
AIInfra
AIInfra(AI 基础设施)指AI系统从底层芯片等硬件,到上层软件栈支持AI大模型训练和推理。
Stars: 1493
AIInfra is an open-source project focused on AI infrastructure, specifically targeting large models in distributed clusters, distributed architecture, distributed training, and algorithms related to large models. The project aims to explore and study system design in artificial intelligence and deep learning, with a focus on the hardware and software stack for building AI large model systems. It provides a comprehensive curriculum covering topics such as AI chip principles, communication and storage, AI clusters, large model training, and inference, as well as algorithms for large models. The course is designed for undergraduate and graduate students, as well as professionals working with AI large model systems, to gain a deep understanding of AI computer system architecture and design.
README:
文字课程内容正在一节节补充更新,尽可能抽空继续更新正在 AIInfra,希望您多多鼓励和参与进来!!!
文字课程开源在 AISys,系列视频托管B 站 ZOMI 酱和油管 ZOMI6222,PPT 开源在 AIInfra,欢迎取用!!!
这个开源项目英文名字叫做AIInfra,中文名字叫做AI基础设施。大模型是基于 AI 集群的全栈软硬件性能优化,通过最小的每一块 AI 芯片组成的 AI 集群,编译器使能到上层的 AI 框架,训练过程需要分布式并行、集群通信等算法支持,而且在大模型领域最近持续演进如智能体等新技术。
本开源课程主要是跟大家一起探讨和学习人工智能、深度学习的系统设计,而整个系统是围绕着 ZOMI 在工作当中所积累、梳理、构建 AI 大模型系统的基础软硬件栈,因此成为 AI 基础设施。希望跟所有关注 AI 开源课程的好朋友一起探讨研究,共同促进学习讨论。
与AISystem[https://github.com/chenzomi12/AISystem] 项目最大的区别就是 AIInfra 项目主要针对大模型,特别是大模型在分布式集群、分布式架构、分布式训练、大模型算法等相关领域进行深度展开。

课程主要包括以下模块,内容陆续更新中,欢迎贡献:
| 序列 | 教程内容 | 简介 | 地址 | 状态 |
|---|---|---|---|---|
| 01 | AI 芯片原理 | AI 芯片主要介绍 AI 的硬件体系架构,包括从芯片基础到 AI 芯片的原理与架构,芯片设计需要考虑 AI 算法与编程体系,以应对 AI 快速的发展。 | [Slides] | DONE |
| 02 | 通信与存储 | 大模型训练和推理的过程中都严重依赖于网络通信,因此会重点介绍通信原理、网络拓扑、组网方案、高速互联通信的内容。存储则是会从节点内的存储到存储 POD 进行介绍。 | [Slides] | DONE |
| 03 | AI 集群 | 大模型虽然已经慢慢在端测设备开始落地,但是总体对云端的依赖仍然很重很重,AI 集群会介绍集群运维管理、集群性能、训练推理一体化拓扑流程等内容。 | [Slides] | 待更 |
| 04 | 大模型训练 | 大模型训练是通过大量数据和计算资源,利用 Transformer 架构优化模型参数,使其能够理解和生成自然语言、图像等内容,广泛应用于对话系统、文本生成、图像识别等领域。 | [Slides] | 更新中 |
| 05 | 大模型推理 | 大模型推理核心工作是优化模型推理,实现推理加速,其中模型推理最核心的部分是Transformer Block。本节会重点探讨大模型推理的算法、调度策略和输出采样等相关算法。 | [Slides] | 更新中 |
| 06 | 大模型算法 | Transformer起源于NLP领域,近期统治了 CV/NLP/多模态的大模型,我们将深入地探讨 Scaling Law 背后的原理。在大模型算法背后数据和算法的评估也是核心的内容之一,如何实现 Prompt 和通过 Prompt 提升模型效果。 | [Slides] | 更新中 |
| 07 | 热点技术剖析 | 当前大模型技术已进入快速迭代期。这一时期的显著特点就是技术的更新换代速度极快,新算法、新模型层出不穷。因此本节内容将会紧跟大模型的时事内容,进行深度技术分析。 | [Slides] | DONE |
本课程主要为本科生高年级、硕博研究生、AI 大模型系统从业者设计,帮助大家:
-
完整了解 AI 的计算机系统架构,并通过实际问题和案例,来了解 AI 完整生命周期下的系统设计。
-
介绍前沿系统架构和 AI 相结合的研究工作,了解主流框架、平台和工具来了解 AI 大模型系统。
| 编号 | 名称 | 具体内容 | 状态 |
|---|---|---|---|
| 1 | AI 计算体系 | 神经网络等 AI 技术的计算模式和计算体系架构 | DONE |
| 2 | AI 芯片基础 | CPU、GPU、NPU 等芯片体系架构基础原理 | DONE |
| 3 | 图形处理器 GPU | GPU 的基本原理,英伟达 GPU 过去 15 年 8 代架构发展 | DONE |
| 4 | 英伟达 GPU 详解 | 英伟达 GPU 的 Tensor Core、NVLink 深度剖析 | DONE |
| 5 | 国外 AI 处理器 | 国外在谷歌 TPU、特斯拉 DOJO 等专用 AI 处理器核心原理 | DONE |
| 6 | 国内 AI 处理器 | 华为昇腾 Ascend、寒武纪、燧原科技等专用 AI 处理器核心原理 | DONE |
| 7 | AI 芯片黄金 10 年 | 对 AI 芯片的编程模式(SIMT、SIMD、SPMD、CUDA)和发展进行总结 | DONE |
| 编号 | 名称 | 具体内容 | 状态 |
|---|---|---|---|
| 1 | 大模型存储 | 数据存储、CheckPoint 梯度检查点等存储与大模型结合的相关技术 | DONE |
| 2 | 集合通信原理 | 通信域、通信算法、集合通信原语 | DONE |
| 3 | 集合通信库 | 深入地剖析 NCCL/HCCL 实现的具体通信领域算法,以及集合通信库对外 API 与使用 | DONE |
| 编号 | 名称 | 具体内容 | 状态 |
|---|---|---|---|
| 1 | AI 超节点 | Scale Up、SuperPod、万卡集群 | DONE |
| 2 | 集群性能分析 | 集群性能分析,MFU、线性度等 | 待更 |
| 3 | Kubernetes | 让集群部署容器化简单且高效 | 待更 |
| 编号 | 名称 | 具体内容 | 状态 |
|---|---|---|---|
| 1 | 分布式并行 | TP、PP、EP、SP、DP 多维并行 | DONE |
| 2 | PyTorch 框架 | PyTorch 框架原理和昇腾适配架构 | 待更 |
| 3 | 模型微调与后训练 | 大模型微调 SFT 与后训练 Post-Training | 待更 |
| 编号 | 名称 | 具体内容 | 状态 |
|---|---|---|---|
| 1 | 大模型推理框架 | 推理框架整体架构,如 vLLM、SGLang | 待更 |
| 2 | 大模型推理加速 | 待更 | |
| 3 | 架构调度与加速 | 待更 | |
| 4 | 长序列推理 | 待更 | |
| 5 | 输出采样 | 待更 | |
| 6 | 大模型量化与蒸馏 | 待更 |
大部分待更,欢迎参与,08 新算法根据时事热点不定期更新
| 编号 | 名称 | 具体内容 | 状态 |
|---|---|---|---|
| 1 | Transformer 架构 | Transformer、MoE 的架构原理介绍 | 待更 |
| 2 | MoE 架构 | MoE(Mixture of Experts) 模型架构原理与细节 | ING |
| 3 | 大模型新架构 | SSM、MMABA、RWKV、Linear Transformer 等新大模型结构 | 待更 |
| 4 | 向量数据库 | 向量数据库中核心技术相似性搜索、相似性度量与大模型结合原理 | DONE |
| 5 | 数据工程 | 数据工程、Prompt Engine、Data2Vec 和 Tokenize 等相关技术 | 待更 |
| 6 | ChatGPT 解读 | GPT 和 ChatGPT 深度解读 | DONE |
| 7 | DeepSeek | DeepSeek 幻方量化基础大模型、多模态大模型等最新算法解读 | ING |
| 8 | 新算法解读 | Llama3.3、DeepSeek V3/R1、KIMI R1.5 等最新大模型算法的深度解读 | 持续 |
基本完结,01 根据时事热点不定期更新
| 编号 | 名称 | 具体内容 | 状态 |
|---|---|---|---|
| 1 | AI 时事热点 | OpenAI o1、WWDC 大会技术洞察 | 持续 |
| 2 | AI智能体 | AI Agent 智能体的原理、架构 | DONE |
| 3 | 自动驾驶 | 端到端自动驾驶技术原理解析,萝卜快跑对产业带来的变化 | DONE |
| 4 | 具身智能 | 关于对具身智能的技术原理、具身架构和产业思考 | DONE |
| 5 | 生成推荐 | 推荐领域的革命发展历程,大模型迎来了生成式推荐新的增长 | DONE |
| 6 | AI 安全 | 隐私计算的发展过程与 Apple 引入隐私计算,到底隐私计算未来发展如何? | DONE |
| 7 | AI 历史十年 | AI 过去十年的重点事件回顾,2012 到 2025 年从模型、算法、芯片硬件的发展 | DONE |

这个仓已经到达疯狂的 10G 啦(ZOMI 把所有制作过程、高清图片都原封不动提供),如果你要 git clone 会非常的慢,因此建议优先到 Releases · chenzomi12/AIInfra 来下载你需要的内容
非常希望您也参与到这个开源课程中,B 站给 ZOMI 留言哦!
欢迎大家使用的过程中发现 bug 或者勘误直接提交代码 PR 到开源社区哦!
请大家尊重开源和 ZOMI 的努力,引用 PPT 的内容请规范转载标明出处哦!
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for AIInfra
Similar Open Source Tools
AIInfra
AIInfra is an open-source project focused on AI infrastructure, specifically targeting large models in distributed clusters, distributed architecture, distributed training, and algorithms related to large models. The project aims to explore and study system design in artificial intelligence and deep learning, with a focus on the hardware and software stack for building AI large model systems. It provides a comprehensive curriculum covering topics such as AI chip principles, communication and storage, AI clusters, large model training, and inference, as well as algorithms for large models. The course is designed for undergraduate and graduate students, as well as professionals working with AI large model systems, to gain a deep understanding of AI computer system architecture and design.
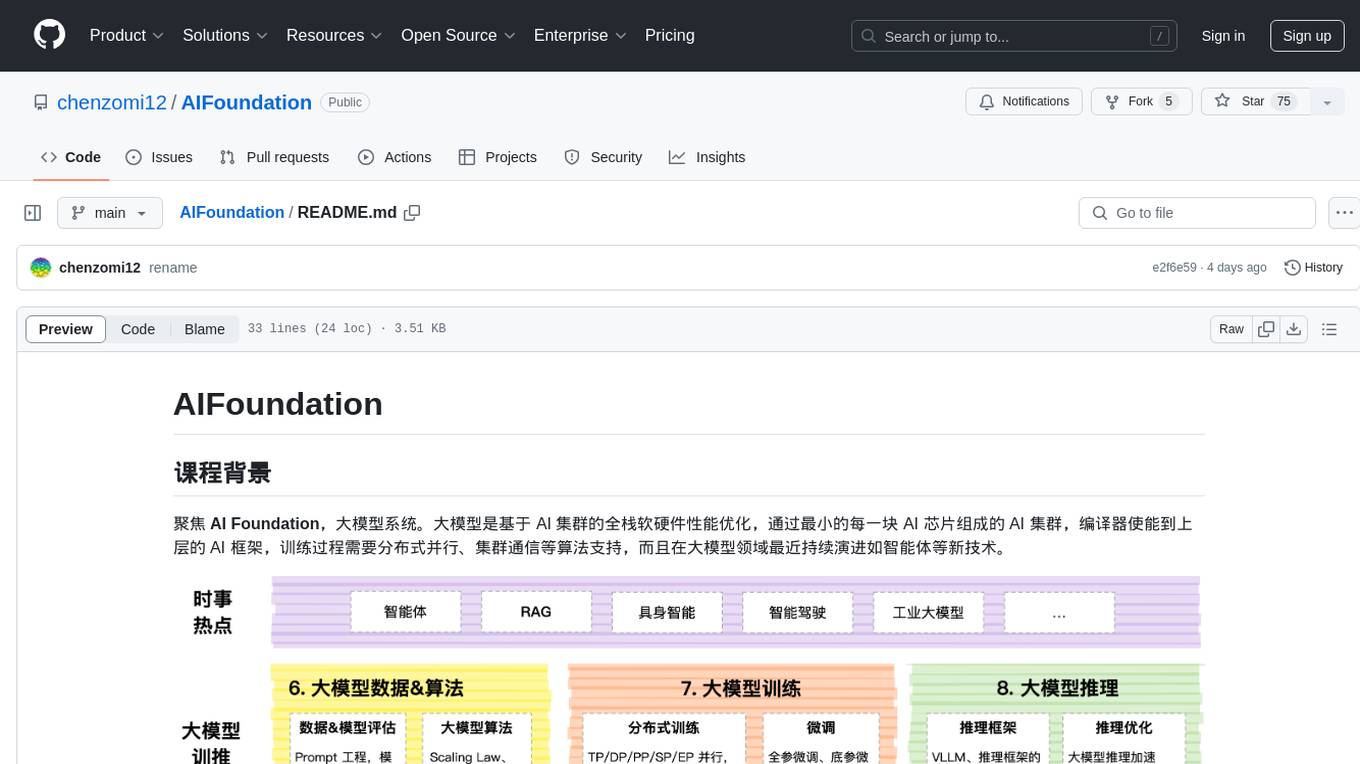
AIFoundation
AIFoundation focuses on AI Foundation, large model systems. Large models optimize the performance of full-stack hardware and software based on AI clusters. The training process requires distributed parallelism, cluster communication algorithms, and continuous evolution in the field of large models such as intelligent agents. The course covers modules like AI chip principles, communication & storage, AI clusters, computing architecture, communication architecture, large model algorithms, training, inference, and analysis of hot technologies in the large model field.
Awesome-AISourceHub
Awesome-AISourceHub is a repository that collects high-quality information sources in the field of AI technology. It serves as a synchronized source of information to avoid information gaps and information silos. The repository aims to provide valuable resources for individuals such as AI book authors, enterprise decision-makers, and tool developers who frequently use Twitter to share insights and updates related to AI advancements. The platform emphasizes the importance of accessing information closer to the source for better quality content. Users can contribute their own high-quality information sources to the repository by following specific steps outlined in the contribution guidelines. The repository covers various platforms such as Twitter, public accounts, knowledge planets, podcasts, blogs, websites, YouTube channels, and more, offering a comprehensive collection of AI-related resources for individuals interested in staying updated with the latest trends and developments in the AI field.
Awesome-AGI
Awesome-AGI is a curated list of resources related to Artificial General Intelligence (AGI), including models, pipelines, applications, and concepts. It provides a comprehensive overview of the current state of AGI research and development, covering various aspects such as model training, fine-tuning, deployment, and applications in different domains. The repository also includes resources on prompt engineering, RLHF, LLM vocabulary expansion, long text generation, hallucination mitigation, controllability and safety, and text detection. It serves as a valuable resource for researchers, practitioners, and anyone interested in the field of AGI.
PaddleScience
PaddleScience is a scientific computing suite developed based on the deep learning framework PaddlePaddle. It utilizes the learning ability of deep neural networks and the automatic (higher-order) differentiation mechanism of PaddlePaddle to solve problems in physics, chemistry, meteorology, and other fields. It supports three solving methods: physics mechanism-driven, data-driven, and mathematical fusion, and provides basic APIs and detailed documentation for users to use and further develop.
AIProductHome
AI Product Home is a repository dedicated to collecting various AI commercial or open-source products. It provides assistance in submitting issues, self-recommendation, correcting resources, and more. The repository also features AI tools like Build Naidia, Autopod, Rytr, Mubert, and a virtual town driven by AI. It includes sections for AI models, chat dialogues, AI assistants, code assistance, artistic creation, content creation, and more. The repository covers a wide range of AI-related tools and resources for users interested in AI products and services.

LLM-for-Healthcare
The repository 'LLM-for-Healthcare' provides a comprehensive survey of large language models (LLMs) for healthcare, covering data, technology, applications, and accountability and ethics. It includes information on various LLM models, training data, evaluation methods, and computation costs. The repository also discusses tasks such as NER, text classification, question answering, dialogue systems, and generation of medical reports from images in the healthcare domain.
MobileLLM
This repository contains the training code of MobileLLM, a language model optimized for on-device use cases with fewer than a billion parameters. It integrates SwiGLU activation function, deep and thin architectures, embedding sharing, and grouped-query attention to achieve high-quality LLMs. MobileLLM-125M/350M shows significant accuracy improvements over previous models on zero-shot commonsense reasoning tasks. The design philosophy scales effectively to larger models, with state-of-the-art results for MobileLLM-600M/1B/1.5B.
AIInfra
AIInfra is an open-source project focused on AI infrastructure, specifically targeting large models in distributed clusters, distributed architecture, distributed training, and algorithms related to large models. The project aims to explore and study system design in artificial intelligence and deep learning, with a focus on the hardware and software stack for building AI large model systems. It provides a comprehensive curriculum covering key topics such as system overview, AI computing clusters, communication and storage, cluster containers and cloud-native technologies, distributed training, distributed inference, large model algorithms and data, and applications of large models.
linktre-tools
The 'linktre-tools' repository is a collection of tools and resources for independent developers, AI products, cross-border e-commerce, and self-media office assistance. It aims to provide a curated list of tools and products in these areas. Users are encouraged to contribute by submitting pull requests and raising issues for continuous updates. The repository covers a wide range of topics including AI tools, independent development tools, popular AI products, tools for web development, online tools, media operations, and cross-border e-commerce resources.

kumo-search
Kumo search is an end-to-end search engine framework that supports full-text search, inverted index, forward index, sorting, caching, hierarchical indexing, intervention system, feature collection, offline computation, storage system, and more. It runs on the EA (Elastic automic infrastructure architecture) platform, enabling engineering automation, service governance, real-time data, service degradation, and disaster recovery across multiple data centers and clusters. The framework aims to provide a ready-to-use search engine framework to help users quickly build their own search engines. Users can write business logic in Python using the AOT compiler in the project, which generates C++ code and binary dynamic libraries for rapid iteration of the search engine.
so-vits-models
This repository collects various LLM, AI-related models, applications, and datasets, including LLM-Chat for dialogue models, LLMs for large models, so-vits-svc for sound-related models, stable-diffusion for image-related models, and virtual-digital-person for generating videos. It also provides resources for deep learning courses and overviews, AI competitions, and specific AI tasks such as text, image, voice, and video processing.
indie-hacker-tools-plus
Indie Hacker Tools Plus is a curated repository of essential tools and technology stacks for independent developers. The repository aims to help developers enhance efficiency, save costs, and mitigate risks by using popular and validated tools. It provides a collection of tools recognized by the industry to empower developers with the most refined technical support. Developers can contribute by submitting articles, software, or resources through issues or pull requests.
ML-AI-2-LT
ML-AI-2-LT is a repository that serves as a glossary for machine learning and deep learning concepts. It contains translations and explanations of various terms related to artificial intelligence, including definitions and notes. Users can contribute by filling issues for unclear concepts or by submitting pull requests with suggestions or additions. The repository aims to provide a comprehensive resource for understanding key terminology in the field of AI and machine learning.
BlossomLM
BlossomLM is a series of open-source conversational large language models. This project aims to provide a high-quality general-purpose SFT dataset in both Chinese and English, making fine-tuning accessible while also providing pre-trained model weights. **Hint**: BlossomLM is a personal non-commercial project.
step_into_llm
The 'step_into_llm' repository is dedicated to the 昇思MindSpore technology open class, which focuses on exploring cutting-edge technologies, combining theory with practical applications, expert interpretations, open sharing, and empowering competitions. The repository contains course materials, including slides and code, for the ongoing second phase of the course. It covers various topics related to large language models (LLMs) such as Transformer, BERT, GPT, GPT2, and more. The course aims to guide developers interested in LLMs from theory to practical implementation, with a special emphasis on the development and application of large models.
For similar tasks

Chinese-Mixtral-8x7B
Chinese-Mixtral-8x7B is an open-source project based on Mistral's Mixtral-8x7B model for incremental pre-training of Chinese vocabulary, aiming to advance research on MoE models in the Chinese natural language processing community. The expanded vocabulary significantly improves the model's encoding and decoding efficiency for Chinese, and the model is pre-trained incrementally on a large-scale open-source corpus, enabling it with powerful Chinese generation and comprehension capabilities. The project includes a large model with expanded Chinese vocabulary and incremental pre-training code.

Awesome-LLMs-on-device
Welcome to the ultimate hub for on-device Large Language Models (LLMs)! This repository is your go-to resource for all things related to LLMs designed for on-device deployment. Whether you're a seasoned researcher, an innovative developer, or an enthusiastic learner, this comprehensive collection of cutting-edge knowledge is your gateway to understanding, leveraging, and contributing to the exciting world of on-device LLMs.
ZhiLight
ZhiLight is a highly optimized large language model (LLM) inference engine developed by Zhihu and ModelBest Inc. It accelerates the inference of models like Llama and its variants, especially on PCIe-based GPUs. ZhiLight offers significant performance advantages compared to mainstream open-source inference engines. It supports various features such as custom defined tensor and unified global memory management, optimized fused kernels, support for dynamic batch, flash attention prefill, prefix cache, and different quantization techniques like INT8, SmoothQuant, FP8, AWQ, and GPTQ. ZhiLight is compatible with OpenAI interface and provides high performance on mainstream NVIDIA GPUs with different model sizes and precisions.
AIInfra
AIInfra is an open-source project focused on AI infrastructure, specifically targeting large models in distributed clusters, distributed architecture, distributed training, and algorithms related to large models. The project aims to explore and study system design in artificial intelligence and deep learning, with a focus on the hardware and software stack for building AI large model systems. It provides a comprehensive curriculum covering topics such as AI chip principles, communication and storage, AI clusters, large model training, and inference, as well as algorithms for large models. The course is designed for undergraduate and graduate students, as well as professionals working with AI large model systems, to gain a deep understanding of AI computer system architecture and design.
ais-k8s
AIStore on Kubernetes is a toolkit for deploying a lightweight, scalable object storage solution designed for AI applications in a Kubernetes environment. It includes documentation, Ansible playbooks, Kubernetes operator, Helm charts, and Terraform definitions for deployment on public cloud platforms. The system overview shows deployment across nodes with proxy and target pods utilizing Persistent Volumes. The AIStore Operator automates cluster management tasks. The repository focuses on production deployments but offers different deployment options. Thorough planning and configuration decisions are essential for successful multi-node deployment. The AIStore Operator simplifies tasks like starting, deploying, adjusting size, and updating AIStore resources within Kubernetes.
AIInfra
AIInfra is an open-source project focused on AI infrastructure, specifically targeting large models in distributed clusters, distributed architecture, distributed training, and algorithms related to large models. The project aims to explore and study system design in artificial intelligence and deep learning, with a focus on the hardware and software stack for building AI large model systems. It provides a comprehensive curriculum covering key topics such as system overview, AI computing clusters, communication and storage, cluster containers and cloud-native technologies, distributed training, distributed inference, large model algorithms and data, and applications of large models.
west
WeST is a Speech Recognition/Transcript tool developed in 300 lines of code, inspired by SLAM-ASR and LLaMA 3.1. The model includes a Language Model (LLM), a Speech Encoder, and a trainable Projector. It requires training data in jsonl format with 'wav' and 'txt' entries. WeST can be used for training and decoding speech recognition models.
fsdp_qlora
The fsdp_qlora repository provides a script for training Large Language Models (LLMs) with Quantized LoRA and Fully Sharded Data Parallelism (FSDP). It integrates FSDP+QLoRA into the Axolotl platform and offers installation instructions for dependencies like llama-recipes, fastcore, and PyTorch. Users can finetune Llama-2 70B on Dual 24GB GPUs using the provided command. The script supports various training options including full params fine-tuning, LoRA fine-tuning, custom LoRA fine-tuning, quantized LoRA fine-tuning, and more. It also discusses low memory loading, mixed precision training, and comparisons to existing trainers. The repository addresses limitations and provides examples for training with different configurations, including BnB QLoRA and HQQ QLoRA. Additionally, it offers SLURM training support and instructions for adding support for a new model.
For similar jobs

llm-resource
llm-resource is a comprehensive collection of high-quality resources for Large Language Models (LLM). It covers various aspects of LLM including algorithms, training, fine-tuning, alignment, inference, data engineering, compression, evaluation, prompt engineering, AI frameworks, AI basics, AI infrastructure, AI compilers, LLM application development, LLM operations, AI systems, and practical implementations. The repository aims to gather and share valuable resources related to LLM for the community to benefit from.

LitServe
LitServe is a high-throughput serving engine designed for deploying AI models at scale. It generates an API endpoint for models, handles batching, streaming, and autoscaling across CPU/GPUs. LitServe is built for enterprise scale with a focus on minimal, hackable code-base without bloat. It supports various model types like LLMs, vision, time-series, and works with frameworks like PyTorch, JAX, Tensorflow, and more. The tool allows users to focus on model performance rather than serving boilerplate, providing full control and flexibility.

how-to-optim-algorithm-in-cuda
This repository documents how to optimize common algorithms based on CUDA. It includes subdirectories with code implementations for specific optimizations. The optimizations cover topics such as compiling PyTorch from source, NVIDIA's reduce optimization, OneFlow's elementwise template, fast atomic add for half data types, upsample nearest2d optimization in OneFlow, optimized indexing in PyTorch, OneFlow's softmax kernel, linear attention optimization, and more. The repository also includes learning resources related to deep learning frameworks, compilers, and optimization techniques.

aiac
AIAC is a library and command line tool to generate Infrastructure as Code (IaC) templates, configurations, utilities, queries, and more via LLM providers such as OpenAI, Amazon Bedrock, and Ollama. Users can define multiple 'backends' targeting different LLM providers and environments using a simple configuration file. The tool allows users to ask a model to generate templates for different scenarios and composes an appropriate request to the selected provider, storing the resulting code to a file and/or printing it to standard output.

ENOVA
ENOVA is an open-source service for Large Language Model (LLM) deployment, monitoring, injection, and auto-scaling. It addresses challenges in deploying stable serverless LLM services on GPU clusters with auto-scaling by deconstructing the LLM service execution process and providing configuration recommendations and performance detection. Users can build and deploy LLM with few command lines, recommend optimal computing resources, experience LLM performance, observe operating status, achieve load balancing, and more. ENOVA ensures stable operation, cost-effectiveness, efficiency, and strong scalability of LLM services.

jina
Jina is a tool that allows users to build multimodal AI services and pipelines using cloud-native technologies. It provides a Pythonic experience for serving ML models and transitioning from local deployment to advanced orchestration frameworks like Docker-Compose, Kubernetes, or Jina AI Cloud. Users can build and serve models for any data type and deep learning framework, design high-performance services with easy scaling, serve LLM models while streaming their output, integrate with Docker containers via Executor Hub, and host on CPU/GPU using Jina AI Cloud. Jina also offers advanced orchestration and scaling capabilities, a smooth transition to the cloud, and easy scalability and concurrency features for applications. Users can deploy to their own cloud or system with Kubernetes and Docker Compose integration, and even deploy to JCloud for autoscaling and monitoring.

vidur
Vidur is a high-fidelity and extensible LLM inference simulator designed for capacity planning, deployment configuration optimization, testing new research ideas, and studying system performance of models under different workloads and configurations. It supports various models and devices, offers chrome trace exports, and can be set up using mamba, venv, or conda. Users can run the simulator with various parameters and monitor metrics using wandb. Contributions are welcome, subject to a Contributor License Agreement and adherence to the Microsoft Open Source Code of Conduct.

AI-System-School
AI System School is a curated list of research in machine learning systems, focusing on ML/DL infra, LLM infra, domain-specific infra, ML/LLM conferences, and general resources. It provides resources such as data processing, training systems, video systems, autoML systems, and more. The repository aims to help users navigate the landscape of AI systems and machine learning infrastructure, offering insights into conferences, surveys, books, videos, courses, and blogs related to the field.