
fastRAG
Efficient Retrieval Augmentation and Generation Framework
Stars: 1254
fastRAG is a research framework designed to build and explore efficient retrieval-augmented generative models. It incorporates state-of-the-art Large Language Models (LLMs) and Information Retrieval to empower researchers and developers with a comprehensive tool-set for advancing retrieval augmented generation. The framework is optimized for Intel hardware, customizable, and includes key features such as optimized RAG pipelines, efficient components, and RAG-efficient components like ColBERT and Fusion-in-Decoder (FiD). fastRAG supports various unique components and backends for running LLMs, making it a versatile tool for research and development in the field of retrieval-augmented generation.
README:

Build and explore efficient retrieval-augmented generative models and applications


📍 Installation • 🚀 Components • 📚 Examples • 🚗 Getting Started • 💊 Demos • ✏️ Scripts • 📊 Benchmarks
fastRAG is a research framework for efficient and optimized retrieval augmented generative pipelines, incorporating state-of-the-art LLMs and Information Retrieval. fastRAG is designed to empower researchers and developers with a comprehensive tool-set for advancing retrieval augmented generation.
Comments, suggestions, issues and pull-requests are welcomed! ❤️
[!IMPORTANT] Now compatible with Haystack v2+. Please report any possible issues you find.
- 2024-05: fastRAG V3 is Haystack 2.0 compatible 🔥
- 2023-12: Gaudi2 and ONNX runtime support; Optimized Embedding models; Multi-modality and Chat demos; REPLUG text generation.
- 2023-06: ColBERT index modification: adding/removing documents; see IndexUpdater.
- 2023-05: RAG with LLM and dynamic prompt synthesis example.
-
2023-04: Qdrant
DocumentStoresupport.
- Optimized RAG: Build RAG pipelines with SOTA efficient components for greater compute efficiency.
- Optimized for Intel Hardware: Leverage Intel extensions for PyTorch (IPEX), 🤗 Optimum Intel and 🤗 Optimum-Habana for running as optimal as possible on Intel® Xeon® Processors and Intel® Gaudi® AI accelerators.
- Customizable: fastRAG is built using Haystack and HuggingFace. All of fastRAG's components are 100% Haystack compatible.
For a brief overview of the various unique components in fastRAG refer to the Components Overview page.
| LLM Backends | |
| Intel Gaudi Accelerators | Running LLMs on Gaudi 2 |
| ONNX Runtime | Running LLMs with optimized ONNX-runtime |
| OpenVINO | Running quantized LLMs using OpenVINO |
| Llama-CPP | Running RAG Pipelines with LLMs on a Llama CPP backend |
| Optimized Components | |
| Embedders | Optimized int8 bi-encoders |
| Rankers | Optimized/sparse cross-encoders |
| RAG-efficient Components | |
| ColBERT | Token-based late interaction |
| Fusion-in-Decoder (FiD) | Generative multi-document encoder-decoder |
| REPLUG | Improved multi-document decoder |
| PLAID | Incredibly efficient indexing engine |
Preliminary requirements:
- Python 3.8 or higher.
- PyTorch 2.0 or higher.
To set up the software, install from pip or clone the project for the bleeding-edge updates. Run the following, preferably in a newly created virtual environment:
pip install fastragThere are additional dependencies that you can install based on your specific usage of fastRAG:
# Additional engines/components
pip install fastrag[intel] # Intel optimized backend [Optimum-intel, IPEX]
pip install fastrag[openvino] # Intel optimized backend using OpenVINO
pip install fastrag[elastic] # Support for ElasticSearch store
pip install fastrag[qdrant] # Support for Qdrant store
pip install fastrag[colbert] # Support for ColBERT+PLAID; requires FAISS
pip install fastrag[faiss-cpu] # CPU-based Faiss library
pip install fastrag[faiss-gpu] # GPU-based Faiss libraryTo work with the latest version of fastRAG, you can install it using the following command:
pip install .pip install .[dev]The code is licensed under the Apache 2.0 License.
This is not an official Intel product.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for fastRAG
Similar Open Source Tools
fastRAG
fastRAG is a research framework designed to build and explore efficient retrieval-augmented generative models. It incorporates state-of-the-art Large Language Models (LLMs) and Information Retrieval to empower researchers and developers with a comprehensive tool-set for advancing retrieval augmented generation. The framework is optimized for Intel hardware, customizable, and includes key features such as optimized RAG pipelines, efficient components, and RAG-efficient components like ColBERT and Fusion-in-Decoder (FiD). fastRAG supports various unique components and backends for running LLMs, making it a versatile tool for research and development in the field of retrieval-augmented generation.
aibrix
AIBrix is an open-source initiative providing essential building blocks for scalable GenAI inference infrastructure. It delivers a cloud-native solution optimized for deploying, managing, and scaling large language model (LLM) inference, tailored to enterprise needs. Key features include High-Density LoRA Management, LLM Gateway and Routing, LLM App-Tailored Autoscaler, Unified AI Runtime, Distributed Inference, Distributed KV Cache, Cost-efficient Heterogeneous Serving, and GPU Hardware Failure Detection.

ApeRAG
ApeRAG is a production-ready platform for Retrieval-Augmented Generation (RAG) that combines Graph RAG, vector search, and full-text search with advanced AI agents. It is ideal for building Knowledge Graphs, Context Engineering, and deploying intelligent AI agents for autonomous search and reasoning across knowledge bases. The platform offers features like advanced index types, intelligent AI agents with MCP support, enhanced Graph RAG with entity normalization, multimodal processing, hybrid retrieval engine, MinerU integration for document parsing, production-grade deployment with Kubernetes, enterprise management features, MCP integration, and developer-friendly tools for customization and contribution.
vearch
Vearch is a cloud-native distributed vector database designed for efficient similarity search of embedding vectors in AI applications. It supports hybrid search with vector search and scalar filtering, offers fast vector retrieval from millions of objects in milliseconds, and ensures scalability and reliability through replication and elastic scaling out. Users can deploy Vearch cluster on Kubernetes, add charts from the repository or locally, start with Docker-compose, or compile from source code. The tool includes components like Master for schema management, Router for RESTful API, and PartitionServer for hosting document partitions with raft-based replication. Vearch can be used for building visual search systems for indexing images and offers a Python SDK for easy installation and usage. The tool is suitable for AI developers and researchers looking for efficient vector search capabilities in their applications.

instill-core
Instill Core is an open-source orchestrator comprising a collection of source-available projects designed to streamline every aspect of building versatile AI features with unstructured data. It includes Instill VDP (Versatile Data Pipeline) for unstructured data, AI, and pipeline orchestration, Instill Model for scalable MLOps and LLMOps for open-source or custom AI models, and Instill Artifact for unified unstructured data management. Instill Core can be used for tasks such as building, testing, and sharing pipelines, importing, serving, fine-tuning, and monitoring ML models, and transforming documents, images, audio, and video into a unified AI-ready format.

llmaz
llmaz is an easy, advanced inference platform for large language models on Kubernetes. It aims to provide a production-ready solution that integrates with state-of-the-art inference backends. The platform supports efficient model distribution, accelerator fungibility, SOTA inference, various model providers, multi-host support, and scaling efficiency. Users can quickly deploy LLM services with minimal configurations and benefit from a wide range of advanced inference backends. llmaz is designed to optimize cost and performance while supporting cutting-edge researches like Speculative Decoding or Splitwise on Kubernetes.
midscene
Midscene.js is an AI-powered automation SDK that allows users to control web pages, perform assertions, and extract data in JSON format using natural language. It offers features such as natural language interaction, understanding UI and providing responses in JSON, intuitive assertion based on AI understanding, compatibility with public multimodal LLMs like GPT-4o, visualization tool for easy debugging, and a brand new experience in automation development.

WeKnora
WeKnora is a document understanding and semantic retrieval framework based on large language models (LLM), designed specifically for scenarios with complex structures and heterogeneous content. The framework adopts a modular architecture, integrating multimodal preprocessing, semantic vector indexing, intelligent recall, and large model generation reasoning to build an efficient and controllable document question-answering process. The core retrieval process is based on the RAG (Retrieval-Augmented Generation) mechanism, combining context-relevant segments with language models to achieve higher-quality semantic answers. It supports various document formats, intelligent inference, flexible extension, efficient retrieval, ease of use, and security and control. Suitable for enterprise knowledge management, scientific literature analysis, product technical support, legal compliance review, and medical knowledge assistance.

starwhale
Starwhale is an MLOps/LLMOps platform that brings efficiency and standardization to machine learning operations. It streamlines the model development lifecycle, enabling teams to optimize workflows around key areas like model building, evaluation, release, and fine-tuning. Starwhale abstracts Model, Runtime, and Dataset as first-class citizens, providing tailored capabilities for common workflow scenarios including Models Evaluation, Live Demo, and LLM Fine-tuning. It is an open-source platform designed for clarity and ease of use, empowering developers to build customized MLOps features tailored to their needs.
wanwu
Wanwu AI Agent Platform is an enterprise-grade one-stop commercially friendly AI agent development platform designed for business scenarios. It provides enterprises with a safe, efficient, and compliant one-stop AI solution. The platform integrates cutting-edge technologies such as large language models and business process automation to build an AI engineering platform covering model full life-cycle management, MCP, web search, AI agent rapid development, enterprise knowledge base construction, and complex workflow orchestration. It supports modular architecture design, flexible functional expansion, and secondary development, reducing the application threshold of AI technology while ensuring security and privacy protection of enterprise data. It accelerates digital transformation, cost reduction, efficiency improvement, and business innovation for enterprises of all sizes.
ai-optimizer
The Oracle AI Optimizer and Toolkit provides a streamlined environment for developers and data scientists to explore Generative Artificial Intelligence (GenAI) and Retrieval-Augmented Generation (RAG) capabilities. It integrates Oracle Database 23ai AI VectorSearch and SelectAI to enhance Large Language Models (LLMs) through RAG.
graphbit
GraphBit is an industry-grade agentic AI framework built for developers and AI teams that demand stability, scalability, and low resource usage. It is written in Rust for maximum performance and safety, delivering significantly lower CPU usage and memory footprint compared to leading alternatives. The framework is designed to run multi-agent workflows in parallel, persist memory across steps, recover from failures, and ensure 100% task success under load. With lightweight architecture, observability, and concurrency support, GraphBit is suitable for deployment in high-scale enterprise environments and low-resource edge scenarios.
Code-Atlas
Code Atlas is a lightweight interpreter developed in C++ that supports the execution of multi-language code snippets and partial Markdown rendering. It consumes significantly lower resources compared to similar tools, making it suitable for resource-limited devices. It leverages llama.cpp for local large-model inference and supports cloud-based large-model APIs. The tool provides features for code execution, Markdown rendering, local AI inference, and resource efficiency.

aigne-framework
AIGNE Framework is a functional AI application development framework designed to simplify and accelerate the process of building modern applications. It combines functional programming features, powerful artificial intelligence capabilities, and modular design principles to help developers easily create scalable solutions. With key features like modular design, TypeScript support, multiple AI model support, flexible workflow patterns, MCP protocol integration, code execution capabilities, and Blocklet ecosystem integration, AIGNE Framework offers a comprehensive solution for developers. The framework provides various workflow patterns such as Workflow Router, Workflow Sequential, Workflow Concurrency, Workflow Handoff, Workflow Reflection, Workflow Orchestration, Workflow Code Execution, and Workflow Group Chat to address different application scenarios efficiently. It also includes built-in MCP support for running MCP servers and integrating with external MCP servers, along with packages for core functionality, agent library, CLI, and various models like OpenAI, Gemini, Claude, and Nova.
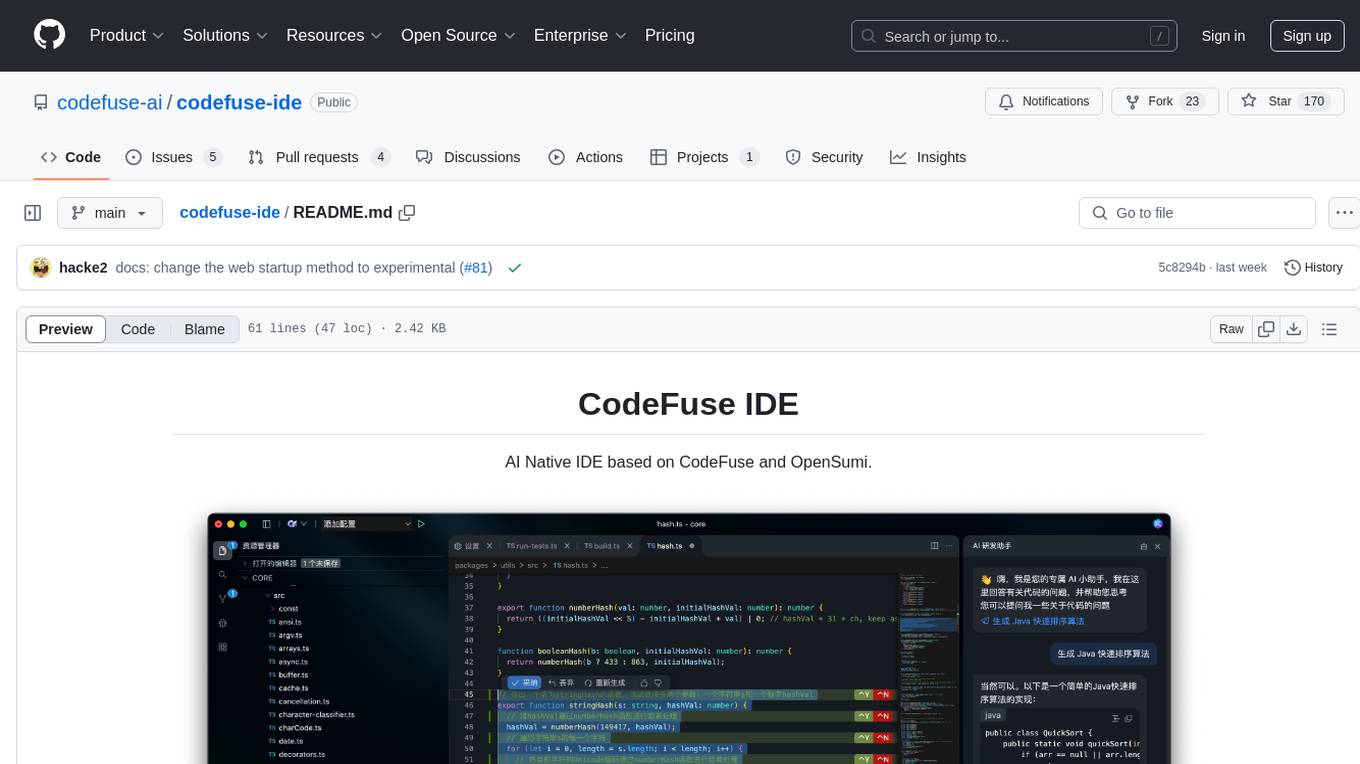
codefuse-ide
CodeFuse IDE is an AI-native integrated development environment that leverages AI technologies to enhance productivity and streamline workflows. It supports seamless integration of various models, enabling developers to customize and extend functionality. The platform is compatible with VS Code extensions, providing access to a rich ecosystem of plugins. CodeFuse IDE uses electron-forge for packaging desktop applications and supports development, building, packaging, and auto updates.
Ivy-Framework
Ivy-Framework is a powerful tool for building internal applications with AI assistance using C# codebase. It provides a CLI for project initialization, authentication integrations, database support, LLM code generation, secrets management, container deployment, hot reload, dependency injection, state management, routing, and external widget framework. Users can easily create data tables for sorting, filtering, and pagination. The framework offers a seamless integration of front-end and back-end development, making it ideal for developing robust internal tools and dashboards.
For similar tasks
instill-core
Instill Core is an open-source orchestrator comprising a collection of source-available projects designed to streamline every aspect of building versatile AI features with unstructured data. It includes Instill VDP (Versatile Data Pipeline) for unstructured data, AI, and pipeline orchestration, Instill Model for scalable MLOps and LLMOps for open-source or custom AI models, and Instill Artifact for unified unstructured data management. Instill Core can be used for tasks such as building, testing, and sharing pipelines, importing, serving, fine-tuning, and monitoring ML models, and transforming documents, images, audio, and video into a unified AI-ready format.
fastRAG
fastRAG is a research framework designed to build and explore efficient retrieval-augmented generative models. It incorporates state-of-the-art Large Language Models (LLMs) and Information Retrieval to empower researchers and developers with a comprehensive tool-set for advancing retrieval augmented generation. The framework is optimized for Intel hardware, customizable, and includes key features such as optimized RAG pipelines, efficient components, and RAG-efficient components like ColBERT and Fusion-in-Decoder (FiD). fastRAG supports various unique components and backends for running LLMs, making it a versatile tool for research and development in the field of retrieval-augmented generation.
ai-on-openshift
AI on OpenShift is a site providing installation recipes, patterns, and demos for AI/ML tools and applications used in Data Science and Data Engineering projects running on OpenShift. It serves as a comprehensive resource for developers looking to deploy AI solutions on the OpenShift platform.

sematic
Sematic is an open-source ML development platform that allows ML Engineers and Data Scientists to write complex end-to-end pipelines with Python. It can be executed locally, on a cloud VM, or on a Kubernetes cluster. Sematic enables chaining data processing jobs with model training into reproducible pipelines that can be monitored and visualized in a web dashboard. It offers features like easy onboarding, local-to-cloud parity, end-to-end traceability, access to heterogeneous compute resources, and reproducibility.

SuperKnowa
SuperKnowa is a fast framework to build Enterprise RAG (Retriever Augmented Generation) Pipelines at Scale, powered by watsonx. It accelerates Enterprise Generative AI applications to get prod-ready solutions quickly on private data. The framework provides pluggable components for tackling various Generative AI use cases using Large Language Models (LLMs), allowing users to assemble building blocks to address challenges in AI-driven text generation. SuperKnowa is battle-tested from 1M to 200M private knowledge base & scaled to billions of retriever tokens.

ZetaForge
ZetaForge is an open-source AI platform designed for rapid development of advanced AI and AGI pipelines. It allows users to assemble reusable, customizable, and containerized Blocks into highly visual AI Pipelines, enabling rapid experimentation and collaboration. With ZetaForge, users can work with AI technologies in any programming language, easily modify and update AI pipelines, dive into the code whenever needed, utilize community-driven blocks and pipelines, and share their own creations. The platform aims to accelerate the development and deployment of advanced AI solutions through its user-friendly interface and community support.

AdalFlow
AdalFlow is a library designed to help developers build and optimize Large Language Model (LLM) task pipelines. It follows a design pattern similar to PyTorch, offering a light, modular, and robust codebase. Named in honor of Ada Lovelace, AdalFlow aims to inspire more women to enter the AI field. The library is tailored for various GenAI applications like chatbots, translation, summarization, code generation, and autonomous agents, as well as classical NLP tasks such as text classification and named entity recognition. AdalFlow emphasizes modularity, robustness, and readability to support users in customizing and iterating code for their specific use cases.
data-prep-kit
Data Prep Kit is a community project aimed at democratizing and speeding up unstructured data preparation for LLM app developers. It provides high-level APIs and modules for transforming data (code, language, speech, visual) to optimize LLM performance across different use cases. The toolkit supports Python, Ray, Spark, and Kubeflow Pipelines runtimes, offering scalability from laptop to datacenter-scale processing. Developers can contribute new custom modules and leverage the data processing library for building data pipelines. Automation features include workflow automation with Kubeflow Pipelines for transform execution.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.