
aibrix
Cost-efficient and pluggable Infrastructure components for GenAI inference
Stars: 4226
AIBrix is an open-source initiative providing essential building blocks for scalable GenAI inference infrastructure. It delivers a cloud-native solution optimized for deploying, managing, and scaling large language model (LLM) inference, tailored to enterprise needs. Key features include High-Density LoRA Management, LLM Gateway and Routing, LLM App-Tailored Autoscaler, Unified AI Runtime, Distributed Inference, Distributed KV Cache, Cost-efficient Heterogeneous Serving, and GPU Hardware Failure Detection.
README:
Welcome to AIBrix, an open-source initiative designed to provide essential building blocks to construct scalable GenAI inference infrastructure. AIBrix delivers a cloud-native solution optimized for deploying, managing, and scaling large language model (LLM) inference, tailored specifically to enterprise needs.
| Documentation | Blog | White Paper | Twitter/X | Developer Slack |
- [2025-08-05] AIBrix v0.4.0 is released. Check out the release notes and Blog Post for more details
- [2025-06-10] The AIBrix team delivered a talk at KubeCon China 2025 titled AIBrix: Cost-Effective and Scalable Kubernetes Control Plane for vLLM, discussing how the framework optimizes vLLM deployment via Kubernetes for cost efficiency and scalability.
- [2025-05-21] AIBrix v0.3.0 is released. Check out the release notes and Blog Post for more details
- [2025-04-04] AIBrix co-delivered a KubeCon EU 2025 keynote with Google on LLM-Aware Load Balancing in Kubernetes: A New Era of Efficiency, focusing on LLM specific routing solutions.
- [2025-03-30] AIBrix was featured at the ASPLOS'25 workshop with the presentation AIBrix: An Open-Source, Large-Scale LLM Inference Infrastructure for System Research, showcasing its architecture for efficient LLM inference in system research scenarios.
- [2025-03-09] AIBrix v0.2.1 is released. DeepSeek-R1 full weights deployment is supported and gateway stability has been improved! Check Blog Post for more details.
- [2025-02-19] AIBrix v0.2.0 is released. Check out the release notes and Blog Post for more details.
- [2024-11-13] AIBrix v0.1.0 is released. Check out the release notes and Blog Post for more details.
The initial release includes the following key features:
- High-Density LoRA Management: Streamlined support for lightweight, low-rank adaptations of models.
- LLM Gateway and Routing: Efficiently manage and direct traffic across multiple models and replicas.
- LLM App-Tailored Autoscaler: Dynamically scale inference resources based on real-time demand.
- Unified AI Runtime: A versatile sidecar enabling metric standardization, model downloading, and management.
- Distributed Inference: Scalable architecture to handle large workloads across multiple nodes.
- Distributed KV Cache: Enables high-capacity, cross-engine KV reuse.
- Cost-efficient Heterogeneous Serving: Enables mixed GPU inference to reduce costs with SLO guarantees.
- GPU Hardware Failure Detection: Proactive detection of GPU hardware issues.

To get started with AIBrix, clone this repository and follow the setup instructions in the documentation. Our comprehensive guide will help you configure and deploy your first LLM infrastructure seamlessly.
# Local Testing
git clone https://github.com/vllm-project/aibrix.git
cd aibrix
# Install nightly aibrix dependencies
kubectl apply -k config/dependency --server-side
# Install nightly aibrix components
kubectl apply -k config/defaultInstall stable distribution
# Install component dependencies
kubectl apply -f "https://github.com/vllm-project/aibrix/releases/download/v0.4.0/aibrix-dependency-v0.4.0.yaml" --server-side
# Install aibrix components
kubectl apply -f "https://github.com/vllm-project/aibrix/releases/download/v0.4.0/aibrix-core-v0.4.0.yaml"For detailed documentation on installation, configuration, and usage, please visit our documentation page.
We welcome contributions from the community! Check out our contributing guidelines to see how you can make a difference.
Slack Channel: #aibrix
AIBrix is licensed under the Apache 2.0 License.
If you have any questions or encounter any issues, please submit an issue on our GitHub issues page.
Thank you for choosing AIBrix for your GenAI infrastructure needs!
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for aibrix
Similar Open Source Tools
aibrix
AIBrix is an open-source initiative providing essential building blocks for scalable GenAI inference infrastructure. It delivers a cloud-native solution optimized for deploying, managing, and scaling large language model (LLM) inference, tailored to enterprise needs. Key features include High-Density LoRA Management, LLM Gateway and Routing, LLM App-Tailored Autoscaler, Unified AI Runtime, Distributed Inference, Distributed KV Cache, Cost-efficient Heterogeneous Serving, and GPU Hardware Failure Detection.
meeting-minutes
An open-source AI assistant for taking meeting notes that captures live meeting audio, transcribes it in real-time, and generates summaries while ensuring user privacy. Perfect for teams to focus on discussions while automatically capturing and organizing meeting content without external servers or complex infrastructure. Features include modern UI, real-time audio capture, speaker diarization, local processing for privacy, and more. The tool also offers a Rust-based implementation for better performance and native integration, with features like live transcription, speaker diarization, and a rich text editor for notes. Future plans include database connection for saving meeting minutes, improving summarization quality, and adding download options for meeting transcriptions and summaries. The backend supports multiple LLM providers through a unified interface, with configurations for Anthropic, Groq, and Ollama models. System architecture includes core components like audio capture service, transcription engine, LLM orchestrator, data services, and API layer. Prerequisites for setup include Node.js, Python, FFmpeg, and Rust. Development guidelines emphasize project structure, testing, documentation, type hints, and ESLint configuration. Contributions are welcome under the MIT License.

Simplifine
Simplifine is an open-source library designed for easy LLM finetuning, enabling users to perform tasks such as supervised fine tuning, question-answer finetuning, contrastive loss for embedding tasks, multi-label classification finetuning, and more. It provides features like WandB logging, in-built evaluation tools, automated finetuning parameters, and state-of-the-art optimization techniques. The library offers bug fixes, new features, and documentation updates in its latest version. Users can install Simplifine via pip or directly from GitHub. The project welcomes contributors and provides comprehensive documentation and support for users.

xllm
xLLM is an efficient LLM inference framework optimized for Chinese AI accelerators, enabling enterprise-grade deployment with enhanced efficiency and reduced cost. It adopts a service-engine decoupled inference architecture, achieving breakthrough efficiency through technologies like elastic scheduling, dynamic PD disaggregation, multi-stream parallel computing, graph fusion optimization, and global KV cache management. xLLM supports deployment of mainstream large models on Chinese AI accelerators, empowering enterprises in scenarios like intelligent customer service, risk control, supply chain optimization, ad recommendation, and more.

flow-like
Flow-Like is an enterprise-grade workflow operating system built upon Rust for uncompromising performance, efficiency, and code safety. It offers a modular frontend for apps, a rich set of events, a node catalog, a powerful no-code workflow IDE, and tools to manage teams, templates, and projects within organizations. With typed workflows, users can create complex, large-scale workflows with clear data origins, transformations, and contracts. Flow-Like is designed to automate any process through seamless integration of LLM, ML-based, and deterministic decision-making instances.
ComfyUI-Copilot
ComfyUI-Copilot is an intelligent assistant built on the Comfy-UI framework that simplifies and enhances the AI algorithm debugging and deployment process through natural language interactions. It offers intuitive node recommendations, workflow building aids, and model querying services to streamline development processes. With features like interactive Q&A bot, natural language node suggestions, smart workflow assistance, and model querying, ComfyUI-Copilot aims to lower the barriers to entry for beginners, boost development efficiency with AI-driven suggestions, and provide real-time assistance for developers.

instill-core
Instill Core is an open-source orchestrator comprising a collection of source-available projects designed to streamline every aspect of building versatile AI features with unstructured data. It includes Instill VDP (Versatile Data Pipeline) for unstructured data, AI, and pipeline orchestration, Instill Model for scalable MLOps and LLMOps for open-source or custom AI models, and Instill Artifact for unified unstructured data management. Instill Core can be used for tasks such as building, testing, and sharing pipelines, importing, serving, fine-tuning, and monitoring ML models, and transforming documents, images, audio, and video into a unified AI-ready format.
wanwu
Wanwu AI Agent Platform is an enterprise-grade one-stop commercially friendly AI agent development platform designed for business scenarios. It provides enterprises with a safe, efficient, and compliant one-stop AI solution. The platform integrates cutting-edge technologies such as large language models and business process automation to build an AI engineering platform covering model full life-cycle management, MCP, web search, AI agent rapid development, enterprise knowledge base construction, and complex workflow orchestration. It supports modular architecture design, flexible functional expansion, and secondary development, reducing the application threshold of AI technology while ensuring security and privacy protection of enterprise data. It accelerates digital transformation, cost reduction, efficiency improvement, and business innovation for enterprises of all sizes.

cherry-studio
Cherry Studio is a desktop client that supports multiple LLM providers on Windows, Mac, and Linux. It offers diverse LLM provider support, AI assistants & conversations, document & data processing, practical tools integration, and enhanced user experience. The tool includes features like support for major LLM cloud services, AI web service integration, local model support, pre-configured AI assistants, document processing for text, images, and more, global search functionality, topic management system, AI-powered translation, and cross-platform support with ready-to-use features and themes for a better user experience.

TaskingAI
TaskingAI brings Firebase's simplicity to **AI-native app development**. The platform enables the creation of GPTs-like multi-tenant applications using a wide range of LLMs from various providers. It features distinct, modular functions such as Inference, Retrieval, Assistant, and Tool, seamlessly integrated to enhance the development process. TaskingAI’s cohesive design ensures an efficient, intelligent, and user-friendly experience in AI application development.

astron-agent
Astron Agent is an enterprise-grade, commercial-friendly Agentic Workflow development platform that integrates AI workflow orchestration, model management, AI and MCP tool integration, RPA automation, and team collaboration features. It supports high-availability deployment, enabling organizations to rapidly build scalable, production-ready intelligent agent applications and establish their AI foundation for the future. The platform is stable, reliable, and business-friendly, with key features such as enterprise-grade high availability, intelligent RPA integration, ready-to-use tool ecosystem, and flexible large model support.
kserve
KServe provides a Kubernetes Custom Resource Definition for serving predictive and generative machine learning (ML) models. It encapsulates the complexity of autoscaling, networking, health checking, and server configuration to bring cutting edge serving features like GPU Autoscaling, Scale to Zero, and Canary Rollouts to ML deployments. KServe enables a simple, pluggable, and complete story for Production ML Serving including prediction, pre-processing, post-processing, and explainability. It is a standard, cloud agnostic Model Inference Platform for serving predictive and generative AI models on Kubernetes, built for highly scalable use cases.
LiteRT
LiteRT is Google's open-source high-performance runtime for on-device AI, previously known as TensorFlow Lite. The repository is currently not intended for open-source development, but aims to evolve to allow direct building and contributions. LiteRT supports Python versions 3.9, 3.10, 3.11 on Linux and MacOS. It ensures compatibility with existing .tflite file extension and format, offering conversion tools and continued active development under the name LiteRT.
veScale
veScale is a PyTorch Native LLM Training Framework. It provides a set of tools and components to facilitate the training of large language models (LLMs) using PyTorch. veScale includes features such as 4D parallelism, fast checkpointing, and a CUDA event monitor. It is designed to be scalable and efficient, and it can be used to train LLMs on a variety of hardware platforms.
BMAD-METHOD
BMAD-METHOD™ is a universal AI agent framework that revolutionizes Agile AI-Driven Development. It offers specialized AI expertise across various domains, including software development, entertainment, creative writing, business strategy, and personal wellness. The framework introduces two key innovations: Agentic Planning, where dedicated agents collaborate to create detailed specifications, and Context-Engineered Development, which ensures complete understanding and guidance for developers. BMAD-METHOD™ simplifies the development process by eliminating planning inconsistency and context loss, providing a seamless workflow for creating AI agents and expanding functionality through expansion packs.
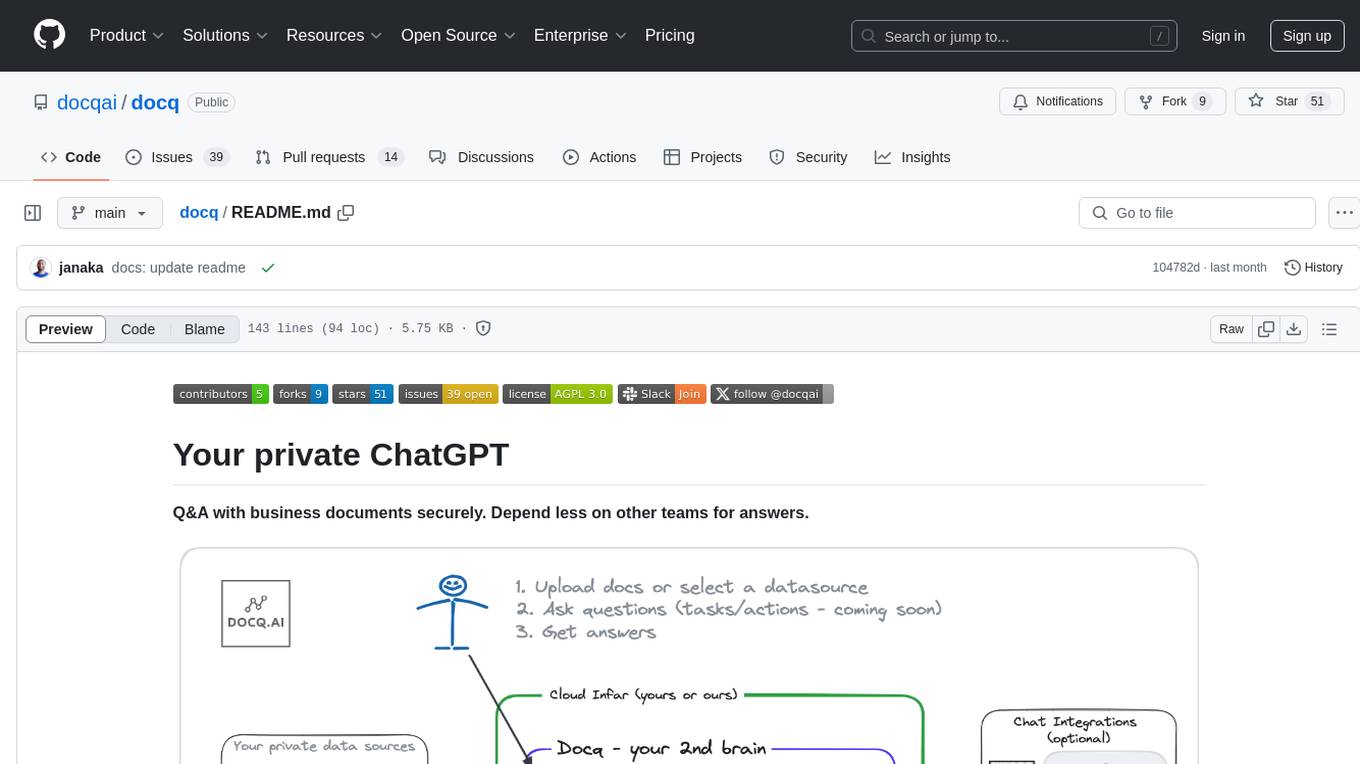
docq
Docq is a private and secure GenAI tool designed to extract knowledge from business documents, enabling users to find answers independently. It allows data to stay within organizational boundaries, supports self-hosting with various cloud vendors, and offers multi-model and multi-modal capabilities. Docq is extensible, open-source (AGPLv3), and provides commercial licensing options. The tool aims to be a turnkey solution for organizations to adopt AI innovation safely, with plans for future features like more data ingestion options and model fine-tuning.
For similar tasks
aibrix
AIBrix is an open-source initiative providing essential building blocks for scalable GenAI inference infrastructure. It delivers a cloud-native solution optimized for deploying, managing, and scaling large language model (LLM) inference, tailored to enterprise needs. Key features include High-Density LoRA Management, LLM Gateway and Routing, LLM App-Tailored Autoscaler, Unified AI Runtime, Distributed Inference, Distributed KV Cache, Cost-efficient Heterogeneous Serving, and GPU Hardware Failure Detection.
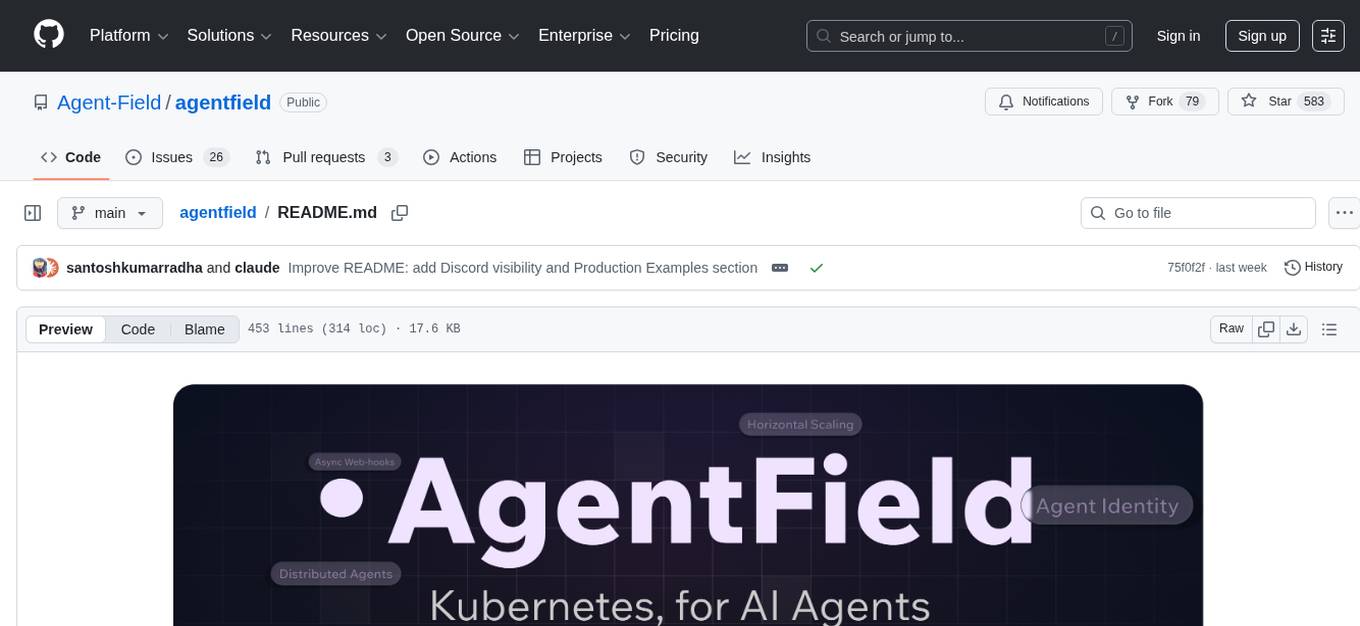
agentfield
AgentField is an open-source control plane designed for autonomous AI agents, providing infrastructure for agents to make decisions beyond chatbots. It offers features like scaling infrastructure, routing & discovery, async execution, durable state, observability, trust infrastructure with cryptographic identity, verifiable credentials, and policy enforcement. Users can write agents in Python, Go, TypeScript, or interact via REST APIs. The tool enables the creation of AI backends that reason autonomously within defined boundaries, offering predictability and flexibility. AgentField aims to bridge the gap between AI frameworks and production-ready infrastructure for AI agents.

mlflow
MLflow is a platform to streamline machine learning development, including tracking experiments, packaging code into reproducible runs, and sharing and deploying models. MLflow offers a set of lightweight APIs that can be used with any existing machine learning application or library (TensorFlow, PyTorch, XGBoost, etc), wherever you currently run ML code (e.g. in notebooks, standalone applications or the cloud). MLflow's current components are:
* `MLflow Tracking

model_server
OpenVINO™ Model Server (OVMS) is a high-performance system for serving models. Implemented in C++ for scalability and optimized for deployment on Intel architectures, the model server uses the same architecture and API as TensorFlow Serving and KServe while applying OpenVINO for inference execution. Inference service is provided via gRPC or REST API, making deploying new algorithms and AI experiments easy.

kitops
KitOps is a packaging and versioning system for AI/ML projects that uses open standards so it works with the AI/ML, development, and DevOps tools you are already using. KitOps simplifies the handoffs between data scientists, application developers, and SREs working with LLMs and other AI/ML models. KitOps' ModelKits are a standards-based package for models, their dependencies, configurations, and codebases. ModelKits are portable, reproducible, and work with the tools you already use.

CSGHub
CSGHub is an open source, trustworthy large model asset management platform that can assist users in governing the assets involved in the lifecycle of LLM and LLM applications (datasets, model files, codes, etc). With CSGHub, users can perform operations on LLM assets, including uploading, downloading, storing, verifying, and distributing, through Web interface, Git command line, or natural language Chatbot. Meanwhile, the platform provides microservice submodules and standardized OpenAPIs, which could be easily integrated with users' own systems. CSGHub is committed to bringing users an asset management platform that is natively designed for large models and can be deployed On-Premise for fully offline operation. CSGHub offers functionalities similar to a privatized Huggingface(on-premise Huggingface), managing LLM assets in a manner akin to how OpenStack Glance manages virtual machine images, Harbor manages container images, and Sonatype Nexus manages artifacts.
AI-Horde
The AI Horde is an enterprise-level ML-Ops crowdsourced distributed inference cluster for AI Models. This middleware can support both Image and Text generation. It is infinitely scalable and supports seamless drop-in/drop-out of compute resources. The Public version allows people without a powerful GPU to use Stable Diffusion or Large Language Models like Pygmalion/Llama by relying on spare/idle resources provided by the community and also allows non-python clients, such as games and apps, to use AI-provided generations.

caikit
Caikit is an AI toolkit that enables users to manage models through a set of developer friendly APIs. It provides a consistent format for creating and using AI models against a wide variety of data domains and tasks.
For similar jobs

llm-resource
llm-resource is a comprehensive collection of high-quality resources for Large Language Models (LLM). It covers various aspects of LLM including algorithms, training, fine-tuning, alignment, inference, data engineering, compression, evaluation, prompt engineering, AI frameworks, AI basics, AI infrastructure, AI compilers, LLM application development, LLM operations, AI systems, and practical implementations. The repository aims to gather and share valuable resources related to LLM for the community to benefit from.

LitServe
LitServe is a high-throughput serving engine designed for deploying AI models at scale. It generates an API endpoint for models, handles batching, streaming, and autoscaling across CPU/GPUs. LitServe is built for enterprise scale with a focus on minimal, hackable code-base without bloat. It supports various model types like LLMs, vision, time-series, and works with frameworks like PyTorch, JAX, Tensorflow, and more. The tool allows users to focus on model performance rather than serving boilerplate, providing full control and flexibility.

how-to-optim-algorithm-in-cuda
This repository documents how to optimize common algorithms based on CUDA. It includes subdirectories with code implementations for specific optimizations. The optimizations cover topics such as compiling PyTorch from source, NVIDIA's reduce optimization, OneFlow's elementwise template, fast atomic add for half data types, upsample nearest2d optimization in OneFlow, optimized indexing in PyTorch, OneFlow's softmax kernel, linear attention optimization, and more. The repository also includes learning resources related to deep learning frameworks, compilers, and optimization techniques.

aiac
AIAC is a library and command line tool to generate Infrastructure as Code (IaC) templates, configurations, utilities, queries, and more via LLM providers such as OpenAI, Amazon Bedrock, and Ollama. Users can define multiple 'backends' targeting different LLM providers and environments using a simple configuration file. The tool allows users to ask a model to generate templates for different scenarios and composes an appropriate request to the selected provider, storing the resulting code to a file and/or printing it to standard output.

ENOVA
ENOVA is an open-source service for Large Language Model (LLM) deployment, monitoring, injection, and auto-scaling. It addresses challenges in deploying stable serverless LLM services on GPU clusters with auto-scaling by deconstructing the LLM service execution process and providing configuration recommendations and performance detection. Users can build and deploy LLM with few command lines, recommend optimal computing resources, experience LLM performance, observe operating status, achieve load balancing, and more. ENOVA ensures stable operation, cost-effectiveness, efficiency, and strong scalability of LLM services.

jina
Jina is a tool that allows users to build multimodal AI services and pipelines using cloud-native technologies. It provides a Pythonic experience for serving ML models and transitioning from local deployment to advanced orchestration frameworks like Docker-Compose, Kubernetes, or Jina AI Cloud. Users can build and serve models for any data type and deep learning framework, design high-performance services with easy scaling, serve LLM models while streaming their output, integrate with Docker containers via Executor Hub, and host on CPU/GPU using Jina AI Cloud. Jina also offers advanced orchestration and scaling capabilities, a smooth transition to the cloud, and easy scalability and concurrency features for applications. Users can deploy to their own cloud or system with Kubernetes and Docker Compose integration, and even deploy to JCloud for autoscaling and monitoring.

vidur
Vidur is a high-fidelity and extensible LLM inference simulator designed for capacity planning, deployment configuration optimization, testing new research ideas, and studying system performance of models under different workloads and configurations. It supports various models and devices, offers chrome trace exports, and can be set up using mamba, venv, or conda. Users can run the simulator with various parameters and monitor metrics using wandb. Contributions are welcome, subject to a Contributor License Agreement and adherence to the Microsoft Open Source Code of Conduct.

AI-System-School
AI System School is a curated list of research in machine learning systems, focusing on ML/DL infra, LLM infra, domain-specific infra, ML/LLM conferences, and general resources. It provides resources such as data processing, training systems, video systems, autoML systems, and more. The repository aims to help users navigate the landscape of AI systems and machine learning infrastructure, offering insights into conferences, surveys, books, videos, courses, and blogs related to the field.