
RAG-Retrieval
Unify Efficient Fine-tuning of RAG Retrieval, including Embedding, ColBERT, ReRanker.
Stars: 755
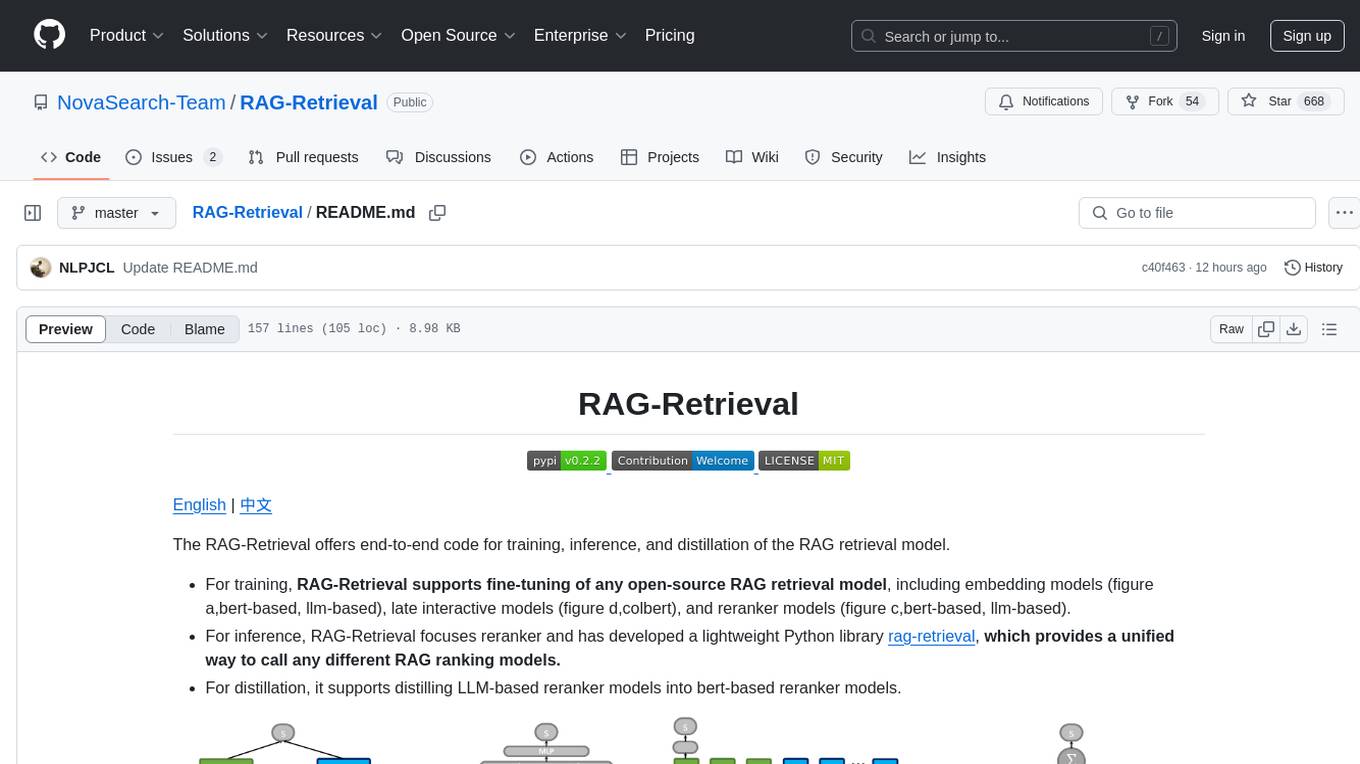
RAG-Retrieval is an end-to-end code repository that provides training, inference, and distillation capabilities for the RAG retrieval model. It supports fine-tuning of various open-source RAG retrieval models, including embedding models, late interactive models, and reranker models. The repository offers a lightweight Python library for calling different RAG ranking models and allows distillation of LLM-based reranker models into bert-based reranker models. It includes features such as support for end-to-end fine-tuning, distillation of large models, advanced algorithms like MRL, multi-GPU training strategy, and a simple code structure for easy modifications.
README:

The RAG-Retrieval offers end-to-end code for training, inference, and distillation of the RAG retrieval model.
- For training, RAG-Retrieval supports fine-tuning of any open-source RAG retrieval models, including embedding models (figure a,bert-based, llm-based), late interactive models (figure d,colbert), and reranker models (figure c,bert-based, llm-based).
- For inference, RAG-Retrieval focuses reranker and has developed a lightweight Python library rag-retrieval, which provides a unified way to call any different RAG ranking models.
- For distillation, Distillation of support embedding models and reranker models, support distill from a larger model to a smaller model (0.5b llm or bert-base).

-
12/29/2024: RAG-Retrieval released the core training code (stage3) of Stella and Jasper embedding model Jasper and Stella: distillation of SOTA embedding models.
-
10/21/2024: RAG-Retrieval released two different methods for Reranker tasks based on LLM, as well as a method for distilling them into BERT. Best Practices for LLM in Reranker Tasks? A Simple Experiment Report (with code)
-
6/5/2024: Implementation of MRL loss for the Embedding model in RAG-Retrieval. RAG-Retrieval: Making MRL Loss a Standard for Training Vector (Embedding) Models
-
6/2/2024: RAG-Retrieval implements LLM preference-based supervised fine-tuning of the RAG retriever. RAG-Retrieval Implements LLM Preference-Based Supervised Fine-Tuning of the RAG Retriever
-
5/5/2024: Released a lightweight Python library for RAG-Retrieval. RAG-Retrieval: Your RAG Application Deserves a Better Ranking Reasoning Framework
-
3/18/2024: Released RAG-Retrieval Introduction to RAG-Retrieval on Zhihu
- Supports end-to-end fine-tuning of RAG retrieval models: Embedding (bert-based, llm-based), late interaction models (colbert), and reranker models (bert-based, llm-based).
- Supports fine-tuning of any open-source RAG retrieval models: Compatible with most open-source embedding and reranker models, such as: bge (bge-embedding, bge-m3, bge-reranker), bce (bce-embedding, bce-reranker), gte (gte-embedding, gte-multilingual-reranker-base).
- Supports distillation of llm-based large models to bert-based smaller models: Currently supports the distillation of llm-based reranker models into bert-based reranker models (implementation of mean squared error and cross-entropy loss).
- Advanced Algorithms: For embedding models, supports the MRL algorithm to reduce the dimensionality of output vectors.
- Multi-gpu training strategy: Includes deepspeed, fsdp.
- Simple yet Elegant: Rejects complex, with a simple and understandable code structure for easy modifications.
For training (all):
conda create -n rag-retrieval python=3.8 && conda activate rag-retrieval
# To avoid incompatibility between the automatically installed torch and the local cuda, it is recommended to manually install the compatible version of torch before proceeding to the next step.
pip install -r requirements.txt For prediction (reranker):
# To avoid incompatibility between the automatically installed torch and the local cuda, it is recommended to manually install the compatible version of torch before proceeding to the next step.
pip install rag-retrievalFor different model types, please go into different subdirectories. For example: For embedding, and similarly for others. Detailed procedures can be found in the README file in each subdirectories.
cd ./rag_retrieval/train/embedding
bash train_embedding.shRAG-Retrieval has developed a lightweight Python library, rag-retrieval, which provides a unified interface for calling various RAG reranker models with the following features:
-
Supports multiple ranking models: Compatible with common open-source ranking models (Cross Encoder Reranker, Decoder-Only LLM Reranker).
-
Long document friendly: Supports two different handling logics for long documents (maximum length truncation and splitting to take the maximum score).
-
Easy to Extend: If there is a new ranking model, users only need to inherit from BaseReranker and implement the rank and compute_score functions.
For detailed usage and considerations of the rag-retrieval package, please refer to the Tutorial
| Model | Model Size(GB) | T2Reranking | MMarcoReranking | CMedQAv1 | CMedQAv2 | Avg |
|---|---|---|---|---|---|---|
| bge-reranker-base | 1.11 | 67.28 | 35.46 | 81.27 | 84.10 | 67.03 |
| bce-reranker-base_v1 | 1.11 | 70.25 | 34.13 | 79.64 | 81.31 | 66.33 |
| rag-retrieval-reranker | 0.41 | 67.33 | 31.57 | 83.54 | 86.03 | 67.12 |
Among them, rag-retrieval-reranker is the result of training on the hfl/chinese-roberta-wwm-ext model using the RAG-Retrieval code, and the training data uses the training data of the bge-rerank model.
| Model | Model Size(GB) | Dim | T2Reranking | MMarcoReranking | CMedQAv1 | CMedQAv2 | Avg |
|---|---|---|---|---|---|---|---|
| bge-m3-colbert | 2.24 | 1024 | 66.82 | 26.71 | 75.88 | 76.83 | 61.56 |
| rag-retrieval-colbert | 0.41 | 1024 | 66.85 | 31.46 | 81.05 | 84.22 | 65.90 |
Among them, rag-retrieval-colbert is the result of training on the hfl/chinese-roberta-wwm-ext model using the RAG-Retrieval code, and the training data uses the training data of the bge-rerank model.
| Model | T2ranking | |
|---|---|---|
| bge-v1.5-embedding | 66.49 | |
| bge-v1.5-embedding finetune | 67.15 | +0.66 |
| bge-m3-colbert | 66.82 | |
| bge-m3-colbert finetune | 67.22 | +0.40 |
| bge-reranker-base | 67.28 | |
| bge-reranker-base finetune | 67.57 | +0.29 |
The number with finetune at the end means that we used RAG-Retrieval to fine-tune the corresponding open source model, and the training data used the training set of T2-Reranking.
It is worth noting that the training set of the three open source models of bge already includes T2-Reranking, and the data is relatively general, so the performance improvement of fine-tuning using this data is not significant. However, if the open source model is fine-tuned using a vertical field data set, the performance improvement will be greater.
If you find this repository helpful, please cite our work:
@misc{zhang2025jasperstelladistillationsota,
title={Jasper and Stella: distillation of SOTA embedding models},
author={Dun Zhang and Jiacheng Li and Ziyang Zeng and Fulong Wang},
year={2025},
eprint={2412.19048},
archivePrefix={arXiv},
primaryClass={cs.IR},
url={https://arxiv.org/abs/2412.19048},
}RAG-Retrieval is licensed under the MIT License.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for RAG-Retrieval
Similar Open Source Tools
RAG-Retrieval
RAG-Retrieval is an end-to-end code repository that provides training, inference, and distillation capabilities for the RAG retrieval model. It supports fine-tuning of various open-source RAG retrieval models, including embedding models, late interactive models, and reranker models. The repository offers a lightweight Python library for calling different RAG ranking models and allows distillation of LLM-based reranker models into bert-based reranker models. It includes features such as support for end-to-end fine-tuning, distillation of large models, advanced algorithms like MRL, multi-GPU training strategy, and a simple code structure for easy modifications.
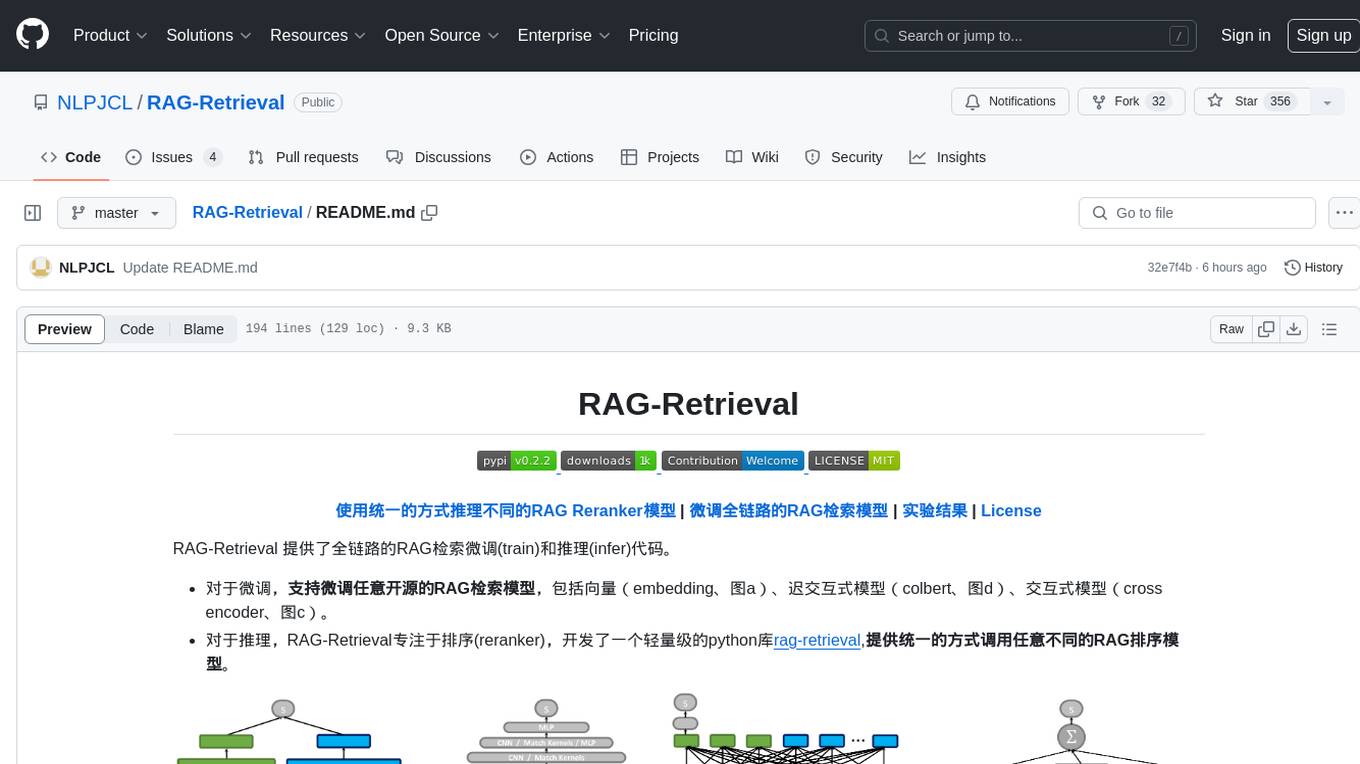
RAG-Retrieval
RAG-Retrieval provides full-chain RAG retrieval fine-tuning and inference code. It supports fine-tuning any open-source RAG retrieval models, including vector (embedding, graph a), delayed interactive models (ColBERT, graph d), interactive models (cross encoder, graph c). For inference, RAG-Retrieval focuses on ranking (reranker) and has developed a lightweight Python library rag-retrieval, providing a unified way to call any different RAG ranking models.
llm-awq
AWQ (Activation-aware Weight Quantization) is a tool designed for efficient and accurate low-bit weight quantization (INT3/4) for Large Language Models (LLMs). It supports instruction-tuned models and multi-modal LMs, providing features such as AWQ search for accurate quantization, pre-computed AWQ model zoo for various LLMs, memory-efficient 4-bit linear in PyTorch, and efficient CUDA kernel implementation for fast inference. The tool enables users to run large models on resource-constrained edge platforms, delivering more efficient responses with LLM/VLM chatbots through 4-bit inference.
kornia
Kornia is a differentiable computer vision library for PyTorch. It consists of a set of routines and differentiable modules to solve generic computer vision problems. At its core, the package uses PyTorch as its main backend both for efficiency and to take advantage of the reverse-mode auto-differentiation to define and compute the gradient of complex functions.

X-AnyLabeling
X-AnyLabeling is a robust annotation tool that seamlessly incorporates an AI inference engine alongside an array of sophisticated features. Tailored for practical applications, it is committed to delivering comprehensive, industrial-grade solutions for image data engineers. This tool excels in swiftly and automatically executing annotations across diverse and intricate tasks.
parallax
Parallax is a fully decentralized inference engine developed by Gradient. It allows users to build their own AI cluster for model inference across distributed nodes with varying configurations and physical locations. Core features include hosting local LLM on personal devices, cross-platform support, pipeline parallel model sharding, paged KV cache management, continuous batching for Mac, dynamic request scheduling, and routing for high performance. The backend architecture includes P2P communication powered by Lattica, GPU backend powered by SGLang and vLLM, and MAC backend powered by MLX LM.
SciCode
SciCode is a challenging benchmark designed to evaluate the capabilities of language models (LMs) in generating code for solving realistic scientific research problems. It contains 338 subproblems decomposed from 80 challenging main problems across 16 subdomains from 6 domains. The benchmark offers optional descriptions specifying useful scientific background information and scientist-annotated gold-standard solutions and test cases for evaluation. SciCode demonstrates a realistic workflow of identifying critical science concepts and facts and transforming them into computation and simulation code, aiming to help showcase LLMs' progress towards assisting scientists and contribute to the future building and evaluation of scientific AI.
Pai-Megatron-Patch
Pai-Megatron-Patch is a deep learning training toolkit built for developers to train and predict LLMs & VLMs by using Megatron framework easily. With the continuous development of LLMs, the model structure and scale are rapidly evolving. Although these models can be conveniently manufactured using Transformers or DeepSpeed training framework, the training efficiency is comparably low. This phenomenon becomes even severer when the model scale exceeds 10 billion. The primary objective of Pai-Megatron-Patch is to effectively utilize the computational power of GPUs for LLM. This tool allows convenient training of commonly used LLM with all the accelerating techniques provided by Megatron-LM.

nuitrack-sdk
Nuitrack™ is an ultimate 3D body tracking solution developed by 3DiVi Inc. It enables body motion analytics applications for virtually any widespread depth sensors and hardware platforms, supporting a wide range of applications from real-time gesture recognition on embedded platforms to large-scale multisensor analytical systems. Nuitrack provides highly-sophisticated 3D skeletal tracking, basic facial analysis, hand tracking, and gesture recognition APIs for UI control. It offers two skeletal tracking engines: classical for embedded hardware and AI for complex poses, providing a human-centric spatial understanding tool for natural and intelligent user engagement.
netdata
Netdata is an open-source, real-time infrastructure monitoring platform that provides instant insights, zero configuration deployment, ML-powered anomaly detection, efficient monitoring with minimal resource usage, and secure & distributed data storage. It offers real-time, per-second updates and clear insights at a glance. Netdata's origin story involves addressing the limitations of existing monitoring tools and led to a fundamental shift in infrastructure monitoring. It is recognized as the most energy-efficient tool for monitoring Docker-based systems according to a study by the University of Amsterdam.
Streamline-Analyst
Streamline Analyst is a cutting-edge, open-source application powered by Large Language Models (LLMs) designed to revolutionize data analysis. This Data Analysis Agent effortlessly automates tasks such as data cleaning, preprocessing, and complex operations like identifying target objects, partitioning test sets, and selecting the best-fit models based on your data. With Streamline Analyst, results visualization and evaluation become seamless. It aims to expedite the data analysis process, making it accessible to all, regardless of their expertise in data analysis. The tool is built to empower users to process data and achieve high-quality visualizations with unparalleled efficiency, and to execute high-performance modeling with the best strategies. Future enhancements include Natural Language Processing (NLP), neural networks, and object detection utilizing YOLO, broadening its capabilities to meet diverse data analysis needs.

MM-RLHF
MM-RLHF is a comprehensive project for aligning Multimodal Large Language Models (MLLMs) with human preferences. It includes a high-quality MLLM alignment dataset, a Critique-Based MLLM reward model, a novel alignment algorithm MM-DPO, and benchmarks for reward models and multimodal safety. The dataset covers image understanding, video understanding, and safety-related tasks with model-generated responses and human-annotated scores. The reward model generates critiques of candidate texts before assigning scores for enhanced interpretability. MM-DPO is an alignment algorithm that achieves performance gains with simple adjustments to the DPO framework. The project enables consistent performance improvements across 10 dimensions and 27 benchmarks for open-source MLLMs.
learn-low-code-agentic-ai
This repository is dedicated to learning about Low-Code Full-Stack Agentic AI Development. It provides material for building modern AI-powered applications using a low-code full-stack approach. The main tools covered are UXPilot for UI/UX mockups, Lovable.dev for frontend applications, n8n for AI agents and workflows, Supabase for backend data storage, authentication, and vector search, and Model Context Protocol (MCP) for integration. The focus is on prompt and context engineering as the foundation for working with AI systems, enabling users to design, develop, and deploy AI-driven full-stack applications faster, smarter, and more reliably.

joliGEN
JoliGEN is an integrated framework for training custom generative AI image-to-image models. It implements GAN, Diffusion, and Consistency models for various image translation tasks, including domain and style adaptation with conservation of semantics. The tool is designed for real-world applications such as Controlled Image Generation, Augmented Reality, Dataset Smart Augmentation, and Synthetic to Real transforms. JoliGEN allows for fast and stable training with a REST API server for simplified deployment. It offers a wide range of options and parameters with detailed documentation available for models, dataset formats, and data augmentation.
lancedb
LanceDB is an open-source database for vector-search built with persistent storage, which greatly simplifies retrieval, filtering, and management of embeddings. The key features of LanceDB include: Production-scale vector search with no servers to manage. Store, query, and filter vectors, metadata, and multi-modal data (text, images, videos, point clouds, and more). Support for vector similarity search, full-text search, and SQL. Native Python and Javascript/Typescript support. Zero-copy, automatic versioning, manage versions of your data without needing extra infrastructure. GPU support in building vector index(*). Ecosystem integrations with LangChain 🦜️🔗, LlamaIndex 🦙, Apache-Arrow, Pandas, Polars, DuckDB, and more on the way. LanceDB's core is written in Rust 🦀 and is built using Lance, an open-source columnar format designed for performant ML workloads.
MemMachine
MemMachine is an open-source long-term memory layer designed for AI agents and LLM-powered applications. It enables AI to learn, store, and recall information from past sessions, transforming stateless chatbots into personalized, context-aware assistants. With capabilities like episodic memory, profile memory, working memory, and agent memory persistence, MemMachine offers a developer-friendly API, flexible storage options, and seamless integration with various AI frameworks. It is suitable for developers, researchers, and teams needing persistent, cross-session memory for their LLM applications.
For similar tasks

DataDreamer
DataDreamer is a powerful open-source Python library designed for prompting, synthetic data generation, and training workflows. It is simple, efficient, and research-grade, allowing users to create prompting workflows, generate synthetic datasets, and train models with ease. The library is built for researchers, by researchers, focusing on correctness, best practices, and reproducibility. It offers features like aggressive caching, resumability, support for bleeding-edge techniques, and easy sharing of datasets and models. DataDreamer enables users to run multi-step prompting workflows, generate synthetic datasets for various tasks, and train models by aligning, fine-tuning, instruction-tuning, and distilling them using existing or synthetic data.
RAG-Retrieval
RAG-Retrieval is an end-to-end code repository that provides training, inference, and distillation capabilities for the RAG retrieval model. It supports fine-tuning of various open-source RAG retrieval models, including embedding models, late interactive models, and reranker models. The repository offers a lightweight Python library for calling different RAG ranking models and allows distillation of LLM-based reranker models into bert-based reranker models. It includes features such as support for end-to-end fine-tuning, distillation of large models, advanced algorithms like MRL, multi-GPU training strategy, and a simple code structure for easy modifications.

mindsdb
MindsDB is a platform for customizing AI from enterprise data. You can create, serve, and fine-tune models in real-time from your database, vector store, and application data. MindsDB "enhances" SQL syntax with AI capabilities to make it accessible for developers worldwide. With MindsDB’s nearly 200 integrations, any developer can create AI customized for their purpose, faster and more securely. Their AI systems will constantly improve themselves — using companies’ own data, in real-time.

training-operator
Kubeflow Training Operator is a Kubernetes-native project for fine-tuning and scalable distributed training of machine learning (ML) models created with various ML frameworks such as PyTorch, Tensorflow, XGBoost, MPI, Paddle and others. Training Operator allows you to use Kubernetes workloads to effectively train your large models via Kubernetes Custom Resources APIs or using Training Operator Python SDK. > Note: Before v1.2 release, Kubeflow Training Operator only supports TFJob on Kubernetes. * For a complete reference of the custom resource definitions, please refer to the API Definition. * TensorFlow API Definition * PyTorch API Definition * Apache MXNet API Definition * XGBoost API Definition * MPI API Definition * PaddlePaddle API Definition * For details of all-in-one operator design, please refer to the All-in-one Kubeflow Training Operator * For details on its observability, please refer to the monitoring design doc.

helix
HelixML is a private GenAI platform that allows users to deploy the best of open AI in their own data center or VPC while retaining complete data security and control. It includes support for fine-tuning models with drag-and-drop functionality. HelixML brings the best of open source AI to businesses in an ergonomic and scalable way, optimizing the tradeoff between GPU memory and latency.

nntrainer
NNtrainer is a software framework for training neural network models on devices with limited resources. It enables on-device fine-tuning of neural networks using user data for personalization. NNtrainer supports various machine learning algorithms and provides examples for tasks such as few-shot learning, ResNet, VGG, and product rating. It is optimized for embedded devices and utilizes CBLAS and CUBLAS for accelerated calculations. NNtrainer is open source and released under the Apache License version 2.0.

petals
Petals is a tool that allows users to run large language models at home in a BitTorrent-style manner. It enables fine-tuning and inference up to 10x faster than offloading. Users can generate text with distributed models like Llama 2, Falcon, and BLOOM, and fine-tune them for specific tasks directly from their desktop computer or Google Colab. Petals is a community-run system that relies on people sharing their GPUs to increase its capacity and offer a distributed network for hosting model layers.

LLaVA-pp
This repository, LLaVA++, extends the visual capabilities of the LLaVA 1.5 model by incorporating the latest LLMs, Phi-3 Mini Instruct 3.8B, and LLaMA-3 Instruct 8B. It provides various models for instruction-following LMMS and academic-task-oriented datasets, along with training scripts for Phi-3-V and LLaMA-3-V. The repository also includes installation instructions and acknowledgments to related open-source contributions.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.