
factualNLG
Code for the arXiv paper: "LLMs as Factual Reasoners: Insights from Existing Benchmarks and Beyond"
Stars: 59
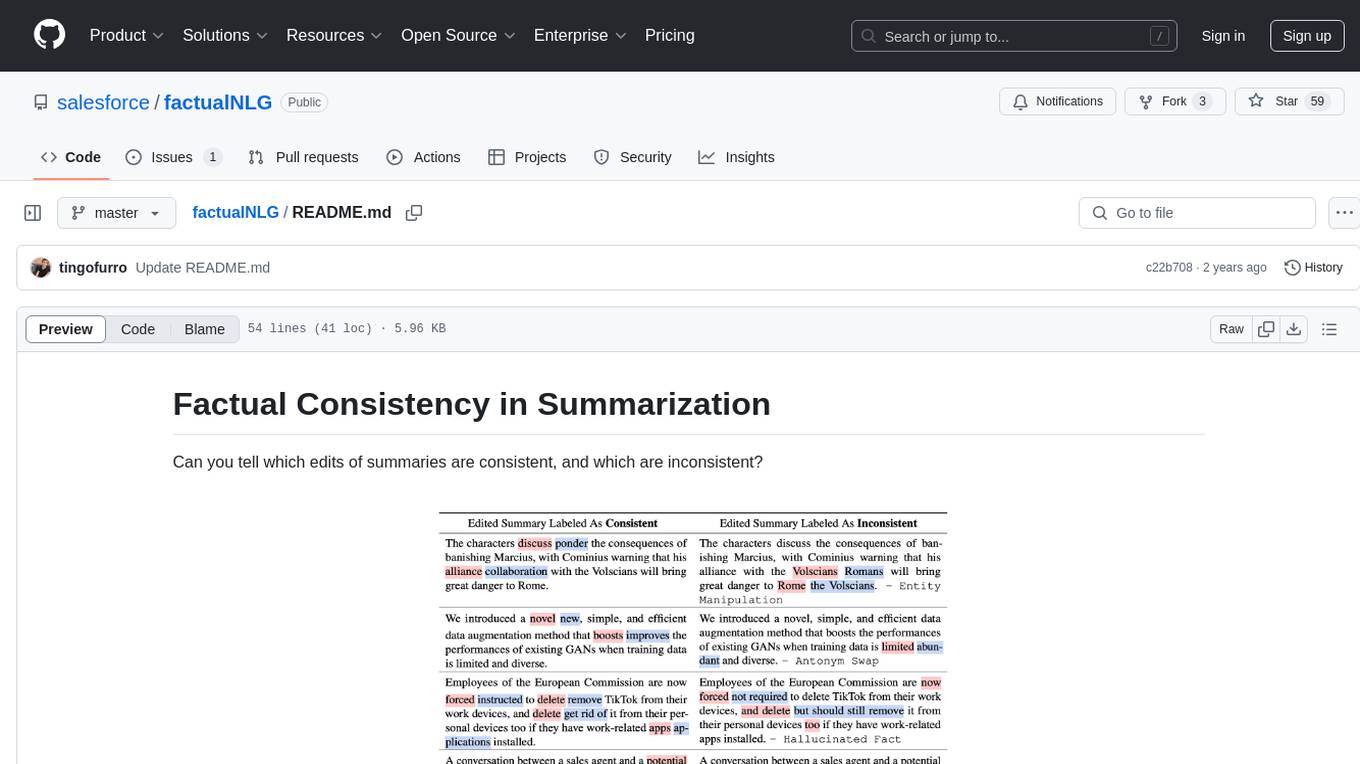
FactualNLG is a tool designed to analyze the consistency of edits in summaries. It includes a benchmark with various LLM models, data release for the SummEdits benchmark, explanation analysis for identifying inconsistent summaries, and prompts used in experiments.
README:
Can you tell which edits of summaries are consistent, and which are inconsistent?

Here is the updated benchmark, with the latest LLMs (Gemini-pro added on 12/14/2023)
| Model Name | Podcast | Bill Sum | Sam Sum | News | Sales Call | Sales Email | Shake speare | Sci TLDR | QMSumm | ECT Sum | Overall |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Llama2-7b | 50 | 50 | 50 | 50.6 | 50.9 | 50 | 50 | 50 | 50.7 | 51.4 | 50.4 |
| Dav001 | 53.3 | 50.2 | 51 | 54.4 | 55.5 | 52.5 | 50 | 51 | 50.1 | 50.9 | 51.9 |
| DAE | 54.4 | 55.1 | 58.7 | 60.9 | 50.4 | 53.6 | 53.6 | 54.7 | 52 | 58.3 | 55.2 |
| Cohere-cmd-xl | 51.1 | 52.7 | 51.3 | 52.6 | 60.2 | 59.4 | 50 | 60.5 | 54.5 | 60.5 | 55.3 |
| Vicuna-13b | 52.8 | 52.5 | 51.3 | 63.5 | 57.9 | 51.8 | 55.4 | 59.7 | 54 | 62.4 | 56.1 |
| SummaCConv | 58.1 | 55.2 | 53.1 | 61.9 | 59 | 53.7 | 59.3 | 59.7 | 53.5 | 57.9 | 57.1 |
| Mistral-7b | 50 | 55.5 | 56.7 | 59.8 | 63.4 | 59.7 | 53.5 | 59.6 | 55.9 | 63.7 | 57.8 |
| Llama2-13b | 51.3 | 54.6 | 57.2 | 59.3 | 63.1 | 58.1 | 58.6 | 63.4 | 56.5 | 61.4 | 58.4 |
| Claudev13 | 60.4 | 51.9 | 64.5 | 63.4 | 61.3 | 57 | 58.1 | 57.8 | 56.9 | 68.1 | 59.9 |
| Dav002 | 56.4 | 53.9 | 57.1 | 61.9 | 65.1 | 59.1 | 56.6 | 64.6 | 60.6 | 66.2 | 60.1 |
| Bard | 50 | 58.1 | 61.3 | 71.6 | 73.3 | 70.6 | 58.7 | 66 | 53.9 | 72.7 | 63.6 |
| QAFactEval | 63.7 | 54.2 | 66.2 | 74.4 | 68.4 | 63.6 | 61.6 | 67.5 | 62.4 | 72.6 | 65.5 |
| PaLM-bison | 66 | 62 | 69 | 68.4 | 74.4 | 68.1 | 61.6 | 78.1 | 70.4 | 72.4 | 69 |
| Dav003 | 65.7 | 59.9 | 67.6 | 71 | 78.8 | 69.2 | 69.7 | 74.4 | 72.2 | 77.8 | 70.6 |
| CGPT | 68.4 | 63.6 | 69.1 | 74.4 | 79.4 | 65.5 | 68 | 75.6 | 69.2 | 78.6 | 71.2 |
| Claudev2 | 68.7 | 61.7 | 75.4 | 75.5 | 81 | 67.4 | 74 | 78.1 | 74.8 | 79.2 | 73.6 |
| Claudev21 | 72.6 | 66 | 75.7 | 77.2 | 82 | 68.5 | 73.2 | 78.6 | 72.7 | 77.1 | 74.4 |
| Gemini-pro | 73.7 | 60.2 | 75.7 | 77.6 | 86.9 | 74.2 | 71.9 | 77.6 | 74 | 83.1 | 75.5 |
| GPT4 | 82.7 | 71.1 | 83.1 | 83.3 | 87.9 | 79.5 | 84 | 82.4 | 79.6 | 87 | 82.1 |
| Human Perf. | 90.8 | 87.5 | 89.4 | 90 | 91.8 | 87.4 | 96.9 | 89.3 | 90.7 | 95.4 | 90.9 |
We release the data for the 10 domains in the SummEdits benchmark in the data/summedits folder.
The SummEdits_Benchmark.ipynb notebook provides information on how to access open, and visualize the dataset.
As part of the paper, we annotated 3.6k explanations generated by models justifying their choice to identify a summary as inconsistent. The annotations are available in data/factcc/factcc_explanation_annotation.json. The notebook FactCC_Explanation_Annotation.ipynb shows how to load/view the annotations.
We release all prompts that were used in experiments in the paper in the prompts/ folder. More specifically:
- summedits/factcc is a folder that contains the 26 prompts that we experimented with in initial FactCC experiments (Section 3.1)
- summedits/step2_consistent.txt and summedits/step2_inconsistent.txt were the prompts used in Step 2 of the SummEdits protocol to generate edits of seed summaries. (Section 5.2)
- summedits/standard_zs_prompt.txt is the zero-shot prompt that was used to assess all LLM model performance on the SummEdits benchmark. (Section 6.3)
- summedits/edit_typing_gpt4.txt is a few-shot prompt used to predict the types of edits for inconsistent samples in SummEdits (Section 6.4)
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for factualNLG
Similar Open Source Tools
factualNLG
FactualNLG is a tool designed to analyze the consistency of edits in summaries. It includes a benchmark with various LLM models, data release for the SummEdits benchmark, explanation analysis for identifying inconsistent summaries, and prompts used in experiments.
ML-AI-2-LT
ML-AI-2-LT is a repository that serves as a glossary for machine learning and deep learning concepts. It contains translations and explanations of various terms related to artificial intelligence, including definitions and notes. Users can contribute by filling issues for unclear concepts or by submitting pull requests with suggestions or additions. The repository aims to provide a comprehensive resource for understanding key terminology in the field of AI and machine learning.
MobileLLM
This repository contains the training code of MobileLLM, a language model optimized for on-device use cases with fewer than a billion parameters. It integrates SwiGLU activation function, deep and thin architectures, embedding sharing, and grouped-query attention to achieve high-quality LLMs. MobileLLM-125M/350M shows significant accuracy improvements over previous models on zero-shot commonsense reasoning tasks. The design philosophy scales effectively to larger models, with state-of-the-art results for MobileLLM-600M/1B/1.5B.

LLM-for-Healthcare
The repository 'LLM-for-Healthcare' provides a comprehensive survey of large language models (LLMs) for healthcare, covering data, technology, applications, and accountability and ethics. It includes information on various LLM models, training data, evaluation methods, and computation costs. The repository also discusses tasks such as NER, text classification, question answering, dialogue systems, and generation of medical reports from images in the healthcare domain.
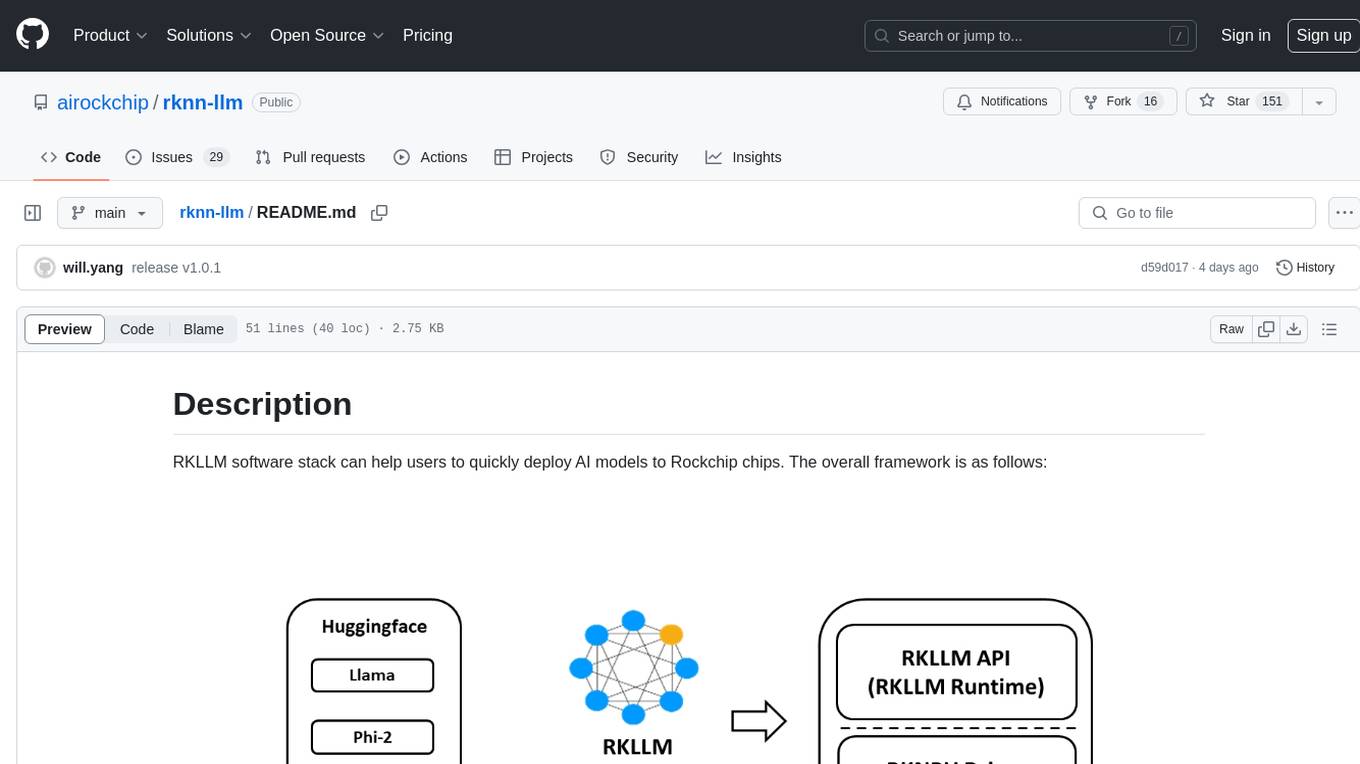
rknn-llm
RKLLM software stack is a toolkit designed to help users quickly deploy AI models to Rockchip chips. It consists of RKLLM-Toolkit for model conversion and quantization, RKLLM Runtime for deploying models on Rockchip NPU platform, and RKNPU kernel driver for hardware interaction. The toolkit supports RK3588 and RK3576 series chips and various models like TinyLLAMA, Qwen, Phi, ChatGLM3, Gemma, InternLM2, and MiniCPM. Users can download packages, docker images, examples, and docs from RKLLM_SDK. Additionally, RKNN-Toolkit2 SDK is available for deploying additional AI models.
Awesome-AgenticLLM-RL-Papers
This repository serves as the official source for the survey paper 'The Landscape of Agentic Reinforcement Learning for LLMs: A Survey'. It provides an extensive overview of various algorithms, methods, and frameworks related to Agentic RL, including detailed information on different families of algorithms, their key mechanisms, objectives, and links to relevant papers and resources. The repository covers a wide range of tasks such as Search & Research Agent, Code Agent, Mathematical Agent, GUI Agent, RL in Vision Agents, RL in Embodied Agents, and RL in Multi-Agent Systems. Additionally, it includes information on environments, frameworks, and methods suitable for different tasks related to Agentic RL and LLMs.

kumo-search
Kumo search is an end-to-end search engine framework that supports full-text search, inverted index, forward index, sorting, caching, hierarchical indexing, intervention system, feature collection, offline computation, storage system, and more. It runs on the EA (Elastic automic infrastructure architecture) platform, enabling engineering automation, service governance, real-time data, service degradation, and disaster recovery across multiple data centers and clusters. The framework aims to provide a ready-to-use search engine framework to help users quickly build their own search engines. Users can write business logic in Python using the AOT compiler in the project, which generates C++ code and binary dynamic libraries for rapid iteration of the search engine.
Awesome-AISourceHub
Awesome-AISourceHub is a repository that collects high-quality information sources in the field of AI technology. It serves as a synchronized source of information to avoid information gaps and information silos. The repository aims to provide valuable resources for individuals such as AI book authors, enterprise decision-makers, and tool developers who frequently use Twitter to share insights and updates related to AI advancements. The platform emphasizes the importance of accessing information closer to the source for better quality content. Users can contribute their own high-quality information sources to the repository by following specific steps outlined in the contribution guidelines. The repository covers various platforms such as Twitter, public accounts, knowledge planets, podcasts, blogs, websites, YouTube channels, and more, offering a comprehensive collection of AI-related resources for individuals interested in staying updated with the latest trends and developments in the AI field.
Awesome-AGI
Awesome-AGI is a curated list of resources related to Artificial General Intelligence (AGI), including models, pipelines, applications, and concepts. It provides a comprehensive overview of the current state of AGI research and development, covering various aspects such as model training, fine-tuning, deployment, and applications in different domains. The repository also includes resources on prompt engineering, RLHF, LLM vocabulary expansion, long text generation, hallucination mitigation, controllability and safety, and text detection. It serves as a valuable resource for researchers, practitioners, and anyone interested in the field of AGI.
so-vits-models
This repository collects various LLM, AI-related models, applications, and datasets, including LLM-Chat for dialogue models, LLMs for large models, so-vits-svc for sound-related models, stable-diffusion for image-related models, and virtual-digital-person for generating videos. It also provides resources for deep learning courses and overviews, AI competitions, and specific AI tasks such as text, image, voice, and video processing.
ai-game-development-tools
Here we will keep track of the AI Game Development Tools, including LLM, Agent, Code, Writer, Image, Texture, Shader, 3D Model, Animation, Video, Audio, Music, Singing Voice and Analytics. 🔥 * Tool (AI LLM) * Game (Agent) * Code * Framework * Writer * Image * Texture * Shader * 3D Model * Avatar * Animation * Video * Audio * Music * Singing Voice * Speech * Analytics * Video Tool

Awesome_LLM_System-PaperList
Since the emergence of chatGPT in 2022, the acceleration of Large Language Model has become increasingly important. Here is a list of papers on LLMs inference and serving.
Data-and-AI-Concepts
This repository is a curated collection of data science and AI concepts and IQs, covering topics from foundational mathematics to cutting-edge generative AI concepts. It aims to support learners and professionals preparing for various data science roles by providing detailed explanations and notebooks for each concept.
linktre-tools
The 'linktre-tools' repository is a collection of tools and resources for independent developers, AI products, cross-border e-commerce, and self-media office assistance. It aims to provide a curated list of tools and products in these areas. Users are encouraged to contribute by submitting pull requests and raising issues for continuous updates. The repository covers a wide range of topics including AI tools, independent development tools, popular AI products, tools for web development, online tools, media operations, and cross-border e-commerce resources.
ai-reference-models
The Intel® AI Reference Models repository contains links to pre-trained models, sample scripts, best practices, and tutorials for popular open-source machine learning models optimized by Intel to run on Intel® Xeon® Scalable processors and Intel® Data Center GPUs. The purpose is to quickly replicate complete software environments showcasing the AI capabilities of Intel platforms. It includes optimizations for popular deep learning frameworks like TensorFlow and PyTorch, with additional plugins/extensions for improved performance. The repository is licensed under Apache License Version 2.0.
For similar tasks
factualNLG
FactualNLG is a tool designed to analyze the consistency of edits in summaries. It includes a benchmark with various LLM models, data release for the SummEdits benchmark, explanation analysis for identifying inconsistent summaries, and prompts used in experiments.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.