
llm-compression-intelligence
Official github repo for the paper "Compression Represents Intelligence Linearly"
Stars: 98

This repository presents the findings of the paper "Compression Represents Intelligence Linearly". The study reveals a strong linear correlation between the intelligence of LLMs, as measured by benchmark scores, and their ability to compress external text corpora. Compression efficiency, derived from raw text corpora, serves as a reliable evaluation metric that is linearly associated with model capabilities. The repository includes the compression corpora used in the paper, code for computing compression efficiency, and data collection and processing pipelines.
README:
🤗 HuggingFace Datasets • 📃 Paper
This is the repository for the paper "Compression Represents Intelligence Linearly".
We find that LLMs’ intelligence – reflected by benchmark scores – almost linearly correlates with their ability to compress external text corpora. Our findings suggest that compression efficiency, as an unsupervised metric derived from raw text corpora, serves as a reliable evaluation measure that is linearly associated with the model capabilities. In this repo, we release the compression corpora we used in the paper, the code to compute compression efficiency, as well as our compression corpora collection and processing piplines. 
- [2024.05.01] Our compression evaluation has been added into OpenCompass 🚀🚀🚀 Please refer to Use Through OpenCompass for details.
We focus on three key abilities: knowledge and commonsense, coding, and mathematical reasoning and colloct new corpora from Common Crawl, GitHub, and Arxiv, respectively. Below are models’ compression efficiency on three external corpora. We report the average bits per character (BPC) as the metric. For more details, please refer to our paper.
| Model | Common Crawl | Python | Arxiv-Math | Average |
|---|---|---|---|---|
| Llama-3-70b | 0.496 | 0.204 | 0.376 | 0.359 |
| Mixtral-8x22B-v0.1 | 0.526 | 0.250 | 0.361 | 0.379 |
| Qwen2-72B | 0.550 | 0.207 | 0.390 | 0.383 |
| Qwen1.5-110B | 0.531 | 0.224 | 0.410 | 0.388 |
| DeepSeek-V2 | 0.529 | 0.243 | 0.400 | 0.391 |
| Mixtral-8x7B | 0.559 | 0.274 | 0.394 | 0.409 |
| Qwen-72b | 0.557 | 0.256 | 0.415 | 0.409 |
| Qwen-1.5-72b | 0.560 | 0.256 | 0.417 | 0.411 |
| Llama-2-70b | 0.527 | 0.287 | 0.429 | 0.415 |
| Qwen-1.5-32b | 0.591 | 0.257 | 0.407 | 0.418 |
| Deepseek-llm-67b | 0.568 | 0.280 | 0.430 | 0.426 |
| Llama-3-8b | 0.582 | 0.268 | 0.430 | 0.427 |
| Yi-34b | 0.572 | 0.297 | 0.421 | 0.430 |
| Llama-1-65b | 0.557 | 0.308 | 0.441 | 0.435 |
| Qwen-1.5-14b | 0.646 | 0.275 | 0.430 | 0.450 |
| Qwen-14b | 0.620 | 0.285 | 0.450 | 0.451 |
| Llama-1-30b | 0.577 | 0.321 | 0.456 | 0.452 |
| Mistral-7b | 0.605 | 0.310 | 0.443 | 0.453 |
| Llama-2-13b | 0.581 | 0.334 | 0.475 | 0.463 |
| Falcon-40b | 0.593 | 0.320 | 0.482 | 0.465 |
| Qwen-1.5-7b | 0.666 | 0.292 | 0.449 | 0.469 |
| Qwen-7b | 0.645 | 0.309 | 0.483 | 0.479 |
| Llama-1-13b | 0.609 | 0.356 | 0.487 | 0.484 |
| Llama-2-7b | 0.612 | 0.354 | 0.500 | 0.488 |
| Yi-6b | 0.638 | 0.351 | 0.483 | 0.491 |
| Deepseek-llm-7b | 0.635 | 0.338 | 0.500 | 0.491 |
| Llama-1-7b | 0.629 | 0.379 | 0.510 | 0.506 |
| Falcon-7b | 0.649 | 0.393 | 0.541 | 0.528 |
We focus on three key abilities: knowledge and commonsense, coding, and mathematical reasoning. The corpora we used are sourced from Common Crawl, GitHub, and Arxiv, and are respectively named: cc, python, and arxiv_math respectively. The data can be obtained through Huggingface Datasets:
from datasets import load_dataset
dataset = load_dataset(r"hkust-nlp/llm-compression",name="python")
print(dataset['test'][0])Below is our data structure, containing three fields: content, subset, meta. Specifically, "content" refers to the evaluation text data, and "meta" contains data-specific meta-information related to its subset.
"content": "A photo journal about returning...",
"subset": "cc" | "python" | "arxiv_math",
"meta": {}
We utilize Bits Per Character (BPC) as the evaluation metric, implementing both Context Window Unification and a sliding window approach for assessing compression performance. The Python code for this evaluation is accessible in the code/evaluation directory and necessitates the specified basic environment:
transformers
datasets
tqdm
After installing the necessary dependencies, execute the evaluation script code/evaluation/main.py with these optional arguments:
--task_name # specifies the subset to eval (cc|python|arxiv_math)
--model_name # specifies the model name
--block_size # specifies the context window
--stride # specifies the stride of sliding window approach
--batch_size # specifies the batch size
--file_num # specifies the number of examples to eval, useful for debugging
--flash # enable this to use flash attention (requires the flash-attn package)
--gpu # specifies the id of gpu
--cache_dir # specifies the cache dir for huggingface
Example:
cd code/evlauation
python -u main.py\
--model_name deepseek-ai/deepseek-llm-7b-base\
--task_name cc\
--block_size 1900\
--stride 512\
--batch_size 8\
--flash
Now, you can evaluate model on llm-compression through OpenCompass, which is a framework for LLM evaluation. The dataset name is llm_compression. For example, to evaluate a model hosted on the HuggingFace Hub (e.g. llama-7b) ,you can use the following command:
python run.py --datasets llm_compression --hf-path huggyllama/llama-7b --model-kwargs use_flash_attention_2=True Please refer to OpenCompass for more details.
We provide data collection pipelines to facilitate future data updates and research, which include:
For details, please refer to the corresponding pages.
This work is licensed under a MIT License.
Our dataset is primarily licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License. When the data source mandates a stricter licensing agreement, we comply with those terms.
@misc{huang2024compression,
title={Compression Represents Intelligence Linearly},
author={Yuzhen Huang and Jinghan Zhang and Zifei Shan and Junxian He},
year={2024},
eprint={2404.09937},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for llm-compression-intelligence
Similar Open Source Tools
llm-compression-intelligence
This repository presents the findings of the paper "Compression Represents Intelligence Linearly". The study reveals a strong linear correlation between the intelligence of LLMs, as measured by benchmark scores, and their ability to compress external text corpora. Compression efficiency, derived from raw text corpora, serves as a reliable evaluation metric that is linearly associated with model capabilities. The repository includes the compression corpora used in the paper, code for computing compression efficiency, and data collection and processing pipelines.

LLM-PowerHouse-A-Curated-Guide-for-Large-Language-Models-with-Custom-Training-and-Inferencing
LLM-PowerHouse is a comprehensive and curated guide designed to empower developers, researchers, and enthusiasts to harness the true capabilities of Large Language Models (LLMs) and build intelligent applications that push the boundaries of natural language understanding. This GitHub repository provides in-depth articles, codebase mastery, LLM PlayLab, and resources for cost analysis and network visualization. It covers various aspects of LLMs, including NLP, models, training, evaluation metrics, open LLMs, and more. The repository also includes a collection of code examples and tutorials to help users build and deploy LLM-based applications.

llm-datasets
LLM Datasets is a repository containing high-quality datasets, tools, and concepts for LLM fine-tuning. It provides datasets with characteristics like accuracy, diversity, and complexity to train large language models for various tasks. The repository includes datasets for general-purpose, math & logic, code, conversation & role-play, and agent & function calling domains. It also offers guidance on creating high-quality datasets through data deduplication, data quality assessment, data exploration, and data generation techniques.

PredictorLLM
PredictorLLM is an advanced trading agent framework that utilizes large language models to automate trading in financial markets. It includes a profiling module to establish agent characteristics, a layered memory module for retaining and prioritizing financial data, and a decision-making module to convert insights into trading strategies. The framework mimics professional traders' behavior, surpassing human limitations in data processing and continuously evolving to adapt to market conditions for superior investment outcomes.
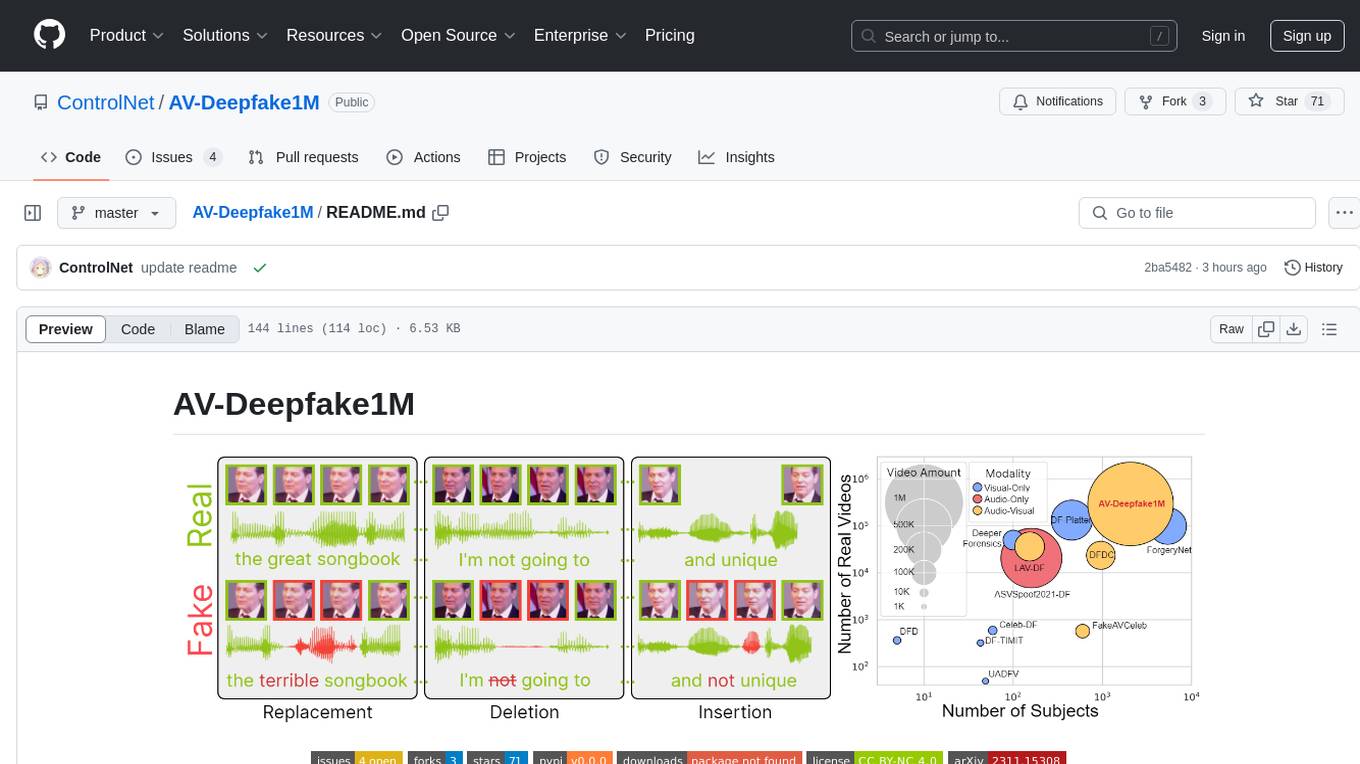
AV-Deepfake1M
The AV-Deepfake1M repository is the official repository for the paper AV-Deepfake1M: A Large-Scale LLM-Driven Audio-Visual Deepfake Dataset. It addresses the challenge of detecting and localizing deepfake audio-visual content by proposing a dataset containing video manipulations, audio manipulations, and audio-visual manipulations for over 2K subjects resulting in more than 1M videos. The dataset is crucial for developing next-generation deepfake localization methods.

jailbreak_llms
This is the official repository for the ACM CCS 2024 paper 'Do Anything Now': Characterizing and Evaluating In-The-Wild Jailbreak Prompts on Large Language Models. The project employs a new framework called JailbreakHub to conduct the first measurement study on jailbreak prompts in the wild, collecting 15,140 prompts from December 2022 to December 2023, including 1,405 jailbreak prompts. The dataset serves as the largest collection of in-the-wild jailbreak prompts. The repository contains examples of harmful language and is intended for research purposes only.

Awesome-LLM-Large-Language-Models-Notes
Awesome-LLM-Large-Language-Models-Notes is a repository that provides a comprehensive collection of information on various Large Language Models (LLMs) classified by year, size, and name. It includes details on known LLM models, their papers, implementations, and specific characteristics. The repository also covers LLM models classified by architecture, must-read papers, blog articles, tutorials, and implementations from scratch. It serves as a valuable resource for individuals interested in understanding and working with LLMs in the field of Natural Language Processing (NLP).
LLMs-Planning
This repository contains code for three papers related to evaluating large language models on planning and reasoning about change. It includes benchmarking tools and analysis for assessing the planning abilities of large language models. The latest addition evaluates and enhances the planning and scheduling capabilities of a specific language reasoning model. The repository provides a static test set leaderboard showcasing model performance on various tasks with natural language and planning domain prompts.

Awesome-LLM-Constrained-Decoding
Awesome-LLM-Constrained-Decoding is a curated list of papers, code, and resources related to constrained decoding of Large Language Models (LLMs). The repository aims to facilitate reliable, controllable, and efficient generation with LLMs by providing a comprehensive collection of materials in this domain.

MathEval
MathEval is a benchmark designed for evaluating the mathematical capabilities of large models. It includes over 20 evaluation datasets covering various mathematical domains with more than 30,000 math problems. The goal is to assess the performance of large models across different difficulty levels and mathematical subfields. MathEval serves as a reliable reference for comparing mathematical abilities among large models and offers guidance on enhancing their mathematical capabilities in the future.
rubra
Rubra is a collection of open-weight large language models enhanced with tool-calling capability. It allows users to call user-defined external tools in a deterministic manner while reasoning and chatting, making it ideal for agentic use cases. The models are further post-trained to teach instruct-tuned models new skills and mitigate catastrophic forgetting. Rubra extends popular inferencing projects for easy use, enabling users to run the models easily.

amber-train
Amber is the first model in the LLM360 family, an initiative for comprehensive and fully open-sourced LLMs. It is a 7B English language model with the LLaMA architecture. The model type is a language model with the same architecture as LLaMA-7B. It is licensed under Apache 2.0. The resources available include training code, data preparation, metrics, and fully processed Amber pretraining data. The model has been trained on various datasets like Arxiv, Book, C4, Refined-Web, StarCoder, StackExchange, and Wikipedia. The hyperparameters include a total of 6.7B parameters, hidden size of 4096, intermediate size of 11008, 32 attention heads, 32 hidden layers, RMSNorm ε of 1e^-6, max sequence length of 2048, and a vocabulary size of 32000.
data-prep-kit
Data Prep Kit accelerates unstructured data preparation for LLM app developers. It allows developers to cleanse, transform, and enrich unstructured data for pre-training, fine-tuning, instruct-tuning LLMs, or building RAG applications. The kit provides modules for Python, Ray, and Spark runtimes, supporting Natural Language and Code data modalities. It offers a framework for custom transforms and uses Kubeflow Pipelines for workflow automation. Users can install the kit via PyPi and access a variety of transforms for data processing pipelines.

RVC_CLI
**RVC_CLI: Retrieval-based Voice Conversion Command Line Interface** This command-line interface (CLI) provides a comprehensive set of tools for voice conversion, enabling you to modify the pitch, timbre, and other characteristics of audio recordings. It leverages advanced machine learning models to achieve realistic and high-quality voice conversions. **Key Features:** * **Inference:** Convert the pitch and timbre of audio in real-time or process audio files in batch mode. * **TTS Inference:** Synthesize speech from text using a variety of voices and apply voice conversion techniques. * **Training:** Train custom voice conversion models to meet specific requirements. * **Model Management:** Extract, blend, and analyze models to fine-tune and optimize performance. * **Audio Analysis:** Inspect audio files to gain insights into their characteristics. * **API:** Integrate the CLI's functionality into your own applications or workflows. **Applications:** The RVC_CLI finds applications in various domains, including: * **Music Production:** Create unique vocal effects, harmonies, and backing vocals. * **Voiceovers:** Generate voiceovers with different accents, emotions, and styles. * **Audio Editing:** Enhance or modify audio recordings for podcasts, audiobooks, and other content. * **Research and Development:** Explore and advance the field of voice conversion technology. **For Jobs:** * Audio Engineer * Music Producer * Voiceover Artist * Audio Editor * Machine Learning Engineer **AI Keywords:** * Voice Conversion * Pitch Shifting * Timbre Modification * Machine Learning * Audio Processing **For Tasks:** * Convert Pitch * Change Timbre * Synthesize Speech * Train Model * Analyze Audio

dl_model_infer
This project is a c++ version of the AI reasoning library that supports the reasoning of tensorrt models. It provides accelerated deployment cases of deep learning CV popular models and supports dynamic-batch image processing, inference, decode, and NMS. The project has been updated with various models and provides tutorials for model exports. It also includes a producer-consumer inference model for specific tasks. The project directory includes implementations for model inference applications, backend reasoning classes, post-processing, pre-processing, and target detection and tracking. Speed tests have been conducted on various models, and onnx downloads are available for different models.

RVC_CLI
RVC_CLI is a command line interface tool for retrieval-based voice conversion. It provides functionalities for installation, getting started, inference, training, UVR, additional features, and API integration. Users can perform tasks like single inference, batch inference, TTS inference, preprocess dataset, extract features, start training, generate index file, model extract, model information, model blender, launch TensorBoard, download models, audio analyzer, and prerequisites download. The tool is built on various projects like ContentVec, HIFIGAN, audio-slicer, python-audio-separator, RMVPE, FCPE, VITS, So-Vits-SVC, Harmonify, and others.
For similar tasks
llm-compression-intelligence
This repository presents the findings of the paper "Compression Represents Intelligence Linearly". The study reveals a strong linear correlation between the intelligence of LLMs, as measured by benchmark scores, and their ability to compress external text corpora. Compression efficiency, derived from raw text corpora, serves as a reliable evaluation metric that is linearly associated with model capabilities. The repository includes the compression corpora used in the paper, code for computing compression efficiency, and data collection and processing pipelines.

edsl
The Expected Parrot Domain-Specific Language (EDSL) package enables users to conduct computational social science and market research with AI. It facilitates designing surveys and experiments, simulating responses using large language models, and performing data labeling and other research tasks. EDSL includes built-in methods for analyzing, visualizing, and sharing research results. It is compatible with Python 3.9 - 3.11 and requires API keys for LLMs stored in a `.env` file.

fast-stable-diffusion
Fast-stable-diffusion is a project that offers notebooks for RunPod, Paperspace, and Colab Pro adaptations with AUTOMATIC1111 Webui and Dreambooth. It provides tools for running and implementing Dreambooth, a stable diffusion project. The project includes implementations by XavierXiao and is sponsored by Runpod, Paperspace, and Colab Pro.

RobustVLM
This repository contains code for the paper 'Robust CLIP: Unsupervised Adversarial Fine-Tuning of Vision Embeddings for Robust Large Vision-Language Models'. It focuses on fine-tuning CLIP in an unsupervised manner to enhance its robustness against visual adversarial attacks. By replacing the vision encoder of large vision-language models with the fine-tuned CLIP models, it achieves state-of-the-art adversarial robustness on various vision-language tasks. The repository provides adversarially fine-tuned ViT-L/14 CLIP models and offers insights into zero-shot classification settings and clean accuracy improvements.

TempCompass
TempCompass is a benchmark designed to evaluate the temporal perception ability of Video LLMs. It encompasses a diverse set of temporal aspects and task formats to comprehensively assess the capability of Video LLMs in understanding videos. The benchmark includes conflicting videos to prevent models from relying on single-frame bias and language priors. Users can clone the repository, install required packages, prepare data, run inference using examples like Video-LLaVA and Gemini, and evaluate the performance of their models across different tasks such as Multi-Choice QA, Yes/No QA, Caption Matching, and Caption Generation.

LLM-LieDetector
This repository contains code for reproducing experiments on lie detection in black-box LLMs by asking unrelated questions. It includes Q/A datasets, prompts, and fine-tuning datasets for generating lies with language models. The lie detectors rely on asking binary 'elicitation questions' to diagnose whether the model has lied. The code covers generating lies from language models, training and testing lie detectors, and generalization experiments. It requires access to GPUs and OpenAI API calls for running experiments with open-source models. Results are stored in the repository for reproducibility.

bigcodebench
BigCodeBench is an easy-to-use benchmark for code generation with practical and challenging programming tasks. It aims to evaluate the true programming capabilities of large language models (LLMs) in a more realistic setting. The benchmark is designed for HumanEval-like function-level code generation tasks, but with much more complex instructions and diverse function calls. BigCodeBench focuses on the evaluation of LLM4Code with diverse function calls and complex instructions, providing precise evaluation & ranking and pre-generated samples to accelerate code intelligence research. It inherits the design of the EvalPlus framework but differs in terms of execution environment and test evaluation.
rag
RAG with txtai is a Retrieval Augmented Generation (RAG) Streamlit application that helps generate factually correct content by limiting the context in which a Large Language Model (LLM) can generate answers. It supports two categories of RAG: Vector RAG, where context is supplied via a vector search query, and Graph RAG, where context is supplied via a graph path traversal query. The application allows users to run queries, add data to the index, and configure various parameters to control its behavior.
For similar jobs

LLM-FineTuning-Large-Language-Models
This repository contains projects and notes on common practical techniques for fine-tuning Large Language Models (LLMs). It includes fine-tuning LLM notebooks, Colab links, LLM techniques and utils, and other smaller language models. The repository also provides links to YouTube videos explaining the concepts and techniques discussed in the notebooks.

lloco
LLoCO is a technique that learns documents offline through context compression and in-domain parameter-efficient finetuning using LoRA, which enables LLMs to handle long context efficiently.

camel
CAMEL is an open-source library designed for the study of autonomous and communicative agents. We believe that studying these agents on a large scale offers valuable insights into their behaviors, capabilities, and potential risks. To facilitate research in this field, we implement and support various types of agents, tasks, prompts, models, and simulated environments.
llm-baselines
LLM-baselines is a modular codebase to experiment with transformers, inspired from NanoGPT. It provides a quick and easy way to train and evaluate transformer models on a variety of datasets. The codebase is well-documented and easy to use, making it a great resource for researchers and practitioners alike.
python-tutorial-notebooks
This repository contains Jupyter-based tutorials for NLP, ML, AI in Python for classes in Computational Linguistics, Natural Language Processing (NLP), Machine Learning (ML), and Artificial Intelligence (AI) at Indiana University.
EvalAI
EvalAI is an open-source platform for evaluating and comparing machine learning (ML) and artificial intelligence (AI) algorithms at scale. It provides a central leaderboard and submission interface, making it easier for researchers to reproduce results mentioned in papers and perform reliable & accurate quantitative analysis. EvalAI also offers features such as custom evaluation protocols and phases, remote evaluation, evaluation inside environments, CLI support, portability, and faster evaluation.
Weekly-Top-LLM-Papers
This repository provides a curated list of weekly published Large Language Model (LLM) papers. It includes top important LLM papers for each week, organized by month and year. The papers are categorized into different time periods, making it easy to find the most recent and relevant research in the field of LLM.
self-llm
This project is a Chinese tutorial for domestic beginners based on the AutoDL platform, providing full-process guidance for various open-source large models, including environment configuration, local deployment, and efficient fine-tuning. It simplifies the deployment, use, and application process of open-source large models, enabling more ordinary students and researchers to better use open-source large models and helping open and free large models integrate into the lives of ordinary learners faster.