
RVC_CLI
RVC CLI enables seamless interaction with Retrieval-based Voice Conversion through commands or HTTP requests.
Stars: 88

RVC_CLI is a command line interface tool for retrieval-based voice conversion. It provides functionalities for installation, getting started, inference, training, UVR, additional features, and API integration. Users can perform tasks like single inference, batch inference, TTS inference, preprocess dataset, extract features, start training, generate index file, model extract, model information, model blender, launch TensorBoard, download models, audio analyzer, and prerequisites download. The tool is built on various projects like ContentVec, HIFIGAN, audio-slicer, python-audio-separator, RMVPE, FCPE, VITS, So-Vits-SVC, Harmonify, and others.
README:
Ensure that you have the necessary Python packages installed by following these steps (Python 3.9 is recommended):
Execute the install.bat file to activate a Conda environment. Afterward, launch the application using env/python.exe rvc.py instead of the conventional python rvc.py command.
chmod +x install.sh
./install.shDownload the necessary models and executables by running the following command:
python rvc.py prerequisitesMore information about the prerequisites command here
For detailed information and command-line options, refer to the help command:
python rvc.py -hThis command provides a clear overview of the available modes and their corresponding parameters, facilitating effective utilization of the RVC CLI.
python rvc.py infer --f0up_key "f0up_key" --filter_radius "filter_radius" --index_rate "index_rate" --hop_length "hop_length" --rms_mix_rate "rms_mix_rate" --protect "protect" --f0autotune "f0autotune" --f0method "f0method" --input_path "input_path" --output_path "output_path" --pth_path "pth_path" --index_path "index_path" --split_audio "split_audio" --clean_audio "clean_audio" --clean_strength "clean_strength" --export_format "export_format"| Parameter Name | Required | Default | Valid Options | Description |
|---|---|---|---|---|
f0up_key |
No | 0 | -24 to +24 | Set the pitch of the audio, the higher the value, thehigher the pitch. |
filter_radius |
No | 3 | 0 to 10 | If the number is greater than or equal to three, employing median filtering on the collected tone results has the potential to decrease respiration. |
index_rate |
No | 0.3 | 0.0 to 1.0 | Influence exerted by the index file; a higher value corresponds to greater influence. However, opting for lower values can help mitigate artifacts present in the audio. |
hop_length |
No | 128 | 1 to 512 | Denotes the duration it takes for the system to transition to a significant pitch change. Smaller hop lengths require more time for inference but tend to yield higher pitch accuracy. |
rms_mix_rate |
No | 1 | 0 to 1 | Substitute or blend with the volume envelope of the output. The closer the ratio is to 1, the more the output envelope is employed. |
protect |
No | 0.33 | 0 to 0.5 | Safeguard distinct consonants and breathing sounds to prevent electro-acoustic tearing and other artifacts. Pulling the parameter to its maximum value of 0.5 offers comprehensive protection. However, reducing this value might decrease the extent of protection while potentially mitigating the indexing effect. |
f0autotune |
No | False | True or False | Apply a soft autotune to your inferences, recommended for singing conversions. |
f0method |
No | rmvpe | pm, harvest, dio, crepe, crepe-tiny, rmvpe, fcpe, hybrid[crepe+rmvpe], hybrid[crepe+fcpe], hybrid[rmvpe+fcpe], hybrid[crepe+rmvpe+fcpe] | Pitch extraction algorithm to use for the audio conversion. The default algorithm is rmvpe, which is recommended for most cases. |
input_path |
Yes | None | Full path to the input audio file | Full path to the input audio file |
output_path |
Yes | None | Full path to the output audio file | Full path to the output audio file |
pth_path |
Yes | None | Full path to the pth file | Full path to the pth file |
index_path |
Yes | None | Full index file path | Full index file path |
split_audio |
No | False | True or False | Split the audio into chunks for inference to obtain better results in some cases. |
clean_audio |
No | False | True or False | Clean your audio output using noise detection algorithms, recommended for speaking audios. |
clean_strength |
No | 0.7 | 0.0 to 1.0 | Set the clean-up level to the audio you want, the more you increase it the more it will clean up, but it is possible that the audio will be more compressed. |
export_format |
No | WAV | WAV, MP3, FLAC, OGG, M4A | File audio format |
embedder_model |
No | hubert | hubert or contentvec | Embedder model to use for the audio conversion. The default model is hubert, which is recommended for most cases. |
upscale_audio |
No | False | True or False | Upscale the audio to 48kHz for better results. |
Refer to python rvc.py infer -h for additional help.
python rvc.py batch_infer --f0up_key "f0up_key" --filter_radius "filter_radius" --index_rate "index_rate" --hop_length "hop_length" --rms_mix_rate "rms_mix_rate" --protect "protect" --f0autotune "f0autotune" --f0method "f0method" --input_folder_path "input_folder_path" --output_folder_path "output_folder_path" --pth_path "pth_path" --index_path "index_path" --split_audio "split_audio" --clean_audio "clean_audio" --clean_strength "clean_strength" --export_format "export_format"| Parameter Name | Required | Default | Valid Options | Description |
|---|---|---|---|---|
f0up_key |
No | 0 | -24 to +24 | Set the pitch of the audio, the higher the value, thehigher the pitch. |
filter_radius |
No | 3 | 0 to 10 | If the number is greater than or equal to three, employing median filtering on the collected tone results has the potential to decrease respiration. |
index_rate |
No | 0.3 | 0.0 to 1.0 | Influence exerted by the index file; a higher value corresponds to greater influence. However, opting for lower values can help mitigate artifacts present in the audio. |
hop_length |
No | 128 | 1 to 512 | Denotes the duration it takes for the system to transition to a significant pitch change. Smaller hop lengths require more time for inference but tend to yield higher pitch accuracy. |
rms_mix_rate |
No | 1 | 0 to 1 | Substitute or blend with the volume envelope of the output. The closer the ratio is to 1, the more the output envelope is employed. |
protect |
No | 0.33 | 0 to 0.5 | Safeguard distinct consonants and breathing sounds to prevent electro-acoustic tearing and other artifacts. Pulling the parameter to its maximum value of 0.5 offers comprehensive protection. However, reducing this value might decrease the extent of protection while potentially mitigating the indexing effect. |
f0autotune |
No | False | True or False | Apply a soft autotune to your inferences, recommended for singing conversions. |
f0method |
No | rmvpe | pm, harvest, dio, crepe, crepe-tiny, rmvpe, fcpe, hybrid[crepe+rmvpe], hybrid[crepe+fcpe], hybrid[rmvpe+fcpe], hybrid[crepe+rmvpe+fcpe] | Pitch extraction algorithm to use for the audio conversion. The default algorithm is rmvpe, which is recommended for most cases. |
input_folder_path |
Yes | None | Full path to the input audio folder (The folder may only contain audio files) | Full path to the input audio folder |
output_folder_path |
Yes | None | Full path to the output audio folder | Full path to the output audio folder |
pth_path |
Yes | None | Full path to the pth file | Full path to the pth file |
index_path |
Yes | None | Full path to the index file | Full path to the index file |
split_audio |
No | False | True or False | Split the audio into chunks for inference to obtain better results in some cases. |
clean_audio |
No | False | True or False | Clean your audio output using noise detection algorithms, recommended for speaking audios. |
clean_strength |
No | 0.7 | 0.0 to 1.0 | Set the clean-up level to the audio you want, the more you increase it the more it will clean up, but it is possible that the audio will be more compressed. |
export_format |
No | WAV | WAV, MP3, FLAC, OGG, M4A | File audio format |
embedder_model |
No | hubert | hubert or contentvec | Embedder model to use for the audio conversion. The default model is hubert, which is recommended for most cases. |
upscale_audio |
No | False | True or False | Upscale the audio to 48kHz for better results. |
Refer to python rvc.py batch_infer -h for additional help.
python rvc.py tts_infer --tts_text "tts_text" --tts_voice "tts_voice" --f0up_key "f0up_key" --filter_radius "filter_radius" --index_rate "index_rate" --hop_length "hop_length" --rms_mix_rate "rms_mix_rate" --protect "protect" --f0autotune "f0autotune" --f0method "f0method" --output_tts_path "output_tts_path" --output_rvc_path "output_rvc_path" --pth_path "pth_path" --index_path "index_path"--split_audio "split_audio" --clean_audio "clean_audio" --clean_strength "clean_strength" --export_format "export_format"| Parameter Name | Required | Default | Valid Options | Description |
|---|---|---|---|---|
tts_text |
Yes | None | Text for TTS synthesis | Text for TTS synthesis |
tts_voice |
Yes | None | Voice for TTS synthesis | Voice for TTS synthesis |
f0up_key |
No | 0 | -24 to +24 | Set the pitch of the audio, the higher the value, thehigher the pitch. |
filter_radius |
No | 3 | 0 to 10 | If the number is greater than or equal to three, employing median filtering on the collected tone results has the potential to decrease respiration. |
index_rate |
No | 0.3 | 0.0 to 1.0 | Influence exerted by the index file; a higher value corresponds to greater influence. However, opting for lower values can help mitigate artifacts present in the audio. |
hop_length |
No | 128 | 1 to 512 | Denotes the duration it takes for the system to transition to a significant pitch change. Smaller hop lengths require more time for inference but tend to yield higher pitch accuracy. |
rms_mix_rate |
No | 1 | 0 to 1 | Substitute or blend with the volume envelope of the output. The closer the ratio is to 1, the more the output envelope is employed. |
protect |
No | 0.33 | 0 to 0.5 | Safeguard distinct consonants and breathing sounds to prevent electro-acoustic tearing and other artifacts. Pulling the parameter to its maximum value of 0.5 offers comprehensive protection. However, reducing this value might decrease the extent of protection while potentially mitigating the indexing effect. |
f0autotune |
No | False | True or False | Apply a soft autotune to your inferences, recommended for singing conversions. |
f0method |
No | rmvpe | pm, harvest, dio, crepe, crepe-tiny, rmvpe, fcpe, hybrid[crepe+rmvpe], hybrid[crepe+fcpe], hybrid[rmvpe+fcpe], hybrid[crepe+rmvpe+fcpe] | Pitch extraction algorithm to use for the audio conversion. The default algorithm is rmvpe, which is recommended for most cases. |
output_tts_path |
Yes | None | Full path to the output TTS audio file | Full path to the output TTS audio file |
output_rvc_path |
Yes | None | Full path to the input RVC audio file | Full path to the input RVC audio file |
pth_path |
Yes | None | Full path to the pth file | Full path to the pth file |
index_path |
Yes | None | Full path to the index file | Full path to the index file |
split_audio |
No | False | True or False | Split the audio into chunks for inference to obtain better results in some cases. |
clean_audio |
No | False | True or False | Clean your audio output using noise detection algorithms, recommended for speaking audios. |
clean_strength |
No | 0.7 | 0.0 to 1.0 | Set the clean-up level to the audio you want, the more you increase it the more it will clean up, but it is possible that the audio will be more compressed. |
export_format |
No | WAV | WAV, MP3, FLAC, OGG, M4A | File audio format |
embedder_model |
No | hubert | hubert or contentvec | Embedder model to use for the audio conversion. The default model is hubert, which is recommended for most cases. |
upscale_audio |
No | False | True or False | Upscale the audio to 48kHz for better results. |
Refer to python rvc.py tts_infer -h for additional help.
python rvc.py preprocess --model_name "model_name" --dataset_path "dataset_path" --sampling_rate "sampling_rate"| Parameter Name | Required | Default | Valid Options | Description |
|---|---|---|---|---|
model_name |
Yes | None | Name of the model | Name of the model |
dataset_path |
Yes | None | Full path to the dataset folder (The folder may only contain audio files) | Full path to the dataset folder |
sampling_rate |
Yes | None | 32000, 40000, or 48000 | Sampling rate of the audio data |
Refer to python rvc.py preprocess -h for additional help.
python rvc.py extract --model_name "model_name" --rvc_version "rvc_version" --pitch_guidance "pitch_guidance" --hop_length "hop_length" --sampling_rate "sampling_rate"| Parameter Name | Required | Default | Valid Options | Description |
|---|---|---|---|---|
model_name |
Yes | None | Name of the model | Name of the model |
rvc_version |
No | v2 | v1 or v2 | Version of the model |
pitch_guidance |
No | True | True or False | By employing pitch guidance, it becomes feasible to mirror the intonation of the original voice, including its pitch. This feature is particularly valuable for singing and other scenarios where preserving the original melody or pitch pattern is essential. |
hop_length |
No | 128 | 1 to 512 | Denotes the duration it takes for the system to transition to a significant pitch change. Smaller hop lengths require more time for inference but tend to yield higher pitch accuracy. |
sampling_rate |
Yes | None | 32000, 40000, or 48000 | Sampling rate of the audio data |
embedder_model |
No | hubert | hubert or contentvec | Embedder model to use for the audio conversion. The default model is hubert, which is recommended for most cases. |
python rvc.py train --model_name "model_name" --rvc_version "rvc_version" --save_every_epoch "save_every_epoch" --save_only_latest "save_only_latest" --save_every_weights "save_every_weights" --total_epoch "total_epoch" --sampling_rate "sampling_rate" --batch_size "batch_size" --gpu "gpu" --pitch_guidance "pitch_guidance" --overtraining_detector "overtraining_detector" --overtraining_threshold "overtraining_threshold" --sync_graph "sync_graph" --pretrained "pretrained" --custom_pretrained "custom_pretrained" [--g_pretrained "g_pretrained"] [--d_pretrained "d_pretrained"]| Parameter Name | Required | Default | Valid Options | Description |
|---|---|---|---|---|
model_name |
Yes | None | Name of the model | Name of the model |
rvc_version |
No | v2 | v1 or v2 | Version of the model |
save_every_epoch |
Yes | None | 1 to 50 | Determine at how many epochs the model will saved at. |
save_only_latest |
No | False | True or False | Enabling this setting will result in the G and D files saving only their most recent versions, effectively conserving storage space. |
save_every_weights |
No | True | True or False | This setting enables you to save the weights of the model at the conclusion of each epoch. |
total_epoch |
No | 1000 | 1 to 10000 | Specifies the overall quantity of epochs for the model training process. |
sampling_rate |
Yes | None | 32000, 40000, or 48000 | Sampling rate of the audio data |
batch_size |
No | 8 | 1 to 50 | It's advisable to align it with the available VRAM of your GPU. A setting of 4 offers improved accuracy but slower processing, while 8 provides faster and standard results. |
gpu |
No | 0 | 0 to ∞ separated by - | Specify the number of GPUs you wish to utilize for training by entering them separated by hyphens (-). |
pitch_guidance |
No | True | True or False | By employing pitch guidance, it becomes feasible to mirror the intonation of the original voice, including its pitch. This feature is particularly valuable for singing and other scenarios where preserving the original melody or pitch pattern is essential. |
overtraining_detector |
No | False | True or False | Utilize the overtraining detector to prevent overfitting. This feature is particularly valuable for scenarios where the model is at risk of overfitting. |
overtraining_threshold |
No | 50 | 1 to 100 | Set the threshold for the overtraining detector. The lower the value, the more sensitive the detector will be. |
pretrained |
No | True | True or False | Utilize pretrained models when training your own. This approach reduces training duration and enhances overall quality. |
custom_pretrained |
No | False | True or False | Utilizing custom pretrained models can lead to superior results, as selecting the most suitable pretrained models tailored to the specific use case can significantly enhance performance. |
g_pretrained |
No | None | Full path to pretrained file G, only if you have used custom_pretrained | Full path to pretrained file G |
d_pretrained |
No | None | Full path to pretrained file D, only if you have used custom_pretrained | Full path to pretrained file D |
sync_graph |
No | False | True or False | Synchronize the graph of the tensorbaord. Only enable this setting if you are training a new model. |
Refer to python rvc.py train -h for additional help.
python rvc.py index --model_name "model_name" --rvc_version "rvc_version"| Parameter Name | Required | Default | Valid Options | Description |
|---|---|---|---|---|
model_name |
Yes | None | Name of the model | Name of the model |
rvc_version |
Yes | None | v1 or v2 | Version of the model |
Refer to python rvc.py index -h for additional help.
python uvr.py [audio_file] [options]| Parameter Name | Required | Default | Valid Options | Description |
|---|---|---|---|---|
audio_file |
Yes | None | Any valid audio file path | The path to the audio file you want to separate, in any common format. |
-d, --debug
|
No | False | Enable debug logging. | |
-e, --env_info
|
No | False | Print environment information and exit. | |
-l, --list_models
|
No | False | List all supported models and exit. | |
--log_level |
No | info | info, debug, warning | Log level. |
| Parameter Name | Required | Default | Valid Options | Description |
|---|---|---|---|---|
-m, --model_filename
|
No | UVR-MDX-NET-Inst_HQ_3.onnx | Any valid model file path | Model to use for separation. |
--output_format |
No | WAV | Any common audio format | Output format for separated files. |
--output_dir |
No | None | Any valid directory path | Directory to write output files. |
--model_file_dir |
No | /tmp/audio-separator-models/ | Any valid directory path | Model files directory. |
| Parameter Name | Required | Default | Valid Options | Description |
|---|---|---|---|---|
--invert_spect |
No | False | Invert secondary stem using spectrogram. | |
--normalization |
No | 0.9 | Any float value | Max peak amplitude to normalize input and output audio to. |
--single_stem |
No | None | Instrumental, Vocals, Drums, Bass, Guitar, Piano, Other | Output only a single stem. |
--sample_rate |
No | 44100 | Any integer value | Modify the sample rate of the output audio. |
| Parameter Name | Required | Default | Valid Options | Description |
|---|---|---|---|---|
--mdxc_segment_size |
No | 256 | Any integer value | Size of segments for MDXC architecture. |
--mdxc_override_model_segment_size |
No | False | Opverride model default segment size instead of using the model default value. | |
--mdxc_overlap |
No | 8 | 2 to 50 | Amount of overlap between prediction windows for MDXC architecture. |
--mdxc_batch_size |
No | 1 | Any integer value | Batch size for MDXC architecture. |
--mdxc_pitch_shift |
No | 0 | Any integer value | Shift audio pitch by a number of semitones while processing for MDXC architecture. |
| Parameter Name | Required | Default | Valid Options | Description |
|---|---|---|---|---|
--mdx_segment_size |
No | 256 | Any integer value | Size of segments for MDX architecture. |
--mdx_overlap |
No | 0.25 | 0.001 to 0.999 | Amount of overlap between prediction windows for MDX architecture. |
--mdx_batch_size |
No | 1 | Any integer value | Batch size for MDX architecture. |
--mdx_hop_length |
No | 1024 | Any integer value | Hop length for MDX architecture. |
--mdx_enable_denoise |
No | False | Enable denoising during separation for MDX architecture. |
| Parameter Name | Required | Default | Valid Options | Description |
|---|---|---|---|---|
--demucs_segment_size |
No | Default | Any integer value | Size of segments for Demucs architecture. |
--demucs_shifts |
No | 2 | Any integer value | Number of predictions with random shifts for Demucs architecture. |
--demucs_overlap |
No | 0.25 | 0.001 to 0.999 | Overlap between prediction windows for Demucs architecture. |
--demucs_segments_enabled |
No | True | Enable segment-wise processing for Demucs architecture. |
| Parameter Name | Required | Default | Valid Options | Description |
|---|---|---|---|---|
--vr_batch_size |
No | 4 | Any integer value | Batch size for VR architecture. |
--vr_window_size |
No | 512 | Any integer value | Window size for VR architecture. |
--vr_aggression |
No | 5 | -100 to 100 | Intensity of primary stem extraction for VR architecture. |
--vr_enable_tta |
No | False | Enable Test-Time-Augmentation for VR architecture. | |
--vr_high_end_process |
No | False | Mirror the missing frequency range of the output for VR architecture. | |
--vr_enable_post_process |
No | False | Identify leftover artifacts within vocal output for VR architecture. | |
--vr_post_process_threshold |
No | 0.2 | 0.1 to 0.3 | Threshold for post-process feature for VR architecture. |
python rvc.py model_extract --pth_path "pth_path" --model_name "model_name" --sampling_rate "sampling_rate" --pitch_guidance "pitch_guidance" --rvc_version "rvc_version" --epoch "epoch" --step "step"| Parameter Name | Required | Default | Valid Options | Description |
|---|---|---|---|---|
pth_path |
Yes | None | Path to the pth file | Full path to the pth file |
model_name |
Yes | None | Name of the model | Name of the model |
sampling_rate |
Yes | None | 32000, 40000, or 48000 | Sampling rate of the audio data |
pitch_guidance |
Yes | None | True or False | By employing pitch guidance, it becomes feasible to mirror the intonation of the original voice, including its pitch. This feature is particularly valuable for singing and other scenarios where preserving the original melody or pitch pattern is essential. |
rvc_version |
Yes | None | v1 or v2 | Version of the model |
epoch |
Yes | None | 1 to 10000 | Specifies the overall quantity of epochs for the model training process. |
step |
Yes | None | 1 to ∞ | Specifies the overall quantity of steps for the model training process. |
python rvc.py model_information --pth_path "pth_path"| Parameter Name | Required | Default | Valid Options | Description |
|---|---|---|---|---|
pth_path |
Yes | None | Path to the pth file | Full path to the pth file |
python rvc.py model_blender --model_name "model_name" --pth_path_1 "pth_path_1" --pth_path_2 "pth_path_2" --ratio "ratio"| Parameter Name | Required | Default | Valid Options | Description |
|---|---|---|---|---|
model_name |
Yes | None | Name of the model | Name of the model |
pth_path_1 |
Yes | None | Path to the first pth file | Full path to the first pth file |
pth_path_2 |
Yes | None | Path to the second pth file | Full path to the second pth file |
ratio |
No | 0.5 | 0.0 to 1 | Value for blender ratio |
python rvc.py tensorboardRun the download script with the following command:
python rvc.py download --model_link "model_link"| Parameter Name | Required | Default | Valid Options | Description |
|---|---|---|---|---|
model_link |
Yes | None | Link of the model (enclosed in double quotes; Google Drive or Hugging Face) | Link of the model |
Refer to python rvc.py download -h for additional help.
python rvc.py audio_analyzer --input_path "input_path"| Parameter Name | Required | Default | Valid Options | Description |
|---|---|---|---|---|
input_path |
Yes | None | Full path to the input audio file | Full path to the input audio file |
Refer to python rvc.py audio_analyzer -h for additional help.
python rvc.py prerequisites --pretraineds_v1 "pretraineds_v1" --pretraineds_v2 "--pretraineds_v2" --models "models" --exe "exe"| Parameter Name | Required | Default | Valid Options | Description |
|---|---|---|---|---|
pretraineds_v1 |
No | True | True or False | Download pretrained models for v1 |
pretraineds_v2 |
No | True | True or False | Download pretrained models for v2 |
models |
No | True | True or False | Download models for v1 and v2 |
exe |
No | True | True or False | Download the necessary executable files for the CLI to function properly (FFmpeg and FFprobe) |
python rvc.py api --host "host" --port "port"| Parameter Name | Required | Default | Valid Options | Description |
|---|---|---|---|---|
host |
No | 127.0.0.1 | Value for host IP | Value for host IP |
port |
No | 8000 | Value for port number | Value for port number |
To use the RVC CLI via the API, utilize the provided script. Make API requests to the following endpoints:
-
Docs:
/docs -
Ping:
/ping -
Infer:
/infer -
Batch Infer:
/batch_infer -
TTS:
/tts -
Preprocess:
/preprocess -
Extract:
/extract -
Train:
/train -
Index:
/index -
Model Information:
/model_information -
Model Fusion:
/model_fusion -
Download:
/download
Make POST requests to these endpoints with the same required parameters as in CLI mode.
The RVC CLI builds upon the foundations of the following projects:
- ContentVec by auspicious3000
- HIFIGAN by jik876
- audio-slicer by openvpi
- python-audio-separator by karaokenerds
- RMVPE by Dream-High
- FCPE by CNChTu
- VITS by jaywalnut310
- So-Vits-SVC by svc-develop-team
- Harmonify by Eempostor
- Retrieval-based-Voice-Conversion-WebUI by RVC-Project
- Mangio-RVC-Fork by Mangio621
- anyf0 by SoulMelody
We acknowledge and appreciate the contributions of the respective authors and communities involved in these projects.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for RVC_CLI
Similar Open Source Tools
RVC_CLI
RVC_CLI is a command line interface tool for retrieval-based voice conversion. It provides functionalities for installation, getting started, inference, training, UVR, additional features, and API integration. Users can perform tasks like single inference, batch inference, TTS inference, preprocess dataset, extract features, start training, generate index file, model extract, model information, model blender, launch TensorBoard, download models, audio analyzer, and prerequisites download. The tool is built on various projects like ContentVec, HIFIGAN, audio-slicer, python-audio-separator, RMVPE, FCPE, VITS, So-Vits-SVC, Harmonify, and others.

RVC_CLI
**RVC_CLI: Retrieval-based Voice Conversion Command Line Interface** This command-line interface (CLI) provides a comprehensive set of tools for voice conversion, enabling you to modify the pitch, timbre, and other characteristics of audio recordings. It leverages advanced machine learning models to achieve realistic and high-quality voice conversions. **Key Features:** * **Inference:** Convert the pitch and timbre of audio in real-time or process audio files in batch mode. * **TTS Inference:** Synthesize speech from text using a variety of voices and apply voice conversion techniques. * **Training:** Train custom voice conversion models to meet specific requirements. * **Model Management:** Extract, blend, and analyze models to fine-tune and optimize performance. * **Audio Analysis:** Inspect audio files to gain insights into their characteristics. * **API:** Integrate the CLI's functionality into your own applications or workflows. **Applications:** The RVC_CLI finds applications in various domains, including: * **Music Production:** Create unique vocal effects, harmonies, and backing vocals. * **Voiceovers:** Generate voiceovers with different accents, emotions, and styles. * **Audio Editing:** Enhance or modify audio recordings for podcasts, audiobooks, and other content. * **Research and Development:** Explore and advance the field of voice conversion technology. **For Jobs:** * Audio Engineer * Music Producer * Voiceover Artist * Audio Editor * Machine Learning Engineer **AI Keywords:** * Voice Conversion * Pitch Shifting * Timbre Modification * Machine Learning * Audio Processing **For Tasks:** * Convert Pitch * Change Timbre * Synthesize Speech * Train Model * Analyze Audio
beet
Beet is a collection of crates for authoring and running web pages, games and AI behaviors. It includes crates like `beet_flow` for scenes-as-control-flow bevy library, `beet_spatial` for spatial behaviors, `beet_ml` for machine learning, `beet_sim` for simulation tooling, `beet_rsx` for authoring tools for html and bevy, and `beet_router` for file-based router for web docs. The `beet` crate acts as a base crate that re-exports sub-crates based on feature flags, similar to the `bevy` crate structure.
aikit
AIKit is a comprehensive platform for hosting, deploying, building, and fine-tuning large language models (LLMs). It offers inference using LocalAI, extensible fine-tuning interface, and OCI packaging for distributing models. AIKit supports various models, multi-modal model and image generation, Kubernetes deployment, and supply chain security. It can run on AMD64 and ARM64 CPUs, NVIDIA GPUs, and Apple Silicon (experimental). Users can quickly get started with AIKit without a GPU and access pre-made models. The platform is OpenAI API compatible and provides easy-to-use configuration for inference and fine-tuning.
aikit
AIKit is a one-stop shop to quickly get started to host, deploy, build and fine-tune large language models (LLMs). AIKit offers two main capabilities: Inference: AIKit uses LocalAI, which supports a wide range of inference capabilities and formats. LocalAI provides a drop-in replacement REST API that is OpenAI API compatible, so you can use any OpenAI API compatible client, such as Kubectl AI, Chatbot-UI and many more, to send requests to open-source LLMs! Fine Tuning: AIKit offers an extensible fine tuning interface. It supports Unsloth for fast, memory efficient, and easy fine-tuning experience.
llm4regression
This project explores the capability of Large Language Models (LLMs) to perform regression tasks using in-context examples. It compares the performance of LLMs like GPT-4 and Claude 3 Opus with traditional supervised methods such as Linear Regression and Gradient Boosting. The project provides preprints and results demonstrating the strong performance of LLMs in regression tasks. It includes datasets, models used, and experiments on adaptation and contamination. The code and data for the experiments are available for interaction and analysis.
apidash
API Dash is an open-source cross-platform API Client that allows users to easily create and customize API requests, visually inspect responses, and generate API integration code. It supports various HTTP methods, GraphQL requests, and multimedia API responses. Users can organize requests in collections, preview data in different formats, and generate code for multiple languages. The tool also offers dark mode support, data persistence, and various customization options.

YuLan-Mini
YuLan-Mini is a lightweight language model with 2.4 billion parameters that achieves performance comparable to industry-leading models despite being pre-trained on only 1.08T tokens. It excels in mathematics and code domains. The repository provides pre-training resources, including data pipeline, optimization methods, and annealing approaches. Users can pre-train their own language models, perform learning rate annealing, fine-tune the model, research training dynamics, and synthesize data. The team behind YuLan-Mini is AI Box at Renmin University of China. The code is released under the MIT License with future updates on model weights usage policies. Users are advised on potential safety concerns and ethical use of the model.
LightMem
LightMem is a lightweight and efficient memory management framework designed for Large Language Models and AI Agents. It provides a simple yet powerful memory storage, retrieval, and update mechanism to help you quickly build intelligent applications with long-term memory capabilities. The framework is minimalist in design, ensuring minimal resource consumption and fast response times. It offers a simple API for easy integration into applications with just a few lines of code. LightMem's modular architecture supports custom storage engines and retrieval strategies, making it flexible and extensible. It is compatible with various cloud APIs like OpenAI and DeepSeek, as well as local models such as Ollama and vLLM.
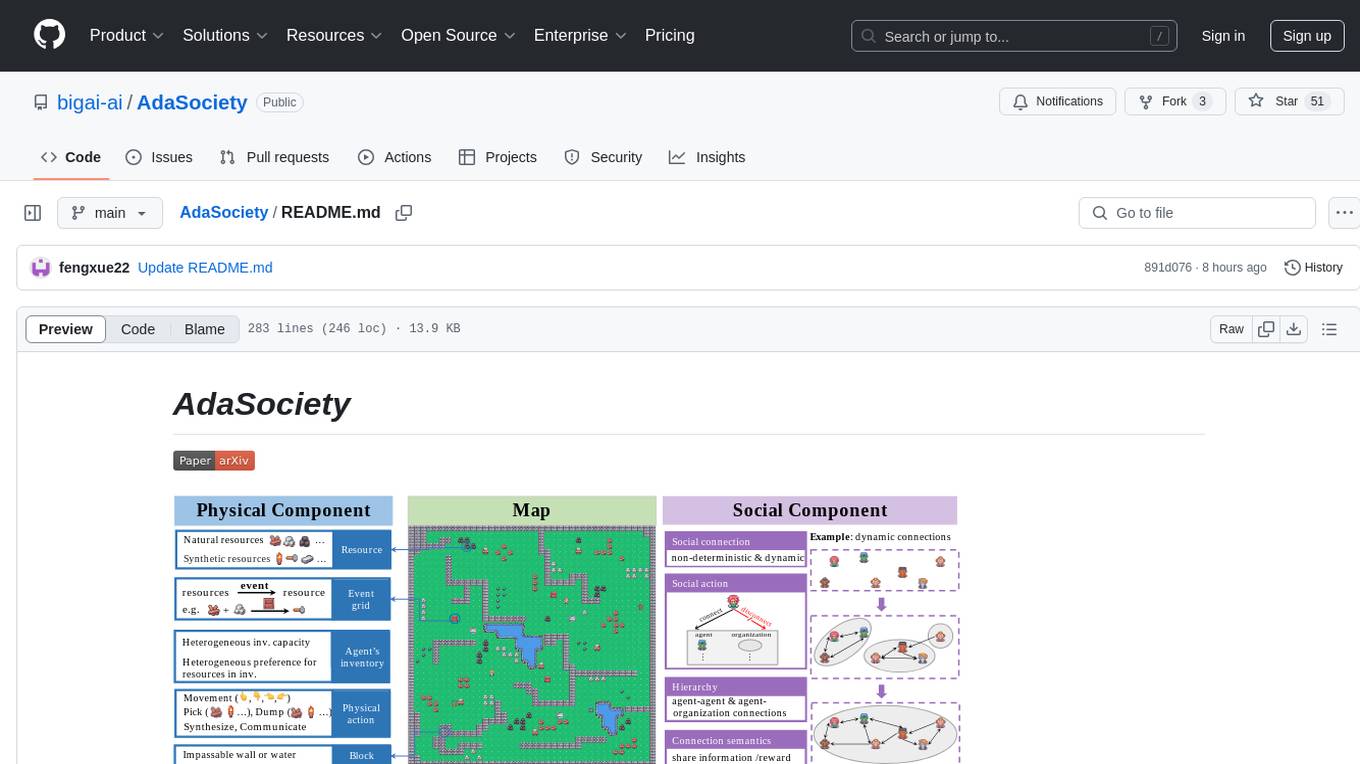
AdaSociety
AdaSociety is a multi-agent environment designed for simulating social structures and decision-making processes. It offers built-in resources, events, and player interactions. Users can customize the environment through JSON configuration or custom Python code. The environment supports training agents using RLlib and LLM frameworks. It provides a platform for studying multi-agent systems and social dynamics.

are-copilots-local-yet
Current trends and state of the art for using open & local LLM models as copilots to complete code, generate projects, act as shell assistants, automatically fix bugs, and more. This document is a curated list of local Copilots, shell assistants, and related projects, intended to be a resource for those interested in a survey of the existing tools and to help developers discover the state of the art for projects like these.

goodai-ltm-benchmark
This repository contains code and data for replicating experiments on Long-Term Memory (LTM) abilities of conversational agents. It includes a benchmark for testing agents' memory performance over long conversations, evaluating tasks requiring dynamic memory upkeep and information integration. The repository supports various models, datasets, and configurations for benchmarking and reporting results.

PredictorLLM
PredictorLLM is an advanced trading agent framework that utilizes large language models to automate trading in financial markets. It includes a profiling module to establish agent characteristics, a layered memory module for retaining and prioritizing financial data, and a decision-making module to convert insights into trading strategies. The framework mimics professional traders' behavior, surpassing human limitations in data processing and continuously evolving to adapt to market conditions for superior investment outcomes.

jailbreak_llms
This is the official repository for the ACM CCS 2024 paper 'Do Anything Now': Characterizing and Evaluating In-The-Wild Jailbreak Prompts on Large Language Models. The project employs a new framework called JailbreakHub to conduct the first measurement study on jailbreak prompts in the wild, collecting 15,140 prompts from December 2022 to December 2023, including 1,405 jailbreak prompts. The dataset serves as the largest collection of in-the-wild jailbreak prompts. The repository contains examples of harmful language and is intended for research purposes only.

awsome-distributed-training
This repository contains reference architectures and test cases for distributed model training with Amazon SageMaker Hyperpod, AWS ParallelCluster, AWS Batch, and Amazon EKS. The test cases cover different types and sizes of models as well as different frameworks and parallel optimizations (Pytorch DDP/FSDP, MegatronLM, NemoMegatron...).

flute
FLUTE (Flexible Lookup Table Engine for LUT-quantized LLMs) is a tool designed for uniform quantization and lookup table quantization of weights in lower-precision intervals. It offers flexibility in mapping intervals to arbitrary values through a lookup table. FLUTE supports various quantization formats such as int4, int3, int2, fp4, fp3, fp2, nf4, nf3, nf2, and even custom tables. The tool also introduces new quantization algorithms like Learned Normal Float (NFL) for improved performance and calibration data learning. FLUTE provides benchmarks, model zoo, and integration with frameworks like vLLM and HuggingFace for easy deployment and usage.
For similar tasks
RVC_CLI
**RVC_CLI: Retrieval-based Voice Conversion Command Line Interface** This command-line interface (CLI) provides a comprehensive set of tools for voice conversion, enabling you to modify the pitch, timbre, and other characteristics of audio recordings. It leverages advanced machine learning models to achieve realistic and high-quality voice conversions. **Key Features:** * **Inference:** Convert the pitch and timbre of audio in real-time or process audio files in batch mode. * **TTS Inference:** Synthesize speech from text using a variety of voices and apply voice conversion techniques. * **Training:** Train custom voice conversion models to meet specific requirements. * **Model Management:** Extract, blend, and analyze models to fine-tune and optimize performance. * **Audio Analysis:** Inspect audio files to gain insights into their characteristics. * **API:** Integrate the CLI's functionality into your own applications or workflows. **Applications:** The RVC_CLI finds applications in various domains, including: * **Music Production:** Create unique vocal effects, harmonies, and backing vocals. * **Voiceovers:** Generate voiceovers with different accents, emotions, and styles. * **Audio Editing:** Enhance or modify audio recordings for podcasts, audiobooks, and other content. * **Research and Development:** Explore and advance the field of voice conversion technology. **For Jobs:** * Audio Engineer * Music Producer * Voiceover Artist * Audio Editor * Machine Learning Engineer **AI Keywords:** * Voice Conversion * Pitch Shifting * Timbre Modification * Machine Learning * Audio Processing **For Tasks:** * Convert Pitch * Change Timbre * Synthesize Speech * Train Model * Analyze Audio
audioseal
AudioSeal is a method for speech localized watermarking, designed with state-of-the-art robustness and detector speed. It jointly trains a generator to embed a watermark in audio and a detector to detect watermarked fragments in longer audios, even in the presence of editing. The tool achieves top-notch detection performance at the sample level, generates minimal alteration of signal quality, and is robust to various audio editing types. With a fast, single-pass detector, AudioSeal surpasses existing models in speed, making it ideal for large-scale and real-time applications.
SLAM-LLM
SLAM-LLM is a deep learning toolkit designed for researchers and developers to train custom multimodal large language models (MLLM) focusing on speech, language, audio, and music processing. It provides detailed recipes for training and high-performance checkpoints for inference. The toolkit supports tasks such as automatic speech recognition (ASR), text-to-speech (TTS), visual speech recognition (VSR), automated audio captioning (AAC), spatial audio understanding, and music caption (MC). SLAM-LLM features easy extension to new models and tasks, mixed precision training for faster training with less GPU memory, multi-GPU training with data and model parallelism, and flexible configuration based on Hydra and dataclass.
freegenius
FreeGenius AI is an ambitious project offering a comprehensive suite of AI solutions that mirror the capabilities of LetMeDoIt AI. It is designed to engage in intuitive conversations, execute codes, provide up-to-date information, and perform various tasks. The tool is free, customizable, and provides access to real-time data and device information. It aims to support offline and online backends, open-source large language models, and optional API keys. Users can use FreeGenius AI for tasks like generating tweets, analyzing audio, searching financial data, checking weather, and creating maps.
RVC_CLI
RVC_CLI is a command line interface tool for retrieval-based voice conversion. It provides functionalities for installation, getting started, inference, training, UVR, additional features, and API integration. Users can perform tasks like single inference, batch inference, TTS inference, preprocess dataset, extract features, start training, generate index file, model extract, model information, model blender, launch TensorBoard, download models, audio analyzer, and prerequisites download. The tool is built on various projects like ContentVec, HIFIGAN, audio-slicer, python-audio-separator, RMVPE, FCPE, VITS, So-Vits-SVC, Harmonify, and others.

towhee
Towhee is a cutting-edge framework designed to streamline the processing of unstructured data through the use of Large Language Model (LLM) based pipeline orchestration. It can extract insights from diverse data types like text, images, audio, and video files using generative AI and deep learning models. Towhee offers rich operators, prebuilt ETL pipelines, and a high-performance backend for efficient data processing. With a Pythonic API, users can build custom data processing pipelines easily. Towhee is suitable for tasks like sentence embedding, image embedding, video deduplication, question answering with documents, and cross-modal retrieval based on CLIP.
chatwise-releases
ChatWise is an offline tool that supports various AI models such as OpenAI, Anthropic, Google AI, Groq, and Ollama. It is multi-modal, allowing text-to-speech powered by OpenAI and ElevenLabs. The tool supports text files, PDFs, audio, and images across different models. ChatWise is currently available for macOS (Apple Silicon & Intel) with Windows support coming soon.
AudioMuse-AI
AudioMuse-AI is a deep learning-based tool for audio analysis and music generation. It provides a user-friendly interface for processing audio data and generating music compositions. The tool utilizes state-of-the-art machine learning algorithms to analyze audio signals and extract meaningful features for music generation. With AudioMuse-AI, users can explore the possibilities of AI in music creation and experiment with different styles and genres. Whether you are a music enthusiast, a researcher, or a developer, AudioMuse-AI offers a versatile platform for audio analysis and music generation.
For similar jobs

metavoice-src
MetaVoice-1B is a 1.2B parameter base model trained on 100K hours of speech for TTS (text-to-speech). It has been built with the following priorities: * Emotional speech rhythm and tone in English. * Zero-shot cloning for American & British voices, with 30s reference audio. * Support for (cross-lingual) voice cloning with finetuning. * We have had success with as little as 1 minute training data for Indian speakers. * Synthesis of arbitrary length text

suno-api
Suno AI API is an open-source project that allows developers to integrate the music generation capabilities of Suno.ai into their own applications. The API provides a simple and convenient way to generate music, lyrics, and other audio content using Suno.ai's powerful AI models. With Suno AI API, developers can easily add music generation functionality to their apps, websites, and other projects.

bark.cpp
Bark.cpp is a C/C++ implementation of the Bark model, a real-time, multilingual text-to-speech generation model. It supports AVX, AVX2, and AVX512 for x86 architectures, and is compatible with both CPU and GPU backends. Bark.cpp also supports mixed F16/F32 precision and 4-bit, 5-bit, and 8-bit integer quantization. It can be used to generate realistic-sounding audio from text prompts.

NSMusicS
NSMusicS is a local music software that is expected to support multiple platforms with AI capabilities and multimodal features. The goal of NSMusicS is to integrate various functions (such as artificial intelligence, streaming, music library management, cross platform, etc.), which can be understood as similar to Navidrome but with more features than Navidrome. It wants to become a plugin integrated application that can almost have all music functions.

ai-voice-cloning
This repository provides a tool for AI voice cloning, allowing users to generate synthetic speech that closely resembles a target speaker's voice. The tool is designed to be user-friendly and accessible, with a graphical user interface that guides users through the process of training a voice model and generating synthetic speech. The tool also includes a variety of features that allow users to customize the generated speech, such as the pitch, volume, and speaking rate. Overall, this tool is a valuable resource for anyone interested in creating realistic and engaging synthetic speech.
RVC_CLI
**RVC_CLI: Retrieval-based Voice Conversion Command Line Interface** This command-line interface (CLI) provides a comprehensive set of tools for voice conversion, enabling you to modify the pitch, timbre, and other characteristics of audio recordings. It leverages advanced machine learning models to achieve realistic and high-quality voice conversions. **Key Features:** * **Inference:** Convert the pitch and timbre of audio in real-time or process audio files in batch mode. * **TTS Inference:** Synthesize speech from text using a variety of voices and apply voice conversion techniques. * **Training:** Train custom voice conversion models to meet specific requirements. * **Model Management:** Extract, blend, and analyze models to fine-tune and optimize performance. * **Audio Analysis:** Inspect audio files to gain insights into their characteristics. * **API:** Integrate the CLI's functionality into your own applications or workflows. **Applications:** The RVC_CLI finds applications in various domains, including: * **Music Production:** Create unique vocal effects, harmonies, and backing vocals. * **Voiceovers:** Generate voiceovers with different accents, emotions, and styles. * **Audio Editing:** Enhance or modify audio recordings for podcasts, audiobooks, and other content. * **Research and Development:** Explore and advance the field of voice conversion technology. **For Jobs:** * Audio Engineer * Music Producer * Voiceover Artist * Audio Editor * Machine Learning Engineer **AI Keywords:** * Voice Conversion * Pitch Shifting * Timbre Modification * Machine Learning * Audio Processing **For Tasks:** * Convert Pitch * Change Timbre * Synthesize Speech * Train Model * Analyze Audio

openvino-plugins-ai-audacity
OpenVINO™ AI Plugins for Audacity* are a set of AI-enabled effects, generators, and analyzers for Audacity®. These AI features run 100% locally on your PC -- no internet connection necessary! OpenVINO™ is used to run AI models on supported accelerators found on the user's system such as CPU, GPU, and NPU. * **Music Separation**: Separate a mono or stereo track into individual stems -- Drums, Bass, Vocals, & Other Instruments. * **Noise Suppression**: Removes background noise from an audio sample. * **Music Generation & Continuation**: Uses MusicGen LLM to generate snippets of music, or to generate a continuation of an existing snippet of music. * **Whisper Transcription**: Uses whisper.cpp to generate a label track containing the transcription or translation for a given selection of spoken audio or vocals.

WavCraft
WavCraft is an LLM-driven agent for audio content creation and editing. It applies LLM to connect various audio expert models and DSP function together. With WavCraft, users can edit the content of given audio clip(s) conditioned on text input, create an audio clip given text input, get more inspiration from WavCraft by prompting a script setting and let the model do the scriptwriting and create the sound, and check if your audio file is synthesized by WavCraft.