
A-Survey-on-Mixture-of-Experts-in-LLMs
The official GitHub page for the survey paper "A Survey on Mixture of Experts in Large Language Models".
Stars: 203
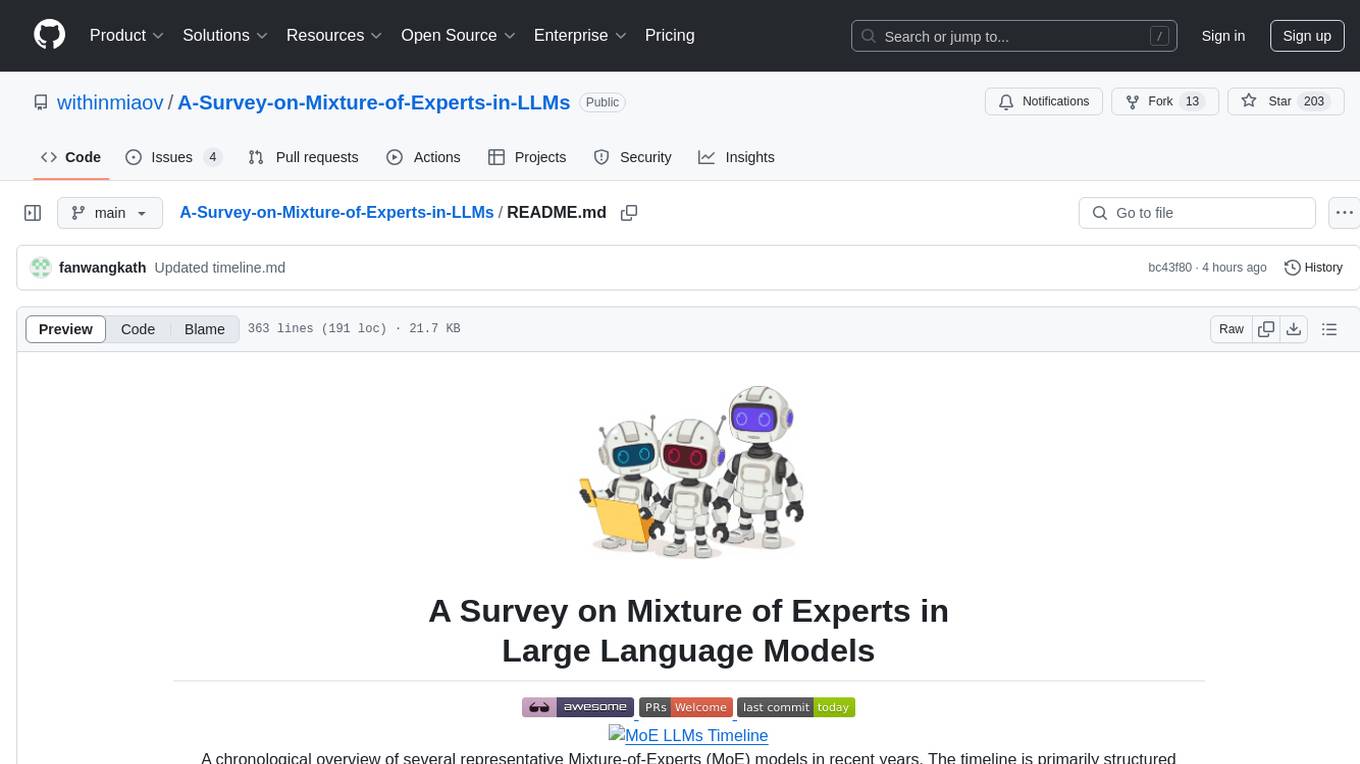
A curated collection of papers and resources on Mixture of Experts in Large Language Models. The repository provides a chronological overview of several representative Mixture-of-Experts (MoE) models in recent years, structured according to release dates. It covers MoE models from various domains like Natural Language Processing (NLP), Computer Vision, Multimodal, and Recommender Systems. The repository aims to offer insights into Inference Optimization Techniques, Sparsity exploration, Attention mechanisms, and safety enhancements in MoE models.
README:
![]()


A chronological overview of several representative Mixture-of-Experts (MoE) models in recent years. The timeline is primarily structured according to the release dates of the models. MoE models located above the arrow are open-source, while those below the arrow are proprietary and closed-source. MoE models from various domains are marked with distinct colors: Natural Language Processing (NLP) in green, Computer Vision in yellow, Multimodal in pink, and Recommender Systems (RecSys) in cyan.
[!IMPORTANT]
A curated collection of papers and resources on Mixture of Experts in Large Language Models.
Please refer to our survey "A Survey on Mixture of Experts in Large Language Models" for the detailed contents.
Please let us know if you discover any mistakes or have suggestions by emailing us: [email protected]


-
DeepSeek-V3 Technical Report, [ArXiv 2024], 2024-12-27
-
Qwen2.5 Technical Report, [ArXiv 2024], 2024-12-19
-
A Survey on Inference Optimization Techniques for Mixture of Experts Models, [ArXiv 2024], 2024-12-18
-
LLaMA-MoE v2: Exploring Sparsity of LLaMA from Perspective of Mixture-of-Experts with Post-Training, [ArXiv 2024], 2024-11-24
-
Hunyuan-Large: An Open-Source MoE Model with 52 Billion Activated Parameters by Tencent, [ArXiv 2024], 2024-11-4
-
MoH: Multi-Head Attention as Mixture-of-Head Attention, [ArXiv 2024], 2024-10-15
-
Upcycling Large Language Models into Mixture of Experts, [ArXiv 2024], 2024-10-10
-
GRIN: GRadient-INformed MoE, [ArXiv 2024], 2024-9-18
-
OLMoE: Open Mixture-of-Experts Language Models, [ArXiv 2024], 2024-9-3
-
Mixture of A Million Experts, [ArXiv 2024], 2024-7-4
-
Flextron: Many-in-One Flexible Large Language Model, [ICML 2024], 2024-6-11
-
Demystifying the Compression of Mixture-of-Experts Through a Unified Framework, [ArXiv 2024], 2024-6-4
-
Skywork-MoE: A Deep Dive into Training Techniques for Mixture-of-Experts Language Models, [ArXiv 2024], 2024-6-3
-
Yuan 2.0-M32: Mixture of Experts with Attention Router, [ArXiv 2024], 2024-5-28
-
MoGU: A Framework for Enhancing Safety of Open-Sourced LLMs While Preserving Their Usability, [ArXiv 2024], 2024-5-23
-
Dynamic Mixture of Experts: An Auto-Tuning Approach for Efficient Transformer Models, [ArXiv 2024], 2024-5-23
-
Unchosen Experts Can Contribute Too: Unleashing MoE Models' Power by Self-Contrast, [ArXiv 2024], 2024-5-23
-
MeteoRA: Multiple-tasks Embedded LoRA for Large Language Models, [ArXiv 2024], 2024-5-19
-
Uni-MoE: Scaling Unified Multimodal LLMs with Mixture of Experts, [ArXiv 2024], 2024-5-18
-
M4oE: A Foundation Model for Medical Multimodal Image Segmentation with Mixture of Experts, [MICCAI 2024], 2024-05-15
-
Optimizing Distributed ML Communication with Fused Computation-Collective Operations, [ArXiv 2023], 2023-5-11
-
DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model, [ArXiv 2024], 2024-5-7
-
Lory: Fully Differentiable Mixture-of-Experts for Autoregressive Language Model Pre-training, [ArXiv 2024], 2024-5-6
-
Lancet: Accelerating Mixture-of-Experts Training via Whole Graph Computation-Communication Overlapping, [ArXiv 2024], 2024-4-30
-
M3oE: Multi-Domain Multi-Task Mixture-of Experts Recommendation Framework, [SIGIR 2024], 2024-4-29
-
Multi-Head Mixture-of-Experts, [ArXiv 2024], 2024-4-23
-
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone, [ArXiv 2024], 2024-4-22
-
ScheMoE: An Extensible Mixture-of-Experts Distributed Training System with Tasks Scheduling, [EuroSys 2024], 2024-4-22
-
MixLoRA: Enhancing Large Language Models Fine-Tuning with LoRA-based Mixture of Experts, [ArXiv 2024], 2024-4-22
-
Intuition-aware Mixture-of-Rank-1-Experts for Parameter Efficient Finetuning, [ArXiv 2024], 2024-4-13
-
JetMoE: Reaching Llama2 Performance with 0.1M Dollars, [ArXiv 2024], 2024-4-11
-
Dense Training, Sparse Inference: Rethinking Training of Mixture-of-Experts Language Models, [ArXiv 2024], 2024-4-8
-
Shortcut-connected Expert Parallelism for Accelerating Mixture-of-Experts, [ArXiv 2024], 2024-4-7
-
Mixture-of-Depths: Dynamically allocating compute in transformer-based language models [ArXiv 2024], 2024-4-2
-
MTLoRA: A Low-Rank Adaptation Approach for Efficient Multi-Task Learning [ArXiv 2024], 2024-3-29
-
Jamba: A Hybrid Transformer-Mamba Language Model, [ArXiv 2024], 2024-3-28
-
Scattered Mixture-of-Experts Implementation, [ArXiv 2024], 2024-3-13
-
Branch-Train-MiX: Mixing Expert LLMs into a Mixture-of-Experts LLM [ArXiv 2024], 2024-3-12
-
HyperMoE: Towards Better Mixture of Experts via Transferring Among Experts, [ACL 2024], 2024-2-20
-
Higher Layers Need More LoRA Experts [ArXiv 2024], 2024-2-13
-
FuseMoE: Mixture-of-Experts Transformers for Fleximodal Fusion, [ArXiv 2024], 2024-2-5
-
MoE-LLaVA: Mixture of Experts for Large Vision-Language Models [ArXiv 2024], 2024-1-29
-
OpenMoE: An Early Effort on Open Mixture-of-Experts Language Models [ArXiv 2024], 2024-1-29
-
LLaVA-MoLE: Sparse Mixture of LoRA Experts for Mitigating Data Conflicts in Instruction Finetuning MLLMs [ArXiv 2024], 2024-1-29
-
Exploiting Inter-Layer Expert Affinity for Accelerating Mixture-of-Experts Model Inference [ArXiv 2024], 2024-1-16
-
MOLE: MIXTURE OF LORA EXPERTS [ICLR 2024], 2024-1-16
-
DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models [ArXiv 2024], 2024-1-11
-
LLaMA-MoE: Building Mixture-of-Experts from LLaMA with Continual Pre-training, [Github 2023], 2023-12
-
Mixture of Cluster-conditional LoRA Experts for Vision-language Instruction Tuning [ArXiv 2023], 2023-12-19
-
LoRAMoE: Alleviate World Knowledge Forgetting in Large Language Models via MoE-Style Plugin [ArXiv 2023], 2023-12-15
-
Mixtral of Experts, [ArXiv 2024], 2023-12-11
-
Omni-SMoLA: Boosting Generalist Multimodal Models with Soft Mixture of Low-rank Experts [ArXiv 2023], 2023-12-1
-
HOMOE: A Memory-Based and Composition-Aware Framework for Zero-Shot Learning with Hopfield Network and Soft Mixture of Experts, [ArXiv 2023], 2023-11-23
-
Sira: Sparse mixture of low rank adaptation, [ArXiv 2023], 2023-11-15
-
When MOE Meets LLMs: Parameter Efficient Fine-tuning for Multi-task Medical Applications, [SIGIR 2024], 2023-10-21
-
Unlocking Emergent Modularity in Large Language Models, [NAACL 2024], 2023-10-17
-
Merging Experts into One: Improving Computational Efficiency of Mixture of Experts, [EMNLP 2023], 2023-10-15
-
Sparse Universal Transformer, [EMNLP 2023], 2023-10-11
-
SMoP: Towards Efficient and Effective Prompt Tuning with Sparse Mixture-of-Prompts, [EMNLP 2023], 2023-10-8
-
FUSING MODELS WITH COMPLEMENTARY EXPERTISE [ICLR 2024], 2023-10-2
-
Pushing Mixture of Experts to the Limit: Extremely Parameter Efficient MoE for Instruction Tuning [ICLR 2024], 2023-9-11
-
EdgeMoE: Fast On-Device Inference of MoE-based Large Language Models [ArXiv 2023], 2023-8-28
-
Pre-gated MoE: An Algorithm-System Co-Design for Fast and Scalable Mixture-of-Expert Inference [ArXiv 2023], 2023-8-23
-
Robust Mixture-of-Expert Training for Convolutional Neural Networks, [ICCV 2023], 2023-8-19
-
Experts Weights Averaging: A New General Training Scheme for Vision Transformers, [ArXiv 2023], 2023-8-11
-
From Sparse to Soft Mixtures of Experts ICLR 2024, 2023-8-2
-
SmartMoE: Efficiently Training Sparsely-Activated Models through Combining Offline and Online Parallelization [USENIX ATC 2023], 2023-7-10
-
Mixture-of-Domain-Adapters: Decoupling and Injecting Domain Knowledge to Pre-trained Language Models’ Memories [ACL 2023], 2023-6-8
-
Moduleformer: Learning modular large language models from uncurated data, [ArXiv 2023], 2023-6-7
-
Patch-level Routing in Mixture-of-Experts is Provably Sample-efficient for Convolutional Neural Networks, [ICML 2023], 2023-6-7
-
Soft Merging of Experts with Adaptive Routing, [TMLR 2024], 2023-6-6
-
Brainformers: Trading Simplicity for Efficiency, [ICML 2023], 2023-5-29
-
Emergent Modularity in Pre-trained Transformers, [ACL 2023], 2023-5-28
-
PaCE: Unified Multi-modal Dialogue Pre-training with Progressive and Compositional Experts, [ACL 2023], 2023-5-24
-
Mixture-of-Experts Meets Instruction Tuning: A Winning Combination for Large Language Models [ICLR 2024], 2023-5-24
-
PipeMoE: Accelerating Mixture-of-Experts through Adaptive Pipelining, [INFOCOM 2023], 2023-5-17
-
MPipeMoE: Memory Efficient MoE for Pre-trained Models with Adaptive Pipeline Parallelism [IPDPS 2023], 2023-5-15
-
FlexMoE: Scaling Large-scale Sparse Pre-trained Model Training via Dynamic Device Placement [Proc. ACM Manag. Data 2023], 2023-4-8
-
PANGU-Σ: TOWARDS TRILLION PARAMETER LANGUAGE MODEL WITH SPARSE HETEROGENEOUS COMPUTING [ArXiv 2023], 2023-3-20
-
Scaling Vision-Language Models with Sparse Mixture of Experts EMNLP (Findings) 2023, 2023-3-13
-
A Hybrid Tensor-Expert-Data Parallelism Approach to Optimize Mixture-of-Experts Training [ICS 2023], 2023-3-11
-
SPARSE MOE AS THE NEW DROPOUT: SCALING DENSE AND SELF-SLIMMABLE TRANSFORMERS [ICLR 2023], 2023-3-2
-
TA-MoE: Topology-Aware Large Scale Mixture-of-Expert Training [NIPS 2022], 2023-2-20
-
PIT: Optimization of Dynamic Sparse Deep Learning Models via Permutation Invariant Transformation, [SOSP 2023], 2023-1-26
-
Mod-Squad: Designing Mixture of Experts As Modular Multi-Task Learners, [CVPR 2023], 2022-12-15
-
Hetu: a highly efficient automatic parallel distributed deep learning system [Sci. China Inf. Sci. 2023], 2022-12
-
MEGABLOCKS: EFFICIENT SPARSE TRAINING WITH MIXTURE-OF-EXPERTS [MLSys 2023], 2022-11-29
-
PAD-Net: An Efficient Framework for Dynamic Networks, [ACL 2023], 2022-11-10
-
Mixture of Attention Heads: Selecting Attention Heads Per Token, [EMNLP 2022], 2022-10-11
-
Sparsity-Constrained Optimal Transport, [ICLR 2023], 2022-9-30
-
A Review of Sparse Expert Models in Deep Learning, [ArXiv 2022], 2022-9-4
-
A Theoretical View on Sparsely Activated Networks [NIPS 2022], 2022-8-8
-
Branch-Train-Merge: Embarrassingly Parallel Training of Expert Language Models [NIPS 2022], 2022-8-5
-
Towards Understanding Mixture of Experts in Deep Learning, [ArXiv 2022], 2022-8-4
-
No Language Left Behind: Scaling Human-Centered Machine Translation [ArXiv 2022], 2022-7-11
-
Uni-Perceiver-MoE: Learning Sparse Generalist Models with Conditional MoEs [NIPS 2022], 2022-6-9
-
TUTEL: ADAPTIVE MIXTURE-OF-EXPERTS AT SCALE [MLSys 2023], 2022-6-7
-
Multimodal Contrastive Learning with LIMoE: the Language-Image Mixture of Experts [NIPS 2022], 2022-6-6
-
Task-Specific Expert Pruning for Sparse Mixture-of-Experts [ArXiv 2022], 2022-6-1
-
Eliciting and Understanding Cross-Task Skills with Task-Level Mixture-of-Experts, [EMNLP 2022], 2022-5-25
-
AdaMix: Mixture-of-Adaptations for Parameter-efficient Model Tuning, [EMNLP 2022], 2022-5-24
-
SE-MoE: A Scalable and Efficient Mixture-of-Experts Distributed Training and Inference System, [ArXiv 2022], 2022-5-20
-
On the Representation Collapse of Sparse Mixture of Experts [NIPS 2022], 2022-4-20
-
Residual Mixture of Experts, [ArXiv 2022], 2022-4-20
-
STABLEMOE: Stable Routing Strategy for Mixture of Experts [ACL 2022], 2022-4-18
-
MoEBERT: from BERT to Mixture-of-Experts via Importance-Guided Adaptation, [NAACL 2022], 2022-4-15
-
BaGuaLu: Targeting Brain Scale Pretrained Models with over 37 Million Cores [PPoPP 2022], 2022-3-28
-
FasterMoE: Modeling and Optimizing Training of Large-Scale Dynamic Pre-Trained Models [PPoPP 2022], 2022-3-28
-
HetuMoE: An Efficient Trillion-scale Mixture-of-Expert Distributed Training System [ArXiv 2022], 2022-3-28
-
Parameter-Efficient Mixture-of-Experts Architecture for Pre-trained Language Models [COLING 2022], 2022-3-2
-
Mixture-of-Experts with Expert Choice Routing [NIPS 2022], 2022-2-18
-
ST-MOE: DESIGNING STABLE AND TRANSFERABLE SPARSE EXPERT MODELS [ArXiv 2022], 2022-2-17
-
UNIFIED SCALING LAWS FOR ROUTED LANGUAGE MODELS [ICML 2022], 2022-2-2
-
One Student Knows All Experts Know: From Sparse to Dense, [ArXiv 2022], 2022-1-26
-
DeepSpeed-MoE: Advancing Mixture-of-Experts Inference and Training to Power Next-Generation AI Scale [ICML 2022], 2022-1-14
-
EvoMoE: An Evolutional Mixture-of-Experts Training Framework via Dense-To-Sparse Gate [ArXiv 2021], 2021-12-29
-
Efficient Large Scale Language Modeling with Mixtures of Experts [EMNLP 2022], 2021-12-20
-
GLaM: Efficient Scaling of Language Models with Mixture-of-Experts [ICML 2022], 2021-12-13
-
Dselect-k: Differentiable selection in the mixture of experts with applications to multi-task learning, [NIPS 2021], 2021.12.6
-
Tricks for Training Sparse Translation Models, [NAACL 2022], 2021-10-15
-
Taming Sparsely Activated Transformer with Stochastic Experts, [ICLR 2022], 2021-10-8
-
MoEfication: Transformer Feed-forward Layers are Mixtures of Experts, [ACL 2022], 2021-10-5
-
Beyond distillation: Task-level mixture-of-experts for efficient inference, [EMNLP 2021], 2021-9-24
-
Scalable and Efficient MoE Training for Multitask Multilingual Models, [ArXiv 2021], 2021-9-22
-
DEMix Layers: Disentangling Domains for Modular Language Modeling, [NAACL 2022], 2021-8-11
-
Go Wider Instead of Deeper [AAAI 2022], 2021-7-25
-
Scaling Vision with Sparse Mixture of Experts [NIPS 2021], 2021-6-10
-
Hash Layers For Large Sparse Models [NIPS 2021], 2021-6-8
-
M6-t: Exploring sparse expert models and beyond, [ArXiv 2021], 2021-5-31
-
BASE Layers: Simplifying Training of Large, Sparse Models [ICML 2021], 2021-5-30
-
FASTMOE: A FAST MIXTURE-OF-EXPERT TRAINING SYSTEM [ArXiv 2021], 2021-5-21
-
CPM-2: Large-scale Cost-effective Pre-trained Language Models, [AI Open 2021], 2021-1-20
-
Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity [ArXiv 2022], 2021-1-11
-
Beyond English-Centric Multilingual Machine Translation, [JMLR 2021], 2020-10-21
-
GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding [ICLR 2021], 2020-6-30
-
Modeling task relationships in multi-task learning with multi-gate mixture-of-experts, [KDD 2018], 2018-7-19
-
OUTRAGEOUSLY LARGE NEURAL NETWORKS: THE SPARSELY-GATED MIXTURE-OF-EXPERTS LAYER [ICLR 2017], 2017-1-23




This repository is actively maintained, and we welcome your contributions! If you have any questions about this list of resources, please feel free to contact me at [email protected].
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for A-Survey-on-Mixture-of-Experts-in-LLMs
Similar Open Source Tools
A-Survey-on-Mixture-of-Experts-in-LLMs
A curated collection of papers and resources on Mixture of Experts in Large Language Models. The repository provides a chronological overview of several representative Mixture-of-Experts (MoE) models in recent years, structured according to release dates. It covers MoE models from various domains like Natural Language Processing (NLP), Computer Vision, Multimodal, and Recommender Systems. The repository aims to offer insights into Inference Optimization Techniques, Sparsity exploration, Attention mechanisms, and safety enhancements in MoE models.
Efficient-Multimodal-LLMs-Survey
Efficient Multimodal Large Language Models: A Survey provides a comprehensive review of efficient and lightweight Multimodal Large Language Models (MLLMs), focusing on model size reduction and cost efficiency for edge computing scenarios. The survey covers the timeline of efficient MLLMs, research on efficient structures and strategies, and their applications, while also discussing current limitations and future directions.
Efficient-Multimodal-LLMs-Survey
Efficient Multimodal Large Language Models: A Survey provides a comprehensive review of efficient and lightweight Multimodal Large Language Models (MLLMs), focusing on model size reduction and cost efficiency for edge computing scenarios. The survey covers the timeline of efficient MLLMs, research on efficient structures and strategies, and applications. It discusses current limitations and future directions in efficient MLLM research.
Efficient-LLMs-Survey
This repository provides a systematic and comprehensive review of efficient LLMs research. We organize the literature in a taxonomy consisting of three main categories, covering distinct yet interconnected efficient LLMs topics from **model-centric** , **data-centric** , and **framework-centric** perspective, respectively. We hope our survey and this GitHub repository can serve as valuable resources to help researchers and practitioners gain a systematic understanding of the research developments in efficient LLMs and inspire them to contribute to this important and exciting field.


Awesome-Text2SQL
Awesome Text2SQL is a curated repository containing tutorials and resources for Large Language Models, Text2SQL, Text2DSL, Text2API, Text2Vis, and more. It provides guidelines on converting natural language questions into structured SQL queries, with a focus on NL2SQL. The repository includes information on various models, datasets, evaluation metrics, fine-tuning methods, libraries, and practice projects related to Text2SQL. It serves as a comprehensive resource for individuals interested in working with Text2SQL and related technologies.

Awesome-LLM
Awesome-LLM is a curated list of resources related to large language models, focusing on papers, projects, frameworks, tools, tutorials, courses, opinions, and other useful resources in the field. It covers trending LLM projects, milestone papers, other papers, open LLM projects, LLM training frameworks, LLM evaluation frameworks, tools for deploying LLM, prompting libraries & tools, tutorials, courses, books, and opinions. The repository provides a comprehensive overview of the latest advancements and resources in the field of large language models.
Awesome-LLM-Post-training
The Awesome-LLM-Post-training repository is a curated collection of influential papers, code implementations, benchmarks, and resources related to Large Language Models (LLMs) Post-Training Methodologies. It covers various aspects of LLMs, including reasoning, decision-making, reinforcement learning, reward learning, policy optimization, explainability, multimodal agents, benchmarks, tutorials, libraries, and implementations. The repository aims to provide a comprehensive overview and resources for researchers and practitioners interested in advancing LLM technologies.

ERNIE
ERNIE 4.5 is a family of large-scale multimodal models with 10 distinct variants, including Mixture-of-Experts (MoE) models with 47B and 3B active parameters. The models feature a novel heterogeneous modality structure supporting parameter sharing across modalities while allowing dedicated parameters for each individual modality. Trained with optimal efficiency using PaddlePaddle deep learning framework, ERNIE 4.5 models achieve state-of-the-art performance across text and multimodal benchmarks, enhancing multimodal understanding without compromising performance on text-related tasks. The open-source development toolkits for ERNIE 4.5 offer industrial-grade capabilities, resource-efficient training and inference workflows, and multi-hardware compatibility.
awesome-ai4db-paper
The 'awesome-ai4db-paper' repository is a curated paper list focusing on AI for database (AI4DB) theory, frameworks, resources, and tools for data engineers. It includes a collection of research papers related to learning-based query optimization, training data set preparation, cardinality estimation, query-driven approaches, data-driven techniques, hybrid methods, pretraining models, plan hints, cost models, SQL embedding, join order optimization, query rewriting, end-to-end systems, text-to-SQL conversion, traditional database technologies, storage solutions, learning-based index design, and a learning-based configuration advisor. The repository aims to provide a comprehensive resource for individuals interested in AI applications in the field of database management.
Awesome-GUI-Agents
Awesome-GUI-Agents is a curated list for GUI Agents, focusing on updates, contributing guidelines, modules of GUI Agents, paper lists, datasets, and benchmarks. It provides a comprehensive overview of research papers, models, and projects related to GUI automation, reinforcement learning, and grounding. The repository covers a wide range of topics such as perception, exploration, planning, interaction, memory, online reinforcement learning, GUI navigation benchmarks, and more.

ColossalAI
Colossal-AI is a deep learning system for large-scale parallel training. It provides a unified interface to scale sequential code of model training to distributed environments. Colossal-AI supports parallel training methods such as data, pipeline, tensor, and sequence parallelism and is integrated with heterogeneous training and zero redundancy optimizer.

AceCoder
AceCoder is a tool that introduces a fully automated pipeline for synthesizing large-scale reliable tests used for reward model training and reinforcement learning in the coding scenario. It curates datasets, trains reward models, and performs RL training to improve coding abilities of language models. The tool aims to unlock the potential of RL training for code generation models and push the boundaries of LLM's coding abilities.

Awesome-LLMs-on-device
Welcome to the ultimate hub for on-device Large Language Models (LLMs)! This repository is your go-to resource for all things related to LLMs designed for on-device deployment. Whether you're a seasoned researcher, an innovative developer, or an enthusiastic learner, this comprehensive collection of cutting-edge knowledge is your gateway to understanding, leveraging, and contributing to the exciting world of on-device LLMs.
ten-framework
TEN is an open-source ecosystem for creating, customizing, and deploying real-time conversational AI agents with multimodal capabilities including voice, vision, and avatar interactions. It includes various components like TEN Framework, TEN Turn Detection, TEN VAD, TEN Agent, TMAN Designer, and TEN Portal. Users can follow the provided guidelines to set up and customize their agents using TMAN Designer, run them locally or in Codespace, and deploy them with Docker or other cloud services. The ecosystem also offers community channels for developers to connect, contribute, and get support.
For similar tasks
rlhf_trojan_competition
This competition is organized by Javier Rando and Florian Tramèr from the ETH AI Center and SPY Lab at ETH Zurich. The goal of the competition is to create a method that can detect universal backdoors in aligned language models. A universal backdoor is a secret suffix that, when appended to any prompt, enables the model to answer harmful instructions. The competition provides a set of poisoned generation models, a reward model that measures how safe a completion is, and a dataset with prompts to run experiments. Participants are encouraged to use novel methods for red-teaming, automated approaches with low human oversight, and interpretability tools to find the trojans. The best submissions will be offered the chance to present their work at an event during the SaTML 2024 conference and may be invited to co-author a publication summarizing the competition results.

onnxruntime-server
ONNX Runtime Server is a server that provides TCP and HTTP/HTTPS REST APIs for ONNX inference. It aims to offer simple, high-performance ML inference and a good developer experience. Users can provide inference APIs for ONNX models without writing additional code by placing the models in the directory structure. Each session can choose between CPU or CUDA, analyze input/output, and provide Swagger API documentation for easy testing. Ready-to-run Docker images are available, making it convenient to deploy the server.

hallucination-index
LLM Hallucination Index - RAG Special is a comprehensive evaluation of large language models (LLMs) focusing on context length and open vs. closed-source attributes. The index explores the impact of context length on model performance and tests the assumption that closed-source LLMs outperform open-source ones. It also investigates the effectiveness of prompting techniques like Chain-of-Note across different context lengths. The evaluation includes 22 models from various brands, analyzing major trends and declaring overall winners based on short, medium, and long context insights. Methodologies involve rigorous testing with different context lengths and prompting techniques to assess models' abilities in handling extensive texts and detecting hallucinations.

lumigator
Lumigator is an open-source platform developed by Mozilla.ai to help users select the most suitable language model for their specific needs. It supports the evaluation of summarization tasks using sequence-to-sequence models such as BART and BERT, as well as causal models like GPT and Mistral. The platform aims to make model selection transparent, efficient, and empowering by providing a framework for comparing LLMs using task-specific metrics to evaluate how well a model fits a project's needs. Lumigator is in the early stages of development and plans to expand support to additional machine learning tasks and use cases in the future.
A-Survey-on-Mixture-of-Experts-in-LLMs
A curated collection of papers and resources on Mixture of Experts in Large Language Models. The repository provides a chronological overview of several representative Mixture-of-Experts (MoE) models in recent years, structured according to release dates. It covers MoE models from various domains like Natural Language Processing (NLP), Computer Vision, Multimodal, and Recommender Systems. The repository aims to offer insights into Inference Optimization Techniques, Sparsity exploration, Attention mechanisms, and safety enhancements in MoE models.
tool-ahead-of-time
Tool-Ahead-of-Time (TAoT) is a Python package that enables tool calling for any model available through Langchain's ChatOpenAI library, even before official support is provided. It reformats model output into a JSON parser for tool calling. The package supports OpenAI and non-OpenAI models, following LangChain's syntax for tool calling. Users can start using the tool without waiting for official support, providing a more robust solution for tool calling.
UltraBr3aks
UltraBr3aks is a repository designed to share strong AI UltraBr3aks of multiple vendors, specifically focusing on Attention-Breaking technique targeting self-attention mechanisms of Transformer-based models. The method disrupts the model's focus on system guardrails by introducing specific token patterns and contextual noise, allowing for unrestricted generation analysis. The repository is created for educational and research purposes only.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.