Best AI tools for< Nlp Specialist >
Infographic
20 - AI tool Sites
Explosion
Explosion is a software company specializing in developer tools and tailored solutions for AI, Machine Learning, and Natural Language Processing (NLP). They are the makers of spaCy, one of the leading open-source libraries for advanced NLP. The company offers consulting services and builds developer tools for various AI-related tasks, such as coreference resolution, dependency parsing, image classification, named entity recognition, and more.
Datasaur
Datasaur is an advanced text and audio data labeling platform that offers customizable solutions for various industries such as LegalTech, Healthcare, Financial, Media, e-Commerce, and Government. It provides features like configurable annotation, quality control automation, and workforce management to enhance the efficiency of NLP and LLM projects. Datasaur prioritizes data security with military-grade practices and offers seamless integrations with AWS and other technologies. The platform aims to streamline the data labeling process, allowing engineers to focus on creating high-quality models.
Answer.AI
Answer.AI is an AI tool developed by Benjamin Clavié, focusing on NLP&IR with a special interest in developing smaller models to power LLM-based applications. The tool includes models like answerai-colbert-small-v1 and JaColBERTv2.5🇯🇵, offering efficient pooling tricks and optimizing retrieval training for lower-resource languages. Benjamin Clavié shares insights and thoughts on ML/NLP/IR ecosystem through blog posts on the website.
Oxygen Digital Recruitment
Oxygen Digital Recruitment is a specialized AI and Data Science recruitment platform that focuses on providing talent solutions for cutting-edge markets, including Geospatial & ESG, Energy Trading, Renewable Energy, Artificial Intelligence, and Data Science. The platform offers various services such as Permanent Search, Embedded Specialist Talent, Short-term Staffing, Retained Search, and Fractional Advisory. Oxygen Digital aims to accelerate decarbonization by delivering top talent to drive change in the industry. The platform collaborates with start-ups, scale-ups, and global enterprises to build domain-specific innovation teams, providing access to deep passive networks and the ability to hire blended workforces.
Next AI Jobs
Next AI Jobs is an AI-powered platform that specializes in connecting professionals with job opportunities in the fields of Artificial Intelligence (AI), Machine Learning (ML), Natural Language Processing (NLP), and Data Science. The platform utilizes advanced algorithms to match candidates with relevant job listings, streamlining the recruitment process for both employers and job seekers. Next AI Jobs provides a user-friendly interface where users can create profiles, upload resumes, and apply for jobs with ease. With a focus on the rapidly growing AI industry, Next AI Jobs aims to bridge the gap between talented individuals and top-tier companies seeking AI expertise.
LangChain
LangChain is a framework for developing applications powered by large language models (LLMs). It simplifies every stage of the LLM application lifecycle, including development, productionization, and deployment. LangChain consists of open-source libraries such as langchain-core, langchain-community, and partner packages. It also includes LangGraph for building stateful agents and LangSmith for debugging and monitoring LLM applications.
LlamaIndex
LlamaIndex is a framework for building context-augmented Large Language Model (LLM) applications. It provides tools to ingest and process data, implement complex query workflows, and build applications like question-answering chatbots, document understanding systems, and autonomous agents. LlamaIndex enables context augmentation by combining LLMs with private or domain-specific data, offering tools for data connectors, data indexes, engines for natural language access, chat engines, agents, and observability/evaluation integrations. It caters to users of all levels, from beginners to advanced developers, and is available in Python and Typescript.
Prompt Engineering
Prompt Engineering is a discipline focused on developing and optimizing prompts to efficiently utilize language models (LMs) for various applications and research topics. It involves skills to understand the capabilities and limitations of large language models, improving their performance on tasks like question answering and arithmetic reasoning. Prompt engineering is essential for designing robust prompting techniques that interact with LLMs and other tools, enhancing safety and building new capabilities by augmenting LLMs with domain knowledge and external tools.
Inspect
Inspect is an open-source framework for large language model evaluations created by the UK AI Safety Institute. It provides built-in components for prompt engineering, tool usage, multi-turn dialog, and model graded evaluations. Users can explore various solvers, tools, scorers, datasets, and models to create advanced evaluations. Inspect supports extensions for new elicitation and scoring techniques through Python packages.
Space-O Technologies
Space-O Technologies is a top-rated Artificial Intelligence Development Company with 14+ years of expertise in AI software development, consulting services, and ML development services. They excel in deep learning, NLP, computer vision, and AutoML, serving both startups and enterprises. Using advanced tools like Python, TensorFlow, and PyTorch, they create scalable and secure AI products to optimize efficiency, drive revenue growth, and deliver sustained performance.
Weavel
Weavel is an AI tool designed to revolutionize prompt engineering for large language models (LLMs). It offers features such as tracing, dataset curation, batch testing, and evaluations to enhance the performance of LLM applications. Weavel enables users to continuously optimize prompts using real-world data, prevent performance regression with CI/CD integration, and engage in human-in-the-loop interactions for scoring and feedback. Ape, the AI prompt engineer, outperforms competitors on benchmark tests and ensures seamless integration and continuous improvement specific to each user's use case. With Weavel, users can effortlessly evaluate LLM applications without the need for pre-existing datasets, streamlining the assessment process and enhancing overall performance.
Token Counter
Token Counter is an AI tool designed to convert text input into tokens for various AI models. It helps users accurately determine the token count and associated costs when working with AI models. By providing insights into tokenization strategies and cost structures, Token Counter streamlines the process of utilizing advanced technologies.
Tinq.ai
Tinq.ai is a natural language processing (NLP) tool that provides a range of text analysis capabilities through its API. It offers tools for tasks such as plagiarism checking, text summarization, sentiment analysis, named entity recognition, and article extraction. Tinq.ai's API can be integrated into applications to add NLP functionality, such as content moderation, sentiment analysis, and text rewriting.

DeepRec.ai
DeepRec.ai is a specialized recruitment platform focusing on AI and ML professionals. The platform offers hiring services for various AI specialisms such as Research GenAI, Machine Learning, Computer Vision, AI Infrastructure, Quantum Computing, Robotics & Embodied AI, and AI4Science. DeepRec.ai provides hiring solutions like Embedded Hiring, Retained Search, Contingent Contract & Flexible Resource, tailored to scale with businesses and address high-volume hiring challenges. The platform boasts positive feedback from both clients and candidates, emphasizing the quality of communication, candidate selection, and support throughout the recruitment process.
Medallia
Medallia is a real-time text analytics software that offers comprehensive feedback capture, role-based reporting, AI and analytics capabilities, integrations, pricing flexibility, enterprise-grade security, and solutions for customer experience, employee experience, contact center, and market research. It provides omnichannel text analytics powered by AI to uncover high-impact insights and enable users to identify emerging trends and key insights at scale. Medallia's text analytics platform supports workflows, event analytics, real-time actions, natural language understanding, out-of-the-box topic models, customizable KPIs, and omnichannel analytics for various industries.
Hexabot
Hexabot is an AI tool designed for building and managing AI-powered chatbots. It offers a user-friendly platform for creating chatbots that can interact with users in a seamless manner. With Hexabot, users can easily design and customize chatbot functionalities to suit their specific needs. The tool provides a range of features and advantages that make it a valuable asset for businesses looking to enhance customer engagement and streamline communication processes.
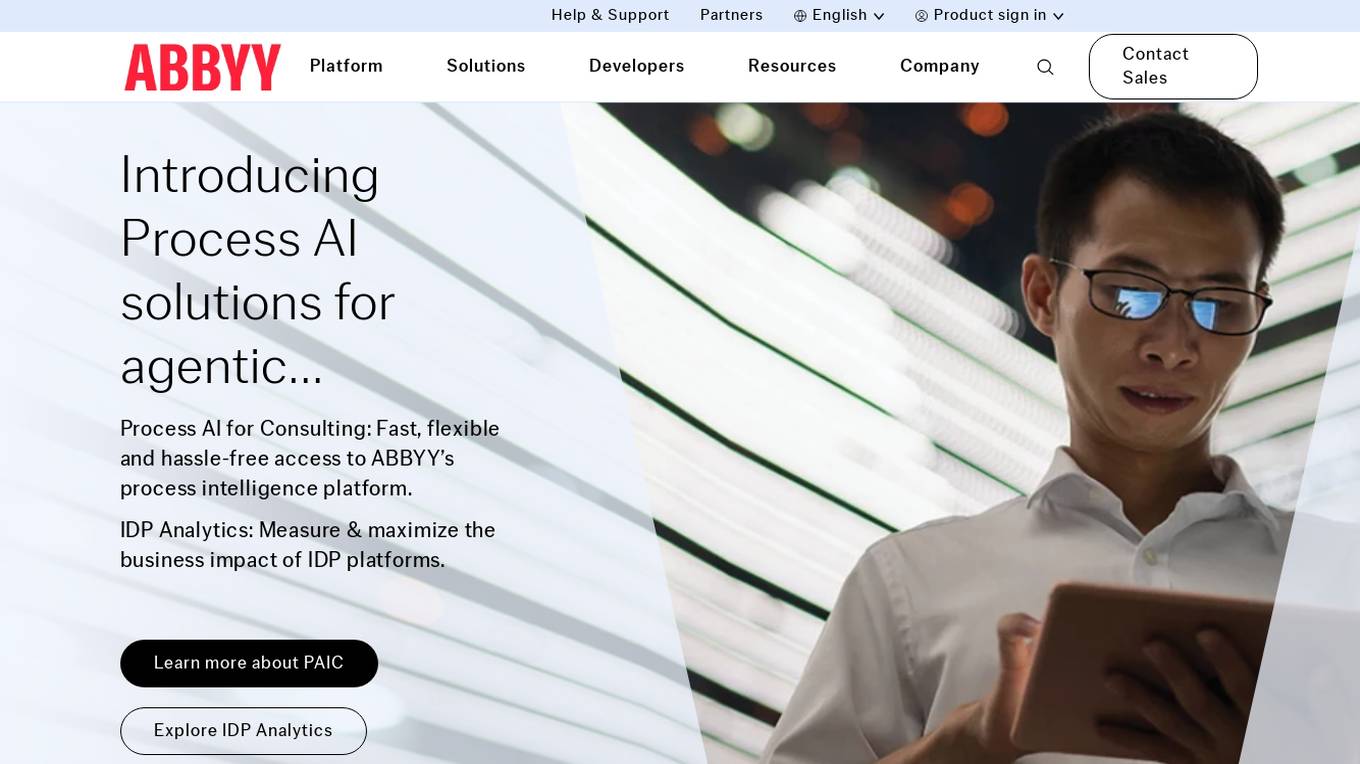
ABBYY
ABBYY is an intelligent automation company that offers purpose-built AI document processing solutions for efficient business process automation. Their products include ABBYY Vantage, ABBYY Timeline, ABBYY Cloud OCR SDK, and ABBYY FlexiCapture Cloud Platform. ABBYY provides tools for document input, classification, splitting, data extraction, validation, quality analytics, OCR/ICR, and IDP analytics. They also offer solutions for process understanding, optimization, monitoring, prediction, and simulation. ABBYY Marketplace offers pre-trained AI extraction models for limitless automation. The company caters to various industries like financial services, public sector, insurance, transportation & logistics, and offers solutions for accounts payable automation, enterprise automation, process intelligence, and customer onboarding.
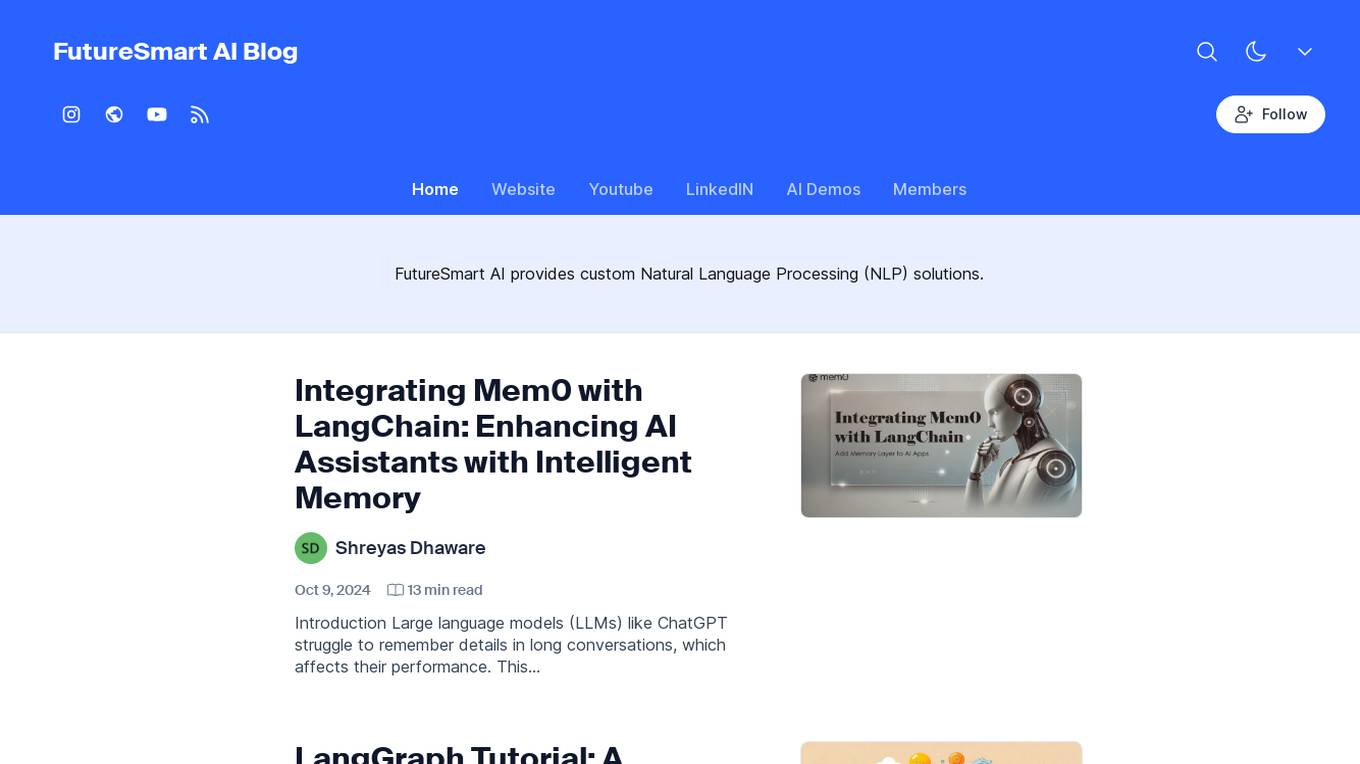
FutureSmart AI
FutureSmart AI is a platform that provides custom Natural Language Processing (NLP) solutions. The platform focuses on integrating Mem0 with LangChain to enhance AI Assistants with Intelligent Memory. It offers tutorials, guides, and practical tips for building applications with large language models (LLMs) to create sophisticated and interactive systems. FutureSmart AI also features internship journeys and practical guides for mastering RAG with LangChain, catering to developers and enthusiasts in the realm of NLP and AI.
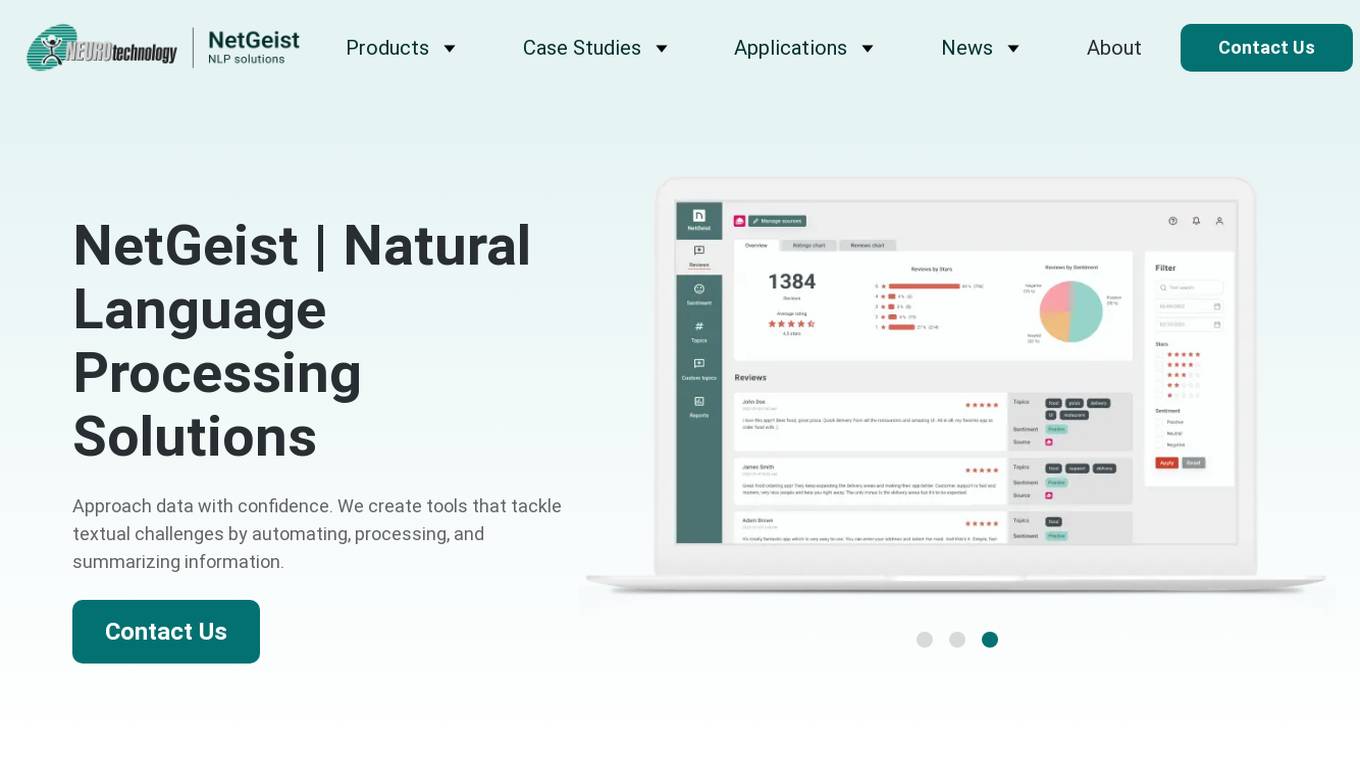
NetGeist
NetGeist is an AI tool that offers Natural Language Processing solutions to tackle textual challenges by automating, processing, and summarizing information. It provides various applications such as app review tracking, HR strategy shaping, stock market sentiment analysis, and custom chatbots. NetGeist aims to create tailor-made NLP solutions for different industries, leveraging AI technologies to enhance workflow efficiency and decision-making processes.
PoweredbyAI
PoweredbyAI is a platform offering a variety of free AI tools for users to utilize. Users can access a range of AI-powered applications to assist with various tasks and projects. The platform aims to simplify the use of AI technology for individuals and businesses, providing easy access to tools that can enhance productivity and efficiency. With a user-friendly interface, PoweredbyAI caters to both beginners and advanced users looking to leverage AI capabilities in their work.
126 - Open Source Tools

Firefly
Firefly is an open-source large model training project that supports pre-training, fine-tuning, and DPO of mainstream large models. It includes models like Llama3, Gemma, Qwen1.5, MiniCPM, Llama, InternLM, Baichuan, ChatGLM, Yi, Deepseek, Qwen, Orion, Ziya, Xverse, Mistral, Mixtral-8x7B, Zephyr, Vicuna, Bloom, etc. The project supports full-parameter training, LoRA, QLoRA efficient training, and various tasks such as pre-training, SFT, and DPO. Suitable for users with limited training resources, QLoRA is recommended for fine-tuning instructions. The project has achieved good results on the Open LLM Leaderboard with QLoRA training process validation. The latest version has significant updates and adaptations for different chat model templates.

llm-resource
llm-resource is a comprehensive collection of high-quality resources for Large Language Models (LLM). It covers various aspects of LLM including algorithms, training, fine-tuning, alignment, inference, data engineering, compression, evaluation, prompt engineering, AI frameworks, AI basics, AI infrastructure, AI compilers, LLM application development, LLM operations, AI systems, and practical implementations. The repository aims to gather and share valuable resources related to LLM for the community to benefit from.

cria
Cria is a Python library designed for running Large Language Models with minimal configuration. It provides an easy and concise way to interact with LLMs, offering advanced features such as custom models, streams, message history management, and running multiple models in parallel. Cria simplifies the process of using LLMs by providing a straightforward API that requires only a few lines of code to get started. It also handles model installation automatically, making it efficient and user-friendly for various natural language processing tasks.

beyondllm
Beyond LLM offers an all-in-one toolkit for experimentation, evaluation, and deployment of Retrieval-Augmented Generation (RAG) systems. It simplifies the process with automated integration, customizable evaluation metrics, and support for various Large Language Models (LLMs) tailored to specific needs. The aim is to reduce LLM hallucination risks and enhance reliability.
fsdp_qlora
The fsdp_qlora repository provides a script for training Large Language Models (LLMs) with Quantized LoRA and Fully Sharded Data Parallelism (FSDP). It integrates FSDP+QLoRA into the Axolotl platform and offers installation instructions for dependencies like llama-recipes, fastcore, and PyTorch. Users can finetune Llama-2 70B on Dual 24GB GPUs using the provided command. The script supports various training options including full params fine-tuning, LoRA fine-tuning, custom LoRA fine-tuning, quantized LoRA fine-tuning, and more. It also discusses low memory loading, mixed precision training, and comparisons to existing trainers. The repository addresses limitations and provides examples for training with different configurations, including BnB QLoRA and HQQ QLoRA. Additionally, it offers SLURM training support and instructions for adding support for a new model.
Awesome-LLM-Survey
This repository, Awesome-LLM-Survey, serves as a comprehensive collection of surveys related to Large Language Models (LLM). It covers various aspects of LLM, including instruction tuning, human alignment, LLM agents, hallucination, multi-modal capabilities, and more. Researchers are encouraged to contribute by updating information on their papers to benefit the LLM survey community.
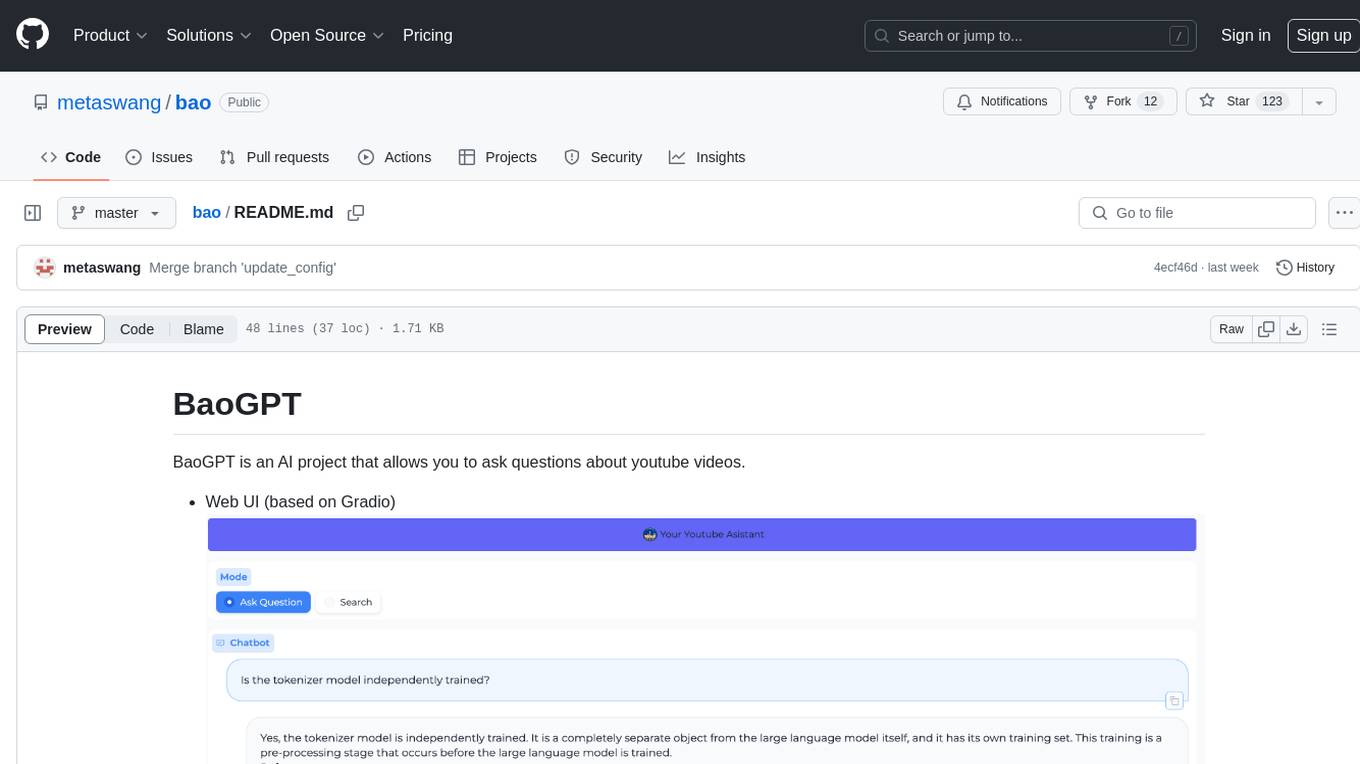
bao
BaoGPT is an AI project designed to facilitate asking questions about YouTube videos. It features a web UI based on Gradio and Discord integration. The tool utilizes a pipeline that routes input questions to either a greeting-like branch or a query & answer branch. The query analysis is performed by the LLM, which extracts attributes as filters and optimizes and rewrites questions for better vector retrieval in the vector DB. The tool then retrieves top-k candidates for grading and outputs final relative documents after grading. Lastly, the LLM performs summarization based on the reranking output, providing answers and attaching sources to the user.
Awesome-LLM-Interpretability
Awesome-LLM-Interpretability is a curated list of materials related to LLM (Large Language Models) interpretability, covering tutorials, code libraries, surveys, videos, papers, and blogs. It includes resources on transformer mechanistic interpretability, visualization, interventions, probing, fine-tuning, feature representation, learning dynamics, knowledge editing, hallucination detection, and redundancy analysis. The repository aims to provide a comprehensive overview of tools, techniques, and methods for understanding and interpreting the inner workings of large language models.
llm-zoomcamp
LLM Zoomcamp is a free online course focusing on real-life applications of Large Language Models (LLMs). Over 10 weeks, participants will learn to build an AI bot capable of answering questions based on a knowledge base. The course covers topics such as LLMs, RAG, open-source LLMs, vector databases, orchestration, monitoring, and advanced RAG systems. Pre-requisites include comfort with programming, Python, and the command line, with no prior exposure to AI or ML required. The course features a pre-course workshop and is led by instructors Alexey Grigorev and Magdalena Kuhn, with support from sponsors and partners.

AgentBench
AgentBench is a benchmark designed to evaluate Large Language Models (LLMs) as autonomous agents in various environments. It includes 8 distinct environments such as Operating System, Database, Knowledge Graph, Digital Card Game, and Lateral Thinking Puzzles. The tool provides a comprehensive evaluation of LLMs' ability to operate as agents by offering Dev and Test sets for each environment. Users can quickly start using the tool by following the provided steps, configuring the agent, starting task servers, and assigning tasks. AgentBench aims to bridge the gap between LLMs' proficiency as agents and their practical usability.

hezar
Hezar is an all-in-one AI library designed specifically for the Persian community. It brings together various AI models and tools, making it easy to use AI with just a few lines of code. The library seamlessly integrates with Hugging Face Hub, offering a developer-friendly interface and task-based model interface. In addition to models, Hezar provides tools like word embeddings, tokenizers, feature extractors, and more. It also includes supplementary ML tools for deployment, benchmarking, and optimization.

Xwin-LM
Xwin-LM is a powerful and stable open-source tool for aligning large language models, offering various alignment technologies like supervised fine-tuning, reward models, reject sampling, and reinforcement learning from human feedback. It has achieved top rankings in benchmarks like AlpacaEval and surpassed GPT-4. The tool is continuously updated with new models and features.

LLM-Finetuning-Toolkit
LLM Finetuning toolkit is a config-based CLI tool for launching a series of LLM fine-tuning experiments on your data and gathering their results. It allows users to control all elements of a typical experimentation pipeline - prompts, open-source LLMs, optimization strategy, and LLM testing - through a single YAML configuration file. The toolkit supports basic, intermediate, and advanced usage scenarios, enabling users to run custom experiments, conduct ablation studies, and automate fine-tuning workflows. It provides features for data ingestion, model definition, training, inference, quality assurance, and artifact outputs, making it a comprehensive tool for fine-tuning large language models.
llm
LLM is a CLI utility and Python library for interacting with Large Language Models, both via remote APIs and models that can be installed and run on your own machine. It allows users to run prompts from the command-line, store results in SQLite, generate embeddings, and more. The tool supports self-hosted language models via plugins and provides access to remote and local models. Users can install plugins to access models by different providers, including models that can be installed and run on their own device. LLM offers various options for running Mistral models in the terminal and enables users to start chat sessions with models. Additionally, users can use a system prompt to provide instructions for processing input to the tool.
awesome-gpt-prompt-engineering
Awesome GPT Prompt Engineering is a curated list of resources, tools, and shiny things for GPT prompt engineering. It includes roadmaps, guides, techniques, prompt collections, papers, books, communities, prompt generators, Auto-GPT related tools, prompt injection information, ChatGPT plug-ins, prompt engineering job offers, and AI links directories. The repository aims to provide a comprehensive guide for prompt engineering enthusiasts, covering various aspects of working with GPT models and improving communication with AI tools.
llm_steer
LLM Steer is a Python module designed to steer Large Language Models (LLMs) towards specific topics or subjects by adding steer vectors to different layers of the model. It enhances the model's capabilities, such as providing correct responses to logical puzzles. The tool should be used in conjunction with the transformers library. Users can add steering vectors to specific layers of the model with coefficients and text, retrieve applied steering vectors, and reset all steering vectors to the initial model. Advanced usage involves changing default parameters, but it may lead to the model outputting gibberish in most cases. The tool is meant for experimentation and can be used to enhance role-play characteristics in LLMs.

unilm
The 'unilm' repository is a collection of tools, models, and architectures for Foundation Models and General AI, focusing on tasks such as NLP, MT, Speech, Document AI, and Multimodal AI. It includes various pre-trained models, such as UniLM, InfoXLM, DeltaLM, MiniLM, AdaLM, BEiT, LayoutLM, WavLM, VALL-E, and more, designed for tasks like language understanding, generation, translation, vision, speech, and multimodal processing. The repository also features toolkits like s2s-ft for sequence-to-sequence fine-tuning and Aggressive Decoding for efficient sequence-to-sequence decoding. Additionally, it offers applications like TrOCR for OCR, LayoutReader for reading order detection, and XLM-T for multilingual NMT.

LLM-SFT
LLM-SFT is a Chinese large model fine-tuning tool that supports models such as ChatGLM, LlaMA, Bloom, Baichuan-7B, and frameworks like LoRA, QLoRA, DeepSpeed, UI, and TensorboardX. It facilitates tasks like fine-tuning, inference, evaluation, and API integration. The tool provides pre-trained weights for various models and datasets for Chinese language processing. It requires specific versions of libraries like transformers and torch for different functionalities.
llm-detect-ai
This repository contains code and configurations for the LLM - Detect AI Generated Text competition. It includes setup instructions for hardware, software, dependencies, and datasets. The training section covers scripts and configurations for training LLM models, DeBERTa ranking models, and an embedding model. Text generation section details fine-tuning LLMs using the CLM objective on the PERSUADE corpus to generate student-like essays.

CogVLM2
CogVLM2 is a new generation of open source models that offer significant improvements in benchmarks such as TextVQA and DocVQA. It supports 8K content length, image resolution up to 1344 * 1344, and both Chinese and English languages. The project provides basic calling methods, fine-tuning examples, and OpenAI API format calling examples to help developers quickly get started with the model.
start-llms
This repository is a comprehensive guide for individuals looking to start and improve their skills in Large Language Models (LLMs) without an advanced background in the field. It provides free resources, online courses, books, articles, and practical tips to become an expert in machine learning. The guide covers topics such as terminology, transformers, prompting, retrieval augmented generation (RAG), and more. It also includes recommendations for podcasts, YouTube videos, and communities to stay updated with the latest news in AI and LLMs.

LLamaTuner
LLamaTuner is a repository for the Efficient Finetuning of Quantized LLMs project, focusing on building and sharing instruction-following Chinese baichuan-7b/LLaMA/Pythia/GLM model tuning methods. The project enables training on a single Nvidia RTX-2080TI and RTX-3090 for multi-round chatbot training. It utilizes bitsandbytes for quantization and is integrated with Huggingface's PEFT and transformers libraries. The repository supports various models, training approaches, and datasets for supervised fine-tuning, LoRA, QLoRA, and more. It also provides tools for data preprocessing and offers models in the Hugging Face model hub for inference and finetuning. The project is licensed under Apache 2.0 and acknowledges contributions from various open-source contributors.

AnglE
AnglE is a library for training state-of-the-art BERT/LLM-based sentence embeddings with just a few lines of code. It also serves as a general sentence embedding inference framework, allowing for inferring a variety of transformer-based sentence embeddings. The library supports various loss functions such as AnglE loss, Contrastive loss, CoSENT loss, and Espresso loss. It provides backbones like BERT-based models, LLM-based models, and Bi-directional LLM-based models for training on single or multi-GPU setups. AnglE has achieved significant performance on various benchmarks and offers official pretrained models for both BERT-based and LLM-based models.
ChatGPT-Telegram-Bot
The ChatGPT Telegram Bot is a powerful Telegram bot that utilizes various GPT models, including GPT3.5, GPT4, GPT4 Turbo, GPT4 Vision, DALL·E 3, Groq Mixtral-8x7b/LLaMA2-70b, and Claude2.1/Claude3 opus/sonnet API. It enables users to engage in efficient conversations and information searches on Telegram. The bot supports multiple AI models, online search with DuckDuckGo and Google, user-friendly interface, efficient message processing, document interaction, Markdown rendering, and convenient deployment options like Zeabur, Replit, and Docker. Users can set environment variables for configuration and deployment. The bot also provides Q&A functionality, supports model switching, and can be deployed in group chats with whitelisting. The project is open source under GPLv3 license.

InternLM
InternLM is a powerful language model series with features such as 200K context window for long-context tasks, outstanding comprehensive performance in reasoning, math, code, chat experience, instruction following, and creative writing, code interpreter & data analysis capabilities, and stronger tool utilization capabilities. It offers models in sizes of 7B and 20B, suitable for research and complex scenarios. The models are recommended for various applications and exhibit better performance than previous generations. InternLM models may match or surpass other open-source models like ChatGPT. The tool has been evaluated on various datasets and has shown superior performance in multiple tasks. It requires Python >= 3.8, PyTorch >= 1.12.0, and Transformers >= 4.34 for usage. InternLM can be used for tasks like chat, agent applications, fine-tuning, deployment, and long-context inference.
inspect_ai
Inspect AI is a framework developed by the UK AI Safety Institute for evaluating large language models. It offers various built-in components for prompt engineering, tool usage, multi-turn dialog, and model graded evaluations. Users can extend Inspect by adding new elicitation and scoring techniques through additional Python packages. The tool aims to provide a comprehensive solution for assessing the performance and safety of language models.

RLAIF-V
RLAIF-V is a novel framework that aligns MLLMs in a fully open-source paradigm for super GPT-4V trustworthiness. It maximally exploits open-source feedback from high-quality feedback data and online feedback learning algorithm. Notable features include achieving super GPT-4V trustworthiness in both generative and discriminative tasks, using high-quality generalizable feedback data to reduce hallucination of different MLLMs, and exhibiting better learning efficiency and higher performance through iterative alignment.

CuMo
CuMo is a project focused on scaling multimodal Large Language Models (LLMs) with Co-Upcycled Mixture-of-Experts. It introduces CuMo, which incorporates Co-upcycled Top-K sparsely-gated Mixture-of-experts blocks into the vision encoder and the MLP connector, enhancing the capabilities of multimodal LLMs. The project adopts a three-stage training approach with auxiliary losses to stabilize the training process and maintain a balanced loading of experts. CuMo achieves comparable performance to other state-of-the-art multimodal LLMs on various Visual Question Answering (VQA) and visual-instruction-following benchmarks.
ABigSurveyOfLLMs
ABigSurveyOfLLMs is a repository that compiles surveys on Large Language Models (LLMs) to provide a comprehensive overview of the field. It includes surveys on various aspects of LLMs such as transformers, alignment, prompt learning, data management, evaluation, societal issues, safety, misinformation, attributes of LLMs, efficient LLMs, learning methods for LLMs, multimodal LLMs, knowledge-based LLMs, extension of LLMs, LLMs applications, and more. The repository aims to help individuals quickly understand the advancements and challenges in the field of LLMs through a collection of recent surveys and research papers.
superpipe
Superpipe is a lightweight framework designed for building, evaluating, and optimizing data transformation and data extraction pipelines using LLMs. It allows users to easily combine their favorite LLM libraries with Superpipe's building blocks to create pipelines tailored to their unique data and use cases. The tool facilitates rapid prototyping, evaluation, and optimization of end-to-end pipelines for tasks such as classification and evaluation of job departments based on work history. Superpipe also provides functionalities for evaluating pipeline performance, optimizing parameters for cost, accuracy, and speed, and conducting grid searches to experiment with different models and prompts.
mslearn-ai-language
This repository contains lab files for Azure AI Language modules. It provides hands-on exercises and resources for learning about various AI language technologies on the Azure platform. The labs cover topics such as natural language processing, text analytics, language understanding, and more. By following the exercises in this repository, users can gain practical experience in implementing AI language solutions using Azure services.

magpie
This is the official repository for 'Alignment Data Synthesis from Scratch by Prompting Aligned LLMs with Nothing'. Magpie is a tool designed to synthesize high-quality instruction data at scale by extracting it directly from an aligned Large Language Models (LLMs). It aims to democratize AI by generating large-scale alignment data and enhancing the transparency of model alignment processes. Magpie has been tested on various model families and can be used to fine-tune models for improved performance on alignment benchmarks such as AlpacaEval, ArenaHard, and WildBench.

Step-DPO
Step-DPO is a method for enhancing long-chain reasoning ability of LLMs with a data construction pipeline creating a high-quality dataset. It significantly improves performance on math and GSM8K tasks with minimal data and training steps. The tool fine-tunes pre-trained models like Qwen2-7B-Instruct with Step-DPO, achieving superior results compared to other models. It provides scripts for training, evaluation, and deployment, along with examples and acknowledgements.
llms-interview-questions
This repository contains a comprehensive collection of 63 must-know Large Language Models (LLMs) interview questions. It covers topics such as the architecture of LLMs, transformer models, attention mechanisms, training processes, encoder-decoder frameworks, differences between LLMs and traditional statistical language models, handling context and long-term dependencies, transformers for parallelization, applications of LLMs, sentiment analysis, language translation, conversation AI, chatbots, and more. The readme provides detailed explanations, code examples, and insights into utilizing LLMs for various tasks.
OpenAIWorkshop
Azure OpenAI Service provides REST API access to OpenAI's powerful language models including GPT-3, Codex and Embeddings. Users can easily adapt models for content generation, summarization, semantic search, and natural language to code translation. The workshop covers basics, prompt engineering, common NLP tasks, generative tasks, conversational dialog, and learning methods. It guides users to build applications with PowerApp, query SQL data, create data pipelines, and work with proprietary datasets. Target audience includes Power Users, Software Engineers, Data Scientists, and AI architects and Managers.

awesome-LLM-resourses
A comprehensive repository of resources for Chinese large language models (LLMs), including data processing tools, fine-tuning frameworks, inference libraries, evaluation platforms, RAG engines, agent frameworks, books, courses, tutorials, and tips. The repository covers a wide range of tools and resources for working with LLMs, from data labeling and processing to model fine-tuning, inference, evaluation, and application development. It also includes resources for learning about LLMs through books, courses, and tutorials, as well as insights and strategies from building with LLMs.
avatar
AvaTaR is a novel and automatic framework that optimizes an LLM agent to effectively use provided tools and improve performance on a given task/domain. It designs a comparator module to provide insightful prompts to the LLM agent via reasoning between positive and negative examples from training data.

tiny-llm-zh
Tiny LLM zh is a project aimed at building a small-parameter Chinese language large model for quick entry into learning large model-related knowledge. The project implements a two-stage training process for large models and subsequent human alignment, including tokenization, pre-training, instruction fine-tuning, human alignment, evaluation, and deployment. It is deployed on ModeScope Tiny LLM website and features open access to all data and code, including pre-training data and tokenizer. The project trains a tokenizer using 10GB of Chinese encyclopedia text to build a Tiny LLM vocabulary. It supports training with Transformers deepspeed, multiple machine and card support, and Zero optimization techniques. The project has three main branches: llama2_torch, main tiny_llm, and tiny_llm_moe, each with specific modifications and features.

candle-vllm
Candle-vllm is an efficient and easy-to-use platform designed for inference and serving local LLMs, featuring an OpenAI compatible API server. It offers a highly extensible trait-based system for rapid implementation of new module pipelines, streaming support in generation, efficient management of key-value cache with PagedAttention, and continuous batching. The tool supports chat serving for various models and provides a seamless experience for users to interact with LLMs through different interfaces.

LongRAG
This repository contains the code for LongRAG, a framework that enhances retrieval-augmented generation with long-context LLMs. LongRAG introduces a 'long retriever' and a 'long reader' to improve performance by using a 4K-token retrieval unit, offering insights into combining RAG with long-context LLMs. The repo provides instructions for installation, quick start, corpus preparation, long retriever, and long reader.
MobileLLM
This repository contains the training code of MobileLLM, a language model optimized for on-device use cases with fewer than a billion parameters. It integrates SwiGLU activation function, deep and thin architectures, embedding sharing, and grouped-query attention to achieve high-quality LLMs. MobileLLM-125M/350M shows significant accuracy improvements over previous models on zero-shot commonsense reasoning tasks. The design philosophy scales effectively to larger models, with state-of-the-art results for MobileLLM-600M/1B/1.5B.
tb1
A Telegram bot for accessing Google Gemini, MS Bing, etc. The bot responds to the keywords 'bot' and 'google' to provide information. It can handle voice messages, text files, images, and links. It can generate images based on descriptions, extract text from images, and summarize content. The bot can interact with various AI models and perform tasks like voice control, text-to-speech, and text recognition. It supports long texts, large responses, and file transfers. Users can interact with the bot using voice commands and text. The bot can be customized for different AI providers and has features for both users and administrators.

Steel-LLM
Steel-LLM is a project to pre-train a large Chinese language model from scratch using over 1T of data to achieve a parameter size of around 1B, similar to TinyLlama. The project aims to share the entire process including data collection, data processing, pre-training framework selection, model design, and open-source all the code. The goal is to enable reproducibility of the work even with limited resources. The name 'Steel' is inspired by a band '万能青年旅店' and signifies the desire to create a strong model despite limited conditions. The project involves continuous data collection of various cultural elements, trivia, lyrics, niche literature, and personal secrets to train the LLM. The ultimate aim is to fill the model with diverse data and leave room for individual input, fostering collaboration among users.

HebTTS
HebTTS is a language modeling approach to diacritic-free Hebrew text-to-speech (TTS) system. It addresses the challenge of accurately mapping text to speech in Hebrew by proposing a language model that operates on discrete speech representations and is conditioned on a word-piece tokenizer. The system is optimized using weakly supervised recordings and outperforms diacritic-based Hebrew TTS systems in terms of content preservation and naturalness of generated speech.

NeMo-Curator
NeMo Curator is a GPU-accelerated open-source framework designed for efficient large language model data curation. It provides scalable dataset preparation for tasks like foundation model pretraining, domain-adaptive pretraining, supervised fine-tuning, and parameter-efficient fine-tuning. The library leverages GPUs with Dask and RAPIDS to accelerate data curation, offering customizable and modular interfaces for pipeline expansion and model convergence. Key features include data download, text extraction, quality filtering, deduplication, downstream-task decontamination, distributed data classification, and PII redaction. NeMo Curator is suitable for curating high-quality datasets for large language model training.

LLM-Pruner
LLM-Pruner is a tool for structural pruning of large language models, allowing task-agnostic compression while retaining multi-task solving ability. It supports automatic structural pruning of various LLMs with minimal human effort. The tool is efficient, requiring only 3 minutes for pruning and 3 hours for post-training. Supported LLMs include Llama-3.1, Llama-3, Llama-2, LLaMA, BLOOM, Vicuna, and Baichuan. Updates include support for new LLMs like GQA and BLOOM, as well as fine-tuning results achieving high accuracy. The tool provides step-by-step instructions for pruning, post-training, and evaluation, along with a Gradio interface for text generation. Limitations include issues with generating repetitive or nonsensical tokens in compressed models and manual operations for certain models.

Simplifine
Simplifine is an open-source library designed for easy LLM finetuning, enabling users to perform tasks such as supervised fine tuning, question-answer finetuning, contrastive loss for embedding tasks, multi-label classification finetuning, and more. It provides features like WandB logging, in-built evaluation tools, automated finetuning parameters, and state-of-the-art optimization techniques. The library offers bug fixes, new features, and documentation updates in its latest version. Users can install Simplifine via pip or directly from GitHub. The project welcomes contributors and provides comprehensive documentation and support for users.
evalscope
Eval-Scope is a framework designed to support the evaluation of large language models (LLMs) by providing pre-configured benchmark datasets, common evaluation metrics, model integration, automatic evaluation for objective questions, complex task evaluation using expert models, reports generation, visualization tools, and model inference performance evaluation. It is lightweight, easy to customize, supports new dataset integration, model hosting on ModelScope, deployment of locally hosted models, and rich evaluation metrics. Eval-Scope also supports various evaluation modes like single mode, pairwise-baseline mode, and pairwise (all) mode, making it suitable for assessing and improving LLMs.
awesome-production-llm
This repository is a curated list of open-source libraries for production large language models. It includes tools for data preprocessing, training/finetuning, evaluation/benchmarking, serving/inference, application/RAG, testing/monitoring, and guardrails/security. The repository also provides a new category called LLM Cookbook/Examples for showcasing examples and guides on using various LLM APIs.
DistillKit
DistillKit is an open-source research effort by Arcee.AI focusing on model distillation methods for Large Language Models (LLMs). It provides tools for improving model performance and efficiency through logit-based and hidden states-based distillation methods. The tool supports supervised fine-tuning and aims to enhance the adoption of open-source LLM distillation techniques.
gigachat
GigaChat is a Python library that allows GigaChain to interact with GigaChat, a neural network model capable of engaging in dialogue, writing code, creating texts, and images on demand. Data exchange with the service is facilitated through the GigaChat API. The library supports processing token streaming, as well as working in synchronous or asynchronous mode. It enables precise token counting in text using the GigaChat API.
multipack_sampler
The Multipack sampler is a tool designed for padding-free distributed training of large language models. It optimizes batch processing efficiency using an approximate solution to the identical machine scheduling problem. The V2 update further enhances the packing algorithm complexity, achieving better throughput for a large number of nodes. It includes two variants for models with different attention types, aiming to balance sequence lengths and optimize packing efficiency. Users can refer to the provided benchmark for evaluating efficiency, utilization, and L^2 lag. The tool is compatible with PyTorch DataLoader and is released under the MIT license.

LLMs
LLMs is a Chinese large language model technology stack for practical use. It includes high-availability pre-training, SFT, and DPO preference alignment code framework. The repository covers pre-training data cleaning, high-concurrency framework, SFT dataset cleaning, data quality improvement, and security alignment work for Chinese large language models. It also provides open-source SFT dataset construction, pre-training from scratch, and various tools and frameworks for data cleaning, quality optimization, and task alignment.
chatwiki
ChatWiki is an open-source knowledge base AI question-answering system. It is built on large language models (LLM) and retrieval-augmented generation (RAG) technologies, providing out-of-the-box data processing, model invocation capabilities, and helping enterprises quickly build their own knowledge base AI question-answering systems. It offers exclusive AI question-answering system, easy integration of models, data preprocessing, simple user interface design, and adaptability to different business scenarios.
LLM-PlayLab
LLM-PlayLab is a repository containing various projects related to LLM (Large Language Models) fine-tuning, generative AI, time-series forecasting, and crash courses. It includes projects for text generation, sentiment analysis, data analysis, chat assistants, image captioning, and more. The repository offers a wide range of tools and resources for exploring and implementing advanced AI techniques.
JamAIBase
JamAI Base is an open-source platform integrating SQLite and LanceDB databases with managed memory and RAG capabilities. It offers built-in LLM, vector embeddings, and reranker orchestration accessible through a spreadsheet-like UI and REST API. Users can transform static tables into dynamic entities, facilitate real-time interactions, manage structured data, and simplify chatbot development. The tool focuses on ease of use, scalability, flexibility, declarative paradigm, and innovative RAG techniques, making complex data operations accessible to users with varying technical expertise.
LLMSpeculativeSampling
This repository implements speculative sampling for large language model (LLM) decoding, utilizing two models - a target model and an approximation model. The approximation model generates token guesses, corrected by the target model, resulting in improved efficiency. It includes implementations of Google's and Deepmind's versions of speculative sampling, supporting models like llama-7B and llama-1B. The tool is designed for fast inference from transformers via speculative decoding.

LARS
LARS is an application that enables users to run Large Language Models (LLMs) locally on their devices, upload their own documents, and engage in conversations where the LLM grounds its responses with the uploaded content. The application focuses on Retrieval Augmented Generation (RAG) to increase accuracy and reduce AI-generated inaccuracies. LARS provides advanced citations, supports various file formats, allows follow-up questions, provides full chat history, and offers customization options for LLM settings. Users can force enable or disable RAG, change system prompts, and tweak advanced LLM settings. The application also supports GPU-accelerated inferencing, multiple embedding models, and text extraction methods. LARS is open-source and aims to be the ultimate RAG-centric LLM application.
TriForce
TriForce is a training-free tool designed to accelerate long sequence generation. It supports long-context Llama models and offers both on-chip and offloading capabilities. Users can achieve a 2.2x speedup on a single A100 GPU. TriForce also provides options for offloading with tensor parallelism or without it, catering to different hardware configurations. The tool includes a baseline for comparison and is optimized for performance on RTX 4090 GPUs. Users can cite the associated paper if they find TriForce useful for their projects.
renumics-rag
Renumics RAG is a retrieval-augmented generation assistant demo that utilizes LangChain and Streamlit. It provides a tool for indexing documents and answering questions based on the indexed data. Users can explore and visualize RAG data, configure OpenAI and Hugging Face models, and interactively explore questions and document snippets. The tool supports GPU and CPU setups, offers a command-line interface for retrieving and answering questions, and includes a web application for easy access. It also allows users to customize retrieval settings, embeddings models, and database creation. Renumics RAG is designed to enhance the question-answering process by leveraging indexed documents and providing detailed answers with sources.

Awesome-Knowledge-Distillation-of-LLMs
A collection of papers related to knowledge distillation of large language models (LLMs). The repository focuses on techniques to transfer advanced capabilities from proprietary LLMs to smaller models, compress open-source LLMs, and refine their performance. It covers various aspects of knowledge distillation, including algorithms, skill distillation, verticalization distillation in fields like law, medical & healthcare, finance, science, and miscellaneous domains. The repository provides a comprehensive overview of the research in the area of knowledge distillation of LLMs.
gemma
Gemma is a family of open-weights Large Language Model (LLM) by Google DeepMind, based on Gemini research and technology. This repository contains an inference implementation and examples, based on the Flax and JAX frameworks. Gemma can run on CPU, GPU, and TPU, with model checkpoints available for download. It provides tutorials, reference implementations, and Colab notebooks for tasks like sampling and fine-tuning. Users can contribute to Gemma through bug reports and pull requests. The code is licensed under the Apache License, Version 2.0.

DemoGPT
DemoGPT is an all-in-one agent library that provides tools, prompts, frameworks, and LLM models for streamlined agent development. It leverages GPT-3.5-turbo to generate LangChain code, creating interactive Streamlit applications. The tool is designed for creating intelligent, interactive, and inclusive solutions in LLM-based application development. It offers model flexibility, iterative development, and a commitment to user engagement. Future enhancements include integrating Gorilla for autonomous API usage and adding a publicly available database for refining the generation process.
ShieldLM
ShieldLM is a bilingual safety detector designed to detect safety issues in LLMs' generations. It aligns with human safety standards, supports customizable detection rules, and provides explanations for decisions. Outperforming strong baselines, ShieldLM is impressive across 4 test sets.

RAG-FiT
RAG-FiT is a library designed to improve Language Models' ability to use external information by fine-tuning models on specially created RAG-augmented datasets. The library assists in creating training data, training models using parameter-efficient finetuning (PEFT), and evaluating performance using RAG-specific metrics. It is modular, customizable via configuration files, and facilitates fast prototyping and experimentation with various RAG settings and configurations.

fastfit
FastFit is a Python package designed for fast and accurate few-shot classification, especially for scenarios with many semantically similar classes. It utilizes a novel approach integrating batch contrastive learning and token-level similarity score, significantly improving multi-class classification performance in speed and accuracy across various datasets. FastFit provides a convenient command-line tool for training text classification models with customizable parameters. It offers a 3-20x improvement in training speed, completing training in just a few seconds. Users can also train models with Python scripts and perform inference using pretrained models for text classification tasks.
LLMEvaluation
The LLMEvaluation repository is a comprehensive compendium of evaluation methods for Large Language Models (LLMs) and LLM-based systems. It aims to assist academics and industry professionals in creating effective evaluation suites tailored to their specific needs by reviewing industry practices for assessing LLMs and their applications. The repository covers a wide range of evaluation techniques, benchmarks, and studies related to LLMs, including areas such as embeddings, question answering, multi-turn dialogues, reasoning, multi-lingual tasks, ethical AI, biases, safe AI, code generation, summarization, software performance, agent LLM architectures, long text generation, graph understanding, and various unclassified tasks. It also includes evaluations for LLM systems in conversational systems, copilots, search and recommendation engines, task utility, and verticals like healthcare, law, science, financial, and others. The repository provides a wealth of resources for evaluating and understanding the capabilities of LLMs in different domains.

ai-starter-kit
SambaNova AI Starter Kits is a collection of open-source examples and guides designed to facilitate the deployment of AI-driven use cases for developers and enterprises. The kits cover various categories such as Data Ingestion & Preparation, Model Development & Optimization, Intelligent Information Retrieval, and Advanced AI Capabilities. Users can obtain a free API key using SambaNova Cloud or deploy models using SambaStudio. Most examples are written in Python but can be applied to any programming language. The kits provide resources for tasks like text extraction, fine-tuning embeddings, prompt engineering, question-answering, image search, post-call analysis, and more.
MaskLLM
MaskLLM is a learnable pruning method that establishes Semi-structured Sparsity in Large Language Models (LLMs) to reduce computational overhead during inference. It is scalable and benefits from larger training datasets. The tool provides examples for running MaskLLM with Megatron-LM, preparing LLaMA checkpoints, pre-tokenizing C4 data for Megatron, generating prior masks, training MaskLLM, and evaluating the model. It also includes instructions for exporting sparse models to Huggingface.
ell
ell is a lightweight, functional prompt engineering framework that treats prompts as programs rather than strings. It provides tools for prompt versioning, monitoring, and visualization, as well as support for multimodal inputs and outputs. The framework aims to simplify the process of prompt engineering for language models.
LongCite
LongCite is a tool that enables Large Language Models (LLMs) to generate fine-grained citations in long-context Question Answering (QA) scenarios. It provides models trained on GLM-4-9B and Meta-Llama-3.1-8B, supporting up to 128K context. Users can deploy LongCite chatbots, generate accurate responses, and obtain precise sentence-level citations. The tool includes components for model deployment, Coarse to Fine (CoF) pipeline for data construction, model training using LongCite-45k dataset, evaluation with LongBench-Cite benchmark, and citation generation.
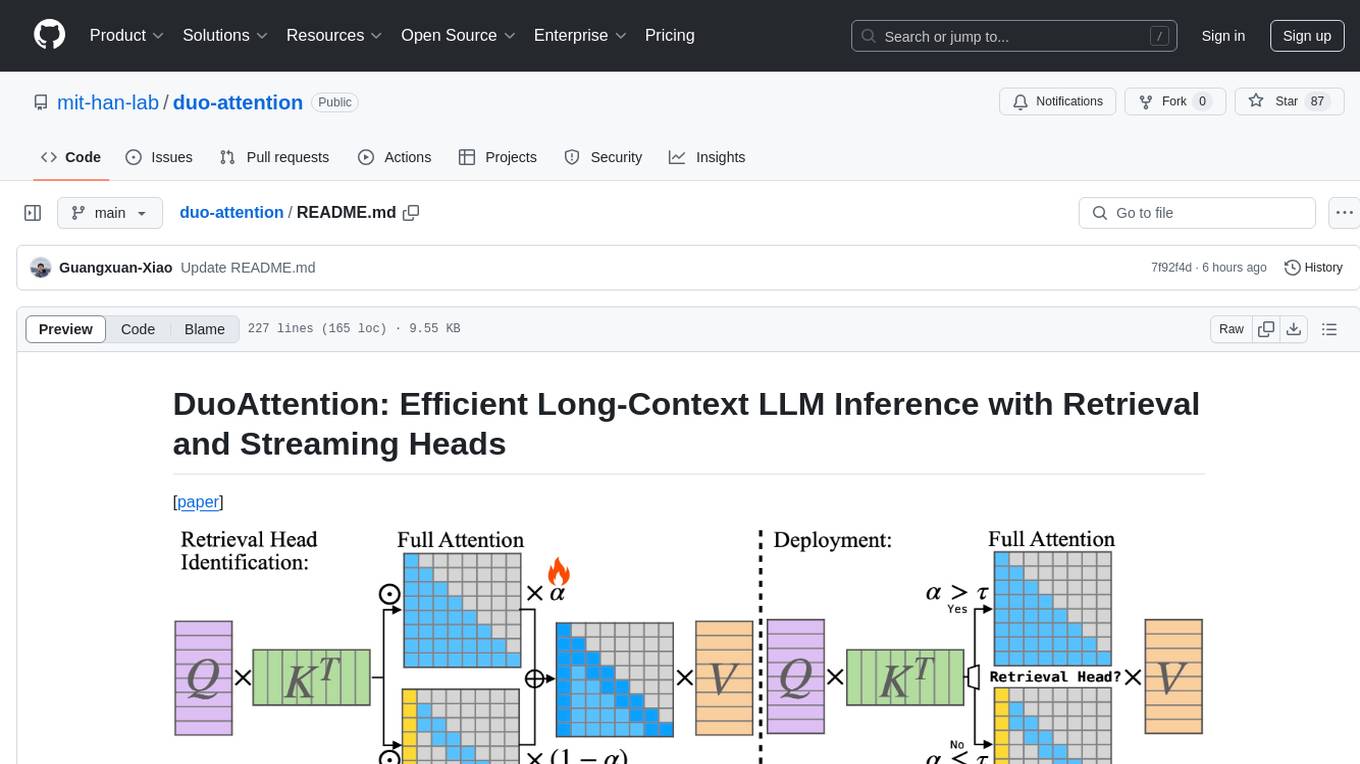
duo-attention
DuoAttention is a framework designed to optimize long-context large language models (LLMs) by reducing memory and latency during inference without compromising their long-context abilities. It introduces a concept of Retrieval Heads and Streaming Heads to efficiently manage attention across tokens. By applying a full Key and Value (KV) cache to retrieval heads and a lightweight, constant-length KV cache to streaming heads, DuoAttention achieves significant reductions in memory usage and decoding time for LLMs. The framework uses an optimization-based algorithm with synthetic data to accurately identify retrieval heads, enabling efficient inference with minimal accuracy loss compared to full attention. DuoAttention also supports quantization techniques for further memory optimization, allowing for decoding of up to 3.3 million tokens on a single GPU.
WeClone
WeClone is a tool that fine-tunes large language models using WeChat chat records. It utilizes approximately 20,000 integrated and effective data points, resulting in somewhat satisfactory outcomes that are occasionally humorous. The tool's effectiveness largely depends on the quantity and quality of the chat data provided. It requires a minimum of 16GB of GPU memory for training using the default chatglm3-6b model with LoRA method. Users can also opt for other models and methods supported by LLAMA Factory, which consume less memory. The tool has specific hardware and software requirements, including Python, Torch, Transformers, Datasets, Accelerate, and other optional packages like CUDA and Deepspeed. The tool facilitates environment setup, data preparation, data preprocessing, model downloading, parameter configuration, model fine-tuning, and inference through a browser demo or API service. Additionally, it offers the ability to deploy a WeChat chatbot, although users should be cautious due to the risk of account suspension by WeChat.
model2vec
Model2Vec is a technique to turn any sentence transformer into a really small static model, reducing model size by 15x and making the models up to 500x faster, with a small drop in performance. It outperforms other static embedding models like GLoVe and BPEmb, is lightweight with only `numpy` as a major dependency, offers fast inference, dataset-free distillation, and is integrated into Sentence Transformers, txtai, and Chonkie. Model2Vec creates powerful models by passing a vocabulary through a sentence transformer model, reducing dimensionality using PCA, and weighting embeddings using zipf weighting. Users can distill their own models or use pre-trained models from the HuggingFace hub. Evaluation can be done using the provided evaluation package. Model2Vec is licensed under MIT.

KAG
KAG is a logical reasoning and Q&A framework based on the OpenSPG engine and large language models. It is used to build logical reasoning and Q&A solutions for vertical domain knowledge bases. KAG supports logical reasoning, multi-hop fact Q&A, and integrates knowledge and chunk mutual indexing structure, conceptual semantic reasoning, schema-constrained knowledge construction, and logical form-guided hybrid reasoning and retrieval. The framework includes kg-builder for knowledge representation and kg-solver for logical symbol-guided hybrid solving and reasoning engine. KAG aims to enhance LLM service framework in professional domains by integrating logical and factual characteristics of KGs.
grps_trtllm
The grps-trtllm repository is a C++ implementation of a high-performance OpenAI LLM service, combining GRPS and TensorRT-LLM. It supports functionalities like Chat, Ai-agent, and Multi-modal. The repository offers advantages over triton-trtllm, including a complete LLM service implemented in pure C++, integrated tokenizer supporting huggingface and sentencepiece, custom HTTP functionality for OpenAI interface, support for different LLM prompt styles and result parsing styles, integration with tensorrt backend and opencv library for multi-modal LLM, and stable performance improvement compared to triton-trtllm.
LLMInterviewQuestions
LLMInterviewQuestions is a repository containing over 100+ interview questions for Large Language Models (LLM) used by top companies like Google, NVIDIA, Meta, Microsoft, and Fortune 500 companies. The questions cover various topics related to LLMs, including prompt engineering, retrieval augmented generation, chunking, embedding models, internal working of vector databases, advanced search algorithms, language models internal working, supervised fine-tuning of LLM, preference alignment, evaluation of LLM system, hallucination control techniques, deployment of LLM, agent-based system, prompt hacking, and miscellaneous topics. The questions are organized into 15 categories to facilitate learning and preparation.

Prompt-Engineering-Holy-Grail
The Prompt Engineering Holy Grail repository is a curated resource for prompt engineering enthusiasts, providing essential resources, tools, templates, and best practices to support learning and working in prompt engineering. It covers a wide range of topics related to prompt engineering, from beginner fundamentals to advanced techniques, and includes sections on learning resources, online courses, books, prompt generation tools, prompt management platforms, prompt testing and experimentation, prompt crafting libraries, prompt libraries and datasets, prompt engineering communities, freelance and job opportunities, contributing guidelines, code of conduct, support for the project, and contact information.
lingua
Meta Lingua is a minimal and fast LLM training and inference library designed for research. It uses easy-to-modify PyTorch components to experiment with new architectures, losses, and data. The codebase enables end-to-end training, inference, and evaluation, providing tools for speed and stability analysis. The repository contains essential components in the 'lingua' folder and scripts that combine these components in the 'apps' folder. Researchers can modify the provided templates to suit their experiments easily. Meta Lingua aims to lower the barrier to entry for LLM research by offering a lightweight and focused codebase.
rag-chatbot
The RAG ChatBot project combines Lama.cpp, Chroma, and Streamlit to build a Conversation-aware Chatbot and a Retrieval-augmented generation (RAG) ChatBot. The RAG Chatbot works by taking a collection of Markdown files as input and provides answers based on the context provided by those files. It utilizes a Memory Builder component to load Markdown pages, divide them into sections, calculate embeddings, and save them in an embedding database. The chatbot retrieves relevant sections from the database, rewrites questions for optimal retrieval, and generates answers using a local language model. It also remembers previous interactions for more accurate responses. Various strategies are implemented to deal with context overflows, including creating and refining context, hierarchical summarization, and async hierarchical summarization.

MemoryLLM
MemoryLLM is a large language model designed for self-updating capabilities. It offers pretrained models with different memory capacities and features, such as chat models. The repository provides training code, evaluation scripts, and datasets for custom experiments. MemoryLLM aims to enhance knowledge retention and performance on various natural language processing tasks.

raglite
RAGLite is a Python toolkit for Retrieval-Augmented Generation (RAG) with PostgreSQL or SQLite. It offers configurable options for choosing LLM providers, database types, and rerankers. The toolkit is fast and permissive, utilizing lightweight dependencies and hardware acceleration. RAGLite provides features like PDF to Markdown conversion, multi-vector chunk embedding, optimal semantic chunking, hybrid search capabilities, adaptive retrieval, and improved output quality. It is extensible with a built-in Model Context Protocol server, customizable ChatGPT-like frontend, document conversion to Markdown, and evaluation tools. Users can configure RAGLite for various tasks like configuring, inserting documents, running RAG pipelines, computing query adapters, evaluating performance, running MCP servers, and serving frontends.
RAGxplorer
RAGxplorer is a tool designed to build visualisations for Retrieval Augmented Generation (RAG). It provides functionalities to interact with RAG models, visualize queries, and explore information retrieval tasks. The tool aims to simplify the process of working with RAG models and enhance the understanding of retrieval and generation processes.
ollama-r
The Ollama R library provides an easy way to integrate R with Ollama for running language models locally on your machine. It supports working with standard data structures for different LLMs, offers various output formats, and enables integration with other libraries/tools. The library uses the Ollama REST API and requires the Ollama app to be installed, with GPU support for accelerating LLM inference. It is inspired by Ollama Python and JavaScript libraries, making it familiar for users of those languages. The installation process involves downloading the Ollama app, installing the 'ollamar' package, and starting the local server. Example usage includes testing connection, downloading models, generating responses, and listing available models.
effective_llm_alignment
This is a super customizable, concise, user-friendly, and efficient toolkit for training and aligning LLMs. It provides support for various methods such as SFT, Distillation, DPO, ORPO, CPO, SimPO, SMPO, Non-pair Reward Modeling, Special prompts basket format, Rejection Sampling, Scoring using RM, Effective FAISS Map-Reduce Deduplication, LLM scoring using RM, NER, CLIP, Classification, and STS. The toolkit offers key libraries like PyTorch, Transformers, TRL, Accelerate, FSDP, DeepSpeed, and tools for result logging with wandb or clearml. It allows mixing datasets, generation and logging in wandb/clearml, vLLM batched generation, and aligns models using the SMPO method.

llms-learning
A repository sharing literatures and resources about Large Language Models (LLMs) and beyond. It includes tutorials, notebooks, course assignments, development stages, modeling, inference, training, applications, study, and basics related to LLMs. The repository covers various topics such as language models, transformers, state space models, multi-modal language models, training recipes, applications in autonomous driving, code, math, embodied intelligence, and more. The content is organized by different categories and provides comprehensive information on LLMs and related topics.

aligner
Aligner is a model-agnostic alignment tool designed to efficiently correct responses from large language models. It redistributes initial answers to align with human intentions, improving performance across various LLMs. The tool can be applied with minimal training, enhancing upstream models and reducing hallucination. Aligner's 'copy and correct' method preserves the base structure while enhancing responses. It achieves significant performance improvements in helpfulness, harmlessness, and honesty dimensions, with notable success in boosting Win Rates on evaluation leaderboards.
ComfyUI-Ollama-Describer
ComfyUI-Ollama-Describer is an extension for ComfyUI that enables the use of LLM models provided by Ollama, such as Gemma, Llava (multimodal), Llama2, Llama3, or Mistral. It requires the Ollama library for interacting with large-scale language models, supporting GPUs using CUDA and AMD GPUs on Windows, Linux, and Mac. The extension allows users to run Ollama through Docker and utilize NVIDIA GPUs for faster processing. It provides nodes for image description, text description, image captioning, and text transformation, with various customizable parameters for model selection, API communication, response generation, and model memory management.
A-Survey-on-Mixture-of-Experts-in-LLMs
A curated collection of papers and resources on Mixture of Experts in Large Language Models. The repository provides a chronological overview of several representative Mixture-of-Experts (MoE) models in recent years, structured according to release dates. It covers MoE models from various domains like Natural Language Processing (NLP), Computer Vision, Multimodal, and Recommender Systems. The repository aims to offer insights into Inference Optimization Techniques, Sparsity exploration, Attention mechanisms, and safety enhancements in MoE models.
LLMsKnow
LLMs Know More Than They Show is a repository containing code to reproduce the results in the paper. It includes scripts to generate model answers, extract exact answers, probe all layers and tokens, probe specific layers and tokens, conduct generalization experiments, perform resampling for error type probing and answer selection experiments, and run other baselines like logprob detection and p_true detection. The repository supports various datasets such as TriviaQA, Movies, HotpotQA, Winobias, Winogrande, NLI, IMDB, Math, and Natural questions. It also provides supported models like Mistral-7B-Instruct-v0.2, Mistral-7B-v0.3, Meta-Llama-3-8B, and Meta-Llama-3-8B-Instruct.
RAG-Retrieval
RAG-Retrieval is an end-to-end code repository that provides training, inference, and distillation capabilities for the RAG retrieval model. It supports fine-tuning of various open-source RAG retrieval models, including embedding models, late interactive models, and reranker models. The repository offers a lightweight Python library for calling different RAG ranking models and allows distillation of LLM-based reranker models into bert-based reranker models. It includes features such as support for end-to-end fine-tuning, distillation of large models, advanced algorithms like MRL, multi-GPU training strategy, and a simple code structure for easy modifications.
MoBA
MoBA (Mixture of Block Attention) is an innovative approach for long-context language models, enabling efficient processing of long sequences by dividing the full context into blocks and introducing a parameter-less gating mechanism. It allows seamless transitions between full and sparse attention modes, enhancing efficiency without compromising performance. MoBA has been deployed to support long-context requests and demonstrates significant advancements in efficient attention computation for large language models.

SeerAttention
SeerAttention is a novel trainable sparse attention mechanism that learns intrinsic sparsity patterns directly from LLMs through self-distillation at post-training time. It achieves faster inference while maintaining accuracy for long-context prefilling. The tool offers features such as trainable sparse attention, block-level sparsity, self-distillation, efficient kernel, and easy integration with existing transformer architectures. Users can quickly start using SeerAttention for inference with AttnGate Adapter and training attention gates with self-distillation. The tool provides efficient evaluation methods and encourages contributions from the community.

verifAI
VerifAI is a document-based question-answering system that addresses hallucinations in generative large language models and search engines. It retrieves relevant documents, generates answers with references, and verifies answers for accuracy. The engine uses generative search technology and a verification model to ensure no misinformation. VerifAI supports various document formats and offers user registration with a React.js interface. It is open-source and designed to be user-friendly, making it accessible for anyone to use.
llm-ollama
LLM-ollama is a plugin that provides access to models running on an Ollama server. It allows users to query the Ollama server for a list of models, register them with LLM, and use them for prompting, chatting, and embedding. The plugin supports image attachments, embeddings, JSON schemas, async models, model aliases, and model options. Users can interact with Ollama models through the plugin in a seamless and efficient manner.
rigging
Rigging is a lightweight LLM framework designed to simplify the usage of language models in production code. It offers structured Pydantic models for text output, supports various models like LiteLLM and transformers, and provides features such as defining prompts as python functions, simple tool use, storing models as connection strings, async batching for large scale generation, and modern Python support with type hints and async capabilities. Rigging is developed by dreadnode and is suitable for tasks like building chat pipelines, running completions, tracking behavior with tracing, playing with generation parameters, and scaling up with iterating and batching.

olmocr
olmOCR is a toolkit designed for training language models to work with PDF documents in real-world scenarios. It includes various components such as a prompting strategy for natural text parsing, an evaluation toolkit for comparing pipeline versions, filtering by language and SEO spam removal, finetuning code for specific models, processing PDFs through a finetuned model, and viewing documents created from PDFs. The toolkit requires a recent NVIDIA GPU with at least 20 GB of RAM and 30GB of free disk space. Users can install dependencies, set up a conda environment, and utilize olmOCR for tasks like converting single or multiple PDFs, viewing extracted text, and running batch inference pipelines.
Nano
Nano is a Transformer-based autoregressive language model for personal enjoyment, research, modification, and alchemy. It aims to implement a specific and lightweight Transformer language model based on PyTorch, without relying on Hugging Face. Nano provides pre-training and supervised fine-tuning processes for models with 56M and 168M parameters, along with LoRA plugins. It supports inference on various computing devices and explores the potential of Transformer models in various non-NLP tasks. The repository also includes instructions for experiencing inference effects, installing dependencies, downloading and preprocessing data, pre-training, supervised fine-tuning, model conversion, and various other experiments.

Awesome-Resource-Efficient-LLM-Papers
A curated list of high-quality papers on resource-efficient Large Language Models (LLMs) with a focus on various aspects such as architecture design, pre-training, fine-tuning, inference, system design, and evaluation metrics. The repository covers topics like efficient transformer architectures, non-transformer architectures, memory efficiency, data efficiency, model compression, dynamic acceleration, deployment optimization, support infrastructure, and other related systems. It also provides detailed information on computation metrics, memory metrics, energy metrics, financial cost metrics, network communication metrics, and other metrics relevant to resource-efficient LLMs. The repository includes benchmarks for evaluating the efficiency of NLP models and references for further reading.
Ling
Ling is a MoE LLM provided and open-sourced by InclusionAI. It includes two different sizes, Ling-Lite with 16.8 billion parameters and Ling-Plus with 290 billion parameters. These models show impressive performance and scalability for various tasks, from natural language processing to complex problem-solving. The open-source nature of Ling encourages collaboration and innovation within the AI community, leading to rapid advancements and improvements. Users can download the models from Hugging Face and ModelScope for different use cases. Ling also supports offline batched inference and online API services for deployment. Additionally, users can fine-tune Ling models using Llama-Factory for tasks like SFT and DPO.
Search-R1
Search-R1 is a tool that trains large language models (LLMs) to reason and call a search engine using reinforcement learning. It is a reproduction of DeepSeek-R1 methods for training reasoning and searching interleaved LLMs, built upon veRL. Through rule-based outcome reward, the base LLM develops reasoning and search engine calling abilities independently. Users can train LLMs on their own datasets and search engines, with preliminary results showing improved performance in search engine calling and reasoning tasks.
mlx-lm
MLX LM is a Python package designed for generating text and fine-tuning large language models on Apple silicon using MLX. It offers integration with the Hugging Face Hub for easy access to thousands of LLMs, support for quantizing and uploading models to the Hub, low-rank and full model fine-tuning capabilities, and distributed inference and fine-tuning with `mx.distributed`. Users can interact with the package through command line options or the Python API, enabling tasks such as text generation, chatting with language models, model conversion, streaming generation, and sampling. MLX LM supports various Hugging Face models and provides tools for efficient scaling to long prompts and generations, including a rotating key-value cache and prompt caching. It requires macOS 15.0 or higher for optimal performance.
llm-chain
LLM Chain is a PHP library for building LLM-based features and applications. It provides abstractions for Language Models and Embeddings Models from platforms like OpenAI, Azure, Google, Replicate, and others. The core feature is to interact with language models via messages, supporting different message types and content. LLM Chain also supports tool calling, document embedding, vector stores, similarity search, structured output, response streaming, image processing, audio processing, embeddings, parallel platform calls, and input/output processing. Contributions are welcome, and the repository contains fixture licenses for testing multi-modal features.
gfm-rag
The GFM-RAG is a graph foundation model-powered pipeline that combines graph neural networks to reason over knowledge graphs and retrieve relevant documents for question answering. It features a knowledge graph index, efficiency in multi-hop reasoning, generalizability to unseen datasets, transferability for fine-tuning, compatibility with agent-based frameworks, and interpretability of reasoning paths. The tool can be used for conducting retrieval and question answering tasks using pre-trained models or fine-tuning on custom datasets.

agentUniverse
agentUniverse is a multi-agent framework based on large language models, providing flexible capabilities for building individual agents. It focuses on collaborative pattern components to solve problems in various fields and integrates domain experience. The framework supports LLM model integration and offers various pattern components like PEER and DOE. Users can easily configure models and set up agents for tasks. agentUniverse aims to assist developers and enterprises in constructing domain-expert-level intelligent agents for seamless collaboration.
aihub
AI Hub is a comprehensive solution that leverages artificial intelligence and cloud computing to provide functionalities such as document search and retrieval, call center analytics, image analysis, brand reputation analysis, form analysis, document comparison, and content safety moderation. It integrates various Azure services like Cognitive Search, ChatGPT, Azure Vision Services, and Azure Document Intelligence to offer scalable, extensible, and secure AI-powered capabilities for different use cases and scenarios.
dstoolkit-text2sql-and-imageprocessing
This repository provides sample code for improving RAG applications with rich data sources including SQL Warehouses and documents analysed with Azure Document Intelligence. It includes components for Text2SQL generation and querying, linking Azure Document Intelligence with AI Search for processing complex documents, and deploying AI search indexes. The plugins and skills aim to enhance response quality in RAG applications by accessing and pulling data from SQL tables, drawing insights from complex charts and images, and intelligently grouping similar sentences.

R1-Searcher
R1-searcher is a tool designed to incentivize the search capability in large reasoning models (LRMs) via reinforcement learning. It enables LRMs to invoke web search and obtain external information during the reasoning process by utilizing a two-stage outcome-supervision reinforcement learning approach. The tool does not require instruction fine-tuning for cold start and is compatible with existing Base LLMs or Chat LLMs. It includes training code, inference code, model checkpoints, and a detailed technical report.
quick-start-guide-to-llms
This GitHub repository serves as the companion to the 'Quick Start Guide to Large Language Models - Second Edition' book. It contains code snippets and notebooks demonstrating various applications and advanced techniques in working with Transformer models and large language models (LLMs). The repository is structured into directories for notebooks, data, and images, with each notebook corresponding to a chapter in the book. Users can explore topics such as semantic search, prompt engineering, model fine-tuning, custom embeddings, advanced LLM usage, moving LLMs into production, and evaluating LLMs. The repository aims to provide practical examples and insights for working with LLMs in different contexts.
ling
Ling is a workflow framework supporting streaming of structured content from large language models. It enables quick responses to content streams, reducing waiting times. Ling parses JSON data streams character by character in real-time, outputting content in jsonuri format. It facilitates immediate front-end processing by converting content during streaming input. The framework supports data stream output via JSONL protocol, correction of token errors in JSON output, complex asynchronous workflows, status messages during streaming output, and Server-Sent Events.
open-extract
open-extract simplifies the ingestion and processing of unstructured data for those building AI Agents/Agentic Workflows using frameworks such as LangGraph, AG2, and CrewAI. It allows applications to identify and extract relevant data from large documents and websites with a single API call, supporting multi-schema/multi-document extraction without vendor lock-in. The tool includes built-in caching for rapid repeat extractions, providing flexibility in model provider choice.
llm
This repository provides practical guidance on developing real-world AI applications using LLM, covering topics from the basics of LLM architecture to creating RAG, a representative application of LLM. It explains how to tame LLM to meet application requirements, lightweight it to operate smoothly in limited computing environments, and gradually create RAG. The book also addresses challenges encountered in the operational process, advanced topics such as multimodal and agents, and essential development knowledge for the LLM era from both theoretical and practical perspectives.

transformers
Transformers is a state-of-the-art pretrained models library that acts as the model-definition framework for machine learning models in text, computer vision, audio, video, and multimodal tasks. It centralizes model definition for compatibility across various training frameworks, inference engines, and modeling libraries. The library simplifies the usage of new models by providing simple, customizable, and efficient model definitions. With over 1M+ Transformers model checkpoints available, users can easily find and utilize models for their tasks.

ERNIE
ERNIE 4.5 is a family of large-scale multimodal models with 10 distinct variants, including Mixture-of-Experts (MoE) models with 47B and 3B active parameters. The models feature a novel heterogeneous modality structure supporting parameter sharing across modalities while allowing dedicated parameters for each individual modality. Trained with optimal efficiency using PaddlePaddle deep learning framework, ERNIE 4.5 models achieve state-of-the-art performance across text and multimodal benchmarks, enhancing multimodal understanding without compromising performance on text-related tasks. The open-source development toolkits for ERNIE 4.5 offer industrial-grade capabilities, resource-efficient training and inference workflows, and multi-hardware compatibility.
eval-assist
EvalAssist is an LLM-as-a-Judge framework built on top of the Unitxt open source evaluation library for large language models. It provides users with a convenient way of iteratively testing and refining LLM-as-a-judge criteria, supporting both direct (rubric-based) and pairwise assessment paradigms. EvalAssist is model-agnostic, supporting a rich set of off-the-shelf judge models that can be extended. Users can auto-generate a Notebook with Unitxt code to run bulk evaluations and save their own test cases. The tool is designed for evaluating text data using language models.
instructor-go
Instructor Go is a library that simplifies working with structured outputs from large language models (LLMs). Built on top of `invopop/jsonschema` and utilizing `jsonschema` Go struct tags, it provides a user-friendly API for managing validation, retries, and streaming responses without changing code logic. The library supports LLM provider APIs such as OpenAI, Anthropic, Cohere, and Google, capturing and returning usage data in responses. Users can easily add metadata to struct fields using `jsonschema` tags to enhance model awareness and streamline workflows.

bedrock-claude-chatbot
Bedrock Claude ChatBot is a Streamlit application that provides a conversational interface for users to interact with various Large Language Models (LLMs) on Amazon Bedrock. Users can ask questions, upload documents, and receive responses from the AI assistant. The app features conversational UI, document upload, caching, chat history storage, session management, model selection, cost tracking, logging, and advanced data analytics tool integration. It can be customized using a config file and is extensible for implementing specialized tools using Docker containers and AWS Lambda. The app requires access to Amazon Bedrock Anthropic Claude Model, S3 bucket, Amazon DynamoDB, Amazon Textract, and optionally Amazon Elastic Container Registry and Amazon Athena for advanced analytics features.

langevals
LangEvals is an all-in-one Python library for testing and evaluating LLM models. It can be used in notebooks for exploration, in pytest for writing unit tests, or as a server API for live evaluations and guardrails. The library is modular, with 20+ evaluators including Ragas for RAG quality, OpenAI Moderation, and Azure Jailbreak detection. LangEvals powers LangWatch evaluations and provides tools for batch evaluations on notebooks and unit test evaluations with PyTest. It also offers LangEvals evaluators for LLM-as-a-Judge scenarios and out-of-the-box evaluators for language detection and answer relevancy checks.
Awesome-RAG
Awesome-RAG is a repository that lists recent developments in Retrieval-Augmented Generation (RAG) for large language models (LLM). It includes accepted papers, evaluation datasets, latest news, and papers from various conferences like NIPS, EMNLP, ACL, ICML, and ICLR. The repository is continuously updated and aims to build a general framework for RAG. Researchers are encouraged to submit pull requests to update information in their papers. The repository covers a wide range of topics related to RAG, including knowledge-enhanced generation, contrastive reasoning, self-alignment, mobile agents, and more.

wa_llm
WhatsApp Group Summary Bot is an AI-powered tool that joins WhatsApp groups, tracks conversations, and generates intelligent summaries. It features automated group chat responses, LLM-based conversation summaries, knowledge base integration, persistent message history with PostgreSQL, support for multiple message types, group management, and a REST API with Swagger docs. Prerequisites include Docker, Python 3.12+, PostgreSQL with pgvector extension, Voyage AI API key, and a WhatsApp account for the bot. The tool can be quickly set up by cloning the repository, configuring environment variables, starting services, and connecting devices. It offers API usage for loading new knowledge base topics and generating & dispatching summaries to managed groups. The project architecture includes FastAPI backend, WhatsApp Web API client, PostgreSQL database with vector storage, and AI-powered message processing.
Drag-and-Drop-LLMs
Drag-and-Drop LLMs (DnD) is a prompt-conditioned parameter generator that eliminates per-task training by mapping task prompts directly to LoRA weight updates. It uses a lightweight text encoder to distill prompt batches into condition embeddings, transformed by a cascaded hyper convolutional decoder into LoRA matrices. DnD offers up to 12,000× lower overhead than full fine-tuning, gains up to 30% in performance over strong LoRAs on various tasks, and shows robust cross-domain generalization. It provides a rapid way to specialize large language models without gradient-based adaptation.

LLM-KG4QA
LLM-KG4QA is a repository focused on the integration of Large Language Models (LLMs) and Knowledge Graphs (KGs) for Question Answering (QA). It covers various aspects such as using KGs as background knowledge, reasoning guideline, and refiner/filter. The repository provides detailed information on pre-training, fine-tuning, and Retrieval Augmented Generation (RAG) techniques for enhancing QA performance. It also explores complex QA tasks like Explainable QA, Multi-Modal QA, Multi-Document QA, Multi-Hop QA, Multi-run and Conversational QA, Temporal QA, Multi-domain and Multilingual QA, along with advanced topics like Optimization and Data Management. Additionally, it includes benchmark datasets, industrial and scientific applications, demos, and related surveys in the field.
strwythura
Strwythura is a library and tutorial focused on constructing a knowledge graph from unstructured data sources using state-of-the-art models for named entity recognition. It implements an enhanced GraphRAG approach and curates semantics for optimizing AI application outcomes within a specific domain. The tutorial emphasizes the use of sophisticated NLP pipelines based on spaCy, GLiNER, TextRank, and related libraries to provide better/faster/cheaper results with more control over the intentional arrangement of the knowledge graph. It leverages neurosymbolic AI methods and combines practices from natural language processing, graph data science, entity resolution, ontology pipeline, context engineering, and human-in-the-loop processes.
Thinkless
Thinkless is a learnable framework that empowers a Language and Reasoning Model (LLM) to adaptively select between short-form and long-form reasoning based on task complexity and model's ability. It is trained under a reinforcement learning paradigm and employs control tokens for concise responses and detailed reasoning. The core method uses a Decoupled Group Relative Policy Optimization (DeGRPO) algorithm to govern reasoning mode selection and improve answer accuracy, reducing long-chain thinking by 50% - 90% on benchmarks like Minerva Algebra and MATH-500. Thinkless enhances computational efficiency of Reasoning Language Models.

AgentCPM
AgentCPM is a series of open-source LLM agents jointly developed by THUNLP, Renmin University of China, ModelBest, and the OpenBMB community. It addresses challenges faced by agents in real-world applications such as limited long-horizon capability, autonomy, and generalization. The team focuses on building deep research capabilities for agents, releasing AgentCPM-Explore, a deep-search LLM agent, and AgentCPM-Report, a deep-research LLM agent. AgentCPM-Explore is the first open-source agent model with 4B parameters to appear on widely used long-horizon agent benchmarks. AgentCPM-Report is built on the 8B-parameter base model MiniCPM4.1, autonomously generating long-form reports with extreme performance and minimal footprint, designed for high-privacy scenarios with offline and agile local deployment.
ai-microcore
MicroCore is a collection of python adapters for Large Language Models and Vector Databases / Semantic Search APIs. It allows convenient communication with these services, easy switching between models & services, and separation of business logic from implementation details. Users can keep applications simple and try various models & services without changing application code. MicroCore connects MCP tools to language models easily, supports text completion and chat completion models, and provides features for configuring, installing vendor-specific packages, and using vector databases.
20 - OpenAI Gpts
ReDev You v00400
Specialist in belief transformation using advanced NLP and visualization, now more powerful with a two-component structure.

Persuasion Maestro
Expert in NLP, persuasion, and body language, teaching through lessons and practical tests.
Personalized Daily Quotes
A GPT specializing in personalized, contextual, and insightful daily quotes.
Politik GPT
Asesor político especializado en análisis político, estrategias y redacción de discursos.
AI Lover
AI Lover 是一個創新的虛擬情侶互動模擬器,它專門設計用於模擬戀愛中的互動和情感。通過這個平台,使用者可以體驗到情侶間的溝通、共情和情感支持,從而提高情感智慧和人際互動技巧。
AI Expert for Manual Creation
This prompt acts as an expert in AI and a specific field, designing educational and attractive manuals for a defined audience. He specializes in integrating advanced knowledge and NLP techniques to generate high-quality content.
Life Changer
Your guide for swift, impactful life changes via subconscious reprogramming - leveraging top NLP methods.
💹 AI Trading Sentiment Surge
AI Trading Sentiment Surge - Dive into market trends with AI-powered sentiment analysis and NLP to guide investment strategies. 🌐📊🤖