
RAG-Retrieval
Unify Efficient Fine-tuning of RAG Retrieval, including Embedding, ColBERT, ReRanker.
Stars: 655
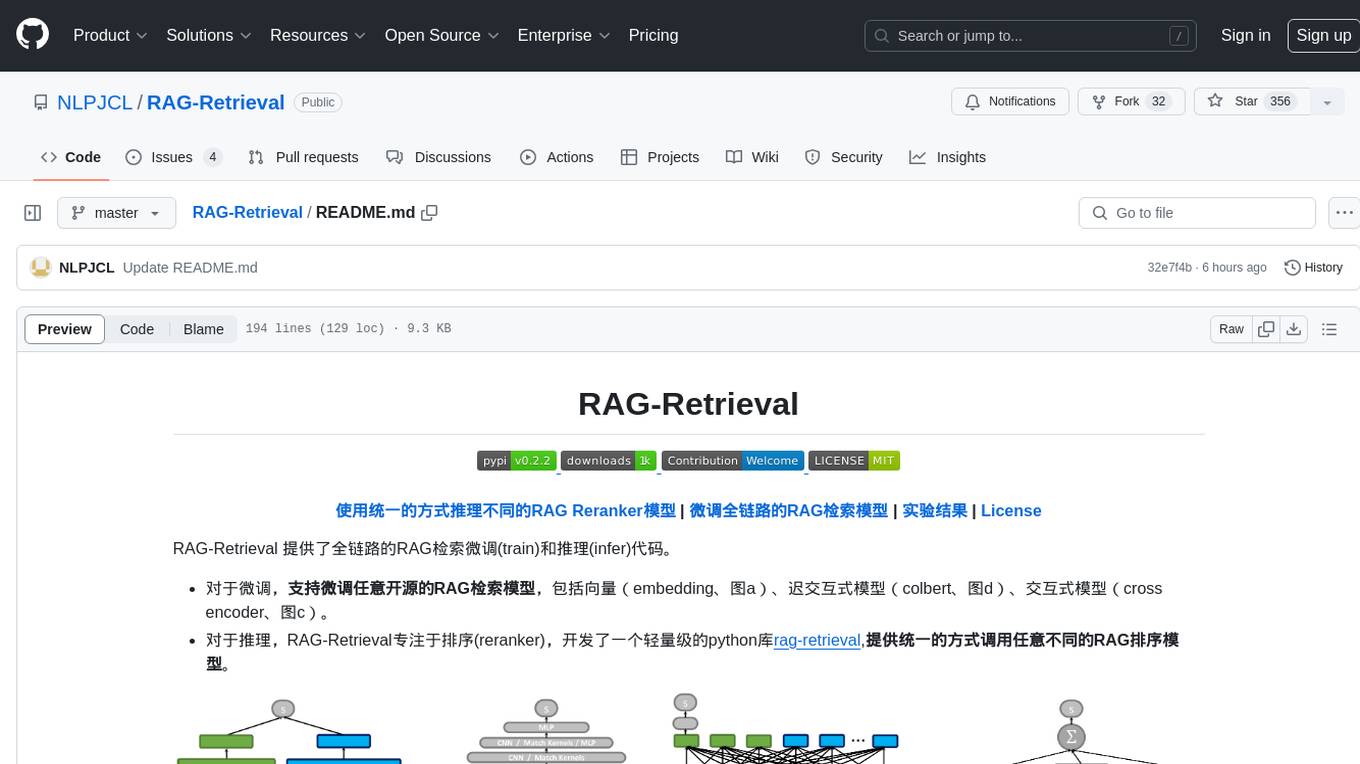
RAG-Retrieval provides full-chain RAG retrieval fine-tuning and inference code. It supports fine-tuning any open-source RAG retrieval models, including vector (embedding, graph a), delayed interactive models (ColBERT, graph d), interactive models (cross encoder, graph c). For inference, RAG-Retrieval focuses on ranking (reranker) and has developed a lightweight Python library rag-retrieval, providing a unified way to call any different RAG ranking models.
README:

The RAG-Retrieval offers end-to-end code for training, inference, and distillation of the RAG retrieval model.
- For training, RAG-Retrieval supports fine-tuning of any open-source RAG retrieval model, including embedding models (figure a,bert-based, llm-based), late interactive models (figure d,colbert), and reranker models (figure c,bert-based, llm-based).
- For inference, RAG-Retrieval focuses reranker and has developed a lightweight Python library rag-retrieval, which provides a unified way to call any different RAG ranking models.
- For distillation, it supports distilling LLM-based reranker models into bert-based reranker models.

-
12/29/2024: RAG-Retrieval released the core training code (stage3) of Stella and Jasper embedding model infgrad/jasper_en_vision_language_v1
-
10/21/2024: RAG-Retrieval released two different methods for Reranker tasks based on LLM, as well as a method for distilling them into BERT. Best Practices for LLM in Reranker Tasks? A Simple Experiment Report (with code)
-
6/5/2024: Implementation of MRL loss for the Embedding model in RAG-Retrieval. RAG-Retrieval: Making MRL Loss a Standard for Training Vector (Embedding) Models
-
6/2/2024: RAG-Retrieval implements LLM preference-based supervised fine-tuning of the RAG retriever. RAG-Retrieval Implements LLM Preference-Based Supervised Fine-Tuning of the RAG Retriever
-
5/5/2024: Released a lightweight Python library for RAG-Retrieval. RAG-Retrieval: Your RAG Application Deserves a Better Ranking Reasoning Framework
-
3/18/2024: Released RAG-Retrieval Introduction to RAG-Retrieval on Zhihu
- Supports end-to-end fine-tuning of RAG retrieval models: Embedding (bert-based, llm-based), late interaction models (colbert), and reranker models (bert-based, llm-based).
- Supports fine-tuning of any open-source RAG retrieval models: Compatible with most open-source embedding and reranker models, such as: bge (bge-embedding, bge-m3, bge-reranker), bce (bce-embedding, bce-reranker), gte (gte-embedding, gte-multilingual-reranker-base).
- Supports distillation of llm-based large models to bert-based smaller models: Currently supports the distillation of llm-based reranker models into bert-based reranker models (implementation of mean squared error and cross-entropy loss).
- Advanced Algorithms: For embedding models, supports the MRL algorithm to reduce the dimensionality of output vectors.
- Multi-gpu training strategy: Includes deepspeed, fsdp.
- Simple yet Elegant: Rejects complex, with a simple and understandable code structure for easy modifications.
For training (all):
conda create -n rag-retrieval python=3.8 && conda activate rag-retrieval
# To avoid incompatibility between the automatically installed torch and the local cuda, it is recommended to manually install the compatible version of torch before proceeding to the next step.
pip install -r requirements.txt For prediction (reranker):
# To avoid incompatibility between the automatically installed torch and the local cuda, it is recommended to manually install the compatible version of torch before proceeding to the next step.
pip install rag-retrievalFor different model types, please go into different subdirectories. For example: For embedding, and similarly for others. Detailed procedures can be found in the README file in each subdirectories.
cd ./rag_retrieval/train/embedding
bash train_embedding.shRAG-Retrieval has developed a lightweight Python library, rag-retrieval, which provides a unified interface for calling various RAG reranker models with the following features:
-
Supports multiple ranking models: Compatible with common open-source ranking models (Cross Encoder Reranker, Decoder-Only LLM Reranker).
-
Long document friendly: Supports two different handling logics for long documents (maximum length truncation and splitting to take the maximum score).
-
Easy to Extend: If there is a new ranking model, users only need to inherit from BaseReranker and implement the rank and compute_score functions.
For detailed usage and considerations of the rag-retrieval package, please refer to the Tutorial
| Model | Model Size(GB) | T2Reranking | MMarcoReranking | CMedQAv1 | CMedQAv2 | Avg |
|---|---|---|---|---|---|---|
| bge-reranker-base | 1.11 | 67.28 | 35.46 | 81.27 | 84.10 | 67.03 |
| bce-reranker-base_v1 | 1.11 | 70.25 | 34.13 | 79.64 | 81.31 | 66.33 |
| rag-retrieval-reranker | 0.41 | 67.33 | 31.57 | 83.54 | 86.03 | 67.12 |
Among them, rag-retrieval-reranker is the result of training on the hfl/chinese-roberta-wwm-ext model using the RAG-Retrieval code, and the training data uses the training data of the bge-rerank model.
| Model | Model Size(GB) | Dim | T2Reranking | MMarcoReranking | CMedQAv1 | CMedQAv2 | Avg |
|---|---|---|---|---|---|---|---|
| bge-m3-colbert | 2.24 | 1024 | 66.82 | 26.71 | 75.88 | 76.83 | 61.56 |
| rag-retrieval-colbert | 0.41 | 1024 | 66.85 | 31.46 | 81.05 | 84.22 | 65.90 |
Among them, rag-retrieval-colbert is the result of training on the hfl/chinese-roberta-wwm-ext model using the RAG-Retrieval code, and the training data uses the training data of the bge-rerank model.
| Model | T2ranking | |
|---|---|---|
| bge-v1.5-embedding | 66.49 | |
| bge-v1.5-embedding finetune | 67.15 | +0.66 |
| bge-m3-colbert | 66.82 | |
| bge-m3-colbert finetune | 67.22 | +0.40 |
| bge-reranker-base | 67.28 | |
| bge-reranker-base finetune | 67.57 | +0.29 |
The number with finetune at the end means that we used RAG-Retrieval to fine-tune the corresponding open source model, and the training data used the training set of T2-Reranking.
It is worth noting that the training set of the three open source models of bge already includes T2-Reranking, and the data is relatively general, so the performance improvement of fine-tuning using this data is not significant. However, if the open source model is fine-tuned using a vertical field data set, the performance improvement will be greater.
RAG-Retrieval is licensed under the MIT License.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for RAG-Retrieval
Similar Open Source Tools
RAG-Retrieval
RAG-Retrieval provides full-chain RAG retrieval fine-tuning and inference code. It supports fine-tuning any open-source RAG retrieval models, including vector (embedding, graph a), delayed interactive models (ColBERT, graph d), interactive models (cross encoder, graph c). For inference, RAG-Retrieval focuses on ranking (reranker) and has developed a lightweight Python library rag-retrieval, providing a unified way to call any different RAG ranking models.
RAG-Retrieval
RAG-Retrieval is an end-to-end code repository that provides training, inference, and distillation capabilities for the RAG retrieval model. It supports fine-tuning of various open-source RAG retrieval models, including embedding models, late interactive models, and reranker models. The repository offers a lightweight Python library for calling different RAG ranking models and allows distillation of LLM-based reranker models into bert-based reranker models. It includes features such as support for end-to-end fine-tuning, distillation of large models, advanced algorithms like MRL, multi-GPU training strategy, and a simple code structure for easy modifications.

UI-TARS-desktop
UI-TARS-desktop is a desktop application that provides a native GUI Agent based on the UI-TARS model. It offers features such as natural language control powered by Vision-Language Model, screenshot and visual recognition support, precise mouse and keyboard control, cross-platform support (Windows/MacOS/Browser), real-time feedback and status display, and private and secure fully local processing. The application aims to enhance the user's computer experience, introduce new browser operation features, and support the advanced UI-TARS-1.5 model for improved performance and precise control.

MiniCPM-V
MiniCPM-V is a series of end-side multimodal LLMs designed for vision-language understanding. The models take image and text inputs to provide high-quality text outputs. The series includes models like MiniCPM-Llama3-V 2.5 with 8B parameters surpassing proprietary models, and MiniCPM-V 2.0, a lighter model with 2B parameters. The models support over 30 languages, efficient deployment on end-side devices, and have strong OCR capabilities. They achieve state-of-the-art performance on various benchmarks and prevent hallucinations in text generation. The models can process high-resolution images efficiently and support multilingual capabilities.
buffer-of-thought-llm
Buffer of Thoughts (BoT) is a thought-augmented reasoning framework designed to enhance the accuracy, efficiency, and robustness of large language models (LLMs). It introduces a meta-buffer to store high-level thought-templates distilled from problem-solving processes, enabling adaptive reasoning for efficient problem-solving. The framework includes a buffer-manager to dynamically update the meta-buffer, ensuring scalability and stability. BoT achieves significant performance improvements on reasoning-intensive tasks and demonstrates superior generalization ability and robustness while being cost-effective compared to other methods.
big-AGI
big-AGI is an AI suite designed for professionals seeking function, form, simplicity, and speed. It offers best-in-class Chats, Beams, and Calls with AI personas, visualizations, coding, drawing, side-by-side chatting, and more, all wrapped in a polished UX. The tool is powered by the latest models from 12 vendors and open-source servers, providing users with advanced AI capabilities and a seamless user experience. With continuous updates and enhancements, big-AGI aims to stay ahead of the curve in the AI landscape, catering to the needs of both developers and AI enthusiasts.
RLinf
RLinf is a flexible and scalable open-source infrastructure designed for post-training foundation models via reinforcement learning. It provides a robust backbone for next-generation training, supporting open-ended learning, continuous generalization, and limitless possibilities in intelligence development. The tool offers unique features like Macro-to-Micro Flow, flexible execution modes, auto-scheduling strategy, embodied agent support, and fast adaptation for mainstream VLA models. RLinf is fast with hybrid mode and automatic online scaling strategy, achieving significant throughput improvement and efficiency. It is also flexible and easy to use with multiple backend integrations, adaptive communication, and built-in support for popular RL methods. The roadmap includes system-level enhancements and application-level extensions to support various training scenarios and models. Users can get started with complete documentation, quickstart guides, key design principles, example gallery, advanced features, and guidelines for extending the framework. Contributions are welcome, and users are encouraged to cite the GitHub repository and acknowledge the broader open-source community.

FlagEmbedding
FlagEmbedding focuses on retrieval-augmented LLMs, consisting of the following projects currently: * **Long-Context LLM** : Activation Beacon * **Fine-tuning of LM** : LM-Cocktail * **Embedding Model** : Visualized-BGE, BGE-M3, LLM Embedder, BGE Embedding * **Reranker Model** : llm rerankers, BGE Reranker * **Benchmark** : C-MTEB

inference
Xorbits Inference (Xinference) is a powerful and versatile library designed to serve language, speech recognition, and multimodal models. With Xorbits Inference, you can effortlessly deploy and serve your or state-of-the-art built-in models using just a single command. Whether you are a researcher, developer, or data scientist, Xorbits Inference empowers you to unleash the full potential of cutting-edge AI models.
fastRAG
fastRAG is a research framework designed to build and explore efficient retrieval-augmented generative models. It incorporates state-of-the-art Large Language Models (LLMs) and Information Retrieval to empower researchers and developers with a comprehensive tool-set for advancing retrieval augmented generation. The framework is optimized for Intel hardware, customizable, and includes key features such as optimized RAG pipelines, efficient components, and RAG-efficient components like ColBERT and Fusion-in-Decoder (FiD). fastRAG supports various unique components and backends for running LLMs, making it a versatile tool for research and development in the field of retrieval-augmented generation.
Pai-Megatron-Patch
Pai-Megatron-Patch is a deep learning training toolkit built for developers to train and predict LLMs & VLMs by using Megatron framework easily. With the continuous development of LLMs, the model structure and scale are rapidly evolving. Although these models can be conveniently manufactured using Transformers or DeepSpeed training framework, the training efficiency is comparably low. This phenomenon becomes even severer when the model scale exceeds 10 billion. The primary objective of Pai-Megatron-Patch is to effectively utilize the computational power of GPUs for LLM. This tool allows convenient training of commonly used LLM with all the accelerating techniques provided by Megatron-LM.
Streamline-Analyst
Streamline Analyst is a cutting-edge, open-source application powered by Large Language Models (LLMs) designed to revolutionize data analysis. This Data Analysis Agent effortlessly automates tasks such as data cleaning, preprocessing, and complex operations like identifying target objects, partitioning test sets, and selecting the best-fit models based on your data. With Streamline Analyst, results visualization and evaluation become seamless. It aims to expedite the data analysis process, making it accessible to all, regardless of their expertise in data analysis. The tool is built to empower users to process data and achieve high-quality visualizations with unparalleled efficiency, and to execute high-performance modeling with the best strategies. Future enhancements include Natural Language Processing (NLP), neural networks, and object detection utilizing YOLO, broadening its capabilities to meet diverse data analysis needs.
LLM4Decompile
LLM4Decompile is an open-source large language model dedicated to decompilation of Linux x86_64 binaries, supporting GCC's O0 to O3 optimization levels. It focuses on assessing re-executability of decompiled code through HumanEval-Decompile benchmark. The tool includes models with sizes ranging from 1.3 billion to 33 billion parameters, available on Hugging Face. Users can preprocess C code into binary and assembly instructions, then decompile assembly instructions into C using LLM4Decompile. Ongoing efforts aim to expand capabilities to support more architectures and configurations, integrate with decompilation tools like Ghidra and Rizin, and enhance performance with larger training datasets.
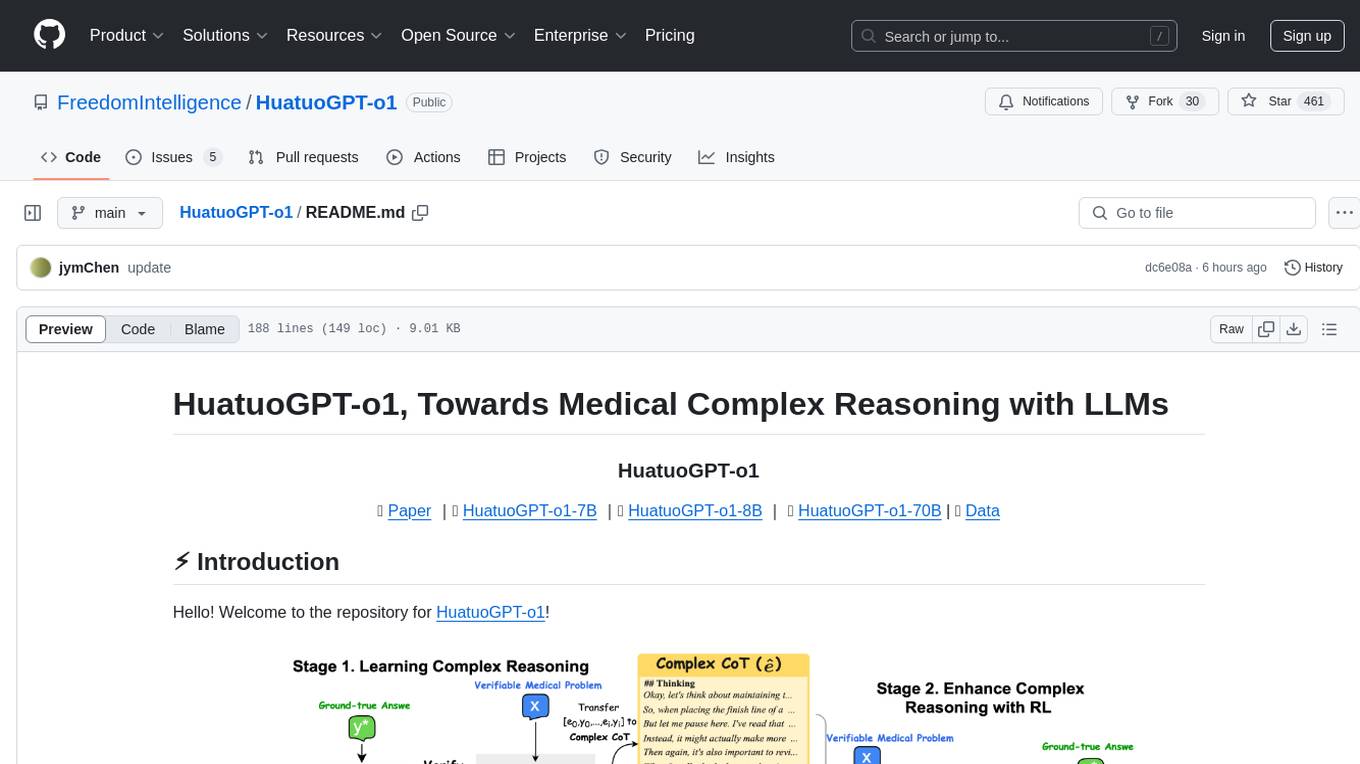
HuatuoGPT-o1
HuatuoGPT-o1 is a medical language model designed for advanced medical reasoning. It can identify mistakes, explore alternative strategies, and refine answers. The model leverages verifiable medical problems and a specialized medical verifier to guide complex reasoning trajectories and enhance reasoning through reinforcement learning. The repository provides access to models, data, and code for HuatuoGPT-o1, allowing users to deploy the model for medical reasoning tasks.
SciCode
SciCode is a challenging benchmark designed to evaluate the capabilities of language models (LMs) in generating code for solving realistic scientific research problems. It contains 338 subproblems decomposed from 80 challenging main problems across 16 subdomains from 6 domains. The benchmark offers optional descriptions specifying useful scientific background information and scientist-annotated gold-standard solutions and test cases for evaluation. SciCode demonstrates a realistic workflow of identifying critical science concepts and facts and transforming them into computation and simulation code, aiming to help showcase LLMs' progress towards assisting scientists and contribute to the future building and evaluation of scientific AI.

X-AnyLabeling
X-AnyLabeling is a robust annotation tool that seamlessly incorporates an AI inference engine alongside an array of sophisticated features. Tailored for practical applications, it is committed to delivering comprehensive, industrial-grade solutions for image data engineers. This tool excels in swiftly and automatically executing annotations across diverse and intricate tasks.
For similar tasks

Co-LLM-Agents
This repository contains code for building cooperative embodied agents modularly with large language models. The agents are trained to perform tasks in two different environments: ThreeDWorld Multi-Agent Transport (TDW-MAT) and Communicative Watch-And-Help (C-WAH). TDW-MAT is a multi-agent environment where agents must transport objects to a goal position using containers. C-WAH is an extension of the Watch-And-Help challenge, which enables agents to send messages to each other. The code in this repository can be used to train agents to perform tasks in both of these environments.

GPT4Point
GPT4Point is a unified framework for point-language understanding and generation. It aligns 3D point clouds with language, providing a comprehensive solution for tasks such as 3D captioning and controlled 3D generation. The project includes an automated point-language dataset annotation engine, a novel object-level point cloud benchmark, and a 3D multi-modality model. Users can train and evaluate models using the provided code and datasets, with a focus on improving models' understanding capabilities and facilitating the generation of 3D objects.

asreview
The ASReview project implements active learning for systematic reviews, utilizing AI-aided pipelines to assist in finding relevant texts for search tasks. It accelerates the screening of textual data with minimal human input, saving time and increasing output quality. The software offers three modes: Oracle for interactive screening, Exploration for teaching purposes, and Simulation for evaluating active learning models. ASReview LAB is designed to support decision-making in any discipline or industry by improving efficiency and transparency in screening large amounts of textual data.

Groma
Groma is a grounded multimodal assistant that excels in region understanding and visual grounding. It can process user-defined region inputs and generate contextually grounded long-form responses. The tool presents a unique paradigm for multimodal large language models, focusing on visual tokenization for localization. Groma achieves state-of-the-art performance in referring expression comprehension benchmarks. The tool provides pretrained model weights and instructions for data preparation, training, inference, and evaluation. Users can customize training by starting from intermediate checkpoints. Groma is designed to handle tasks related to detection pretraining, alignment pretraining, instruction finetuning, instruction following, and more.

amber-train
Amber is the first model in the LLM360 family, an initiative for comprehensive and fully open-sourced LLMs. It is a 7B English language model with the LLaMA architecture. The model type is a language model with the same architecture as LLaMA-7B. It is licensed under Apache 2.0. The resources available include training code, data preparation, metrics, and fully processed Amber pretraining data. The model has been trained on various datasets like Arxiv, Book, C4, Refined-Web, StarCoder, StackExchange, and Wikipedia. The hyperparameters include a total of 6.7B parameters, hidden size of 4096, intermediate size of 11008, 32 attention heads, 32 hidden layers, RMSNorm ε of 1e^-6, max sequence length of 2048, and a vocabulary size of 32000.

kan-gpt
The KAN-GPT repository is a PyTorch implementation of Generative Pre-trained Transformers (GPTs) using Kolmogorov-Arnold Networks (KANs) for language modeling. It provides a model for generating text based on prompts, with a focus on improving performance compared to traditional MLP-GPT models. The repository includes scripts for training the model, downloading datasets, and evaluating model performance. Development tasks include integrating with other libraries, testing, and documentation.

LLM-SFT
LLM-SFT is a Chinese large model fine-tuning tool that supports models such as ChatGLM, LlaMA, Bloom, Baichuan-7B, and frameworks like LoRA, QLoRA, DeepSpeed, UI, and TensorboardX. It facilitates tasks like fine-tuning, inference, evaluation, and API integration. The tool provides pre-trained weights for various models and datasets for Chinese language processing. It requires specific versions of libraries like transformers and torch for different functionalities.

zshot
Zshot is a highly customizable framework for performing Zero and Few shot named entity and relationships recognition. It can be used for mentions extraction, wikification, zero and few shot named entity recognition, zero and few shot named relationship recognition, and visualization of zero-shot NER and RE extraction. The framework consists of two main components: the mentions extractor and the linker. There are multiple mentions extractors and linkers available, each serving a specific purpose. Zshot also includes a relations extractor and a knowledge extractor for extracting relations among entities and performing entity classification. The tool requires Python 3.6+ and dependencies like spacy, torch, transformers, evaluate, and datasets for evaluation over datasets like OntoNotes. Optional dependencies include flair and blink for additional functionalities. Zshot provides examples, tutorials, and evaluation methods to assess the performance of the components.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.