolkit for deploying and serving open source text embeddings and sequence classification models. TEI enables high-performance extraction for popular models like FlagEmbedding, Ember, GTE, and E5. It implements features such as no model graph compilation step, Metal support for local execution on Macs, small docker images with fast boot times, token-based dynamic batching, optimized transformers code for inference using Flash Attention, Candle, and cuBLASLt, Safetensors weight loading, and production-ready features like distributed tracing with Open Telemetry and Prometheus metrics.

xFasterTransformer
xFasterTransformer is an optimized solution for Large Language Models (LLMs) on the X86 platform, providing high performance and scalability for inference on mainstream LLM models. It offers C++ and Python APIs for easy integration, along with example codes and benchmark scripts. Users can prepare models in a different format, convert them, and use the APIs for tasks like encoding input prompts, generating token ids, and serving inference requests. The tool supports various data types and models, and can run in single or multi-rank modes using MPI. A web demo based on Gradio is available for popular LLM models like ChatGLM and Llama2. Benchmark scripts help evaluate model inference performance quickly, and MLServer enables serving with REST and gRPC interfaces.
UCAgent
UCAgent is an AI-powered automated UT verification agent for chip design. It automates chip verification workflow, supports functional and code coverage analysis, ensures consistency among documentation, code, and reports, and collaborates with mainstream Code Agents via MCP protocol. It offers three intelligent interaction modes and requires Python 3.11+, Linux/macOS OS, 4GB+ memory, and access to an AI model API. Users can clone the repository, install dependencies, configure qwen, and start verification. UCAgent supports various verification quality improvement options and basic operations through TUI shortcuts and stage color indicators. It also provides documentation build and preview using MkDocs, PDF manual build using Pandoc + XeLaTeX, and resources for further help and contribution.

r2ai
r2ai is a tool designed to run a language model locally without internet access. It can be used to entertain users or assist in answering questions related to radare2 or reverse engineering. The tool allows users to prompt the language model, index large codebases, slurp file contents, embed the output of an r2 command, define different system-level assistant roles, set environment variables, and more. It is accessible as an r2lang-python plugin and can be scripted from various languages. Users can use different models, adjust query templates dynamically, load multiple models, and make them communicate with each other.

skyvern
Skyvern automates browser-based workflows using LLMs and computer vision. It provides a simple API endpoint to fully automate manual workflows, replacing brittle or unreliable automation solutions. Traditional approaches to browser automations required writing custom scripts for websites, often relying on DOM parsing and XPath-based interactions which would break whenever the website layouts changed. Instead of only relying on code-defined XPath interactions, Skyvern adds computer vision and LLMs to the mix to parse items in the viewport in real-time, create a plan for interaction and interact with them. This approach gives us a few advantages: 1. Skyvern can operate on websites it’s never seen before, as it’s able to map visual elements to actions necessary to complete a workflow, without any customized code 2. Skyvern is resistant to website layout changes, as there are no pre-determined XPaths or other selectors our system is looking for while trying to navigate 3. Skyvern leverages LLMs to reason through interactions to ensure we can cover complex situations. Examples include: 1. If you wanted to get an auto insurance quote from Geico, the answer to a common question “Were you eligible to drive at 18?” could be inferred from the driver receiving their license at age 16 2. If you were doing competitor analysis, it’s understanding that an Arnold Palmer 22 oz can at 7/11 is almost definitely the same product as a 23 oz can at Gopuff (even though the sizes are slightly different, which could be a rounding error!) Want to see examples of Skyvern in action? Jump to #real-world-examples-of- skyvern
mcpd
mcpd is a tool developed by Mozilla AI to declaratively manage Model Context Protocol (MCP) servers, enabling consistent interface for defining and running tools across different environments. It bridges the gap between local development and enterprise deployment by providing secure secrets management, declarative configuration, and seamless environment promotion. mcpd simplifies the developer experience by offering zero-config tool setup, language-agnostic tooling, version-controlled configuration files, enterprise-ready secrets management, and smooth transition from local to production environments.
gollama
Gollama is a delightful tool that brings Ollama, your offline conversational AI companion, directly into your terminal. It provides a fun and interactive way to generate responses from various models without needing internet connectivity. Whether you're brainstorming ideas, exploring creative writing, or just looking for inspiration, Gollama is here to assist you. The tool offers an interactive interface, customizable prompts, multiple models selection, and visual feedback to enhance user experience. It can be installed via different methods like downloading the latest release, using Go, running with Docker, or building from source. Users can interact with Gollama through various options like specifying a custom base URL, prompt, model, and enabling raw output mode. The tool supports different modes like interactive, piped, CLI with image, and TUI with image. Gollama relies on third-party packages like bubbletea, glamour, huh, and lipgloss. The roadmap includes implementing piped mode, support for extracting codeblocks, copying responses/codeblocks to clipboard, GitHub Actions for automated releases, and downloading models directly from Ollama using the rest API. Contributions are welcome, and the project is licensed under the MIT License.
ai-elements
AI Elements is a component library built on top of shadcn/ui to help build AI-native applications faster. It provides pre-built, customizable React components specifically designed for AI applications, including conversations, messages, code blocks, reasoning displays, and more. The CLI makes it easy to add these components to your Next.js project.
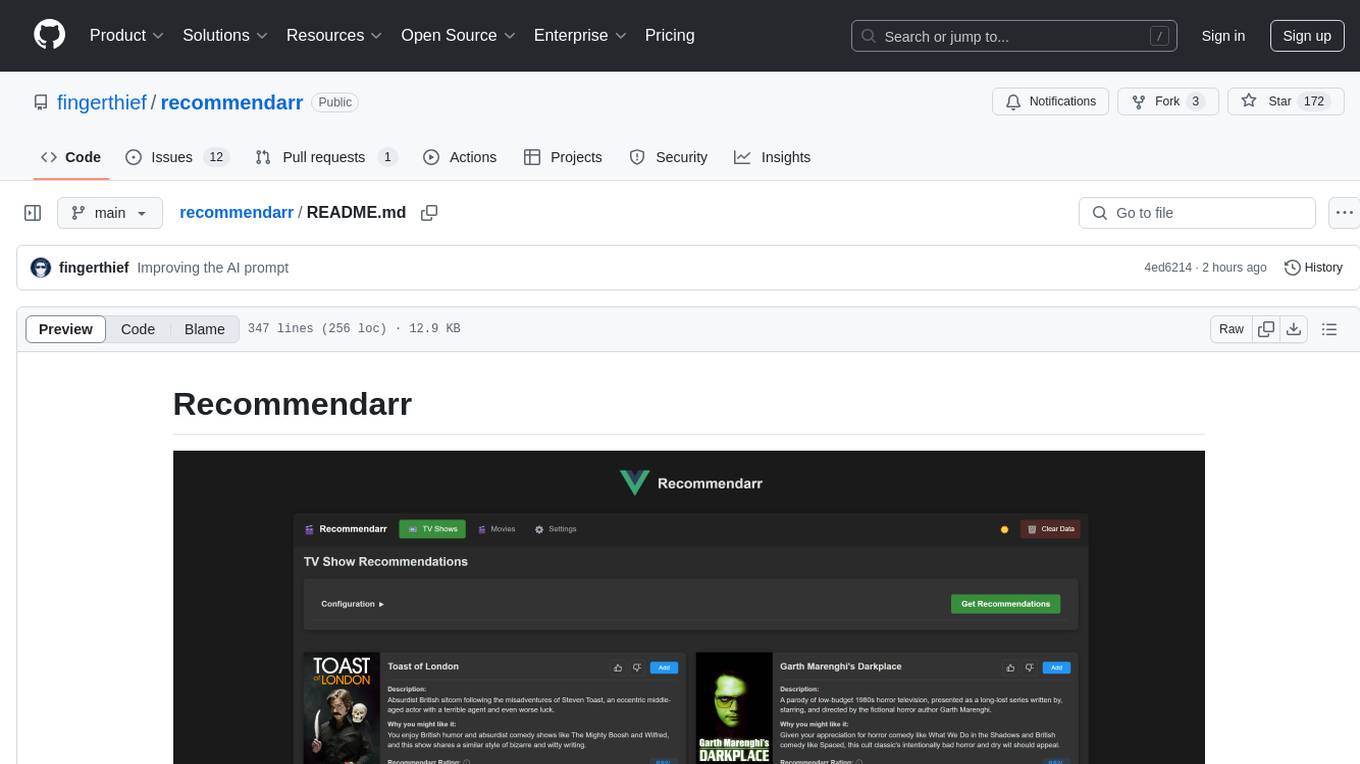
recommendarr
Recommendarr is a tool that generates personalized TV show and movie recommendations based on your Sonarr, Radarr, Plex, and Jellyfin libraries using AI. It offers AI-powered recommendations, media server integration, flexible AI support, watch history analysis, customization options, and dark/light mode toggle. Users can connect their media libraries and watch history services, configure AI service settings, and get personalized recommendations based on genre, language, and mood/vibe preferences. The tool works with any OpenAI-compatible API and offers various recommended models for different cost options and performance levels. It provides personalized suggestions, detailed information, filter options, watch history analysis, and one-click adding of recommended content to Sonarr/Radarr.
ollama4j-web-ui
Ollama4j Web UI is a Java-based web interface built using Spring Boot and Vaadin framework for Ollama users with Java and Spring background. It allows users to interact with various models running on Ollama servers, providing a fully functional web UI experience. The project offers multiple ways to run the application, including via Docker, Docker Compose, or as a standalone JAR. Users can configure the environment variables and access the web UI through a browser. The project also includes features for error handling on the UI and settings pane for customizing default parameters.
For similar tasks
stable-diffusion-webui
Stable Diffusion WebUI Docker Image allows users to run Automatic1111 WebUI in a docker container locally or in the cloud. The images do not bundle models or third-party configurations, requiring users to use a provisioning script for container configuration. It supports NVIDIA CUDA, AMD ROCm, and CPU platforms, with additional environment variables for customization and pre-configured templates for Vast.ai and Runpod.io. The service is password protected by default, with options for version pinning, startup flags, and service management using supervisorctl.
ezlocalai
ezlocalai is an artificial intelligence server that simplifies running multimodal AI models locally. It handles model downloading and server configuration based on hardware specs. It offers OpenAI Style endpoints for integration, voice cloning, text-to-speech, voice-to-text, and offline image generation. Users can modify environment variables for customization. Supports NVIDIA GPU and CPU setups. Provides demo UI and workflow visualization for easy usage.
BotSharp-UI
BotSharp UI is a web app for managing agents and conversations. It allows users to build new AI assistants quickly using a Node-based Agent building experience. The project is written in SvelteKit v2 and utilizes BotSharp as the LLM services.
ai-accelerator
The AI Accelerator project source code is designed to initialize an OpenShift cluster with a recommended set of operators and components for training, deploying, serving, and monitoring Machine Learning models. It provides core OpenShift features for Data Science environments and can be customized for specific scenarios. The project automates IT infrastructure using GitOps practices, including Git, code review, and CI/CD. ArgoCD Application objects are used to manage the installation of operators on the cluster.

AirGym
AirGym is an open source Python quadrotor simulator based on IsaacGym, providing a high-fidelity dynamics and Deep Reinforcement Learning (DRL) framework for quadrotor robot learning research. It offers a lightweight and customizable platform with strict alignment with PX4 logic, multiple control modes, and Sim-to-Real toolkits. Users can perform tasks such as Hovering, Balloon, Tracking, Avoid, and Planning, with the ability to create customized environments and tasks. The tool also supports training from scratch, visual encoding approaches, playing and testing of trained models, and customization of new tasks and assets.
comfyui
ComfyUI is a highly-configurable, cloud-first AI-Dock container that allows users to run ComfyUI without bundled models or third-party configurations. Users can configure the container using provisioning scripts. The Docker image supports NVIDIA CUDA, AMD ROCm, and CPU platforms, with version tags for different configurations. Additional environment variables and Python environments are provided for customization. ComfyUI service runs on port 8188 and can be managed using supervisorctl. The tool also includes an API wrapper service and pre-configured templates for Vast.ai. The author may receive compensation for services linked in the documentation.
dubbo-kubernetes
Dubbo Kubernetes provides support for building and deploying Dubbo applications in various environments, including Kubernetes and Alibaba Cloud ACK. It includes dubboctl for command line utility, dubbod for the control plane built on Istio, navigator for configuring proxies at runtime, and operator for user-friendly options to operate the dubbo proxyless mesh.
For similar jobs

AirGo
AirGo is a front and rear end separation, multi user, multi protocol proxy service management system, simple and easy to use. It supports vless, vmess, shadowsocks, and hysteria2.

mosec
Mosec is a high-performance and flexible model serving framework for building ML model-enabled backend and microservices. It bridges the gap between any machine learning models you just trained and the efficient online service API. * **Highly performant** : web layer and task coordination built with Rust 🦀, which offers blazing speed in addition to efficient CPU utilization powered by async I/O * **Ease of use** : user interface purely in Python 🐍, by which users can serve their models in an ML framework-agnostic manner using the same code as they do for offline testing * **Dynamic batching** : aggregate requests from different users for batched inference and distribute results back * **Pipelined stages** : spawn multiple processes for pipelined stages to handle CPU/GPU/IO mixed workloads * **Cloud friendly** : designed to run in the cloud, with the model warmup, graceful shutdown, and Prometheus monitoring metrics, easily managed by Kubernetes or any container orchestration systems * **Do one thing well** : focus on the online serving part, users can pay attention to the model optimization and business logic

llm-code-interpreter
The 'llm-code-interpreter' repository is a deprecated plugin that provides a code interpreter on steroids for ChatGPT by E2B. It gives ChatGPT access to a sandboxed cloud environment with capabilities like running any code, accessing Linux OS, installing programs, using filesystem, running processes, and accessing the internet. The plugin exposes commands to run shell commands, read files, and write files, enabling various possibilities such as running different languages, installing programs, starting servers, deploying websites, and more. It is powered by the E2B API and is designed for agents to freely experiment within a sandboxed environment.

pezzo
Pezzo is a fully cloud-native and open-source LLMOps platform that allows users to observe and monitor AI operations, troubleshoot issues, save costs and latency, collaborate, manage prompts, and deliver AI changes instantly. It supports various clients for prompt management, observability, and caching. Users can run the full Pezzo stack locally using Docker Compose, with prerequisites including Node.js 18+, Docker, and a GraphQL Language Feature Support VSCode Extension. Contributions are welcome, and the source code is available under the Apache 2.0 License.

learn-generative-ai
Learn Cloud Applied Generative AI Engineering (GenEng) is a course focusing on the application of generative AI technologies in various industries. The course covers topics such as the economic impact of generative AI, the role of developers in adopting and integrating generative AI technologies, and the future trends in generative AI. Students will learn about tools like OpenAI API, LangChain, and Pinecone, and how to build and deploy Large Language Models (LLMs) for different applications. The course also explores the convergence of generative AI with Web 3.0 and its potential implications for decentralized intelligence.

gcloud-aio
This repository contains shared codebase for two projects: gcloud-aio and gcloud-rest. gcloud-aio is built for Python 3's asyncio, while gcloud-rest is a threadsafe requests-based implementation. It provides clients for Google Cloud services like Auth, BigQuery, Datastore, KMS, PubSub, Storage, and Task Queue. Users can install the library using pip and refer to the documentation for usage details. Developers can contribute to the project by following the contribution guide.

fluid
Fluid is an open source Kubernetes-native Distributed Dataset Orchestrator and Accelerator for data-intensive applications, such as big data and AI applications. It implements dataset abstraction, scalable cache runtime, automated data operations, elasticity and scheduling, and is runtime platform agnostic. Key concepts include Dataset and Runtime. Prerequisites include Kubernetes version > 1.16, Golang 1.18+, and Helm 3. The tool offers features like accelerating remote file accessing, machine learning, accelerating PVC, preloading dataset, and on-the-fly dataset cache scaling. Contributions are welcomed, and the project is under the Apache 2.0 license with a vendor-neutral approach.

aiges
AIGES is a core component of the Athena Serving Framework, designed as a universal encapsulation tool for AI developers to deploy AI algorithm models and engines quickly. By integrating AIGES, you can deploy AI algorithm models and engines rapidly and host them on the Athena Serving Framework, utilizing supporting auxiliary systems for networking, distribution strategies, data processing, etc. The Athena Serving Framework aims to accelerate the cloud service of AI algorithm models and engines, providing multiple guarantees for cloud service stability through cloud-native architecture. You can efficiently and securely deploy, upgrade, scale, operate, and monitor models and engines without focusing on underlying infrastructure and service-related development, governance, and operations.