
ai-reference-models
Intel® AI Reference Models: contains Intel optimizations for running deep learning workloads on Intel® Xeon® Scalable processors and Intel® Data Center GPUs
Stars: 676
The Intel® AI Reference Models repository contains links to pre-trained models, sample scripts, best practices, and tutorials for popular open-source machine learning models optimized by Intel to run on Intel® Xeon® Scalable processors and Intel® Data Center GPUs. The purpose is to quickly replicate complete software environments showcasing the AI capabilities of Intel platforms. It includes optimizations for popular deep learning frameworks like TensorFlow and PyTorch, with additional plugins/extensions for improved performance. The repository is licensed under Apache License Version 2.0.
README:
This repository contains links to pre-trained models, sample scripts, best practices, and step-by-step tutorials for many popular open-source machine learning models optimized by Intel to run on Intel® Xeon® Scalable processors and Intel® Data Center GPUs.
Containers for running the workloads can be found at Intel® AI Containers.
Intel® AI Reference Models in a Jupyter Notebook is also available for the listed workloads
Intel optimizes popular deep learning frameworks such as TensorFlow* and PyTorch* by contributing to the upstream projects. Additional optimizations are built into plugins/extensions such as the Intel Extension for Pytorch* and the Intel Extension for TensorFlow*. Popular neural network models running against common datasets are the target workloads that drive these optimizations.
The purpose of the Intel® AI Reference Models repository (and associated containers) is to quickly replicate the complete software environment that demonstrates the best-known performance of each of these target model/dataset combinations. When executed in optimally-configured hardware environments, these software environments showcase the AI capabilities of Intel platforms.
DISCLAIMER: These scripts are not intended for benchmarking Intel platforms. For any performance and/or benchmarking information on specific Intel platforms, visit https://www.intel.ai/blog.
Intel is committed to respecting human rights and avoiding causing or contributing to adverse impacts on human rights. See Intel’s Global Human Rights Principles. Intel’s products and software are intended only to be used in applications that do not cause or contribute to adverse impacts on human rights.
The Intel® AI Reference Models is licensed under Apache License Version 2.0.
To the extent that any public datasets are referenced by Intel or accessed using tools or code on this site those datasets are provided by the third party indicated as the data source. Intel does not create the data, or datasets, and does not warrant their accuracy or quality. By accessing the public dataset(s) you agree to the terms associated with those datasets and that your use complies with the applicable license.
Please check the list of datasets used in Intel® AI Reference Models in datasets directory.
Intel expressly disclaims the accuracy, adequacy, or completeness of any public datasets, and is not liable for any errors, omissions, or defects in the data, or for any reliance on the data. Intel is not liable for any liability or damages relating to your use of public datasets.
The model documentation in the tables below have information on the prerequisites to run each model. The model scripts run on Linux. Certain models are also able to run using bare metal on Windows. For more information and a list of models that are supported on Windows, see the documentation here.
Instructions available to run on Sapphire Rapids.
For best performance on Intel® Data Center GPU Flex and Max Series, please check the list of supported workloads. It provides instructions to run inference and training using Intel(R) Extension for PyTorch or Intel(R) Extension for TensorFlow.
| Model | Framework | Mode | Model Documentation | Benchmark/Test Dataset |
|---|---|---|---|---|
| ResNet 50v1.5 Sapphire Rapids | TensorFlow | Inference | Int8 FP32 BFloat16 BFloat32 | ImageNet 2012 |
| ResNet 50v1.5 Sapphire Rapids | TensorFlow | Training | FP32 BFloat16 BFloat32 | ImageNet 2012 |
| ResNet 50 | PyTorch | Inference | Int8 FP32 BFloat16 BFloat32 | [ImageNet 2012] |
| ResNet 50 | PyTorch | Training | FP32 BFloat16 BFloat32 | [ImageNet 2012] |
| Vision Transformer | PyTorch | Inference | FP32 BFloat16 BFloat32 FP16 INT8 | [ImageNet 2012] |
| Model | Framework | Mode | Model Documentation | Benchmark/Test Dataset |
|---|---|---|---|---|
| 3D U-Net | TensorFlow | Inference | FP32 BFloat16 Int8 | BRATS 2018 |
| Model | Framework | Mode | Model Documentation | Benchmark/Test Dataset |
|---|---|---|---|---|
| BERT | TensorFlow | Inference | FP32 | MRPC |
| Model | Framework | Mode | Model Documentation | Benchmark/Test Dataset |
|---|---|---|---|---|
| Mask R-CNN | PyTorch | Inference | FP32 BFloat16 BFloat32 | COCO 2017 |
| Mask R-CNN | PyTorch | Training | FP32 BFloat16 BFloat32 | COCO 2017 |
| SSD-ResNet34 | PyTorch | Inference | FP32 Int8 BFloat16 BFloat32 | COCO 2017 |
| SSD-ResNet34 | PyTorch | Training | FP32 BFloat16 BFloat32 | COCO 2017 |
| Yolo V7 | PyTorch | Inference | Int8 FP32 FP16 BFloat16 BFloat32 | [COCO 2017](/models_v2/pytorch/yolov7/inference/cpu/README.md## Prepare Dataset) |
| Model | Framework | Mode | Model Documentation | Benchmark/Test Dataset |
|---|---|---|---|---|
| Wide & Deep | TensorFlow | Inference | FP32 | Census Income dataset |
| DLRM | PyTorch | Inference | FP32 Int8 BFloat16 BFloat32 | Criteo Terabyte |
| DLRM | PyTorch | Training | FP32 BFloat16 BFloat32 | Criteo Terabyte |
| DLRM v2 | PyTorch | Inference | FP32 FP16 BFloat16 BFloat32 Int8 | Criteo 1TB Click Logs dataset |
| Model | Framework | Mode | Model Documentation | Benchmark/Test Dataset |
|---|---|---|---|---|
| Stable Diffusion | TensorFlow | Inference | FP32 BFloat16 FP16 | COCO 2017 validation dataset |
| Stable Diffusion | PyTorch | Inference | FP32 BFloat16 FP16 BFloat32 Int8-FP32 Int8-BFloat16 | COCO 2017 validation dataset |
| Stable Diffusion | PyTorch | Training | FP32 BFloat16 FP16 BFloat32 | cat images |
| Latent Consistency Models(LCM) | PyTorch | Inference | FP32 BFloat16 FP16 BFloat32 Int8-FP32 Int8-BFloat16 | COCO 2017 validation dataset |
| Model | Framework | Mode | Model Documentation | Benchmark/Test Dataset |
|---|---|---|---|---|
| GraphSAGE | TensorFlow | Inference | FP32 BFloat16 FP16 Int8 BFloat32 | Protein Protein Interaction |
*Means the model belongs to MLPerf models and will be supported long-term.
| Model | Framework | Mode | GPU Type | Model Documentation |
|---|---|---|---|---|
| ResNet 50v1.5 | TensorFlow | Inference | Flex Series | Float32 TF32 Float16 BFloat16 Int8 |
| ResNet 50 v1.5 | TensorFlow | Training | Max Series | BFloat16 FP32 |
| ResNet 50 v1.5 | PyTorch | Inference | Flex Series, Max Series, Arc Series | Int8 FP32 FP16 TF32 |
| ResNet 50 v1.5 | PyTorch | Training | Max Series, Arc Series | BFloat16 TF32 FP32 |
| DistilBERT | PyTorch | Inference | Flex Series, Max Series | FP32 FP16 BF16 TF32 |
| DLRM v1 | PyTorch | Inference | Flex Series | FP16 FP32 |
| SSD-MobileNet* | PyTorch | Inference | Arc Series | INT8 FP16 FP32 |
| EfficientNet | PyTorch | Inference | Flex Series | FP16 BF16 FP32 |
| EfficientNet | TensorFlow | Inference | Flex Series | FP16 |
| FBNet | PyTorch | Inference | Flex Series | FP16 BF16 FP32 |
| Wide Deep Large Dataset | TensorFlow | Inference | Flex Series | FP16 |
| YOLO V5 | PyTorch | Inference | Flex Series | FP16 |
| BERT large | PyTorch | Inference | Max Series, Arc Series | BFloat16 FP32 FP16 |
| BERT large | PyTorch | Training | Max Series, Arc Series | BFloat16 FP32 TF32 |
| BERT large | TensorFlow | Training | Max Series | BFloat16 TF32 FP32 |
| DLRM v2 | PyTorch | Inference | Max Series | FP32 BF16 |
| DLRM v2 | PyTorch | Training | Max Series | FP32 TF32 BF16 |
| 3D-Unet | PyTorch | Inference | Max Series | FP16 INT8 FP32 |
| 3D-Unet | TensorFlow | Training | Max Series | BFloat16 FP32 |
| Stable Diffusion | PyTorch | Inference | Flex Series, Max Series, Arc Series | FP16 FP32 |
| Stable Diffusion | TensorFlow | Inference | Flex Series | FP16 FP32 |
| Mask R-CNN | TensorFlow | Inference | Flex Series | FP32 Float16 |
| Mask R-CNN | TensorFlow | Training | Max Series | FP32 BFloat16 |
| Swin Transformer | PyTorch | Inference | Flex Series | FP16 |
| FastPitch | PyTorch | Inference | Flex Series | FP16 |
| UNet++ | PyTorch | Inference | Flex Series | FP16 |
| RNN-T | PyTorch | Inference | Max Series | FP16 BF16 FP32 |
| RNN-T | PyTorch | Training | Max Series | FP32 BF16 TF32 |
| IFRNet | PyTorch | Inference | Flex Series | FP16 |
| RIFE | PyTorch | Inference | Flex Series | FP16 |
If you would like to add a new benchmarking script, please use this guide.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for ai-reference-models
Similar Open Source Tools
ai-reference-models
The Intel® AI Reference Models repository contains links to pre-trained models, sample scripts, best practices, and tutorials for popular open-source machine learning models optimized by Intel to run on Intel® Xeon® Scalable processors and Intel® Data Center GPUs. The purpose is to quickly replicate complete software environments showcasing the AI capabilities of Intel platforms. It includes optimizations for popular deep learning frameworks like TensorFlow and PyTorch, with additional plugins/extensions for improved performance. The repository is licensed under Apache License Version 2.0.
models
The Intel® AI Reference Models repository contains links to pre-trained models, sample scripts, best practices, and tutorials for popular open-source machine learning models optimized by Intel to run on Intel® Xeon® Scalable processors and Intel® Data Center GPUs. It aims to replicate the best-known performance of target model/dataset combinations in optimally-configured hardware environments. The repository will be deprecated upon the publication of v3.2.0 and will no longer be maintained or published.
Model-References
The 'Model-References' repository contains examples for training and inference using Intel Gaudi AI Accelerator. It includes models for computer vision, natural language processing, audio, generative models, MLPerf™ training, and MLPerf™ inference. The repository provides performance data and model validation information for various frameworks like PyTorch. Users can find examples of popular models like ResNet, BERT, and Stable Diffusion optimized for Intel Gaudi AI accelerator.
Azure-AIGEN-demos
Microsoft Foundry is a unified Azure platform-as-a-service offering for enterprise AI operations, model builders, and application development. This foundation combines production-grade infrastructure with friendly interfaces, enabling developers to focus on building applications rather than managing infrastructure. Microsoft Foundry unifies agents, models, and tools under a single management grouping with built-in enterprise-readiness capabilities including tracing, monitoring, evaluations, and customizable enterprise setup configurations. The platform provides streamlined management through unified Role-based access control (RBAC), networking, and policies under one Azure resource provider namespace.
ai-game-development-tools
Here we will keep track of the AI Game Development Tools, including LLM, Agent, Code, Writer, Image, Texture, Shader, 3D Model, Animation, Video, Audio, Music, Singing Voice and Analytics. 🔥 * Tool (AI LLM) * Game (Agent) * Code * Framework * Writer * Image * Texture * Shader * 3D Model * Avatar * Animation * Video * Audio * Music * Singing Voice * Speech * Analytics * Video Tool
LLM4EC
LLM4EC is an interdisciplinary research repository focusing on the intersection of Large Language Models (LLM) and Evolutionary Computation (EC). It provides a comprehensive collection of papers and resources exploring various applications, enhancements, and synergies between LLM and EC. The repository covers topics such as LLM-assisted optimization, EA-based LLM architecture search, and applications in code generation, software engineering, neural architecture search, and other generative tasks. The goal is to facilitate research and development in leveraging LLM and EC for innovative solutions in diverse domains.
Data-and-AI-Concepts
This repository is a curated collection of data science and AI concepts and IQs, covering topics from foundational mathematics to cutting-edge generative AI concepts. It aims to support learners and professionals preparing for various data science roles by providing detailed explanations and notebooks for each concept.

Awesome_LLM_System-PaperList
Since the emergence of chatGPT in 2022, the acceleration of Large Language Model has become increasingly important. Here is a list of papers on LLMs inference and serving.
Multiverse_of_100-_data_science_project_series
This repository contains a series of 100+ data science projects covering a wide range of topics and techniques. Each project is designed to help learners practice and improve their data science skills by working on real-world datasets and problems. The projects include data cleaning, exploratory data analysis, machine learning modeling, and data visualization. Whether you are a beginner looking to build a portfolio or an experienced data scientist wanting to sharpen your skills, this repository offers a diverse set of projects to work on.

LLM-KG4QA
LLM-KG4QA is a repository focused on the integration of Large Language Models (LLMs) and Knowledge Graphs (KGs) for Question Answering (QA). It covers various aspects such as using KGs as background knowledge, reasoning guideline, and refiner/filter. The repository provides detailed information on pre-training, fine-tuning, and Retrieval Augmented Generation (RAG) techniques for enhancing QA performance. It also explores complex QA tasks like Explainable QA, Multi-Modal QA, Multi-Document QA, Multi-Hop QA, Multi-run and Conversational QA, Temporal QA, Multi-domain and Multilingual QA, along with advanced topics like Optimization and Data Management. Additionally, it includes benchmark datasets, industrial and scientific applications, demos, and related surveys in the field.

Awesome-Resource-Efficient-LLM-Papers
A curated list of high-quality papers on resource-efficient Large Language Models (LLMs) with a focus on various aspects such as architecture design, pre-training, fine-tuning, inference, system design, and evaluation metrics. The repository covers topics like efficient transformer architectures, non-transformer architectures, memory efficiency, data efficiency, model compression, dynamic acceleration, deployment optimization, support infrastructure, and other related systems. It also provides detailed information on computation metrics, memory metrics, energy metrics, financial cost metrics, network communication metrics, and other metrics relevant to resource-efficient LLMs. The repository includes benchmarks for evaluating the efficiency of NLP models and references for further reading.
GenAI-Learning
GenAI-Learning is a repository dedicated to providing resources and courses for individuals interested in Generative AI. It covers a wide range of topics from prompt engineering to user-centered design, offering courses on LLM Bootcamp, DeepLearning AI, Microsoft Copilot Learning, Amazon Generative AI, Google Cloud Skills, NVIDIA Learn, Oracle Cloud, and IBM AI Learn. The repository includes detailed course descriptions, partners, and topics for each course, making it a valuable resource for AI enthusiasts and professionals.

open-llms
Open LLMs is a repository containing various Large Language Models licensed for commercial use. It includes models like T5, GPT-NeoX, UL2, Bloom, Cerebras-GPT, Pythia, Dolly, and more. These models are designed for tasks such as transfer learning, language understanding, chatbot development, code generation, and more. The repository provides information on release dates, checkpoints, papers/blogs, parameters, context length, and licenses for each model. Contributions to the repository are welcome, and it serves as a resource for exploring the capabilities of different language models.
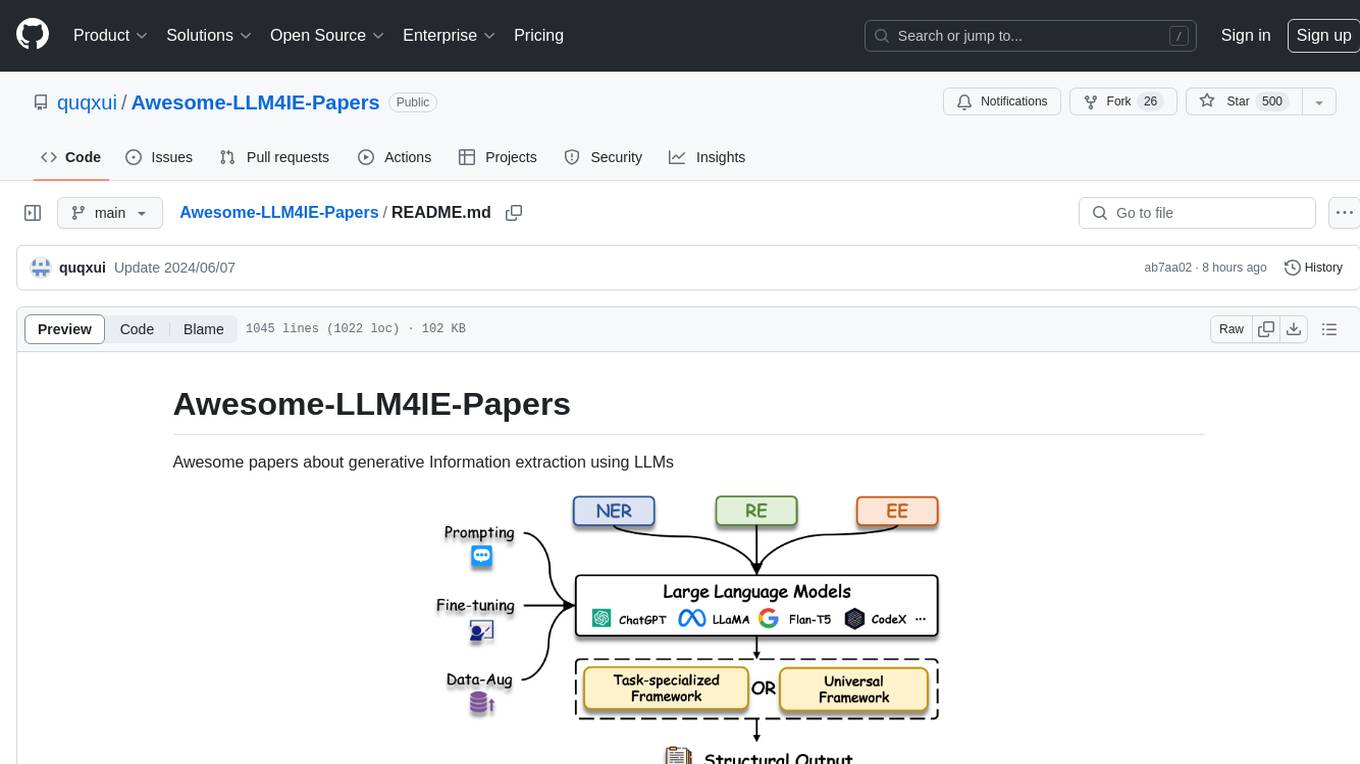
For similar tasks
awesome-open-data-annotation
At ZenML, we believe in the importance of annotation and labeling workflows in the machine learning lifecycle. This repository showcases a curated list of open-source data annotation and labeling tools that are actively maintained and fit for purpose. The tools cover various domains such as multi-modal, text, images, audio, video, time series, and other data types. Users can contribute to the list and discover tools for tasks like named entity recognition, data annotation for machine learning, image and video annotation, text classification, sequence labeling, object detection, and more. The repository aims to help users enhance their data-centric workflows by leveraging these tools.
ai-reference-models
The Intel® AI Reference Models repository contains links to pre-trained models, sample scripts, best practices, and tutorials for popular open-source machine learning models optimized by Intel to run on Intel® Xeon® Scalable processors and Intel® Data Center GPUs. The purpose is to quickly replicate complete software environments showcasing the AI capabilities of Intel platforms. It includes optimizations for popular deep learning frameworks like TensorFlow and PyTorch, with additional plugins/extensions for improved performance. The repository is licensed under Apache License Version 2.0.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.