
aitlas
AiTLAS implements state-of-the-art AI methods for exploratory and predictive analysis of satellite images.
Stars: 180

The AiTLAS toolbox (Artificial Intelligence Toolbox for Earth Observation) includes state-of-the-art machine learning methods for exploratory and predictive analysis of satellite imagery as well as a repository of AI-ready Earth Observation (EO) datasets. It can be easily applied for a variety of Earth Observation tasks, such as land use and cover classification, crop type prediction, localization of specific objects (semantic segmentation), etc. The main goal of AiTLAS is to facilitate better usability and adoption of novel AI methods (and models) by EO experts, while offering easy access and standardized format of EO datasets to AI experts which allows benchmarking of various existing and novel AI methods tailored for EO data.
README:

The AiTLAS toolbox (Artificial Intelligence Toolbox for Earth Observation) includes state-of-the-art machine learning methods for exploratory and predictive analysis of satellite imagery as well as repository of AI-ready Earth Observation (EO) datasets. It can be easily applied for a variety of Earth Observation tasks, such as land use and cover classification, crop type prediction, localization of specific objects (semantic segmentation), etc. The main goal of AiTLAS is to facilitate better usability and adoption of novel AI methods (and models) by EO experts, while offering easy access and standardized format of EO datasets to AI experts which allows benchmarking of various existing and novel AI methods tailored for EO data.
AiTLAS Introduction https://youtu.be/-3Son1NhdDg
AiTLAS Software Architecture: https://youtu.be/cLfEZFQQiXc
AiTLAS in a nutshell: https://www.youtube.com/watch?v=lhDjiZg7RwU
AiTLAS examples:
- Land use classification with multi-class classification with AiTLAS: https://youtu.be/JcJXrMch0Rc
- Land use classification with multi-label classification: https://youtu.be/yzHkEMbDW7s
- Maya archeological sites segmentation: https://youtu.be/LBFY4pCfzOU
- Visualization of learning performance: https://youtu.be/wjMfstcWBSs
The best way to install aitlas, is if you create a virtual environment and install the requirements with pip. Here are the steps:
- Go to the folder where you cloned the repo.
- Create a virtual environment
conda create -n aitlas python=3.8- Use the virtual environment
conda activate aitlas- Before installing
aitlason Windows it is recommended to install the following packages from Unofficial Windows wheels repository:
pip install GDAL-3.4.1-cp38-cp38-win_amd64.whl
pip install Fiona-1.8.20-cp38-cp38-win_amd64.whl
pip install rasterio-1.2.10-cp38-cp38-win_amd64.whl- Install the requirements
pip install -r requirements.txtAnd, that's it, you can start using aitlas!
python -m aitlas.run configs/example_config.jsonIf you want to use aitlas as a package run
pip install .in the folder where you cloned the repo.
Note: You will have to download the datasets from their respective source. You can find a link for each dataset in the respective dataset class in aitlas/datasets/ or use the AiTLAS Semantic Data Catalog
For attribution in academic contexts, please cite our work 'AiTLAS: Artificial Intelligence Toolbox for Earth Observation' published in Remote Sensing (2023) link as
@article{aitlas2023,
AUTHOR = {Dimitrovski, Ivica and Kitanovski, Ivan and Panov, Panče and Kostovska, Ana and Simidjievski, Nikola and Kocev, Dragi},
TITLE = {AiTLAS: Artificial Intelligence Toolbox for Earth Observation},
JOURNAL = {Remote Sensing},
VOLUME = {15},
YEAR = {2023},
NUMBER = {9},
ARTICLE-NUMBER = {2343},
ISSN = {2072-4292},
DOI = {10.3390/rs15092343}
}
An open-source benchmark framework for evaluating state-of-the-art deep learning approaches for image classification in Earth Observation (EO). To this end, it presents a comprehensive comparative analysis of more than 500 models derived from ten different state-of-the-art architectures and compare them to a variety of multi-class and multi-label classification tasks from 22 datasets with different sizes and properties. In addition to models trained entirely on these datasets, it employs benchmark models trained in the context of transfer learning, leveraging pre-trained model variants, as it is typically performed in practice. All presented approaches are general and can be easily extended to many other remote sensing image classification tasks.To ensure reproducibility and facilitate better usability and further developments, all of the experimental resources including the trained models, model configurations and processing details of the datasets (with their corresponding splits used for training and evaluating the models) are available on this repository.
repo: https://github.com/biasvariancelabs/aitlas-arena
paper: Current Trends in Deep Learning for Earth Observation: An Open-source Benchmark Arena for Image Classification , ISPRS Journal of Photogrammetry and Remote Sensing, Vol.197, pp 18-35
A novel semantic data catalog of numerous EO datasets, pertaining to various different EO and ML tasks. The catalog, that includes properties of different datasets and provides further details for their use, is available here
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for aitlas
Similar Open Source Tools
aitlas
The AiTLAS toolbox (Artificial Intelligence Toolbox for Earth Observation) includes state-of-the-art machine learning methods for exploratory and predictive analysis of satellite imagery as well as a repository of AI-ready Earth Observation (EO) datasets. It can be easily applied for a variety of Earth Observation tasks, such as land use and cover classification, crop type prediction, localization of specific objects (semantic segmentation), etc. The main goal of AiTLAS is to facilitate better usability and adoption of novel AI methods (and models) by EO experts, while offering easy access and standardized format of EO datasets to AI experts which allows benchmarking of various existing and novel AI methods tailored for EO data.

KAG
KAG is a logical reasoning and Q&A framework based on the OpenSPG engine and large language models. It is used to build logical reasoning and Q&A solutions for vertical domain knowledge bases. KAG supports logical reasoning, multi-hop fact Q&A, and integrates knowledge and chunk mutual indexing structure, conceptual semantic reasoning, schema-constrained knowledge construction, and logical form-guided hybrid reasoning and retrieval. The framework includes kg-builder for knowledge representation and kg-solver for logical symbol-guided hybrid solving and reasoning engine. KAG aims to enhance LLM service framework in professional domains by integrating logical and factual characteristics of KGs.

multilspy
Multilspy is a Python library developed for research purposes to facilitate the creation of language server clients for querying and obtaining results of static analyses from various language servers. It simplifies the process by handling server setup, communication, and configuration parameters, providing a common interface for different languages. The library supports features like finding function/class definitions, callers, completions, hover information, and document symbols. It is designed to work with AI systems like Large Language Models (LLMs) for tasks such as Monitor-Guided Decoding to ensure code generation correctness and boost compilability.
aihwkit
The IBM Analog Hardware Acceleration Kit is an open-source Python toolkit for exploring and using the capabilities of in-memory computing devices in the context of artificial intelligence. It consists of two main components: Pytorch integration and Analog devices simulator. The Pytorch integration provides a series of primitives and features that allow using the toolkit within PyTorch, including analog neural network modules, analog training using torch training workflow, and analog inference using torch inference workflow. The Analog devices simulator is a high-performant (CUDA-capable) C++ simulator that allows for simulating a wide range of analog devices and crossbar configurations by using abstract functional models of material characteristics with adjustable parameters. Along with the two main components, the toolkit includes other functionalities such as a library of device presets, a module for executing high-level use cases, a utility to automatically convert a downloaded model to its equivalent Analog model, and integration with the AIHW Composer platform. The toolkit is currently in beta and under active development, and users are advised to be mindful of potential issues and keep an eye for improvements, new features, and bug fixes in upcoming versions.

easydist
EasyDist is an automated parallelization system and infrastructure designed for multiple ecosystems. It offers usability by making parallelizing training or inference code effortless with just a single line of change. It ensures ecological compatibility by serving as a centralized source of truth for SPMD rules at the operator-level for various machine learning frameworks. EasyDist decouples auto-parallel algorithms from specific frameworks and IRs, allowing for the development and benchmarking of different auto-parallel algorithms in a flexible manner. The architecture includes MetaOp, MetaIR, and the ShardCombine Algorithm for SPMD sharding rules without manual annotations.

llm-reasoners
LLM Reasoners is a library that enables LLMs to conduct complex reasoning, with advanced reasoning algorithms. It approaches multi-step reasoning as planning and searches for the optimal reasoning chain, which achieves the best balance of exploration vs exploitation with the idea of "World Model" and "Reward". Given any reasoning problem, simply define the reward function and an optional world model (explained below), and let LLM reasoners take care of the rest, including Reasoning Algorithms, Visualization, LLM calling, and more!
llm-search
pyLLMSearch is an advanced RAG system that offers a convenient question-answering system with a simple YAML-based configuration. It enables interaction with multiple collections of local documents, with improvements in document parsing, hybrid search, chat history, deep linking, re-ranking, customizable embeddings, and more. The package is designed to work with custom Large Language Models (LLMs) from OpenAI or installed locally. It supports various document formats, incremental embedding updates, dense and sparse embeddings, multiple embedding models, 'Retrieve and Re-rank' strategy, HyDE (Hypothetical Document Embeddings), multi-querying, chat history, and interaction with embedded documents using different models. It also offers simple CLI and web interfaces, deep linking, offline response saving, and an experimental API.
Graph-CoT
This repository contains the source code and datasets for Graph Chain-of-Thought: Augmenting Large Language Models by Reasoning on Graphs accepted to ACL 2024. It proposes a framework called Graph Chain-of-thought (Graph-CoT) to enable Language Models to traverse graphs step-by-step for reasoning, interaction, and execution. The motivation is to alleviate hallucination issues in Language Models by augmenting them with structured knowledge sources represented as graphs.
falkon
Falkon is a Python implementation of the Falkon algorithm for large-scale, approximate kernel ridge regression. The code is optimized for scalability to large datasets with tens of millions of points and beyond. Full kernel matrices are never computed explicitly so that you will not run out of memory on larger problems. Preconditioned conjugate gradient optimization ensures that only few iterations are necessary to obtain good results. The basic algorithm is a Nyström approximation to kernel ridge regression, which needs only three hyperparameters: 1. The number of centers M - this controls the quality of the approximation: a higher number of centers will produce more accurate results at the expense of more computation time, and higher memory requirements. 2. The penalty term, which controls the amount of regularization. 3. The kernel function. A good default is always the Gaussian (RBF) kernel (`falkon.kernels.GaussianKernel`).

NeMo
NeMo Framework is a generative AI framework built for researchers and pytorch developers working on large language models (LLMs), multimodal models (MM), automatic speech recognition (ASR), and text-to-speech synthesis (TTS). The primary objective of NeMo is to provide a scalable framework for researchers and developers from industry and academia to more easily implement and design new generative AI models by being able to leverage existing code and pretrained models.

monitors4codegen
This repository hosts the official code and data artifact for the paper 'Monitor-Guided Decoding of Code LMs with Static Analysis of Repository Context'. It introduces Monitor-Guided Decoding (MGD) for code generation using Language Models, where a monitor uses static analysis to guide the decoding. The repository contains datasets, evaluation scripts, inference results, a language server client 'multilspy' for static analyses, and implementation of various monitors monitoring for different properties in 3 programming languages. The monitors guide Language Models to adhere to properties like valid identifier dereferences, correct number of arguments to method calls, typestate validity of method call sequences, and more.

mscclpp
MSCCL++ is a GPU-driven communication stack for scalable AI applications. It provides a highly efficient and customizable communication stack for distributed GPU applications. MSCCL++ redefines inter-GPU communication interfaces, delivering a highly efficient and customizable communication stack for distributed GPU applications. Its design is specifically tailored to accommodate diverse performance optimization scenarios often encountered in state-of-the-art AI applications. MSCCL++ provides communication abstractions at the lowest level close to hardware and at the highest level close to application API. The lowest level of abstraction is ultra light weight which enables a user to implement logics of data movement for a collective operation such as AllReduce inside a GPU kernel extremely efficiently without worrying about memory ordering of different ops. The modularity of MSCCL++ enables a user to construct the building blocks of MSCCL++ in a high level abstraction in Python and feed them to a CUDA kernel in order to facilitate the user's productivity. MSCCL++ provides fine-grained synchronous and asynchronous 0-copy 1-sided abstracts for communication primitives such as `put()`, `get()`, `signal()`, `flush()`, and `wait()`. The 1-sided abstractions allows a user to asynchronously `put()` their data on the remote GPU as soon as it is ready without requiring the remote side to issue any receive instruction. This enables users to easily implement flexible communication logics, such as overlapping communication with computation, or implementing customized collective communication algorithms without worrying about potential deadlocks. Additionally, the 0-copy capability enables MSCCL++ to directly transfer data between user's buffers without using intermediate internal buffers which saves GPU bandwidth and memory capacity. MSCCL++ provides consistent abstractions regardless of the location of the remote GPU (either on the local node or on a remote node) or the underlying link (either NVLink/xGMI or InfiniBand). This simplifies the code for inter-GPU communication, which is often complex due to memory ordering of GPU/CPU read/writes and therefore, is error-prone.
suql
SUQL (Structured and Unstructured Query Language) is a tool that augments SQL with free text primitives for building chatbots that can interact with relational data sources containing both structured and unstructured information. It seamlessly integrates retrieval models, large language models (LLMs), and traditional SQL to provide a clean interface for hybrid data access. SUQL supports optimizations to minimize expensive LLM calls, scalability to large databases with PostgreSQL, and general SQL operations like JOINs and GROUP BYs.
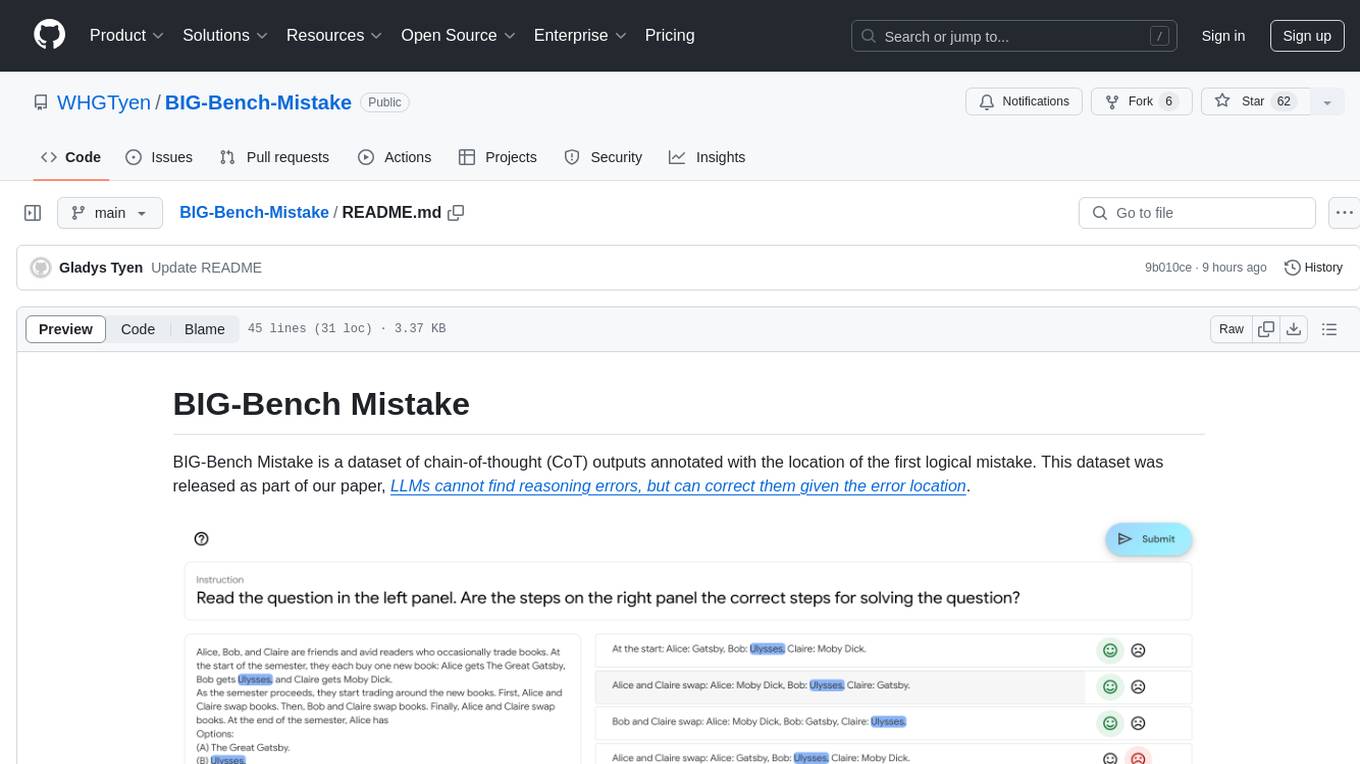
BIG-Bench-Mistake
BIG-Bench Mistake is a dataset of chain-of-thought (CoT) outputs annotated with the location of the first logical mistake. It was released as part of a research paper focusing on benchmarking LLMs in terms of their mistake-finding ability. The dataset includes CoT traces for tasks like Word Sorting, Tracking Shuffled Objects, Logical Deduction, Multistep Arithmetic, and Dyck Languages. Human annotators were recruited to identify mistake steps in these tasks, with automated annotation for Dyck Languages. Each JSONL file contains input questions, steps in the chain of thoughts, model's answer, correct answer, and the index of the first logical mistake.
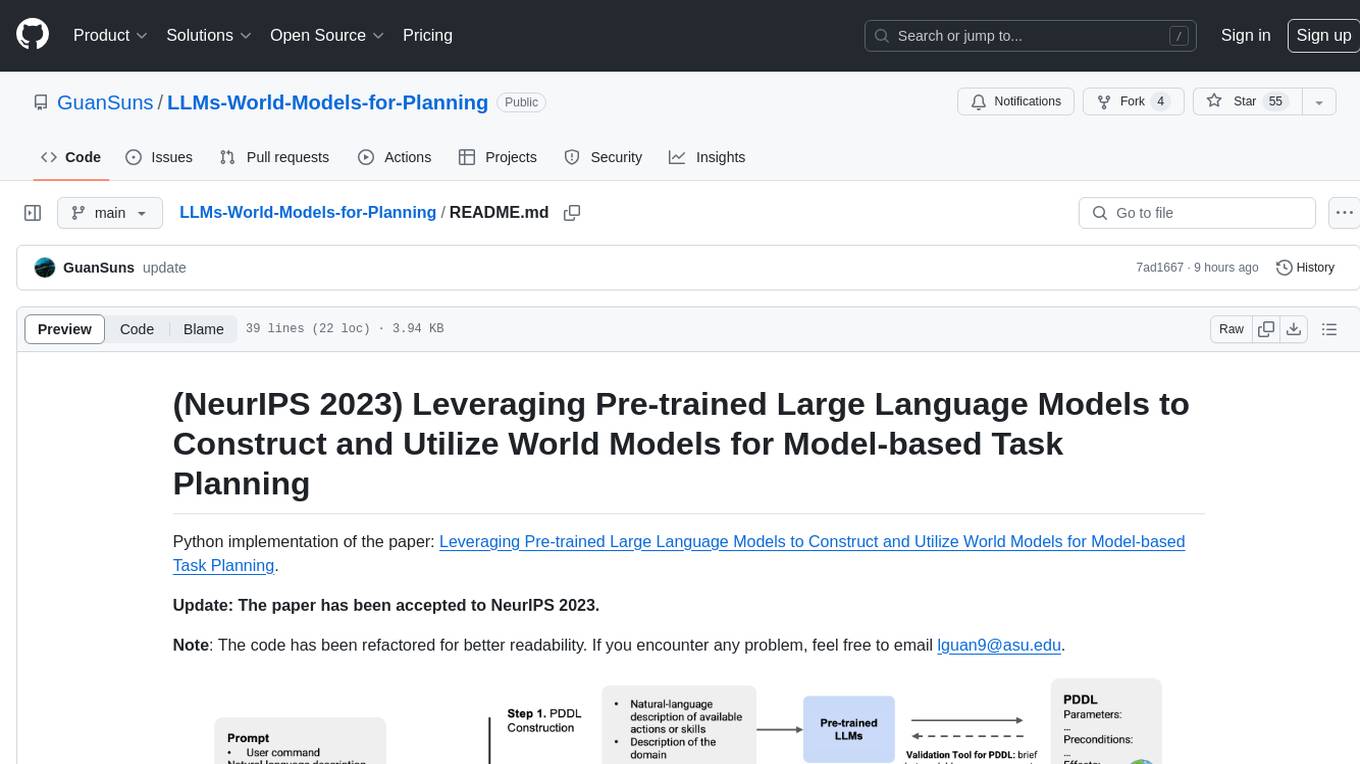
LLMs-World-Models-for-Planning
This repository provides a Python implementation of a method that leverages pre-trained large language models to construct and utilize world models for model-based task planning. It includes scripts to generate domain models using natural language descriptions, correct domain models based on feedback, and support plan generation for tasks in different domains. The code has been refactored for better readability and includes tools for validating PDDL syntax and handling corrective feedback.

NeMo
NVIDIA NeMo Framework is a scalable and cloud-native generative AI framework built for researchers and PyTorch developers working on Large Language Models (LLMs), Multimodal Models (MMs), Automatic Speech Recognition (ASR), Text to Speech (TTS), and Computer Vision (CV) domains. It is designed to help you efficiently create, customize, and deploy new generative AI models by leveraging existing code and pre-trained model checkpoints.
For similar tasks
aitlas
The AiTLAS toolbox (Artificial Intelligence Toolbox for Earth Observation) includes state-of-the-art machine learning methods for exploratory and predictive analysis of satellite imagery as well as a repository of AI-ready Earth Observation (EO) datasets. It can be easily applied for a variety of Earth Observation tasks, such as land use and cover classification, crop type prediction, localization of specific objects (semantic segmentation), etc. The main goal of AiTLAS is to facilitate better usability and adoption of novel AI methods (and models) by EO experts, while offering easy access and standardized format of EO datasets to AI experts which allows benchmarking of various existing and novel AI methods tailored for EO data.
Vitron
Vitron is a unified pixel-level vision LLM designed for comprehensive understanding, generating, segmenting, and editing static images and dynamic videos. It addresses challenges in existing vision LLMs such as superficial instance-level understanding, lack of unified support for images and videos, and insufficient coverage across various vision tasks. The tool requires Python >= 3.8, Pytorch == 2.1.0, and CUDA Version >= 11.8 for installation. Users can deploy Gradio demo locally and fine-tune their models for specific tasks.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

agentcloud
AgentCloud is an open-source platform that enables companies to build and deploy private LLM chat apps, empowering teams to securely interact with their data. It comprises three main components: Agent Backend, Webapp, and Vector Proxy. To run this project locally, clone the repository, install Docker, and start the services. The project is licensed under the GNU Affero General Public License, version 3 only. Contributions and feedback are welcome from the community.

oss-fuzz-gen
This framework generates fuzz targets for real-world `C`/`C++` projects with various Large Language Models (LLM) and benchmarks them via the `OSS-Fuzz` platform. It manages to successfully leverage LLMs to generate valid fuzz targets (which generate non-zero coverage increase) for 160 C/C++ projects. The maximum line coverage increase is 29% from the existing human-written targets.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.