
kumo-search
docs for search system and ai infra
Stars: 248

Kumo search is an end-to-end search engine framework that supports full-text search, inverted index, forward index, sorting, caching, hierarchical indexing, intervention system, feature collection, offline computation, storage system, and more. It runs on the EA (Elastic automic infrastructure architecture) platform, enabling engineering automation, service governance, real-time data, service degradation, and disaster recovery across multiple data centers and clusters. The framework aims to provide a ready-to-use search engine framework to help users quickly build their own search engines. Users can write business logic in Python using the AOT compiler in the project, which generates C++ code and binary dynamic libraries for rapid iteration of the search engine.
README:
![]()
| 应用 - 安装 - 开发 - 文档 - 深度学习 - FAQ - TIPS - EA半小时 - 技术专题 |
kumo search
是一个端到端搜索引擎框架,支持全文检索、倒排索引、正排索引、排序、缓存、索引分层、干预系统、特征收集、离线计算、存储系统等功能。kumo search
运行在 EA(Elastic automic infrastructure architecture)
平台上,支持在多机房、多集群上实现工程自动化、服务治理、实时数据、服务降级与容灾等功能。
随着互联网的发展,全网搜索已经不再是获取信息的唯一途径。很多垂直的信息服务,如电商、社交、新闻等,都有自己的搜索引擎。
这些搜索引擎的特点是:数据量中等,业务复杂,用户体验要求高。这些搜索引擎的开发,需要大量的工程和算法支持。kumo search旨在
提供一套开箱即用的搜索引擎框架,帮助用户快速搭建自己的搜索引擎。在这个框架上,用户可以通过项目内的AOT编译器,用
python编写业务逻辑,框架会自动生成c++代码,并生成二进制动态库,动态更新到搜索引擎中。从而实现搜索引擎的快速迭代。

| 序号 | 项目名 | 说明 | 说明 |
|---|---|---|---|
| 1 | collie | 引用外部header only library 如jason,toml等,统一管理 | |
| 2 | turbo | hash,log,容器类,字符串相关操作 | |
| 3 | melon | rpc通信 | |
| 4 | alkaid | 文件系统封装、本地文件,hdfs,s3等 | 文件系统统一api,zlib,lz4,zst unified api |
| 5 | mizar | 基于rocksdb,toplingdb存储引擎内核 | 待开发wisekey功能,暂时先用rocksdb官方版本 |
| 6 | alioth玉衡 | 表格内存 | 开发中 |
| 7 | megrez天权 | 数据集读写 | hdf5 cvs bin已完成,待封装高级c++api |
| 8 | phekda | 统一向量引擎访问api UnifiedIndex,简化接口 | 支持snapshot,过滤插件 |
| 9 | merak天璇 | 综合搜索引擎内核 | 待开发 |
| 10 | dubhe 天枢 | nlp内核 | 待开发 |
| 11 | flare | gpu、cpu高维张量计算,等计算 | |
| 12 | theia | 基于opengl图形图像显示,服务端不可用(无显示设备) | |
| 13 | dwarf | jupyter协议c++内核 | |
| 14 | exodus | hercules and other jupyter应用 | 完成 |
| 15 | hercules | python aot编译器 | |
| 16 | carbin | c++包管理器,cmake生成器 | 完成 |
| 17 | carbin-template | cmake模板库 | 完成 |
| 18 | carbin-recipes | carbin recipes 依赖库自定义配置 | 完成 |
| 18 | hadar | suggest 搜索建议服务 内核 | 接近完成,商用不开源 |
| 序号 | 项目名 | 说明 | 进度 |
|---|---|---|---|
| 1 | sirius | EA元数据服务器 服务发现,全局时钟服务,全局配置服务, 全局id服务 | 完成 |
| 2 | polaris | 向量引擎单机服务 | 完成 |
| 3 | elnath | 综合搜索引单机服务 | 开发中 |
| 4 | vega | 向量引擎数据库集群版 | 完成 商用不开源 |
| 5 | arcturus | 综合搜索引擎集群版 | 开发中 商用不开源 |
| 6 | pollux | 综合引擎业务控制台 | 开发中 商用不开源 |
| 7 | capella | ltr排序服务 | 开发中 商用不开源 |
| 8 | aldebaran | suggest搜索建议服务集群 | 开发中 商用不开源 |
| 9 | nunki | nlp服务 | 开发中 商用不开源 |
半小时系列, 关注基于EA基础设施快速搭建企业级应用服务,侧重实际操作,快速上手,快速开发,快速部署,快速迭代。
- a001-hala-ea - 基础环境安装,使用carbin创建项目
- a002-hala-ea - 创建一个c++应用,在cmake创建库并使用
- a003-hala-ea - 创建一个c++库,使用googletest进行单元测试
- a004-hala-restful - 使用melon库, 创建一个restful服务
- a005-hala-echo - 使用melon库, 创建一个echo服务
- a006-hala-vue - 创建一个cache服务,并提供浏览器访问界面
- a007-hala-vue-ext - cache服务源码解读
- a008-hala-kv - 单机kv服务完整实现
本专题主要介绍搜索引擎的基础知识,以及随着搜索技术和搜索业务的发展,搜索架构的演进,升级和设计,以及背后的技术原理和实现。
EA是服务端应用的基础架构,EA目前支持centos和ubuntu两种操作系统,mac系统目前在开发中, 尽最大可能支持mac
系统。但目前并没有
尝试,为方便编译和ide开发,后续部分功能可能进行尝试兼容。基础环境部署参见安装与使用
EA体系的cicd使用carbin工具进行管理。carbin是一个c++包管理器,cmake生成器,cicd工具。carbin可以下载第三方依赖库,
生成cmake构建系统,进行工程编译和部署。carbin的使用参见carbin docs
| carbin | conda | cmake | CPM | conan | bazel | |
|---|---|---|---|---|---|---|
| 使用复杂度 | easy | middle | hard | middle | hard | hard |
| 安装难度 | pip easy | binary easy | NA easy | cmake | pip easy | binary hard |
| 依赖模式 | source/binary | binary | source | source | source/binary | source |
| 依赖树 | support | support | support | support | support | support |
| 本地源码 | support | NA | support | support | NA | support |
| 兼容性 | good | middle | good | good | good | poor |
| 速度 | good | middle | poor | poor | good | poor |
conda是一款不错的管理工具,没有选择conda,是因为conda的编译依赖项比较复杂,而且编译选项经常会出现问题,不太适合c++工程的编译。 cmake自带的管理工具,不太适合大型工程的管理,每次重新编译项目可能导致重新下载依赖库,编译时间过长。CPM是一个c++包管理器,同样,在国内的网络 环境下,下载依赖库速度较慢,不太适合大型工程的管理。conan是一个c++包管理器,但是conan的依赖库下载速度较慢,不太适合大型工程的管理。
同时carbin也是非常适合c++工程的管理,carbin能够快速生成c++项目管理cmake体系,统一了项目编译过程,选项配置,以及编译后安装导出的变量规则,
EA体系的项目可以通过固定规则find_package找到项目和项目对象.当时也适合任何基于cmake的项目使用。
如果基于docker开发,EA 提供了已经基础开发ea inf容器:
centos7-openssl11-python-310-gcc-9.3:
lijippy/ea_inf:c7_base_v1
- 天空中最亮的星 ———— 集群元数据服务 - 服务发现,全局时钟服务,全局配置服务,全局id服务
- cmake有点甜 - 利用cmake构建系统进行工程编译和部署,实现cicd自动化。
- 走近AI:向量检索 - 向量检索是一种基于向量相似度的检索技术,本文介绍了向量检索的基本原理和应用场景, 以及kumo搜索引擎的实现。
- @author Jeff.li vicky codejie
- @email [email protected]
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for kumo-search
Similar Open Source Tools
kumo-search
Kumo search is an end-to-end search engine framework that supports full-text search, inverted index, forward index, sorting, caching, hierarchical indexing, intervention system, feature collection, offline computation, storage system, and more. It runs on the EA (Elastic automic infrastructure architecture) platform, enabling engineering automation, service governance, real-time data, service degradation, and disaster recovery across multiple data centers and clusters. The framework aims to provide a ready-to-use search engine framework to help users quickly build their own search engines. Users can write business logic in Python using the AOT compiler in the project, which generates C++ code and binary dynamic libraries for rapid iteration of the search engine.
so-vits-models
This repository collects various LLM, AI-related models, applications, and datasets, including LLM-Chat for dialogue models, LLMs for large models, so-vits-svc for sound-related models, stable-diffusion for image-related models, and virtual-digital-person for generating videos. It also provides resources for deep learning courses and overviews, AI competitions, and specific AI tasks such as text, image, voice, and video processing.

LLM-for-Healthcare
The repository 'LLM-for-Healthcare' provides a comprehensive survey of large language models (LLMs) for healthcare, covering data, technology, applications, and accountability and ethics. It includes information on various LLM models, training data, evaluation methods, and computation costs. The repository also discusses tasks such as NER, text classification, question answering, dialogue systems, and generation of medical reports from images in the healthcare domain.
MobileLLM
This repository contains the training code of MobileLLM, a language model optimized for on-device use cases with fewer than a billion parameters. It integrates SwiGLU activation function, deep and thin architectures, embedding sharing, and grouped-query attention to achieve high-quality LLMs. MobileLLM-125M/350M shows significant accuracy improvements over previous models on zero-shot commonsense reasoning tasks. The design philosophy scales effectively to larger models, with state-of-the-art results for MobileLLM-600M/1B/1.5B.
Awesome-AgenticLLM-RL-Papers
This repository serves as the official source for the survey paper 'The Landscape of Agentic Reinforcement Learning for LLMs: A Survey'. It provides an extensive overview of various algorithms, methods, and frameworks related to Agentic RL, including detailed information on different families of algorithms, their key mechanisms, objectives, and links to relevant papers and resources. The repository covers a wide range of tasks such as Search & Research Agent, Code Agent, Mathematical Agent, GUI Agent, RL in Vision Agents, RL in Embodied Agents, and RL in Multi-Agent Systems. Additionally, it includes information on environments, frameworks, and methods suitable for different tasks related to Agentic RL and LLMs.
ML-AI-2-LT
ML-AI-2-LT is a repository that serves as a glossary for machine learning and deep learning concepts. It contains translations and explanations of various terms related to artificial intelligence, including definitions and notes. Users can contribute by filling issues for unclear concepts or by submitting pull requests with suggestions or additions. The repository aims to provide a comprehensive resource for understanding key terminology in the field of AI and machine learning.
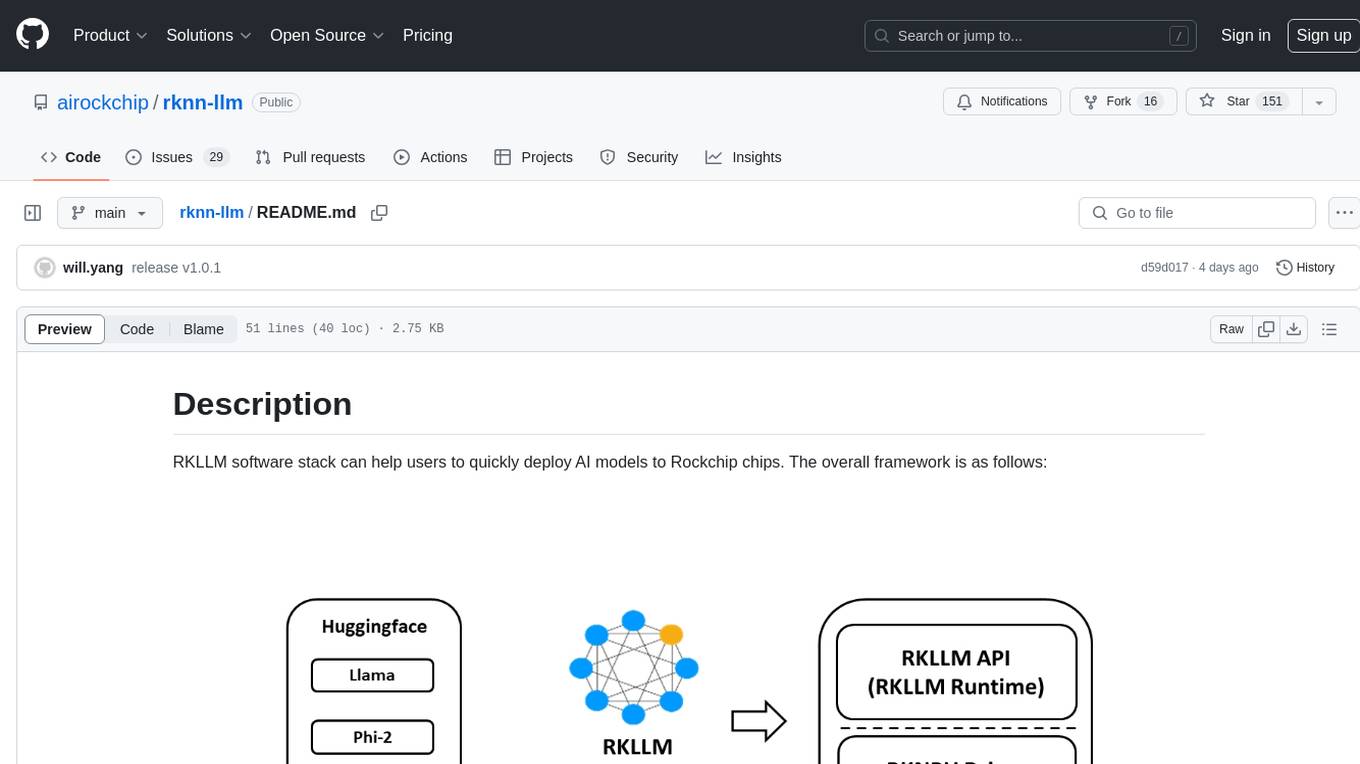
rknn-llm
RKLLM software stack is a toolkit designed to help users quickly deploy AI models to Rockchip chips. It consists of RKLLM-Toolkit for model conversion and quantization, RKLLM Runtime for deploying models on Rockchip NPU platform, and RKNPU kernel driver for hardware interaction. The toolkit supports RK3588 and RK3576 series chips and various models like TinyLLAMA, Qwen, Phi, ChatGLM3, Gemma, InternLM2, and MiniCPM. Users can download packages, docker images, examples, and docs from RKLLM_SDK. Additionally, RKNN-Toolkit2 SDK is available for deploying additional AI models.
PaddleScience
PaddleScience is a scientific computing suite developed based on the deep learning framework PaddlePaddle. It utilizes the learning ability of deep neural networks and the automatic (higher-order) differentiation mechanism of PaddlePaddle to solve problems in physics, chemistry, meteorology, and other fields. It supports three solving methods: physics mechanism-driven, data-driven, and mathematical fusion, and provides basic APIs and detailed documentation for users to use and further develop.
step_into_llm
The 'step_into_llm' repository is dedicated to the 昇思MindSpore technology open class, which focuses on exploring cutting-edge technologies, combining theory with practical applications, expert interpretations, open sharing, and empowering competitions. The repository contains course materials, including slides and code, for the ongoing second phase of the course. It covers various topics related to large language models (LLMs) such as Transformer, BERT, GPT, GPT2, and more. The course aims to guide developers interested in LLMs from theory to practical implementation, with a special emphasis on the development and application of large models.
BlossomLM
BlossomLM is a series of open-source conversational large language models. This project aims to provide a high-quality general-purpose SFT dataset in both Chinese and English, making fine-tuning accessible while also providing pre-trained model weights. **Hint**: BlossomLM is a personal non-commercial project.
Awesome-AGI
Awesome-AGI is a curated list of resources related to Artificial General Intelligence (AGI), including models, pipelines, applications, and concepts. It provides a comprehensive overview of the current state of AGI research and development, covering various aspects such as model training, fine-tuning, deployment, and applications in different domains. The repository also includes resources on prompt engineering, RLHF, LLM vocabulary expansion, long text generation, hallucination mitigation, controllability and safety, and text detection. It serves as a valuable resource for researchers, practitioners, and anyone interested in the field of AGI.
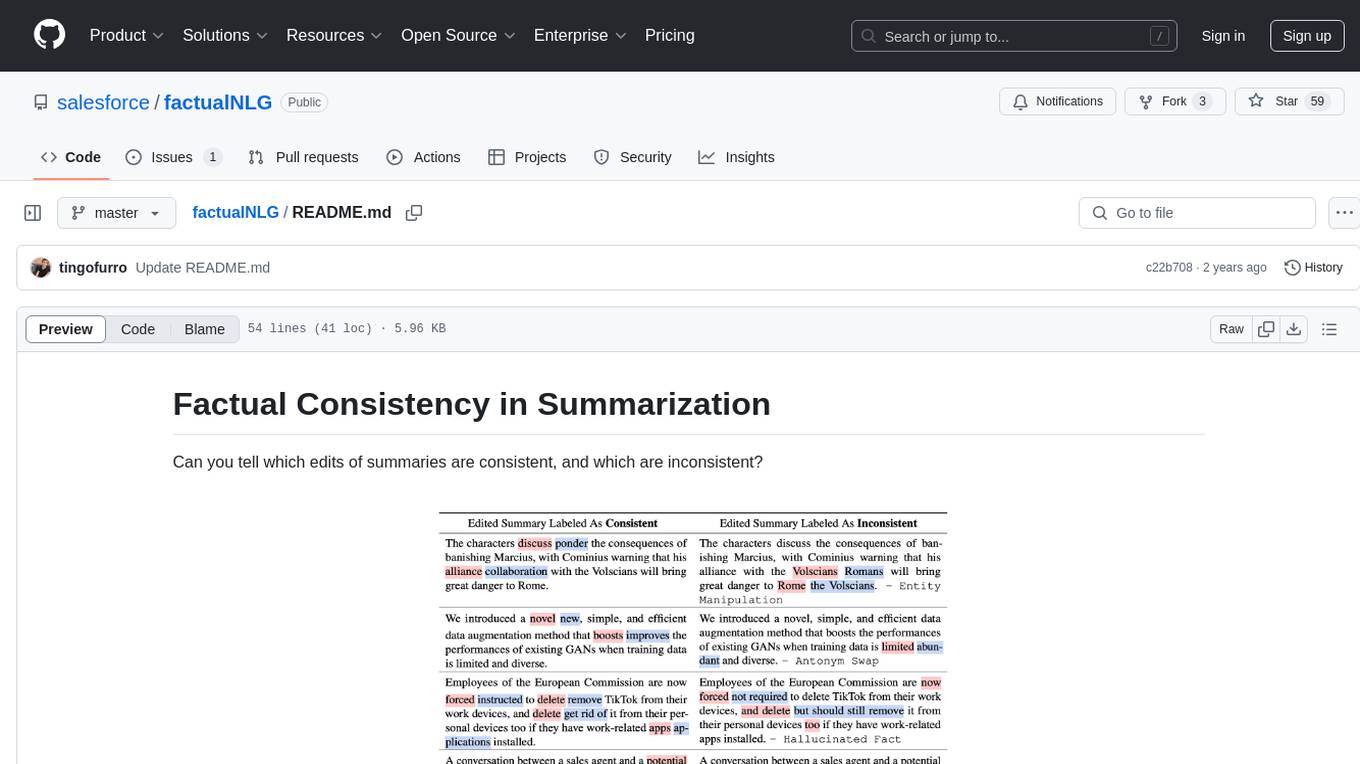
factualNLG
FactualNLG is a tool designed to analyze the consistency of edits in summaries. It includes a benchmark with various LLM models, data release for the SummEdits benchmark, explanation analysis for identifying inconsistent summaries, and prompts used in experiments.
Data-and-AI-Concepts
This repository is a curated collection of data science and AI concepts and IQs, covering topics from foundational mathematics to cutting-edge generative AI concepts. It aims to support learners and professionals preparing for various data science roles by providing detailed explanations and notebooks for each concept.
AlignBench
AlignBench is the first comprehensive evaluation benchmark for assessing the alignment level of Chinese large models across multiple dimensions. It includes introduction information, data, and code related to AlignBench. The benchmark aims to evaluate the alignment performance of Chinese large language models through a multi-dimensional and rule-calibrated evaluation method, enhancing reliability and interpretability.
AIInfra
AIInfra is an open-source project focused on AI infrastructure, specifically targeting large models in distributed clusters, distributed architecture, distributed training, and algorithms related to large models. The project aims to explore and study system design in artificial intelligence and deep learning, with a focus on the hardware and software stack for building AI large model systems. It provides a comprehensive curriculum covering topics such as AI chip principles, communication and storage, AI clusters, large model training, and inference, as well as algorithms for large models. The course is designed for undergraduate and graduate students, as well as professionals working with AI large model systems, to gain a deep understanding of AI computer system architecture and design.

Awesome-LLM-Eval
Awesome-LLM-Eval: a curated list of tools, benchmarks, demos, papers for Large Language Models (like ChatGPT, LLaMA, GLM, Baichuan, etc) Evaluation on Language capabilities, Knowledge, Reasoning, Fairness and Safety.
For similar tasks
kumo-search
Kumo search is an end-to-end search engine framework that supports full-text search, inverted index, forward index, sorting, caching, hierarchical indexing, intervention system, feature collection, offline computation, storage system, and more. It runs on the EA (Elastic automic infrastructure architecture) platform, enabling engineering automation, service governance, real-time data, service degradation, and disaster recovery across multiple data centers and clusters. The framework aims to provide a ready-to-use search engine framework to help users quickly build their own search engines. Users can write business logic in Python using the AOT compiler in the project, which generates C++ code and binary dynamic libraries for rapid iteration of the search engine.
search_with_lepton
Build your own conversational search engine using less than 500 lines of code. Features built-in support for LLM, search engine, customizable UI interface, and shareable cached search results. Setup includes Bing and Google search engines. Utilize LLM and KV functions with Lepton for seamless integration. Easily deploy to Lepton AI or your own environment with one-click deployment options.
wikipedia-semantic-search
This repository showcases a project that indexes millions of Wikipedia articles using Upstash Vector. It includes a semantic search engine and a RAG chatbot SDK. The project involves preparing and embedding Wikipedia articles, indexing vectors, building a semantic search engine, and implementing a RAG chatbot. Key features include indexing over 144 million vectors, multilingual support, cross-lingual semantic search, and a RAG chatbot. Technologies used include Upstash Vector, Upstash Redis, Upstash RAG Chat SDK, SentenceTransformers, and Meta-Llama-3-8B-Instruct for LLM provider.

FlashRank
FlashRank is an ultra-lite and super-fast Python library designed to add re-ranking capabilities to existing search and retrieval pipelines. It is based on state-of-the-art Language Models (LLMs) and cross-encoders, offering support for pairwise/pointwise rerankers and listwise LLM-based rerankers. The library boasts the tiniest reranking model in the world (~4MB) and runs on CPU without the need for Torch or Transformers. FlashRank is cost-conscious, with a focus on low cost per invocation and smaller package size for efficient serverless deployments. It supports various models like ms-marco-TinyBERT, ms-marco-MiniLM, rank-T5-flan, ms-marco-MultiBERT, and more, with plans for future model additions. The tool is ideal for enhancing search precision and speed in scenarios where lightweight models with competitive performance are preferred.
For similar jobs

db2rest
DB2Rest is a modern low-code REST DATA API platform that simplifies the development of intelligent applications. It seamlessly integrates existing and new databases with language models (LMs/LLMs) and vector stores, enabling the rapid delivery of context-aware, reasoning applications without vendor lock-in.

mage-ai
Mage is an open-source data pipeline tool for transforming and integrating data. It offers an easy developer experience, engineering best practices built-in, and data as a first-class citizen. Mage makes it easy to build, preview, and launch data pipelines, and provides observability and scaling capabilities. It supports data integrations, streaming pipelines, and dbt integration.

airbyte
Airbyte is an open-source data integration platform that makes it easy to move data from any source to any destination. With Airbyte, you can build and manage data pipelines without writing any code. Airbyte provides a library of pre-built connectors that make it easy to connect to popular data sources and destinations. You can also create your own connectors using Airbyte's no-code Connector Builder or low-code CDK. Airbyte is used by data engineers and analysts at companies of all sizes to build and manage their data pipelines.

labelbox-python
Labelbox is a data-centric AI platform for enterprises to develop, optimize, and use AI to solve problems and power new products and services. Enterprises use Labelbox to curate data, generate high-quality human feedback data for computer vision and LLMs, evaluate model performance, and automate tasks by combining AI and human-centric workflows. The academic & research community uses Labelbox for cutting-edge AI research.

telemetry-airflow
This repository codifies the Airflow cluster that is deployed at workflow.telemetry.mozilla.org (behind SSO) and commonly referred to as "WTMO" or simply "Airflow". Some links relevant to users and developers of WTMO: * The `dags` directory in this repository contains some custom DAG definitions * Many of the DAGs registered with WTMO don't live in this repository, but are instead generated from ETL task definitions in bigquery-etl * The Data SRE team maintains a WTMO Developer Guide (behind SSO)

airflow
Apache Airflow (or simply Airflow) is a platform to programmatically author, schedule, and monitor workflows. When workflows are defined as code, they become more maintainable, versionable, testable, and collaborative. Use Airflow to author workflows as directed acyclic graphs (DAGs) of tasks. The Airflow scheduler executes your tasks on an array of workers while following the specified dependencies. Rich command line utilities make performing complex surgeries on DAGs a snap. The rich user interface makes it easy to visualize pipelines running in production, monitor progress, and troubleshoot issues when needed.

airbyte-platform
Airbyte is an open-source data integration platform that makes it easy to move data from any source to any destination. With Airbyte, you can build and manage data pipelines without writing any code. Airbyte provides a library of pre-built connectors that make it easy to connect to popular data sources and destinations. You can also create your own connectors using Airbyte's low-code Connector Development Kit (CDK). Airbyte is used by data engineers and analysts at companies of all sizes to move data for a variety of purposes, including data warehousing, data analysis, and machine learning.

chronon
Chronon is a platform that simplifies and improves ML workflows by providing a central place to define features, ensuring point-in-time correctness for backfills, simplifying orchestration for batch and streaming pipelines, offering easy endpoints for feature fetching, and guaranteeing and measuring consistency. It offers benefits over other approaches by enabling the use of a broad set of data for training, handling large aggregations and other computationally intensive transformations, and abstracting away the infrastructure complexity of data plumbing.