
flute
Fast Matrix Multiplications for Lookup Table-Quantized LLMs
Stars: 229

FLUTE (Flexible Lookup Table Engine for LUT-quantized LLMs) is a tool designed for uniform quantization and lookup table quantization of weights in lower-precision intervals. It offers flexibility in mapping intervals to arbitrary values through a lookup table. FLUTE supports various quantization formats such as int4, int3, int2, fp4, fp3, fp2, nf4, nf3, nf2, and even custom tables. The tool also introduces new quantization algorithms like Learned Normal Float (NFL) for improved performance and calibration data learning. FLUTE provides benchmarks, model zoo, and integration with frameworks like vLLM and HuggingFace for easy deployment and usage.
README:
![]()
FLUTE: Flexible Lookup Table Engine for LUT-quantized LLMs


- Fenburary, 2024. HIGGS will appear in NAACL 2025.
- Jan 9, 2025. Added (very) experimental support for removing specialization on shapes + GPU via auto-tune.
- December 12, 2024. Added support for Hadamard Transform (via HadaCore).
-
November 26, 2024. Added support for vector (de)quantization (
vector_size=2), as part of HIGGS. - October 5, 2024. FLUTE will appear in EMNLP 2024 (Findings).
- September 15, 2024. Added experimental support for loading pre-quantized FLUTE models in HuggingFace.
- September 6, 2024. Added (unlearned) NF-quantized LLaMA-3.1 (405B) models: base and instruction tuned.
- August 31, 2024. Added support and example for the Learned Normal Float (NFL) quantization.
-
August 26, 2024. Added support for converting
bitsandbytesmodel into FLUTE model. - August 5, 2024. Added quantized LLaMA-3.1 (8B/70B) models.
- August 2, 2024. Added support for RTX4090.
- July 27, 2024. Added support for LLaMA-3.1 (405B) and tuned BF16 performance. FP16 is still the recommended data type, especially for 3-bit settings.
Install FLUTE with pip or from source:
# For CUDA 12.1
pip install flute-kernel
# For CUDA 11.8
pip install flute-kernel -i https://flute-ai.github.io/whl/cu118
# For CUDA 12.4
pip install flute-kernel -i https://flute-ai.github.io/whl/cu124Head over to Getting Started and try it out!
Uniform quantization converts full precision weights to lower-precision intervals of equal size. Lookup table (LUT) quantization is a flexible variant of non-uniform quantization which can map intervals to arbitrary values via a lookup table.
| Uniform (Integer) Quantization | Lookup Table Quantization |
|---|---|
|
$$\widehat{\mathbf{W}} = \mathtt{float}(\mathbf{Q}) \cdot \mathbf{s}$$ |
$$\widehat{\mathbf{W}} = \mathtt{tableLookup}(\mathbf{Q}, \mathtt{table}) \cdot \mathbf{s}$$ |
where $\mathbf{Q}$ denote the quantized weight, $\mathbf{s}$ the (group-wise) scales, and $\widehat{\mathbf{W}}$ the de-quantized weight. Here are some examples of the lookup table suppored in FLUTE.
| Examples | Notes |
|---|---|
|
|
recovers uniform/integer quantization |
|
|
|
|
|
generalizes the |
|
any arbitrary table |
you could even learn it! |
The flexibility of the kernel could lead to new quantization algorithms. As a proof of concept, we are releasing a few models quantized using Learned Normal Float (NFL) --- a simple extension to the nf4 data format introduced in QLoRA. NFL initialized the lookup table and the scales with those from NF quantization. Then, it uses calibration data to learn the scales via straight through estimation for for the gradient with respect to the scales.
For additional benchmarks, detailed breakdowns, and corresponding instruction-tuned models, please refer to the paper and the model zoo.

| Wiki PPL | C4 PPL | LLM Eval Avg. | Wiki PPL | C4 PPL | LLM Eval Avg. | ||
|---|---|---|---|---|---|---|---|
| LLaMA-3.1 (8B) | 6.31 | 9.60 | 69.75 | LLaMA-3.1 (70B) | 2.82 | 7.18 | 75.45 |
| + NFL W4G64 | 6.24 | 10.06 | 69.13 | + NFL W4G64 | 3.09 | 7.53 | 74.84 |
| + NFL W3G64 | 7.23 | 11.83 | 65.66 | + NFL W3G64 | 4.29 | 8.91 | 72.65 |
| Wiki PPL | C4 PPL | LLM Eval Avg. | Wiki PPL | C4 PPL | LLM Eval Avg. | ||
|---|---|---|---|---|---|---|---|
| Gemma-2 (9B) | 6.88 | 10.12 | 73.12 | Gemma-2 (27B) | 5.70 | 8.98 | 75.71 |
| + NFL W4G64 | 6.49 | 10.35 | 72.50 | + NFL W4G64 | 5.69 | 9.31 | 74.11 |
FLUTE-quantized models (Model Zoo) can be directly served using exisiting frameworks such as vLLM.
- python -m vllm.entrypoints.openai.api_server \
+ python -m flute.integrations.vllm vllm.entrypoints.openai.api_server \
--model [MODEL] \
--revision [REVISION] \
--tensor-parallel-size [TP_SIZE] \
+ --quantization fluteFor example, the following commmand runs the FLUTE-quantized LLaMA-3.1 (8B) on a single GPU.
python -m flute.integrations.vllm vllm.entrypoints.openai.api_server \
--model radi-cho/Meta-Llama-3.1-8B-FLUTE \
--quantization fluteWe can then query the vLLM server as usual.
curl http://localhost:8000/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "radi-cho/Meta-Llama-3.1-8B-FLUTE",
"prompt": "San Francisco is a",
"max_tokens": 7,
"temperature": 0
}'FLUTE also runs out of the box with HuggingFace and its accelerate extension. This integration is mostly experimental and not optimized. Users sensitive to performance considerations should use the vLLM integration instead.
- Loading a pre-quantized FLUTE model.
import flute.integrations.huggingface
- model = AutoModelForCausalLM.from_pretrained(
+ model = flute.integrations.huggingface.from_pretrained(
"radi-cho/Meta-Llama-3.1-8B-FLUTE",
# all of your favoriate HF flags will be forwarded
device_map="auto")- Loading and quantizing a dense model.
import flute.integrations.base
flute.integrations.base.prepare_model_flute(
name="model.model.layers",
module=model.model.layers, # for LLaMA-3 and Gemma-2
num_bits=num_bits,
group_size=group_size,
fake=False,
handle_hooks=True) # for `accelerate` hooksAfter this, the model can be used as normal. Please checkout the quantization guide for more information.
| Description | Supported (via pip) | Supported (build from source) |
|---|---|---|
| Input dtypes |
torch.float16 torch.bfloat16
|
|
| Bits |
4bit 3bit
|
2bit |
| Group Sizes |
32 64 128 256
|
❓ |
| GPUs |
A100 A6000 RTX 4090
|
H100 (unoptimized) |
[!WARNING] In the current release, we noticed
torch.bfloat16is slower thantorch.float16. This likely because of lack of tuning, and that Ampere GPUs lack a hardware acceleration forbfloat16vectorized atomic-add.
[!WARNING] We noticed several numerically unstable situations using
bits=4, group-size=256, GPU=A100, though this is relatively rare (8 of 9360 test cases failed). We also noticed correctness issues in some situations withbits=4, group-size=256, dtype=bfloat16, GPU=RTX4090(1 of 52 test cases failed). We will be looking into this, but we suggest avoiding these particular use cases (W4G256) for now.
[!NOTE] As of the current release, the kernel is shape-specialized due to legacy reasons (i.e., we tune tile sizes etc for each matrix shape). Please see the below chart for the supported use cases, as different platform and tensor parallel size changes the matrix shapes. We plan to add supports for a broad range of shapes in the near future. In the meantime, please let us know if you have any specific models in mind and we are happy to add support for them.
| Model | Single GPU / Pipeline Parallel | Tensor Parallel |
|---|---|---|
| LLaMA-3/3.1 (8B) | ✅ | |
| LLaMA-3/3.1 (70B) | ✅ | 2 or 4 GPUs |
| LLaMA-3.1 (405B) | ✅ | 4 or 8 GPUs |
| Gemma-2 (9B) | ✅ | |
| Gemma-2 (27B) | ✅ | 2 or 4 GPUs |
[!NOTE] The models we release here are trained on more data and hence different from those in the paper.
[!TIP] The HuggingFace Hub links are for
NFL W4G64quantization by default. To use theNFL W3G64quantization, add--revision nfl_w3g64.
| Wiki | C4 | PIQA | ARC-E | ARC-C | HellaSwag | Wino | Avg. | |
|---|---|---|---|---|---|---|---|---|
| Unquantized | 6.31 | 9.60 | 79.16 | 82.20 | 52.65 | 60.71 | 74.03 | 69.75 |
| NFL W4G64 | 6.24 | 10.06 | 79.38 | 81.61 | 51.54 | 59.57 | 73.56 | 69.13 |
| NFL W3G64 | 7.23 | 11.83 | 77.91 | 76.98 | 46.33 | 56.74 | 70.32 | 65.66 |
| Wiki | C4 | PIQA | ARC-E | ARC-C | HellaSwag | Wino | Avg. | |
|---|---|---|---|---|---|---|---|---|
| Unquantized | 2.82 | 7.18 | 82.81 | 85.31 | 59.64 | 67.49 | 82.00 | 75.45 |
| NFL W4G64 | 3.09 | 7.53 | 83.03 | 85.52 | 58.19 | 67.04 | 80.43 | 74.84 |
| NFL W3G64 | 4.29 | 8.91 | 82.04 | 83.29 | 54.78 | 64.99 | 78.14 | 72.65 |
Note that the weights are in the branch nf_w4g64 and thus --revision nf_w4g64 is needed since these are not on the default branch.
| Wiki | C4 | |
|---|---|---|
| NFL W4G64 | 6.78 | 11.11 |
| NFL W3G64 | 7.73 | 12.83 |
| Wiki | C4 | |
|---|---|---|
| NFL W4G64 | 4.15 | 9.18 |
| NFL W3G64 | 4.74 | 9.48 |
Note that the weights are in the branch nf_w4g64 and thus --revision nf_w4g64 is needed since these are not on the default branch.
| Wiki | C4 | PIQA | ARC-E | ARC-C | HellaSwag | Wino | Avg. | |
|---|---|---|---|---|---|---|---|---|
| Unquantized | 6.1 | 9.2 | 79.9 | 80.1 | 50.4 | 60.2 | 72.8 | 68.6 |
| NFL W4G64 | 6.11 | 9.38 | 79.33 | 79.79 | 49.74 | 59.22 | 73.95 | 68.41 |
| NFL W3G64 | 7.13 | 11.06 | 78.78 | 76.22 | 44.37 | 56.69 | 70.32 | 65.28 |
| Wiki | C4 | PIQA | ARC-E | ARC-C | HellaSwag | Wino | Avg. | |
|---|---|---|---|---|---|---|---|---|
| Unquantized | 2.9 | 6.9 | 82.4 | 86.9 | 60.3 | 66.4 | 80.6 | 75.3 |
| NFL W4G64 | 3.03 | 7.03 | 82.15 | 85.98 | 57.85 | 66.17 | 79.79 | 74.39 |
| NFL W3G64 | 4.15 | 8.10 | 80.74 | 83.71 | 55.29 | 64.05 | 78.45 | 72.45 |
| Wiki | C4 | |
|---|---|---|
| NFL W4G64 | 6.78 | 10.61 |
| NFL W3G64 | 7.75 | 12.28 |
| Wiki | C4 | |
|---|---|---|
| NFL W4G64 | 3.67 | 7.95 |
| NFL W3G64 | 4.90 | 10.86 |
| Wiki | C4 | PIQA | ARC-E | ARC-C | HellaSwag | Wino | Avg. | |
|---|---|---|---|---|---|---|---|---|
| Unquantized | 6.88 | 10.12 | 81.39 | 87.37 | 61.35 | 61.23 | 74.27 | 73.12 |
| NFL W4G64 | 6.49 | 10.35 | 81.28 | 86.24 | 59.30 | 60.40 | 75.30 | 72.50 |
| NFL W3G64 | 7.06 | 11.14 | 80.52 | 83.16 | 55.46 | 58.28 | 72.69 | 70.02 |
| Wiki | C4 | PIQA | ARC-E | ARC-C | HellaSwag | Wino | Avg. | |
|---|---|---|---|---|---|---|---|---|
| Unquantized | 5.70 | 8.98 | 83.24 | 87.84 | 62.88 | 65.35 | 79.24 | 75.71 |
| NFL W4G64 | 5.69 | 9.31 | 82.53 | 86.45 | 59.22 | 64.13 | 78.21 | 74.11 |
| Wiki | C4 | |
|---|---|---|
| NFL W4G64 | 6.88 | 11.02 |
| NFL W3G64 | 7.35 | 11.72 |
| Wiki | C4 | |
|---|---|---|
| NFL W4G64 | 5.91 | 9.71 |
We provide two APIs to quantize a custom models. The easist way is to use the command line interface.
python -m flute.integrations.base \
--pretrained_model_name_or_path meta-llama/Meta-Llama-3-70B-Instruct \
--save_directory Meta-Llama-3-70B-Instruct-NF4 \
--num_bits 4 \
--group_size 128The CLI essentially wraps around the following Python API,
from transformers import (
LlamaForCausalLM,
Gemma2ForCausalLM,
AutoModelForCausalLM)
import flute.integrations.base
model = AutoModelForCausalLM.from_pretrained(
pretrained_model_name_or_path,
device_map="cpu",
torch_dtype="auto")
if isinstance(model, (LlamaForCausalLM, Gemma2ForCausalLM)):
flute.integrations.base.prepare_model_flute(
name="model.model.layers",
module=model.model.layers,
num_bits=num_bits,
group_size=group_size,
fake=False)
else:
# more models to come
raise NotImplementedErrorWhile FLUTE has its own Normal Float (NF) implementation, we could convert an existing HuggingFace model quantized via bitsandbytes into FLUTE format. To do so, just add two lines to the Python API,
flute.integrations.base.prepare_model_flute(
name="model.model.layers",
module=model.model.layers,
num_bits=num_bits,
group_size=group_size,
fake=False,
+ prepare_bnb_layers=True,
+ default_bnb_dtype=torch.float16,
)It's worth noting that we do not support double quantization, and the conversion will materialize the first-level scales.
NFL initialized the lookup table and the scales with those from NF quantization. Then, it uses calibration data to learn the scales via straight through estimation for for the gradient with respect to the scales.
To use NFL quantization, call the following function before prepare_model_flute. We also provide an example jupyter notebook to illustrate the entire process.
import flute.integrations.learnable
flute.integrations.learnable.learn_scales(
model=model,
tokenizer=tokenizer,
num_bits=num_bits,
group_size=group_size,
custom_corpora=list_of_corpora,
samples=num_samples,
)At the moment, FLUTE kernel is specialized to the combination of GPU, matrix shapes, data types, bits, and group sizes. This means adding supporting new models requires tuning the kernel configurations for the corresponding use cases. We are hoping to add support for just-in-time tuning, but in the meantime, here are the ways to tune the kernel ahead-of-time.
- Reset the previously tuned kernel,
cp flute/csrc/qgemm_kernel_generated.template.cu flute/csrc/qgemm_kernel_generated.cu- Un-comment the combination(s) to tune in
flute/csrc/qgemm_kernel_raw_generated.cu,
INSTANTIATE_TEMPLATE(NUM_SMs, DTYPE, cute::uint16_t, __half2, BITS, GROUP_SIZE);Example for W4G64 on A100
-// INSTANTIATE_TEMPLATE(108, cute::half_t , cute::uint16_t, __half2 , 4, 64);
+INSTANTIATE_TEMPLATE(108, cute::half_t , cute::uint16_t, __half2 , 4, 64);
-// INSTANTIATE_TEMPLATE(108, cute::bfloat16_t, cute::uint16_t, __nv_bfloat162, 4, 64);
+INSTANTIATE_TEMPLATE(108, cute::bfloat16_t, cute::uint16_t, __nv_bfloat162, 4, 64);- Remove settings not tuned in
flute/csrc/qgemm.cpp,flute/__init__.py, andflute/ops.py
[!NOTE] Although including other settings could still build, it could break the linking process and require re-compiling the library.
Example for W4G64 on A100
diff --git a/flute/csrc/qgemm.cpp b/flute/csrc/qgemm.cpp
index 84bae95..c4a0236 100644
--- a/flute/csrc/qgemm.cpp
+++ b/flute/csrc/qgemm.cpp
@@ -314,3 +313,0 @@ qgemm_raw_simple(const at::Tensor& input,
- case 32: \
- RUN_QGEMM_RAW(T, NUM_BITS, 32); \
- break; \
@@ -320,6 +316,0 @@ qgemm_raw_simple(const at::Tensor& input,
- case 128: \
- RUN_QGEMM_RAW(T, NUM_BITS, 128); \
- break; \
- case 256: \
- RUN_QGEMM_RAW(T, NUM_BITS, 256); \
- break; \
@@ -335,6 +325,0 @@ qgemm_raw_simple(const at::Tensor& input,
- case 2: \
- RUN_QGEMM_RAW_SWITCH_GROUP_SIZE(T, 2); \
- break; \
- case 3: \
- RUN_QGEMM_RAW_SWITCH_GROUP_SIZE(T, 3); \
- break; \
@@ -381 +366 @@ TORCH_LIBRARY(flute, m) {
- // m.def("qgemm_raw_simple_80(Tensor input, Tensor weight, Tensor(a!) output, Tensor scales, Tensor table, Tensor table2, Tensor(b!) workspace, int
num_bits, int group_size, int template_id) -> ()");
+ m.def("qgemm_raw_simple_80(Tensor input, Tensor weight, Tensor(a!) output, Tensor scales, Tensor table, Tensor table2, Tensor(b!) workspace,
int num_bits, int group_size, int template_id) -> ()");
@@ -391 +376 @@ TORCH_LIBRARY_IMPL(flute, CUDA, m) {
- // m.impl("qgemm_raw_simple_80", &qgemm_raw_simple<cute::Int<108>>);
+ m.impl("qgemm_raw_simple_80", &qgemm_raw_simple<cute::Int<108>>);diff --git a/flute/__init__.py b/flute/__init__.py
index 34b1a26..f524841 100644
--- a/flute/__init__.py
+++ b/flute/__init__.py
@@ -69 +69 @@ QGEMM_SIMPLE_DICT = {
-# QGEMM_RAW_SIMPLE_DICT = {
+QGEMM_RAW_SIMPLE_DICT = {
@@ -71 +71 @@ QGEMM_SIMPLE_DICT = {
-# 108: cast(QGEMM_RAW_SIMPLE_TYPE, torch.ops.flute.qgemm_raw_simple_80),
+ 108: cast(QGEMM_RAW_SIMPLE_TYPE, torch.ops.flute.qgemm_raw_simple_80),
@@ -73 +73 @@ QGEMM_SIMPLE_DICT = {
-# }
+}
@@ -76 +76 @@ qgemm_simple = QGEMM_SIMPLE_DICT[NUM_SMS]
-qgemm_raw_simple = None # QGEMM_RAW_SIMPLE_DICT[NUM_SMS]
+qgemm_raw_simple = QGEMM_RAW_SIMPLE_DICT[NUM_SMS]diff --git a/flute/ops.py b/flute/ops.py
index 9fd91a2..80782ea 100644
--- a/flute/ops.py
+++ b/flute/ops.py
@@ -124 +124 @@ def _qgemm_simple_89_abstract(
-# @torch.library.register_fake("flute::qgemm_raw_simple_80")
+@torch.library.register_fake("flute::qgemm_raw_simple_80")- Build from source (see instructions below).
pip install -e . --no-build-isolation # `--no-build-isolation` is optionalDepending on the number of configurations to tune, this could take time in the order of tens of minutes to hours.
import torch
from flute.tune import TuneTask, tune_tasks_legacy
tasks = [
TuneTask(
M=1, # batch size (x sequence length, usually 1 for token-by-token generation)
N=1024, # parameter dimension (note when using tensor-parallelism, this could change)
K=4096, # parameter dimension (note when using tensor-parallelism, this could change)
num_bits=4, # number of bits
group_size=64, # group size
num_sms=108, # number of streaming multiprocessors of the GPU
dtype=torch.float16, # data type
device=torch.device("cuda:0")
),
]
tune_tasks_legacy(tasks)After this step is complete, artifacts will be saved in flute/data/.
# remove changes
git checkout -- flute/csrc/
# generating new dispatching logic based on tuning artifacts
bash scripts/codegen_tuned.sh
# remove changes
git checkout -- \
flute/ops.py \
flute/__init__.py
# Build
pip install -e . --no-build-isolationNote that if only one data type is tuned, you will also need to edit flute/utils.py.
Example
diff --git a/flute/utils.py b/flute/utils.py
index 5add543..13f49c0 100644
--- a/flute/utils.py
+++ b/flute/utils.py
@@ -270,7 +270,7 @@ def pack(
K, N = W.shape
template_ids = []
- for dtype in [torch.float16, torch.bfloat16]:
+ for dtype in [torch.float16]:
template_id = TEMPLATE_TUNED_WITHOUT_M_CONFIGS[(
NUM_SMS,
num_bits,Finally, please follow the examples in tests/ to verify that the kernel is working correctly.
- Clone the CUTLASS library.
# Unfortunately, the path is hard-coded as of now. If you install CUTLASS
# in a different directory, please make sure the corresponding path in
# `setup.py` is updated.
cd /workspace
git clone https://github.com/NVIDIA/cutlass.git
cd cutlass
git checkout v3.4.1- Build.
git clone https://github.com/HanGuo97/flute
cd flute
pip install -e .Note: the build process requires having the local CUDA version (nvcc --version) match PyTorch's CUDA. In situations in which the build process throws an error related to CUDA version mismatch, try adding --no-build-isolation.
Special thanks to Dmytro Ivchenko, Yijie Bei, and the Fireworks AI team for helpful discussion. If you find any of the models or code in this repo useful, please feel free to cite:
@inproceedings{flute2024,
title={Fast Matrix Multiplications for Lookup Table-Quantized LLMs},
author={Guo, Han and Brandon, William and Cholakov, Radostin and Ragan-Kelley, Jonathan and Xing, Eric and Kim, Yoon},
booktitle={Findings of the Association for Computational Linguistics: EMNLP 2024},
pages={12419--12433},
year={2024}
}
@article{higgs2024,
title={Pushing the Limits of Large Language Model Quantization via the Linearity Theorem},
author={Malinovskii, Vladimir and Panferov, Andrei and Ilin, Ivan and Guo, Han and Richt{\'a}rik, Peter and Alistarh, Dan},
journal={arXiv preprint arXiv:2411.17525},
year={2024}
}For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for flute
Similar Open Source Tools
flute
FLUTE (Flexible Lookup Table Engine for LUT-quantized LLMs) is a tool designed for uniform quantization and lookup table quantization of weights in lower-precision intervals. It offers flexibility in mapping intervals to arbitrary values through a lookup table. FLUTE supports various quantization formats such as int4, int3, int2, fp4, fp3, fp2, nf4, nf3, nf2, and even custom tables. The tool also introduces new quantization algorithms like Learned Normal Float (NFL) for improved performance and calibration data learning. FLUTE provides benchmarks, model zoo, and integration with frameworks like vLLM and HuggingFace for easy deployment and usage.
llm4regression
This project explores the capability of Large Language Models (LLMs) to perform regression tasks using in-context examples. It compares the performance of LLMs like GPT-4 and Claude 3 Opus with traditional supervised methods such as Linear Regression and Gradient Boosting. The project provides preprints and results demonstrating the strong performance of LLMs in regression tasks. It includes datasets, models used, and experiments on adaptation and contamination. The code and data for the experiments are available for interaction and analysis.
LightMem
LightMem is a lightweight and efficient memory management framework designed for Large Language Models and AI Agents. It provides a simple yet powerful memory storage, retrieval, and update mechanism to help you quickly build intelligent applications with long-term memory capabilities. The framework is minimalist in design, ensuring minimal resource consumption and fast response times. It offers a simple API for easy integration into applications with just a few lines of code. LightMem's modular architecture supports custom storage engines and retrieval strategies, making it flexible and extensible. It is compatible with various cloud APIs like OpenAI and DeepSeek, as well as local models such as Ollama and vLLM.

YuLan-Mini
YuLan-Mini is a lightweight language model with 2.4 billion parameters that achieves performance comparable to industry-leading models despite being pre-trained on only 1.08T tokens. It excels in mathematics and code domains. The repository provides pre-training resources, including data pipeline, optimization methods, and annealing approaches. Users can pre-train their own language models, perform learning rate annealing, fine-tune the model, research training dynamics, and synthesize data. The team behind YuLan-Mini is AI Box at Renmin University of China. The code is released under the MIT License with future updates on model weights usage policies. Users are advised on potential safety concerns and ethical use of the model.

EVE
EVE is an official PyTorch implementation of Unveiling Encoder-Free Vision-Language Models. The project aims to explore the removal of vision encoders from Vision-Language Models (VLMs) and transfer LLMs to encoder-free VLMs efficiently. It also focuses on bridging the performance gap between encoder-free and encoder-based VLMs. EVE offers a superior capability with arbitrary image aspect ratio, data efficiency by utilizing publicly available data for pre-training, and training efficiency with a transparent and practical strategy for developing a pure decoder-only architecture across modalities.
FlipAttack
FlipAttack is a jailbreak attack tool designed to exploit black-box Language Model Models (LLMs) by manipulating text inputs. It leverages insights into LLMs' autoregressive nature to construct noise on the left side of the input text, deceiving the model and enabling harmful behaviors. The tool offers four flipping modes to guide LLMs in denoising and executing malicious prompts effectively. FlipAttack is characterized by its universality, stealthiness, and simplicity, allowing users to compromise black-box LLMs with just one query. Experimental results demonstrate its high success rates against various LLMs, including GPT-4o and guardrail models.

llm.nvim
llm.nvim is a universal plugin for a large language model (LLM) designed to enable users to interact with LLM within neovim. Users can customize various LLMs such as gpt, glm, kimi, and local LLM. The plugin provides tools for optimizing code, comparing code, translating text, and more. It also supports integration with free models from Cloudflare, Github models, siliconflow, and others. Users can customize tools, chat with LLM, quickly translate text, and explain code snippets. The plugin offers a flexible window interface for easy interaction and customization.
gollama
Gollama is a tool designed for managing Ollama models through a Text User Interface (TUI). Users can list, inspect, delete, copy, and push Ollama models, as well as link them to LM Studio. The application offers interactive model selection, sorting by various criteria, and actions using hotkeys. It provides features like sorting and filtering capabilities, displaying model metadata, model linking, copying, pushing, and more. Gollama aims to be user-friendly and useful for managing models, especially for cleaning up old models.

InternVL
InternVL scales up the ViT to _**6B parameters**_ and aligns it with LLM. It is a vision-language foundation model that can perform various tasks, including: **Visual Perception** - Linear-Probe Image Classification - Semantic Segmentation - Zero-Shot Image Classification - Multilingual Zero-Shot Image Classification - Zero-Shot Video Classification **Cross-Modal Retrieval** - English Zero-Shot Image-Text Retrieval - Chinese Zero-Shot Image-Text Retrieval - Multilingual Zero-Shot Image-Text Retrieval on XTD **Multimodal Dialogue** - Zero-Shot Image Captioning - Multimodal Benchmarks with Frozen LLM - Multimodal Benchmarks with Trainable LLM - Tiny LVLM InternVL has been shown to achieve state-of-the-art results on a variety of benchmarks. For example, on the MMMU image classification benchmark, InternVL achieves a top-1 accuracy of 51.6%, which is higher than GPT-4V and Gemini Pro. On the DocVQA question answering benchmark, InternVL achieves a score of 82.2%, which is also higher than GPT-4V and Gemini Pro. InternVL is open-sourced and available on Hugging Face. It can be used for a variety of applications, including image classification, object detection, semantic segmentation, image captioning, and question answering.
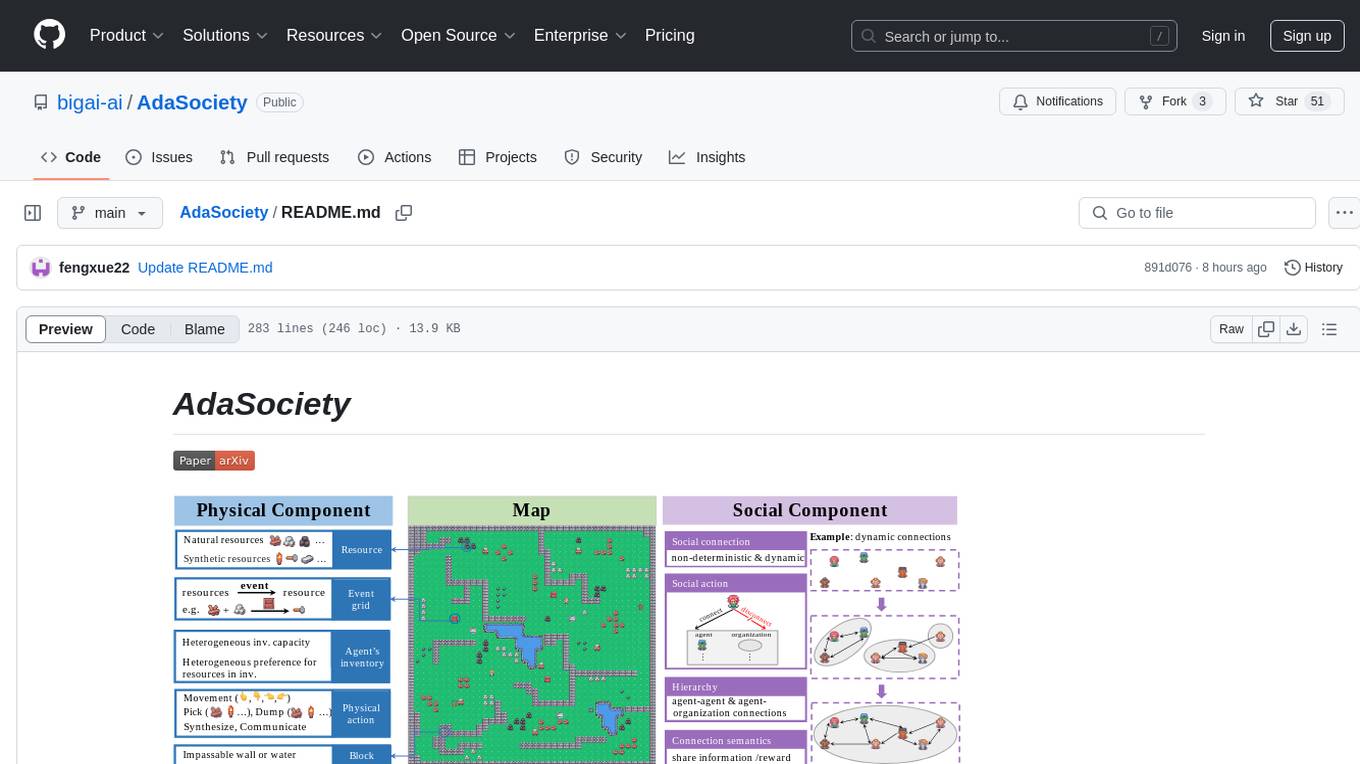
AdaSociety
AdaSociety is a multi-agent environment designed for simulating social structures and decision-making processes. It offers built-in resources, events, and player interactions. Users can customize the environment through JSON configuration or custom Python code. The environment supports training agents using RLlib and LLM frameworks. It provides a platform for studying multi-agent systems and social dynamics.

DeepRetrieval
DeepRetrieval is a tool designed to enhance search engines and retrievers using Large Language Models (LLMs) and Reinforcement Learning (RL). It allows LLMs to learn how to search effectively by integrating with search engine APIs and customizing reward functions. The tool provides functionalities for data preparation, training, evaluation, and monitoring search performance. DeepRetrieval aims to improve information retrieval tasks by leveraging advanced AI techniques.

spiceai
Spice is a portable runtime written in Rust that offers developers a unified SQL interface to materialize, accelerate, and query data from any database, data warehouse, or data lake. It connects, fuses, and delivers data to applications, machine-learning models, and AI-backends, functioning as an application-specific, tier-optimized Database CDN. Built with industry-leading technologies such as Apache DataFusion, Apache Arrow, Apache Arrow Flight, SQLite, and DuckDB. Spice makes it fast and easy to query data from one or more sources using SQL, co-locating a managed dataset with applications or machine learning models, and accelerating it with Arrow in-memory, SQLite/DuckDB, or attached PostgreSQL for fast, high-concurrency, low-latency queries.

llm4s
llm4s is an experimental Scala 3 bindings tool for llama.cpp using Slinc. It provides version compatibility with Scala 3.3.0 and JDK 17, 19 for llama.cpp. Users can utilize llm4s to work with llama.cpp shared library and model, enabling completion and embeddings functionalities in Scala.

MOSS-TTS
MOSS-TTS Family is an open-source speech and sound generation model family designed for high-fidelity, high-expressiveness, and complex real-world scenarios. It includes five production-ready models: MOSS-TTS, MOSS-TTSD, MOSS-VoiceGenerator, MOSS-TTS-Realtime, and MOSS-SoundEffect, each serving specific purposes in speech generation, dialogue, voice design, real-time interactions, and sound effect generation. The models offer features like long-speech generation, fine-grained control over phonemes and duration, multilingual synthesis, voice cloning, and real-time voice agents.
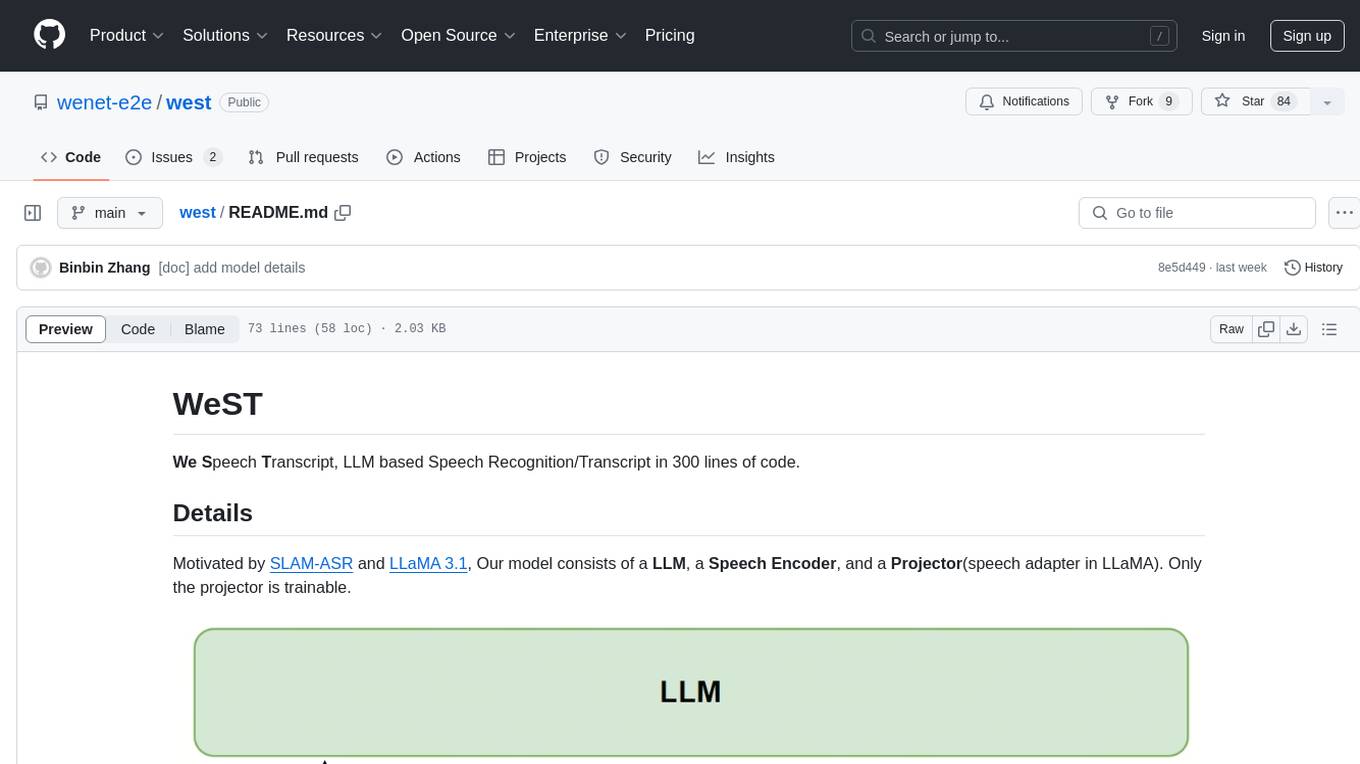
west
WeST is a Speech Recognition/Transcript tool developed in 300 lines of code, inspired by SLAM-ASR and LLaMA 3.1. The model includes a Language Model (LLM), a Speech Encoder, and a trainable Projector. It requires training data in jsonl format with 'wav' and 'txt' entries. WeST can be used for training and decoding speech recognition models.

MooER
MooER (摩耳) is an LLM-based speech recognition and translation model developed by Moore Threads. It allows users to transcribe speech into text (ASR) and translate speech into other languages (AST) in an end-to-end manner. The model was trained using 5K hours of data and is now also available with an 80K hours version. MooER is the first LLM-based speech model trained and inferred using domestic GPUs. The repository includes pretrained models, inference code, and a Gradio demo for a better user experience.
For similar tasks

byteir
The ByteIR Project is a ByteDance model compilation solution. ByteIR includes compiler, runtime, and frontends, and provides an end-to-end model compilation solution. Although all ByteIR components (compiler/runtime/frontends) are together to provide an end-to-end solution, and all under the same umbrella of this repository, each component technically can perform independently. The name, ByteIR, comes from a legacy purpose internally. The ByteIR project is NOT an IR spec definition project. Instead, in most scenarios, ByteIR directly uses several upstream MLIR dialects and Google Mhlo. Most of ByteIR compiler passes are compatible with the selected upstream MLIR dialects and Google Mhlo.

ScandEval
ScandEval is a framework for evaluating pretrained language models on mono- or multilingual language tasks. It provides a unified interface for benchmarking models on a variety of tasks, including sentiment analysis, question answering, and machine translation. ScandEval is designed to be easy to use and extensible, making it a valuable tool for researchers and practitioners alike.

opencompass
OpenCompass is a one-stop platform for large model evaluation, aiming to provide a fair, open, and reproducible benchmark for large model evaluation. Its main features include: * Comprehensive support for models and datasets: Pre-support for 20+ HuggingFace and API models, a model evaluation scheme of 70+ datasets with about 400,000 questions, comprehensively evaluating the capabilities of the models in five dimensions. * Efficient distributed evaluation: One line command to implement task division and distributed evaluation, completing the full evaluation of billion-scale models in just a few hours. * Diversified evaluation paradigms: Support for zero-shot, few-shot, and chain-of-thought evaluations, combined with standard or dialogue-type prompt templates, to easily stimulate the maximum performance of various models. * Modular design with high extensibility: Want to add new models or datasets, customize an advanced task division strategy, or even support a new cluster management system? Everything about OpenCompass can be easily expanded! * Experiment management and reporting mechanism: Use config files to fully record each experiment, and support real-time reporting of results.

openvino.genai
The GenAI repository contains pipelines that implement image and text generation tasks. The implementation uses OpenVINO capabilities to optimize the pipelines. Each sample covers a family of models and suggests certain modifications to adapt the code to specific needs. It includes the following pipelines: 1. Benchmarking script for large language models 2. Text generation C++ samples that support most popular models like LLaMA 2 3. Stable Diffuison (with LoRA) C++ image generation pipeline 4. Latent Consistency Model (with LoRA) C++ image generation pipeline

GPT4Point
GPT4Point is a unified framework for point-language understanding and generation. It aligns 3D point clouds with language, providing a comprehensive solution for tasks such as 3D captioning and controlled 3D generation. The project includes an automated point-language dataset annotation engine, a novel object-level point cloud benchmark, and a 3D multi-modality model. Users can train and evaluate models using the provided code and datasets, with a focus on improving models' understanding capabilities and facilitating the generation of 3D objects.

octopus-v4
The Octopus-v4 project aims to build the world's largest graph of language models, integrating specialized models and training Octopus models to connect nodes efficiently. The project focuses on identifying, training, and connecting specialized models. The repository includes scripts for running the Octopus v4 model, methods for managing the graph, training code for specialized models, and inference code. Environment setup instructions are provided for Linux with NVIDIA GPU. The Octopus v4 model helps users find suitable models for tasks and reformats queries for effective processing. The project leverages Language Large Models for various domains and provides benchmark results. Users are encouraged to train and add specialized models following recommended procedures.

Awesome-LLM-RAG
This repository, Awesome-LLM-RAG, aims to record advanced papers on Retrieval Augmented Generation (RAG) in Large Language Models (LLMs). It serves as a resource hub for researchers interested in promoting their work related to LLM RAG by updating paper information through pull requests. The repository covers various topics such as workshops, tutorials, papers, surveys, benchmarks, retrieval-enhanced LLMs, RAG instruction tuning, RAG in-context learning, RAG embeddings, RAG simulators, RAG search, RAG long-text and memory, RAG evaluation, RAG optimization, and RAG applications.

stm32ai-modelzoo
The STM32 AI model zoo is a collection of reference machine learning models optimized to run on STM32 microcontrollers. It provides a large collection of application-oriented models ready for re-training, scripts for easy retraining from user datasets, pre-trained models on reference datasets, and application code examples generated from user AI models. The project offers training scripts for transfer learning or training custom models from scratch. It includes performances on reference STM32 MCU and MPU for float and quantized models. The project is organized by application, providing step-by-step guides for training and deploying models.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.