
MobileLLM
MobileLLM Optimizing Sub-billion Parameter Language Models for On-Device Use Cases. In ICML 2024.
Stars: 917
This repository contains the training code of MobileLLM, a language model optimized for on-device use cases with fewer than a billion parameters. It integrates SwiGLU activation function, deep and thin architectures, embedding sharing, and grouped-query attention to achieve high-quality LLMs. MobileLLM-125M/350M shows significant accuracy improvements over previous models on zero-shot commonsense reasoning tasks. The design philosophy scales effectively to larger models, with state-of-the-art results for MobileLLM-600M/1B/1.5B.
README:
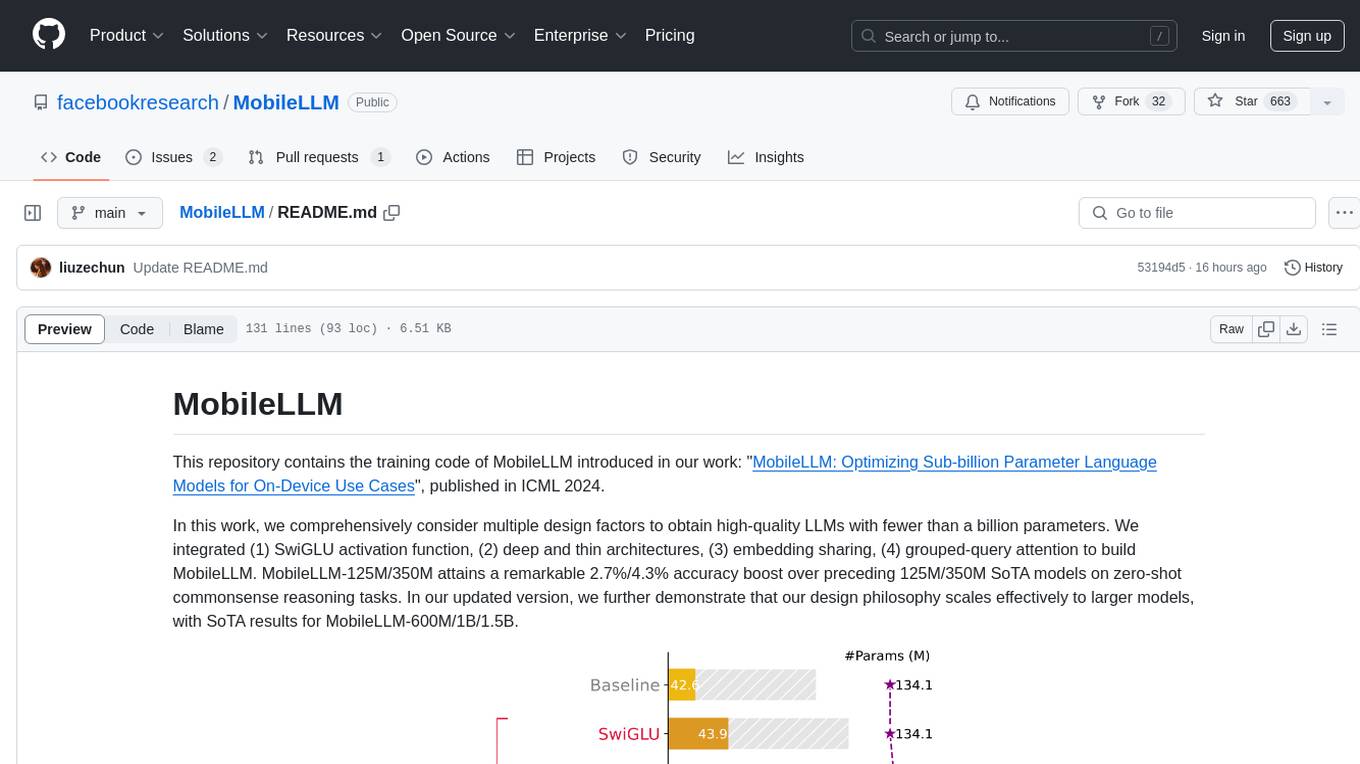
This repository contains the training code of MobileLLM introduced in our work: "MobileLLM: Optimizing Sub-billion Parameter Language Models for On-Device Use Cases", published in ICML 2024.
In this work, we comprehensively consider multiple design factors to obtain high-quality LLMs with fewer than a billion parameters. We integrated (1) SwiGLU activation function, (2) deep and thin architectures, (3) embedding sharing, (4) grouped-query attention to build MobileLLM. MobileLLM-125M/350M attains a remarkable 2.7%/4.3% accuracy boost over preceding 125M/350M SoTA models on zero-shot commonsense reasoning tasks. In our updated version, we further demonstrate that our design philosophy scales effectively to larger models, with SoTA results for MobileLLM-600M/1B/1.5B.

If you find our code useful for your research, please consider citing:
@article{liu2024mobilellm,
title={MobileLLM: Optimizing Sub-billion Parameter Language Models for On-Device Use Cases},
author={Liu, Zechun and Zhao, Changsheng and Iandola, Forrest and Lai, Chen and Tian, Yuandong and Fedorov, Igor and Xiong, Yunyang and Chang, Ernie and Shi, Yangyang and Krishnamoorthi, Raghuraman and others},
journal={arXiv preprint arXiv:2402.14905},
year={2024}
}
- python 3.9, pytorch >= 2.0
- pip install -r requirement.txt
Dividing a tokenized dataset or tokenize your own dataset, and even distribute it across the total number of training nodes, where each node comprises 1x8 GPUs. Next, organize the data into the following structure:
- basepath
- 1
- xxx.jsonl
- 2
- xxx.jsonl
- ...
- #nodes
- xxx.jsonl
- 1
Each line of a jsonl file is a key-value pair of tokenized data {"token_ids": [1,2,3,4,...]}.
Our training code is compatible with the data pre-processing method in https://github.com/LLM360/amber-data-prep.
The script pretrain.sh is provided to initiate training on a 1x8 node setup using torchrun. This script can be modified to adjust the --nnodes parameter and other settings to suit different multi-node configurations, such as those using slurm or torchx. The learning rate in the script is for 1x8 node with a batch size of 32. If you increase the number of nodes or the batch size, you need to increase the learning rate linearly.
Steps to run:
- In
pretrain.shfile, specify the--train_data_local_pathto the pre-processed data in Step 2 and--input_model_filenameto./configs/{model_size}/. - Run
bash pretrain.sh
The model weights is still under legal review. If you have any questions, feel free to email (zechunliu at meta dot com) and (cszhao at meta dot com)
It takes the following number of days to train MobileLLM on 1T tokens using 32 NVIDIA A100 80G GPUs.
| 125M | 350M | 600M | 1B | 1.5B |
|---|---|---|---|---|
| ~3 days | ~6 days | ~8 days | ~12 days | ~18 days |
| model | boolq | piqa | siqa | hellaswag | winogrande | arc_easy | arc_challenge | obqa | avg. |
|---|---|---|---|---|---|---|---|---|---|
| OPT-125M | 41.3 | 25.2 | 57.5 | 62.0 | 41.9 | 31.1 | 31.2 | 50.8 | 42.6 |
| GPT-neo-125M | 40.7 | 24.8 | 61.3 | 62.5 | 41.9 | 29.7 | 31.6 | 50.7 | 42.9 |
| Pythia-160M | 40.0 | 25.3 | 59.5 | 62.0 | 41.5 | 29.9 | 31.2 | 50.9 | 42.5 |
| MobileLLM-125M | 43.9 | 27.1 | 60.2 | 65.3 | 42.4 | 38.9 | 39.5 | 53.1 | 46.3 |
| MobileLLM-LS-125M | 45.8 | 28.7 | 60.4 | 65.7 | 42.9 | 39.5 | 41.1 | 52.1 | 47.0 |
| model | boolq | piqa | siqa | hellaswag | winogrande | arc_easy | arc_challenge | obqa | avg. |
|---|---|---|---|---|---|---|---|---|---|
| OPT-350M | 41.9 | 25.7 | 54.0 | 64.8 | 42.6 | 36.2 | 33.3 | 52.4 | 43.9 |
| Pythia-410M | 47.1 | 30.3 | 55.3 | 67.2 | 43.1 | 40.1 | 36.2 | 53.4 | 46.6 |
| MobileLLM-350M | 53.8 | 33.5 | 62.4 | 68.6 | 44.7 | 49.6 | 40.0 | 57.6 | 51.3 |
| MobileLLM-LS-350M | 54.4 | 32.5 | 62.8 | 69.8 | 44.1 | 50.6 | 45.8 | 57.2 | 52.1 |
| model | boolq | piqa | siqa | hellaswag | winogrande | arc_easy | arc_challenge | obqa | avg. |
|---|---|---|---|---|---|---|---|---|---|
| Qwen1.5-500M | 54.7 | 32.1 | 46.9 | 68.9 | 46.0 | 48.8 | 37.7 | 55.0 | 48.8 |
| BLOOM-560M | 43.7 | 27.5 | 53.7 | 65.1 | 42.5 | 36.5 | 32.6 | 52.2 | 44.2 |
| MobiLlama-800M | 52.0 | 31.7 | 54.6 | 73.0 | 43.3 | 52.3 | 42.5 | 56.3 | 50.7 |
| MobileLLM-600M | 58.1 | 35.8 | 61.0 | 72.3 | 44.9 | 55.9 | 47.9 | 58.6 | 54.3 |
| model | boolq | piqa | siqa | hellaswag | winogrande | arc_easy | arc_challenge | obqa | avg. |
|---|---|---|---|---|---|---|---|---|---|
| Pythia-1B | 49.9 | 30.4 | 58.7 | 69.2 | 43.3 | 47.4 | 38.6 | 52.2 | 48.7 |
| MobiLlama-1B | 59.7 | 38.4 | 59.2 | 74.5 | 44.9 | 62.0 | 43.7 | 59.0 | 55.2 |
| Falcon-1B | 59.5 | 38.4 | 63.9 | 74.6 | 44.6 | 62.9 | 45.6 | 60.9 | 56.3 |
| BLOOM-1.1B | 47.6 | 27.3 | 58.6 | 67.0 | 42.4 | 42.2 | 36.6 | 53.8 | 46.9 |
| TinyLlama-1.1B | 59.2 | 37.1 | 58.1 | 72.9 | 43.9 | 59.1 | 44.7 | 58.8 | 54.2 |
| MobileLLM-1B | 63.0 | 39.0 | 66.7 | 74.4 | 45.0 | 61.4 | 46.8 | 62.3 | 57.3 |
| model | boolq | piqa | siqa | hellaswag | winogrande | arc_easy | arc_challenge | obqa | avg. |
|---|---|---|---|---|---|---|---|---|---|
| GPT-neo-1.3B | 51.3 | 33.0 | 61.8 | 70.9 | 43.7 | 48.6 | 41.2 | 54.5 | 50.6 |
| OPT-1.3B | 54.4 | 31.7 | 58.4 | 71.5 | 44.7 | 53.7 | 44.6 | 59.1 | 52.3 |
| BLOOM-1.7B | 50.9 | 31.2 | 61.7 | 70.0 | 43.2 | 47.2 | 36.2 | 56.1 | 49.6 |
| Qwen1.5-1.8B | 61.1 | 36.5 | 68.3 | 74.1 | 47.2 | 60.4 | 42.9 | 61.2 | 56.5 |
| GPT-neo-2.7B | 55.8 | 34.3 | 62.4 | 72.9 | 43.6 | 55.6 | 40.0 | 57.9 | 52.8 |
| OPT-2.7B | 56.6 | 34.6 | 61.8 | 74.5 | 45.6 | 60.2 | 48.2 | 59.6 | 55.1 |
| Pythia-2.8B | 59.4 | 38.9 | 66.1 | 73.8 | 44.5 | 59.6 | 45.0 | 59.4 | 55.8 |
| BLOOM-3B | 55.1 | 33.6 | 62.1 | 70.5 | 43.2 | 53.9 | 41.6 | 58.2 | 52.3 |
| MobileLLM-1.5B | 67.5 | 40.9 | 65.7 | 74.8 | 46.4 | 64.5 | 50.5 | 64.7 | 59.4 |
This code is partially based on Hugging Face transformer repo.
Zechun Liu, Meta Inc (zechunliu at meta dot com)
Changsheng Zhao, Meta Inc (cszhao at meta dot com)
SpinQuant: LLM Quantization with Learned Rotations [Paper] [Code]
LLM-QAT: Data-Free Quantization Aware Training for Large Language Models [Paper] [Code]
BiT is CC-BY-NC 4.0 licensed as of now.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for MobileLLM
Similar Open Source Tools
MobileLLM
This repository contains the training code of MobileLLM, a language model optimized for on-device use cases with fewer than a billion parameters. It integrates SwiGLU activation function, deep and thin architectures, embedding sharing, and grouped-query attention to achieve high-quality LLMs. MobileLLM-125M/350M shows significant accuracy improvements over previous models on zero-shot commonsense reasoning tasks. The design philosophy scales effectively to larger models, with state-of-the-art results for MobileLLM-600M/1B/1.5B.
factualNLG
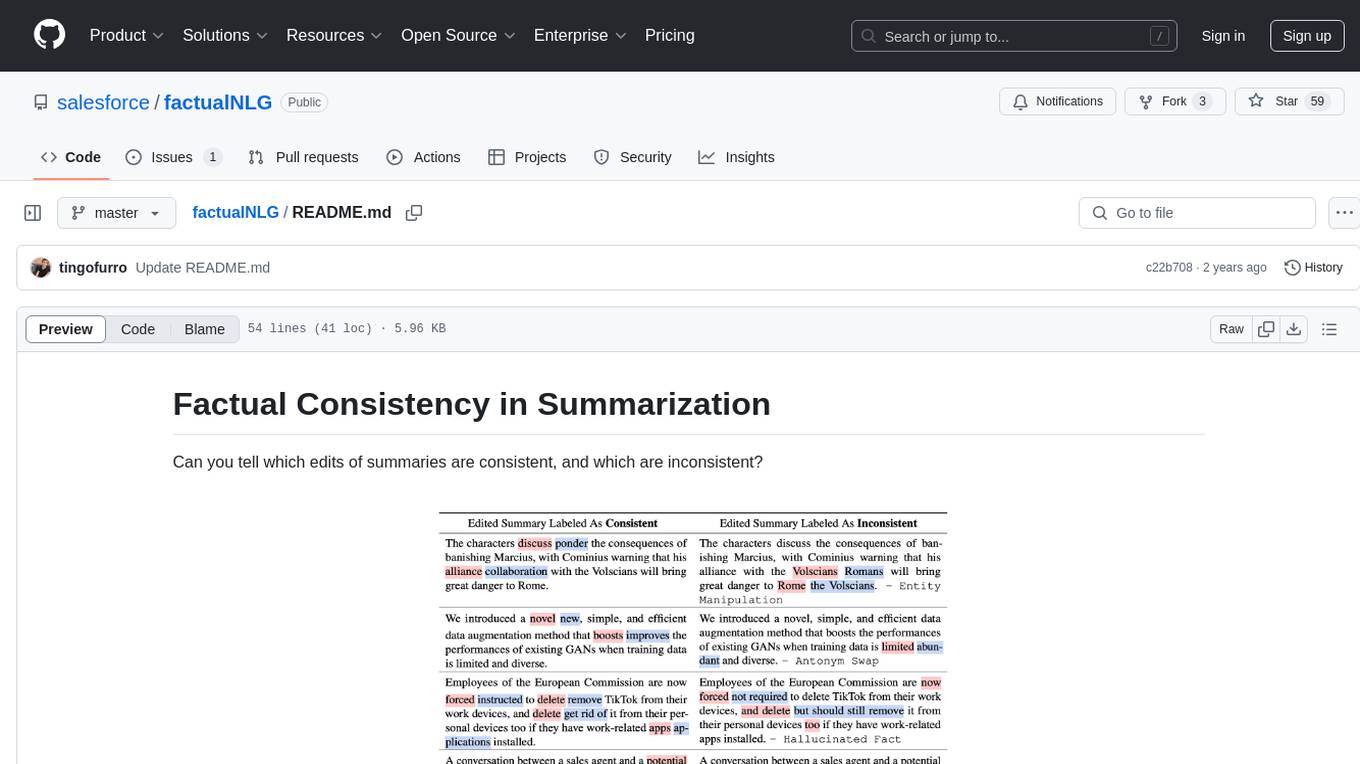
FactualNLG is a tool designed to analyze the consistency of edits in summaries. It includes a benchmark with various LLM models, data release for the SummEdits benchmark, explanation analysis for identifying inconsistent summaries, and prompts used in experiments.
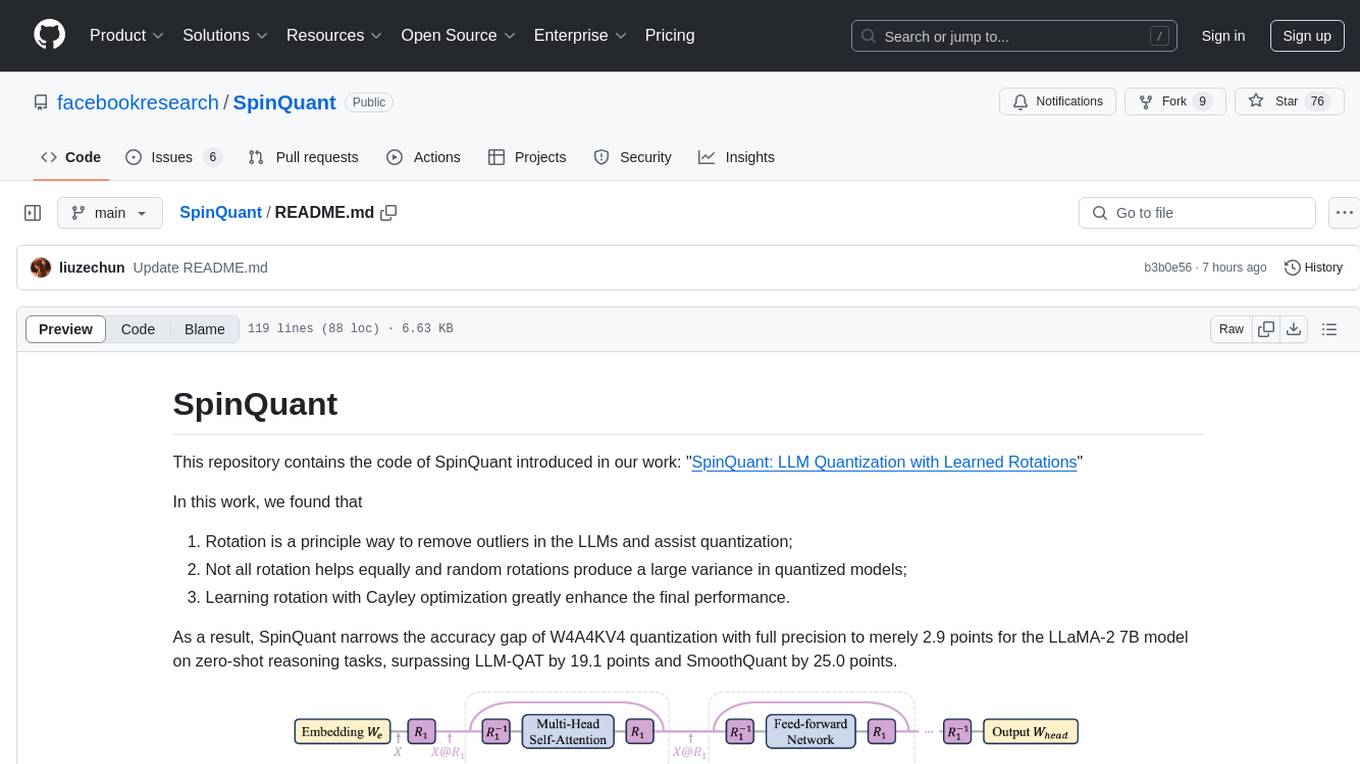
SpinQuant
SpinQuant is a tool designed for LLM quantization with learned rotations. It focuses on optimizing rotation matrices to enhance the performance of quantized models, narrowing the accuracy gap to full precision models. The tool implements rotation optimization and PTQ evaluation with optimized rotation, providing arguments for model name, batch sizes, quantization bits, and rotation options. SpinQuant is based on the findings that rotation helps in removing outliers and improving quantization, with specific enhancements achieved through learning rotation with Cayley optimization.
Awesome-AGI
Awesome-AGI is a curated list of resources related to Artificial General Intelligence (AGI), including models, pipelines, applications, and concepts. It provides a comprehensive overview of the current state of AGI research and development, covering various aspects such as model training, fine-tuning, deployment, and applications in different domains. The repository also includes resources on prompt engineering, RLHF, LLM vocabulary expansion, long text generation, hallucination mitigation, controllability and safety, and text detection. It serves as a valuable resource for researchers, practitioners, and anyone interested in the field of AGI.

LLM-for-Healthcare
The repository 'LLM-for-Healthcare' provides a comprehensive survey of large language models (LLMs) for healthcare, covering data, technology, applications, and accountability and ethics. It includes information on various LLM models, training data, evaluation methods, and computation costs. The repository also discusses tasks such as NER, text classification, question answering, dialogue systems, and generation of medical reports from images in the healthcare domain.
Chinese-LLaMA-Alpaca-3
Chinese-LLaMA-Alpaca-3 is a project based on Meta's latest release of the new generation open-source large model Llama-3. It is the third phase of the Chinese-LLaMA-Alpaca open-source large model series projects (Phase 1, Phase 2). This project open-sources the Chinese Llama-3 base model and the Chinese Llama-3-Instruct instruction fine-tuned large model. These models incrementally pre-train with a large amount of Chinese data on the basis of the original Llama-3 and further fine-tune using selected instruction data, enhancing Chinese basic semantics and instruction understanding capabilities. Compared to the second-generation related models, significant performance improvements have been achieved.
rknn-llm
RKLLM software stack is a toolkit designed to help users quickly deploy AI models to Rockchip chips. It consists of RKLLM-Toolkit for model conversion and quantization, RKLLM Runtime for deploying models on Rockchip NPU platform, and RKNPU kernel driver for hardware interaction. The toolkit supports RK3588 and RK3576 series chips and various models like TinyLLAMA, Qwen, Phi, ChatGLM3, Gemma, InternLM2, and MiniCPM. Users can download packages, docker images, examples, and docs from RKLLM_SDK. Additionally, RKNN-Toolkit2 SDK is available for deploying additional AI models.
awesome-hosting
awesome-hosting is a curated list of hosting services sorted by minimal plan price. It includes various categories such as Web Services Platform, Backend-as-a-Service, Lambda, Node.js, Static site hosting, WordPress hosting, VPS providers, managed databases, GPU cloud services, and LLM/Inference API providers. Each category lists multiple service providers along with details on their minimal plan, trial options, free tier availability, open-source support, and specific features. The repository aims to help users find suitable hosting solutions based on their budget and requirements.

CogVLM2
CogVLM2 is a new generation of open source models that offer significant improvements in benchmarks such as TextVQA and DocVQA. It supports 8K content length, image resolution up to 1344 * 1344, and both Chinese and English languages. The project provides basic calling methods, fine-tuning examples, and OpenAI API format calling examples to help developers quickly get started with the model.

kumo-search
Kumo search is an end-to-end search engine framework that supports full-text search, inverted index, forward index, sorting, caching, hierarchical indexing, intervention system, feature collection, offline computation, storage system, and more. It runs on the EA (Elastic automic infrastructure architecture) platform, enabling engineering automation, service governance, real-time data, service degradation, and disaster recovery across multiple data centers and clusters. The framework aims to provide a ready-to-use search engine framework to help users quickly build their own search engines. Users can write business logic in Python using the AOT compiler in the project, which generates C++ code and binary dynamic libraries for rapid iteration of the search engine.
so-vits-models
This repository collects various LLM, AI-related models, applications, and datasets, including LLM-Chat for dialogue models, LLMs for large models, so-vits-svc for sound-related models, stable-diffusion for image-related models, and virtual-digital-person for generating videos. It also provides resources for deep learning courses and overviews, AI competitions, and specific AI tasks such as text, image, voice, and video processing.

Awesome-LLM-Eval
Awesome-LLM-Eval: a curated list of tools, benchmarks, demos, papers for Large Language Models (like ChatGPT, LLaMA, GLM, Baichuan, etc) Evaluation on Language capabilities, Knowledge, Reasoning, Fairness and Safety.
PaddleScience
PaddleScience is a scientific computing suite developed based on the deep learning framework PaddlePaddle. It utilizes the learning ability of deep neural networks and the automatic (higher-order) differentiation mechanism of PaddlePaddle to solve problems in physics, chemistry, meteorology, and other fields. It supports three solving methods: physics mechanism-driven, data-driven, and mathematical fusion, and provides basic APIs and detailed documentation for users to use and further develop.

TRACE
TRACE is a temporal grounding video model that utilizes causal event modeling to capture videos' inherent structure. It presents a task-interleaved video LLM model tailored for sequential encoding/decoding of timestamps, salient scores, and textual captions. The project includes various model checkpoints for different stages and fine-tuning on specific datasets. It provides evaluation codes for different tasks like VTG, MVBench, and VideoMME. The repository also offers annotation files and links to raw videos preparation projects. Users can train the model on different tasks and evaluate the performance based on metrics like CIDER, METEOR, SODA_c, F1, mAP, Hit@1, etc. TRACE has been enhanced with trace-retrieval and trace-uni models, showing improved performance on dense video captioning and general video understanding tasks.

oss-fuzz-gen
This framework generates fuzz targets for real-world `C`/`C++` projects with various Large Language Models (LLM) and benchmarks them via the `OSS-Fuzz` platform. It manages to successfully leverage LLMs to generate valid fuzz targets (which generate non-zero coverage increase) for 160 C/C++ projects. The maximum line coverage increase is 29% from the existing human-written targets.
Awesome-AgenticLLM-RL-Papers
This repository serves as the official source for the survey paper 'The Landscape of Agentic Reinforcement Learning for LLMs: A Survey'. It provides an extensive overview of various algorithms, methods, and frameworks related to Agentic RL, including detailed information on different families of algorithms, their key mechanisms, objectives, and links to relevant papers and resources. The repository covers a wide range of tasks such as Search & Research Agent, Code Agent, Mathematical Agent, GUI Agent, RL in Vision Agents, RL in Embodied Agents, and RL in Multi-Agent Systems. Additionally, it includes information on environments, frameworks, and methods suitable for different tasks related to Agentic RL and LLMs.
For similar tasks
MobileLLM
This repository contains the training code of MobileLLM, a language model optimized for on-device use cases with fewer than a billion parameters. It integrates SwiGLU activation function, deep and thin architectures, embedding sharing, and grouped-query attention to achieve high-quality LLMs. MobileLLM-125M/350M shows significant accuracy improvements over previous models on zero-shot commonsense reasoning tasks. The design philosophy scales effectively to larger models, with state-of-the-art results for MobileLLM-600M/1B/1.5B.

MiniAI-Face-LivenessDetection-AndroidSDK
The MiniAiLive Face Liveness Detection Android SDK provides advanced computer vision techniques to enhance security and accuracy on Android platforms. It offers 3D Passive Face Liveness Detection capabilities, ensuring that users are physically present and not using spoofing methods to access applications or services. The SDK is fully on-premise, with all processing happening on the hosting server, ensuring data privacy and security.

AIMr
AIMr is an AI aimbot tool written in Python that leverages modern technologies to achieve an undetected system with a pleasing appearance. It works on any game that uses human-shaped models. To optimize its performance, users should build OpenCV with CUDA. For Valorant, additional perks in the Discord and an Arduino Leonardo R3 are required.

Woodpecker
Woodpecker is a tool designed to correct hallucinations in Multimodal Large Language Models (MLLMs) by introducing a training-free method that picks out and corrects inconsistencies between generated text and image content. It consists of five stages: key concept extraction, question formulation, visual knowledge validation, visual claim generation, and hallucination correction. Woodpecker can be easily integrated with different MLLMs and provides interpretable results by accessing intermediate outputs of the stages. The tool has shown significant improvements in accuracy over baseline models like MiniGPT-4 and mPLUG-Owl.
Fortnite-menu
Welcome to the Fortnite Menu repository! This project offers a multi-functional cheat for Valorant, providing features like Aimbot, Wallhack, ESP, No Recoil, Triggerbot, and Radar Hack to enhance your gameplay. Please note that using cheats in Fortnite is against Epic Games' terms of service and can lead to permanent bans. The repository is for educational purposes only, and fair play is encouraged.
IntelliQ
IntelliQ is an open-source project aimed at providing a multi-turn question-answering system based on a large language model (LLM). The system combines advanced intent recognition and slot filling technology to enhance the depth of understanding and accuracy of responses in conversation systems. It offers a flexible and efficient solution for developers to build and optimize various conversational applications. The system features multi-turn dialogue management, intent recognition, slot filling, interface slot technology for real-time data retrieval and processing, adaptive learning for improving response accuracy and speed, and easy integration with detailed API documentation supporting multiple programming languages and platforms.
BetterOCR
BetterOCR is a tool that enhances text detection by combining multiple OCR engines with LLM (Language Model). It aims to improve OCR results, especially for languages with limited training data or noisy outputs. The tool combines results from EasyOCR, Tesseract, and Pororo engines, along with LLM support from OpenAI. Users can provide custom context for better accuracy, view performance examples by language, and upcoming features include box detection, improved interface, and async support. The package is under rapid development and contributions are welcomed.
flash-tokenizer
FlashTokenizer is a high-performance CPU tokenizer library implemented in C++ for LLM inference serving. It is 10 times faster than BertTokenizerFast in transformers, offering the highest speed and accuracy. Developed to be faster, more accurate, and easier to use than existing tokenizers like BertTokenizerFast, FlashTokenizer is implemented in C++ for straightforward maintenance. It supports parallel processing at the C++ level for batch encoding, delivering outstanding speed. The tokenizer is based on the LinMax Tokenizer proposed in Fast WordPiece Tokenization, enabling tokenization in linear time.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.