Best AI tools for< Ai Infrastructure Engineer >
Infographic
20 - AI tool Sites
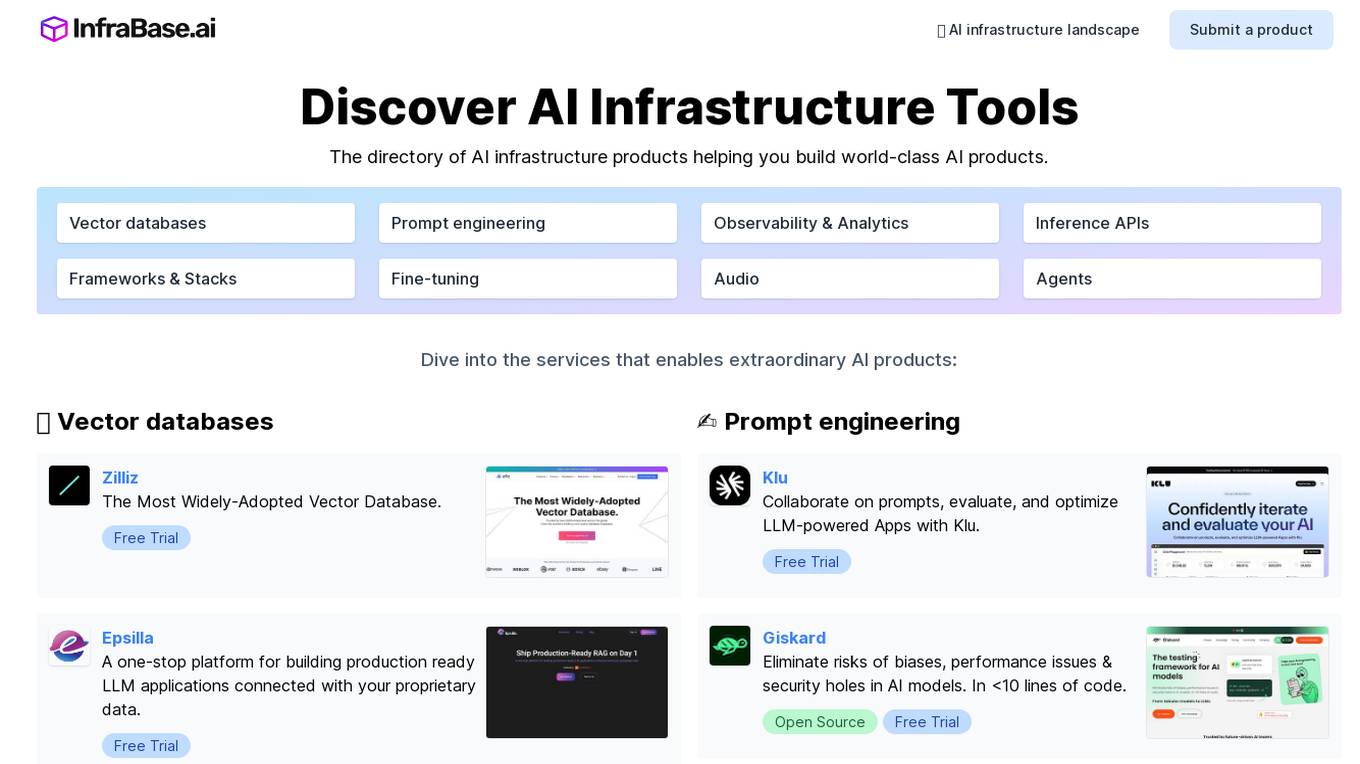
Infrabase.ai
Infrabase.ai is a directory of AI infrastructure products that helps users discover and explore a wide range of tools for building world-class AI products. The platform offers a comprehensive directory of products in categories such as Vector databases, Prompt engineering, Observability & Analytics, Inference APIs, Frameworks & Stacks, Fine-tuning, Audio, and Agents. Users can find tools for tasks like data storage, model development, performance monitoring, and more, making it a valuable resource for AI projects.
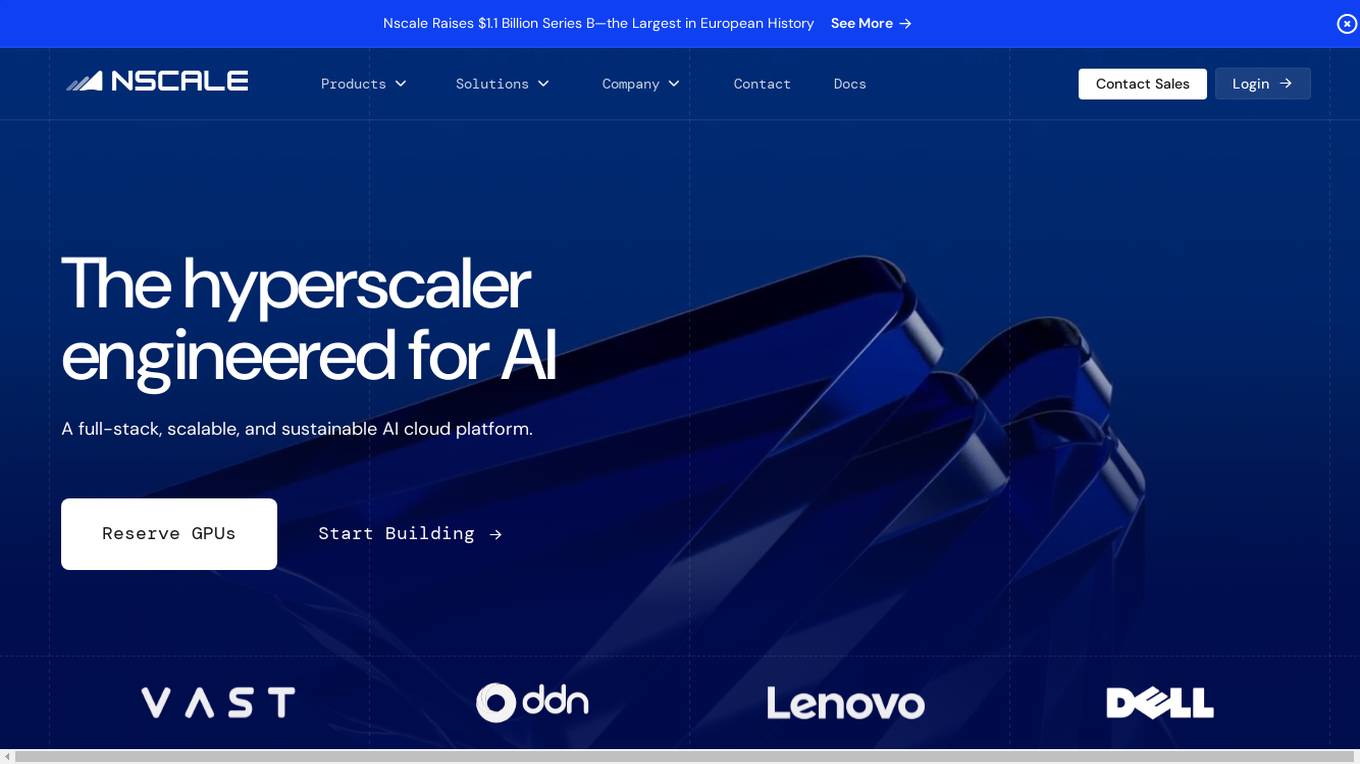
Nscale
Nscale is a full-stack, scalable, and sustainable AI cloud platform that offers a wide range of AI services and solutions. It provides services for developing, training, tuning, and deploying AI models using on-demand services. Nscale also offers serverless inference API endpoints, fine-tuning capabilities, private cloud solutions, and various GPU clusters engineered for AI. The platform aims to simplify the journey from AI model development to production, offering a marketplace for AI/ML tools and resources. Nscale's infrastructure includes data centers powered by renewable energy, high-performance GPU nodes, and optimized networking and storage solutions.
GooseAI
GooseAI is a fully managed NLP-as-a-Service delivered via API, at 30% the cost of other providers. It offers a variety of NLP models, including GPT-Neo 1.3B, Fairseq 1.3B, GPT-J 6B, Fairseq 6B, Fairseq 13B, and GPT-NeoX 20B. GooseAI is easy to use, with feature parity with industry standard APIs. It is also highly performant, with the industry's fastest generation speeds.
Granica
Granica is an AI tool designed for data compression and optimization, enabling users to transform petabytes of data into terabytes with self-optimizing, lossless compression. It offers state-of-the-art technology that works seamlessly across various platforms like Iceberg, Delta, Trino, Spark, Snowflake, and Databricks. Granica helps organizations reduce storage costs, improve query performance, and enhance data accessibility for AI and analytics workloads.
Anyscale
Anyscale is a company that provides a scalable compute platform for AI and Python applications. Their platform includes a serverless API for serving and fine-tuning open LLMs, a private cloud solution for data privacy and governance, and an open source framework for training, batch, and real-time workloads. Anyscale's platform is used by companies such as OpenAI, Uber, and Spotify to power their AI workloads.
Microtica
Microtica is an AI-powered cloud delivery platform that offers a comprehensive suite of DevOps tools to help users build, deploy, and optimize their infrastructure efficiently. With features like AI Incident Investigator, AI Infrastructure Builder, Kubernetes deployment simplification, alert monitoring, pipeline automation, and cloud monitoring, Microtica aims to streamline the development and management processes for DevOps teams. The platform provides real-time insights, cost optimization suggestions, and guided deployments, making it a valuable tool for businesses looking to enhance their cloud infrastructure operations.
Denvr DataWorks AI Cloud
Denvr DataWorks AI Cloud is a cloud-based AI platform that provides end-to-end AI solutions for businesses. It offers a range of features including high-performance GPUs, scalable infrastructure, ultra-efficient workflows, and cost efficiency. Denvr DataWorks is an NVIDIA Elite Partner for Compute, and its platform is used by leading AI companies to develop and deploy innovative AI solutions.

Cerebium
Cerebium is a serverless AI infrastructure platform that allows teams to build, test, and deploy AI applications quickly and efficiently. With a focus on speed, performance, and cost optimization, Cerebium offers a range of features and tools to simplify the development and deployment of AI projects. The platform ensures high reliability, security, and compliance while providing real-time logging, cost tracking, and observability tools. Cerebium also offers GPU variety and effortless autoscaling to meet the diverse needs of developers and businesses.

Outspeed
Outspeed is a platform for Realtime Voice and Video AI applications, providing networking and inference infrastructure to build fast, real-time voice and video AI apps. It offers tools for intelligence across industries, including Voice AI, Streaming Avatars, Visual Intelligence, Meeting Copilot, and the ability to build custom multimodal AI solutions. Outspeed is designed by engineers from Google and MIT, offering robust streaming infrastructure, low-latency inference, instant deployment, and enterprise-ready compliance with regulations such as SOC2, GDPR, and HIPAA.
Inworld
Inworld is an AI framework designed for games and media, offering a production-ready framework for building AI agents with client-side logic and local model inference. It provides tools optimized for real-time data ingestion, low latency, and massive scale, enabling developers to create engaging and immersive experiences for users. Inworld allows for building custom AI agent pipelines, refining agent behavior and performance, and seamlessly transitioning from prototyping to production. With support for C++, Python, and game engines, Inworld aims to future-proof AI development by integrating 3rd-party components and foundational models to avoid vendor lock-in.
UbiOps
UbiOps is an AI infrastructure platform that helps teams quickly run their AI & ML workloads as reliable and secure microservices. It offers powerful AI model serving and orchestration with unmatched simplicity, speed, and scale. UbiOps allows users to deploy models and functions in minutes, manage AI workloads from a single control plane, integrate easily with tools like PyTorch and TensorFlow, and ensure security and compliance by design. The platform supports hybrid and multi-cloud workload orchestration, rapid adaptive scaling, and modular applications with unique workflow management system.
NVIDIA Run:ai
NVIDIA Run:ai is an enterprise platform for AI workloads and GPU orchestration. It accelerates AI and machine learning operations by addressing key infrastructure challenges through dynamic resource allocation, comprehensive AI life-cycle support, and strategic resource management. The platform significantly enhances GPU efficiency and workload capacity by pooling resources across environments and utilizing advanced orchestration. NVIDIA Run:ai provides unparalleled flexibility and adaptability, supporting public clouds, private clouds, hybrid environments, or on-premises data centers.
CodeGPT
CodeGPT is a comprehensive AI-powered platform that provides a suite of tools and services designed to enhance business operations and streamline coding processes. It offers a range of AI assistants, known as Copilots, Agents, or GPTs, that can be customized and integrated into various applications. These AI assistants can automate tasks, generate content, provide insights, and assist with coding, among other functions. CodeGPT also features a marketplace where users can explore and discover a wide selection of pre-built AI assistants tailored to specific tasks and industries. Additionally, the platform offers an API for advanced users to integrate AI capabilities into their own custom projects. With its focus on customization, flexibility, and ease of use, CodeGPT empowers businesses and individuals to leverage AI technology to improve efficiency, productivity, and innovation.

Mystic.ai
Mystic.ai is an AI tool designed to deploy and scale Machine Learning models with ease. It offers a fully managed Kubernetes platform that runs in your own cloud, allowing users to deploy ML models in their own Azure/AWS/GCP account or in a shared GPU cluster. Mystic.ai provides cost optimizations, fast inference, simpler developer experience, and performance optimizations to ensure high-performance AI model serving. With features like pay-as-you-go API, cloud integration with AWS/Azure/GCP, and a beautiful dashboard, Mystic.ai simplifies the deployment and management of ML models for data scientists and AI engineers.

DeepRec.ai
DeepRec.ai is a specialized recruitment platform focusing on AI and ML professionals. The platform offers hiring services for various AI specialisms such as Research GenAI, Machine Learning, Computer Vision, AI Infrastructure, Quantum Computing, Robotics & Embodied AI, and AI4Science. DeepRec.ai provides hiring solutions like Embedded Hiring, Retained Search, Contingent Contract & Flexible Resource, tailored to scale with businesses and address high-volume hiring challenges. The platform boasts positive feedback from both clients and candidates, emphasizing the quality of communication, candidate selection, and support throughout the recruitment process.
Lambda
Lambda is a superintelligence cloud platform that offers on-demand GPU clusters for multi-node training and fine-tuning, private large-scale GPU clusters, seamless management and scaling of AI workloads, inference endpoints and API, and a privacy-first chat app with open source models. It also provides NVIDIA's latest generation infrastructure for enterprise AI. With Lambda, AI teams can access gigawatt-scale AI factories for training and inference, deploy GPU instances, and leverage the latest NVIDIA GPUs for high-performance computing.
vHive
vHive is an autonomous digital twin software that enables users to create a digitized portfolio of global enterprise assets. The platform offers advanced AI analytics and insights to maximize revenue and facilitate exponential growth. With vHive, users can improve operational efficiency, rapidly digitize assets worldwide, ensure security and compliance, and scale their asset portfolio through end-to-end automation. Trusted by leading enterprises, vHive provides a user-friendly platform for collecting data and insights across various use cases, ultimately driving organizational efficiency and innovation.
Enterprise AI
Enterprise AI provides comprehensive information, news, and tips on artificial intelligence (AI) for businesses. It covers various aspects of AI, including AI business strategies, AI infrastructure, AI technologies, AI platforms, careers in AI, and enterprise applications of AI. The website offers insights into the latest AI trends, best practices, and industry news. It also provides resources such as e-books, webinars, and podcasts to help businesses understand and implement AI solutions.

Moreh
Moreh is an AI platform that aims to make hyperscale AI infrastructure more accessible for scaling any AI model and application. It provides a full-stack infrastructure software from PyTorch to GPUs for the LLM era, enabling users to train large language models efficiently and effectively.

Cisco AI Solutions
Cisco offers a range of Artificial Intelligence (AI) solutions to help organizations leverage the power of AI in various aspects of their operations. From infrastructure scaling to data insights and AI-powered software, Cisco provides a comprehensive suite of services to accelerate the adoption and implementation of AI technologies. The company also invests in AI innovation and collaborates with industry leaders like NVIDIA to shape the future of AI infrastructure. With a focus on responsible AI, Cisco aims to deliver cutting-edge solutions that drive productivity and security while ensuring inclusivity and transparency in the AI ecosystem.
30 - Open Source Tools

llm-resource
llm-resource is a comprehensive collection of high-quality resources for Large Language Models (LLM). It covers various aspects of LLM including algorithms, training, fine-tuning, alignment, inference, data engineering, compression, evaluation, prompt engineering, AI frameworks, AI basics, AI infrastructure, AI compilers, LLM application development, LLM operations, AI systems, and practical implementations. The repository aims to gather and share valuable resources related to LLM for the community to benefit from.

LitServe
LitServe is a high-throughput serving engine designed for deploying AI models at scale. It generates an API endpoint for models, handles batching, streaming, and autoscaling across CPU/GPUs. LitServe is built for enterprise scale with a focus on minimal, hackable code-base without bloat. It supports various model types like LLMs, vision, time-series, and works with frameworks like PyTorch, JAX, Tensorflow, and more. The tool allows users to focus on model performance rather than serving boilerplate, providing full control and flexibility.

how-to-optim-algorithm-in-cuda
This repository documents how to optimize common algorithms based on CUDA. It includes subdirectories with code implementations for specific optimizations. The optimizations cover topics such as compiling PyTorch from source, NVIDIA's reduce optimization, OneFlow's elementwise template, fast atomic add for half data types, upsample nearest2d optimization in OneFlow, optimized indexing in PyTorch, OneFlow's softmax kernel, linear attention optimization, and more. The repository also includes learning resources related to deep learning frameworks, compilers, and optimization techniques.

aiac
AIAC is a library and command line tool to generate Infrastructure as Code (IaC) templates, configurations, utilities, queries, and more via LLM providers such as OpenAI, Amazon Bedrock, and Ollama. Users can define multiple 'backends' targeting different LLM providers and environments using a simple configuration file. The tool allows users to ask a model to generate templates for different scenarios and composes an appropriate request to the selected provider, storing the resulting code to a file and/or printing it to standard output.

ENOVA
ENOVA is an open-source service for Large Language Model (LLM) deployment, monitoring, injection, and auto-scaling. It addresses challenges in deploying stable serverless LLM services on GPU clusters with auto-scaling by deconstructing the LLM service execution process and providing configuration recommendations and performance detection. Users can build and deploy LLM with few command lines, recommend optimal computing resources, experience LLM performance, observe operating status, achieve load balancing, and more. ENOVA ensures stable operation, cost-effectiveness, efficiency, and strong scalability of LLM services.

jina
Jina is a tool that allows users to build multimodal AI services and pipelines using cloud-native technologies. It provides a Pythonic experience for serving ML models and transitioning from local deployment to advanced orchestration frameworks like Docker-Compose, Kubernetes, or Jina AI Cloud. Users can build and serve models for any data type and deep learning framework, design high-performance services with easy scaling, serve LLM models while streaming their output, integrate with Docker containers via Executor Hub, and host on CPU/GPU using Jina AI Cloud. Jina also offers advanced orchestration and scaling capabilities, a smooth transition to the cloud, and easy scalability and concurrency features for applications. Users can deploy to their own cloud or system with Kubernetes and Docker Compose integration, and even deploy to JCloud for autoscaling and monitoring.

vidur
Vidur is a high-fidelity and extensible LLM inference simulator designed for capacity planning, deployment configuration optimization, testing new research ideas, and studying system performance of models under different workloads and configurations. It supports various models and devices, offers chrome trace exports, and can be set up using mamba, venv, or conda. Users can run the simulator with various parameters and monitor metrics using wandb. Contributions are welcome, subject to a Contributor License Agreement and adherence to the Microsoft Open Source Code of Conduct.

AI-System-School
AI System School is a curated list of research in machine learning systems, focusing on ML/DL infra, LLM infra, domain-specific infra, ML/LLM conferences, and general resources. It provides resources such as data processing, training systems, video systems, autoML systems, and more. The repository aims to help users navigate the landscape of AI systems and machine learning infrastructure, offering insights into conferences, surveys, books, videos, courses, and blogs related to the field.
AITemplate
AITemplate (AIT) is a Python framework that transforms deep neural networks into CUDA (NVIDIA GPU) / HIP (AMD GPU) C++ code for lightning-fast inference serving. It offers high performance close to roofline fp16 TensorCore (NVIDIA GPU) / MatrixCore (AMD GPU) performance on major models. AITemplate is unified, open, and flexible, supporting a comprehensive range of fusions for both GPU platforms. It provides excellent backward capability, horizontal fusion, vertical fusion, memory fusion, and works with or without PyTorch. FX2AIT is a tool that converts PyTorch models into AIT for fast inference serving, offering easy conversion and expanded support for models with unsupported operators.
olah
Olah is a self-hosted lightweight Huggingface mirror service that implements mirroring feature for Huggingface resources at file block level, enhancing download speeds and saving bandwidth. It offers cache control policies and allows administrators to configure accessible repositories. Users can install Olah with pip or from source, set up the mirror site, and download models and datasets using huggingface-cli. Olah provides additional configurations through a configuration file for basic setup and accessibility restrictions. Future work includes implementing an administrator and user system, OOS backend support, and mirror update schedule task. Olah is released under the MIT License.

vllm-ascend
vLLM Ascend plugin is a backend plugin designed to run vLLM on the Ascend NPU. It provides a hardware-pluggable interface that allows popular open-source models to run seamlessly on the Ascend NPU. The plugin is recommended within the vLLM community and adheres to the principles of hardware pluggability outlined in the RFC. Users can set up their environment with specific hardware and software prerequisites to utilize this plugin effectively.
Tutel
Tutel MoE is an optimized Mixture-of-Experts implementation that offers a parallel solution with 'No-penalty Parallism/Sparsity/Capacity/Switching' for modern training and inference. It supports Pytorch framework (version >= 1.10) and various GPUs including CUDA and ROCm. The tool enables Full Precision Inference of MoE-based Deepseek R1 671B on AMD MI300. Tutel provides features like all-to-all benchmarking, tensorcore option, NCCL timeout settings, Megablocks solution, and dynamic switchable configurations. Users can run Tutel in distributed mode across multiple GPUs and machines. The tool allows for custom MoE implementations and offers detailed usage examples and reference documentation.
AIInfra
AIInfra is an open-source project focused on AI infrastructure, specifically targeting large models in distributed clusters, distributed architecture, distributed training, and algorithms related to large models. The project aims to explore and study system design in artificial intelligence and deep learning, with a focus on the hardware and software stack for building AI large model systems. It provides a comprehensive curriculum covering topics such as AI chip principles, communication and storage, AI clusters, large model training, and inference, as well as algorithms for large models. The course is designed for undergraduate and graduate students, as well as professionals working with AI large model systems, to gain a deep understanding of AI computer system architecture and design.
aibrix
AIBrix is an open-source initiative providing essential building blocks for scalable GenAI inference infrastructure. It delivers a cloud-native solution optimized for deploying, managing, and scaling large language model (LLM) inference, tailored to enterprise needs. Key features include High-Density LoRA Management, LLM Gateway and Routing, LLM App-Tailored Autoscaler, Unified AI Runtime, Distributed Inference, Distributed KV Cache, Cost-efficient Heterogeneous Serving, and GPU Hardware Failure Detection.
ShannonBase
ShannonBase is a HTAP database provided by Shannon Data AI, designed for big data and AI. It extends MySQL with native embedding support, machine learning capabilities, a JavaScript engine, and a columnar storage engine. ShannonBase supports multimodal data types and natively integrates LightGBM for training and prediction. It leverages embedding algorithms and vector data type for ML/RAG tasks, providing Zero Data Movement, Native Performance Optimization, and Seamless SQL Integration. The tool includes a lightweight JavaScript engine for writing stored procedures in SQL or JavaScript.
AIInfra
AIInfra is an open-source project focused on AI infrastructure, specifically targeting large models in distributed clusters, distributed architecture, distributed training, and algorithms related to large models. The project aims to explore and study system design in artificial intelligence and deep learning, with a focus on the hardware and software stack for building AI large model systems. It provides a comprehensive curriculum covering key topics such as system overview, AI computing clusters, communication and storage, cluster containers and cloud-native technologies, distributed training, distributed inference, large model algorithms and data, and applications of large models.
mcpd
mcpd is a tool developed by Mozilla AI to declaratively manage Model Context Protocol (MCP) servers, enabling consistent interface for defining and running tools across different environments. It bridges the gap between local development and enterprise deployment by providing secure secrets management, declarative configuration, and seamless environment promotion. mcpd simplifies the developer experience by offering zero-config tool setup, language-agnostic tooling, version-controlled configuration files, enterprise-ready secrets management, and smooth transition from local to production environments.

tensor-fusion
Tensor Fusion is a state-of-the-art GPU virtualization and pooling solution designed to optimize GPU cluster utilization. It offers features like fractional virtual GPU, remote GPU sharing, GPU-first scheduling, GPU oversubscription, GPU pooling, monitoring, live migration, and more. The tool aims to enhance GPU utilization efficiency and streamline AI infrastructure management for organizations.
llm-d-kv-cache-manager
Efficiently caching Key & Value (KV) tensors is crucial for optimizing LLM inference. Reusing the KV-Cache significantly improves Time To First Token (TTFT) and overall throughput, maximizing system resource-utilization. `llm-d-kv-cache-manager` is a pluggable service enabling KV-Cache Aware Routing for vLLM-based serving platforms, with a high-performance KV-Cache Indexer component tracking KV-Block locality across vLLM pods. It provides intelligent routing for optimal KV-cache-aware placement decisions.
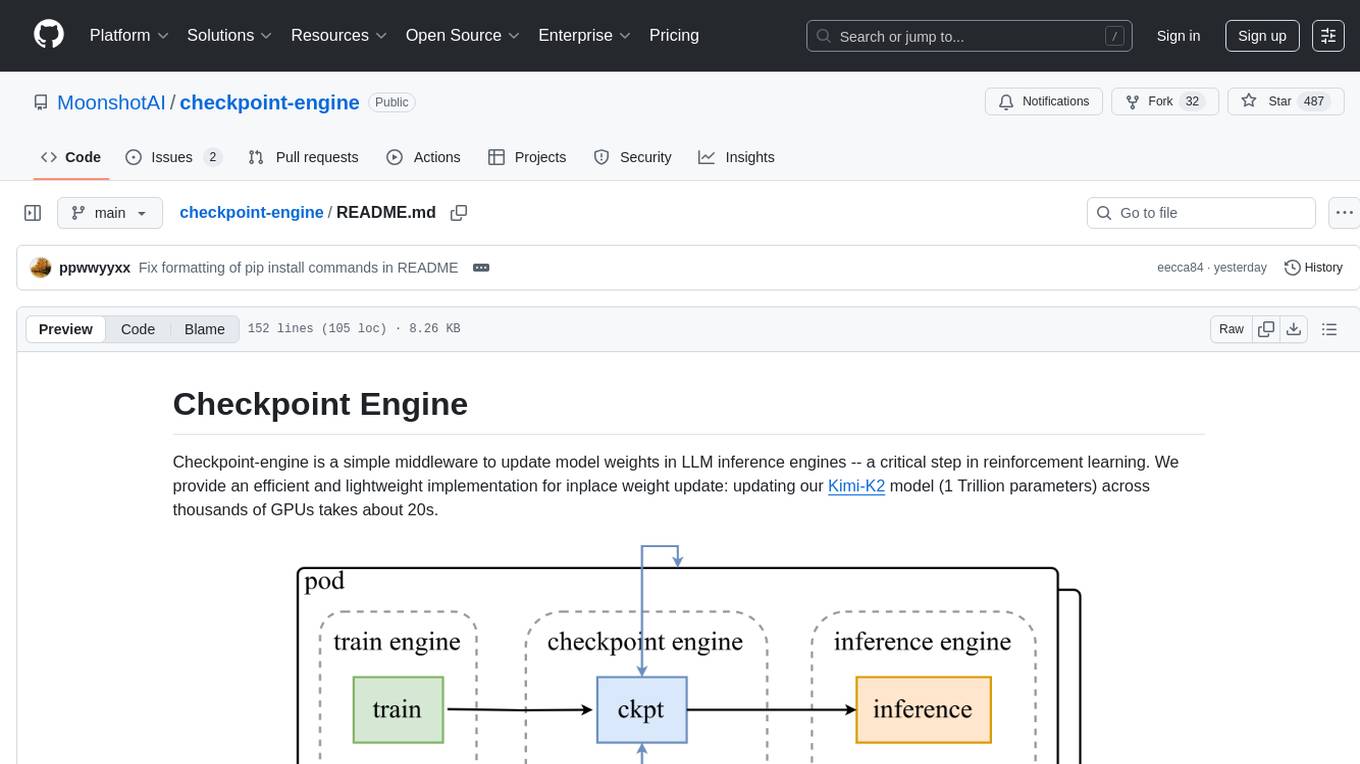
checkpoint-engine
Checkpoint-engine is a middleware tool designed for updating model weights in LLM inference engines efficiently. It provides implementations for both Broadcast and P2P weight update methods, orchestrating the transfer process and controlling the inference engine through ZeroMQ socket. The tool optimizes weight broadcast by arranging data transfer into stages and organizing transfers into a pipeline for performance. It supports flexible installation options and is tested with various models and device setups. Checkpoint-engine also allows reusing weights from existing instances and provides a patch for FP8 quantization in vLLM.
tiny-llm
tiny-llm is a course on LLM serving using MLX for system engineers. The codebase is focused on MLX array/matrix APIs to build model serving infrastructure from scratch and explore optimizations. The goal is to efficiently serve large language models like Qwen2 models. The course covers implementing components in Python, building an inference system similar to vLLM, and advanced topics on model interaction. The tool aims to provide hands-on experience in serving language models without high-level neural network APIs.

zeus
Zeus is a library for measuring the energy consumption of Deep Learning workloads and optimizing their energy consumption. It provides functionalities for energy and power measurement, time and energy optimization, device abstraction, utility functions, and more. Zeus is part of The ML.ENERGY Initiative and has been recognized in various research papers and conferences. It offers a Docker image with all dependencies, working examples for integration, and ongoing research to enhance its capabilities.
aiconfigurator
The `aiconfigurator` tool assists in finding a strong starting configuration for disaggregated serving in AI deployments. It helps optimize throughput at a given latency by evaluating thousands of configurations based on model, GPU count, and GPU type. The tool models LLM inference using collected data for a target machine and framework, running via CLI and web app. It generates configuration files for deployment with Dynamo, offering features like customized configuration, all-in-one automation, and tuning with advanced features. The tool estimates performance by breaking down LLM inference into operations, collecting operation execution times, and searching for strong configurations. Supported features include models like GPT and operations like attention, KV cache, GEMM, AllReduce, embedding, P2P, element-wise, MoE, MLA BMM, TRTLLM versions, and parallel modes like tensor-parallel and pipeline-parallel.
conduit
Conduit is an open-source, cross-platform mobile application for Open-WebUI, providing a native mobile experience for interacting with your self-hosted AI infrastructure. It supports real-time chat, model selection, conversation management, markdown rendering, theme support, voice input, file uploads, multi-modal support, secure storage, folder management, and tools invocation. Conduit offers multiple authentication flows and follows a clean architecture pattern with Riverpod for state management, Dio for HTTP networking, WebSocket for real-time streaming, and Flutter Secure Storage for credential management.
ai-performance-engineering
This repository is a comprehensive resource for AI Systems Performance Engineering, providing code examples, tools, and resources for GPU optimization, distributed training, inference scaling, and performance tuning. It covers a wide range of topics such as performance tuning mindset, system architecture, GPU programming, memory optimization, and the latest profiling tools. The focus areas include GPU architecture, PyTorch, CUDA programming, distributed training, memory optimization, and multi-node scaling strategies.
aikit
AIKit is a comprehensive platform for hosting, deploying, building, and fine-tuning large language models (LLMs). It offers inference using LocalAI, extensible fine-tuning interface, and OCI packaging for distributing models. AIKit supports various models, multi-modal model and image generation, Kubernetes deployment, and supply chain security. It can run on AMD64 and ARM64 CPUs, NVIDIA GPUs, and Apple Silicon (experimental). Users can quickly get started with AIKit without a GPU and access pre-made models. The platform is OpenAI API compatible and provides easy-to-use configuration for inference and fine-tuning.
llm-d-kv-cache
Efficiently caching Key & Value (KV) tensors is crucial for optimizing LLM inference. Reusing the KV-Cache significantly improves Time To First Token (TTFT) and overall throughput, maximizing system resource utilization. `llm-d-kv-cache` is a pluggable service for KV-Cache Aware Routing in vLLM-based serving platforms, providing comprehensive KV-Cache management capabilities. The repository includes the KV-Cache Indexer, a high-performance library for global KV-Cache block locality view across vLLM pods, powered by KVEvents for intelligent routing and optimal cache-aware placement decisions.
BharatMLStack
BharatMLStack is a comprehensive, production-ready machine learning infrastructure platform designed to democratize ML capabilities across India and beyond. It provides a robust, scalable, and accessible ML stack empowering organizations to build, deploy, and manage machine learning solutions at massive scale. It includes core components like Horizon, Trufflebox UI, Online Feature Store, Go SDK, Python SDK, and Numerix, offering features such as control plane, ML management console, real-time features, mathematical compute engine, and more. The platform is production-ready, cloud agnostic, and offers observability through built-in monitoring and logging.
paddler
Paddler is an open-source LLM load balancer and serving platform designed for digital products and users who prioritize privacy, reliability, cost control, and independence from closed-source model providers. It allows running inference, deploying, and scaling LLMs on personal infrastructure, offering a seamless developer experience. Key features include inference through llama.cpp engine, LLM-specific load balancing, dynamic model swapping, request buffering, and built-in web admin panel for management and monitoring. Paddler is suitable for product teams needing LLM inference, DevOps/LLMOps teams deploying LLMs at scale, organizations handling sensitive data, and product leaders aiming for predictable LLM costs and reliable model performance.

surogate
Surogate is a high-performance, mixed-precision LLM pre-training and fine-tuning framework designed for practical hardware limits. It combines a native C++/CUDA execution engine, a low-overhead Python frontend, and a highly optimized multi-threaded scheduler to achieve industry-leading Speed-Of-Light (SOL) utilization on NVIDIA GPUs. Surogate Studio is the no-code companion for enterprise-grade LLMOps, offering features like pre-training, fine-tuning, native multi-GPU and multi-Node training, smart CPU offloading, pre-built training recipes, mixed-precision training, and adaptive training. It supports various NVIDIA GPUs and provides a unified platform for managing AI infrastructure and operations.
20 - OpenAI Gpts
ML Engineer GPT
I'm a Python and PyTorch expert with knowledge of ML infrastructure requirements ready to help you build and scale your ML projects.
Architext
Architext is a sophisticated chatbot designed to guide users through the complexities of AWS architecture, leveraging the AWS Well-Architected Framework. It offers real-time, tailored advice, interactive learning, and up-to-date resources for both novices and experts in AWS cloud infrastructure.
Securia
AI-powered audit ally. Enhance cybersecurity effortlessly with intelligent, automated security analysis. Safe, swift, and smart.
Global Construction Oracle
Futuristic construction AI with interplanetary and nano-robotics integration
ethicallyHackingspace (eHs)® (IoN-A-SCP)™
Interactive on Network (IoN) Automation SCP (IoN-A-SCP)™ AI-copilot (BETA)
RailwayGPT
Technical expert on locomotives, trains, signalling, and railway technology. Can answer questions and draw designs specific to transportation domain.

Ryan Pollock GPT
🤖 AMAIA: ask Ryan's AI anything you'd ask the real Ryan 🧠 Deep Tech VP Marketing & Growth 🌥 Cloud Infrastructure, Databases, Machine Learning, APIs 🤖 Google Cloud, DigitalOcean, Oracle, Vultr, Android 🌁 More at linkedin.com/in/ryanpollock

AI Assistant for Writers and Creatives
Organize and develop ideas, respecting privacy and copyright laws.

AI Mentor
An AI advisor guiding your businesses in starting with AI, using some hand-picked resources.