
BizFinBench
A Business-Driven Real-World Financial Benchmark for Evaluating LLMs
Stars: 203
BizFinBench is a benchmark tool designed for evaluating large language models (LLMs) in logic-heavy and precision-critical domains such as finance. It comprises over 100,000 bilingual financial questions rooted in real-world business scenarios. The tool covers five dimensions: numerical calculation, reasoning, information extraction, prediction recognition, and knowledge-based question answering, mapped to nine fine-grained categories. BizFinBench aims to assess the capacity of LLMs in real-world financial scenarios and provides insights into their strengths and limitations.
README:
Guilong Lu1,* , Xuntao Guo1,2,*, Rongjunchen Zhang1,♠, Wenqiao Zhu1, Ji Liu1,♠
*Co-first authors, ♠Corresponding author, {zhangrongjunchen, liuji}@myhexin.com
📖Paper |🏠Homepage|🤗Huggingface
Large language models excel across general tasks, yet judging their reliability in logic‑heavy, precision‑critical domains such as finance, law and healthcare is still difficult. To address this challenge, we propose BizFinBench, the first benchmark grounded in real-world financial applications. BizFinBench comprises over 100,000+ bilingual (English & Chinese) financial questions, each rooted in real-world business scenarios. The first public release, BizFinBench.v1, delivers 6,781 well annotated Chinese queries, covering five dimensions: numerical calculation, reasoning, information extraction, prediction recognition and knowledge‐based question answering, which are mapped to nine fine-grained categories.
-
🚀 [04/07/2025] External API support is now live—evaluate BizFinBench with your own endpoints in just a few calls.
-
🚀 [16/05/2025] We released BizFinBench.v1 benchmark, the first benchmark grounded in real-world financial applications.
- 🔥 Benchmark: We propose BizFinBench, the first evaluation benchmark in the financial domain that integrates business-oriented tasks, covering 5 dimensions and 9 categories. It is designed to assess the capacity of LLMs in real-world financial scenarios.
- 🔥 Judge model: We design a novel evaluation method, i.e., Iterajudge, which enhances the capability of LLMs as a judge by refining their decision boundaries in specific financial evaluation tasks.
- 🔥 key insights: We conduct a comprehensive evaluation with 25 LLMs based on BizFinBench, uncovering key insights into their strengths and limitations in financial applications.
This dataset contains multiple subtasks, each focusing on a different financial understanding and reasoning ability, as follows:

| Dataset | Description | Evaluation Dimensions | Volume |
|---|---|---|---|
| Anomalous Event Attribution | A financial anomaly attribution evaluation dataset assessing models' ability to trace stock fluctuations based on given information (e.g., timestamps, news articles, financial reports, and stock movements). | Causal consistency, information relevance, noise resistance | 1,064 |
| Financial Numerical Computation | A financial numerical computation dataset evaluating models' ability to perform accurate numerical calculations in financial scenarios, including interest rate calculations, gain/loss computations, etc. | Calculation accuracy, unit consistency | 581 |
| Financial Time Reasoning | A financial temporal reasoning evaluation dataset assessing models' ability to comprehend and reason about time-based financial events, such as "the previous trading day" or "the first trading day of the year." | Temporal reasoning correctness | 514 |
| Financial Data Description | A financial data description evaluation dataset measuring models' ability to analyze and describe structured/unstructured financial data, e.g., "the stock price first rose to XX before falling to XX." | Trend accuracy, data consistency | 1,461 |
| Stock Price Prediction | A stock price movement prediction dataset evaluating models' ability to forecast future stock price trends based on historical data, financial indicators, and market news. | Trend judgment, causal rationality | 497 |
| Financial Named Entity Recognition | A financial named entity recognition dataset assessing models' ability to identify entities (Person, Organization, Market, Location, Financial Products, Date/Time) in short/long financial news. | Recognition accuracy, entity category correctness | 433 |
| Emotion_Recognition | A financial sentiment recognition dataset evaluating models' ability to discern nuanced user emotions in complex financial market environments. Inputs include multi-dimensional data such as market conditions, news, research reports, user holdings, and queries, covering six emotion categories: optimism, anxiety, pessimism, excitement, calmness, and regret. | Emotion classification accuracy, implicit information extraction and reasoning correctness | 600 |
| Financial Tool Usage | A financial tool usage dataset evaluating models' ability to understand user queries and appropriately utilize various financial tools (investment analysis, market research, information retrieval, etc.) to solve real-world problems. Tools include calculators, financial encyclopedia queries, search engines, data queries, news queries, economic calendars, and company lookups. Models must accurately interpret user intent, select appropriate tools, input correct parameters, and coordinate multiple tools when necessary. | Tool selection rationality, parameter input accuracy, multi-tool coordination capability | 641 |
| Financial Knowledge QA | A financial encyclopedia QA dataset assessing models' understanding and response accuracy regarding core financial knowledge, covering key domains: financial fundamentals, markets, investment theories, macroeconomics, etc. | Query comprehension accuracy, knowledge coverage breadth, answer accuracy and professionalism | 990 |

llm-eval
├── README.md
├── benchmark_code
├── config # All custom sample configs can be found in this folder
├── envs #env settings
├── inference # All inference-engine-related code is in this folder
├── post_eval.py # Evaluation launcher after inference is finished
├── reqirements.txt
├── run.py # Entry point for the entire evaluation workflow
├── run.sh # Sample execution script for launching an evaluation; maintain your own run.sh as needed
├── scripts # Reference run.sh scripts
├── tools # tools
├── statistic.py # Aggregates final evaluation statistics
└── utils
pip install -r requirements.txtexport MODEL_PATH=model/Qwen2.5-0.5B # Path to the model to be evaluated
export REMOTE_MODEL_PORT=16668
export REMOTE_MODEL_URL=http://127.0.0.1:${REMOTE_MODEL_PORT}/model
export MODEL_NAME=Qwen2.5-0.5B
export PROMPT_TYPE=chat_template # Hithink llama3 llama2 none qwen chat_template; chat_template is recommended
# First start the model as a service
python inference/predict_multi_gpu.py \
--model ${MODEL_PATH} \
--server_port ${REMOTE_MODEL_PORT} \
--prompt ${PROMPT_TYPE} \
--preprocess preprocess \
--run_forever \
--max_new_tokens 4096 \
--tensor_parallel ${TENSOR_PARALLEL} &
# Pass in the config file path to start evaluation
python run.py --config config/offical/eval_fin_eval_diamond.yaml --model_name ${MODEL_NAME}export MODEL_PATH=model/Qwen2.5-0.5B # Path to the model to be evaluated
export REMOTE_MODEL_PORT=16668
export REMOTE_MODEL_URL=http://127.0.0.1:${REMOTE_MODEL_PORT}/model
export MODEL_NAME=Qwen2.5-0.5B
export PROMPT_TYPE=chat_template # llama3 llama2 none qwen chat_template; chat_template is recommended
# First start the model as a service
python inference/predict_multi_gpu.py \
--model ${MODEL_PATH} \
--server_port ${REMOTE_MODEL_PORT} \
--prompt ${PROMPT_TYPE} \
--preprocess preprocess \
--run_forever \
--max_new_tokens 4096 \
--tensor_parallel ${TENSOR_PARALLEL} \
--low_vram &
# Start the judge model
export JUDGE_MODEL_PATH=/mnt/data/llm/models/base/Qwen2.5-7B
export JUDGE_TENSOR_PARALLEL=1
export JUDGE_MODEL_PORT=16667
python inference/predict_multi_gpu.py \
--model ${JUDGE_MODEL_PATH} \
--server_port ${JUDGE_MODEL_PORT} \
--prompt chat_template \
--preprocess preprocess \
--run_forever \
--manual_start \
--max_new_tokens 4096 \
--tensor_parallel ${JUDGE_TENSOR_PARALLEL} \
--low_vram &
# Pass in the config file path to start evaluation
python run.py --config "config/offical/eval_fin_eval.yaml" --model_name ${MODEL_NAME}Note: Add the
--manual_startargument when launching the judge model, because the judge must wait until the main model finishes inference before starting (this is handled automatically by themaybe_start_judge_modelfunction inrun.py).
export API_NAME=chatgpt # The api name, currently support chatgpt
export API_KEY=xxx # Your api key
export MODEL_NAME=gpt-4.1
# Pass in the config file path to start evaluation
python run.py --config config/offical/eval_fin_eval_diamond.yaml --model_name ${MODEL_NAME}Note: You can adjust the API’s queries-per-second limit by modifying the semaphore_limit setting in envs/constants.py. e.g., GPTClient(api_name=api_name,api_key=api_key,model_name=model_name,base_url='https://api.openai.com/v1/chat/completions', timeout=600, semaphore_limit=5)
The models are evaluated across multiple tasks, with results color-coded to represent the top three performers for each task:
- 🥇 indicates the top-performing model.
- 🥈 represents the second-best result.
- 🥉 denotes the third-best performance.
| Model | AEA | FNC | FTR | FTU | FQA | FDD | ER | SP | FNER | Average |
|---|---|---|---|---|---|---|---|---|---|---|
| Proprietary LLMs | ||||||||||
| ChatGPT-o3 | 🥈 86.23 | 61.30 | 🥈 75.36 | 🥇 89.15 | 🥈 91.25 | 🥉 98.55 | 🥉 44.48 | 53.27 | 65.13 | 🥇 73.86 |
| ChatGPT-o4-mini | 🥉 85.62 | 60.10 | 71.23 | 74.40 | 90.27 | 95.73 | 🥇 47.67 | 52.32 | 64.24 | 71.29 |
| GPT-4o | 79.42 | 56.51 | 🥇 76.20 | 82.37 | 87.79 | 🥇 98.84 | 🥈 45.33 | 54.33 | 65.37 | 🥉 71.80 |
| Gemini-2.0-Flash | 🥇 86.94 | 🥉 62.67 | 73.97 | 82.55 | 90.29 | 🥈 98.62 | 22.17 | 🥉 56.14 | 54.43 | 69.75 |
| Claude-3.5-Sonnet | 84.68 | 🥈 63.18 | 42.81 | 🥈 88.05 | 87.35 | 96.85 | 16.67 | 47.60 | 63.09 | 65.59 |
| Open Source LLMs | ||||||||||
| Qwen2.5-7B-Instruct | 73.87 | 32.88 | 39.38 | 79.03 | 83.34 | 78.93 | 37.50 | 51.91 | 30.31 | 56.35 |
| Qwen2.5-72B-Instruct | 69.27 | 54.28 | 70.72 | 85.29 | 87.79 | 97.43 | 35.33 | 55.13 | 54.02 | 67.70 |
| Qwen2.5-VL-3B | 53.85 | 15.92 | 17.29 | 8.95 | 81.60 | 59.44 | 39.50 | 52.49 | 21.57 | 38.96 |
| Qwen2.5-VL-7B | 73.87 | 32.71 | 40.24 | 77.85 | 83.94 | 77.41 | 38.83 | 51.91 | 33.40 | 56.68 |
| Qwen2.5-VL-14B | 37.12 | 41.44 | 53.08 | 82.07 | 84.23 | 7.97 | 37.33 | 54.93 | 47.47 | 49.52 |
| Qwen2.5-VL-32B | 76.79 | 50.00 | 62.16 | 83.57 | 85.30 | 95.95 | 40.50 | 54.93 | 🥉 68.36 | 68.62 |
| Qwen2.5-VL-72B | 69.55 | 54.11 | 69.86 | 85.18 | 87.37 | 97.34 | 35.00 | 54.94 | 54.41 | 67.53 |
| Qwen3-1.7B | 77.40 | 35.80 | 33.40 | 75.82 | 73.81 | 78.62 | 22.40 | 48.53 | 11.23 | 50.78 |
| Qwen3-4B | 83.60 | 47.40 | 50.00 | 78.19 | 82.24 | 80.16 | 42.20 | 50.51 | 25.19 | 59.94 |
| Qwen3-14B | 84.20 | 58.20 | 65.80 | 82.19 | 84.12 | 92.91 | 33.00 | 52.31 | 50.70 | 67.05 |
| Qwen3-32B | 83.80 | 59.60 | 64.60 | 85.12 | 85.43 | 95.37 | 39.00 | 52.26 | 49.19 | 68.26 |
| Xuanyuan3-70B | 12.14 | 19.69 | 15.41 | 80.89 | 86.51 | 83.90 | 29.83 | 52.62 | 37.33 | 46.48 |
| Llama-3.1-8B-Instruct | 73.12 | 22.09 | 2.91 | 77.42 | 76.18 | 69.09 | 29.00 | 54.21 | 36.56 | 48.95 |
| Llama-3.1-70B-Instruct | 16.26 | 34.25 | 56.34 | 80.64 | 79.97 | 86.90 | 33.33 | 🥇 62.16 | 45.95 | 55.09 |
| Llama 4 Scout | 73.60 | 45.80 | 44.20 | 85.02 | 85.21 | 92.32 | 25.60 | 55.76 | 43.00 | 61.17 |
| DeepSeek-V3 (671B) | 74.34 | 61.82 | 72.60 | 🥈 86.54 | 🥉 91.07 | 98.11 | 32.67 | 55.73 | 🥈 71.24 | 71.57 |
| DeepSeek-R1 (671B) | 80.36 | 🥇 64.04 | 🥉 75.00 | 81.96 | 🥇 91.44 | 98.41 | 39.67 | 55.13 | 🥇 71.46 | 🥈 73.05 |
| QwQ-32B | 84.02 | 52.91 | 64.90 | 84.81 | 89.60 | 94.20 | 34.50 | 🥈 56.68 | 30.27 | 65.77 |
| DeepSeek-R1-Distill-Qwen-14B | 71.33 | 44.35 | 16.95 | 81.96 | 85.52 | 92.81 | 39.50 | 50.20 | 52.76 | 59.49 |
| DeepSeek-R1-Distill-Qwen-32B | 73.68 | 51.20 | 50.86 | 83.27 | 87.54 | 97.81 | 41.50 | 53.92 | 56.80 | 66.29 |
@article{lu2025bizfinbench,
title={BizFinBench: A Business-Driven Real-World Financial Benchmark for Evaluating LLMs},
author={Lu, Guilong and Guo, Xuntao and Zhang, Rongjunchen and Zhu, Wenqiao and Liu, Ji},
journal={arXiv preprint arXiv:2505.19457},
year={2025}
}
Usage and License Notices: The data and code are intended and licensed for research use only.
License: Attribution-NonCommercial 4.0 International It should abide by the policy of OpenAI: https://openai.com/policies/terms-of-use
- We would like to thank Weijie Zhang for his contribution to the development of the inference engine.
- This work leverages vLLM as the backend model server for evaluation purposes.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for BizFinBench
Similar Open Source Tools
BizFinBench
BizFinBench is a benchmark tool designed for evaluating large language models (LLMs) in logic-heavy and precision-critical domains such as finance. It comprises over 100,000 bilingual financial questions rooted in real-world business scenarios. The tool covers five dimensions: numerical calculation, reasoning, information extraction, prediction recognition, and knowledge-based question answering, mapped to nine fine-grained categories. BizFinBench aims to assess the capacity of LLMs in real-world financial scenarios and provides insights into their strengths and limitations.

YuLan-Mini
YuLan-Mini is a lightweight language model with 2.4 billion parameters that achieves performance comparable to industry-leading models despite being pre-trained on only 1.08T tokens. It excels in mathematics and code domains. The repository provides pre-training resources, including data pipeline, optimization methods, and annealing approaches. Users can pre-train their own language models, perform learning rate annealing, fine-tune the model, research training dynamics, and synthesize data. The team behind YuLan-Mini is AI Box at Renmin University of China. The code is released under the MIT License with future updates on model weights usage policies. Users are advised on potential safety concerns and ethical use of the model.

denodo-ai-sdk
Denodo AI SDK is a tool that enables users to create AI chatbots and agents that provide accurate and context-aware answers using enterprise data. It connects to the Denodo Platform, supports popular LLMs and vector stores, and includes a sample chatbot and simple APIs for quick setup. The tool also offers benchmarks for evaluating LLM performance and provides guidance on configuring DeepQuery for different LLM providers.
llmq
llm.q is an implementation of (quantized) large language model training in CUDA, inspired by llm.c. It is particularly aimed at medium-sized training setups, i.e., a single node with multiple GPUs. The code is written in C++20 and requires CUDA 12 or later. It depends on nccl for communication, and cudnn for fast attention. Multi-GPU training can either be run in multi-process mode (requires OpenMPI) or in multi-thread mode. Additional header-only dependencies are automatically downloaded by cmake during the build process. The tool provides detailed instructions on data preparation, training runs, inspecting logs, evaluations, and a larger example for real training runs. It also offers detailed usage instructions covering model configuration, data configuration, optimization parameters, checkpointing, output, low-bit settings, activation checkpointing/recomputation, multi-GPU settings, offloading, algorithm selection, and Python bindings. The code organization includes directories for kernels, models, training, and utilities. Speed benchmarks for different GPU configurations are provided, along with testing details for recomputation, fixed reference, and Python reference tests.

nntrainer
NNtrainer is a software framework for training neural network models on devices with limited resources. It enables on-device fine-tuning of neural networks using user data for personalization. NNtrainer supports various machine learning algorithms and provides examples for tasks such as few-shot learning, ResNet, VGG, and product rating. It is optimized for embedded devices and utilizes CBLAS and CUBLAS for accelerated calculations. NNtrainer is open source and released under the Apache License version 2.0.

goodai-ltm-benchmark
This repository contains code and data for replicating experiments on Long-Term Memory (LTM) abilities of conversational agents. It includes a benchmark for testing agents' memory performance over long conversations, evaluating tasks requiring dynamic memory upkeep and information integration. The repository supports various models, datasets, and configurations for benchmarking and reporting results.
LightMem
LightMem is a lightweight and efficient memory management framework designed for Large Language Models and AI Agents. It provides a simple yet powerful memory storage, retrieval, and update mechanism to help you quickly build intelligent applications with long-term memory capabilities. The framework is minimalist in design, ensuring minimal resource consumption and fast response times. It offers a simple API for easy integration into applications with just a few lines of code. LightMem's modular architecture supports custom storage engines and retrieval strategies, making it flexible and extensible. It is compatible with various cloud APIs like OpenAI and DeepSeek, as well as local models such as Ollama and vLLM.

CogVLM2
CogVLM2 is a new generation of open source models that offer significant improvements in benchmarks such as TextVQA and DocVQA. It supports 8K content length, image resolution up to 1344 * 1344, and both Chinese and English languages. The project provides basic calling methods, fine-tuning examples, and OpenAI API format calling examples to help developers quickly get started with the model.
linghe
A library of high-performance kernels for LLM training, linghe is designed for MoE training with FP8 quantization. It provides fused quantization kernels, memory-efficiency kernels, and implementation-optimized kernels. The repo benchmarks on H800 with specific configurations and offers examples in tests. Users can refer to the API for more details.

are-copilots-local-yet
Current trends and state of the art for using open & local LLM models as copilots to complete code, generate projects, act as shell assistants, automatically fix bugs, and more. This document is a curated list of local Copilots, shell assistants, and related projects, intended to be a resource for those interested in a survey of the existing tools and to help developers discover the state of the art for projects like these.

Awesome-Tabular-LLMs
This repository is a collection of papers on Tabular Large Language Models (LLMs) specialized for processing tabular data. It includes surveys, models, and applications related to table understanding tasks such as Table Question Answering, Table-to-Text, Text-to-SQL, and more. The repository categorizes the papers based on key ideas and provides insights into the advancements in using LLMs for processing diverse tables and fulfilling various tabular tasks based on natural language instructions.

Awesome-LLM-Constrained-Decoding
Awesome-LLM-Constrained-Decoding is a curated list of papers, code, and resources related to constrained decoding of Large Language Models (LLMs). The repository aims to facilitate reliable, controllable, and efficient generation with LLMs by providing a comprehensive collection of materials in this domain.
llm-deploy
LLM-Deploy focuses on the theory and practice of model/LLM reasoning and deployment, aiming to be your partner in mastering the art of LLM reasoning and deployment. Whether you are a newcomer to this field or a senior professional seeking to deepen your skills, you can find the key path to successfully deploy large language models here. The project covers reasoning and deployment theories, model and service optimization practices, and outputs from experienced engineers. It serves as a valuable resource for algorithm engineers and individuals interested in reasoning deployment.

TRACE
TRACE is a temporal grounding video model that utilizes causal event modeling to capture videos' inherent structure. It presents a task-interleaved video LLM model tailored for sequential encoding/decoding of timestamps, salient scores, and textual captions. The project includes various model checkpoints for different stages and fine-tuning on specific datasets. It provides evaluation codes for different tasks like VTG, MVBench, and VideoMME. The repository also offers annotation files and links to raw videos preparation projects. Users can train the model on different tasks and evaluate the performance based on metrics like CIDER, METEOR, SODA_c, F1, mAP, Hit@1, etc. TRACE has been enhanced with trace-retrieval and trace-uni models, showing improved performance on dense video captioning and general video understanding tasks.
llm4regression
This project explores the capability of Large Language Models (LLMs) to perform regression tasks using in-context examples. It compares the performance of LLMs like GPT-4 and Claude 3 Opus with traditional supervised methods such as Linear Regression and Gradient Boosting. The project provides preprints and results demonstrating the strong performance of LLMs in regression tasks. It includes datasets, models used, and experiments on adaptation and contamination. The code and data for the experiments are available for interaction and analysis.
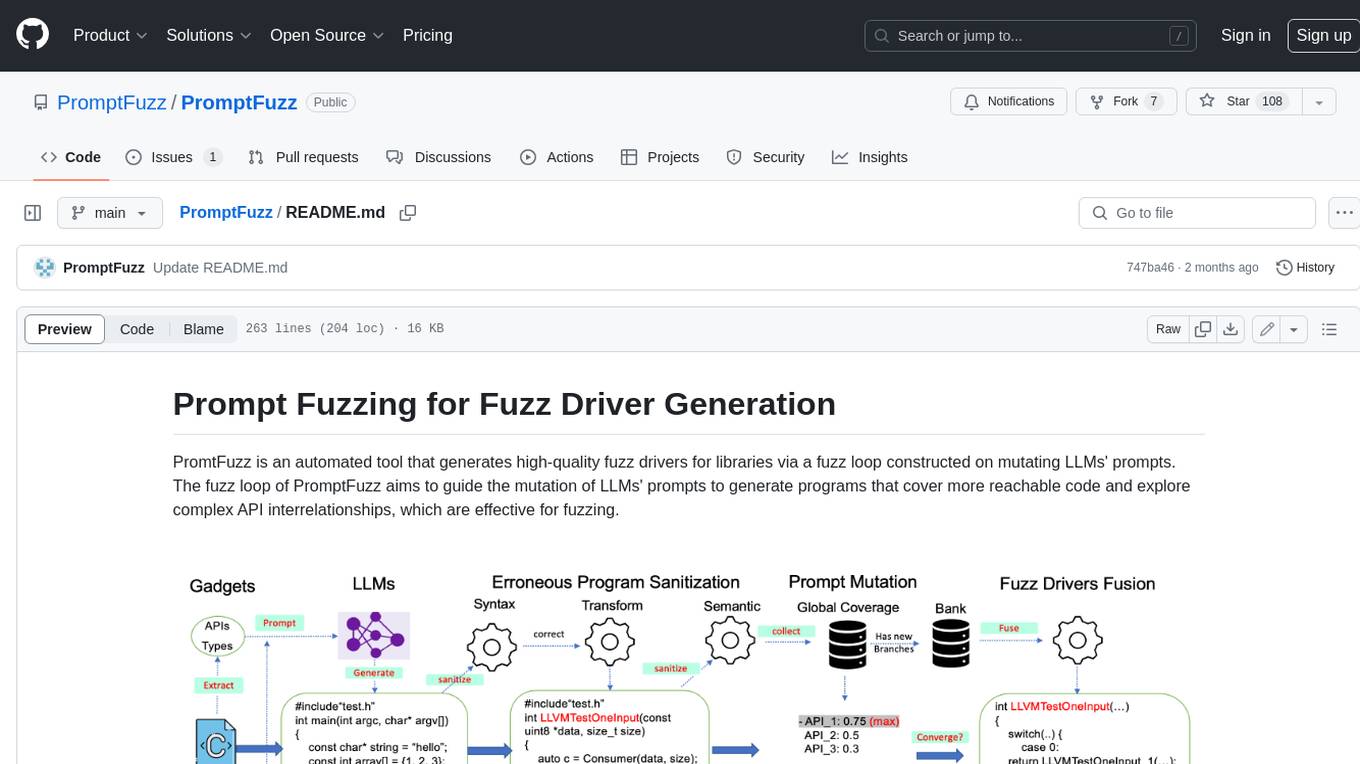
PromptFuzz
**Description:** PromptFuzz is an automated tool that generates high-quality fuzz drivers for libraries via a fuzz loop constructed on mutating LLMs' prompts. The fuzz loop of PromptFuzz aims to guide the mutation of LLMs' prompts to generate programs that cover more reachable code and explore complex API interrelationships, which are effective for fuzzing. **Features:** * **Multiply LLM support** : Supports the general LLMs: Codex, Inocder, ChatGPT, and GPT4 (Currently tested on ChatGPT). * **Context-based Prompt** : Construct LLM prompts with the automatically extracted library context. * **Powerful Sanitization** : The program's syntax, semantics, behavior, and coverage are thoroughly analyzed to sanitize the problematic programs. * **Prioritized Mutation** : Prioritizes mutating the library API combinations within LLM's prompts to explore complex interrelationships, guided by code coverage. * **Fuzz Driver Exploitation** : Infers API constraints using statistics and extends fixed API arguments to receive random bytes from fuzzers. * **Fuzz engine integration** : Integrates with grey-box fuzz engine: LibFuzzer. **Benefits:** * **High branch coverage:** The fuzz drivers generated by PromptFuzz achieved a branch coverage of 40.12% on the tested libraries, which is 1.61x greater than _OSS-Fuzz_ and 1.67x greater than _Hopper_. * **Bug detection:** PromptFuzz detected 33 valid security bugs from 49 unique crashes. * **Wide range of bugs:** The fuzz drivers generated by PromptFuzz can detect a wide range of bugs, most of which are security bugs. * **Unique bugs:** PromptFuzz detects uniquely interesting bugs that other fuzzers may miss. **Usage:** 1. Build the library using the provided build scripts. 2. Export the LLM API KEY if using ChatGPT or GPT4. 3. Generate fuzz drivers using the `fuzzer` command. 4. Run the fuzz drivers using the `harness` command. 5. Deduplicate and analyze the reported crashes. **Future Works:** * **Custom LLMs suport:** Support custom LLMs. * **Close-source libraries:** Apply PromptFuzz to close-source libraries by fine tuning LLMs on private code corpus. * **Performance** : Reduce the huge time cost required in erroneous program elimination.
For similar tasks

PIXIU
PIXIU is a project designed to support the development, fine-tuning, and evaluation of Large Language Models (LLMs) in the financial domain. It includes components like FinBen, a Financial Language Understanding and Prediction Evaluation Benchmark, FIT, a Financial Instruction Dataset, and FinMA, a Financial Large Language Model. The project provides open resources, multi-task and multi-modal financial data, and diverse financial tasks for training and evaluation. It aims to encourage open research and transparency in the financial NLP field.
BizFinBench
BizFinBench is a benchmark tool designed for evaluating large language models (LLMs) in logic-heavy and precision-critical domains such as finance. It comprises over 100,000 bilingual financial questions rooted in real-world business scenarios. The tool covers five dimensions: numerical calculation, reasoning, information extraction, prediction recognition, and knowledge-based question answering, mapped to nine fine-grained categories. BizFinBench aims to assess the capacity of LLMs in real-world financial scenarios and provides insights into their strengths and limitations.

langchain_dart
LangChain.dart is a Dart port of the popular LangChain Python framework created by Harrison Chase. LangChain provides a set of ready-to-use components for working with language models and a standard interface for chaining them together to formulate more advanced use cases (e.g. chatbots, Q&A with RAG, agents, summarization, extraction, etc.). The components can be grouped into a few core modules: * **Model I/O:** LangChain offers a unified API for interacting with various LLM providers (e.g. OpenAI, Google, Mistral, Ollama, etc.), allowing developers to switch between them with ease. Additionally, it provides tools for managing model inputs (prompt templates and example selectors) and parsing the resulting model outputs (output parsers). * **Retrieval:** assists in loading user data (via document loaders), transforming it (with text splitters), extracting its meaning (using embedding models), storing (in vector stores) and retrieving it (through retrievers) so that it can be used to ground the model's responses (i.e. Retrieval-Augmented Generation or RAG). * **Agents:** "bots" that leverage LLMs to make informed decisions about which available tools (such as web search, calculators, database lookup, etc.) to use to accomplish the designated task. The different components can be composed together using the LangChain Expression Language (LCEL).
x-crawl
x-crawl is a flexible Node.js AI-assisted crawler library that offers powerful AI assistance functions to make crawler work more efficient, intelligent, and convenient. It consists of a crawler API and various functions that can work normally even without relying on AI. The AI component is currently based on a large AI model provided by OpenAI, simplifying many tedious operations. The library supports crawling dynamic pages, static pages, interface data, and file data, with features like control page operations, device fingerprinting, asynchronous sync, interval crawling, failed retry handling, rotation proxy, priority queue, crawl information control, and TypeScript support.

nlp-llms-resources
The 'nlp-llms-resources' repository is a comprehensive resource list for Natural Language Processing (NLP) and Large Language Models (LLMs). It covers a wide range of topics including traditional NLP datasets, data acquisition, libraries for NLP, neural networks, sentiment analysis, optical character recognition, information extraction, semantics, topic modeling, multilingual NLP, domain-specific LLMs, vector databases, ethics, costing, books, courses, surveys, aggregators, newsletters, papers, conferences, and societies. The repository provides valuable information and resources for individuals interested in NLP and LLMs.

sycamore
Sycamore is a conversational search and analytics platform for complex unstructured data, such as documents, presentations, transcripts, embedded tables, and internal knowledge repositories. It retrieves and synthesizes high-quality answers through bringing AI to data preparation, indexing, and retrieval. Sycamore makes it easy to prepare unstructured data for search and analytics, providing a toolkit for data cleaning, information extraction, enrichment, summarization, and generation of vector embeddings that encapsulate the semantics of data. Sycamore uses your choice of generative AI models to make these operations simple and effective, and it enables quick experimentation and iteration. Additionally, Sycamore uses OpenSearch for indexing, enabling hybrid (vector + keyword) search, retrieval-augmented generation (RAG) pipelining, filtering, analytical functions, conversational memory, and other features to improve information retrieval.
langroid
Langroid is a Python framework that makes it easy to build LLM-powered applications. It uses a multi-agent paradigm inspired by the Actor Framework, where you set up Agents, equip them with optional components (LLM, vector-store and tools/functions), assign them tasks, and have them collaboratively solve a problem by exchanging messages. Langroid is a fresh take on LLM app-development, where considerable thought has gone into simplifying the developer experience; it does not use Langchain.

ontogpt
OntoGPT is a Python package for extracting structured information from text using large language models, instruction prompts, and ontology-based grounding. It provides a command line interface and a minimal web app for easy usage. The tool has been evaluated on test data and is used in related projects like TALISMAN for gene set analysis. OntoGPT enables users to extract information from text by specifying relevant terms and provides the extracted objects as output.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

agentcloud
AgentCloud is an open-source platform that enables companies to build and deploy private LLM chat apps, empowering teams to securely interact with their data. It comprises three main components: Agent Backend, Webapp, and Vector Proxy. To run this project locally, clone the repository, install Docker, and start the services. The project is licensed under the GNU Affero General Public License, version 3 only. Contributions and feedback are welcome from the community.

oss-fuzz-gen
This framework generates fuzz targets for real-world `C`/`C++` projects with various Large Language Models (LLM) and benchmarks them via the `OSS-Fuzz` platform. It manages to successfully leverage LLMs to generate valid fuzz targets (which generate non-zero coverage increase) for 160 C/C++ projects. The maximum line coverage increase is 29% from the existing human-written targets.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.