
mscclpp
MSCCL++: A GPU-driven communication stack for scalable AI applications
Stars: 203

MSCCL++ is a GPU-driven communication stack for scalable AI applications. It provides a highly efficient and customizable communication stack for distributed GPU applications. MSCCL++ redefines inter-GPU communication interfaces, delivering a highly efficient and customizable communication stack for distributed GPU applications. Its design is specifically tailored to accommodate diverse performance optimization scenarios often encountered in state-of-the-art AI applications. MSCCL++ provides communication abstractions at the lowest level close to hardware and at the highest level close to application API. The lowest level of abstraction is ultra light weight which enables a user to implement logics of data movement for a collective operation such as AllReduce inside a GPU kernel extremely efficiently without worrying about memory ordering of different ops. The modularity of MSCCL++ enables a user to construct the building blocks of MSCCL++ in a high level abstraction in Python and feed them to a CUDA kernel in order to facilitate the user's productivity. MSCCL++ provides fine-grained synchronous and asynchronous 0-copy 1-sided abstracts for communication primitives such as `put()`, `get()`, `signal()`, `flush()`, and `wait()`. The 1-sided abstractions allows a user to asynchronously `put()` their data on the remote GPU as soon as it is ready without requiring the remote side to issue any receive instruction. This enables users to easily implement flexible communication logics, such as overlapping communication with computation, or implementing customized collective communication algorithms without worrying about potential deadlocks. Additionally, the 0-copy capability enables MSCCL++ to directly transfer data between user's buffers without using intermediate internal buffers which saves GPU bandwidth and memory capacity. MSCCL++ provides consistent abstractions regardless of the location of the remote GPU (either on the local node or on a remote node) or the underlying link (either NVLink/xGMI or InfiniBand). This simplifies the code for inter-GPU communication, which is often complex due to memory ordering of GPU/CPU read/writes and therefore, is error-prone.
README:


![]()
| Pipelines | Build Status |
|---|---|
| Unit Tests (CUDA) | |
| Integration Tests (CUDA) |
NOTE (Nov 2023): Azure pipelines for ROCm will be added soon.
A GPU-driven communication stack for scalable AI applications.
See Quick Start to quickly get started.
MSCCL++ redefines inter-GPU communication interfaces, thereby delivering a highly efficient and customizable communication stack for distributed GPU applications. Its design is specifically tailored to accommodate diverse performance optimization scenarios often encountered in state-of-the-art AI applications. Figure below provides a high-level overview of MSCCL++ abstractions in CUDA, C, and Python.
| MSCCL++ Abstractions Overview |
|---|
 |
The followings highlight the key features of MSCCL++.
-
Light-weight and multi-layer abstractions. MSCCL++ provides communication abstractions at lowest level close to hardware and at the highest level close to application API. The lowest level of abstraction is ultra light weight which enables a user to implement logics of data movement for a collective operation such as AllReduce inside a GPU kernel extremely efficiently without worrying about memory ordering of different ops. The modularity of MSCCL++ enables a user to construct the building blocks of MSCCL++ in a high level abstraction in Python and feed them to a CUDA kernel in order to facilitate the user's productivity.
-
1-sided 0-copy synchronous and asynchronous abstracts. MSCCL++ provides fine-grained synchronous and asynchronous 0-copy 1-sided abstracts for communication primitives such as
put(),get(),signal(),flush(), andwait(). The 1-sided abstractions allows a user to asynchronouslyput()their data on the remote GPU as soon as it is ready without requiring the remote side to issue any receive instruction. This enables users to easily implement flexible communication logics, such as overlapping communication with computation, or implementing customized collective communication algorithms without worrying about potential deadlocks. Additionally, the 0-copy capability enables MSCCL++ to directly transfer data between user's buffers without using intermediate internal buffers which saves GPU bandwidth and memory capacity. -
Unified abstractions for different interconnection hardware. MSCCL++ provides consistent abstractions regardless of the location of the remote GPU (either on the local node or on a remote node) or the underlying link (either NVLink/xGMI or InfiniBand). This simplifies the code for inter-GPU communication, which is often complex due to memory ordering of GPU/CPU read/writes and therefore, is error-prone.
While the power of MSCCL++ is fully realized with application-specific optimization, it still delivers performance benefits even for collective communication operations. The following figures provide a comparison of the AllReduce throughput of MSCCL++ against NCCL 2.19.3. This benchmark was tested over two Azure NDmv4 SKUs (8 A100-80G GPUs per node).
The key motivation behind these results is scaling of inference for LLM models using tensor parallelism. LLM requests usually are executed in two phases: prompt processing and token sampling. The prompt processing uses a large batch size that is usually equal to a request context length and the corresponding AllReduce size is len_context*dim_hidden*sizeof(fp16). For a context length of 2048 with a hidden dimension of 12288 (GPT-3 size), the AllReduce size is 48MB. The token sampling uses a smaller batch size which corresponds to concurrent user requests in the system and therefore, the AllReduce size is batch_size*dim_hidden*sizeof(fp16). For a concurrency of 16 users, the AllReduce size is 384KB. As the figures below demonstrates, MSCCL++ provides significant speed up over NCCL which is crucial for efficiency of serving LLMs at large scale.
| Single-node AllReduce | Two-node AllReduce |
|---|---|
 |
 |
The following highlights key concepts of MSCCL++.
MSCCL++ provides peer-to-peer communication methods between GPUs. A peer-to-peer connection between two GPUs is called a Channel. Channels are constructed by MSCCL++ host-side interfaces and copied to GPUs during initialization. Channels provide GPU-side interfaces, which means that all communication methods are defined as a device function to be called from a GPU kernel code. For example, the put() method in the following example copies 1KB data from the local GPU to a remote GPU.
// `ProxyChannel` will be explained in the following section.
__device__ mscclpp::DeviceHandle<mscclpp::SimpleProxyChannel> channel;
__global__ void gpuKernel() {
...
// Only one thread is needed for this method.
channel.put(/*dstOffset=*/ 0, /*srcOffset=*/ 0, /*size=*/ 1024);
...
}MSCCL++ also provides efficient synchronization methods, signal(), flush(), and wait(). For example, we can implement a simple barrier between two ranks (peer-to-peer connected through channel) as follows. Explanation of each method is inlined.
// Only one thread is needed for this function.
__device__ void barrier() {
// Inform the peer GPU that I have arrived at this point.
channel.signal();
// Flush the previous signal() call, which will wait for completion of signaling.
channel.flush();
// Wait for the peer GPU to call signal().
channel.wait();
// Now this thread is synchronized with the remote GPU’s thread.
// Users may call a local synchronize functions (e.g., __syncthreads())
// to synchronize other local threads as well with the remote side.
}MSCCL++ provides consistent interfaces, i.e., the above interfaces are used regardless of the location of the remote GPU (either on the local node or on a remote node) or the underlying link (either NVLink/xGMI or InfiniBand).
MSCCL++ delivers two types of channels, ProxyChannel and SmChannel. ProxyChannel provides (R)DMA-based data copy and synchronization methods. When called, these methods send/receive a signal to/from a host-side proxy (hence the name ProxyChannel), which will trigger (R)DMA (such as cudaMemcpy* or ibv_post_send) or issue synchronization methods (such as cudaStreamSynchronize or ibv_poll_cq). Since the key functionalities are run by the proxy, ProxyChannel requires only a single GPU thread to call its methods. See all ProxyChannel methods from here.
On the other hand, SmChannel provides memory-mapping-based copy and synchronization methods. When called, these methods will directly use GPU threads to read/write from/to the remote GPU's memory space. Comparing against ProxyChannel, SmChannel is especially performant for low-latency scenarios, while it may need many GPU threads to call copying methods at the same time to achieve high copying bandwidth. See all SmChannel methods from here.
MSCCL++ provides a default implementation of a host-side proxy for ProxyChannels, which is a background host thread that busy polls triggers from GPUs and conducts functionalities accordingly. For example, the following is a typical host-side code for MSCCL++.
// Bootstrap: initialize control-plane connections between all ranks
auto bootstrap = std::make_shared<mscclpp::TcpBootstrap>(rank, world_size);
// Create a communicator for connection setup
mscclpp::Communicator comm(bootstrap);
// Setup connections here using `comm`
...
// Construct the default proxy
mscclpp::ProxyService proxyService();
// Start the proxy
proxyService.startProxy();
// Run the user application, i.e., launch GPU kernels here
...
// Stop the proxy after the application is finished
proxyService.stopProxy();While the default implementation already enables any kinds of communication, MSCCL++ also supports users to easily implement their own customized proxies for further optimization. For example, the following example re-defines how to interpret triggers from GPUs.
// Proxy FIFO is obtained from mscclpp::Proxy on the host and copied to the device.
__device__ mscclpp::FifoDeviceHandle fifo;
__global__ void gpuKernel() {
...
// Only one thread is needed for the followings
mscclpp::ProxyTrigger trigger;
// Send a custom request: "1"
trigger.fst = 1;
fifo.push(trigger);
// Send a custom request: "2"
trigger.fst = 2;
fifo.push(trigger);
// Send a custom request: "0xdeadbeef"
trigger.fst = 0xdeadbeef;
fifo.push(trigger);
...
}
// Host-side custom proxy service
class CustomProxyService {
private:
mscclpp::Proxy proxy_;
public:
CustomProxyService() : proxy_([&](mscclpp::ProxyTrigger trigger) {
// Custom trigger handler
if (trigger.fst == 1) {
// Handle request "1"
} else if (trigger.fst == 2) {
// Handle request "2"
} else if (trigger.fst == 0xdeadbeef) {
// Handle request "0xdeadbeef"
}
},
[&]() { /* Empty proxy initializer */ }) {}
void startProxy() { proxy_.start(); }
void stopProxy() { proxy_.stop(); }
};Customized proxies can be used for conducting a series of pre-defined data transfers within only a single trigger from GPU at runtime. This would be more efficient than sending a trigger for each data transfer one by one.
MSCCL++ provides Python bindings and interfaces, which simplifies integration with Python applications.
This project welcomes contributions and suggestions. Most contributions require you to agree to a Contributor License Agreement (CLA) declaring that you have the right to, and actually do, grant us the rights to use your contribution. For details, visit https://cla.opensource.microsoft.com.
When you submit a pull request, a CLA bot will automatically determine whether you need to provide a CLA and decorate the PR appropriately (e.g., status check, comment). Simply follow the instructions provided by the bot. You will only need to do this once across all repos using our CLA.
This project has adopted the Microsoft Open Source Code of Conduct. For more information see the Code of Conduct FAQ or contact [email protected] with any additional questions or comments.
This project may contain trademarks or logos for projects, products, or services. Authorized use of Microsoft trademarks or logos is subject to and must follow Microsoft's Trademark & Brand Guidelines. Use of Microsoft trademarks or logos in modified versions of this project must not cause confusion or imply Microsoft sponsorship. Any use of third-party trademarks or logos are subject to those third-party's policies.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for mscclpp
Similar Open Source Tools
mscclpp
MSCCL++ is a GPU-driven communication stack for scalable AI applications. It provides a highly efficient and customizable communication stack for distributed GPU applications. MSCCL++ redefines inter-GPU communication interfaces, delivering a highly efficient and customizable communication stack for distributed GPU applications. Its design is specifically tailored to accommodate diverse performance optimization scenarios often encountered in state-of-the-art AI applications. MSCCL++ provides communication abstractions at the lowest level close to hardware and at the highest level close to application API. The lowest level of abstraction is ultra light weight which enables a user to implement logics of data movement for a collective operation such as AllReduce inside a GPU kernel extremely efficiently without worrying about memory ordering of different ops. The modularity of MSCCL++ enables a user to construct the building blocks of MSCCL++ in a high level abstraction in Python and feed them to a CUDA kernel in order to facilitate the user's productivity. MSCCL++ provides fine-grained synchronous and asynchronous 0-copy 1-sided abstracts for communication primitives such as `put()`, `get()`, `signal()`, `flush()`, and `wait()`. The 1-sided abstractions allows a user to asynchronously `put()` their data on the remote GPU as soon as it is ready without requiring the remote side to issue any receive instruction. This enables users to easily implement flexible communication logics, such as overlapping communication with computation, or implementing customized collective communication algorithms without worrying about potential deadlocks. Additionally, the 0-copy capability enables MSCCL++ to directly transfer data between user's buffers without using intermediate internal buffers which saves GPU bandwidth and memory capacity. MSCCL++ provides consistent abstractions regardless of the location of the remote GPU (either on the local node or on a remote node) or the underlying link (either NVLink/xGMI or InfiniBand). This simplifies the code for inter-GPU communication, which is often complex due to memory ordering of GPU/CPU read/writes and therefore, is error-prone.

gepa
GEPA (Genetic-Pareto) is a framework for optimizing arbitrary systems composed of text components like AI prompts, code snippets, or textual specs against any evaluation metric. It employs LLMs to reflect on system behavior, using feedback from execution and evaluation traces to drive targeted improvements. Through iterative mutation, reflection, and Pareto-aware candidate selection, GEPA evolves robust, high-performing variants with minimal evaluations, co-evolving multiple components in modular systems for domain-specific gains. The repository provides the official implementation of the GEPA algorithm as proposed in the paper titled 'GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning'.

llm_client
llm_client is a Rust interface designed for Local Large Language Models (LLMs) that offers automated build support for CPU, CUDA, MacOS, easy model presets, and a novel cascading prompt workflow for controlled generation. It provides a breadth of configuration options and API support for various OpenAI compatible APIs. The tool is primarily focused on deterministic signals from probabilistic LLM vibes, enabling specialized workflows for specific tasks and reproducible outcomes.

onnxruntime-genai
ONNX Runtime Generative AI is a library that provides the generative AI loop for ONNX models, including inference with ONNX Runtime, logits processing, search and sampling, and KV cache management. Users can call a high level `generate()` method, or run each iteration of the model in a loop. It supports greedy/beam search and TopP, TopK sampling to generate token sequences, has built in logits processing like repetition penalties, and allows for easy custom scoring.

multilspy
Multilspy is a Python library developed for research purposes to facilitate the creation of language server clients for querying and obtaining results of static analyses from various language servers. It simplifies the process by handling server setup, communication, and configuration parameters, providing a common interface for different languages. The library supports features like finding function/class definitions, callers, completions, hover information, and document symbols. It is designed to work with AI systems like Large Language Models (LLMs) for tasks such as Monitor-Guided Decoding to ensure code generation correctness and boost compilability.
uTensor
uTensor is an extremely light-weight machine learning inference framework built on Tensorflow and optimized for Arm targets. It consists of a runtime library and an offline tool that handles most of the model translation work. The core runtime is only ~2KB. The workflow involves constructing and training a model in Tensorflow, then using uTensor to produce C++ code for inferencing. The runtime ensures system safety, guarantees RAM usage, and focuses on clear, concise, and debuggable code. The high-level API simplifies tensor handling and operator execution for embedded systems.
aiomultiprocess
aiomultiprocess is a Python library that combines AsyncIO and multiprocessing to achieve high levels of concurrency in Python applications. It allows running a full AsyncIO event loop on each child process, enabling multiple coroutines to execute simultaneously. The library provides a simple interface for executing asynchronous tasks on a pool of worker processes, making it easy to gather large amounts of network requests quickly. aiomultiprocess is designed to take Python codebases to the next level of performance by leveraging the combined power of AsyncIO and multiprocessing.

kafka-ml
Kafka-ML is a framework designed to manage the pipeline of Tensorflow/Keras and PyTorch machine learning models on Kubernetes. It enables the design, training, and inference of ML models with datasets fed through Apache Kafka, connecting them directly to data streams like those from IoT devices. The Web UI allows easy definition of ML models without external libraries, catering to both experts and non-experts in ML/AI.

verifAI
VerifAI is a document-based question-answering system that addresses hallucinations in generative large language models and search engines. It retrieves relevant documents, generates answers with references, and verifies answers for accuracy. The engine uses generative search technology and a verification model to ensure no misinformation. VerifAI supports various document formats and offers user registration with a React.js interface. It is open-source and designed to be user-friendly, making it accessible for anyone to use.

MegatronApp
MegatronApp is a toolchain built around the Megatron-LM training framework, offering performance tuning, slow-node detection, and training-process visualization. It includes modules like MegaScan for anomaly detection, MegaFBD for forward-backward decoupling, MegaDPP for dynamic pipeline planning, and MegaScope for visualization. The tool aims to enhance large-scale distributed training by providing valuable capabilities and insights.

monitors4codegen
This repository hosts the official code and data artifact for the paper 'Monitor-Guided Decoding of Code LMs with Static Analysis of Repository Context'. It introduces Monitor-Guided Decoding (MGD) for code generation using Language Models, where a monitor uses static analysis to guide the decoding. The repository contains datasets, evaluation scripts, inference results, a language server client 'multilspy' for static analyses, and implementation of various monitors monitoring for different properties in 3 programming languages. The monitors guide Language Models to adhere to properties like valid identifier dereferences, correct number of arguments to method calls, typestate validity of method call sequences, and more.

easydist
EasyDist is an automated parallelization system and infrastructure designed for multiple ecosystems. It offers usability by making parallelizing training or inference code effortless with just a single line of change. It ensures ecological compatibility by serving as a centralized source of truth for SPMD rules at the operator-level for various machine learning frameworks. EasyDist decouples auto-parallel algorithms from specific frameworks and IRs, allowing for the development and benchmarking of different auto-parallel algorithms in a flexible manner. The architecture includes MetaOp, MetaIR, and the ShardCombine Algorithm for SPMD sharding rules without manual annotations.

lerobot
LeRobot is a state-of-the-art AI library for real-world robotics in PyTorch. It aims to provide models, datasets, and tools to lower the barrier to entry to robotics, focusing on imitation learning and reinforcement learning. LeRobot offers pretrained models, datasets with human-collected demonstrations, and simulation environments. It plans to support real-world robotics on affordable and capable robots. The library hosts pretrained models and datasets on the Hugging Face community page.

llm-reasoners
LLM Reasoners is a library that enables LLMs to conduct complex reasoning, with advanced reasoning algorithms. It approaches multi-step reasoning as planning and searches for the optimal reasoning chain, which achieves the best balance of exploration vs exploitation with the idea of "World Model" and "Reward". Given any reasoning problem, simply define the reward function and an optional world model (explained below), and let LLM reasoners take care of the rest, including Reasoning Algorithms, Visualization, LLM calling, and more!
craftium
Craftium is an open-source platform based on the Minetest voxel game engine and the Gymnasium and PettingZoo APIs, designed for creating fast, rich, and diverse single and multi-agent environments. It allows for connecting to Craftium's Python process, executing actions as keyboard and mouse controls, extending the Lua API for creating RL environments and tasks, and supporting client/server synchronization for slow agents. Craftium is fully extensible, extensively documented, modern RL API compatible, fully open source, and eliminates the need for Java. It offers a variety of environments for research and development in reinforcement learning.
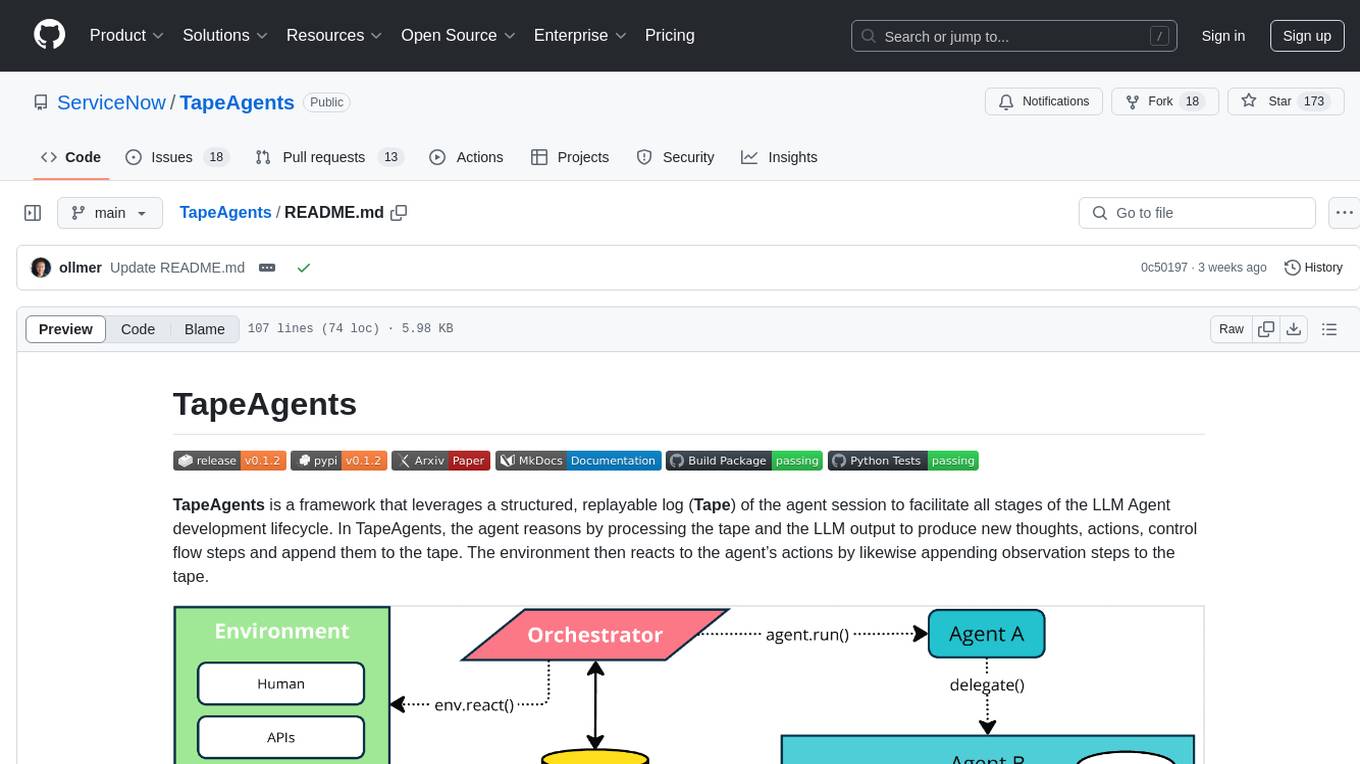
TapeAgents
TapeAgents is a framework that leverages a structured, replayable log of the agent session to facilitate all stages of the LLM Agent development lifecycle. The agent reasons by processing the tape and the LLM output to produce new thoughts, actions, control flow steps, and append them to the tape. Key features include building agents as low-level state machines or high-level multi-agent team configurations, debugging agents with TapeAgent studio or TapeBrowser apps, serving agents with response streaming, and optimizing agent configurations using successful tapes. The Tape-centric design of TapeAgents provides ultimate flexibility in project development, allowing access to tapes for making prompts, generating next steps, and controlling agent behavior.
For similar tasks

ai-on-gke
This repository contains assets related to AI/ML workloads on Google Kubernetes Engine (GKE). Run optimized AI/ML workloads with Google Kubernetes Engine (GKE) platform orchestration capabilities. A robust AI/ML platform considers the following layers: Infrastructure orchestration that support GPUs and TPUs for training and serving workloads at scale Flexible integration with distributed computing and data processing frameworks Support for multiple teams on the same infrastructure to maximize utilization of resources

ray
Ray is a unified framework for scaling AI and Python applications. It consists of a core distributed runtime and a set of AI libraries for simplifying ML compute, including Data, Train, Tune, RLlib, and Serve. Ray runs on any machine, cluster, cloud provider, and Kubernetes, and features a growing ecosystem of community integrations. With Ray, you can seamlessly scale the same code from a laptop to a cluster, making it easy to meet the compute-intensive demands of modern ML workloads.

labelbox-python
Labelbox is a data-centric AI platform for enterprises to develop, optimize, and use AI to solve problems and power new products and services. Enterprises use Labelbox to curate data, generate high-quality human feedback data for computer vision and LLMs, evaluate model performance, and automate tasks by combining AI and human-centric workflows. The academic & research community uses Labelbox for cutting-edge AI research.

djl
Deep Java Library (DJL) is an open-source, high-level, engine-agnostic Java framework for deep learning. It is designed to be easy to get started with and simple to use for Java developers. DJL provides a native Java development experience and allows users to integrate machine learning and deep learning models with their Java applications. The framework is deep learning engine agnostic, enabling users to switch engines at any point for optimal performance. DJL's ergonomic API interface guides users with best practices to accomplish deep learning tasks, such as running inference and training neural networks.

mlflow
MLflow is a platform to streamline machine learning development, including tracking experiments, packaging code into reproducible runs, and sharing and deploying models. MLflow offers a set of lightweight APIs that can be used with any existing machine learning application or library (TensorFlow, PyTorch, XGBoost, etc), wherever you currently run ML code (e.g. in notebooks, standalone applications or the cloud). MLflow's current components are:
* `MLflow Tracking

tt-metal
TT-NN is a python & C++ Neural Network OP library. It provides a low-level programming model, TT-Metalium, enabling kernel development for Tenstorrent hardware.

burn
Burn is a new comprehensive dynamic Deep Learning Framework built using Rust with extreme flexibility, compute efficiency and portability as its primary goals.

awsome-distributed-training
This repository contains reference architectures and test cases for distributed model training with Amazon SageMaker Hyperpod, AWS ParallelCluster, AWS Batch, and Amazon EKS. The test cases cover different types and sizes of models as well as different frameworks and parallel optimizations (Pytorch DDP/FSDP, MegatronLM, NemoMegatron...).
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.