
shandu
OpenAI DeepResearch alternative, An AI-driven research system that performs comprehensive, iterative research on any topic using multiple search engines and LLMs.
Stars: 426
Shandu is an advanced AI research system that automates comprehensive research processes using language models, web scraping, and iterative exploration to generate well-structured reports with citations. It features intelligent state-based workflow, deep exploration, multi-source information synthesis, enhanced web scraping, smart source evaluation, content analysis pipeline, comprehensive report generation, parallel processing, adaptive search strategy, and full citation management.
README:
Shandu is a cutting-edge AI research assistant that performs in-depth, multi-source research on any topic using advanced language models, intelligent web scraping, and iterative exploration to generate comprehensive, well-structured reports with proper citations.
Shandu is an intelligent, LLM-powered research system that automates the comprehensive research process - from initial query clarification to in-depth content analysis and report generation. Built on LangGraph's state-based workflow, it recursively explores topics with sophisticated algorithms for source evaluation, content extraction, and knowledge synthesis.
- Academic Research: Generate literature reviews, background information, and complex topic analyses
- Market Intelligence: Analyze industry trends, competitor strategies, and market opportunities
- Content Creation: Produce well-researched articles, blog posts, and reports with proper citations
- Technology Exploration: Track emerging technologies, innovations, and technical developments
- Policy Analysis: Research regulations, compliance requirements, and policy implications
- Competitive Analysis: Compare products, services, and company strategies across industries
flowchart TB
subgraph Input
Q[User Query]
B[Breadth Parameter]
D[Depth Parameter]
end
DR[Deep Research] -->
SQ[SERP Queries] -->
PR[Process Results]
subgraph Results[Results]
direction TB
NL((Learnings))
ND((Directions))
end
PR --> NL
PR --> ND
DP{depth > 0?}
RD["Next Direction:
- Prior Goals
- New Questions
- Learnings"]
MR[Markdown Report]
%% Main Flow
Q & B & D --> DR
%% Results to Decision
NL & ND --> DP
%% Circular Flow
DP -->|Yes| RD
RD -->|New Context| DR
%% Final Output
DP -->|No| MR
%% Styling
classDef input fill:#7bed9f,stroke:#2ed573,color:black
classDef process fill:#70a1ff,stroke:#1e90ff,color:black
classDef recursive fill:#ffa502,stroke:#ff7f50,color:black
classDef output fill:#ff4757,stroke:#ff6b81,color:black
classDef results fill:#a8e6cf,stroke:#3b7a57,color:black
class Q,B,D input
class DR,SQ,PR process
class DP,RD recursive
class MR output
class NL,ND results- Intelligent State-based Workflow: Leverages LangGraph for a structured, step-by-step research process with clear state transitions
- Iterative Deep Exploration: Recursively explores topics with dynamic depth and breadth, adapting to information discovered
- Multi-source Information Synthesis: Analyzes data from search engines, web content, and structured knowledge bases
- Enhanced Web Scraping: Features dynamic JS rendering, content extraction, and ethical scraping practices
- Smart Source Evaluation: Automatically assesses source credibility, relevance, and information value
- Content Analysis Pipeline: Uses advanced NLP to extract key information, identify patterns, and synthesize findings
- Comprehensive Report Generation: Creates detailed, well-structured reports with proper citations and thematic organization
- Parallel Processing Architecture: Implements concurrent operations for efficient multi-query execution
- Adaptive Search Strategy: Dynamically adjusts search queries based on discovered information and knowledge gaps
- Full Citation Management: Properly attributes all sources with formatted citations in multiple styles
# Install from PyPI
pip install shandu
# Install from source
git clone https://github.com/jolovicdev/shandu.git
cd shandu
pip install -e .# Configure API settings (supports various LLM providers)
shandu configure
# Run comprehensive research
shandu research "Your research query" --depth 2 --breadth 4 --output report.md
# Quick AI-powered search with web scraping (You dont need Perplexity!)
shandu aisearch "Who is the current sitting president of United States?" --detailed
# Basic multi-engine search
shandu search "Your search query"shandu research "Your research query" \
--depth 3 \ # How deep to explore (1-5, default: 2)
--breadth 5 \ # How many parallel queries (2-10, default: 4)
--output report.md \ # Save to file instead of terminal
--verbose # Show detailed progressYou can find example reports in the examples directory:
-
The Intersection of Quantum Computing, Synthetic Biology, and Climate Modeling
shandu research "The Intersection of Quantum Computing, Synthetic Biology, and Climate Modeling" --depth 3 --breadth 3 --output examples/o3-mini-high.md
shandu aisearch "Your search query" \
--engines "google,duckduckgo" \ # Comma-separated list of search engines
--max-results 15 \ # Maximum number of results to return
--output results.md \ # Save to file instead of terminal
--detailed # Generate a detailed analysisfrom shandu.agents import ResearchGraph
from langchain_openai import ChatOpenAI
# Initialize with custom LLM if desired
llm = ChatOpenAI(model="gpt-4")
# Initialize the research graph
researcher = ResearchGraph(
llm=llm,
temperature=0.5
)
# Perform deep research
results = researcher.research_sync(
query="Your research query",
depth=3, # How deep to go with recursive research
breadth=4, # How many parallel queries to explore
detail_level="high"
)
# Print or save results
print(results.to_markdown())Shandu implements a sophisticated multi-stage research pipeline:
- Query Clarification: Interactive questions to understand research needs
- Research Planning: Strategic planning for comprehensive topic coverage
-
Iterative Exploration:
- Smart query generation based on knowledge gaps
- Multi-engine search with parallelized execution
- Relevance filtering of search results
- Intelligent web scraping with content extraction
- Source credibility assessment
- Information analysis and synthesis
- Reflection on findings to identify gaps
-
Report Generation:
- Theme extraction and organization
- Multi-step report enhancement
- Citation formatting and management
- Section expansion for comprehensive coverage
- Google Search
- DuckDuckGo
- Wikipedia
- ArXiv (academic papers)
- Custom search engines can be added
- Dynamic JS Rendering: Handles JavaScript-heavy websites
- Content Extraction: Identifies and extracts main content from web pages
- Parallel Processing: Concurrent execution of searches and scraping
- Caching: Efficient caching of search results and scraped content
- Rate Limiting: Respectful access to web resources
- Robots.txt Compliance: Ethical web scraping practices
- Flexible Output Formats: Markdown, JSON, plain text
Note: this is just an idea, i need contributors, this is project where I'm taking deep dive into LangChain and LangGraph! This project is licensed under the MIT License - see the LICENSE file for details.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for shandu
Similar Open Source Tools
shandu
Shandu is an advanced AI research system that automates comprehensive research processes using language models, web scraping, and iterative exploration to generate well-structured reports with citations. It features intelligent state-based workflow, deep exploration, multi-source information synthesis, enhanced web scraping, smart source evaluation, content analysis pipeline, comprehensive report generation, parallel processing, adaptive search strategy, and full citation management.

Mira
Mira is an agentic AI library designed for automating company research by gathering information from various sources like company websites, LinkedIn profiles, and Google Search. It utilizes a multi-agent architecture to collect and merge data points into a structured profile with confidence scores and clear source attribution. The core library is framework-agnostic and can be integrated into applications, pipelines, or custom workflows. Mira offers features such as real-time progress events, confidence scoring, company criteria matching, and built-in services for data gathering. The tool is suitable for users looking to streamline company research processes and enhance data collection efficiency.
VeritasGraph
VeritasGraph is an enterprise-grade graph RAG framework designed for secure, on-premise AI applications. It leverages a knowledge graph to perform complex, multi-hop reasoning, providing transparent, auditable reasoning paths with full source attribution. The framework excels at answering complex questions that traditional vector search engines struggle with, ensuring trust and reliability in enterprise AI. VeritasGraph offers full control over data and AI models, verifiable attribution for every claim, advanced graph reasoning capabilities, and open-source deployment with sovereignty and customization.

ApeRAG
ApeRAG is a production-ready platform for Retrieval-Augmented Generation (RAG) that combines Graph RAG, vector search, and full-text search with advanced AI agents. It is ideal for building Knowledge Graphs, Context Engineering, and deploying intelligent AI agents for autonomous search and reasoning across knowledge bases. The platform offers features like advanced index types, intelligent AI agents with MCP support, enhanced Graph RAG with entity normalization, multimodal processing, hybrid retrieval engine, MinerU integration for document parsing, production-grade deployment with Kubernetes, enterprise management features, MCP integration, and developer-friendly tools for customization and contribution.

WeKnora
WeKnora is a document understanding and semantic retrieval framework based on large language models (LLM), designed specifically for scenarios with complex structures and heterogeneous content. The framework adopts a modular architecture, integrating multimodal preprocessing, semantic vector indexing, intelligent recall, and large model generation reasoning to build an efficient and controllable document question-answering process. The core retrieval process is based on the RAG (Retrieval-Augmented Generation) mechanism, combining context-relevant segments with language models to achieve higher-quality semantic answers. It supports various document formats, intelligent inference, flexible extension, efficient retrieval, ease of use, and security and control. Suitable for enterprise knowledge management, scientific literature analysis, product technical support, legal compliance review, and medical knowledge assistance.

Biomni
Biomni is a general-purpose biomedical AI agent designed to autonomously execute a wide range of research tasks across diverse biomedical subfields. By integrating cutting-edge large language model (LLM) reasoning with retrieval-augmented planning and code-based execution, Biomni helps scientists dramatically enhance research productivity and generate testable hypotheses.
resume-job-matcher
Resume Job Matcher is a Python script that automates the process of matching resumes to a job description using AI. It leverages the Anthropic Claude API or OpenAI's GPT API to analyze resumes and provide a match score along with personalized email responses for candidates. The tool offers comprehensive resume processing, advanced AI-powered analysis, in-depth evaluation & scoring, comprehensive analytics & reporting, enhanced candidate profiling, and robust system management. Users can customize font presets, generate PDF versions of unified resumes, adjust logging level, change scoring model, modify AI provider, and adjust AI model. The final score for each resume is calculated based on AI-generated match score and resume quality score, ensuring content relevance and presentation quality are considered. Troubleshooting tips, best practices, contribution guidelines, and required Python packages are provided.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.

premsql
PremSQL is an open-source library designed to help developers create secure, fully local Text-to-SQL solutions using small language models. It provides essential tools for building and deploying end-to-end Text-to-SQL pipelines with customizable components, ideal for secure, autonomous AI-powered data analysis. The library offers features like Local-First approach, Customizable Datasets, Robust Executors and Evaluators, Advanced Generators, Error Handling and Self-Correction, Fine-Tuning Support, and End-to-End Pipelines. Users can fine-tune models, generate SQL queries from natural language inputs, handle errors, and evaluate model performance against predefined metrics. PremSQL is extendible for customization and private data usage.

tinyllm
tinyllm is a lightweight framework designed for developing, debugging, and monitoring LLM and Agent powered applications at scale. It aims to simplify code while enabling users to create complex agents or LLM workflows in production. The core classes, Function and FunctionStream, standardize and control LLM, ToolStore, and relevant calls for scalable production use. It offers structured handling of function execution, including input/output validation, error handling, evaluation, and more, all while maintaining code readability. Users can create chains with prompts, LLM models, and evaluators in a single file without the need for extensive class definitions or spaghetti code. Additionally, tinyllm integrates with various libraries like Langfuse and provides tools for prompt engineering, observability, logging, and finite state machine design.
Vodalus-Expert-LLM-Forge
Vodalus Expert LLM Forge is a tool designed for crafting datasets and efficiently fine-tuning models using free open-source tools. It includes components for data generation, LLM interaction, RAG engine integration, model training, fine-tuning, and quantization. The tool is suitable for users at all levels and is accompanied by comprehensive documentation. Users can generate synthetic data, interact with LLMs, train models, and optimize performance for local execution. The tool provides detailed guides and instructions for setup, usage, and customization.
Curie
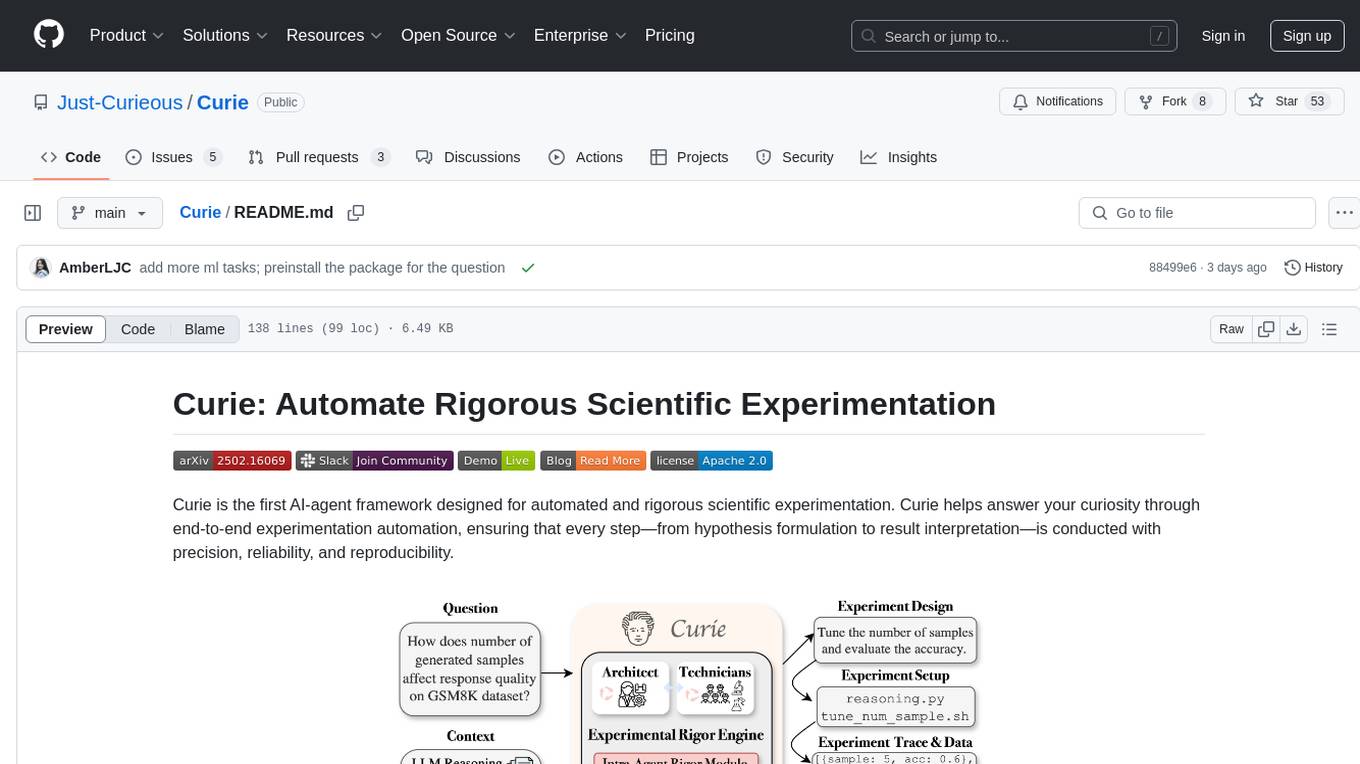
Curie is an AI-agent framework designed for automated and rigorous scientific experimentation. It automates end-to-end workflow management, ensures methodical procedure, reliability, and interpretability, and supports ML research, system analysis, and scientific discovery. It provides a benchmark with questions from 4 Computer Science domains. Users can customize experiment agents and adapt to their own tasks by configuring base_config.json. Curie is suitable for hyperparameter tuning, algorithm behavior analysis, system performance benchmarking, and automating computational simulations.
wanwu
Wanwu AI Agent Platform is an enterprise-grade one-stop commercially friendly AI agent development platform designed for business scenarios. It provides enterprises with a safe, efficient, and compliant one-stop AI solution. The platform integrates cutting-edge technologies such as large language models and business process automation to build an AI engineering platform covering model full life-cycle management, MCP, web search, AI agent rapid development, enterprise knowledge base construction, and complex workflow orchestration. It supports modular architecture design, flexible functional expansion, and secondary development, reducing the application threshold of AI technology while ensuring security and privacy protection of enterprise data. It accelerates digital transformation, cost reduction, efficiency improvement, and business innovation for enterprises of all sizes.

aigne-framework
AIGNE Framework is a functional AI application development framework designed to simplify and accelerate the process of building modern applications. It combines functional programming features, powerful artificial intelligence capabilities, and modular design principles to help developers easily create scalable solutions. With key features like modular design, TypeScript support, multiple AI model support, flexible workflow patterns, MCP protocol integration, code execution capabilities, and Blocklet ecosystem integration, AIGNE Framework offers a comprehensive solution for developers. The framework provides various workflow patterns such as Workflow Router, Workflow Sequential, Workflow Concurrency, Workflow Handoff, Workflow Reflection, Workflow Orchestration, Workflow Code Execution, and Workflow Group Chat to address different application scenarios efficiently. It also includes built-in MCP support for running MCP servers and integrating with external MCP servers, along with packages for core functionality, agent library, CLI, and various models like OpenAI, Gemini, Claude, and Nova.
dot-ai
Dot-ai is a machine learning library designed to simplify the process of building and deploying AI models. It provides a wide range of tools and utilities for data preprocessing, model training, and evaluation. With Dot-ai, users can easily create and experiment with various machine learning algorithms without the need for extensive coding knowledge. The library is built with scalability and performance in mind, making it suitable for both small-scale projects and large-scale applications. Whether you are a beginner or an experienced data scientist, Dot-ai offers a user-friendly interface to streamline your AI development workflow.

crawl4ai
Crawl4AI is a powerful and free web crawling service that extracts valuable data from websites and provides LLM-friendly output formats. It supports crawling multiple URLs simultaneously, replaces media tags with ALT, and is completely free to use and open-source. Users can integrate Crawl4AI into Python projects as a library or run it as a standalone local server. The tool allows users to crawl and extract data from specified URLs using different providers and models, with options to include raw HTML content, force fresh crawls, and extract meaningful text blocks. Configuration settings can be adjusted in the `crawler/config.py` file to customize providers, API keys, chunk processing, and word thresholds. Contributions to Crawl4AI are welcome from the open-source community to enhance its value for AI enthusiasts and developers.
For similar tasks
shandu
Shandu is an advanced AI research system that automates comprehensive research processes using language models, web scraping, and iterative exploration to generate well-structured reports with citations. It features intelligent state-based workflow, deep exploration, multi-source information synthesis, enhanced web scraping, smart source evaluation, content analysis pipeline, comprehensive report generation, parallel processing, adaptive search strategy, and full citation management.
For similar jobs

ChatFAQ
ChatFAQ is an open-source comprehensive platform for creating a wide variety of chatbots: generic ones, business-trained, or even capable of redirecting requests to human operators. It includes a specialized NLP/NLG engine based on a RAG architecture and customized chat widgets, ensuring a tailored experience for users and avoiding vendor lock-in.

anything-llm
AnythingLLM is a full-stack application that enables you to turn any document, resource, or piece of content into context that any LLM can use as references during chatting. This application allows you to pick and choose which LLM or Vector Database you want to use as well as supporting multi-user management and permissions.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

mikupad
mikupad is a lightweight and efficient language model front-end powered by ReactJS, all packed into a single HTML file. Inspired by the likes of NovelAI, it provides a simple yet powerful interface for generating text with the help of various backends.

glide
Glide is a cloud-native LLM gateway that provides a unified REST API for accessing various large language models (LLMs) from different providers. It handles LLMOps tasks such as model failover, caching, key management, and more, making it easy to integrate LLMs into applications. Glide supports popular LLM providers like OpenAI, Anthropic, Azure OpenAI, AWS Bedrock (Titan), Cohere, Google Gemini, OctoML, and Ollama. It offers high availability, performance, and observability, and provides SDKs for Python and NodeJS to simplify integration.

onnxruntime-genai
ONNX Runtime Generative AI is a library that provides the generative AI loop for ONNX models, including inference with ONNX Runtime, logits processing, search and sampling, and KV cache management. Users can call a high level `generate()` method, or run each iteration of the model in a loop. It supports greedy/beam search and TopP, TopK sampling to generate token sequences, has built in logits processing like repetition penalties, and allows for easy custom scoring.

firecrawl
Firecrawl is an API service that takes a URL, crawls it, and converts it into clean markdown. It crawls all accessible subpages and provides clean markdown for each, without requiring a sitemap. The API is easy to use and can be self-hosted. It also integrates with Langchain and Llama Index. The Python SDK makes it easy to crawl and scrape websites in Python code.