
fluid
Fluid, elastic data abstraction and acceleration for BigData/AI applications in cloud. (Project under CNCF)
Stars: 1807

Fluid is an open source Kubernetes-native Distributed Dataset Orchestrator and Accelerator for data-intensive applications, such as big data and AI applications. It implements dataset abstraction, scalable cache runtime, automated data operations, elasticity and scheduling, and is runtime platform agnostic. Key concepts include Dataset and Runtime. Prerequisites include Kubernetes version > 1.16, Golang 1.18+, and Helm 3. The tool offers features like accelerating remote file accessing, machine learning, accelerating PVC, preloading dataset, and on-the-fly dataset cache scaling. Contributions are welcomed, and the project is under the Apache 2.0 license with a vendor-neutral approach.
README:


| 📅 Community Meeting |
|---|
| The Fluid project holds bi-weekly community online meeting. To join or watch previous meeting notes and recordings, please see meeting schedule and meeting minutes. |
Fluid is an open source Kubernetes-native Distributed Dataset Orchestrator and Accelerator for data-intensive applications, such as big data and AI applications. It is hosted by the Cloud Native Computing Foundation (CNCF) as a sandbox project.
For more information, please refer to our papers:
-
Rong Gu, Kai Zhang, Zhihao Xu, et al. Fluid: Dataset Abstraction and Elastic Acceleration for Cloud-native Deep Learning Training Jobs. IEEE ICDE, pp. 2183-2196, May, 2022. (Conference Version)
-
Rong Gu, Zhihao Xu, Yang Che, et al. High-level Data Abstraction and Elastic Data Caching for Data-intensive AI Applications on Cloud-native Platforms. IEEE TPDS, pp. 2946-2964, Vol 34(11), 2023. (Journal Version)
English | 简体中文
|
|
|---|
| Latest Release: Apr. 17th, 2024. Fluid v1.0.0. Please check the CHANGELOG for details. |
| v0.9.0 Release: May. 26th, 2023. Fluid v0.9.0. Please check the CHANGELOG for details. |
| v0.8.0 Release: Sep. 03th, 2022. Fluid v0.8.0. Please check the CHANGELOG for details. |
| v0.7.0 Release: Mar. 02th, 2022. Fluid v0.7.0. Please check the CHANGELOG for details. |
| v0.6.0 Release: Aug. 11th, 2021. Fluid v0.6.0. Please check the CHANGELOG for details. |
| Apr. 27th, 2021. Fluid accepted by CNCF! Fluid project was accepted as an official CNCF Sandbox Project by CNCF Technical Oversight Committee (TOC) with a majority vote after the review process. New beginning for Fluid! . |

-
Dataset Abstraction
Implements the unified abstraction for datasets from multiple storage sources, with observability features to help users evaluate the need for scaling the cache system.
-
Scalable Cache Runtime
Offers a unified access interface for data operations with different runtimes, enabling access to third-party storage systems.
-
Automated Data Operations
Provides various automated data operation modes to facilitate integration with automated operations systems.
-
Elasticity and Scheduling
Enhances data access performance by combining data caching technology with elastic scaling, portability, observability, and data affinity-scheduling capabilities.
-
Runtime Platform Agnostic
Supports a variety of environments and can run different storage clients based on the environment, including native, edge, Serverless Kubernetes clusters, and Kubernetes multi-cluster environments.
Dataset: A Dataset is a set of data logically related that can be used by computing engines, such as Spark for big data analytics and TensorFlow for AI applications. Intelligently leveraging data often creates core industry values. Managing Datasets may require features in different dimensions, such as security, version management and data acceleration. We hope to start with data acceleration to support the management of datasets.
Runtime: The Runtime enforces dataset isolation/share, provides version management, and enables data acceleration by defining a set of interfaces to handle DataSets throughout their lifecycle, allowing for the implementation of management and acceleration functionalities behind these interfaces.
- Kubernetes version > 1.16, and support CSI
- Golang 1.18+
- Helm 3
You can follow our Get Started guide to quickly start a testing Kubernetes cluster.
You can see our documentation at docs for more in-depth installation and instructions for production:
You can also visit Fluid Homepage to get relevant documents.
Demo 1: Accelerate Remote File Accessing with Fluid

Demo 2: Machine Learning with Fluid

Demo 3: Accelerate PVC with Fluid

Demo 4: Preload dataset with Fluid


Demo 5: On-the-fly dataset cache scaling


See ROADMAP.md for the roadmap details. It may be updated from time to time.
Feel free to reach out if you have any questions. The maintainers of this project are reachable via:
DingTalk Group:

WeChat Group:

WeChat Official Account:

Slack:
- Join in the
CNCF Slackand navigate to the#fluidchannel for discussion.
Contributions are highly welcomed and greatly appreciated. See CONTRIBUTING.md for details on submitting patches and the contribution workflow.
If you are interested in Fluid and would like to share your experiences with others, you are warmly welcome to add your information on ADOPTERS.md page. We will continuously discuss new requirements and feature design with you in advance.
Fluid is under the Apache 2.0 license. See the LICENSE file for details. It is vendor-neutral.
Security is a first priority thing for us at Fluid. If you come across a related issue, please send an email to [email protected]. Also see our SECURITY.md file for details.
Fluid adopts CNCF Code of Conduct.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for fluid
Similar Open Source Tools
fluid
Fluid is an open source Kubernetes-native Distributed Dataset Orchestrator and Accelerator for data-intensive applications, such as big data and AI applications. It implements dataset abstraction, scalable cache runtime, automated data operations, elasticity and scheduling, and is runtime platform agnostic. Key concepts include Dataset and Runtime. Prerequisites include Kubernetes version > 1.16, Golang 1.18+, and Helm 3. The tool offers features like accelerating remote file accessing, machine learning, accelerating PVC, preloading dataset, and on-the-fly dataset cache scaling. Contributions are welcomed, and the project is under the Apache 2.0 license with a vendor-neutral approach.

Geoweaver
Geoweaver is an in-browser software that enables users to easily compose and execute full-stack data processing workflows using online spatial data facilities, high-performance computation platforms, and open-source deep learning libraries. It provides server management, code repository, workflow orchestration software, and history recording capabilities. Users can run it from both local and remote machines. Geoweaver aims to make data processing workflows manageable for non-coder scientists and preserve model run history. It offers features like progress storage, organization, SSH connection to external servers, and a web UI with Python support.
taipy
Taipy is an open-source Python library for easy, end-to-end application development, featuring what-if analyses, smart pipeline execution, built-in scheduling, and deployment tools.

clearml
ClearML is a suite of tools designed to streamline the machine learning workflow. It includes an experiment manager, MLOps/LLMOps, data management, and model serving capabilities. ClearML is open-source and offers a free tier hosting option. It supports various ML/DL frameworks and integrates with Jupyter Notebook and PyCharm. ClearML provides extensive logging capabilities, including source control info, execution environment, hyper-parameters, and experiment outputs. It also offers automation features, such as remote job execution and pipeline creation. ClearML is designed to be easy to integrate, requiring only two lines of code to add to existing scripts. It aims to improve collaboration, visibility, and data transparency within ML teams.

lightllm
LightLLM is a Python-based LLM (Large Language Model) inference and serving framework known for its lightweight design, scalability, and high-speed performance. It offers features like tri-process asynchronous collaboration, Nopad for efficient attention operations, dynamic batch scheduling, FlashAttention integration, tensor parallelism, Token Attention for zero memory waste, and Int8KV Cache. The tool supports various models like BLOOM, LLaMA, StarCoder, Qwen-7b, ChatGLM2-6b, Baichuan-7b, Baichuan2-7b, Baichuan2-13b, InternLM-7b, Yi-34b, Qwen-VL, Llava-7b, Mixtral, Stablelm, and MiniCPM. Users can deploy and query models using the provided server launch commands and interact with multimodal models like QWen-VL and Llava using specific queries and images.

clearml
ClearML is an auto-magical suite of tools designed to streamline AI workflows. It includes modules for experiment management, MLOps/LLMOps, data management, model serving, and more. ClearML offers features like experiment tracking, model serving, orchestration, and automation. It supports various ML/DL frameworks and integrates with Jupyter Notebook and PyCharm for remote debugging. ClearML aims to simplify collaboration, automate processes, and enhance visibility in AI projects.
agentgateway
Agentgateway is an open source data plane optimized for agentic AI connectivity within or across any agent framework or environment. It provides drop-in security, observability, and governance for agent-to-agent and agent-to-tool communication, supporting leading interoperable protocols like Agent2Agent (A2A) and Model Context Protocol (MCP). Highly performant, security-first, multi-tenant, dynamic, and supporting legacy API transformation, agentgateway is designed to handle any scale and run anywhere with any agent framework.

DocsGPT
DocsGPT is an open-source documentation assistant powered by GPT models. It simplifies the process of searching for information in project documentation by allowing developers to ask questions and receive accurate answers. With DocsGPT, users can say goodbye to manual searches and quickly find the information they need. The tool aims to revolutionize project documentation experiences and offers features like live previews, Discord community, guides, and contribution opportunities. It consists of a Flask app, Chrome extension, similarity search index creation script, and a frontend built with Vite and React. Users can quickly get started with DocsGPT by following the provided setup instructions and can contribute to its development by following the guidelines in the CONTRIBUTING.md file. The project follows a Code of Conduct to ensure a harassment-free community environment for all participants. DocsGPT is licensed under MIT and is built with LangChain.
docq
Docq is a private and secure GenAI tool designed to extract knowledge from business documents, enabling users to find answers independently. It allows data to stay within organizational boundaries, supports self-hosting with various cloud vendors, and offers multi-model and multi-modal capabilities. Docq is extensible, open-source (AGPLv3), and provides commercial licensing options. The tool aims to be a turnkey solution for organizations to adopt AI innovation safely, with plans for future features like more data ingestion options and model fine-tuning.
refly
Refly.AI is an open-source AI-native creation engine that empowers users to transform ideas into production-ready content. It features a free-form canvas interface with multi-threaded conversations, knowledge base integration, contextual memory, intelligent search, WYSIWYG AI editor, and more. Users can leverage AI-powered capabilities, context memory, knowledge base integration, quotes, and AI document editing to enhance their content creation process. Refly offers both cloud and self-hosting options, making it suitable for individuals, enterprises, and organizations. The tool is designed to facilitate human-AI collaboration and streamline content creation workflows.

instill-core
Instill Core is an open-source orchestrator comprising a collection of source-available projects designed to streamline every aspect of building versatile AI features with unstructured data. It includes Instill VDP (Versatile Data Pipeline) for unstructured data, AI, and pipeline orchestration, Instill Model for scalable MLOps and LLMOps for open-source or custom AI models, and Instill Artifact for unified unstructured data management. Instill Core can be used for tasks such as building, testing, and sharing pipelines, importing, serving, fine-tuning, and monitoring ML models, and transforming documents, images, audio, and video into a unified AI-ready format.

openvino
OpenVINO™ is an open-source toolkit for optimizing and deploying AI inference. It provides a common API to deliver inference solutions on various platforms, including CPU, GPU, NPU, and heterogeneous devices. OpenVINO™ supports pre-trained models from Open Model Zoo and popular frameworks like TensorFlow, PyTorch, and ONNX. Key components of OpenVINO™ include the OpenVINO™ Runtime, plugins for different hardware devices, frontends for reading models from native framework formats, and the OpenVINO Model Converter (OVC) for adjusting models for optimal execution on target devices.
seatunnel
SeaTunnel is a high-performance, distributed data integration tool trusted by numerous companies for synchronizing vast amounts of data daily. It addresses common data integration challenges by seamlessly integrating with diverse data sources, supporting multimodal data integration, complex synchronization scenarios, resource efficiency, and quality monitoring. With over 100 connectors, SeaTunnel offers batch-stream integration, distributed snapshot algorithm, multi-engine support, JDBC multiplexing, and log parsing. It provides high throughput, low latency, real-time monitoring, and supports two job development methods. Users can configure jobs, select execution engines, and parallelize data using source connectors. SeaTunnel also supports multimodal data integration, Apache SeaTunnel tools, real-world use cases, and visual management of jobs through the SeaTunnel Web Project.

mlcraft
Synmetrix (prev. MLCraft) is an open source data engineering platform and semantic layer for centralized metrics management. It provides a complete framework for modeling, integrating, transforming, aggregating, and distributing metrics data at scale. Key features include data modeling and transformations, semantic layer for unified data model, scheduled reports and alerts, versioning, role-based access control, data exploration, caching, and collaboration on metrics modeling. Synmetrix leverages Cube (Cube.js) for flexible data models that consolidate metrics from various sources, enabling downstream distribution via a SQL API for integration into BI tools, reporting, dashboards, and data science. Use cases include data democratization, business intelligence, embedded analytics, and enhancing accuracy in data handling and queries. The tool speeds up data-driven workflows from metrics definition to consumption by combining data engineering best practices with self-service analytics capabilities.
synmetrix
Synmetrix is an open source data engineering platform and semantic layer for centralized metrics management. It provides a complete framework for modeling, integrating, transforming, aggregating, and distributing metrics data at scale. Key features include data modeling and transformations, semantic layer for unified data model, scheduled reports and alerts, versioning, role-based access control, data exploration, caching, and collaboration on metrics modeling. Synmetrix leverages Cube.js to consolidate metrics from various sources and distribute them downstream via a SQL API. Use cases include data democratization, business intelligence and reporting, embedded analytics, and enhancing accuracy in data handling and queries. The tool speeds up data-driven workflows from metrics definition to consumption by combining data engineering best practices with self-service analytics capabilities.
ten_framework
TEN Framework, short for Transformative Extensions Network, is the world's first real-time multimodal AI agent framework. It offers native support for high-performance, real-time multimodal interactions, supports multiple languages and platforms, enables edge-cloud integration, provides flexibility beyond model limitations, and allows for real-time agent state management. The framework facilitates the development of complex AI applications that transcend the limitations of large models by offering a drag-and-drop programming approach. It is suitable for scenarios like simultaneous interpretation, speech-to-text conversion, multilingual chat rooms, audio interaction, and audio-visual interaction.
For similar tasks
fluid
Fluid is an open source Kubernetes-native Distributed Dataset Orchestrator and Accelerator for data-intensive applications, such as big data and AI applications. It implements dataset abstraction, scalable cache runtime, automated data operations, elasticity and scheduling, and is runtime platform agnostic. Key concepts include Dataset and Runtime. Prerequisites include Kubernetes version > 1.16, Golang 1.18+, and Helm 3. The tool offers features like accelerating remote file accessing, machine learning, accelerating PVC, preloading dataset, and on-the-fly dataset cache scaling. Contributions are welcomed, and the project is under the Apache 2.0 license with a vendor-neutral approach.

deeplake
Deep Lake is a Database for AI powered by a storage format optimized for deep-learning applications. Deep Lake can be used for: 1. Storing data and vectors while building LLM applications 2. Managing datasets while training deep learning models Deep Lake simplifies the deployment of enterprise-grade LLM-based products by offering storage for all data types (embeddings, audio, text, videos, images, pdfs, annotations, etc.), querying and vector search, data streaming while training models at scale, data versioning and lineage, and integrations with popular tools such as LangChain, LlamaIndex, Weights & Biases, and many more. Deep Lake works with data of any size, it is serverless, and it enables you to store all of your data in your own cloud and in one place. Deep Lake is used by Intel, Bayer Radiology, Matterport, ZERO Systems, Red Cross, Yale, & Oxford.

python-aiplatform
The Vertex AI SDK for Python is a library that provides a convenient way to use the Vertex AI API. It offers a high-level interface for creating and managing Vertex AI resources, such as datasets, models, and endpoints. The SDK also provides support for training and deploying custom models, as well as using AutoML models. With the Vertex AI SDK for Python, you can quickly and easily build and deploy machine learning models on Vertex AI.

CSGHub
CSGHub is an open source, trustworthy large model asset management platform that can assist users in governing the assets involved in the lifecycle of LLM and LLM applications (datasets, model files, codes, etc). With CSGHub, users can perform operations on LLM assets, including uploading, downloading, storing, verifying, and distributing, through Web interface, Git command line, or natural language Chatbot. Meanwhile, the platform provides microservice submodules and standardized OpenAPIs, which could be easily integrated with users' own systems. CSGHub is committed to bringing users an asset management platform that is natively designed for large models and can be deployed On-Premise for fully offline operation. CSGHub offers functionalities similar to a privatized Huggingface(on-premise Huggingface), managing LLM assets in a manner akin to how OpenStack Glance manages virtual machine images, Harbor manages container images, and Sonatype Nexus manages artifacts.
awesome-object-detection-datasets
This repository is a curated list of awesome public object detection and recognition datasets. It includes a wide range of datasets related to object detection and recognition tasks, such as general detection and recognition datasets, autonomous driving datasets, adverse weather datasets, person detection datasets, anti-UAV datasets, optical aerial imagery datasets, low-light image datasets, infrared image datasets, SAR image datasets, multispectral image datasets, 3D object detection datasets, vehicle-to-everything field datasets, super-resolution field datasets, and face detection and recognition datasets. The repository also provides information on tools for data annotation, data augmentation, and data management related to object detection tasks.

aisheets
Hugging Face AI Sheets is an open-source tool for building, enriching, and transforming datasets using AI models with no code. It can be deployed locally or on the Hub, providing access to thousands of open models. Users can easily generate datasets, run data generation scripts, and customize inference endpoints for text generation. The tool supports custom LLMs and offers advanced configuration options for authentication, inference, and miscellaneous settings. With AI Sheets, users can leverage the power of AI models without writing any code, making dataset management and transformation efficient and accessible.

CosmosAIGraph
CosmosAIGraph is an AI-powered graph and RAG implementation of OmniRAG pattern, utilizing Azure Cosmos DB and other sources. It includes presentations, reference application documentation, FAQs, and a reference dataset of Python libraries pre-vectorized. The project focuses on Azure Cosmos DB for NoSQL and Apache Jena implementation for the in-memory RDF graph. It provides DockerHub images, with plans to add RBAC and Microsoft Entra ID/AAD authentication support, update AI model to gpt-4.5, and offer generic graph examples with a graph generation solution.
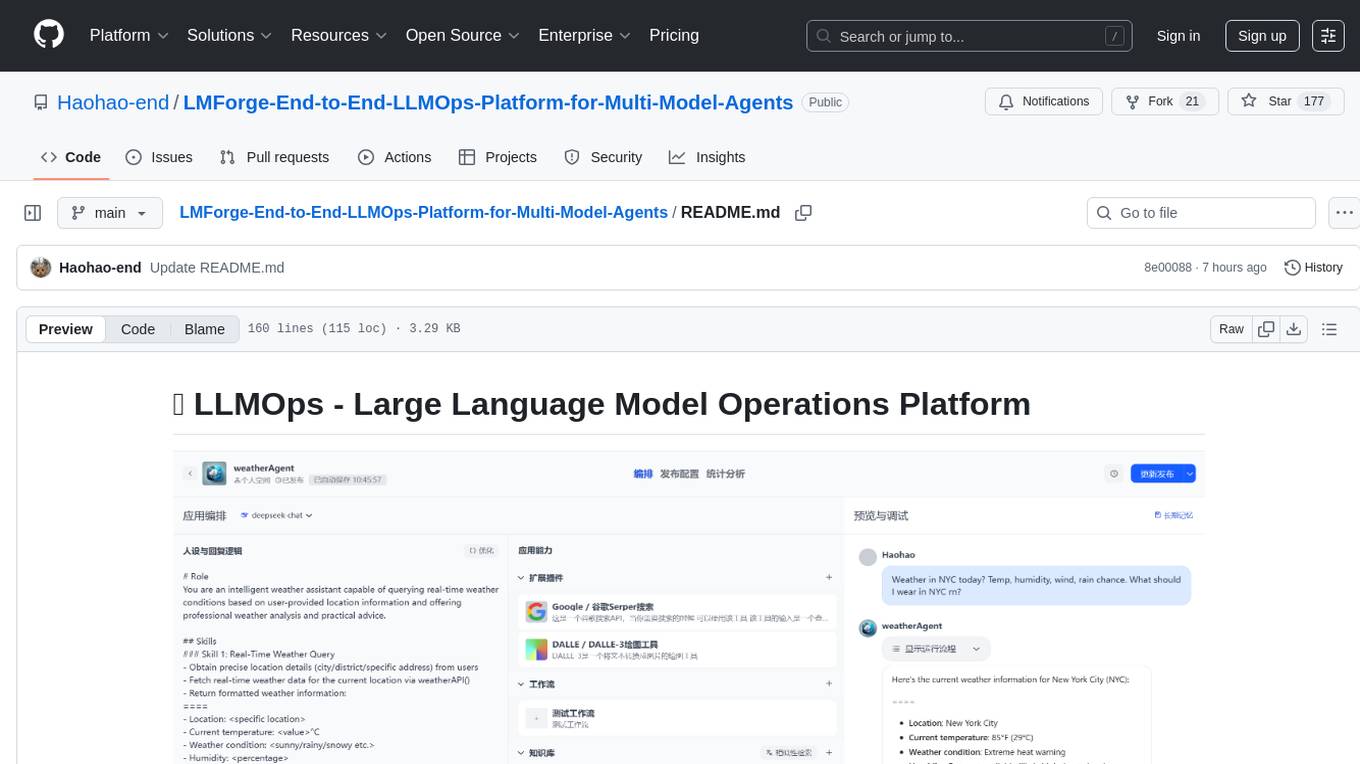
LMForge-End-to-End-LLMOps-Platform-for-Multi-Model-Agents
LMForge is an end-to-end LLMOps platform designed for multi-model agents. It provides a comprehensive solution for managing and deploying large language models efficiently. The platform offers tools for training, fine-tuning, and deploying various types of language models, enabling users to streamline the development and deployment process. With LMForge, users can easily experiment with different model architectures, optimize hyperparameters, and scale their models to meet specific requirements. The platform also includes features for monitoring model performance, managing datasets, and collaborating with team members, making it a versatile tool for researchers and developers working with language models.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.