
Pai-Megatron-Patch
The official repo of Pai-Megatron-Patch for LLM & VLM large scale training developed by Alibaba Cloud.
Stars: 923
Pai-Megatron-Patch is a deep learning training toolkit built for developers to train and predict LLMs & VLMs by using Megatron framework easily. With the continuous development of LLMs, the model structure and scale are rapidly evolving. Although these models can be conveniently manufactured using Transformers or DeepSpeed training framework, the training efficiency is comparably low. This phenomenon becomes even severer when the model scale exceeds 10 billion. The primary objective of Pai-Megatron-Patch is to effectively utilize the computational power of GPUs for LLM. This tool allows convenient training of commonly used LLM with all the accelerating techniques provided by Megatron-LM.
README:
| Megatron-LM-Dense | Megatron-Core-Dense | Megatron-Core-MoE | MegaBlocks-MoE | |
|---|---|---|---|---|
| DeepSeek-V3 | N/A | N/A | ReadMe | N/A |
| Qwen2-VL | N/A | ReadMe | N/A | N/A |
| LLaVA | N/A | ReadMe | N/A | N/A |
| Qwen2.5 | N/A | ReadMe | N/A | N/A |
| LLama3.1 | N/A | ReadMe | N/A | N/A |
| LLama3 | ReadMe | ReadMe | N/A | N/A |
| LLama2 | ReadMe | ReadMe | N/A | N/A |
| Mistral | ReadMe | ReadMe | ReadMe | N/A |
| Qwen2 | N/A | ReadMe | ReadMe | N/A |
| Qwen1.5 | ReadMe | ReadMe | ReadMe | ReadMe |
| DeepSeek-V2 | N/A | N/A | ReadMe | N/A |
English | 简体中文
Pai-Megatron-Patch (https://github.com/alibaba/Pai-Megatron-Patch) is a deep learning training toolkit built for developers to train and predict LLMs & VLMs by using Megatron framework easily. With the continuous development of LLMs, the model structure and scale are rapidly evolving. Although these models can be conveniently manufactured using Transformers or DeepSpeed training framework, the training efficiency is comparably low. This phenomenon becomes even severer when the model scale exceeds 10 billion. The primary objective of Pai-Megatron-Patch is to effectively utilize the computational power of GPUs for LLM. This tool allows convenient training of commonly used LLM with all the accelerating techniques provided by Megatron-LM.
What's New:
- Support training DeepSeek-V3 671B model by using Megatron-Core. [🔥🔥 2025.02.21]
- Upgrade LLM SFT Training Process [🔥🔥 2025.02.20]
- Upgrade DeepSeek-V2-MoE for facilitating a smooth transition to integrating the DeepSeek-V3-MoE. [🔥🔥 2025.01.16]
- Upgrade Qwen2-VL models to support Sequence Parallel, VPP and TP-Comm-Overlap. [🔥🔥 2025.01.15]
- Upgrade Qwen2-VL models to support MG2HF ckpts conversion and training with multi-turn complex multimodal samples. [🔥🔥 2024.12.27]
- Support training Qwen2-VL models by using Megatron-Core. [🔥🔥 2024.11.27]
- Support training LLaVA models by using Megatron-Core. [🔥🔥 2024.11.20]
- Add llm auto configurator and apply per seq sft loss for qwen2/2.5 models. [🔥🔥 2024.10.30]
- Upgrade deepseek-v2-moe models to support MLA via transformer engine and pipeline ckpts conversion. [🔥🔥 2024.09.26]
- Support training Qwen2.5 models by using Megatron-Core. [🔥🔥 2024.09.20]
- Support Sequence Packing in SFT for Qwen2 and LLaMA 3.1 models. [🔥🔥 2024.09.13]
- Upgrade qwen2 dense and moe models to support Flash-Attention 3, Offloading, Comm-Overlapping features. [🔥🔥 2024.08.26]
- Support training LLaMA 3.1 dense models with Flash-Attention 3 backend. [🔥🔥 2024.08.23]
- Support training LLaMA 3.1 dense models by using Megatron-Core. [🔥🔥 2024.08.23]
- Support auto optimizer offloading in OffloadDistributedOptimizer. [🔥🔥 2024.07.25]
- Support static optimizer offloading in OffloadDistributedOptimizer. [🔥🔥 2024.07.15]
- Support training qwen2 moe models by using Megatron-Core. [🔥🔥 2024.06.19]
- Support training qwen2 dense models by using Megatron-Core. [🔥🔥 2024.06.12]
- Support training deepseek-v2-moe models by using Megatron-Core. [🔥🔥 2024.05.30]
- Support training qwen1.5-moe models by using Megatron-Core. [🔥🔥 2024.05.13]
- Support training llama3 models by using Megatron-LM and Megatron-Core. [🔥🔥 2024.04.21]
- Support training qwen1.5 models by using Megatron-Core. [🔥🔥 2024.03.20]
- Support training qwen1.5 models by using Megatron-LM. [🔥🔥 2024.02.28]
- Support training mixtral-8x7b moe model by using Megatron-Core. [🔥🔥 2024.01.26]
- Support training qwen-vl multimodel by using Megatron-LM. [🔥🔥 2023.12.15]
- Support training LLava multimodel by using Megatron-LM. [🔥🔥 2023.12.01]
- Support training deepseek model by using Megatron-LM. [🔥🔥 2023.11.24]
- Support training qwen-72B model by using Megatron-LM. [🔥🔥 2023.11.23]
- Support training Mistral-7B, Yi-6B and Codellama-34B [🔥🔥 2023.11.16]
- Upgrade Megatron-LM for Llama2, qwen and baichuan2 to use transformer engine and fp8. [🔥🔥 2023.10.19]
- Support training qwen-14B and baichuan2-13B model by using Megatron-LM. [🔥🔥 2023.10.08]
Pai-Megatron-Patch is developed by the Alibaba Cloud Machine Learning Platform (PAI) algorithm team. The tool aims to assist developers in quickly getting started with Lingjun products and completing the entire development pipeline for LLM, including efficient distributed training, supervised fine-tuning, and offline model inference or verification. It has several merits as follows:
- Support for multiple commonly used LLM such as llama, llama-2, codellama, deepseek, baichuan, qwen, Falcon, GLM, Starcoder, Bloom, chatglm, etc.
- Support for model weight conversion: Mapping operator namespaces between Huggingface, Megatron, and Transformer Engine.
- Support for FP8 training acceleration in Flash Attention 2.0 and Transformer Engine modes, ensuring training convergence.
- Rich and user-friendly usage examples, offering best practices for the entire workflow of LLM pre-training, fine-tuning, evaluation, and inference, as well as reinforcement learning.
The design philosophy of Pai-Megatron-Patch is to avoid invasive modifications to the source code of Megatron-LM. In other words, it does not add new modules directly to Megatron-LM. Instead, the functions that need expansion and improvement are presented in the form of patch. This decoupling ensures that users can continue to embrace the best practices of LLM without being affected by upgrades of Megatron-LM.
Pai-Megatron-Patch includes key components for building LLM training, such as model library, tokenizers, model convertors, reinforcement learning , offline text generation, usages examples, and toolkits. The model library provides popular LLMs implemented in Megatron, such as baichuan, bloom, chatglm, falcon, galactica, glm, llama, qwen, and starcoder. More Megatron-based implementations of LLMs will be added as needed in the future. Additionally, the patch provides bidirectional conversion between Huggingface and Megatron model weights. This allows users to easily utilize Huggingface pretrained models for continued pre-training or fine-tuning in Megatron, as well as evaluating model quality using Huggingface's evaluation/inference pipelines on trained Megatron models.
In the reinforcement learning section, the patch offers PPO training workflows, enabling users to perform reinforcement learning with SFT models and RM models. Finally, the patch provides numerous usage examples to help users quickly start LLMs training and offline inference. For specific usage processes within Alibaba Cloud Lingjun products, please refer to the following link: PAI-Lingjun Intelligent Computing Service LLM solution.

- 基于 Megatron 的多模态大模型训练加速技术解析
- Pai-Megatron-Patch:围绕Megatron-Core打造大模型训练加速生态
- Meta Llama3.1模型在PAI-Megatron-Patch的最佳实践
- 基于Megatron-Core的稀疏大模型训练工具:阿里云MoE大模型最佳实践
- Mixtral-8x7B在PAI灵骏的训练指南
- 通义千问开源模型在PAI灵骏的最佳实践
- 阿里云机器学习PAI开源AI大模型训练工具Pai-Megatron-Patch, 助力大模型技术落地
- 基于单机最高能效270亿参数GPT模型的文本生成与理解
- 中文稀疏GPT大模型落地 — 通往低成本&高性能多任务通用自然语言理解的关键里程碑
- 预训练知识度量比赛夺冠!阿里云PAI发布知识预训练工具
- 阿里云PAI获得FewCLUE基于大模型的小样本学习双料冠军
Use Dingtalk to scan blow QR code.
Note: group 1 is full, please add group 2.


This project is licensed under the Apache License (Version 2.0). This toolkit also contains some code modified from other repos under other open-source licenses. See the NOTICE file for more information.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for Pai-Megatron-Patch
Similar Open Source Tools
Pai-Megatron-Patch
Pai-Megatron-Patch is a deep learning training toolkit built for developers to train and predict LLMs & VLMs by using Megatron framework easily. With the continuous development of LLMs, the model structure and scale are rapidly evolving. Although these models can be conveniently manufactured using Transformers or DeepSpeed training framework, the training efficiency is comparably low. This phenomenon becomes even severer when the model scale exceeds 10 billion. The primary objective of Pai-Megatron-Patch is to effectively utilize the computational power of GPUs for LLM. This tool allows convenient training of commonly used LLM with all the accelerating techniques provided by Megatron-LM.

MiniCPM-V
MiniCPM-V is a series of end-side multimodal LLMs designed for vision-language understanding. The models take image and text inputs to provide high-quality text outputs. The series includes models like MiniCPM-Llama3-V 2.5 with 8B parameters surpassing proprietary models, and MiniCPM-V 2.0, a lighter model with 2B parameters. The models support over 30 languages, efficient deployment on end-side devices, and have strong OCR capabilities. They achieve state-of-the-art performance on various benchmarks and prevent hallucinations in text generation. The models can process high-resolution images efficiently and support multilingual capabilities.
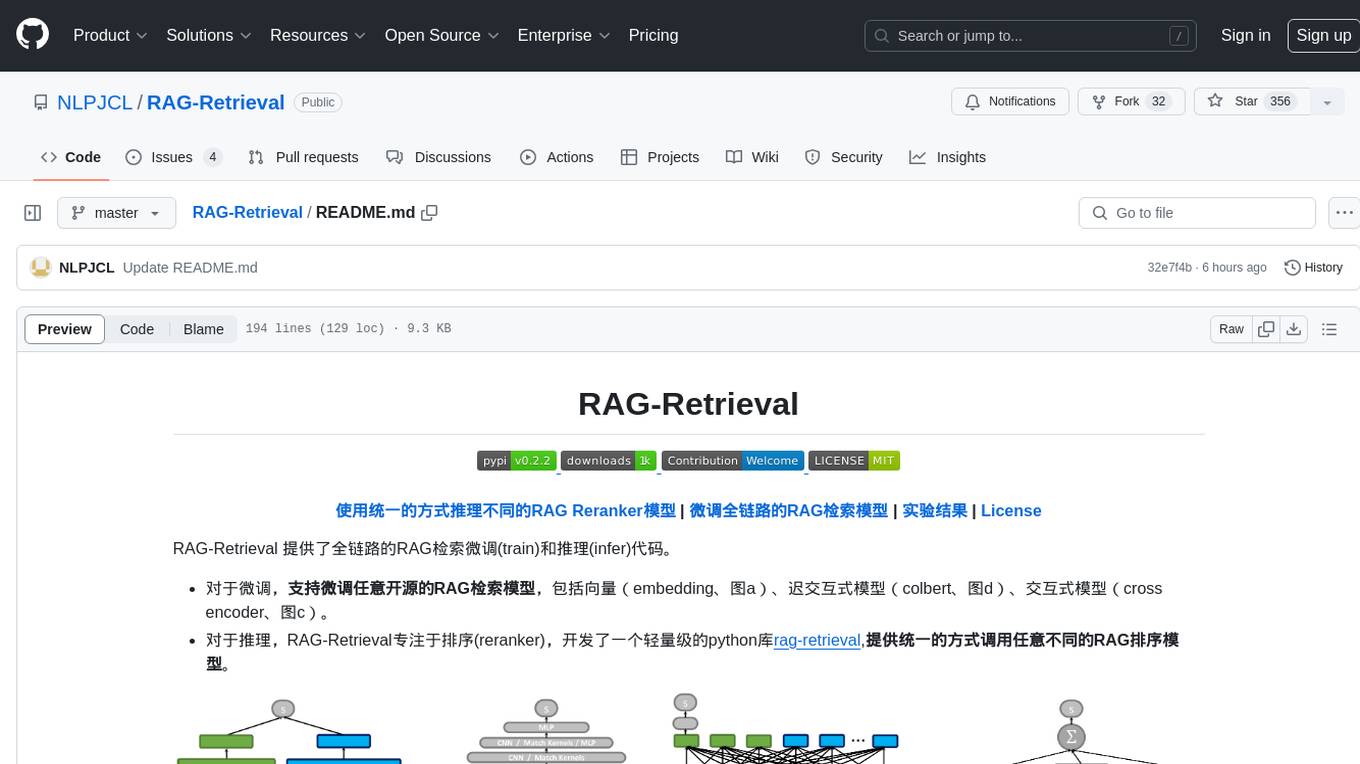
RAG-Retrieval
RAG-Retrieval provides full-chain RAG retrieval fine-tuning and inference code. It supports fine-tuning any open-source RAG retrieval models, including vector (embedding, graph a), delayed interactive models (ColBERT, graph d), interactive models (cross encoder, graph c). For inference, RAG-Retrieval focuses on ranking (reranker) and has developed a lightweight Python library rag-retrieval, providing a unified way to call any different RAG ranking models.
RLinf
RLinf is a flexible and scalable open-source infrastructure designed for post-training foundation models via reinforcement learning. It provides a robust backbone for next-generation training, supporting open-ended learning, continuous generalization, and limitless possibilities in intelligence development. The tool offers unique features like Macro-to-Micro Flow, flexible execution modes, auto-scheduling strategy, embodied agent support, and fast adaptation for mainstream VLA models. RLinf is fast with hybrid mode and automatic online scaling strategy, achieving significant throughput improvement and efficiency. It is also flexible and easy to use with multiple backend integrations, adaptive communication, and built-in support for popular RL methods. The roadmap includes system-level enhancements and application-level extensions to support various training scenarios and models. Users can get started with complete documentation, quickstart guides, key design principles, example gallery, advanced features, and guidelines for extending the framework. Contributions are welcome, and users are encouraged to cite the GitHub repository and acknowledge the broader open-source community.
Awesome-Attention-Heads
Awesome-Attention-Heads is a platform providing the latest research on Attention Heads, focusing on enhancing understanding of Transformer structure for model interpretability. It explores attention mechanisms for behavior, inference, and analysis, alongside feed-forward networks for knowledge storage. The repository aims to support researchers studying LLM interpretability and hallucination by offering cutting-edge information on Attention Head Mining.
rai
RAI is a framework designed to bring general multi-agent system capabilities to robots, enhancing human interactivity, flexibility in problem-solving, and out-of-the-box AI features. It supports multi-modalities, incorporates an advanced database for agent memory, provides ROS 2-oriented tooling, and offers a comprehensive task/mission orchestrator. The framework includes features such as voice interaction, customizable robot identity, camera sensor access, reasoning through ROS logs, and integration with LangChain for AI tools. RAI aims to support various AI vendors, improve human-robot interaction, provide an SDK for developers, and offer a user interface for configuration.

sealos
Sealos is a cloud operating system distribution based on the Kubernetes kernel, designed for a seamless development lifecycle. It allows users to spin up full-stack environments in seconds, effortlessly push releases, and scale production seamlessly. With core features like easy application management, quick database creation, and cloud universality, Sealos offers efficient and economical cloud management with high universality and ease of use. The platform also emphasizes agility and security through its multi-tenancy sharing model. Sealos is supported by a community offering full documentation, Discord support, and active development roadmap.

inference
Xorbits Inference (Xinference) is a powerful and versatile library designed to serve language, speech recognition, and multimodal models. With Xorbits Inference, you can effortlessly deploy and serve your or state-of-the-art built-in models using just a single command. Whether you are a researcher, developer, or data scientist, Xorbits Inference empowers you to unleash the full potential of cutting-edge AI models.
fAIr
fAIr is an open AI-assisted mapping service developed by the Humanitarian OpenStreetMap Team (HOT) to improve mapping efficiency and accuracy for humanitarian purposes. It uses AI models, specifically computer vision techniques, to detect objects like buildings, roads, waterways, and trees from satellite and UAV imagery. The service allows OSM community members to create and train their own AI models for mapping in their region of interest and ensures models are relevant to local communities. Constant feedback loop with local communities helps eliminate model biases and improve model accuracy.
awesome-weather-models
A catalogue and categorization of AI-based weather forecasting models. This page provides a catalogue and categorization of AI-based weather forecasting models to enable discovery and comparison of different available model options. The weather models are categorized based on metadata found in the JSON schema specification. The table includes information such as the name of the weather model, the organization that developed it, operational data availability, open-source status, and links for further details.

beeai-framework
BeeAI Framework is a versatile tool for building production-ready multi-agent systems. It offers flexibility in orchestrating agents, seamless integration with various models and tools, and production-grade controls for scaling. The framework supports Python and TypeScript libraries, enabling users to implement simple to complex multi-agent patterns, connect with AI services, and optimize token usage and resource management.

FlagEmbedding
FlagEmbedding focuses on retrieval-augmented LLMs, consisting of the following projects currently: * **Long-Context LLM** : Activation Beacon * **Fine-tuning of LM** : LM-Cocktail * **Embedding Model** : Visualized-BGE, BGE-M3, LLM Embedder, BGE Embedding * **Reranker Model** : llm rerankers, BGE Reranker * **Benchmark** : C-MTEB
agents-towards-production
Agents Towards Production is an open-source playbook for building production-ready GenAI agents that scale from prototype to enterprise. Tutorials cover stateful workflows, vector memory, real-time web search APIs, Docker deployment, FastAPI endpoints, security guardrails, GPU scaling, browser automation, fine-tuning, multi-agent coordination, observability, evaluation, and UI development.

InternLM-XComposer
InternLM-XComposer2 is a groundbreaking vision-language large model (VLLM) based on InternLM2-7B excelling in free-form text-image composition and comprehension. It boasts several amazing capabilities and applications: * **Free-form Interleaved Text-Image Composition** : InternLM-XComposer2 can effortlessly generate coherent and contextual articles with interleaved images following diverse inputs like outlines, detailed text requirements and reference images, enabling highly customizable content creation. * **Accurate Vision-language Problem-solving** : InternLM-XComposer2 accurately handles diverse and challenging vision-language Q&A tasks based on free-form instructions, excelling in recognition, perception, detailed captioning, visual reasoning, and more. * **Awesome performance** : InternLM-XComposer2 based on InternLM2-7B not only significantly outperforms existing open-source multimodal models in 13 benchmarks but also **matches or even surpasses GPT-4V and Gemini Pro in 6 benchmarks** We release InternLM-XComposer2 series in three versions: * **InternLM-XComposer2-4KHD-7B** 🤗: The high-resolution multi-task trained VLLM model with InternLM-7B as the initialization of the LLM for _High-resolution understanding_ , _VL benchmarks_ and _AI assistant_. * **InternLM-XComposer2-VL-7B** 🤗 : The multi-task trained VLLM model with InternLM-7B as the initialization of the LLM for _VL benchmarks_ and _AI assistant_. **It ranks as the most powerful vision-language model based on 7B-parameter level LLMs, leading across 13 benchmarks.** * **InternLM-XComposer2-VL-1.8B** 🤗 : A lightweight version of InternLM-XComposer2-VL based on InternLM-1.8B. * **InternLM-XComposer2-7B** 🤗: The further instruction tuned VLLM for _Interleaved Text-Image Composition_ with free-form inputs. Please refer to Technical Report and 4KHD Technical Reportfor more details.

Awesome-LLMs-on-device
Welcome to the ultimate hub for on-device Large Language Models (LLMs)! This repository is your go-to resource for all things related to LLMs designed for on-device deployment. Whether you're a seasoned researcher, an innovative developer, or an enthusiastic learner, this comprehensive collection of cutting-edge knowledge is your gateway to understanding, leveraging, and contributing to the exciting world of on-device LLMs.
chronos-forecasting
Chronos is a family of pretrained time series forecasting models based on language model architectures. A time series is transformed into a sequence of tokens via scaling and quantization, and a language model is trained on these tokens using the cross-entropy loss. Once trained, probabilistic forecasts are obtained by sampling multiple future trajectories given the historical context. Chronos models have been trained on a large corpus of publicly available time series data, as well as synthetic data generated using Gaussian processes.
For similar tasks

litgpt
LitGPT is a command-line tool designed to easily finetune, pretrain, evaluate, and deploy 20+ LLMs **on your own data**. It features highly-optimized training recipes for the world's most powerful open-source large-language-models (LLMs).

llm.c
LLM training in simple, pure C/CUDA. There is no need for 245MB of PyTorch or 107MB of cPython. For example, training GPT-2 (CPU, fp32) is ~1,000 lines of clean code in a single file. It compiles and runs instantly, and exactly matches the PyTorch reference implementation. I chose GPT-2 as the first working example because it is the grand-daddy of LLMs, the first time the modern stack was put together.

torchtune
Torchtune is a PyTorch-native library for easily authoring, fine-tuning, and experimenting with LLMs. It provides native-PyTorch implementations of popular LLMs using composable and modular building blocks, easy-to-use and hackable training recipes for popular fine-tuning techniques, YAML configs for easily configuring training, evaluation, quantization, or inference recipes, and built-in support for many popular dataset formats and prompt templates to help you quickly get started with training.
llm-engine
Scale's LLM Engine is an open-source Python library, CLI, and Helm chart that provides everything you need to serve and fine-tune foundation models, whether you use Scale's hosted infrastructure or do it in your own cloud infrastructure using Kubernetes.

LLaMA-Factory
LLaMA Factory is a unified framework for fine-tuning 100+ large language models (LLMs) with various methods, including pre-training, supervised fine-tuning, reward modeling, PPO, DPO and ORPO. It features integrated algorithms like GaLore, BAdam, DoRA, LongLoRA, LLaMA Pro, LoRA+, LoftQ and Agent tuning, as well as practical tricks like FlashAttention-2, Unsloth, RoPE scaling, NEFTune and rsLoRA. LLaMA Factory provides experiment monitors like LlamaBoard, TensorBoard, Wandb, MLflow, etc., and supports faster inference with OpenAI-style API, Gradio UI and CLI with vLLM worker. Compared to ChatGLM's P-Tuning, LLaMA Factory's LoRA tuning offers up to 3.7 times faster training speed with a better Rouge score on the advertising text generation task. By leveraging 4-bit quantization technique, LLaMA Factory's QLoRA further improves the efficiency regarding the GPU memory.
Pai-Megatron-Patch
Pai-Megatron-Patch is a deep learning training toolkit built for developers to train and predict LLMs & VLMs by using Megatron framework easily. With the continuous development of LLMs, the model structure and scale are rapidly evolving. Although these models can be conveniently manufactured using Transformers or DeepSpeed training framework, the training efficiency is comparably low. This phenomenon becomes even severer when the model scale exceeds 10 billion. The primary objective of Pai-Megatron-Patch is to effectively utilize the computational power of GPUs for LLM. This tool allows convenient training of commonly used LLM with all the accelerating techniques provided by Megatron-LM.

LLM-PowerHouse-A-Curated-Guide-for-Large-Language-Models-with-Custom-Training-and-Inferencing
LLM-PowerHouse is a comprehensive and curated guide designed to empower developers, researchers, and enthusiasts to harness the true capabilities of Large Language Models (LLMs) and build intelligent applications that push the boundaries of natural language understanding. This GitHub repository provides in-depth articles, codebase mastery, LLM PlayLab, and resources for cost analysis and network visualization. It covers various aspects of LLMs, including NLP, models, training, evaluation metrics, open LLMs, and more. The repository also includes a collection of code examples and tutorials to help users build and deploy LLM-based applications.

llm-foundry
LLM Foundry is a codebase for training, finetuning, evaluating, and deploying LLMs for inference with Composer and the MosaicML platform. It is designed to be easy-to-use, efficient _and_ flexible, enabling rapid experimentation with the latest techniques. You'll find in this repo: * `llmfoundry/` - source code for models, datasets, callbacks, utilities, etc. * `scripts/` - scripts to run LLM workloads * `data_prep/` - convert text data from original sources to StreamingDataset format * `train/` - train or finetune HuggingFace and MPT models from 125M - 70B parameters * `train/benchmarking` - profile training throughput and MFU * `inference/` - convert models to HuggingFace or ONNX format, and generate responses * `inference/benchmarking` - profile inference latency and throughput * `eval/` - evaluate LLMs on academic (or custom) in-context-learning tasks * `mcli/` - launch any of these workloads using MCLI and the MosaicML platform * `TUTORIAL.md` - a deeper dive into the repo, example workflows, and FAQs
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.