
AIInfra
AIInfra(AI 基础设施)指AI系统从底层芯片等硬件,到上层软件栈支持AI大模型训练和推理。
Stars: 4601
AIInfra is an open-source project focused on AI infrastructure, specifically targeting large models in distributed clusters, distributed architecture, distributed training, and algorithms related to large models. The project aims to explore and study system design in artificial intelligence and deep learning, with a focus on the hardware and software stack for building AI large model systems. It provides a comprehensive curriculum covering key topics such as system overview, AI computing clusters, communication and storage, cluster containers and cloud-native technologies, distributed training, distributed inference, large model algorithms and data, and applications of large models.
README:
文字课程内容正在一节节补充更新,尽可能抽空继续更新正在 ![]() AIInfra,希望您多多鼓励和参与进来!!!
AIInfra,希望您多多鼓励和参与进来!!!
文字课程开源在 🍔 AIInfra,系列视频托管B 站 ZOMI 酱和 :yt: 油管 ZOMI6222,PPT 开源在 ![]() AIInfra,欢迎引用!
AIInfra,欢迎引用!
这个开源项目英文名字叫做 AIInfra,中文名字叫做 AI 基础设施。大模型是基于 AI 集群的全栈软硬件性能优化,通过最小的每一块 AI 芯片组成的 AI 集群,编译器使能到上层的 AI 框架,训练过程需要分布式并行、集群通信等算法支持,而且在大模型领域最近持续演进如智能体等新技术。
本开源课程主要是跟大家一起探讨和学习人工智能、深度学习的系统设计,而整个系统是围绕着 ZOMI 在工作当中所积累、梳理、构建 AI 大模型系统的基础软硬件栈,因此成为 AI 基础设施。希望跟所有关注 AI 开源课程的好朋友一起探讨研究,共同促进学习讨论。
与 AISystem[https://github.com/Infrasys-AI/AISystem] 项目最大的区别就是 AIInfra 项目主要针对大模型,特别是大模型在分布式集群、分布式架构、分布式训练、大模型算法等相关领域进行深度展开。

课程主要包括以下模块,内容陆续更新中,欢迎贡献:
| 序列 | 教程内容 | 简介 | 地址 |
|---|---|---|---|
| 00 | 🏁 大模型系统概述 | 系统梳理了大模型关键技术点,涵盖 Scaling Law 的多场景应用、训练与推理全流程技术栈、AI 系统与大模型系统的差异,以及未来趋势如智能体、多模态、轻量化架构和算力升级。 | Slides |
| 01 | 🏁 AI 计算集群 | 大模型虽然已经慢慢在端测设备开始落地,但是总体对云端的依赖仍然很重很重,AI 集群会介绍集群运维管理、集群性能、训练推理一体化拓扑流程等内容。 | Slides |
| 02 | 🏁 通信与存储 | 大模型训练和推理的过程中都严重依赖于网络通信,因此会重点介绍通信原理、网络拓扑、组网方案、高速互联通信的内容。存储则是会从节点内的存储到存储 POD 进行介绍。 | Slides |
| 03 | 🏁 集群容器与云原生 | 讲解容器与 K8S 技术原理及 AI 模型部署实践,涵盖容器基础、Docker 与 K8S 核心概念、集群搭建、AI 应用部署、任务调度、资源管理、可观测性、高可靠设计等云原生与大模型结合的关键技术点。 | Slides |
| 04 | 🏁 分布式训练 | 大模型训练是通过大量数据和计算资源,利用 Transformer 架构优化模型参数,使其能够理解和生成自然语言、图像等内容,广泛应用于对话系统、文本生成、图像识别等领域。 | Slides |
| 05 | 🏁 分布式推理 | 大模型推理核心工作是优化模型推理,实现推理加速,其中模型推理最核心的部分是 Transformer Block。本节会重点探讨大模型推理的算法、调度策略和输出采样等相关算法。 | Slides |
| 06 | 🏁 大模型算法与数据 | Transformer 起源于 NLP 领域,近期统治了 CV/NLP/多模态的大模型,我们将深入地探讨 Scaling Law 背后的原理。在大模型算法背后数据和算法的评估也是核心的内容之一,如何实现 Prompt 和通过 Prompt 提升模型效果。 | Slides |
| 07 | 🏁 大模型应用 | 当前大模型技术已进入快速迭代期。这一时期的显著特点就是技术的更新换代速度极快,新算法、新模型层出不穷。因此本节内容将会紧跟大模型的时事内容,进行深度技术分析。 | Slides |
系统梳理了大模型关键技术点,涵盖 Scaling Law 的多场景应用、训练与推理全流程技术栈、AI 系统与大模型系统的差异,以及未来趋势如智能体、多模态、轻量化架构和算力升级。
| 大纲 | 小结 | 链接 | 状态 |
|---|---|---|---|
| 概述 | 01. Scaling Law 整体解读 | Markdown, 文章 | ⭕ |
| 概述 | 02. Standard Scaling Law | Markdown, 文章 | ✅ |
| 概述 | 03. Inference Time Scaling Law | Markdown, 文章 | ⭕ |
| 概述 | 04. 大模型训练与 AI Infra 的关系分析 | Markdown, 文章 | ✅ |
| 概述 | 05. 大模型推理与 AI Infra 的关系分析 | Markdown, 文章 | ✅ |
| 概述 | 06. AI Infra 核心逻辑与行业趋势 | Markdown, 文章 | ✅ |
AI 集群架构演进、万卡集群方案、性能建模与优化,GPU/NPU 精度差异及定位方法。
| 编号 | 名称 | 具体内容 | 状态 |
|---|---|---|---|
| 1 | 计算集群之路 | 高性能计算集群发展与万卡 AI 集群建设及机房基础设施挑战 | ✅ |
| 2 | L0/L1 AI 集群基建 | 服务器节点的基础知识、散热技术的发展与实践 | ✅ |
| 3 | 万卡 AI 集群 | 围绕万卡 AI 集群从存算网络协同、快速交付与紧张工期等挑战 | ✅ |
| 4 | 集群性能分析 | 集群性能指标分析、建模与常见问题定位方法解析 | ⭕ |
| 大纲 | 小节 | 链接 | 状态 |
|---|---|---|---|
| 💖 | 🌟 | 💖 | |
| 性能 实践 💻 | CODE 01: 拆解 Transformer-Decoder | Markdown, Jupyter, 文章 | ✅ |
| 性能 实践 💻 | CODE 02: MOE 参数量和计算量 | Markdown, Jupyter, 文章 | ✅ |
| 性能 实践 💻 | CODE 03: MFU 模型利用率评估 | Markdown, Jupyter, 文章 | ✅ |
通信与存储篇:AI 集群组网技术、高速互联方案、集合通信原理与优化、存储系统设计及大模型挑战。
| 编号 | 名称 | 具体内容 | 状态 |
|---|---|---|---|
| 1 | 集群组网之路 | AI 集群组网架构设计与高速互联技术解析 | ✅ |
| 2 | 网络通信进阶 | 网络通信技术进阶:高速互联、拓扑算法与拥塞控制解析 | ⭕ |
| 3 | 集合通信原理 | 通信域、通信算法、集合通信原语 | ✅ |
| 4 | 集合通信库 | 集合通信库技术解析:MPI、NCCL 与 HCCL 架构及算法原理 | ✅ |
| 5 | 集群存储之路 | 数据存储、CheckPoint 梯度检查点等存储与大模型结合的相关技术 | ✅ |
AI 集群云原生篇:容器技术、K8S 编排、AI 云平台与任务调度,提升集群资源管理与应用部署效率。
| 编号 | 名称 | 具体内容 |
|---|---|---|
| 1 | 容器时代 | 容器技术基础与云原生架构解析,结合分布式训练应用实践 |
| 2 | 容器初体验 | Docker 与 K8S 基础原理及实战,涵盖容器技术与集群管理架构解析 |
| 3 | 深入 K8S | K8S 核心机制深度解析:编排、存储、网络、调度与监控实践 |
| 4 | AI 云平台 | AI 云平台演进与云原生架构解析,涵盖持续交付与智能化运维实践 |
大模型训练全解析:并行策略、加速算法、微调与评估,覆盖训练到优化的完整流程。
| 编号 | 名称 | 具体内容 |
|---|---|---|
| 1 | 4.1 分布式并行基础 | 分布式并行的策略分类、模型适配与硬件资源优化对比 |
| 2 | 4.2 大模型并行进阶 | Megatron、DeepSeed 架构解析、MoE 扩展与高效训练策略 |
| 3 | 4.3 大模型训练加速 | 大模型训练加速在算法优化、内存管理与通算融合策略解析 |
| 4 | 4.4 后训练与强化学习 | 后训练与强化学习算法对比、框架解析与工程实践 |
| 5 | 4.5 大模型微调 SFT | 大模型微调算法原理、变体优化与多模态实践 |
| 6 | 4.6 大模型验证评估 | 大模型评估、基准测试与统一框架解析 |
| 大纲 | 小节 | 链接 | 状态 |
|---|---|---|---|
| 分布式并行 | 01 分布式并行框架介绍 | PPT, 视频 | |
| 分布式并行 | 02 DeepSpeed 介绍 | PPT, 视频 | |
| 并行 实践 💻 | CODE 01: 从零构建 PyTorch DDP | Markdown, Jupyter, 文章 | ✅ |
| 并行 实践 💻 | CODE 02: PyTorch 实现模型并行 | Markdown, Jupyter, 文章 | ✅ |
| 大纲 | 小节 | 链接 | 状态 |
|---|---|---|---|
| 分布式并行 | 01 优化器并行 ZeRO1/2/3 原理 | PPT, 视频 | |
| 分布式并行 | 02 Megatron-LM 代码概览 | PPT, 视频 | |
| 分布式并行 | 03 大模型并行与 GPU 集群配置 | PPT, 视频 | |
| 分布式并行 | 04 Megatron-LM TP 原理 | PPT, 视频 | |
| 分布式并行 | 05 Megatron-LM TP 代码解析 | PPT, 视频 | |
| 分布式并行 | 06 Megatron-LM SP 代码解析 | PPT, 视频 | |
| 分布式并行 | 07 Megatron-LM PP 基本原理 | PPT, 视频 | |
| 分布式并行 | 08 流水并行 1F1B/1F1B Interleaved 原理 | PPT, 视频 | |
| 分布式并行 | 09 Megatron-LM 流水并行 PP 代码解析 | PPT, 视频 | |
| 💖 | 🌟 | 💖 | |
| 并行 实践 💻 | CODE 01: ZeRO 显存优化实践 | Markdown, Jupyter, 文章 | ✅ |
| 并行 实践 💻 | CODE 02: Megatron 张量并行复现 | Markdown, Jupyter, 文章 | ✅ |
| 并行 实践 💻 | CODE 03: Pipeline 并行实践 | Markdown, Jupyter, 文章 | ✅ |
| 并行 实践 💻 | CODE 04: 专家并行大规模训练 | Markdown, Jupyter, 文章 | ✅ |
| 大纲 | 小节 | 链接 | 状态 |
|---|---|---|---|
| 大模型训练加速 | PPT, 文章, 视频 | ||
| 💖 | 🌟 | 💖 | |
| 并行 实践 💻 | CODE 01: Flash Attention 实现 | Markdown, Jupyter, 文章 | ✅ |
| 并行 实践 💻 | CODE 02: 梯度检查点内存优化 | Markdown, Jupyter, 文章 | ✅ |
| 并行 实践 💻 | CODE 03: FP8 混合精度训练 | Markdown, Jupyter, 文章 | ✅ |
| 并行 实践 💻 | CODE 04: Ring Attention 实践 | Markdown, Jupyter, 文章 | ✅ |
| 大纲 | 小节 | 链接 | 状态 |
|---|---|---|---|
| PPT, 文章, 视频 | |||
| 💖 | 🌟 | 💖 | |
| RL 实践 💻 | CODE 01: 经典 InstructGPT 复现 | Markdown, Jupyter, 文章 | ✅ |
| RL 实践 💻 | CODE 02: DPO 与 PPO 在 LLM 对比 | Markdown, Jupyter, 文章 | ✅ |
| RL 实践 💻 | CODE 03: LLM + GRPO 实践 | Markdown, Jupyter, 文章 | ✅ |
| 大纲 | 小节 | 链接 | 状态 |
|---|---|---|---|
| PPT, 文章, 视频 | |||
| 💖 | 🌟 | 💖 | |
| SFT 实践 💻 | CODE 01: Qwen3-4B 模型微调 | Markdown, Jupyter, 文章 | ✅ |
| SFT 实践 💻 | CODE 02: LoRA 微调 SD | Markdown, Jupyter, 文章 | ✅ |
| 大纲 | 小节 | 链接 | 状态 |
|---|---|---|---|
| PPT, 文章, 视频 | |||
| 💖 | 🌟 | 💖 | |
| EVA 实践 💻 | CODE 01: OpenCompass 评估实践 | Markdown, Jupyter, 文章 | ✅ |
大模型推理全解析:加速技术、架构优化、长序列处理与压缩方案,覆盖推理全流程与实战实践。
| 编号 | 名称 | 具体内容 |
|---|---|---|
| 1 | 5.1 基本概念 | 大模型推理流程、框架对比与性能指标解析 |
| 2 | 5.2 大模型推理加速 | 大模型推理加速中 KV 缓存优化、算子改进与高效引擎解析 |
| 3 | 5.3 架构调度加速 | 架构调度加速中缓存优化、批处理与分布式系统调度解析 |
| 4 | 5.4 长序列推理 | 长序列推理算法优化、并行策略与高效生成方法解析 |
| 5 | 5.5 输出采样 | 推理输出采样的基础方法、加速策略与 MOE 推理优化 |
| 6 | 5.6 大模型压缩 | 低精度量化、知识蒸馏与高效推理优化解析 |
🚩 5.1 基本概念
大模型算法与数据全览:Transformer 架构、MoE 创新、多模态模型与数据工程全流程实践。
| 编号 | 名称 | 具体内容 | 状态 |
|---|---|---|---|
| 1 | Transformer 架构 | Transformer 架构原理深度介绍 | ✅ |
| 2 | MoE 架构 | MoE(Mixture of Experts) 混合专家模型架构原理与细节实现 | ✅ |
| 3 | 创新架构 | SSM、MMABA、RWKV、Linear Transformer、JPEA 等新大模型结构 | ⭕ |
| 4 | 图文生成与理解 | 多模态对齐、生成、理解及统一多模态架构解析 | ⭕ |
| 5 | 视频大模型 | 视频多模态理解与生成方法演进及 Flow Matching 应用 | ⭕ |
| 6 | 语音大模型 | 语音多模态识别、合成与端到端模型演进及推理应用 | ⭕ |
| 7 | 数据工程 | 数据工程、Prompt Engine 等相关技术 | ⭕ |
| 大纲 | 小节 | 链接 | 状态 |
|---|---|---|---|
| Transformer 架构 | 01 Transformer 基础结构 | PPT, 视频, 文章 | ✅ |
| Transformer 架构 | 02 大模型 Tokenizer 算法 | PPT, 视频, 文章 | ✅ |
| Transformer 架构 | 03 大模型 Embedding 算法 | PPT, 视频, 文章 | ✅ |
| Transformer 架构 | 04 Attention 注意力机制 | PPT, 视频, 文章 | ✅ |
| Transformer 架构 | 05 Attention 变种算法 | PPT, 视频, 文章 | ✅ |
| Transformer 架构 | 06 Transformer 长序列架构 | PPT, 视频, 文章 | ✅ |
| Transformer 架构 | 07 大模型参数设置 | PPT, 视频, 文章 | ✅ |
| 💖 | 🌟 | 💖 | |
| Transformer 实践 💻 | 01 搭建迷你 Transformer | Markdown, Jupyter | ✅ |
| Transformer 实践 💻 | 02 从零实现 Transformer 训练 | Markdown, Jupyter | ✅ |
| Transformer 实践 💻 | 03 实战 Transformer 机器翻译 | Markdown, Jupyter | ✅ |
| Transformer 实践 💻 | 04 手把手实现核心机制 Sinusoidal 编码 | Markdown, Jupyter | ✅ |
| Transformer 实践 💻 | 05 手把手实现核心机制 BPE 分词算法 | Markdown, Jupyter | ✅ |
| Transformer 实践 💻 | 06 手把手实现核心机制 Embedding 词嵌入 | Markdown, Jupyter | ✅ |
| Transformer 实践 💻 | 07 深入注意力机制 MHA、MQA、GQA、MLA | Markdown, Jupyter | ✅ |
| 大纲 | 小节 | 链接 | 状态 |
|---|---|---|---|
| MOE 基本介绍 | 01 MOE 架构剖析 | PPT, 视频, 文章 | ✅ |
| MOE 前世今生 | 02 MOE 前世今生 | PPT, 视频, 文章 | ✅ |
| MOE 核心论文 | 03 MOE 奠基论文 | PPT, 视频, 文章 | ✅ |
| MOE 核心论文 | 04 MOE 初遇 RNN | PPT, 视频, 文章 | ✅ |
| MOE 核心论文 | 05 GSard 解读 | PPT, 视频, 文章 | ✅ |
| MOE 核心论文 | 06 Switch Trans 解读 | PPT, 视频, 文章 | ✅ |
| MOE 核心论文 | 07 GLaM & ST-MOE 解读 | PPT, 视频, 文章 | ✅ |
| MOE 核心论文 | 08 DeepSeek MOE 解读 | PPT, 视频, 文章 | ✅ |
| MOE 架构原理 | 09 MOE 模型可视化 | PPT, 视频, 文章 | ✅ |
| 大模型遇 MOE | 10 MoE 参数与专家 | PPT, 视频, 文章 | ✅ |
| 手撕 MOE 代码 | 11 单机单卡 MoE | PPT, 视频 | ✅ |
| 手撕 MOE 代码 | 12 单机多卡 MoE | PPT, 视频 | ✅ |
| 视觉 MoE | 13 视觉 MoE 模型 | PPT, 视频, 文章 | ✅ |
| 💖 | 🌟 | 💖 | |
| MOE 实践 💻 | 01 基于 HF 实现 MOE 推理 | Markdown, Jupyter | ✅ |
| MOE 实践 💻 | 02 从零开始手撕 MoE | Markdown, Jupyter | ✅ |
| MOE 实践 💻 | 03 MoE 从原理到分布式实现 | Markdown, Jupyter | ✅ |
| MOE 实践 💻 | 04 MoE 分布式性能分析 | Markdown, Jupyter | ✅ |
大模型应用篇:AI Agent 技术、RAG 检索增强生成与 GraphRAG,推动智能体与知识增强应用落地。
| 编号 | 名称 | 具体内容 |
|---|---|---|
| 00 | 大模型热点 | OpenAI、WWDC、GTC 等大会技术洞察 |
| 01 | Agent 简单概念 | AI Agent 智能体的原理、架构 |
| 02 | Agent 核心技术 | 深入 AI Agent 原理和核心 |
| 03 | 检索增强生成(RAG) | 检索增强生成技术的介绍 |
| 04 | 自动驾驶 | 端到端自动驾驶技术原理解析,萝卜快跑对产业带来的变化 |
| 05 | 具身智能 | 关于对具身智能的技术原理、具身架构和产业思考 |
| 06 | 生成推荐 | 推荐领域的革命发展历程,大模型迎来了生成式推荐新的增长 |
| 07 | AI 安全 | 隐私计算发展过程,隐私计算未来发展如何? |
| 08 | AI 历史十年 | 过去十年 AI 大事件回顾,2012 到 2025 从模型、算法、芯片硬件发展 |

Considering contibuting to AIInfra? To get started, please take a moment to read the CONTRIBUTING.md guide.
Join Aim contributors by submitting your first pull request. Happy coding! 😊
Made with contrib.rocks.
这个仓已经到达疯狂的 10G 啦(ZOMI 把所有制作过程、高清图片都原封不动提供),如果你要 git clone 会非常的慢,因此建议优先到 Releases · chenzomi12/AIInfra 来下载你需要的内容!
请大家尊重开源和 ZOMI 和贡献者的努力,引用 PPT 的内容请规范转载标明出处哦!
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for AIInfra
Similar Open Source Tools
AIInfra
AIInfra is an open-source project focused on AI infrastructure, specifically targeting large models in distributed clusters, distributed architecture, distributed training, and algorithms related to large models. The project aims to explore and study system design in artificial intelligence and deep learning, with a focus on the hardware and software stack for building AI large model systems. It provides a comprehensive curriculum covering key topics such as system overview, AI computing clusters, communication and storage, cluster containers and cloud-native technologies, distributed training, distributed inference, large model algorithms and data, and applications of large models.
Awesome-AGI
Awesome-AGI is a curated list of resources related to Artificial General Intelligence (AGI), including models, pipelines, applications, and concepts. It provides a comprehensive overview of the current state of AGI research and development, covering various aspects such as model training, fine-tuning, deployment, and applications in different domains. The repository also includes resources on prompt engineering, RLHF, LLM vocabulary expansion, long text generation, hallucination mitigation, controllability and safety, and text detection. It serves as a valuable resource for researchers, practitioners, and anyone interested in the field of AGI.
AIInfra
AIInfra is an open-source project focused on AI infrastructure, specifically targeting large models in distributed clusters, distributed architecture, distributed training, and algorithms related to large models. The project aims to explore and study system design in artificial intelligence and deep learning, with a focus on the hardware and software stack for building AI large model systems. It provides a comprehensive curriculum covering topics such as AI chip principles, communication and storage, AI clusters, large model training, and inference, as well as algorithms for large models. The course is designed for undergraduate and graduate students, as well as professionals working with AI large model systems, to gain a deep understanding of AI computer system architecture and design.
PaddleScience
PaddleScience is a scientific computing suite developed based on the deep learning framework PaddlePaddle. It utilizes the learning ability of deep neural networks and the automatic (higher-order) differentiation mechanism of PaddlePaddle to solve problems in physics, chemistry, meteorology, and other fields. It supports three solving methods: physics mechanism-driven, data-driven, and mathematical fusion, and provides basic APIs and detailed documentation for users to use and further develop.

adata
AData is a free and open-source A-share database that focuses on transaction-related data. It provides comprehensive data on stocks, including basic information, market data, and sentiment analysis. AData is designed to be easy to use and integrate with other applications, making it a valuable tool for quantitative trading and AI training.
yudao-ui-admin-vue3
The yudao-ui-admin-vue3 repository is an open-source project focused on building a fast development platform for developers in China. It utilizes Vue3 and Element Plus to provide features such as configurable themes, internationalization, dynamic route permission generation, common component encapsulation, and rich examples. The project supports the latest front-end technologies like Vue3 and Vite4, and also includes tools like TypeScript, pinia, vueuse, vue-i18n, vue-router, unocss, iconify, and wangeditor. It offers a range of development tools and features for system functions, infrastructure, workflow management, payment systems, member centers, data reporting, e-commerce systems, WeChat public accounts, ERP systems, and CRM systems.
so-vits-models
This repository collects various LLM, AI-related models, applications, and datasets, including LLM-Chat for dialogue models, LLMs for large models, so-vits-svc for sound-related models, stable-diffusion for image-related models, and virtual-digital-person for generating videos. It also provides resources for deep learning courses and overviews, AI competitions, and specific AI tasks such as text, image, voice, and video processing.
indie-hacker-tools-plus
Indie Hacker Tools Plus is a curated repository of essential tools and technology stacks for independent developers. The repository aims to help developers enhance efficiency, save costs, and mitigate risks by using popular and validated tools. It provides a collection of tools recognized by the industry to empower developers with the most refined technical support. Developers can contribute by submitting articles, software, or resources through issues or pull requests.

kumo-search
Kumo search is an end-to-end search engine framework that supports full-text search, inverted index, forward index, sorting, caching, hierarchical indexing, intervention system, feature collection, offline computation, storage system, and more. It runs on the EA (Elastic automic infrastructure architecture) platform, enabling engineering automation, service governance, real-time data, service degradation, and disaster recovery across multiple data centers and clusters. The framework aims to provide a ready-to-use search engine framework to help users quickly build their own search engines. Users can write business logic in Python using the AOT compiler in the project, which generates C++ code and binary dynamic libraries for rapid iteration of the search engine.
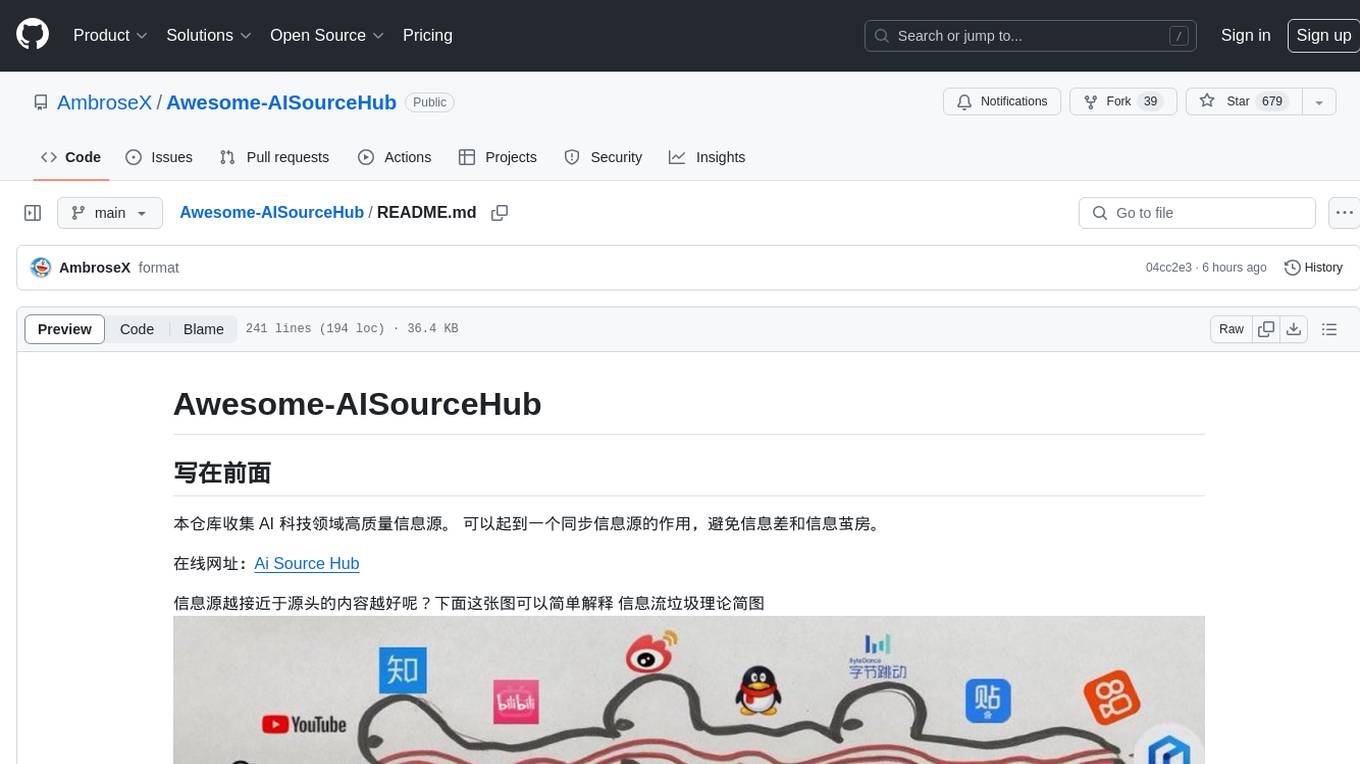
Awesome-AISourceHub
Awesome-AISourceHub is a repository that collects high-quality information sources in the field of AI technology. It serves as a synchronized source of information to avoid information gaps and information silos. The repository aims to provide valuable resources for individuals such as AI book authors, enterprise decision-makers, and tool developers who frequently use Twitter to share insights and updates related to AI advancements. The platform emphasizes the importance of accessing information closer to the source for better quality content. Users can contribute their own high-quality information sources to the repository by following specific steps outlined in the contribution guidelines. The repository covers various platforms such as Twitter, public accounts, knowledge planets, podcasts, blogs, websites, YouTube channels, and more, offering a comprehensive collection of AI-related resources for individuals interested in staying updated with the latest trends and developments in the AI field.
linktre-tools
The 'linktre-tools' repository is a collection of tools and resources for independent developers, AI products, cross-border e-commerce, and self-media office assistance. It aims to provide a curated list of tools and products in these areas. Users are encouraged to contribute by submitting pull requests and raising issues for continuous updates. The repository covers a wide range of topics including AI tools, independent development tools, popular AI products, tools for web development, online tools, media operations, and cross-border e-commerce resources.

carrot
The 'carrot' repository on GitHub provides a list of free and user-friendly ChatGPT mirror sites for easy access. The repository includes sponsored sites offering various GPT models and services. Users can find and share sites, report errors, and access stable and recommended sites for ChatGPT usage. The repository also includes a detailed list of ChatGPT sites, their features, and accessibility options, making it a valuable resource for ChatGPT users seeking free and unlimited GPT services.
teaching-boyfriend-llm
The 'teaching-boyfriend-llm' repository contains study notes on LLM (Large Language Models) for the purpose of advancing towards AGI (Artificial General Intelligence). The notes are a collaborative effort towards understanding and implementing LLM technology.
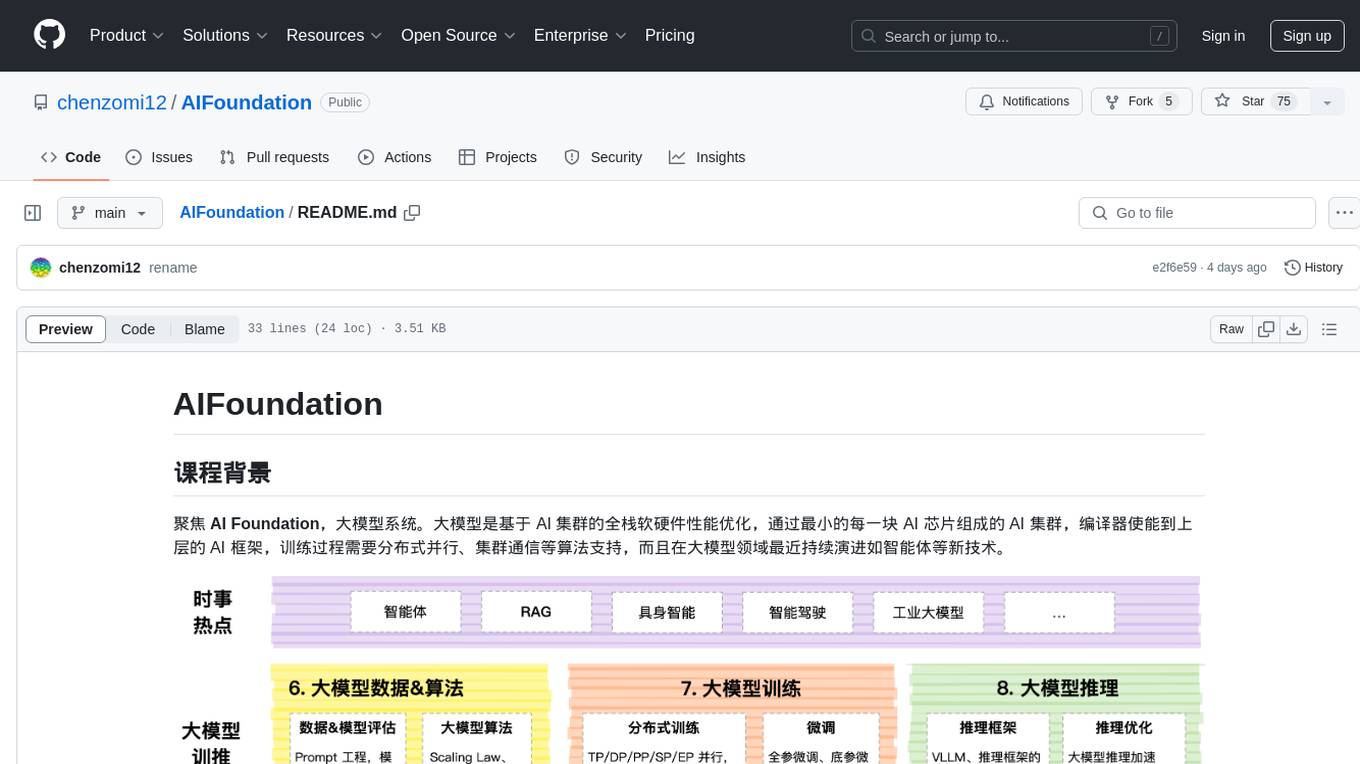
AIFoundation
AIFoundation focuses on AI Foundation, large model systems. Large models optimize the performance of full-stack hardware and software based on AI clusters. The training process requires distributed parallelism, cluster communication algorithms, and continuous evolution in the field of large models such as intelligent agents. The course covers modules like AI chip principles, communication & storage, AI clusters, computing architecture, communication architecture, large model algorithms, training, inference, and analysis of hot technologies in the large model field.
awesome-hosting
awesome-hosting is a curated list of hosting services sorted by minimal plan price. It includes various categories such as Web Services Platform, Backend-as-a-Service, Lambda, Node.js, Static site hosting, WordPress hosting, VPS providers, managed databases, GPU cloud services, and LLM/Inference API providers. Each category lists multiple service providers along with details on their minimal plan, trial options, free tier availability, open-source support, and specific features. The repository aims to help users find suitable hosting solutions based on their budget and requirements.
For similar tasks

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.

zep-python
Zep is an open-source platform for building and deploying large language model (LLM) applications. It provides a suite of tools and services that make it easy to integrate LLMs into your applications, including chat history memory, embedding, vector search, and data enrichment. Zep is designed to be scalable, reliable, and easy to use, making it a great choice for developers who want to build LLM-powered applications quickly and easily.

AI-in-a-Box
AI-in-a-Box is a curated collection of solution accelerators that can help engineers establish their AI/ML environments and solutions rapidly and with minimal friction, while maintaining the highest standards of quality and efficiency. It provides essential guidance on the responsible use of AI and LLM technologies, specific security guidance for Generative AI (GenAI) applications, and best practices for scaling OpenAI applications within Azure. The available accelerators include: Azure ML Operationalization in-a-box, Edge AI in-a-box, Doc Intelligence in-a-box, Image and Video Analysis in-a-box, Cognitive Services Landing Zone in-a-box, Semantic Kernel Bot in-a-box, NLP to SQL in-a-box, Assistants API in-a-box, and Assistants API Bot in-a-box.

NeMo
NeMo Framework is a generative AI framework built for researchers and pytorch developers working on large language models (LLMs), multimodal models (MM), automatic speech recognition (ASR), and text-to-speech synthesis (TTS). The primary objective of NeMo is to provide a scalable framework for researchers and developers from industry and academia to more easily implement and design new generative AI models by being able to leverage existing code and pretrained models.
E2B
E2B Sandbox is a secure sandboxed cloud environment made for AI agents and AI apps. Sandboxes allow AI agents and apps to have long running cloud secure environments. In these environments, large language models can use the same tools as humans do. For example: * Cloud browsers * GitHub repositories and CLIs * Coding tools like linters, autocomplete, "go-to defintion" * Running LLM generated code * Audio & video editing The E2B sandbox can be connected to any LLM and any AI agent or app.

floneum
Floneum is a graph editor that makes it easy to develop your own AI workflows. It uses large language models (LLMs) to run AI models locally, without any external dependencies or even a GPU. This makes it easy to use LLMs with your own data, without worrying about privacy. Floneum also has a plugin system that allows you to improve the performance of LLMs and make them work better for your specific use case. Plugins can be used in any language that supports web assembly, and they can control the output of LLMs with a process similar to JSONformer or guidance.

dify
Dify is an open-source LLM app development platform that combines AI workflow, RAG pipeline, agent capabilities, model management, observability features, and more. It allows users to quickly go from prototype to production. Key features include: 1. Workflow: Build and test powerful AI workflows on a visual canvas. 2. Comprehensive model support: Seamless integration with hundreds of proprietary / open-source LLMs from dozens of inference providers and self-hosted solutions. 3. Prompt IDE: Intuitive interface for crafting prompts, comparing model performance, and adding additional features. 4. RAG Pipeline: Extensive RAG capabilities that cover everything from document ingestion to retrieval. 5. Agent capabilities: Define agents based on LLM Function Calling or ReAct, and add pre-built or custom tools. 6. LLMOps: Monitor and analyze application logs and performance over time. 7. Backend-as-a-Service: All of Dify's offerings come with corresponding APIs for easy integration into your own business logic.
For similar jobs

llm-resource
llm-resource is a comprehensive collection of high-quality resources for Large Language Models (LLM). It covers various aspects of LLM including algorithms, training, fine-tuning, alignment, inference, data engineering, compression, evaluation, prompt engineering, AI frameworks, AI basics, AI infrastructure, AI compilers, LLM application development, LLM operations, AI systems, and practical implementations. The repository aims to gather and share valuable resources related to LLM for the community to benefit from.

LitServe
LitServe is a high-throughput serving engine designed for deploying AI models at scale. It generates an API endpoint for models, handles batching, streaming, and autoscaling across CPU/GPUs. LitServe is built for enterprise scale with a focus on minimal, hackable code-base without bloat. It supports various model types like LLMs, vision, time-series, and works with frameworks like PyTorch, JAX, Tensorflow, and more. The tool allows users to focus on model performance rather than serving boilerplate, providing full control and flexibility.

how-to-optim-algorithm-in-cuda
This repository documents how to optimize common algorithms based on CUDA. It includes subdirectories with code implementations for specific optimizations. The optimizations cover topics such as compiling PyTorch from source, NVIDIA's reduce optimization, OneFlow's elementwise template, fast atomic add for half data types, upsample nearest2d optimization in OneFlow, optimized indexing in PyTorch, OneFlow's softmax kernel, linear attention optimization, and more. The repository also includes learning resources related to deep learning frameworks, compilers, and optimization techniques.

aiac
AIAC is a library and command line tool to generate Infrastructure as Code (IaC) templates, configurations, utilities, queries, and more via LLM providers such as OpenAI, Amazon Bedrock, and Ollama. Users can define multiple 'backends' targeting different LLM providers and environments using a simple configuration file. The tool allows users to ask a model to generate templates for different scenarios and composes an appropriate request to the selected provider, storing the resulting code to a file and/or printing it to standard output.

ENOVA
ENOVA is an open-source service for Large Language Model (LLM) deployment, monitoring, injection, and auto-scaling. It addresses challenges in deploying stable serverless LLM services on GPU clusters with auto-scaling by deconstructing the LLM service execution process and providing configuration recommendations and performance detection. Users can build and deploy LLM with few command lines, recommend optimal computing resources, experience LLM performance, observe operating status, achieve load balancing, and more. ENOVA ensures stable operation, cost-effectiveness, efficiency, and strong scalability of LLM services.

jina
Jina is a tool that allows users to build multimodal AI services and pipelines using cloud-native technologies. It provides a Pythonic experience for serving ML models and transitioning from local deployment to advanced orchestration frameworks like Docker-Compose, Kubernetes, or Jina AI Cloud. Users can build and serve models for any data type and deep learning framework, design high-performance services with easy scaling, serve LLM models while streaming their output, integrate with Docker containers via Executor Hub, and host on CPU/GPU using Jina AI Cloud. Jina also offers advanced orchestration and scaling capabilities, a smooth transition to the cloud, and easy scalability and concurrency features for applications. Users can deploy to their own cloud or system with Kubernetes and Docker Compose integration, and even deploy to JCloud for autoscaling and monitoring.

vidur
Vidur is a high-fidelity and extensible LLM inference simulator designed for capacity planning, deployment configuration optimization, testing new research ideas, and studying system performance of models under different workloads and configurations. It supports various models and devices, offers chrome trace exports, and can be set up using mamba, venv, or conda. Users can run the simulator with various parameters and monitor metrics using wandb. Contributions are welcome, subject to a Contributor License Agreement and adherence to the Microsoft Open Source Code of Conduct.

AI-System-School
AI System School is a curated list of research in machine learning systems, focusing on ML/DL infra, LLM infra, domain-specific infra, ML/LLM conferences, and general resources. It provides resources such as data processing, training systems, video systems, autoML systems, and more. The repository aims to help users navigate the landscape of AI systems and machine learning infrastructure, offering insights into conferences, surveys, books, videos, courses, and blogs related to the field.