
DataDreamer
DataDreamer: Prompt. Generate Synthetic Data. Train & Align Models. 🤖💤
Stars: 897

DataDreamer is a powerful open-source Python library designed for prompting, synthetic data generation, and training workflows. It is simple, efficient, and research-grade, allowing users to create prompting workflows, generate synthetic datasets, and train models with ease. The library is built for researchers, by researchers, focusing on correctness, best practices, and reproducibility. It offers features like aggressive caching, resumability, support for bleeding-edge techniques, and easy sharing of datasets and models. DataDreamer enables users to run multi-step prompting workflows, generate synthetic datasets for various tasks, and train models by aligning, fine-tuning, instruction-tuning, and distilling them using existing or synthetic data.
README:
Prompt. Generate Synthetic Data. Train & Align Models.


DataDreamer is a powerful open-source Python library for prompting, synthetic data generation, and training workflows. It is designed to be simple, extremely efficient, and research-grade.
|
Installation pip3 install datadreamer.dev |
|
demo.py |
Result of demo.py
|
|---|---|
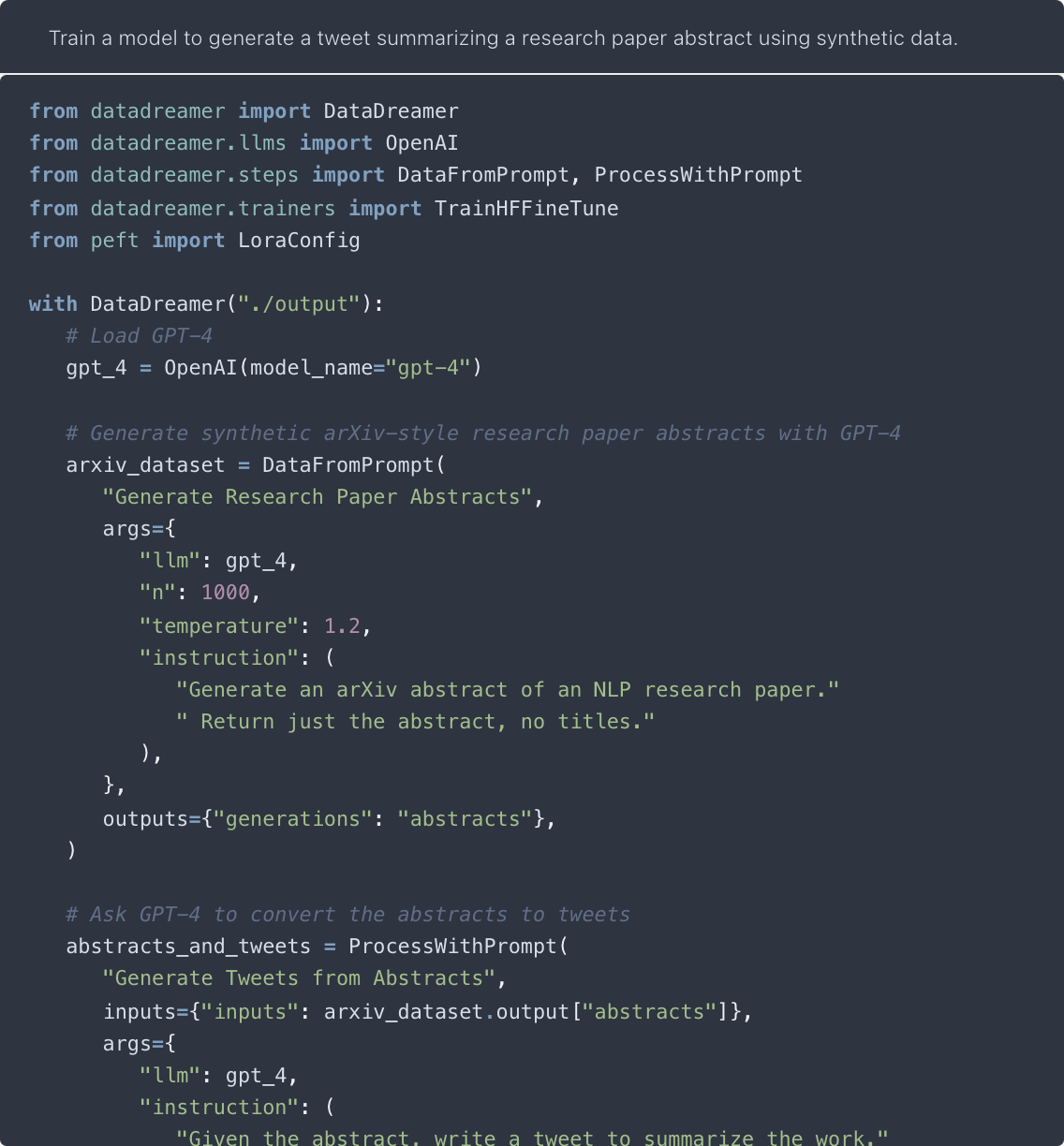
See the full demo script |

See the synthetic dataset and the trained model |
|
🚀 For more demonstrations and recipes see the Quick Tour page. |
|
With DataDreamer you can:
- 💬 Create Prompting Workflows: Create and run multi-step, complex, prompting workflows easily with major open source or API-based LLMs.
- 📊 Generate Synthetic Datasets: Generate synthetic datasets for novel tasks or augment existing datasets with LLMs.
- ⚙️ Train Models: Align models. Fine-tune models. Instruction-tune models. Distill models. Train on existing data or synthetic data.
- ... learn more about what's possible in the Overview Guide
DataDreamer is:
- 🧩 Simple: Simple and approachable to use with sensible defaults, yet powerful with support for bleeding edge techniques.
- 🔬 Research-Grade: Built for researchers, by researchers, but accessible to all. A focus on correctness, best practices, and reproducibility.
- 🏎️ Efficient: Aggressive caching and resumability built-in. Support for techniques like quantization, parameter-efficient training (LoRA), and more.
- 🔄 Reproducible: Workflows built with DataDreamer are easily shareable, reproducible, and extendable.
- 🤝 Makes Sharing Easy: Publishing datasets and models is simple. Automatically generate data cards and model cards with metadata. Generate a list of any citations required.
- ... learn more about the motivation and design principles behind DataDreamer.
Please cite the DataDreamer paper:
@misc{patel2024datadreamer,
title={DataDreamer: A Tool for Synthetic Data Generation and Reproducible LLM Workflows},
author={Ajay Patel and Colin Raffel and Chris Callison-Burch},
year={2024},
eprint={2402.10379},
archivePrefix={arXiv},
primaryClass={cs.CL}
}Please reach out to us via email ([email protected]) or on Discord if you have any questions, comments, or feedback.
Copyright © 2024, Ajay Patel. Released under the MIT License.
Thank you to the maintainers at Hugging Face and LiteLLM for accepting contributions necessary for DataDreamer and providing upstream support.
ODNI, IARPA: This research is supported in part by the Office of the Director of National Intelligence (ODNI), Intelligence Advanced Research Projects Activity (IARPA), via the HIATUS Program contract #2022-22072200005. The views and conclusions contained herein are those of the authors and should not be interpreted as necessarily representing the official policies, either expressed or implied, of ODNI, IARPA, or the U.S. Government. The U.S. Government is authorized to reproduce and distribute reprints for governmental purposes notwithstanding any copyright annotation therein.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for DataDreamer
Similar Open Source Tools
DataDreamer
DataDreamer is a powerful open-source Python library designed for prompting, synthetic data generation, and training workflows. It is simple, efficient, and research-grade, allowing users to create prompting workflows, generate synthetic datasets, and train models with ease. The library is built for researchers, by researchers, focusing on correctness, best practices, and reproducibility. It offers features like aggressive caching, resumability, support for bleeding-edge techniques, and easy sharing of datasets and models. DataDreamer enables users to run multi-step prompting workflows, generate synthetic datasets for various tasks, and train models by aligning, fine-tuning, instruction-tuning, and distilling them using existing or synthetic data.

lerobot
LeRobot is a state-of-the-art AI library for real-world robotics in PyTorch. It aims to provide models, datasets, and tools to lower the barrier to entry to robotics, focusing on imitation learning and reinforcement learning. LeRobot offers pretrained models, datasets with human-collected demonstrations, and simulation environments. It plans to support real-world robotics on affordable and capable robots. The library hosts pretrained models and datasets on the Hugging Face community page.
aiida-core
AiiDA (www.aiida.net) is a workflow manager for computational science with a strong focus on provenance, performance and extensibility. **Features** * **Workflows:** Write complex, auto-documenting workflows in python, linked to arbitrary executables on local and remote computers. The event-based workflow engine supports tens of thousands of processes per hour with full checkpointing. * **Data provenance:** Automatically track inputs, outputs & metadata of all calculations in a provenance graph for full reproducibility. Perform fast queries on graphs containing millions of nodes. * **HPC interface:** Move your calculations to a different computer by changing one line of code. AiiDA is compatible with schedulers like SLURM, PBS Pro, torque, SGE or LSF out of the box. * **Plugin interface:** Extend AiiDA with plugins for new simulation codes (input generation & parsing), data types, schedulers, transport modes and more. * **Open Science:** Export subsets of your provenance graph and share them with peers or make them available online for everyone on the Materials Cloud. * **Open source:** AiiDA is released under the MIT open source license
neptune-client
Neptune is a scalable experiment tracker for teams training foundation models. Log millions of runs, effortlessly monitor and visualize model training, and deploy on your infrastructure. Track 100% of metadata to accelerate AI breakthroughs. Log and display any framework and metadata type from any ML pipeline. Organize experiments with nested structures and custom dashboards. Compare results, visualize training, and optimize models quicker. Version models, review stages, and access production-ready models. Share results, manage users, and projects. Integrate with 25+ frameworks. Trusted by great companies to improve workflow.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.

clearml
ClearML is a suite of tools designed to streamline the machine learning workflow. It includes an experiment manager, MLOps/LLMOps, data management, and model serving capabilities. ClearML is open-source and offers a free tier hosting option. It supports various ML/DL frameworks and integrates with Jupyter Notebook and PyCharm. ClearML provides extensive logging capabilities, including source control info, execution environment, hyper-parameters, and experiment outputs. It also offers automation features, such as remote job execution and pipeline creation. ClearML is designed to be easy to integrate, requiring only two lines of code to add to existing scripts. It aims to improve collaboration, visibility, and data transparency within ML teams.

Kiln
Kiln is an intuitive tool for fine-tuning LLM models, generating synthetic data, and collaborating on datasets. It offers desktop apps for Windows, MacOS, and Linux, zero-code fine-tuning for various models, interactive data generation, and Git-based version control. Users can easily collaborate with QA, PM, and subject matter experts, generate auto-prompts, and work with a wide range of models and providers. The tool is open-source, privacy-first, and supports structured data tasks in JSON format. Kiln is free to use and helps build high-quality AI products with datasets, facilitates collaboration between technical and non-technical teams, allows comparison of models and techniques without code, ensures structured data integrity, and prioritizes user privacy.

clearml
ClearML is an auto-magical suite of tools designed to streamline AI workflows. It includes modules for experiment management, MLOps/LLMOps, data management, model serving, and more. ClearML offers features like experiment tracking, model serving, orchestration, and automation. It supports various ML/DL frameworks and integrates with Jupyter Notebook and PyCharm for remote debugging. ClearML aims to simplify collaboration, automate processes, and enhance visibility in AI projects.

mlflow
MLflow is a platform to streamline machine learning development, including tracking experiments, packaging code into reproducible runs, and sharing and deploying models. MLflow offers a set of lightweight APIs that can be used with any existing machine learning application or library (TensorFlow, PyTorch, XGBoost, etc), wherever you currently run ML code (e.g. in notebooks, standalone applications or the cloud). MLflow's current components are:
* `MLflow Tracking

h2ogpt
h2oGPT is an Apache V2 open-source project that allows users to query and summarize documents or chat with local private GPT LLMs. It features a private offline database of any documents (PDFs, Excel, Word, Images, Video Frames, Youtube, Audio, Code, Text, MarkDown, etc.), a persistent database (Chroma, Weaviate, or in-memory FAISS) using accurate embeddings (instructor-large, all-MiniLM-L6-v2, etc.), and efficient use of context using instruct-tuned LLMs (no need for LangChain's few-shot approach). h2oGPT also offers parallel summarization and extraction, reaching an output of 80 tokens per second with the 13B LLaMa2 model, HYDE (Hypothetical Document Embeddings) for enhanced retrieval based upon LLM responses, a variety of models supported (LLaMa2, Mistral, Falcon, Vicuna, WizardLM. With AutoGPTQ, 4-bit/8-bit, LORA, etc.), GPU support from HF and LLaMa.cpp GGML models, and CPU support using HF, LLaMa.cpp, and GPT4ALL models. Additionally, h2oGPT provides Attention Sinks for arbitrarily long generation (LLaMa-2, Mistral, MPT, Pythia, Falcon, etc.), a UI or CLI with streaming of all models, the ability to upload and view documents through the UI (control multiple collaborative or personal collections), Vision Models LLaVa, Claude-3, Gemini-Pro-Vision, GPT-4-Vision, Image Generation Stable Diffusion (sdxl-turbo, sdxl) and PlaygroundAI (playv2), Voice STT using Whisper with streaming audio conversion, Voice TTS using MIT-Licensed Microsoft Speech T5 with multiple voices and Streaming audio conversion, Voice TTS using MPL2-Licensed TTS including Voice Cloning and Streaming audio conversion, AI Assistant Voice Control Mode for hands-free control of h2oGPT chat, Bake-off UI mode against many models at the same time, Easy Download of model artifacts and control over models like LLaMa.cpp through the UI, Authentication in the UI by user/password via Native or Google OAuth, State Preservation in the UI by user/password, Linux, Docker, macOS, and Windows support, Easy Windows Installer for Windows 10 64-bit (CPU/CUDA), Easy macOS Installer for macOS (CPU/M1/M2), Inference Servers support (oLLaMa, HF TGI server, vLLM, Gradio, ExLLaMa, Replicate, OpenAI, Azure OpenAI, Anthropic), OpenAI-compliant, Server Proxy API (h2oGPT acts as drop-in-replacement to OpenAI server), Python client API (to talk to Gradio server), JSON Mode with any model via code block extraction. Also supports MistralAI JSON mode, Claude-3 via function calling with strict Schema, OpenAI via JSON mode, and vLLM via guided_json with strict Schema, Web-Search integration with Chat and Document Q/A, Agents for Search, Document Q/A, Python Code, CSV frames (Experimental, best with OpenAI currently), Evaluate performance using reward models, and Quality maintained with over 1000 unit and integration tests taking over 4 GPU-hours.

sdialog
SDialog is an MIT-licensed open-source toolkit for building, simulating, and evaluating LLM-based conversational agents end-to-end. It aims to bridge agent construction, user simulation, dialog generation, and evaluation in a single reproducible workflow, enabling the generation of reliable, controllable dialog systems or data at scale. The toolkit standardizes a Dialog schema, offers persona-driven multi-agent simulation with LLMs, provides composable orchestration for precise control over behavior and flow, includes built-in evaluation metrics, and offers mechanistic interpretability. It allows for easy creation of user-defined components and interoperability across various AI platforms.

vllm
vLLM is a fast and easy-to-use library for LLM inference and serving. It is designed to be efficient, flexible, and easy to use. vLLM can be used to serve a variety of LLM models, including Hugging Face models. It supports a variety of decoding algorithms, including parallel sampling, beam search, and more. vLLM also supports tensor parallelism for distributed inference and streaming outputs. It is open-source and available on GitHub.
Agent-R1
Agent-R1 is an open-source framework designed to accelerate research and development at the critical intersection of RL and Agent. It employs End-to-End reinforcement learning to train agents in specific environments. Developers define domain-specific tools and reward functions to extend Agent-R1 to unique use cases, eliminating the need for complex workflow engineering. Key features include multi-turn tool calling, multi-tool coordination, process rewards, custom tools and environments, support for multiple RL algorithms, and multi-modal support. It aims to make it easier for researchers and developers to create and explore agents in their own domains, collectively advancing the development of autonomous agents.

TaskingAI
TaskingAI brings Firebase's simplicity to **AI-native app development**. The platform enables the creation of GPTs-like multi-tenant applications using a wide range of LLMs from various providers. It features distinct, modular functions such as Inference, Retrieval, Assistant, and Tool, seamlessly integrated to enhance the development process. TaskingAI’s cohesive design ensures an efficient, intelligent, and user-friendly experience in AI application development.
onyx-foss
Onyx is an open-source AI platform that offers a feature-rich, self-hostable Chat UI with advanced features like custom agents, web search, RAG, connectors to 40+ knowledge sources, deep research, code interpreter, image generation, collaboration tools, and more. It works with various LLMs and self-hosted LLMs, providing users with a versatile and powerful tool for AI-related tasks.
workflows-py
LlamaIndex Workflows is a framework for orchestrating and chaining together complex systems of steps and events. It shines in orchestrating complex, multi-step processes involving AI models, APIs, and decision-making. The async-first, event-driven architecture allows building workflows that can route between different capabilities, implement parallel processing patterns, loop over complex sequences, and maintain state across multiple steps. Key features include async-first design, event-driven structure, state management, and observability through tools like Arize Phoenix and OpenTelemetry.
For similar tasks
DataDreamer
DataDreamer is a powerful open-source Python library designed for prompting, synthetic data generation, and training workflows. It is simple, efficient, and research-grade, allowing users to create prompting workflows, generate synthetic datasets, and train models with ease. The library is built for researchers, by researchers, focusing on correctness, best practices, and reproducibility. It offers features like aggressive caching, resumability, support for bleeding-edge techniques, and easy sharing of datasets and models. DataDreamer enables users to run multi-step prompting workflows, generate synthetic datasets for various tasks, and train models by aligning, fine-tuning, instruction-tuning, and distilling them using existing or synthetic data.
RAG-Retrieval
RAG-Retrieval is an end-to-end code repository that provides training, inference, and distillation capabilities for the RAG retrieval model. It supports fine-tuning of various open-source RAG retrieval models, including embedding models, late interactive models, and reranker models. The repository offers a lightweight Python library for calling different RAG ranking models and allows distillation of LLM-based reranker models into bert-based reranker models. It includes features such as support for end-to-end fine-tuning, distillation of large models, advanced algorithms like MRL, multi-GPU training strategy, and a simple code structure for easy modifications.

mindsdb
MindsDB is a platform for customizing AI from enterprise data. You can create, serve, and fine-tune models in real-time from your database, vector store, and application data. MindsDB "enhances" SQL syntax with AI capabilities to make it accessible for developers worldwide. With MindsDB’s nearly 200 integrations, any developer can create AI customized for their purpose, faster and more securely. Their AI systems will constantly improve themselves — using companies’ own data, in real-time.

training-operator
Kubeflow Training Operator is a Kubernetes-native project for fine-tuning and scalable distributed training of machine learning (ML) models created with various ML frameworks such as PyTorch, Tensorflow, XGBoost, MPI, Paddle and others. Training Operator allows you to use Kubernetes workloads to effectively train your large models via Kubernetes Custom Resources APIs or using Training Operator Python SDK. > Note: Before v1.2 release, Kubeflow Training Operator only supports TFJob on Kubernetes. * For a complete reference of the custom resource definitions, please refer to the API Definition. * TensorFlow API Definition * PyTorch API Definition * Apache MXNet API Definition * XGBoost API Definition * MPI API Definition * PaddlePaddle API Definition * For details of all-in-one operator design, please refer to the All-in-one Kubeflow Training Operator * For details on its observability, please refer to the monitoring design doc.

helix
HelixML is a private GenAI platform that allows users to deploy the best of open AI in their own data center or VPC while retaining complete data security and control. It includes support for fine-tuning models with drag-and-drop functionality. HelixML brings the best of open source AI to businesses in an ergonomic and scalable way, optimizing the tradeoff between GPU memory and latency.

nntrainer
NNtrainer is a software framework for training neural network models on devices with limited resources. It enables on-device fine-tuning of neural networks using user data for personalization. NNtrainer supports various machine learning algorithms and provides examples for tasks such as few-shot learning, ResNet, VGG, and product rating. It is optimized for embedded devices and utilizes CBLAS and CUBLAS for accelerated calculations. NNtrainer is open source and released under the Apache License version 2.0.

petals
Petals is a tool that allows users to run large language models at home in a BitTorrent-style manner. It enables fine-tuning and inference up to 10x faster than offloading. Users can generate text with distributed models like Llama 2, Falcon, and BLOOM, and fine-tune them for specific tasks directly from their desktop computer or Google Colab. Petals is a community-run system that relies on people sharing their GPUs to increase its capacity and offer a distributed network for hosting model layers.

LLaVA-pp
This repository, LLaVA++, extends the visual capabilities of the LLaVA 1.5 model by incorporating the latest LLMs, Phi-3 Mini Instruct 3.8B, and LLaMA-3 Instruct 8B. It provides various models for instruction-following LMMS and academic-task-oriented datasets, along with training scripts for Phi-3-V and LLaMA-3-V. The repository also includes installation instructions and acknowledgments to related open-source contributions.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.
griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.