
lerobot
🤗 LeRobot: Making AI for Robotics more accessible with end-to-end learning
Stars: 21727

LeRobot is a state-of-the-art AI library for real-world robotics in PyTorch. It aims to provide models, datasets, and tools to lower the barrier to entry to robotics, focusing on imitation learning and reinforcement learning. LeRobot offers pretrained models, datasets with human-collected demonstrations, and simulation environments. It plans to support real-world robotics on affordable and capable robots. The library hosts pretrained models and datasets on the Hugging Face community page.
README:
![]()
![]()



LeRobot aims to provide models, datasets, and tools for real-world robotics in PyTorch. The goal is to lower the barrier to entry so that everyone can contribute to and benefit from shared datasets and pretrained models.
🤗 A hardware-agnostic, Python-native interface that standardizes control across diverse platforms, from low-cost arms (SO-100) to humanoids.
🤗 A standardized, scalable LeRobotDataset format (Parquet + MP4 or images) hosted on the Hugging Face Hub, enabling efficient storage, streaming and visualization of massive robotic datasets.
🤗 State-of-the-art policies that have been shown to transfer to the real-world ready for training and deployment.
🤗 Comprehensive support for the open-source ecosystem to democratize physical AI.
LeRobot can be installed directly from PyPI.
pip install lerobot
lerobot-info[!IMPORTANT] For detailed installation guide, please see the Installation Documentation.

LeRobot provides a unified Robot class interface that decouples control logic from hardware specifics. It supports a wide range of robots and teleoperation devices.
from lerobot.robots.myrobot import MyRobot
# Connect to a robot
robot = MyRobot(config=...)
robot.connect()
# Read observation and send action
obs = robot.get_observation()
action = model.select_action(obs)
robot.send_action(action)Supported Hardware: SO100, LeKiwi, Koch, HopeJR, OMX, EarthRover, Reachy2, Gamepads, Keyboards, Phones, OpenARM, Unitree G1.
While these devices are natively integrated into the LeRobot codebase, the library is designed to be extensible. You can easily implement the Robot interface to utilize LeRobot's data collection, training, and visualization tools for your own custom robot.
For detailed hardware setup guides, see the Hardware Documentation.
To solve the data fragmentation problem in robotics, we utilize the LeRobotDataset format.
- Structure: Synchronized MP4 videos (or images) for vision and Parquet files for state/action data.
- HF Hub Integration: Explore thousands of robotics datasets on the Hugging Face Hub.
- Tools: Seamlessly delete episodes, split by indices/fractions, add/remove features, and merge multiple datasets.
from lerobot.datasets.lerobot_dataset import LeRobotDataset
# Load a dataset from the Hub
dataset = LeRobotDataset("lerobot/aloha_mobile_cabinet")
# Access data (automatically handles video decoding)
episode_index=0
print(f"{dataset[episode_index]['action'].shape=}\n")Learn more about it in the LeRobotDataset Documentation
LeRobot implements state-of-the-art policies in pure PyTorch, covering Imitation Learning, Reinforcement Learning, and Vision-Language-Action (VLA) models, with more coming soon. It also provides you with the tools to instrument and inspect your training process.

Training a policy is as simple as running a script configuration:
lerobot-train \
--policy=act \
--dataset.repo_id=lerobot/aloha_mobile_cabinet| Category | Models |
|---|---|
| Imitation Learning | ACT, Diffusion, VQ-BeT |
| Reinforcement Learning | HIL-SERL, TDMPC & QC-FQL (coming soon) |
| VLAs Models | Pi0Fast, Pi0.5, GR00T N1.5, SmolVLA, XVLA |
Similarly to the hardware, you can easily implement your own policy & leverage LeRobot's data collection, training, and visualization tools, and share your model to the HF Hub
For detailed policy setup guides, see the Policy Documentation.
Evaluate your policies in simulation or on real hardware using the unified evaluation script. LeRobot supports standard benchmarks like LIBERO, MetaWorld and more to come.
# Evaluate a policy on the LIBERO benchmark
lerobot-eval \
--policy.path=lerobot/pi0_libero_finetuned \
--env.type=libero \
--env.task=libero_object \
--eval.n_episodes=10Learn how to implement your own simulation environment or benchmark and distribute it from the HF Hub by following the EnvHub Documentation
- Documentation: The complete guide to tutorials & API.
- Chinese Tutorials: LeRobot+SO-ARM101中文教程-同济子豪兄 Detailed doc for assembling, teleoperate, dataset, train, deploy. Verified by Seed Studio and 5 global hackathon players.
-
Discord: Join the
LeRobotserver to discuss with the community. - X: Follow us on X to stay up-to-date with the latest developments.
- Robot Learning Tutorial: A free, hands-on course to learn robot learning using LeRobot.
If you use LeRobot in your research, please cite:
@misc{cadene2024lerobot,
author = {Cadene, Remi and Alibert, Simon and Soare, Alexander and Gallouedec, Quentin and Zouitine, Adil and Palma, Steven and Kooijmans, Pepijn and Aractingi, Michel and Shukor, Mustafa and Aubakirova, Dana and Russi, Martino and Capuano, Francesco and Pascal, Caroline and Choghari, Jade and Moss, Jess and Wolf, Thomas},
title = {LeRobot: State-of-the-art Machine Learning for Real-World Robotics in Pytorch},
howpublished = "\url{https://github.com/huggingface/lerobot}",
year = {2024}
}We welcome contributions from everyone in the community! To get started, please read our CONTRIBUTING.md guide. Whether you're adding a new feature, improving documentation, or fixing a bug, your help and feedback are invaluable. We're incredibly excited about the future of open-source robotics and can't wait to work with you on what's next—thank you for your support!

For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for lerobot
Similar Open Source Tools
lerobot
LeRobot is a state-of-the-art AI library for real-world robotics in PyTorch. It aims to provide models, datasets, and tools to lower the barrier to entry to robotics, focusing on imitation learning and reinforcement learning. LeRobot offers pretrained models, datasets with human-collected demonstrations, and simulation environments. It plans to support real-world robotics on affordable and capable robots. The library hosts pretrained models and datasets on the Hugging Face community page.

AdalFlow
AdalFlow is a library designed to help developers build and optimize Large Language Model (LLM) task pipelines. It follows a design pattern similar to PyTorch, offering a light, modular, and robust codebase. Named in honor of Ada Lovelace, AdalFlow aims to inspire more women to enter the AI field. The library is tailored for various GenAI applications like chatbots, translation, summarization, code generation, and autonomous agents, as well as classical NLP tasks such as text classification and named entity recognition. AdalFlow emphasizes modularity, robustness, and readability to support users in customizing and iterating code for their specific use cases.

LightLLM
LightLLM is a lightweight library for linear and logistic regression models. It provides a simple and efficient way to train and deploy machine learning models for regression tasks. The library is designed to be easy to use and integrate into existing projects, making it suitable for both beginners and experienced data scientists. With LightLLM, users can quickly build and evaluate regression models using a variety of algorithms and hyperparameters. The library also supports feature engineering and model interpretation, allowing users to gain insights from their data and make informed decisions based on the model predictions.

openrl
OpenRL is an open-source general reinforcement learning research framework that supports training for various tasks such as single-agent, multi-agent, offline RL, self-play, and natural language. Developed based on PyTorch, the goal of OpenRL is to provide a simple-to-use, flexible, efficient and sustainable platform for the reinforcement learning research community. It supports a universal interface for all tasks/environments, single-agent and multi-agent tasks, offline RL training with expert dataset, self-play training, reinforcement learning training for natural language tasks, DeepSpeed, Arena for evaluation, importing models and datasets from Hugging Face, user-defined environments, models, and datasets, gymnasium environments, callbacks, visualization tools, unit testing, and code coverage testing. It also supports various algorithms like PPO, DQN, SAC, and environments like Gymnasium, MuJoCo, Atari, and more.

biochatter
Generative AI models have shown tremendous usefulness in increasing accessibility and automation of a wide range of tasks. This repository contains the `biochatter` Python package, a generic backend library for the connection of biomedical applications to conversational AI. It aims to provide a common framework for deploying, testing, and evaluating diverse models and auxiliary technologies in the biomedical domain. BioChatter is part of the BioCypher ecosystem, connecting natively to BioCypher knowledge graphs.
Open-LLM-VTuber
Open-LLM-VTuber is a voice-interactive AI companion supporting real-time voice conversations and featuring a Live2D avatar. It can run offline on Windows, macOS, and Linux, offering web and desktop client modes. Users can customize appearance and persona, with rich LLM inference, text-to-speech, and speech recognition support. The project is highly customizable, extensible, and actively developed with exciting features planned. It provides privacy with offline mode, persistent chat logs, and various interaction features like voice interruption, touch feedback, Live2D expressions, pet mode, and more.

ludwig
Ludwig is a declarative deep learning framework designed for scale and efficiency. It is a low-code framework that allows users to build custom AI models like LLMs and other deep neural networks with ease. Ludwig offers features such as optimized scale and efficiency, expert level control, modularity, and extensibility. It is engineered for production with prebuilt Docker containers, support for running with Ray on Kubernetes, and the ability to export models to Torchscript and Triton. Ludwig is hosted by the Linux Foundation AI & Data.

cognee
Cognee is an open-source framework designed for creating self-improving deterministic outputs for Large Language Models (LLMs) using graphs, LLMs, and vector retrieval. It provides a platform for AI engineers to enhance their models and generate more accurate results. Users can leverage Cognee to add new information, utilize LLMs for knowledge creation, and query the system for relevant knowledge. The tool supports various LLM providers and offers flexibility in adding different data types, such as text files or directories. Cognee aims to streamline the process of working with LLMs and improving AI models for better performance and efficiency.

MineStudio
MineStudio is a simple and efficient Minecraft development kit for AI research. It contains tools and APIs for developing Minecraft AI agents, including a customizable simulator, trajectory data structure, policy models, offline and online training pipelines, inference framework, and benchmarking automation. The repository is under development and welcomes contributions and suggestions.

lobe-chat
Lobe Chat is an open-source, modern-design ChatGPT/LLMs UI/Framework. Supports speech-synthesis, multi-modal, and extensible ([function call][docs-functionc-call]) plugin system. One-click **FREE** deployment of your private OpenAI ChatGPT/Claude/Gemini/Groq/Ollama chat application.
pipecat
Pipecat is an open-source framework designed for building generative AI voice bots and multimodal assistants. It provides code building blocks for interacting with AI services, creating low-latency data pipelines, and transporting audio, video, and events over the Internet. Pipecat supports various AI services like speech-to-text, text-to-speech, image generation, and vision models. Users can implement new services and contribute to the framework. Pipecat aims to simplify the development of applications like personal coaches, meeting assistants, customer support bots, and more by providing a complete framework for integrating AI services.

plano
Plano is an AI-native proxy server and data plane for agentic apps that simplifies agent routing, orchestration, signals and traces, guardrail filters, and smart LLM routing APIs. It centralizes core delivery concerns into a unified dataplane, allowing developers to focus on the core product logic of agentic applications. Plano supports any language or AI framework, enabling faster delivery of agents to production. It is built on industry-leading LLM research and Envoy by core contributors.
repromodel
ReproModel is an open-source toolbox designed to boost AI research efficiency by enabling researchers to reproduce, compare, train, and test AI models faster. It provides standardized models, dataloaders, and processing procedures, allowing researchers to focus on new datasets and model development. With a no-code solution, users can access benchmark and SOTA models and datasets, utilize training visualizations, extract code for publication, and leverage an LLM-powered automated methodology description writer. The toolbox helps researchers modularize development, compare pipeline performance reproducibly, and reduce time for model development, computation, and writing. Future versions aim to facilitate building upon state-of-the-art research by loading previously published study IDs with verified code, experiments, and results stored in the system.

gpt4all
GPT4All is an ecosystem to run powerful and customized large language models that work locally on consumer grade CPUs and any GPU. Note that your CPU needs to support AVX or AVX2 instructions. Learn more in the documentation. A GPT4All model is a 3GB - 8GB file that you can download and plug into the GPT4All open-source ecosystem software. Nomic AI supports and maintains this software ecosystem to enforce quality and security alongside spearheading the effort to allow any person or enterprise to easily train and deploy their own on-edge large language models.
tuff
Tuff is a local-first, AI-native, and infinitely extensible desktop command center designed to enhance workflow efficiency. It offers a seamless integration of core utilities, AI-powered search, contextual intelligence, and extensibility through custom plugins. With a beautiful UI design, rich functionality, simple operations, and a focus on security and reliability, Tuff provides users with a cross-platform desktop software that is easy to use and offers a good user experience.
fAIr
fAIr is an open AI-assisted mapping service developed by the Humanitarian OpenStreetMap Team (HOT) to improve mapping efficiency and accuracy for humanitarian purposes. It uses AI models, specifically computer vision techniques, to detect objects like buildings, roads, waterways, and trees from satellite and UAV imagery. The service allows OSM community members to create and train their own AI models for mapping in their region of interest and ensures models are relevant to local communities. Constant feedback loop with local communities helps eliminate model biases and improve model accuracy.
For similar tasks
lerobot
LeRobot is a state-of-the-art AI library for real-world robotics in PyTorch. It aims to provide models, datasets, and tools to lower the barrier to entry to robotics, focusing on imitation learning and reinforcement learning. LeRobot offers pretrained models, datasets with human-collected demonstrations, and simulation environments. It plans to support real-world robotics on affordable and capable robots. The library hosts pretrained models and datasets on the Hugging Face community page.
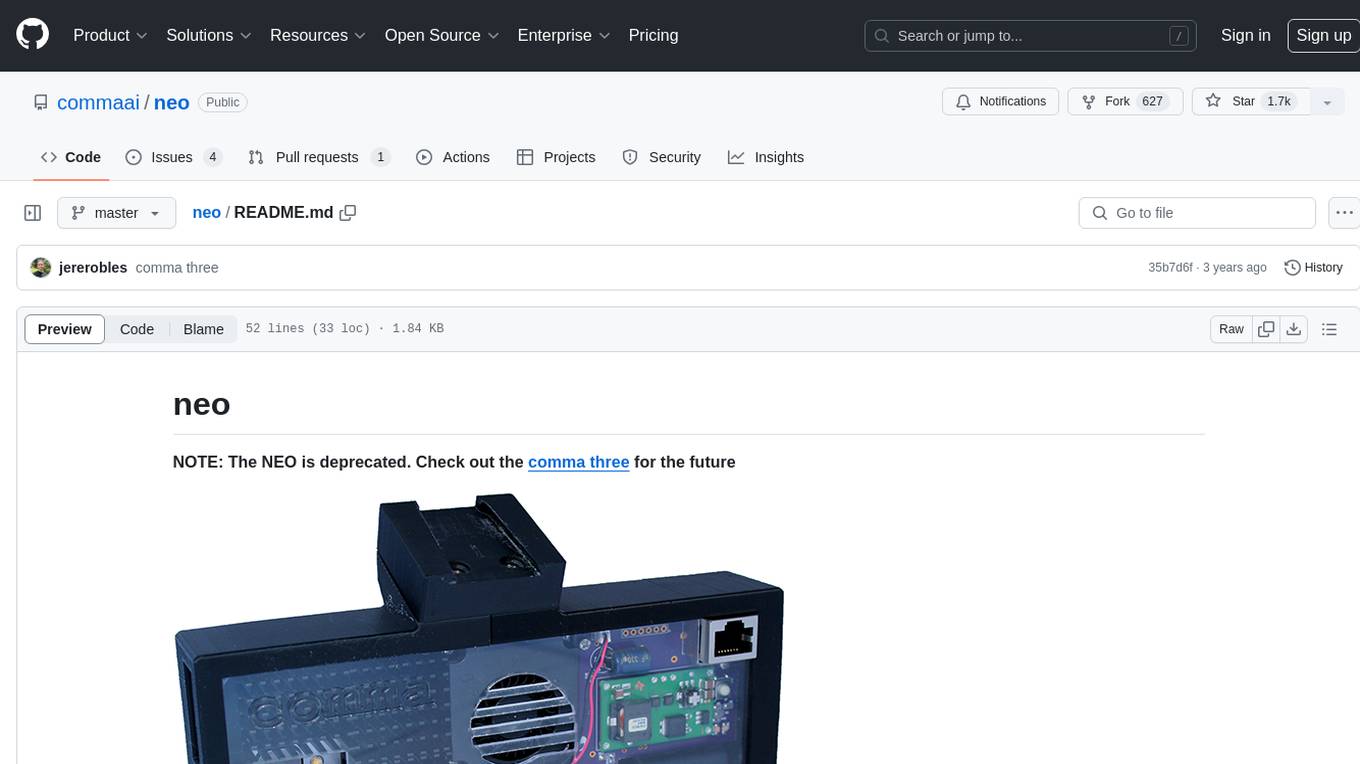
neo
The neo is an open source robotics research platform powered by a OnePlus 3 smartphone and an STM32F205-based CAN interface board, housed in a 3d-printed casing with active cooling. It includes NEOS, a stripped down Android ROM, and offers a modern Linux environment for development. The platform leverages the high performance embedded processor and sensor capabilities of modern smartphones at a low cost. A detailed guide is available for easy construction, requiring online shopping and soldering skills. The total cost for building a neo is approximately $700.
robot-3dlotus
Towards Generalizable Vision-Language Robotic Manipulation: A Benchmark and LLM-guided 3D Policy is a research project focusing on addressing the challenge of generalizing language-conditioned robotic policies to new tasks. The project introduces GemBench, a benchmark to evaluate the generalization capabilities of vision-language robotic manipulation policies. It also presents the 3D-LOTUS approach, which leverages rich 3D information for action prediction conditioned on language. Additionally, the project introduces 3D-LOTUS++, a framework that integrates 3D-LOTUS's motion planning capabilities with the task planning capabilities of LLMs and the object grounding accuracy of VLMs to achieve state-of-the-art performance on novel tasks in robotic manipulation.
machinascript-for-robots
MachinaScript For Robots is a dynamic set of tools and a LLM-JSON-based language designed to empower humans in the creation of their own robots. It facilitates the animation of generative movements, the integration of personality, and the teaching of new skills with a high degree of autonomy. With MachinaScript, users can control a wide range of electronic components, including Arduinos, Raspberry Pis, servo motors, cameras, sensors, and more. The tool enables the creation of intelligent robots accessible to everyone, allowing for complex tasks to be performed with elegance and precision.

vllm
vLLM is a fast and easy-to-use library for LLM inference and serving. It is designed to be efficient, flexible, and easy to use. vLLM can be used to serve a variety of LLM models, including Hugging Face models. It supports a variety of decoding algorithms, including parallel sampling, beam search, and more. vLLM also supports tensor parallelism for distributed inference and streaming outputs. It is open-source and available on GitHub.

bce-qianfan-sdk
The Qianfan SDK provides best practices for large model toolchains, allowing AI workflows and AI-native applications to access the Qianfan large model platform elegantly and conveniently. The core capabilities of the SDK include three parts: large model reasoning, large model training, and general and extension: * `Large model reasoning`: Implements interface encapsulation for reasoning of Yuyan (ERNIE-Bot) series, open source large models, etc., supporting dialogue, completion, Embedding, etc. * `Large model training`: Based on platform capabilities, it supports end-to-end large model training process, including training data, fine-tuning/pre-training, and model services. * `General and extension`: General capabilities include common AI development tools such as Prompt/Debug/Client. The extension capability is based on the characteristics of Qianfan to adapt to common middleware frameworks.

dstack
Dstack is an open-source orchestration engine for running AI workloads in any cloud. It supports a wide range of cloud providers (such as AWS, GCP, Azure, Lambda, TensorDock, Vast.ai, CUDO, RunPod, etc.) as well as on-premises infrastructure. With Dstack, you can easily set up and manage dev environments, tasks, services, and pools for your AI workloads.

RVC_CLI
**RVC_CLI: Retrieval-based Voice Conversion Command Line Interface** This command-line interface (CLI) provides a comprehensive set of tools for voice conversion, enabling you to modify the pitch, timbre, and other characteristics of audio recordings. It leverages advanced machine learning models to achieve realistic and high-quality voice conversions. **Key Features:** * **Inference:** Convert the pitch and timbre of audio in real-time or process audio files in batch mode. * **TTS Inference:** Synthesize speech from text using a variety of voices and apply voice conversion techniques. * **Training:** Train custom voice conversion models to meet specific requirements. * **Model Management:** Extract, blend, and analyze models to fine-tune and optimize performance. * **Audio Analysis:** Inspect audio files to gain insights into their characteristics. * **API:** Integrate the CLI's functionality into your own applications or workflows. **Applications:** The RVC_CLI finds applications in various domains, including: * **Music Production:** Create unique vocal effects, harmonies, and backing vocals. * **Voiceovers:** Generate voiceovers with different accents, emotions, and styles. * **Audio Editing:** Enhance or modify audio recordings for podcasts, audiobooks, and other content. * **Research and Development:** Explore and advance the field of voice conversion technology. **For Jobs:** * Audio Engineer * Music Producer * Voiceover Artist * Audio Editor * Machine Learning Engineer **AI Keywords:** * Voice Conversion * Pitch Shifting * Timbre Modification * Machine Learning * Audio Processing **For Tasks:** * Convert Pitch * Change Timbre * Synthesize Speech * Train Model * Analyze Audio
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.