
ail-framework
AIL framework - Analysis Information Leak framework
Stars: 793

AIL framework is a modular framework to analyze potential information leaks from unstructured data sources like pastes from Pastebin or similar services or unstructured data streams. AIL framework is flexible and can be extended to support other functionalities to mine or process sensitive information (e.g. data leak prevention).
README:
![]()
| Latest Release |  |
| CI | |
| Gitter |  |
| Contributors |  |
| License |  |
AIL framework - Framework for Analysis of Information Leaks
AIL is a modular framework to analyse potential information leaks from unstructured data sources like pastes from Pastebin or similar services or unstructured data streams. AIL framework is flexible and can be extended to support other functionalities to mine or process sensitive information (e.g. data leak prevention).


AIL v5.0 introduces significant improvements and new features:
- Codebase Rewrite: The codebase has undergone a substantial rewrite, resulting in enhanced performance and speed improvements.
- Database Upgrade: The database has been migrated from ARDB to Kvrocks.
- New Correlation Engine: AIL v5.0 introduces a new powerful correlation engine with two new correlation types: CVE and Title.
- Enhanced Logging: The logging system has been improved to provide better troubleshooting capabilities.
- Tagging Support: AIL objects now support tagging, allowing users to categorize and label extracted information for easier analysis and organization.
- Trackers: Improved objects filtering, PGP and decoded tracking added.
- UI Content Visualization: The user interface has been upgraded to visualize extracted and tracked information.
- New Crawler Lacus: improve crawling capabilities.
- Modular Importers and Exporters: New importers (ZMQ, AIL Feeders) and exporters (MISP, Mail, TheHive) modular design. Allow easy creation and customization by extending an abstract class.
- Module Queues: improved the queuing mechanism between detection modules.
- New Object CVE and Title: Extract an correlate CVE IDs and web page titles.

- Modular architecture to handle streams of unstructured or structured information
- Default support for external ZMQ feeds, such as provided by CIRCL or other providers
- Multiple Importers and feeds support
- Each module can process and reprocess the information already analyzed by AIL
- Detecting and extracting URLs including their geographical location (e.g. IP address location)
- Extracting and validating potential leaks of credit card numbers, credentials, ...
- Extracting and validating leaked email addresses, including DNS MX validation
- Module for extracting Tor .onion addresses for further analysis
- Keep tracks of credentials duplicates (and diffing between each duplicate found)
- Extracting and validating potential hostnames (e.g. to feed Passive DNS systems)
- A full-text indexer module to index unstructured information
- Terms, Set of terms, Regex, typo squatting and YARA tracking and occurrence
- YARA Retro Hunt
- Many more modules for extracting phone numbers, credentials, and more
- Alerting to MISP to share found leaks within a threat intelligence platform using MISP standard
- Detecting and decoding encoded file (Base64, hex encoded or your own decoding scheme) and storing files
- Detecting Amazon AWS and Google API keys
- Detecting Bitcoin address and Bitcoin private keys
- Detecting private keys, certificate, keys (including SSH, OpenVPN)
- Detecting IBAN bank accounts
- Tagging system with MISP Galaxy and MISP Taxonomies tags
- UI submission
- Create events on MISP and cases on The Hive
- Automatic export on detection with MISP (events) and The Hive (alerts) on selected tags
- Extracted and decoded files can be searched by date range, type of file (mime-type) and encoding discovered
- Correlations engine and Graph to visualize relationships between decoded files (hashes), PGP UIDs, domains, username, and cryptocurrencies addresses
- Websites, Forums and Tor Hidden-Services hidden services crawler to crawl and parse output
- Domain availability monitoring to detect up and down of websites and hidden services
- Browsed hidden services are automatically captured and integrated into the analyzed output, including a blurring screenshot interface (to avoid "burning the eyes" of security analysts with sensitive content)
- Tor hidden services is part of the standard framework, all the AIL modules are available to the crawled hidden services
- Crawler scheduler to trigger crawling on demand or at regular intervals for URLs or Tor hidden services
Trackers are user-defined rules or patterns that automatically detect, tag and notify about relevant information collected by AIL.
Trackers types: Documentation
- word or set of words
- YARA rules
- Regex
- Typo Squatting
![]()
![]()

To install the AIL framework, run the following commands:
# Clone the repo first
git clone https://github.com/ail-project/ail-framework.git
git submodule update --init --recursive
cd ail-framework
# For Debian and Ubuntu based distributions
./installing_deps.sh
# Launch ail
cd ~/ail-framework/
cd bin/
./LAUNCH.sh -lThe default installing_deps.sh is for Debian and Ubuntu based distributions.
Requirement:
- Python 3.8+
For Lacus Crawler and LibreTranslate installation instructions (if you want to use those features), refer to the HOWTO
To start AIL, use the following commands:
cd bin/
./LAUNCH.sh -lYou can access the AIL framework web interface at the following URL:
https://localhost:7000/
The default credentials for the web interface are located in the DEFAULT_PASSWORDfile, which is deleted when you change your password.
CIRCL organises training on how to use or extend the AIL framework. AIL training materials are available at https://github.com/ail-project/ail-training.
The documentation is available in doc/README.md
The API documentation is available in doc/api.md
HOWTO are available in HOWTO.md
For information on AIL's compliance with GDPR and privacy considerations, refer to the AIL information leaks analysis and the GDPR in the context of collection, analysis and sharing information leaks document.
this document provides an overview how to use AIL in a lawfulness context especially in the scope of General Data Protection Regulation.
If you use or reference AIL in an academic paper, you can cite it using the following BibTeX:
@inproceedings{mokaddem2018ail,
title={AIL-The design and implementation of an Analysis Information Leak framework},
author={Mokaddem, Sami and Wagener, G{\'e}rard and Dulaunoy, Alexandre},
booktitle={2018 IEEE International Conference on Big Data (Big Data)},
pages={5049--5057},
year={2018},
organization={IEEE}
}
Websites, Forums and Tor Hidden-Services










Copyright (C) 2014 Jules Debra
Copyright (c) 2021 Olivier Sagit
Copyright (C) 2014-2024 CIRCL - Computer Incident Response Center Luxembourg (c/o smile, security made in Lëtzebuerg, Groupement d'Intérêt Economique)
Copyright (c) 2014-2024 Raphaël Vinot
Copyright (c) 2014-2024 Alexandre Dulaunoy
Copyright (c) 2016-2024 Sami Mokaddem
Copyright (c) 2018-2024 Thirion Aurélien
This program is free software: you can redistribute it and/or modify
it under the terms of the GNU Affero General Public License as published by
the Free Software Foundation, either version 3 of the License, or
(at your option) any later version.
This program is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU Affero General Public License for more details.
You should have received a copy of the GNU Affero General Public License
along with this program. If not, see <http://www.gnu.org/licenses/>.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for ail-framework
Similar Open Source Tools
ail-framework
AIL framework is a modular framework to analyze potential information leaks from unstructured data sources like pastes from Pastebin or similar services or unstructured data streams. AIL framework is flexible and can be extended to support other functionalities to mine or process sensitive information (e.g. data leak prevention).

AIL-framework
AIL framework is a modular framework to analyze potential information leaks from unstructured data sources like pastes from Pastebin or similar services or unstructured data streams. AIL framework is flexible and can be extended to support other functionalities to mine or process sensitive information (e.g. data leak prevention).
StratosphereLinuxIPS
Slips is a powerful endpoint behavioral intrusion prevention and detection system that uses machine learning to detect malicious behaviors in network traffic. It can work with network traffic in real-time, PCAP files, and network flows from tools like Suricata, Zeek/Bro, and Argus. Slips threat detection is based on machine learning models, threat intelligence feeds, and expert heuristics. It gathers evidence of malicious behavior and triggers alerts when enough evidence is accumulated. The tool is Python-based and supported on Linux and MacOS, with blocking features only on Linux. Slips relies on Zeek network analysis framework and Redis for interprocess communication. It offers a graphical user interface for easy monitoring and analysis.
logfire
Pydantic Logfire is an observability platform that provides simple and powerful dashboard, Python-centric insights, SQL querying, OpenTelemetry integration, and Pydantic validation analytics. It offers unparalleled visibility into Python applications' behavior and allows querying data using standard SQL. Logfire is an opinionated wrapper around OpenTelemetry, supporting traces, metrics, and logs. The Python SDK for logfire is open source, while the server application for recording and displaying data is closed source.

DevDocs
DevDocs is a platform designed to simplify the process of digesting technical documentation for software engineers and developers. It automates the extraction and conversion of web content into markdown format, making it easier for users to access and understand the information. By crawling through child pages of a given URL, DevDocs provides a streamlined approach to gathering relevant data and integrating it into various tools for software development. The tool aims to save time and effort by eliminating the need for manual research and content extraction, ultimately enhancing productivity and efficiency in the development process.
CursorLens
Cursor Lens is an open-source tool that acts as a proxy between Cursor and various AI providers, logging interactions and providing detailed analytics to help developers optimize their use of AI in their coding workflow. It supports multiple AI providers, captures and logs all requests, provides visual analytics on AI usage, allows users to set up and switch between different AI configurations, offers real-time monitoring of AI interactions, tracks token usage, estimates costs based on token usage and model pricing. Built with Next.js, React, PostgreSQL, Prisma ORM, Vercel AI SDK, Tailwind CSS, and shadcn/ui components.
gpt-rag-ingestion
The GPT-RAG Data Ingestion service automates processing of diverse document types for indexing in Azure AI Search. It uses intelligent chunking strategies tailored to each format, generates text and image embeddings, and enables rich, multimodal retrieval experiences for agent-based RAG applications. Supported data sources include Blob Storage, NL2SQL Metadata, and SharePoint. The service selects chunkers based on file extension, such as DocAnalysisChunker for PDF files, OCR for image files, LangChainChunker for text-based files, TranscriptionChunker for video transcripts, and SpreadsheetChunker for spreadsheets. Deployment requires provisioning infrastructure and assigning specific roles to the user or service principal.

premsql
PremSQL is an open-source library designed to help developers create secure, fully local Text-to-SQL solutions using small language models. It provides essential tools for building and deploying end-to-end Text-to-SQL pipelines with customizable components, ideal for secure, autonomous AI-powered data analysis. The library offers features like Local-First approach, Customizable Datasets, Robust Executors and Evaluators, Advanced Generators, Error Handling and Self-Correction, Fine-Tuning Support, and End-to-End Pipelines. Users can fine-tune models, generate SQL queries from natural language inputs, handle errors, and evaluate model performance against predefined metrics. PremSQL is extendible for customization and private data usage.

swark
Swark is a VS Code extension that automatically generates architecture diagrams from code using large language models (LLMs). It is directly integrated with GitHub Copilot, requires no authentication or API key, and supports all languages. Swark helps users learn new codebases, review AI-generated code, improve documentation, understand legacy code, spot design flaws, and gain test coverage insights. It saves output in a 'swark-output' folder with diagram and log files. Source code is only shared with GitHub Copilot for privacy. The extension settings allow customization for file reading, file extensions, exclusion patterns, and language model selection. Swark is open source under the GNU Affero General Public License v3.0.

comfyui_LLM_Polymath
LLM Polymath Chat Node is an advanced Chat Node for ComfyUI that integrates large language models to build text-driven applications and automate data processes, enhancing prompt responses by incorporating real-time web search, linked content extraction, and custom agent instructions. It supports both OpenAI’s GPT-like models and alternative models served via a local Ollama API. The core functionalities include Comfy Node Finder and Smart Assistant, along with additional agents like Flux Prompter, Custom Instructors, Python debugger, and scripter. The tool offers features for prompt processing, web search integration, model & API integration, custom instructions, image handling, logging & debugging, output compression, and more.
marly
Marly is a tool that allows users to search for and extract context-specific data from various types of documents such as PDFs, Word files, Powerpoints, and websites. It provides the ability to extract data in structured formats like JSON or Markdown, making it easy to integrate into workflows. Marly supports multi-schema and multi-document extraction, offers built-in caching for rapid repeat extractions, and ensures no vendor lock-in by allowing flexibility in choosing model providers.
paperless-ai
Paperless-AI is an automated document analyzer tool designed for Paperless-ngx users. It utilizes the OpenAI API and Ollama (Mistral, llama, phi 3, gemma 2) to automatically scan, analyze, and tag documents. The tool offers features such as automatic document scanning, AI-powered document analysis, automatic title and tag assignment, manual mode for analyzing documents, easy setup through a web interface, document processing dashboard, error handling, and Docker support. Users can configure the tool through a web interface and access a debug interface for monitoring and troubleshooting. Paperless-AI aims to streamline document organization and analysis processes for users with access to Paperless-ngx and AI capabilities.

langmanus
LangManus is a community-driven AI automation framework that combines language models with specialized tools for tasks like web search, crawling, and Python code execution. It implements a hierarchical multi-agent system with agents like Coordinator, Planner, Supervisor, Researcher, Coder, Browser, and Reporter. The framework supports LLM integration, search and retrieval tools, Python integration, workflow management, and visualization. LangManus aims to give back to the open-source community and welcomes contributions in various forms.

Mira
Mira is an agentic AI library designed for automating company research by gathering information from various sources like company websites, LinkedIn profiles, and Google Search. It utilizes a multi-agent architecture to collect and merge data points into a structured profile with confidence scores and clear source attribution. The core library is framework-agnostic and can be integrated into applications, pipelines, or custom workflows. Mira offers features such as real-time progress events, confidence scoring, company criteria matching, and built-in services for data gathering. The tool is suitable for users looking to streamline company research processes and enhance data collection efficiency.

cosdata
Cosdata is a cutting-edge AI data platform designed to power the next generation search pipelines. It features immutability, version control, and excels in semantic search, structured knowledge graphs, hybrid search capabilities, real-time search at scale, and ML pipeline integration. The platform is customizable, scalable, efficient, enterprise-grade, easy to use, and can manage multi-modal data. It offers high performance, indexing, low latency, and high requests per second. Cosdata is designed to meet the demands of modern search applications, empowering businesses to harness the full potential of their data.
SMRY
SMRY.ai is a Next.js application that bypasses paywalls and generates AI-powered summaries by fetching content from multiple sources simultaneously. It provides a distraction-free reader with summary builder, cleans articles, offers multi-source fetching, built-in AI summaries in 14 languages, rich debug context, soft paywall access, smart extraction using Diffbot's AI, multi-source parallel fetching, type-safe error handling, dual caching strategy, intelligent source routing, content parsing pipeline, multilingual summaries, and more. The tool aims to make referencing reporting easier, provide original articles alongside summaries, and offer concise summaries in various languages.
For similar tasks
AIL-framework
AIL framework is a modular framework to analyze potential information leaks from unstructured data sources like pastes from Pastebin or similar services or unstructured data streams. AIL framework is flexible and can be extended to support other functionalities to mine or process sensitive information (e.g. data leak prevention).
ail-framework
AIL framework is a modular framework to analyze potential information leaks from unstructured data sources like pastes from Pastebin or similar services or unstructured data streams. AIL framework is flexible and can be extended to support other functionalities to mine or process sensitive information (e.g. data leak prevention).
For similar jobs
ail-framework
AIL framework is a modular framework to analyze potential information leaks from unstructured data sources like pastes from Pastebin or similar services or unstructured data streams. AIL framework is flexible and can be extended to support other functionalities to mine or process sensitive information (e.g. data leak prevention).
ai-exploits
AI Exploits is a repository that showcases practical attacks against AI/Machine Learning infrastructure, aiming to raise awareness about vulnerabilities in the AI/ML ecosystem. It contains exploits and scanning templates for responsibly disclosed vulnerabilities affecting machine learning tools, including Metasploit modules, Nuclei templates, and CSRF templates. Users can use the provided Docker image to easily run the modules and templates. The repository also provides guidelines for using Metasploit modules, Nuclei templates, and CSRF templates to exploit vulnerabilities in machine learning tools.
NGCBot
NGCBot is a WeChat bot based on the HOOK mechanism, supporting scheduled push of security news from FreeBuf, Xianzhi, Anquanke, and Qianxin Attack and Defense Community, KFC copywriting, filing query, phone number attribution query, WHOIS information query, constellation query, weather query, fishing calendar, Weibei threat intelligence query, beautiful videos, beautiful pictures, and help menu. It supports point functions, automatic pulling of people, ad detection, automatic mass sending, Ai replies, rich customization, and easy for beginners to use. The project is open-source and periodically maintained, with additional features such as Ai (Gpt, Xinghuo, Qianfan), keyword invitation to groups, automatic mass sending, and group welcome messages.

airgorah
Airgorah is a WiFi security auditing software written in Rust that utilizes the aircrack-ng tools suite. It allows users to capture WiFi traffic, discover connected clients, perform deauthentication attacks, capture handshakes, and crack access point passwords. The software is designed for testing and discovering flaws in networks owned by the user, and requires root privileges to run on Linux systems with a wireless network card supporting monitor mode and packet injection. Airgorah is not responsible for any illegal activities conducted with the software.
agentic_security
Agentic Security is an open-source vulnerability scanner designed for safety scanning, offering customizable rule sets and agent-based attacks. It provides comprehensive fuzzing for any LLMs, LLM API integration, and stress testing with a wide range of fuzzing and attack techniques. The tool is not a foolproof solution but aims to enhance security measures against potential threats. It offers installation via pip and supports quick start commands for easy setup. Users can utilize the tool for LLM integration, adding custom datasets, running CI checks, extending dataset collections, and dynamic datasets with mutations. The tool also includes a probe endpoint for integration testing. The roadmap includes expanding dataset variety, introducing new attack vectors, developing an attacker LLM, and integrating OWASP Top 10 classification.
pwnagotchi
Pwnagotchi is an AI tool leveraging bettercap to learn from WiFi environments and maximize crackable WPA key material. It uses LSTM with MLP feature extractor for A2C agent, learning over epochs to improve performance in various WiFi environments. Units can cooperate using a custom parasite protocol. Visit https://www.pwnagotchi.ai for documentation and community links.
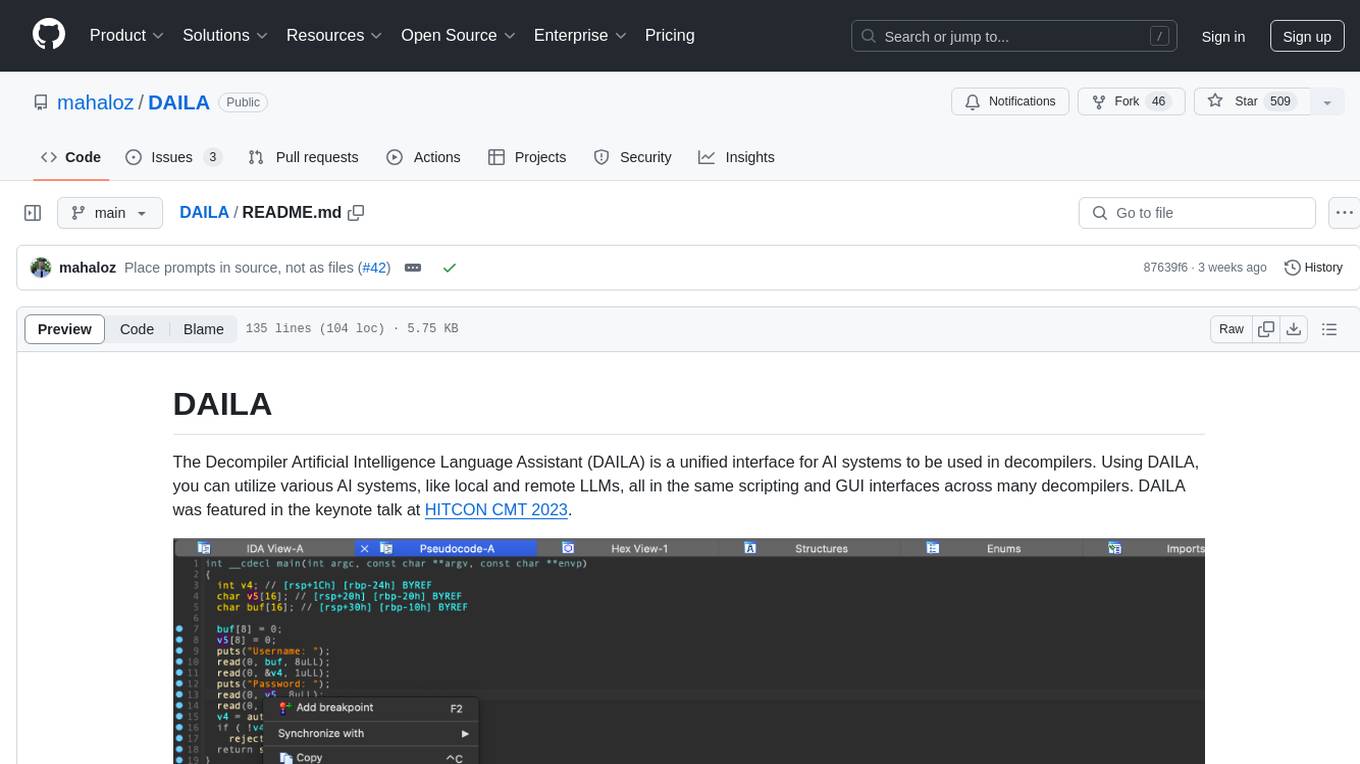
DAILA
DAILA is a unified interface for AI systems in decompilers, supporting various decompilers and AI systems. It allows users to utilize local and remote LLMs, like ChatGPT and Claude, and local models such as VarBERT. DAILA can be used as a decompiler plugin with GUI or as a scripting library. It also provides a Docker container for offline installations and supports tasks like summarizing functions and renaming variables in decompilation.
jadx-ai-mcp
JADX-AI-MCP is a plugin for the JADX decompiler that integrates with Model Context Protocol (MCP) to provide live reverse engineering support with LLMs like Claude. It allows for quick analysis, vulnerability detection, and AI code modification, all in real time. The tool combines JADX-AI-MCP and JADX MCP SERVER to analyze Android APKs effortlessly. It offers various prompts for code understanding, vulnerability detection, reverse engineering helpers, static analysis, AI code modification, and documentation. The tool is part of the Zin MCP Suite and aims to connect all android reverse engineering and APK modification tools with a single MCP server for easy reverse engineering of APK files.