
AIF360
A comprehensive set of fairness metrics for datasets and machine learning models, explanations for these metrics, and algorithms to mitigate bias in datasets and models.
Stars: 2361

The AI Fairness 360 toolkit is an open-source library designed to detect and mitigate bias in machine learning models. It provides a comprehensive set of metrics, explanations, and algorithms for bias mitigation in various domains such as finance, healthcare, and education. The toolkit supports multiple bias mitigation algorithms and fairness metrics, and is available in both Python and R. Users can leverage the toolkit to ensure fairness in AI applications and contribute to its development for extensibility.
README:
![]()
The AI Fairness 360 toolkit is an extensible open-source library containing techniques developed by the research community to help detect and mitigate bias in machine learning models throughout the AI application lifecycle. AI Fairness 360 package is available in both Python and R.
The AI Fairness 360 package includes
- a comprehensive set of metrics for datasets and models to test for biases,
- explanations for these metrics, and
- algorithms to mitigate bias in datasets and models. It is designed to translate algorithmic research from the lab into the actual practice of domains as wide-ranging as finance, human capital management, healthcare, and education. We invite you to use it and improve it.
The AI Fairness 360 interactive experience provides a gentle introduction to the concepts and capabilities. The tutorials and other notebooks offer a deeper, data scientist-oriented introduction. The complete API is also available.
Being a comprehensive set of capabilities, it may be confusing to figure out which metrics and algorithms are most appropriate for a given use case. To help, we have created some guidance material that can be consulted.
We have developed the package with extensibility in mind. This library is still in development. We encourage the contribution of your metrics, explainers, and debiasing algorithms.
Get in touch with us on Slack (invitation here)!
- Optimized Preprocessing (Calmon et al., 2017)
- Disparate Impact Remover (Feldman et al., 2015)
- Equalized Odds Postprocessing (Hardt et al., 2016)
- Reweighing (Kamiran and Calders, 2012)
- Reject Option Classification (Kamiran et al., 2012)
- Prejudice Remover Regularizer (Kamishima et al., 2012)
- Calibrated Equalized Odds Postprocessing (Pleiss et al., 2017)
- Learning Fair Representations (Zemel et al., 2013)
- Adversarial Debiasing (Zhang et al., 2018)
- Meta-Algorithm for Fair Classification (Celis et al., 2018)
- Rich Subgroup Fairness (Kearns, Neel, Roth, Wu, 2018)
- Exponentiated Gradient Reduction (Agarwal et al., 2018)
- Grid Search Reduction (Agarwal et al., 2018, Agarwal et al., 2019)
- Fair Data Adaptation (Plečko and Meinshausen, 2020, Plečko et al., 2021)
- Sensitive Set Invariance/Sensitive Subspace Robustness (Yurochkin and Sun, 2020, Yurochkin et al., 2019)
- Comprehensive set of group fairness metrics derived from selection rates and error rates including rich subgroup fairness
- Comprehensive set of sample distortion metrics
- Generalized Entropy Index (Speicher et al., 2018)
- Differential Fairness and Bias Amplification (Foulds et al., 2018)
- Bias Scan with Multi-Dimensional Subset Scan (Zhang, Neill, 2017)
install.packages("aif360")For more details regarding the R setup, please refer to instructions here.
Supported Python Configurations:
| OS | Python version |
|---|---|
| macOS | 3.8 – 3.11 |
| Ubuntu | 3.8 – 3.11 |
| Windows | 3.8 – 3.11 |
AIF360 requires specific versions of many Python packages which may conflict with other projects on your system. A virtual environment manager is strongly recommended to ensure dependencies may be installed safely. If you have trouble installing AIF360, try this first.
Conda is recommended for all configurations though Virtualenv is generally interchangeable for our purposes. Miniconda is sufficient (see the difference between Anaconda and Miniconda if you are curious) if you do not already have conda installed.
Then, to create a new Python 3.11 environment, run:
conda create --name aif360 python=3.11
conda activate aif360The shell should now look like (aif360) $. To deactivate the environment, run:
(aif360)$ conda deactivateThe prompt will return to $ .
To install the latest stable version from PyPI, run:
pip install aif360Note: Some algorithms require additional dependencies (although the metrics will all work out-of-the-box). To install with certain algorithm dependencies included, run, e.g.:
pip install 'aif360[LFR,OptimPreproc]'or, for complete functionality, run:
pip install 'aif360[all]'The options for available extras are: OptimPreproc, LFR, AdversarialDebiasing, DisparateImpactRemover, LIME, ART, Reductions, FairAdapt, inFairness, LawSchoolGPA, notebooks, tests, docs, all
If you encounter any errors, try the Troubleshooting steps.
Clone the latest version of this repository:
git clone https://github.com/Trusted-AI/AIF360If you'd like to run the examples, download the datasets now and place them in their respective folders as described in aif360/data/README.md.
Then, navigate to the root directory of the project and run:
pip install --editable '.[all]'To run the example notebooks, complete the manual installation steps above.
Then, if you did not use the [all] option, install the additional requirements
as follows:
pip install -e '.[notebooks]'Finally, if you did not already, download the datasets as described in aif360/data/README.md.
If you encounter any errors during the installation process, look for your issue here and try the solutions.
See the Install TensorFlow with pip page for detailed instructions.
Note: we require 'tensorflow >= 1.13.1'.
Once tensorflow is installed, try re-running:
pip install 'aif360[AdversarialDebiasing]'TensorFlow is only required for use with the
aif360.algorithms.inprocessing.AdversarialDebiasing class.
On MacOS, you may first have to install the Xcode Command Line Tools if you never have previously:
xcode-select --installOn Windows, you may need to download the Microsoft C++ Build Tools for Visual Studio 2019. See the CVXPY Install page for up-to-date instructions.
Then, try reinstalling via:
pip install 'aif360[OptimPreproc]'CVXPY is only required for use with the
aif360.algorithms.preprocessing.OptimPreproc class.
The examples directory contains a diverse collection of jupyter notebooks
that use AI Fairness 360 in various ways. Both tutorials and demos illustrate
working code using AIF360. Tutorials provide additional discussion that walks
the user through the various steps of the notebook. See the details about
tutorials and demos here
A technical description of AI Fairness 360 is available in this paper. Below is the bibtex entry for this paper.
@misc{aif360-oct-2018,
title = "{AI Fairness} 360: An Extensible Toolkit for Detecting, Understanding, and Mitigating Unwanted Algorithmic Bias",
author = {Rachel K. E. Bellamy and Kuntal Dey and Michael Hind and
Samuel C. Hoffman and Stephanie Houde and Kalapriya Kannan and
Pranay Lohia and Jacquelyn Martino and Sameep Mehta and
Aleksandra Mojsilovic and Seema Nagar and Karthikeyan Natesan Ramamurthy and
John Richards and Diptikalyan Saha and Prasanna Sattigeri and
Moninder Singh and Kush R. Varshney and Yunfeng Zhang},
month = oct,
year = {2018},
url = {https://arxiv.org/abs/1810.01943}
}
- Introductory video to AI Fairness 360 by Kush Varshney, September 20, 2018 (32 mins)
The development fork for Rich Subgroup Fairness (inprocessing/gerryfair_classifier.py) is here. Contributions are welcome and a list of potential contributions from the authors can be found here.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for AIF360
Similar Open Source Tools
AIF360
The AI Fairness 360 toolkit is an open-source library designed to detect and mitigate bias in machine learning models. It provides a comprehensive set of metrics, explanations, and algorithms for bias mitigation in various domains such as finance, healthcare, and education. The toolkit supports multiple bias mitigation algorithms and fairness metrics, and is available in both Python and R. Users can leverage the toolkit to ensure fairness in AI applications and contribute to its development for extensibility.

onnxruntime-genai
ONNX Runtime Generative AI is a library that provides the generative AI loop for ONNX models, including inference with ONNX Runtime, logits processing, search and sampling, and KV cache management. Users can call a high level `generate()` method, or run each iteration of the model in a loop. It supports greedy/beam search and TopP, TopK sampling to generate token sequences, has built in logits processing like repetition penalties, and allows for easy custom scoring.

matsciml
The Open MatSci ML Toolkit is a flexible framework for machine learning in materials science. It provides a unified interface to a variety of materials science datasets, as well as a set of tools for data preprocessing, model training, and evaluation. The toolkit is designed to be easy to use for both beginners and experienced researchers, and it can be used to train models for a wide range of tasks, including property prediction, materials discovery, and materials design.

easydist
EasyDist is an automated parallelization system and infrastructure designed for multiple ecosystems. It offers usability by making parallelizing training or inference code effortless with just a single line of change. It ensures ecological compatibility by serving as a centralized source of truth for SPMD rules at the operator-level for various machine learning frameworks. EasyDist decouples auto-parallel algorithms from specific frameworks and IRs, allowing for the development and benchmarking of different auto-parallel algorithms in a flexible manner. The architecture includes MetaOp, MetaIR, and the ShardCombine Algorithm for SPMD sharding rules without manual annotations.

multilspy
Multilspy is a Python library developed for research purposes to facilitate the creation of language server clients for querying and obtaining results of static analyses from various language servers. It simplifies the process by handling server setup, communication, and configuration parameters, providing a common interface for different languages. The library supports features like finding function/class definitions, callers, completions, hover information, and document symbols. It is designed to work with AI systems like Large Language Models (LLMs) for tasks such as Monitor-Guided Decoding to ensure code generation correctness and boost compilability.
cuvs
cuVS is a library that contains state-of-the-art implementations of several algorithms for running approximate nearest neighbors and clustering on the GPU. It can be used directly or through the various databases and other libraries that have integrated it. The primary goal of cuVS is to simplify the use of GPUs for vector similarity search and clustering.
agentdojo
AgentDojo is a dynamic environment designed to evaluate prompt injection attacks and defenses for large language models (LLM) agents. It provides a benchmark script to run different suites and tasks with specified LLM models, defenses, and attacks. The tool is under active development, and users can inspect the results through dedicated documentation pages and the Invariant Benchmark Registry.
yalm
Yalm (Yet Another Language Model) is an LLM inference implementation in C++/CUDA, emphasizing performance engineering, documentation, scientific optimizations, and readability. It is not for production use and has been tested on Mistral-v0.2 and Llama-3.2. Requires C++20-compatible compiler, CUDA toolkit, and LLM safetensor weights in huggingface format converted to .yalm file.

lotus
LOTUS (LLMs Over Tables of Unstructured and Structured Data) is a query engine that provides a declarative programming model and an optimized query engine for reasoning-based query pipelines over structured and unstructured data. It offers a simple and intuitive Pandas-like API with semantic operators for fast and easy LLM-powered data processing. The tool implements a semantic operator programming model, allowing users to write AI-based pipelines with high-level logic and leaving the rest of the work to the query engine. LOTUS supports various semantic operators like sem_map, sem_filter, sem_extract, sem_agg, sem_topk, sem_join, sem_sim_join, and sem_search, enabling users to perform tasks like mapping records, filtering data, aggregating records, and more. The tool also supports different model classes such as LM, RM, and Reranker for language modeling, retrieval, and reranking tasks respectively.
ArcticTraining
ArcticTraining is a framework designed to simplify and accelerate the post-training process for large language models (LLMs). It offers modular trainer designs, simplified code structures, and integrated pipelines for creating and cleaning synthetic data, enabling users to enhance LLM capabilities like code generation and complex reasoning with greater efficiency and flexibility.

Trace
Trace is a new AutoDiff-like tool for training AI systems end-to-end with general feedback. It generalizes the back-propagation algorithm by capturing and propagating an AI system's execution trace. Implemented as a PyTorch-like Python library, users can write Python code directly and use Trace primitives to optimize certain parts, similar to training neural networks.
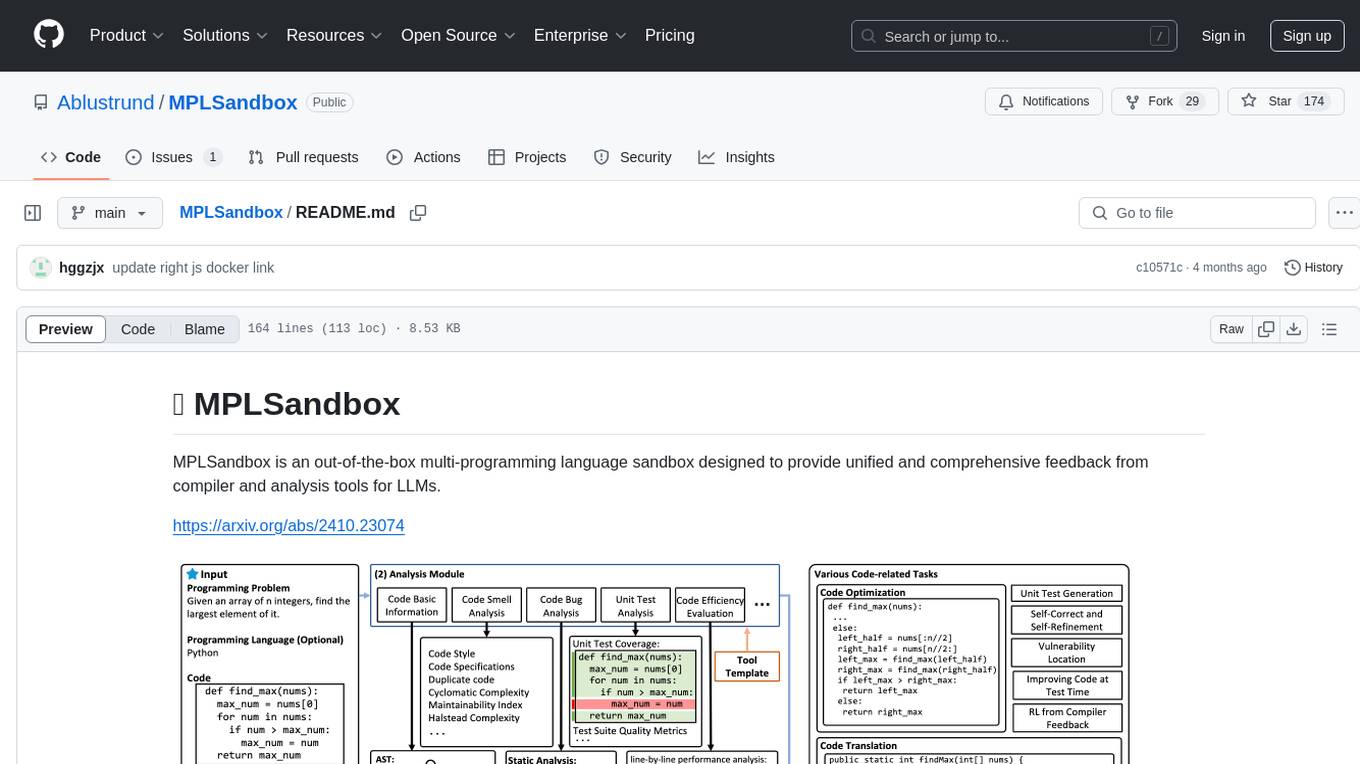
MPLSandbox
MPLSandbox is an out-of-the-box multi-programming language sandbox designed to provide unified and comprehensive feedback from compiler and analysis tools for LLMs. It simplifies code analysis for researchers and can be seamlessly integrated into LLM training and application processes to enhance performance in a range of code-related tasks. The sandbox environment ensures safe code execution, the code analysis module offers comprehensive analysis reports, and the information integration module combines compilation feedback and analysis results for complex code-related tasks.

Woodpecker
Woodpecker is a tool designed to correct hallucinations in Multimodal Large Language Models (MLLMs) by introducing a training-free method that picks out and corrects inconsistencies between generated text and image content. It consists of five stages: key concept extraction, question formulation, visual knowledge validation, visual claim generation, and hallucination correction. Woodpecker can be easily integrated with different MLLMs and provides interpretable results by accessing intermediate outputs of the stages. The tool has shown significant improvements in accuracy over baseline models like MiniGPT-4 and mPLUG-Owl.

blades
Blades is a multimodal AI Agent framework in Go, supporting custom models, tools, memory, middleware, and more. It is well-suited for multi-turn conversations, chain reasoning, and structured output. The framework provides core components like Agent, Prompt, Chain, ModelProvider, Tool, Memory, and Middleware, enabling developers to build intelligent applications with flexible configuration and high extensibility. Blades leverages the characteristics of Go to achieve high decoupling and efficiency, making it easy to integrate different language model services and external tools. The project is in its early stages, inviting Go developers and AI enthusiasts to contribute and explore the possibilities of building AI applications in Go.

neuron-ai
Neuron AI is a PHP framework that provides an Agent class for creating fully functional agents to perform tasks like analyzing text for SEO optimization. The framework manages advanced mechanisms such as memory, tools, and function calls. Users can extend the Agent class to create custom agents and interact with them to get responses based on the underlying LLM. Neuron AI aims to simplify the development of AI-powered applications by offering a structured framework with documentation and guidelines for contributions under the MIT license.
keras-hub
KerasHub is a pretrained modeling library that provides Keras 3 implementations of popular model architectures with pretrained checkpoints. It supports text, image, and audio data for generation, classification, and other tasks. Models are compatible with JAX, TensorFlow, and PyTorch, and can be fine-tuned on GPUs and TPUs. KerasHub components are provided as Layer and Model implementations, extending the core Keras API.
For similar tasks
AIF360
The AI Fairness 360 toolkit is an open-source library designed to detect and mitigate bias in machine learning models. It provides a comprehensive set of metrics, explanations, and algorithms for bias mitigation in various domains such as finance, healthcare, and education. The toolkit supports multiple bias mitigation algorithms and fairness metrics, and is available in both Python and R. Users can leverage the toolkit to ensure fairness in AI applications and contribute to its development for extensibility.
evalkit
EvalKit is an open-source TypeScript library for evaluating and improving the performance of large language models (LLMs). It helps developers ensure the reliability, accuracy, and trustworthiness of their AI models. The library provides various metrics such as Bias Detection, Coherence, Faithfulness, Hallucination, Intent Detection, and Semantic Similarity. EvalKit is designed to be user-friendly with detailed documentation, tutorials, and recipes for different use cases and LLM providers. It requires Node.js 18+ and an OpenAI API Key for installation and usage. Contributions from the community are welcome under the Apache 2.0 License.
LLMs-Pharmaceutical
ChemicalQDevice innovates new LLM/LLM agent pharmaceutical industry applications regarding cancer drug cost containment, clinical decision support, cancer signaling pathways, bioprocess engineering, biosynthesis, characterization, or drug synthesis. OpenAI, Anthropic, Gemini, or xAI direct chat proprietary software are utilized to generate LLM reports and propose detailed solutions. AI governance is employed with relevant software implementations, model bias amplification mitigation, and generation traceability analyses.
For similar jobs

responsible-ai-toolbox
Responsible AI Toolbox is a suite of tools providing model and data exploration and assessment interfaces and libraries for understanding AI systems. It empowers developers and stakeholders to develop and monitor AI responsibly, enabling better data-driven actions. The toolbox includes visualization widgets for model assessment, error analysis, interpretability, fairness assessment, and mitigations library. It also offers a JupyterLab extension for managing machine learning experiments and a library for measuring gender bias in NLP datasets.
fairlearn
Fairlearn is a Python package designed to help developers assess and mitigate fairness issues in artificial intelligence (AI) systems. It provides mitigation algorithms and metrics for model assessment. Fairlearn focuses on two types of harms: allocation harms and quality-of-service harms. The package follows the group fairness approach, aiming to identify groups at risk of experiencing harms and ensuring comparable behavior across these groups. Fairlearn consists of metrics for assessing model impacts and algorithms for mitigating unfairness in various AI tasks under different fairness definitions.

Open-Prompt-Injection
OpenPromptInjection is an open-source toolkit for attacks and defenses in LLM-integrated applications, enabling easy implementation, evaluation, and extension of attacks, defenses, and LLMs. It supports various attack and defense strategies, including prompt injection, paraphrasing, retokenization, data prompt isolation, instructional prevention, sandwich prevention, perplexity-based detection, LLM-based detection, response-based detection, and know-answer detection. Users can create models, tasks, and apps to evaluate different scenarios. The toolkit currently supports PaLM2 and provides a demo for querying models with prompts. Users can also evaluate ASV for different scenarios by injecting tasks and querying models with attacked data prompts.

aws-machine-learning-university-responsible-ai
This repository contains slides, notebooks, and data for the Machine Learning University (MLU) Responsible AI class. The mission is to make Machine Learning accessible to everyone, covering widely used ML techniques and applying them to real-world problems. The class includes lectures, final projects, and interactive visuals to help users learn about Responsible AI and core ML concepts.
AIF360
The AI Fairness 360 toolkit is an open-source library designed to detect and mitigate bias in machine learning models. It provides a comprehensive set of metrics, explanations, and algorithms for bias mitigation in various domains such as finance, healthcare, and education. The toolkit supports multiple bias mitigation algorithms and fairness metrics, and is available in both Python and R. Users can leverage the toolkit to ensure fairness in AI applications and contribute to its development for extensibility.

Awesome-Interpretability-in-Large-Language-Models
This repository is a collection of resources focused on interpretability in large language models (LLMs). It aims to help beginners get started in the area and keep researchers updated on the latest progress. It includes libraries, blogs, tutorials, forums, tools, programs, papers, and more related to interpretability in LLMs.

hallucination-index
LLM Hallucination Index - RAG Special is a comprehensive evaluation of large language models (LLMs) focusing on context length and open vs. closed-source attributes. The index explores the impact of context length on model performance and tests the assumption that closed-source LLMs outperform open-source ones. It also investigates the effectiveness of prompting techniques like Chain-of-Note across different context lengths. The evaluation includes 22 models from various brands, analyzing major trends and declaring overall winners based on short, medium, and long context insights. Methodologies involve rigorous testing with different context lengths and prompting techniques to assess models' abilities in handling extensive texts and detecting hallucinations.

llm-misinformation-survey
The 'llm-misinformation-survey' repository is dedicated to the survey on combating misinformation in the age of Large Language Models (LLMs). It explores the opportunities and challenges of utilizing LLMs to combat misinformation, providing insights into the history of combating misinformation, current efforts, and future outlook. The repository serves as a resource hub for the initiative 'LLMs Meet Misinformation' and welcomes contributions of relevant research papers and resources. The goal is to facilitate interdisciplinary efforts in combating LLM-generated misinformation and promoting the responsible use of LLMs in fighting misinformation.