Best AI tools for< Train Model >
20 - AI tool Sites
Backend.AI
Backend.AI is an enterprise-scale cluster backend for AI frameworks that offers scalability, GPU virtualization, HPC optimization, and DGX-Ready software products. It provides a fast and efficient way to build, train, and serve AI models of any type and size, with flexible infrastructure options. Backend.AI aims to optimize backend resources, reduce costs, and simplify deployment for AI developers and researchers. The platform integrates seamlessly with existing tools and offers fractional GPU usage and pay-as-you-play model to maximize resource utilization.
Outlier AI
Outlier AI is a platform that connects subject matter experts to help build the world's most advanced Generative AI. It allows experts to work on various projects from generating training data to evaluating model performance. The platform offers flexibility, allowing contributors to work from home on their own schedule. Outlier AI aims to redefine how AI learns by leveraging the expertise of domain specialists across different fields.
Arcee AI
Arcee AI is a platform that offers a cost-effective, secure, end-to-end solution for building and deploying Small Language Models (SLMs). It allows users to merge and train custom language models by leveraging open source models and their own data. The platform is known for its Model Merging technique, which combines the power of pre-trained Large Language Models (LLMs) with user-specific data to create high-performing models across various industries.
Unsloth
Unsloth is an AI tool designed to make finetuning large language models like Llama-3, Mistral, Phi-3, and Gemma 2x faster, use 70% less memory, and with no degradation in accuracy. The tool provides documentation to help users navigate through training their custom models, covering essentials such as installing and updating Unsloth, creating datasets, running, and deploying models. Users can also integrate third-party tools and utilize platforms like Google Colab.

LuckyRobots
LuckyRobots is an AI tool designed to make robotics accessible to software engineers by providing a simulation platform for deploying end-to-end AI models. The platform allows users to interact with robots using natural language commands, explore virtual environments, test robot models in realistic scenarios, and receive camera feeds for monitoring. LuckyRobots aims to train AI models on real-world simulations and respond to natural language inputs, offering a user-friendly and innovative approach to robotics development.
Welo Data
Welo Data is an AI tool that specializes in AI benchmarking, model assessment, and training high-quality datasets for AI models. The platform offers services such as supervised fine tuning, reinforcement learning with human feedback, data generation, expert evaluations, and data quality framework to support the development of world-class AI models. With over 27 years of experience, Welo Data combines language expertise and AI data to deliver exceptional training and performance evaluation solutions.
Together AI
Together AI is an AI Acceleration Cloud platform that offers fast inference, fine-tuning, and training services. It provides self-service NVIDIA GPUs, model deployment on custom hardware, AI chat app, code execution sandbox, and tools to find the right model for specific use cases. The platform also includes a model library with open-source models, documentation for developers, and resources for advancing open-source AI. Together AI enables users to leverage pre-trained models, fine-tune them, or build custom models from scratch, catering to various generative AI needs.
Sherpa.ai
Sherpa.ai is a SaaS platform that enables data collaborations without sharing data. It allows businesses to build and train models with sensitive data from different parties, without compromising privacy or regulatory compliance. Sherpa.ai's Federated Learning platform is used in various industries, including healthcare, financial services, and manufacturing, to improve AI models, accelerate research, and optimize operations.
PredictModel
PredictModel is an AI tool that specializes in creating custom Machine Learning models tailored to meet unique requirements. The platform offers a comprehensive three-step process, including generating synthetic data, training ML models, and deploying them to AWS. PredictModel helps businesses streamline processes, improve customer segmentation, enhance client interaction, and boost overall business performance. The tool maximizes accuracy through customized synthetic data generation and saves time and money by providing expert ML engineers. With a focus on automated lead prioritization, fraud detection, cost optimization, and planning, PredictModel aims to stay ahead of the curve in the ML industry.
Sherpa.ai
Sherpa.ai is a Federated Learning Platform that enables data collaborations without sharing data. It allows organizations to build and train models with sensitive data from various sources while preserving privacy and complying with regulations. The platform offers enterprise-grade privacy-compliant solutions for improving AI models and fostering collaborations in a secure manner. Sherpa.ai is trusted by global organizations to maximize the value of data and AI, improve results, and ensure regulatory compliance.

Teachable Machine
Teachable Machine is a web-based tool that makes it easy to create custom machine learning models, even if you don't have any coding experience. With Teachable Machine, you can train models to recognize images, sounds, and poses. Once you've trained a model, you can export it to use in your own projects.
Gretel.ai
Gretel.ai is a synthetic data platform purpose-built for AI applications. It allows users to generate artificial, synthetic datasets with the same characteristics as real data, enabling the improvement of AI models without compromising privacy. The platform offers APIs for generating anonymized and safe synthetic data, training generative AI models, and validating models with quality and privacy scores. Users can deploy Gretel for enterprise use cases and run it on various cloud platforms or in their own environment.
Labelbox
Labelbox is a data factory platform that empowers AI teams to manage data labeling, train models, and create better data with internet scale RLHF platform. It offers an all-in-one solution comprising tooling and services powered by a global community of domain experts. Labelbox operates a global data labeling infrastructure and operations for AI workloads, providing expert human network for data labeling in various domains. The platform also includes AI-assisted alignment for maximum efficiency, data curation, model training, and labeling services. Customers achieve breakthroughs with high-quality data through Labelbox.
micro1
micro1 is an AI recruitment engine designed to hire top global talent efficiently. It utilizes human data produced by subject matter experts to provide end-to-end post-training services. The platform offers a Zara AI recruiter agent to identify and hire the best talent on earth, catering to various industries such as tech startups, staffing agencies, and enterprises. With features like sourcing and vetting candidates, seamless onboarding, and high-quality data training, micro1 aims to streamline the recruitment process and save time and costs for businesses. The platform also provides resources for companies and talent, including case studies, cost savings calculators, and interview preparation tools.
DeepfakeVFX.com
DeepfakeVFX.com is an AI tool designed for the deepfake community, providing forums, guides, tutorials, and downloads for users interested in creating deepfake videos. The platform offers comprehensive resources for learning how to deepfake, including step-by-step tutorials and pretrained models. Users can engage in discussions, share knowledge, and access a variety of tools and settings to enhance their deepfake creations.
CrazyHorseAI
CrazyHorseAI is an AI tool that offers an API for users to enhance and customize the appearance and personality traits of an AI girl through features like changing clothes, hair, body, pose, and background. The tool provides functionalities such as natural language processing, emotional intelligence, and adaptive learning capabilities to create immersive and engaging experiences.
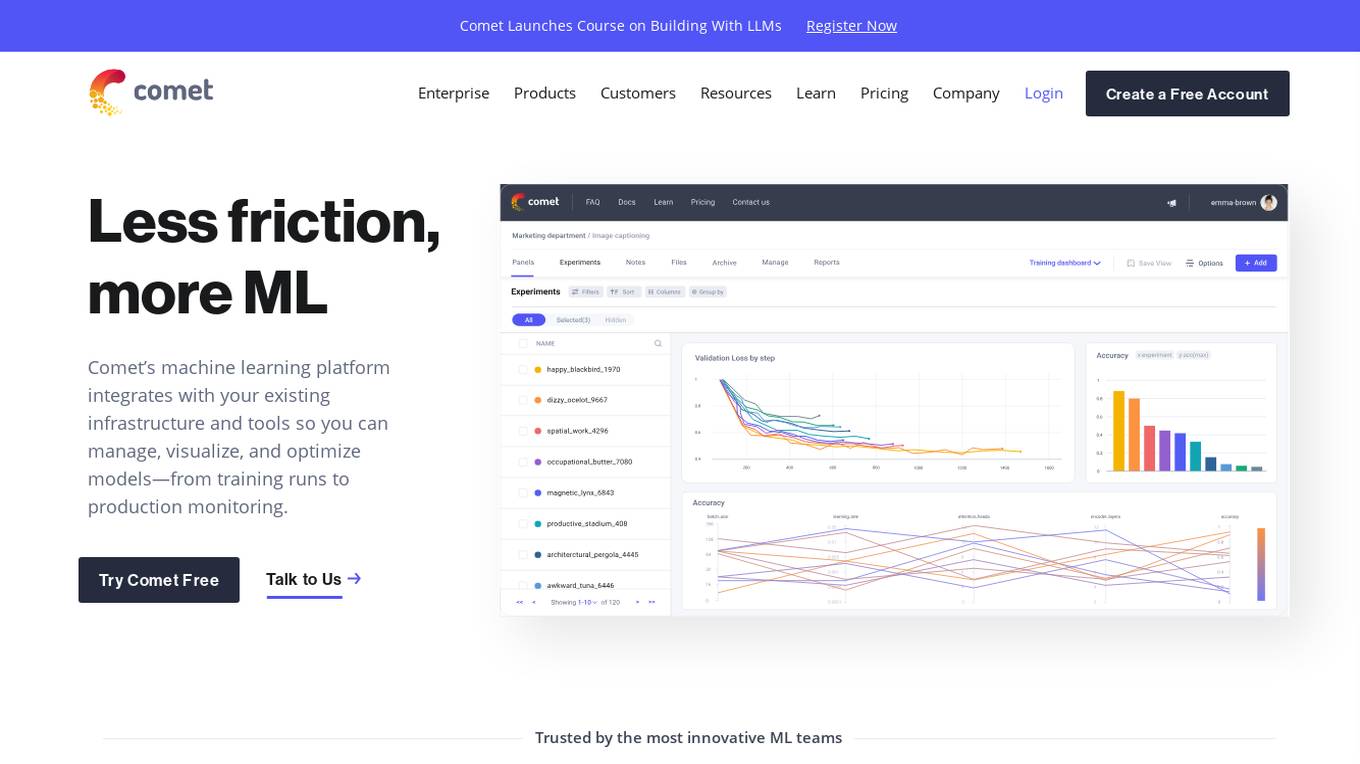
Comet ML
Comet ML is a machine learning platform that integrates with your existing infrastructure and tools so you can manage, visualize, and optimize models—from training runs to production monitoring.
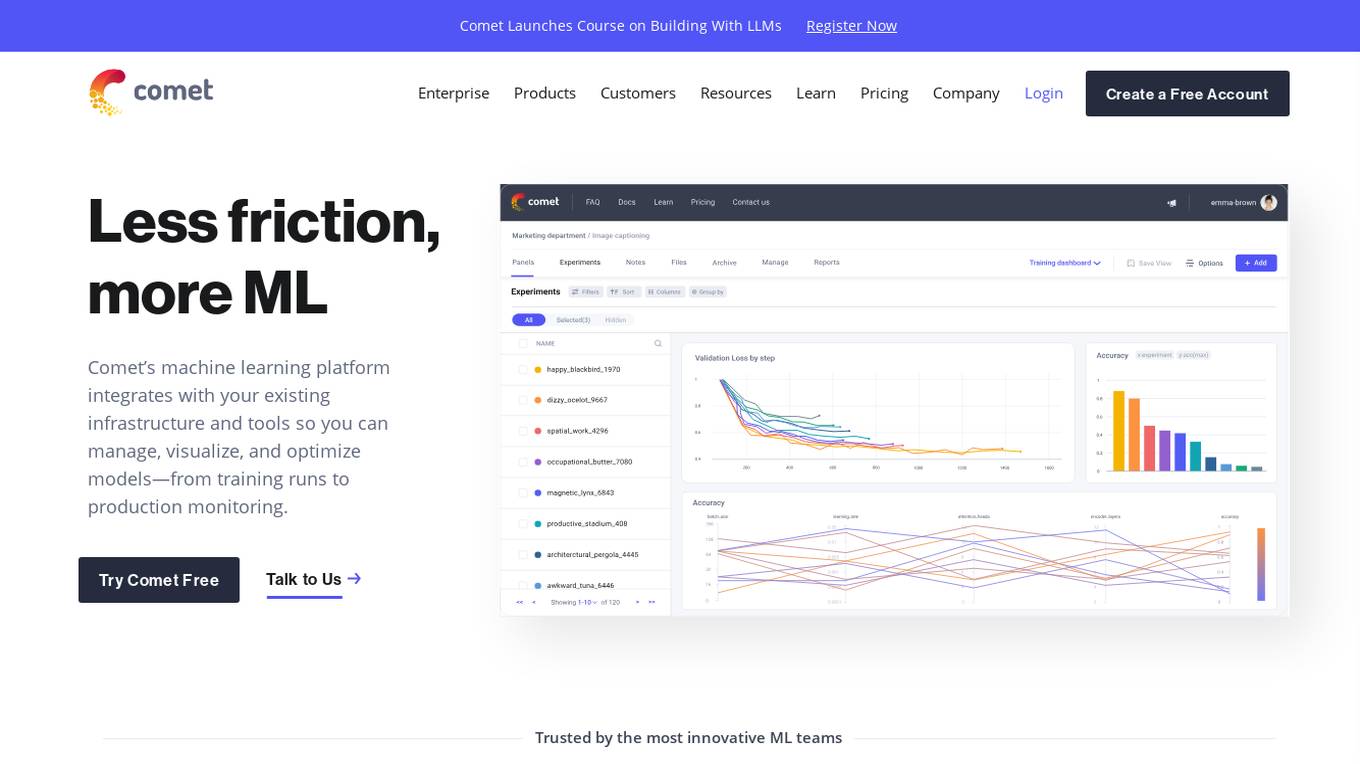
Comet ML
Comet ML is a machine learning platform that integrates with your existing infrastructure and tools so you can manage, visualize, and optimize models—from training runs to production monitoring.
ClearML
ClearML is an open-source, end-to-end platform for continuous machine learning (ML). It provides a unified platform for data management, experiment tracking, model training, deployment, and monitoring. ClearML is designed to make it easy for teams to collaborate on ML projects and to ensure that models are deployed and maintained in a reliable and scalable way.
Baseten
Baseten is a machine learning infrastructure that provides a unified platform for data scientists and engineers to build, train, and deploy machine learning models. It offers a range of features to simplify the ML lifecycle, including data preparation, model training, and deployment. Baseten also provides a marketplace of pre-built models and components that can be used to accelerate the development of ML applications.
52 - Open Source AI Tools

vllm
vLLM is a fast and easy-to-use library for LLM inference and serving. It is designed to be efficient, flexible, and easy to use. vLLM can be used to serve a variety of LLM models, including Hugging Face models. It supports a variety of decoding algorithms, including parallel sampling, beam search, and more. vLLM also supports tensor parallelism for distributed inference and streaming outputs. It is open-source and available on GitHub.

bce-qianfan-sdk
The Qianfan SDK provides best practices for large model toolchains, allowing AI workflows and AI-native applications to access the Qianfan large model platform elegantly and conveniently. The core capabilities of the SDK include three parts: large model reasoning, large model training, and general and extension: * `Large model reasoning`: Implements interface encapsulation for reasoning of Yuyan (ERNIE-Bot) series, open source large models, etc., supporting dialogue, completion, Embedding, etc. * `Large model training`: Based on platform capabilities, it supports end-to-end large model training process, including training data, fine-tuning/pre-training, and model services. * `General and extension`: General capabilities include common AI development tools such as Prompt/Debug/Client. The extension capability is based on the characteristics of Qianfan to adapt to common middleware frameworks.

dstack
Dstack is an open-source orchestration engine for running AI workloads in any cloud. It supports a wide range of cloud providers (such as AWS, GCP, Azure, Lambda, TensorDock, Vast.ai, CUDO, RunPod, etc.) as well as on-premises infrastructure. With Dstack, you can easily set up and manage dev environments, tasks, services, and pools for your AI workloads.

RVC_CLI
**RVC_CLI: Retrieval-based Voice Conversion Command Line Interface** This command-line interface (CLI) provides a comprehensive set of tools for voice conversion, enabling you to modify the pitch, timbre, and other characteristics of audio recordings. It leverages advanced machine learning models to achieve realistic and high-quality voice conversions. **Key Features:** * **Inference:** Convert the pitch and timbre of audio in real-time or process audio files in batch mode. * **TTS Inference:** Synthesize speech from text using a variety of voices and apply voice conversion techniques. * **Training:** Train custom voice conversion models to meet specific requirements. * **Model Management:** Extract, blend, and analyze models to fine-tune and optimize performance. * **Audio Analysis:** Inspect audio files to gain insights into their characteristics. * **API:** Integrate the CLI's functionality into your own applications or workflows. **Applications:** The RVC_CLI finds applications in various domains, including: * **Music Production:** Create unique vocal effects, harmonies, and backing vocals. * **Voiceovers:** Generate voiceovers with different accents, emotions, and styles. * **Audio Editing:** Enhance or modify audio recordings for podcasts, audiobooks, and other content. * **Research and Development:** Explore and advance the field of voice conversion technology. **For Jobs:** * Audio Engineer * Music Producer * Voiceover Artist * Audio Editor * Machine Learning Engineer **AI Keywords:** * Voice Conversion * Pitch Shifting * Timbre Modification * Machine Learning * Audio Processing **For Tasks:** * Convert Pitch * Change Timbre * Synthesize Speech * Train Model * Analyze Audio

llm-finetuning
llm-finetuning is a repository that provides a serverless twist to the popular axolotl fine-tuning library using Modal's serverless infrastructure. It allows users to quickly fine-tune any LLM model with state-of-the-art optimizations like Deepspeed ZeRO, LoRA adapters, Flash attention, and Gradient checkpointing. The repository simplifies the fine-tuning process by not exposing all CLI arguments, instead allowing users to specify options in a config file. It supports efficient training and scaling across multiple GPUs, making it suitable for production-ready fine-tuning jobs.

zeta
Zeta is a tool designed to build state-of-the-art AI models faster by providing modular, high-performance, and scalable building blocks. It addresses the common issues faced while working with neural nets, such as chaotic codebases, lack of modularity, and low performance modules. Zeta emphasizes usability, modularity, and performance, and is currently used in hundreds of models across various GitHub repositories. It enables users to prototype, train, optimize, and deploy the latest SOTA neural nets into production. The tool offers various modules like FlashAttention, SwiGLUStacked, RelativePositionBias, FeedForward, BitLinear, PalmE, Unet, VisionEmbeddings, niva, FusedDenseGELUDense, FusedDropoutLayerNorm, MambaBlock, Film, hyper_optimize, DPO, and ZetaCloud for different tasks in AI model development.

llm_qlora
LLM_QLoRA is a repository for fine-tuning Large Language Models (LLMs) using QLoRA methodology. It provides scripts for training LLMs on custom datasets, pushing models to HuggingFace Hub, and performing inference. Additionally, it includes models trained on HuggingFace Hub, a blog post detailing the QLoRA fine-tuning process, and instructions for converting and quantizing models. The repository also addresses troubleshooting issues related to Python versions and dependencies.

LLMBox
LLMBox is a comprehensive library designed for implementing Large Language Models (LLMs) with a focus on a unified training pipeline and comprehensive model evaluation. It serves as a one-stop solution for training and utilizing LLMs, offering flexibility and efficiency in both training and utilization stages. The library supports diverse training strategies, comprehensive datasets, tokenizer vocabulary merging, data construction strategies, parameter efficient fine-tuning, and efficient training methods. For utilization, LLMBox provides comprehensive evaluation on various datasets, in-context learning strategies, chain-of-thought evaluation, evaluation methods, prefix caching for faster inference, support for specific LLM models like vLLM and Flash Attention, and quantization options. The tool is suitable for researchers and developers working with LLMs for natural language processing tasks.
AlphaFold3
AlphaFold3 is an implementation of the Alpha Fold 3 model in PyTorch for accurate structure prediction of biomolecular interactions. It includes modules for genetic diffusion and full model examples for forward pass computations. The tool allows users to generate random pair and single representations, operate on atomic coordinates, and perform structure predictions based on input tensors. The implementation also provides functionalities for training and evaluating the model.
fms-fsdp
The 'fms-fsdp' repository is a companion to the Foundation Model Stack, providing a (pre)training example to efficiently train FMS models, specifically Llama2, using native PyTorch features like FSDP for training and SDPA implementation of Flash attention v2. It focuses on leveraging FSDP for training efficiently, not as an end-to-end framework. The repo benchmarks training throughput on different GPUs, shares strategies, and provides installation and training instructions. It trained a model on IBM curated data achieving high efficiency and performance metrics.

kan-gpt
The KAN-GPT repository is a PyTorch implementation of Generative Pre-trained Transformers (GPTs) using Kolmogorov-Arnold Networks (KANs) for language modeling. It provides a model for generating text based on prompts, with a focus on improving performance compared to traditional MLP-GPT models. The repository includes scripts for training the model, downloading datasets, and evaluating model performance. Development tasks include integrating with other libraries, testing, and documentation.
LESS
This repository contains the code for the paper 'LESS: Selecting Influential Data for Targeted Instruction Tuning'. The work proposes a data selection method to choose influential data for inducing a target capability. It includes steps for warmup training, building the gradient datastore, selecting data for a task, and training with the selected data. The repository provides tools for data preparation, data selection pipeline, and evaluation of the model trained on the selected data.
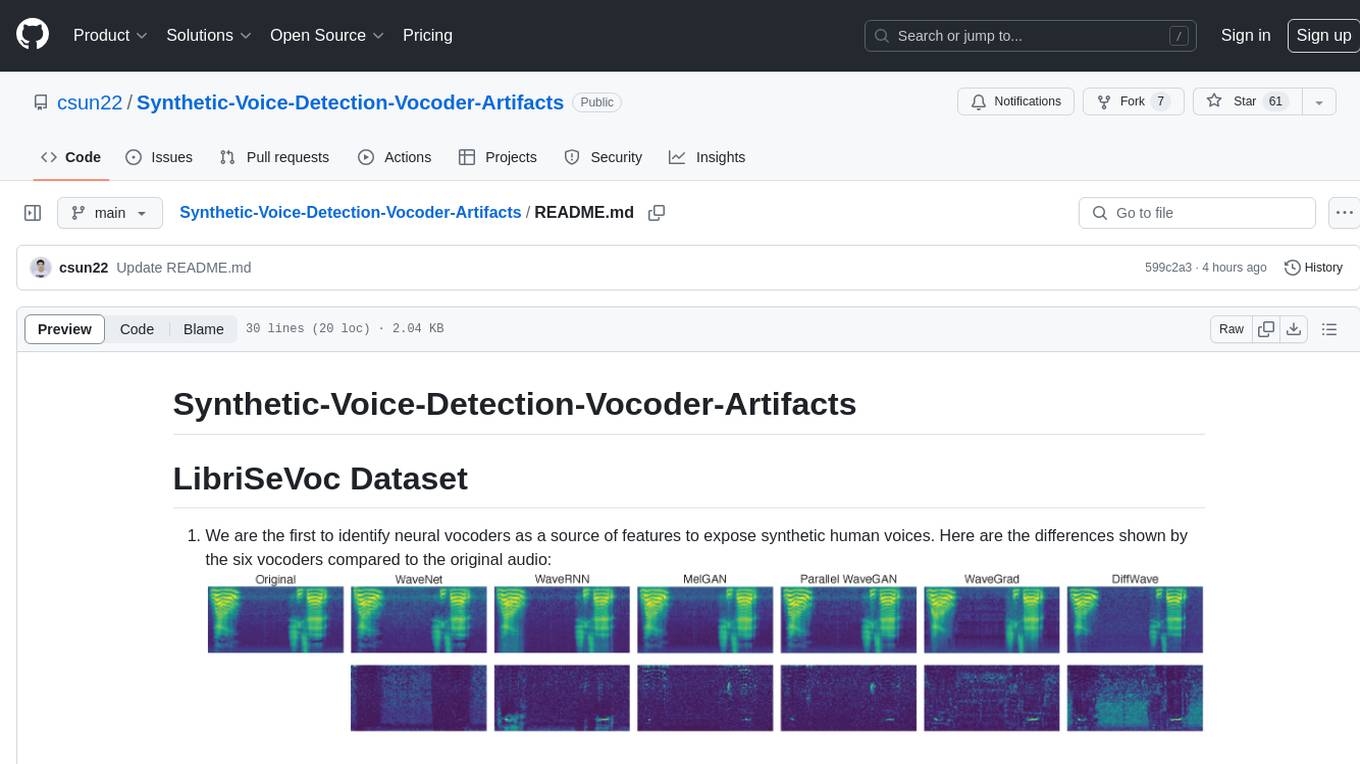
Synthetic-Voice-Detection-Vocoder-Artifacts
The Synthetic-Voice-Detection-Vocoder-Artifacts repository provides the LibriSeVoc dataset containing self-vocoding samples created with six state-of-the-art vocoders to expose and exploit vocoder artifacts. It also introduces a new approach for detecting synthetic human voices by identifying signal artifacts left by neural vocoders and enhancing the RawNet2 baseline. The repository includes a paper and dataset for further reference and offers instructions for training the model and testing it in the wild.
lightning-lab
Lightning Lab is a public template for artificial intelligence and machine learning research projects using Lightning AI's PyTorch Lightning. It provides a structured project layout with modules for command line interface, experiment utilities, Lightning Module and Trainer, data acquisition and preprocessing, model serving APIs, project configurations, training checkpoints, technical documentation, logs, notebooks for data analysis, requirements management, testing, and packaging. The template simplifies the setup of deep learning projects and offers extras for different domains like vision, text, audio, reinforcement learning, and forecasting.
ShapeLLM
ShapeLLM is the first 3D Multimodal Large Language Model designed for embodied interaction, exploring a universal 3D object understanding with 3D point clouds and languages. It supports single-view colored point cloud input and introduces a robust 3D QA benchmark, 3D MM-Vet, encompassing various variants. The model extends the powerful point encoder architecture, ReCon++, achieving state-of-the-art performance across a range of representation learning tasks. ShapeLLM can be used for tasks such as training, zero-shot understanding, visual grounding, few-shot learning, and zero-shot learning on 3D MM-Vet.

hi-ml
The Microsoft Health Intelligence Machine Learning Toolbox is a repository that provides low-level and high-level building blocks for Machine Learning / AI researchers and practitioners. It simplifies and streamlines work on deep learning models for healthcare and life sciences by offering tested components such as data loaders, pre-processing tools, deep learning models, and cloud integration utilities. The repository includes two Python packages, 'hi-ml-azure' for helper functions in AzureML, 'hi-ml' for ML components, and 'hi-ml-cpath' for models and workflows related to histopathology images.
SimpleAICV_pytorch_training_examples
SimpleAICV_pytorch_training_examples is a repository that provides simple training and testing examples for various computer vision tasks such as image classification, object detection, semantic segmentation, instance segmentation, knowledge distillation, contrastive learning, masked image modeling, OCR text detection, OCR text recognition, human matting, salient object detection, interactive segmentation, image inpainting, and diffusion model tasks. The repository includes support for multiple datasets and networks, along with instructions on how to prepare datasets, train and test models, and use gradio demos. It also offers pretrained models and experiment records for download from huggingface or Baidu-Netdisk. The repository requires specific environments and package installations to run effectively.
LLM-from-scratch
This repository contains notes on re-implementing some LLM models from scratch. It includes steps to pre-train a super mini LLaMA 3 model, implement LoRA from scratch using PyTorch, and work on implementing the 'generate' method.
Train-llm-from-scratch
Train-llm-from-scratch is a repository that guides users through training a Large Language Model (LLM) from scratch. The model size can be adjusted based on available computing power. The repository utilizes deepspeed for distributed training and includes detailed explanations of the code and key steps at each stage to facilitate learning. Users can train their own tokenizer or use pre-trained tokenizers like ChatGLM2-6B. The repository provides information on preparing pre-training data, processing training data, and recommended SFT data for fine-tuning. It also references other projects and books related to LLM training.

Steel-LLM
Steel-LLM is a project to pre-train a large Chinese language model from scratch using over 1T of data to achieve a parameter size of around 1B, similar to TinyLlama. The project aims to share the entire process including data collection, data processing, pre-training framework selection, model design, and open-source all the code. The goal is to enable reproducibility of the work even with limited resources. The name 'Steel' is inspired by a band '万能青年旅店' and signifies the desire to create a strong model despite limited conditions. The project involves continuous data collection of various cultural elements, trivia, lyrics, niche literature, and personal secrets to train the LLM. The ultimate aim is to fill the model with diverse data and leave room for individual input, fostering collaboration among users.

RVC_CLI
RVC_CLI is a command line interface tool for retrieval-based voice conversion. It provides functionalities for installation, getting started, inference, training, UVR, additional features, and API integration. Users can perform tasks like single inference, batch inference, TTS inference, preprocess dataset, extract features, start training, generate index file, model extract, model information, model blender, launch TensorBoard, download models, audio analyzer, and prerequisites download. The tool is built on various projects like ContentVec, HIFIGAN, audio-slicer, python-audio-separator, RMVPE, FCPE, VITS, So-Vits-SVC, Harmonify, and others.

lerobot
LeRobot is a state-of-the-art AI library for real-world robotics in PyTorch. It aims to provide models, datasets, and tools to lower the barrier to entry to robotics, focusing on imitation learning and reinforcement learning. LeRobot offers pretrained models, datasets with human-collected demonstrations, and simulation environments. It plans to support real-world robotics on affordable and capable robots. The library hosts pretrained models and datasets on the Hugging Face community page.
End-to-End-LLM
The End-to-End LLM Bootcamp is a comprehensive training program that covers the entire process of developing and deploying large language models. Participants learn to preprocess datasets, train models, optimize performance using NVIDIA technologies, understand guardrail prompts, and deploy AI pipelines using Triton Inference Server. The bootcamp includes labs, challenges, and practical applications, with a total duration of approximately 7.5 hours. It is designed for individuals interested in working with advanced language models and AI technologies.
CALF
CALF (LLaTA) is a cross-modal fine-tuning framework that bridges the distribution discrepancy between temporal data and the textual nature of LLMs. It introduces three cross-modal fine-tuning techniques: Cross-Modal Match Module, Feature Regularization Loss, and Output Consistency Loss. The framework aligns time series and textual inputs, ensures effective weight updates, and maintains consistent semantic context for time series data. CALF provides scripts for long-term and short-term forecasting, requires Python 3.9, and utilizes word token embeddings for model training.
ST-LLM
ST-LLM is a temporal-sensitive video large language model that incorporates joint spatial-temporal modeling, dynamic masking strategy, and global-local input module for effective video understanding. It has achieved state-of-the-art results on various video benchmarks. The repository provides code and weights for the model, along with demo scripts for easy usage. Users can train, validate, and use the model for tasks like video description, action identification, and reasoning.
LongRecipe
LongRecipe is a tool designed for efficient long context generalization in large language models. It provides a recipe for extending the context window of language models while maintaining their original capabilities. The tool includes data preprocessing steps, model training stages, and a process for merging fine-tuned models to enhance foundational capabilities. Users can follow the provided commands and scripts to preprocess data, train models in multiple stages, and merge models effectively.
maxtext
MaxText is a high performance, highly scalable, open-source Large Language Model (LLM) written in pure Python/Jax targeting Google Cloud TPUs and GPUs for training and inference. It aims to be a launching off point for ambitious LLM projects in research and production, supporting TPUs and GPUs, models like Llama2, Mistral, and Gemma. MaxText provides specific instructions for getting started, runtime performance results, comparison to alternatives, and features like stack trace collection, ahead of time compilation for TPUs and GPUs, and automatic upload of logs to Vertex Tensorboard.
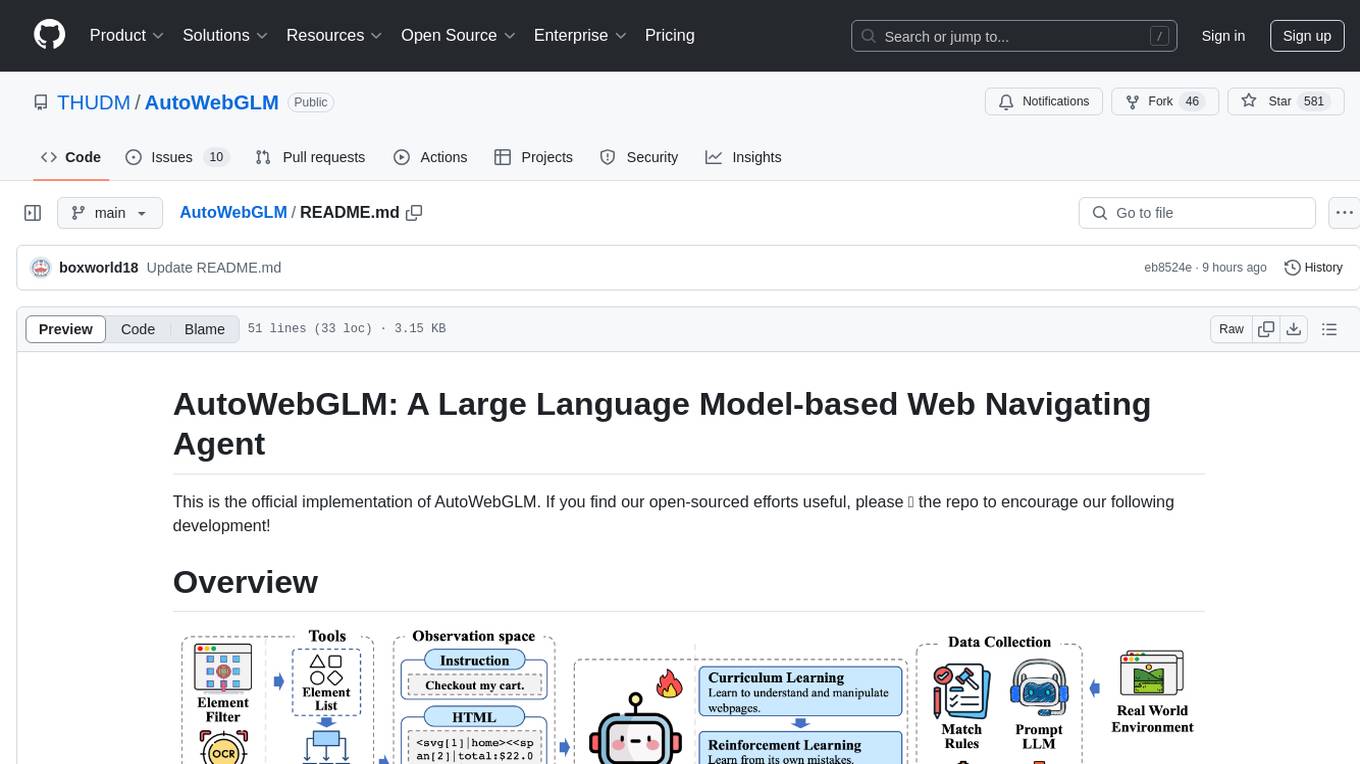
AutoWebGLM
AutoWebGLM is a project focused on developing a language model-driven automated web navigation agent. It extends the capabilities of the ChatGLM3-6B model to navigate the web more efficiently and address real-world browsing challenges. The project includes features such as an HTML simplification algorithm, hybrid human-AI training, reinforcement learning, rejection sampling, and a bilingual web navigation benchmark for testing AI web navigation agents.

NineRec
NineRec is a benchmark dataset suite for evaluating transferable recommendation models. It provides datasets for pre-training and transfer learning in recommender systems, focusing on multimodal and foundation model tasks. The dataset includes user-item interactions, item texts in multiple languages, item URLs, and raw images. Researchers can use NineRec to develop more effective and efficient methods for pre-training recommendation models beyond end-to-end training. The dataset is accompanied by code for dataset preparation, training, and testing in PyTorch environment.

LotteryAi
LotteryAi is a lottery prediction artificial intelligence that uses machine learning to predict the winning numbers of any lottery game. It requires Python 3.x and specific libraries like numpy, tensorflow, keras, and art for installation. Users need a data file with past lottery results in a comma-separated format to train the model and generate predictions. The tool comes with no guarantee of accuracy in predicting lottery numbers and is meant for educational and research purposes only.
WeClone
WeClone is a tool that fine-tunes large language models using WeChat chat records. It utilizes approximately 20,000 integrated and effective data points, resulting in somewhat satisfactory outcomes that are occasionally humorous. The tool's effectiveness largely depends on the quantity and quality of the chat data provided. It requires a minimum of 16GB of GPU memory for training using the default chatglm3-6b model with LoRA method. Users can also opt for other models and methods supported by LLAMA Factory, which consume less memory. The tool has specific hardware and software requirements, including Python, Torch, Transformers, Datasets, Accelerate, and other optional packages like CUDA and Deepspeed. The tool facilitates environment setup, data preparation, data preprocessing, model downloading, parameter configuration, model fine-tuning, and inference through a browser demo or API service. Additionally, it offers the ability to deploy a WeChat chatbot, although users should be cautious due to the risk of account suspension by WeChat.
llm-deploy
LLM-Deploy focuses on the theory and practice of model/LLM reasoning and deployment, aiming to be your partner in mastering the art of LLM reasoning and deployment. Whether you are a newcomer to this field or a senior professional seeking to deepen your skills, you can find the key path to successfully deploy large language models here. The project covers reasoning and deployment theories, model and service optimization practices, and outputs from experienced engineers. It serves as a valuable resource for algorithm engineers and individuals interested in reasoning deployment.
zenu
ZeNu is a high-performance deep learning framework implemented in pure Rust, featuring a pure Rust implementation for safety and performance, GPU performance comparable to PyTorch with CUDA support, a simple and intuitive API, and a modular design for easy extension. It supports various layers like Linear, Convolution 2D, LSTM, and optimizers such as SGD and Adam. ZeNu also provides device support for CPU and CUDA (NVIDIA GPU) with CUDA 12.3 and cuDNN 9. The project structure includes main library, automatic differentiation engine, neural network layers, matrix operations, optimization algorithms, CUDA implementation, and other support crates. Users can find detailed implementations like MNIST classification, CIFAR10 classification, and ResNet implementation in the examples directory. Contributions to ZeNu are welcome under the MIT License.
lingua
Meta Lingua is a minimal and fast LLM training and inference library designed for research. It uses easy-to-modify PyTorch components to experiment with new architectures, losses, and data. The codebase enables end-to-end training, inference, and evaluation, providing tools for speed and stability analysis. The repository contains essential components in the 'lingua' folder and scripts that combine these components in the 'apps' folder. Researchers can modify the provided templates to suit their experiments easily. Meta Lingua aims to lower the barrier to entry for LLM research by offering a lightweight and focused codebase.
llm-dev
The 'llm-dev' repository contains source code and resources for the book 'Practical Projects of Large Models: Multi-Domain Intelligent Application Development'. It covers topics such as language model basics, application architecture, working modes, environment setup, model installation, fine-tuning, quantization, multi-modal model applications, chat applications, programming large model applications, VS Code plugin development, enhanced generation applications, translation applications, intelligent agent applications, speech model applications, digital human applications, model training applications, and AI town applications.

labo
LABO is a time series forecasting and analysis framework that integrates pre-trained and fine-tuned LLMs with multi-domain agent-based systems. It allows users to create and tune agents easily for various scenarios, such as stock market trend prediction and web public opinion analysis. LABO requires a specific runtime environment setup, including system requirements, Python environment, dependency installations, and configurations. Users can fine-tune their own models using LABO's Low-Rank Adaptation (LoRA) for computational efficiency and continuous model updates. Additionally, LABO provides a Python library for building model training pipelines and customizing agents for specific tasks.
llms-from-scratch-rs
This project provides Rust code that follows the text 'Build An LLM From Scratch' by Sebastian Raschka. It translates PyTorch code into Rust using the Candle crate, aiming to build a GPT-style LLM. Users can clone the repo, run examples/exercises, and access the same datasets as in the book. The project includes chapters on understanding large language models, working with text data, coding attention mechanisms, implementing a GPT model, pretraining unlabeled data, fine-tuning for classification, and fine-tuning to follow instructions.

VLM-R1
VLM-R1 is a stable and generalizable R1-style Large Vision-Language Model proposed for Referring Expression Comprehension (REC) task. It compares R1 and SFT approaches, showing R1 model's steady improvement on out-of-domain test data. The project includes setup instructions, training steps for GRPO and SFT models, support for user data loading, and evaluation process. Acknowledgements to various open-source projects and resources are mentioned. The project aims to provide a reliable and versatile solution for vision-language tasks.
Fast-LLM
Fast-LLM is an open-source library designed for training large language models with exceptional speed, scalability, and flexibility. Built on PyTorch and Triton, it offers optimized kernel efficiency, reduced overheads, and memory usage, making it suitable for training models of all sizes. The library supports distributed training across multiple GPUs and nodes, offers flexibility in model architectures, and is easy to use with pre-built Docker images and simple configuration. Fast-LLM is licensed under Apache 2.0, developed transparently on GitHub, and encourages contributions and collaboration from the community.
Kolo
Kolo is a lightweight tool for fast and efficient data generation, fine-tuning, and testing of Large Language Models (LLMs) on your local machine. It simplifies the fine-tuning and data generation process, runs locally without the need for cloud-based services, and supports popular LLM toolkits. Kolo is built using tools like Unsloth, Torchtune, Llama.cpp, Ollama, Docker, and Open WebUI. It requires Windows 10 OS or higher, Nvidia GPU with CUDA 12.1 capability, and 8GB+ VRAM, and 16GB+ system RAM. Users can join the Discord group for issues or feedback. The tool provides easy setup, training data generation, and integration with major LLM frameworks.
Open-R1
Open-R1 is an open-source library for training a hyper-personalized DeepSeek-R1-like model using minimal compute resources. It provides the flexibility to use your own data and aims to streamline the model training process. The project is licensed under Apache 2.0 and acknowledges contributions from various open-source contributors, including Hugging Face and Vicuna.
DQN_WUKONG
DQN_WUKONG is a repository containing code for training an AI model to play a specific game. It provides instructions for setting up the environment using Conda or venv, as well as details on key files such as window.py, judge.py, restart.py, and main.py. The repository includes scripts for training the model and specific configurations for gameplay. It also references a BossRush V3 mod for repetitive training and acknowledges code contributions from other repositories like DQN_play_sekiro and pygta5. For a more general AI framework, users can refer to the GameAISDK repository.
fish-identification
Fishial.ai is a project focused on training and validating scripts for fish segmentation and classification models. It includes various scripts for automatic training with different loss functions, dataset manipulation, and model setup using Detectron2 API. The project also provides tools for converting classification models to TorchScript format and creating training datasets. The models available include MaskRCNN for fish segmentation and various versions of ResNet18 for fish classification with different class counts and features. The project aims to facilitate fish identification and analysis through machine learning techniques.
Search-R1
Search-R1 is a tool that trains large language models (LLMs) to reason and call a search engine using reinforcement learning. It is a reproduction of DeepSeek-R1 methods for training reasoning and searching interleaved LLMs, built upon veRL. Through rule-based outcome reward, the base LLM develops reasoning and search engine calling abilities independently. Users can train LLMs on their own datasets and search engines, with preliminary results showing improved performance in search engine calling and reasoning tasks.
NeuroSync_Player
NeuroSync Player is a real-time AI endpoint server that combines text-to-speech and NeuroSync generations. It includes code for various AI endpoints such as speech-to-text, text-to-speech, embedding, and vision. The tool allows users to connect their llm to Twitch and YouTube, enabling the llm-powered metahuman to respond to viewers in real-time. Additionally, it offers features like push-to-talk, face animation integration, and support for blendshapes generated from audio inputs for Unreal Engine 5. Users can train and fine-tune their own models using NeuroSync Trainer Lite, with simplified loss functions and mixed precision for faster training. The tool also supports data augmentation to help with fine detail reproduction.
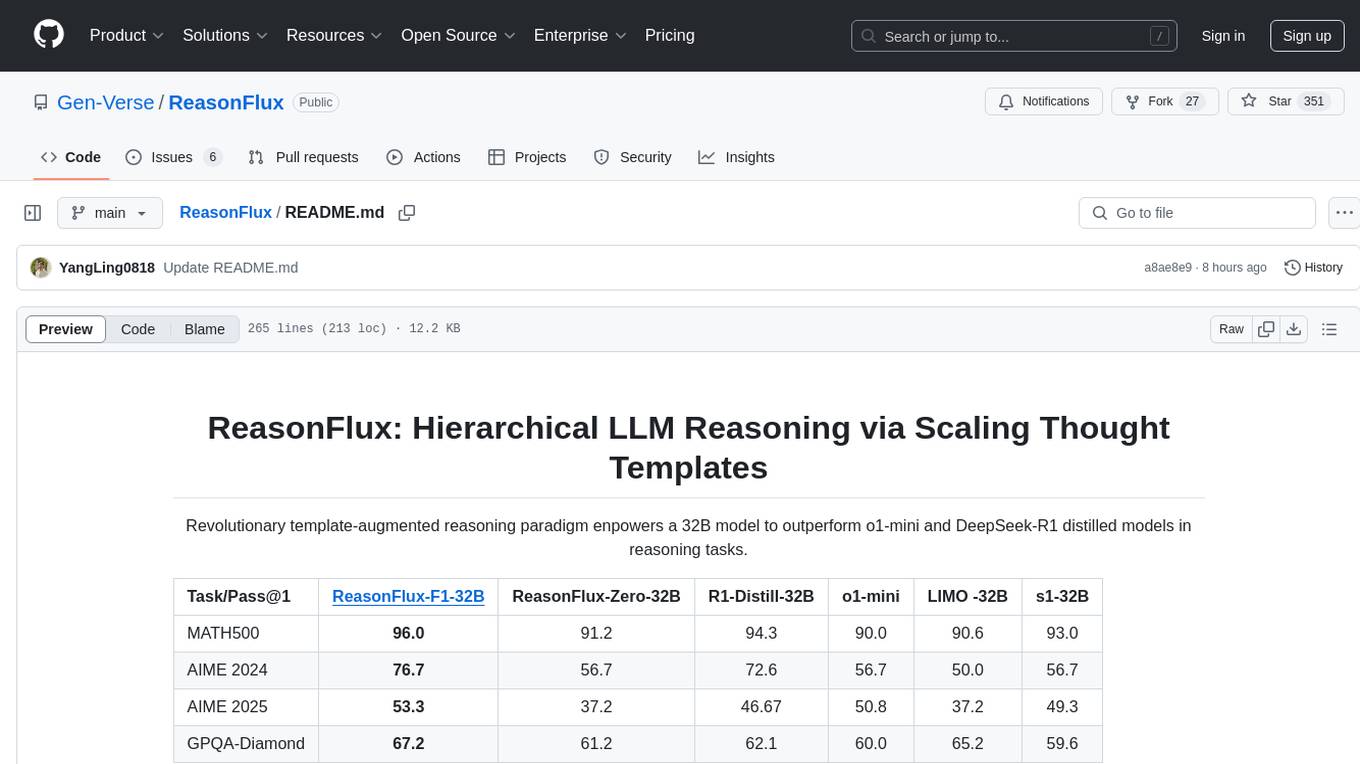
ReasonFlux
ReasonFlux is a revolutionary template-augmented reasoning paradigm that empowers a 32B model to outperform other models in reasoning tasks. The repository provides official resources for the paper 'ReasonFlux: Hierarchical LLM Reasoning via Scaling Thought Templates', including the latest released model ReasonFlux-F1-32B. It includes updates, dataset links, model zoo, getting started guide, training instructions, evaluation details, inference examples, performance comparisons, reasoning examples, preliminary work references, and citation information.
ArcticTraining
ArcticTraining is a framework designed to simplify and accelerate the post-training process for large language models (LLMs). It offers modular trainer designs, simplified code structures, and integrated pipelines for creating and cleaning synthetic data, enabling users to enhance LLM capabilities like code generation and complex reasoning with greater efficiency and flexibility.
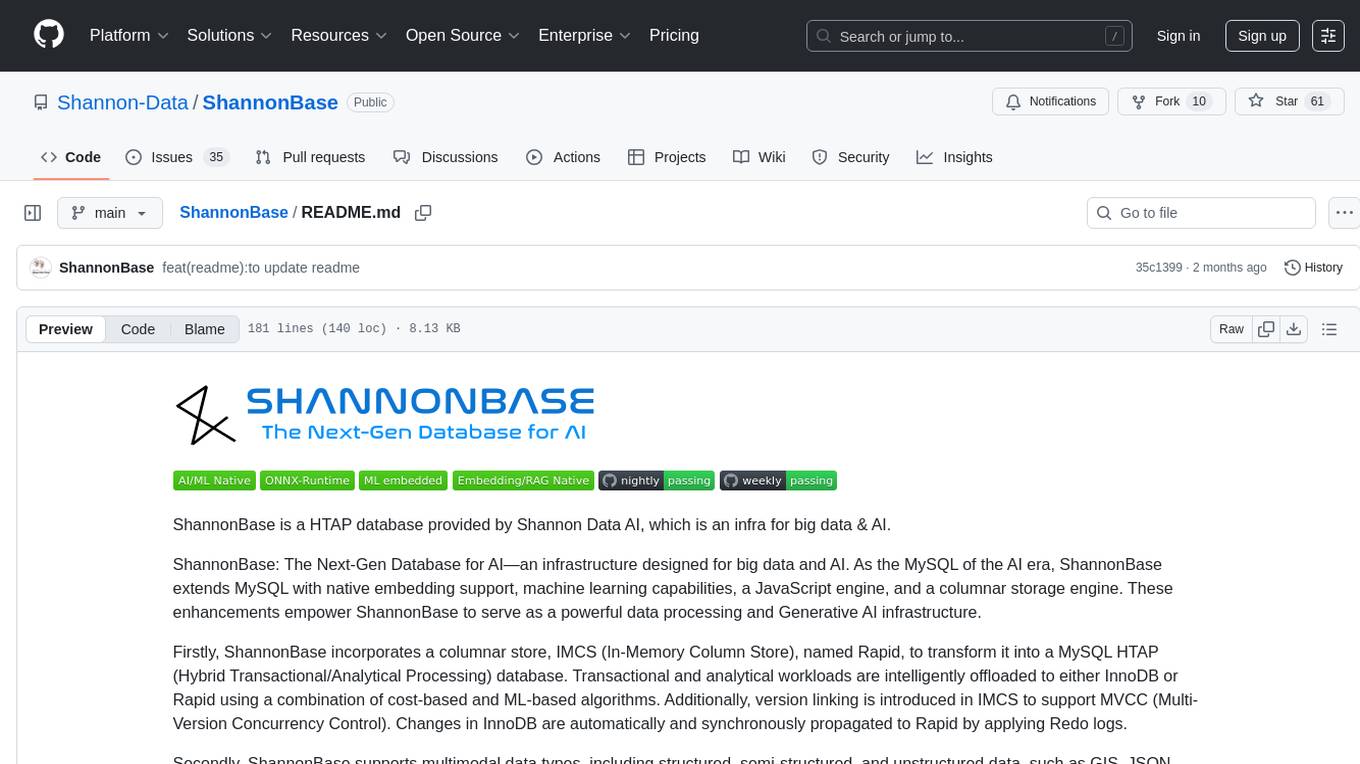
ShannonBase
ShannonBase is a HTAP database provided by Shannon Data AI, designed for big data and AI. It extends MySQL with native embedding support, machine learning capabilities, a JavaScript engine, and a columnar storage engine. ShannonBase supports multimodal data types and natively integrates LightGBM for training and prediction. It leverages embedding algorithms and vector data type for ML/RAG tasks, providing Zero Data Movement, Native Performance Optimization, and Seamless SQL Integration. The tool includes a lightweight JavaScript engine for writing stored procedures in SQL or JavaScript.
phosphobot
Phosphobot is a software tool designed to control robots, record data, train and use VLA (vision language action) models. It allows users to control robots using various input methods, train action models with ease, and is compatible with a range of robots and cameras. The tool runs on multiple operating systems and provides a user-friendly API for developers. Users can purchase a starter pack or use supported robots, record datasets, train action models, and control robots using the webapp or Python package. Phosphobot is open source, allowing users to extend its functionality with their own robots and cameras.

AirGym
AirGym is an open source Python quadrotor simulator based on IsaacGym, providing a high-fidelity dynamics and Deep Reinforcement Learning (DRL) framework for quadrotor robot learning research. It offers a lightweight and customizable platform with strict alignment with PX4 logic, multiple control modes, and Sim-to-Real toolkits. Users can perform tasks such as Hovering, Balloon, Tracking, Avoid, and Planning, with the ability to create customized environments and tasks. The tool also supports training from scratch, visual encoding approaches, playing and testing of trained models, and customization of new tasks and assets.

DelhiLM
DelhiLM is a natural language processing tool for building and training language models. It provides a user-friendly interface for text processing tasks such as tokenization, lemmatization, and language model training. With DelhiLM, users can easily preprocess text data and train custom language models for various NLP applications. The tool supports different languages and allows for fine-tuning pre-trained models to suit specific needs. DelhiLM is designed to be flexible, efficient, and easy to use for both beginners and experienced NLP practitioners.
bumblecore
BumbleCore is a hands-on large language model training framework that allows complete control over every training detail. It provides manual training loop, customizable model architecture, and support for mainstream open-source models. The framework follows core principles of transparency, flexibility, and efficiency. BumbleCore is suitable for deep learning researchers, algorithm engineers, learners, and enterprise teams looking for customization and control over model training processes.
20 - OpenAI Gpts



Instructor GCP ML
Formador para la certificación de ML Engineer en GCP, con respuestas y explicaciones detalladas.


ChatXGB
GPT chatbot that helps you with technical questions related to XGBoost algorithm and library

HuggingFace Helper
A witty yet succinct guide for HuggingFace, offering technical assistance on using the platform - based on their Learning Hub

TensorFlow Oracle
I'm an expert in TensorFlow, providing detailed, accurate guidance for all skill levels.
TonyAIDeveloperResume
Chat with my resume to see if I am a good fit for your AI related job.