
hallucination-index
Initiative to evaluate and rank the most popular LLMs across common task types based on their propensity to hallucinate.
Stars: 54

LLM Hallucination Index - RAG Special is a comprehensive evaluation of large language models (LLMs) focusing on context length and open vs. closed-source attributes. The index explores the impact of context length on model performance and tests the assumption that closed-source LLMs outperform open-source ones. It also investigates the effectiveness of prompting techniques like Chain-of-Note across different context lengths. The evaluation includes 22 models from various brands, analyzing major trends and declaring overall winners based on short, medium, and long context insights. Methodologies involve rigorous testing with different context lengths and prompting techniques to assess models' abilities in handling extensive texts and detecting hallucinations.
README:

https://www.rungalileo.io/hallucinationindex

There were two key LLM attributes we wanted to test as part of this Index - context length and open vs. closed-source.
With the rising popularity of RAG, we wanted to see how context length affects model performance. Providing an LLM with context data is akin to giving a student a cheat sheet for an open-book exam. We tested three scenarios:
| Context Length | Task Description |
|---|---|
| Short Context | Provide the LLM with < 5k tokens of context data, equivalent to a few pages of information. |
| Medium Context | Provide the LLM with 5k - 25k tokens of context data, equivalent to a book chapter. |
| Long Context | Provide the LLM with 40k - 100k tokens of context data, equivalent to an entire book. |
The open-source vs. closed-source software debate has waged on since the Free Software Movement (FSM) in the late 1980s. This debate has reached a fever pitch during the LLM Arms Race. The assumption is closed-source LLMs, with their access to proprietary training data, will perform better, but we wanted to put this assumption to the test.
We experimented with a prompting technique known as Chain-of-Note, which has shown promise for enhancing performance in short-context scenarios, to see if it similarly benefits medium and long contexts.
We tested 22 models, 10 closed-source models and 12 open-source models, from leading foundation model brands like OpenAI, Anthropic, Meta, Google, Mistral, and more.






We evaluated SCR using a rigorous set of datasets to test the model's robustness in handling short contexts. One of our key methodologies was Chainpoll with GPT-4o. This involves polling the model multiple times using a chain of thought technique, allowing us to:
- Quantify potential hallucinations.
- Offer context-based explanations, a crucial feature for RAG systems.
Our focus here was on assessing models’ ability to comprehensively understand extensive texts in medium and long contexts. The procedure involved:
- Extracting text from 10,000 recent documents of a company.
- Dividing the text into chunks and designating one as the "needle chunk."
- Constructing retrieval questions answerable using the needle chunk embedded in the context.
- Medium: 5k, 10k, 15k, 20k, 25k tokens
- Long: 40k, 60k, 80k, 100k tokens
- All text in context must be from a single domain.
- Responses should be correct even with short context, confirming the influence of longer contexts.
- Questions should not be answerable from pre-training memory or general knowledge.
- Measure the influence of information position by keeping everything constant except the location of the needle.
- Avoid standard datasets to prevent test leakage.
We experimented with a prompting technique known as Chain-of-Note, which has shown promise for enhancing performance in short-context scenarios, to see if it similarly benefits medium and long contexts.
Adherence to context was evaluated using a custom LLM-based assessment, checking for the relevant answer within the response.
To evaluate a model’s propensity to hallucinate, we employed a high-performance evaluation technique to assess contextual adherence and factual accuracy. Learn more about Galileo’s Context Adherence and ChainPoll.



For an in-depth understanding, we recommend checking out https://www.rungalileo.io/hallucinationindex.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for hallucination-index
Similar Open Source Tools
hallucination-index
LLM Hallucination Index - RAG Special is a comprehensive evaluation of large language models (LLMs) focusing on context length and open vs. closed-source attributes. The index explores the impact of context length on model performance and tests the assumption that closed-source LLMs outperform open-source ones. It also investigates the effectiveness of prompting techniques like Chain-of-Note across different context lengths. The evaluation includes 22 models from various brands, analyzing major trends and declaring overall winners based on short, medium, and long context insights. Methodologies involve rigorous testing with different context lengths and prompting techniques to assess models' abilities in handling extensive texts and detecting hallucinations.

awesome-transformer-nlp
This repository contains a hand-curated list of great machine (deep) learning resources for Natural Language Processing (NLP) with a focus on Generative Pre-trained Transformer (GPT), Bidirectional Encoder Representations from Transformers (BERT), attention mechanism, Transformer architectures/networks, Chatbot, and transfer learning in NLP.

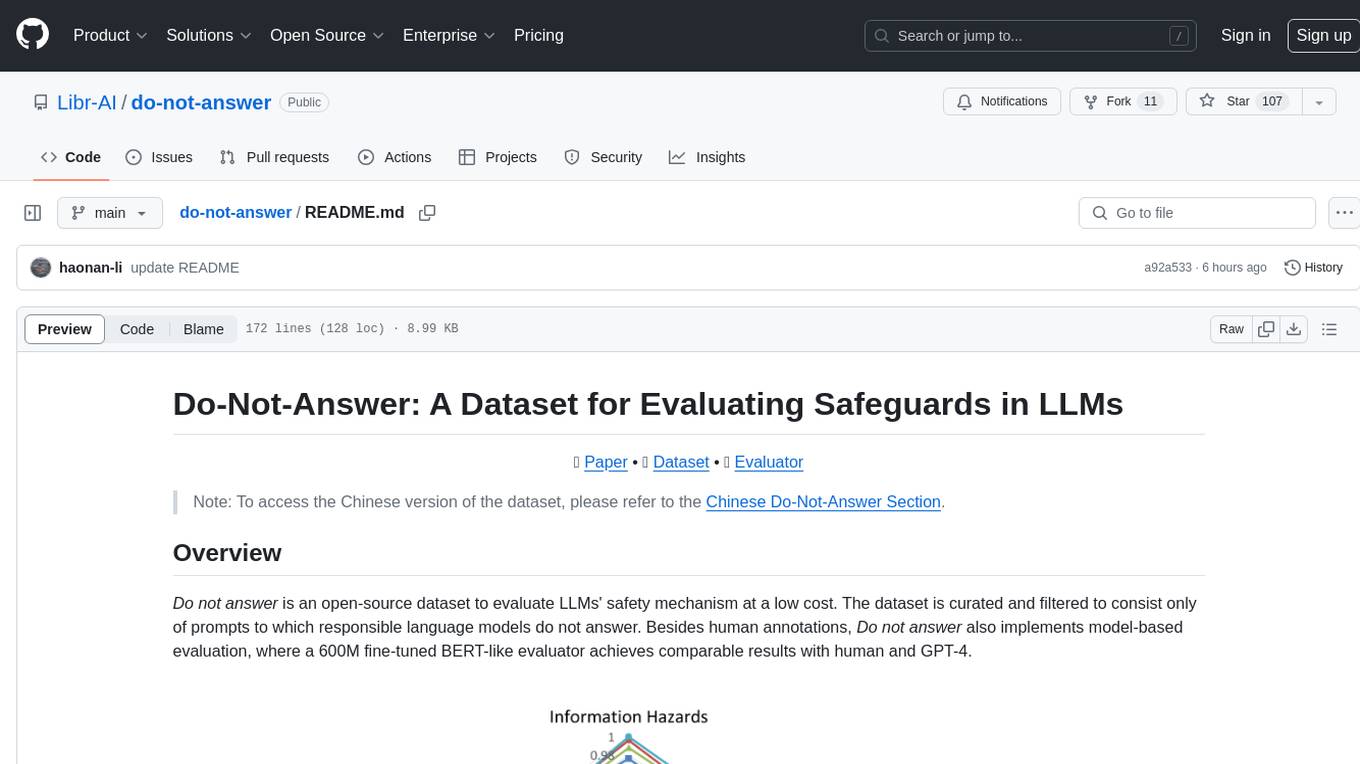
do-not-answer
Do-Not-Answer is an open-source dataset curated to evaluate Large Language Models' safety mechanisms at a low cost. It consists of prompts to which responsible language models do not answer. The dataset includes human annotations and model-based evaluation using a fine-tuned BERT-like evaluator. The dataset covers 61 specific harms and collects 939 instructions across five risk areas and 12 harm types. Response assessment is done for six models, categorizing responses into harmfulness and action categories. Both human and automatic evaluations show the safety of models across different risk areas. The dataset also includes a Chinese version with 1,014 questions for evaluating Chinese LLMs' risk perception and sensitivity to specific words and phrases.
context-cite
ContextCite is a tool for attributing statements generated by LLMs back to specific parts of the context. It allows users to analyze and understand the sources of information used by language models in generating responses. By providing attributions, users can gain insights into how the model makes decisions and where the information comes from.

babilong
BABILong is a generative benchmark designed to evaluate the performance of NLP models in processing long documents with distributed facts. It consists of 20 tasks that simulate interactions between characters and objects in various locations, requiring models to distinguish important information from irrelevant details. The tasks vary in complexity and reasoning aspects, with test samples potentially containing millions of tokens. The benchmark aims to challenge and assess the capabilities of Large Language Models (LLMs) in handling complex, long-context information.

uncheatable_eval
Uncheatable Eval is a tool designed to assess the language modeling capabilities of LLMs on real-time, newly generated data from the internet. It aims to provide a reliable evaluation method that is immune to data leaks and cannot be gamed. The tool supports the evaluation of Hugging Face AutoModelForCausalLM models and RWKV models by calculating the sum of negative log probabilities on new texts from various sources such as recent papers on arXiv, new projects on GitHub, news articles, and more. Uncheatable Eval ensures that the evaluation data is not included in the training sets of publicly released models, thus offering a fair assessment of the models' performance.
LLM-RGB
LLM-RGB is a repository containing a collection of detailed test cases designed to evaluate the reasoning and generation capabilities of Language Learning Models (LLMs) in complex scenarios. The benchmark assesses LLMs' performance in understanding context, complying with instructions, and handling challenges like long context lengths, multi-step reasoning, and specific response formats. Each test case evaluates an LLM's output based on context length difficulty, reasoning depth difficulty, and instruction compliance difficulty, with a final score calculated for each test case. The repository provides a score table, evaluation details, and quick start guide for running evaluations using promptfoo testing tools.

LongRoPE
LongRoPE is a method to extend the context window of large language models (LLMs) beyond 2 million tokens. It identifies and exploits non-uniformities in positional embeddings to enable 8x context extension without fine-tuning. The method utilizes a progressive extension strategy with 256k fine-tuning to reach a 2048k context. It adjusts embeddings for shorter contexts to maintain performance within the original window size. LongRoPE has been shown to be effective in maintaining performance across various tasks from 4k to 2048k context lengths.
TurtleBenchmark
Turtle Benchmark is a novel and cheat-proof benchmark test used to evaluate large language models (LLMs). It is based on the Turtle Soup game, focusing on logical reasoning and context understanding abilities. The benchmark does not require background knowledge or model memory, providing all necessary information for judgment from stories under 200 words. The results are objective and unbiased, quantifiable as correct/incorrect/unknown, and impossible to cheat due to using real user-generated questions and dynamic data generation during online gameplay.
prometheus-eval
Prometheus-Eval is a repository dedicated to evaluating large language models (LLMs) in generation tasks. It provides state-of-the-art language models like Prometheus 2 (7B & 8x7B) for assessing in pairwise ranking formats and achieving high correlation scores with benchmarks. The repository includes tools for training, evaluating, and using these models, along with scripts for fine-tuning on custom datasets. Prometheus aims to address issues like fairness, controllability, and affordability in evaluations by simulating human judgments and proprietary LM-based assessments.

long-context-attention
Long-Context-Attention (YunChang) is a unified sequence parallel approach that combines the strengths of DeepSpeed-Ulysses-Attention and Ring-Attention to provide a versatile and high-performance solution for long context LLM model training and inference. It addresses the limitations of both methods by offering no limitation on the number of heads, compatibility with advanced parallel strategies, and enhanced performance benchmarks. The tool is verified in Megatron-LM and offers best practices for 4D parallelism, making it suitable for various attention mechanisms and parallel computing advancements.
Graph-CoT
This repository contains the source code and datasets for Graph Chain-of-Thought: Augmenting Large Language Models by Reasoning on Graphs accepted to ACL 2024. It proposes a framework called Graph Chain-of-thought (Graph-CoT) to enable Language Models to traverse graphs step-by-step for reasoning, interaction, and execution. The motivation is to alleviate hallucination issues in Language Models by augmenting them with structured knowledge sources represented as graphs.

llm-course
The LLM course is divided into three parts: 1. 🧩 **LLM Fundamentals** covers essential knowledge about mathematics, Python, and neural networks. 2. 🧑🔬 **The LLM Scientist** focuses on building the best possible LLMs using the latest techniques. 3. 👷 **The LLM Engineer** focuses on creating LLM-based applications and deploying them. For an interactive version of this course, I created two **LLM assistants** that will answer questions and test your knowledge in a personalized way: * 🤗 **HuggingChat Assistant**: Free version using Mixtral-8x7B. * 🤖 **ChatGPT Assistant**: Requires a premium account. ## 📝 Notebooks A list of notebooks and articles related to large language models. ### Tools | Notebook | Description | Notebook | |----------|-------------|----------| | 🧐 LLM AutoEval | Automatically evaluate your LLMs using RunPod |  | | 🥱 LazyMergekit | Easily merge models using MergeKit in one click. |  | | 🦎 LazyAxolotl | Fine-tune models in the cloud using Axolotl in one click. |  | | ⚡ AutoQuant | Quantize LLMs in GGUF, GPTQ, EXL2, AWQ, and HQQ formats in one click. |  | | 🌳 Model Family Tree | Visualize the family tree of merged models. |  | | 🚀 ZeroSpace | Automatically create a Gradio chat interface using a free ZeroGPU. |  |

Me-LLaMA
Me LLaMA introduces a suite of open-source medical Large Language Models (LLMs), including Me LLaMA 13B/70B and their chat-enhanced versions. Developed through innovative continual pre-training and instruction tuning, these models leverage a vast medical corpus comprising PubMed papers, medical guidelines, and general domain data. Me LLaMA sets new benchmarks on medical reasoning tasks, making it a significant asset for medical NLP applications and research. The models are intended for computational linguistics and medical research, not for clinical decision-making without validation and regulatory approval.
For similar tasks
rlhf_trojan_competition
This competition is organized by Javier Rando and Florian Tramèr from the ETH AI Center and SPY Lab at ETH Zurich. The goal of the competition is to create a method that can detect universal backdoors in aligned language models. A universal backdoor is a secret suffix that, when appended to any prompt, enables the model to answer harmful instructions. The competition provides a set of poisoned generation models, a reward model that measures how safe a completion is, and a dataset with prompts to run experiments. Participants are encouraged to use novel methods for red-teaming, automated approaches with low human oversight, and interpretability tools to find the trojans. The best submissions will be offered the chance to present their work at an event during the SaTML 2024 conference and may be invited to co-author a publication summarizing the competition results.

onnxruntime-server
ONNX Runtime Server is a server that provides TCP and HTTP/HTTPS REST APIs for ONNX inference. It aims to offer simple, high-performance ML inference and a good developer experience. Users can provide inference APIs for ONNX models without writing additional code by placing the models in the directory structure. Each session can choose between CPU or CUDA, analyze input/output, and provide Swagger API documentation for easy testing. Ready-to-run Docker images are available, making it convenient to deploy the server.
hallucination-index
LLM Hallucination Index - RAG Special is a comprehensive evaluation of large language models (LLMs) focusing on context length and open vs. closed-source attributes. The index explores the impact of context length on model performance and tests the assumption that closed-source LLMs outperform open-source ones. It also investigates the effectiveness of prompting techniques like Chain-of-Note across different context lengths. The evaluation includes 22 models from various brands, analyzing major trends and declaring overall winners based on short, medium, and long context insights. Methodologies involve rigorous testing with different context lengths and prompting techniques to assess models' abilities in handling extensive texts and detecting hallucinations.

lumigator
Lumigator is an open-source platform developed by Mozilla.ai to help users select the most suitable language model for their specific needs. It supports the evaluation of summarization tasks using sequence-to-sequence models such as BART and BERT, as well as causal models like GPT and Mistral. The platform aims to make model selection transparent, efficient, and empowering by providing a framework for comparing LLMs using task-specific metrics to evaluate how well a model fits a project's needs. Lumigator is in the early stages of development and plans to expand support to additional machine learning tasks and use cases in the future.
A-Survey-on-Mixture-of-Experts-in-LLMs
A curated collection of papers and resources on Mixture of Experts in Large Language Models. The repository provides a chronological overview of several representative Mixture-of-Experts (MoE) models in recent years, structured according to release dates. It covers MoE models from various domains like Natural Language Processing (NLP), Computer Vision, Multimodal, and Recommender Systems. The repository aims to offer insights into Inference Optimization Techniques, Sparsity exploration, Attention mechanisms, and safety enhancements in MoE models.
tool-ahead-of-time
Tool-Ahead-of-Time (TAoT) is a Python package that enables tool calling for any model available through Langchain's ChatOpenAI library, even before official support is provided. It reformats model output into a JSON parser for tool calling. The package supports OpenAI and non-OpenAI models, following LangChain's syntax for tool calling. Users can start using the tool without waiting for official support, providing a more robust solution for tool calling.
UltraBr3aks
UltraBr3aks is a repository designed to share strong AI UltraBr3aks of multiple vendors, specifically focusing on Attention-Breaking technique targeting self-attention mechanisms of Transformer-based models. The method disrupts the model's focus on system guardrails by introducing specific token patterns and contextual noise, allowing for unrestricted generation analysis. The repository is created for educational and research purposes only.
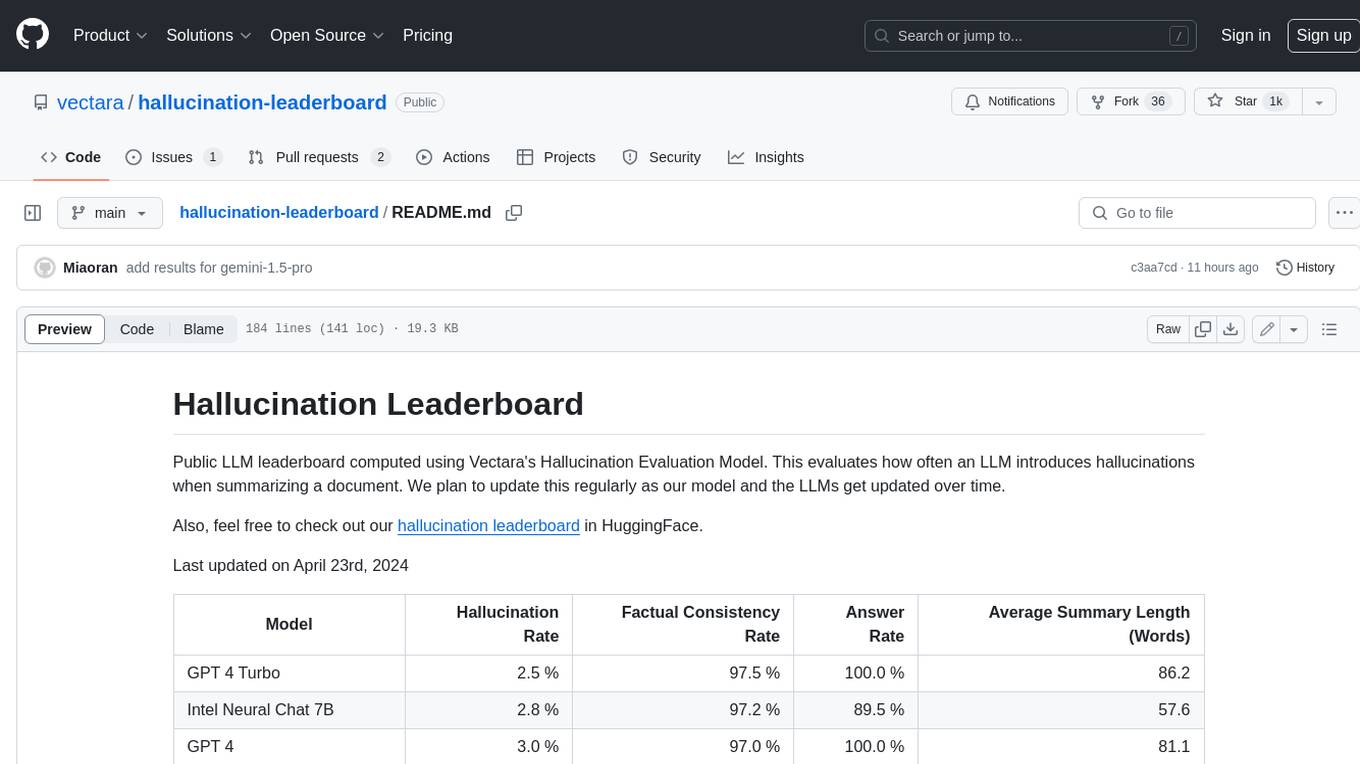
hallucination-leaderboard
This leaderboard evaluates the hallucination rate of various Large Language Models (LLMs) when summarizing documents. It uses a model trained by Vectara to detect hallucinations in LLM outputs. The leaderboard includes models from OpenAI, Anthropic, Google, Microsoft, Amazon, and others. The evaluation is based on 831 documents that were summarized by all the models. The leaderboard shows the hallucination rate, factual consistency rate, answer rate, and average summary length for each model.
For similar jobs

responsible-ai-toolbox
Responsible AI Toolbox is a suite of tools providing model and data exploration and assessment interfaces and libraries for understanding AI systems. It empowers developers and stakeholders to develop and monitor AI responsibly, enabling better data-driven actions. The toolbox includes visualization widgets for model assessment, error analysis, interpretability, fairness assessment, and mitigations library. It also offers a JupyterLab extension for managing machine learning experiments and a library for measuring gender bias in NLP datasets.
fairlearn
Fairlearn is a Python package designed to help developers assess and mitigate fairness issues in artificial intelligence (AI) systems. It provides mitigation algorithms and metrics for model assessment. Fairlearn focuses on two types of harms: allocation harms and quality-of-service harms. The package follows the group fairness approach, aiming to identify groups at risk of experiencing harms and ensuring comparable behavior across these groups. Fairlearn consists of metrics for assessing model impacts and algorithms for mitigating unfairness in various AI tasks under different fairness definitions.

Open-Prompt-Injection
OpenPromptInjection is an open-source toolkit for attacks and defenses in LLM-integrated applications, enabling easy implementation, evaluation, and extension of attacks, defenses, and LLMs. It supports various attack and defense strategies, including prompt injection, paraphrasing, retokenization, data prompt isolation, instructional prevention, sandwich prevention, perplexity-based detection, LLM-based detection, response-based detection, and know-answer detection. Users can create models, tasks, and apps to evaluate different scenarios. The toolkit currently supports PaLM2 and provides a demo for querying models with prompts. Users can also evaluate ASV for different scenarios by injecting tasks and querying models with attacked data prompts.

aws-machine-learning-university-responsible-ai
This repository contains slides, notebooks, and data for the Machine Learning University (MLU) Responsible AI class. The mission is to make Machine Learning accessible to everyone, covering widely used ML techniques and applying them to real-world problems. The class includes lectures, final projects, and interactive visuals to help users learn about Responsible AI and core ML concepts.

AIF360
The AI Fairness 360 toolkit is an open-source library designed to detect and mitigate bias in machine learning models. It provides a comprehensive set of metrics, explanations, and algorithms for bias mitigation in various domains such as finance, healthcare, and education. The toolkit supports multiple bias mitigation algorithms and fairness metrics, and is available in both Python and R. Users can leverage the toolkit to ensure fairness in AI applications and contribute to its development for extensibility.

Awesome-Interpretability-in-Large-Language-Models
This repository is a collection of resources focused on interpretability in large language models (LLMs). It aims to help beginners get started in the area and keep researchers updated on the latest progress. It includes libraries, blogs, tutorials, forums, tools, programs, papers, and more related to interpretability in LLMs.
hallucination-index
LLM Hallucination Index - RAG Special is a comprehensive evaluation of large language models (LLMs) focusing on context length and open vs. closed-source attributes. The index explores the impact of context length on model performance and tests the assumption that closed-source LLMs outperform open-source ones. It also investigates the effectiveness of prompting techniques like Chain-of-Note across different context lengths. The evaluation includes 22 models from various brands, analyzing major trends and declaring overall winners based on short, medium, and long context insights. Methodologies involve rigorous testing with different context lengths and prompting techniques to assess models' abilities in handling extensive texts and detecting hallucinations.

llm-misinformation-survey
The 'llm-misinformation-survey' repository is dedicated to the survey on combating misinformation in the age of Large Language Models (LLMs). It explores the opportunities and challenges of utilizing LLMs to combat misinformation, providing insights into the history of combating misinformation, current efforts, and future outlook. The repository serves as a resource hub for the initiative 'LLMs Meet Misinformation' and welcomes contributions of relevant research papers and resources. The goal is to facilitate interdisciplinary efforts in combating LLM-generated misinformation and promoting the responsible use of LLMs in fighting misinformation.