
LLM-FineTuning-Large-Language-Models
LLM (Large Language Model) FineTuning
Stars: 319

This repository contains projects and notes on common practical techniques for fine-tuning Large Language Models (LLMs). It includes fine-tuning LLM notebooks, Colab links, LLM techniques and utils, and other smaller language models. The repository also provides links to YouTube videos explaining the concepts and techniques discussed in the notebooks.
README:

- 🐦 TWITTER: https://twitter.com/rohanpaul_ai
- 🟠 YouTube: https://www.youtube.com/@RohanPaul-AI/featured
- 👨🏻💼 LINKEDIN: https://www.linkedin.com/in/rohan-paul-b27285129/
- 👨🔧 KAGGLE: https://www.kaggle.com/paulrohan2020
-
 FineTuning BERT for Multi-Class Classification on custom Dataset
FineTuning BERT for Multi-Class Classification on custom Dataset -
Document STRIDE when Tokenizing with HuggingFace Transformer for NLP Projects
-
Fine-tuning of a PreTrained Transformer model - what really happens to the weights (parameters)
-
Cerebras-GPT New Large Language Model Open Sourced with Apache 2.0 License
-
Roberta-Large Named Entity Recognition on Kaggle NLP Competition with PyTorch
-
Zero Shot Multilingual Sentiment Classification with PyTorch Lightning
-
Fine Tuning Transformer (BERT) for Customer Review Prediction | NLP | HuggingFace
-
Understanding BERT Embeddings and Tokenization | NLP | HuggingFace
-
Adding a custom task-specific Layer to a HuggingFace Pretrained Model
-
Debarta-v3-large model fine tuning for Kaggle Competition Feedback-Prize | NLP
-
FinBERT Sentiment Analysis for very Long Text (more than 512 Tokens) | PART 2
-
FinBERT Sentiment Analysis for very Long Text Corpus (more than 512 Tokens) | PART-1
-
Cosine Similarity between sentences with Transformers HuggingFace
-
Zero Shot Learning - Cross Lingual Named Entity Recognition with XLM-Roberta
-
Understanding Word Vectors usage with Spacy Word and Sentence Similarity
-
Named Entity Recognition NER using spaCy - Extracting Subject Verb Action
-
Fine-Tuning-DistilBert - Hugging Face Transformer for Poem Sentiment Prediction | NLP
-
Fine Tuning BERT-Based-Uncased Hugging Face Model on Kaggle Hate Speech Dataset
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for LLM-FineTuning-Large-Language-Models
Similar Open Source Tools
LLM-FineTuning-Large-Language-Models
This repository contains projects and notes on common practical techniques for fine-tuning Large Language Models (LLMs). It includes fine-tuning LLM notebooks, Colab links, LLM techniques and utils, and other smaller language models. The repository also provides links to YouTube videos explaining the concepts and techniques discussed in the notebooks.

AiTreasureBox
AiTreasureBox is a versatile AI tool that provides a collection of pre-trained models and algorithms for various machine learning tasks. It simplifies the process of implementing AI solutions by offering ready-to-use components that can be easily integrated into projects. With AiTreasureBox, users can quickly prototype and deploy AI applications without the need for extensive knowledge in machine learning or deep learning. The tool covers a wide range of tasks such as image classification, text generation, sentiment analysis, object detection, and more. It is designed to be user-friendly and accessible to both beginners and experienced developers, making AI development more efficient and accessible to a wider audience.
AITreasureBox
AITreasureBox is a comprehensive collection of AI tools and resources designed to simplify and accelerate the development of AI projects. It provides a wide range of pre-trained models, datasets, and utilities that can be easily integrated into various AI applications. With AITreasureBox, developers can quickly prototype, test, and deploy AI solutions without having to build everything from scratch. Whether you are working on computer vision, natural language processing, or reinforcement learning projects, AITreasureBox has something to offer for everyone. The repository is regularly updated with new tools and resources to keep up with the latest advancements in the field of artificial intelligence.
ms-copilot-play
Microsoft Copilot Play is a Cloudflare Worker service that accelerates Microsoft Copilot functionalities in China. It allows high-speed access to Microsoft Copilot features like chatting, notebook, plugins, image generation, and sharing. The service filters out meaningless requests used for statistics, saving up to 80% of Cloudflare Worker requests. Users can deploy the service easily with Cloudflare Worker, ensuring fast and unlimited access with no additional operations. The service leverages the power of Microsoft Copilot, based on OpenAI GPT-4, and utilizes Bing search to answer questions.
mnn-llm
MNN-LLM is a high-performance inference engine for large language models (LLMs) on mobile and embedded devices. It provides optimized implementations of popular LLM models, such as ChatGPT, BLOOM, and GPT-3, enabling developers to easily integrate these models into their applications. MNN-LLM is designed to be efficient and lightweight, making it suitable for resource-constrained devices. It supports various deployment options, including mobile apps, web applications, and embedded systems. With MNN-LLM, developers can leverage the power of LLMs to enhance their applications with natural language processing capabilities, such as text generation, question answering, and dialogue generation.

swift
SWIFT (Scalable lightWeight Infrastructure for Fine-Tuning) supports training, inference, evaluation and deployment of nearly **200 LLMs and MLLMs** (multimodal large models). Developers can directly apply our framework to their own research and production environments to realize the complete workflow from model training and evaluation to application. In addition to supporting the lightweight training solutions provided by [PEFT](https://github.com/huggingface/peft), we also provide a complete **Adapters library** to support the latest training techniques such as NEFTune, LoRA+, LLaMA-PRO, etc. This adapter library can be used directly in your own custom workflow without our training scripts. To facilitate use by users unfamiliar with deep learning, we provide a Gradio web-ui for controlling training and inference, as well as accompanying deep learning courses and best practices for beginners. Additionally, we are expanding capabilities for other modalities. Currently, we support full-parameter training and LoRA training for AnimateDiff.

UMOE-Scaling-Unified-Multimodal-LLMs
Uni-MoE is a MoE-based unified multimodal model that can handle diverse modalities including audio, speech, image, text, and video. The project focuses on scaling Unified Multimodal LLMs with a Mixture of Experts framework. It offers enhanced functionality for training across multiple nodes and GPUs, as well as parallel processing at both the expert and modality levels. The model architecture involves three training stages: building connectors for multimodal understanding, developing modality-specific experts, and incorporating multiple trained experts into LLMs using the LoRA technique on mixed multimodal data. The tool provides instructions for installation, weights organization, inference, training, and evaluation on various datasets.

Awesome-Colorful-LLM
Awesome-Colorful-LLM is a meticulously assembled anthology of vibrant multimodal research focusing on advancements propelled by large language models (LLMs) in domains such as Vision, Audio, Agent, Robotics, and Fundamental Sciences like Mathematics. The repository contains curated collections of works, datasets, benchmarks, projects, and tools related to LLMs and multimodal learning. It serves as a comprehensive resource for researchers and practitioners interested in exploring the intersection of language models and various modalities for tasks like image understanding, video pretraining, 3D modeling, document understanding, audio analysis, agent learning, robotic applications, and mathematical research.

LLaVA-pp
This repository, LLaVA++, extends the visual capabilities of the LLaVA 1.5 model by incorporating the latest LLMs, Phi-3 Mini Instruct 3.8B, and LLaMA-3 Instruct 8B. It provides various models for instruction-following LMMS and academic-task-oriented datasets, along with training scripts for Phi-3-V and LLaMA-3-V. The repository also includes installation instructions and acknowledgments to related open-source contributions.
osm-ai-helper
OSM-AI-helper is a Blueprint by Mozilla.ai designed to assist users in mapping features in OpenStreetMap using object detection and image segmentation models. It provides tools for identifying and mapping various features, such as swimming pools, in OpenStreetMap. Users can also create custom datasets and fine-tune models for different use cases. The project is licensed under the AGPL-3.0 License and welcomes contributions from the community.
goat
GOAT (Great Onchain Agent Toolkit) is an open-source framework designed to simplify the process of making AI agents perform onchain actions by providing a provider-agnostic solution that abstracts away the complexities of interacting with blockchain tools such as wallets, token trading, and smart contracts. It offers a catalog of ready-made blockchain actions for agent developers and allows dApp/smart contract developers to develop plugins for easy access by agents. With compatibility across popular agent frameworks, support for multiple blockchains and wallet providers, and customizable onchain functionalities, GOAT aims to streamline the integration of blockchain capabilities into AI agents.

VideoLLaMA2
VideoLLaMA 2 is a project focused on advancing spatial-temporal modeling and audio understanding in video-LLMs. It provides tools for multi-choice video QA, open-ended video QA, and video captioning. The project offers model zoo with different configurations for visual encoder and language decoder. It includes training and evaluation guides, as well as inference capabilities for video and image processing. The project also features a demo setup for running a video-based Large Language Model web demonstration.
david-ai
David UI is a free and open-source collection of customizable, production-ready UI components built with Tailwind CSS. It is designed to be developer-friendly and performance-focused, streamlining the creation of modern, visually appealing interfaces to help deliver high-quality user experiences faster.
fastapi-admin
智元 Fast API is a one-stop API management system that unifies various LLM APIs in terms of format, standards, and management to achieve the ultimate in functionality, performance, and user experience. It includes features such as model management with intelligent and regex matching, backup model functionality, key management, proxy management, company management, user management, and chat management for both admin and user ends. The project supports cluster deployment, multi-site deployment, and cross-region deployment. It also provides a public API site for registration with a contact to the author for a 10 million quota. The tool offers a comprehensive dashboard, model management, application management, key management, and chat management functionalities for users.
haystack-core-integrations
This repository contains integrations to extend the capabilities of Haystack version 2.0 and onwards. The code in this repo is maintained by deepset, see each integration's `README` file for details around installation, usage and support.

databend
Databend is an open-source cloud data warehouse that serves as a cost-effective alternative to Snowflake. With its focus on fast query execution and data ingestion, it's designed for complex analysis of the world's largest datasets.
For similar tasks
LLM-FineTuning-Large-Language-Models
This repository contains projects and notes on common practical techniques for fine-tuning Large Language Models (LLMs). It includes fine-tuning LLM notebooks, Colab links, LLM techniques and utils, and other smaller language models. The repository also provides links to YouTube videos explaining the concepts and techniques discussed in the notebooks.
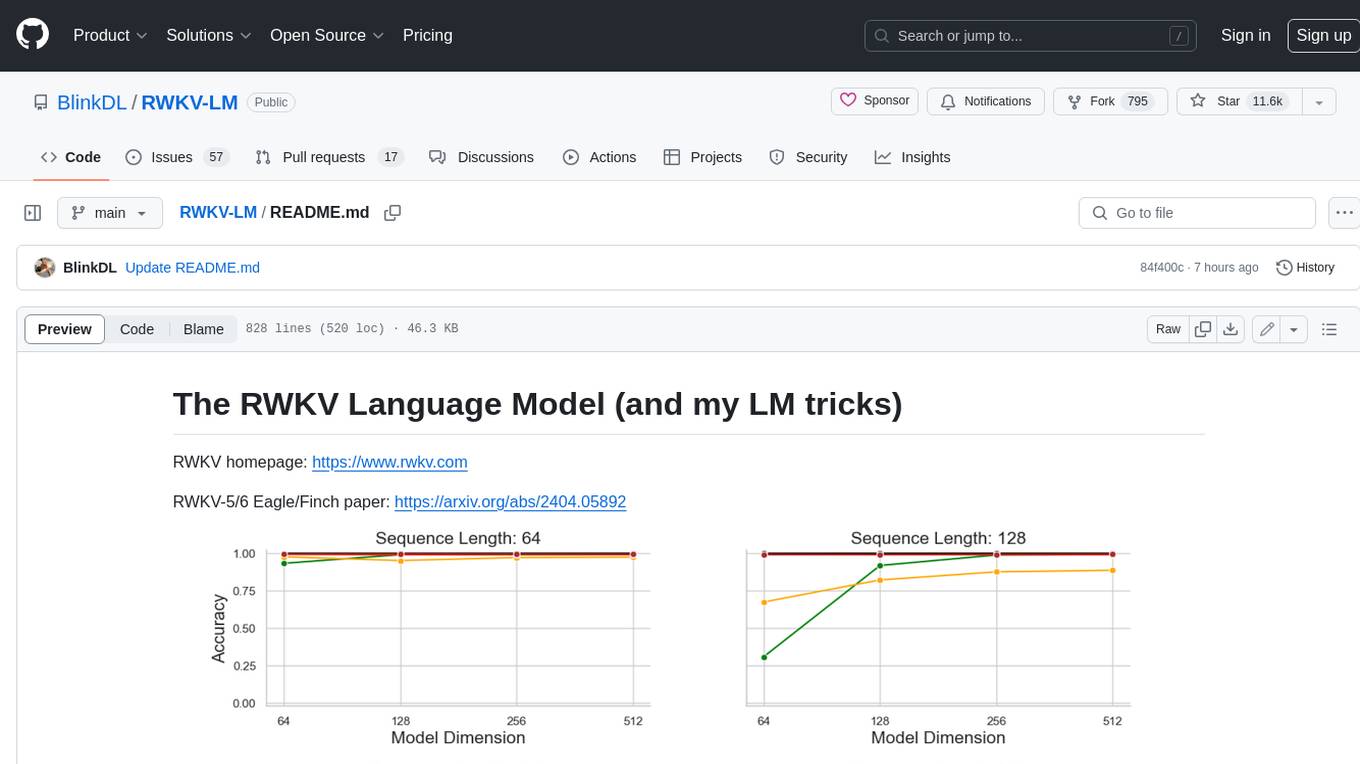
RWKV-LM
RWKV is an RNN with Transformer-level LLM performance, which can also be directly trained like a GPT transformer (parallelizable). And it's 100% attention-free. You only need the hidden state at position t to compute the state at position t+1. You can use the "GPT" mode to quickly compute the hidden state for the "RNN" mode. So it's combining the best of RNN and transformer - **great performance, fast inference, saves VRAM, fast training, "infinite" ctx_len, and free sentence embedding** (using the final hidden state).

awesome-transformer-nlp
This repository contains a hand-curated list of great machine (deep) learning resources for Natural Language Processing (NLP) with a focus on Generative Pre-trained Transformer (GPT), Bidirectional Encoder Representations from Transformers (BERT), attention mechanism, Transformer architectures/networks, Chatbot, and transfer learning in NLP.
self-llm
This project is a Chinese tutorial for domestic beginners based on the AutoDL platform, providing full-process guidance for various open-source large models, including environment configuration, local deployment, and efficient fine-tuning. It simplifies the deployment, use, and application process of open-source large models, enabling more ordinary students and researchers to better use open-source large models and helping open and free large models integrate into the lives of ordinary learners faster.
LLMs-from-scratch
This repository contains the code for coding, pretraining, and finetuning a GPT-like LLM and is the official code repository for the book Build a Large Language Model (From Scratch). In _Build a Large Language Model (From Scratch)_, you'll discover how LLMs work from the inside out. In this book, I'll guide you step by step through creating your own LLM, explaining each stage with clear text, diagrams, and examples. The method described in this book for training and developing your own small-but-functional model for educational purposes mirrors the approach used in creating large-scale foundational models such as those behind ChatGPT.

PaddleNLP
PaddleNLP is an easy-to-use and high-performance NLP library. It aggregates high-quality pre-trained models in the industry and provides out-of-the-box development experience, covering a model library for multiple NLP scenarios with industry practice examples to meet developers' flexible customization needs.
Tutorial
The Bookworm·Puyu large model training camp aims to promote the implementation of large models in more industries and provide developers with a more efficient platform for learning the development and application of large models. Within two weeks, you will learn the entire process of fine-tuning, deploying, and evaluating large models.
LLM-Finetune-Guide
This project provides a comprehensive guide to fine-tuning large language models (LLMs) with efficient methods like LoRA and P-tuning V2. It includes detailed instructions, code examples, and performance benchmarks for various LLMs and fine-tuning techniques. The guide also covers data preparation, evaluation, prediction, and running inference on CPU environments. By leveraging this guide, users can effectively fine-tune LLMs for specific tasks and applications.
For similar jobs
LLM-FineTuning-Large-Language-Models
This repository contains projects and notes on common practical techniques for fine-tuning Large Language Models (LLMs). It includes fine-tuning LLM notebooks, Colab links, LLM techniques and utils, and other smaller language models. The repository also provides links to YouTube videos explaining the concepts and techniques discussed in the notebooks.

lloco
LLoCO is a technique that learns documents offline through context compression and in-domain parameter-efficient finetuning using LoRA, which enables LLMs to handle long context efficiently.

camel
CAMEL is an open-source library designed for the study of autonomous and communicative agents. We believe that studying these agents on a large scale offers valuable insights into their behaviors, capabilities, and potential risks. To facilitate research in this field, we implement and support various types of agents, tasks, prompts, models, and simulated environments.
llm-baselines
LLM-baselines is a modular codebase to experiment with transformers, inspired from NanoGPT. It provides a quick and easy way to train and evaluate transformer models on a variety of datasets. The codebase is well-documented and easy to use, making it a great resource for researchers and practitioners alike.
python-tutorial-notebooks
This repository contains Jupyter-based tutorials for NLP, ML, AI in Python for classes in Computational Linguistics, Natural Language Processing (NLP), Machine Learning (ML), and Artificial Intelligence (AI) at Indiana University.
EvalAI
EvalAI is an open-source platform for evaluating and comparing machine learning (ML) and artificial intelligence (AI) algorithms at scale. It provides a central leaderboard and submission interface, making it easier for researchers to reproduce results mentioned in papers and perform reliable & accurate quantitative analysis. EvalAI also offers features such as custom evaluation protocols and phases, remote evaluation, evaluation inside environments, CLI support, portability, and faster evaluation.
Weekly-Top-LLM-Papers
This repository provides a curated list of weekly published Large Language Model (LLM) papers. It includes top important LLM papers for each week, organized by month and year. The papers are categorized into different time periods, making it easy to find the most recent and relevant research in the field of LLM.
self-llm
This project is a Chinese tutorial for domestic beginners based on the AutoDL platform, providing full-process guidance for various open-source large models, including environment configuration, local deployment, and efficient fine-tuning. It simplifies the deployment, use, and application process of open-source large models, enabling more ordinary students and researchers to better use open-source large models and helping open and free large models integrate into the lives of ordinary learners faster.