
python-tutorial-notebooks
Python tutorials as Jupyter Notebooks for NLP, ML, AI
Stars: 151
This repository contains Jupyter-based tutorials for NLP, ML, AI in Python for classes in Computational Linguistics, Natural Language Processing (NLP), Machine Learning (ML), and Artificial Intelligence (AI) at Indiana University.
README:
(C) 2016-2024 by Damir Cavar
NLP-Lab at Indiana University.
- Anthropic / VoyageAI Embeddings
- OpenAI Embeddings
- BERT Embeddings
- Claude 3 Interaction using the Anthropic API
- GPT-4 interaction using the OpenAI API
- Neo4j interaction
- Simple Transformer-based Text Classification
- Stanza Tutorial
- Converting SEC CIKs to a Knowledge Graph
- Allegro Graph example
- Extracting Abbreviations
- Bayesian Classification for Machine Learning for Computational Linguistics
- Python Tutorial 1: Part-of-Speech Tagging 1
- Lexical Clustering
- Linear Algebra
- Neural Network Example with Keras
- Computing Finite State Automata
- Parallel Processing on Multiple Threads
- Perceptron Learning in Python
- Clustering with Scikit-learn
- Simple Language ID with N-grams
- Support Vector Machine (SVM) Classifier Example
- Scikit-Learn for Computational Linguists
- Tutorial: Tokens and N-grams
- Tutorial 1: Part-of-Speech Tagging 1
- Tutorial 2: Hidden Markov Models
- Word Sense Disambiguation
- Python examples and notes for Machine Learning for Computational Linguistics
- RDFlib Graphs
- Scikit-learn Logistic Regression
- Convert the Stanford Sentiment Treebank Data to CSV
- TextRank Example
- NLTK: Texts and Frequencies - N-gram models and frequency profiles
- Parsing with NLTK
- Parsing with NLTK and Foma
- Categorial Grammar Parsing in NLTK
- Dependency Grammar in NLTK
- Document Classification Tutorial 1 - Amazon Reviews
- WordNet using NLTK
- WordNet and NLTK
- Framenet in NLTK
- FrameNet Examples using NLTK
- PropBank in NLTK
- Machine Translation in Python 3 with NLTK
- N-gram Models from Text for Language Models
- Probabilistic Context-free Grammar (PCFG) Parsing using NLTK
- Python for Text Similarities 1
- spaCy Tutorial
- spaCy 3.x Tutorial: Transformers Spanish
- spaCy Model from CoNLL Data
- Train spaCy Model for Marathi (mr)
- Linear Algebra and Embeddings - spaCy
See the licensing details on the individual documents and in the LICENSE file in the code folder.
The files in this folder are Jupyter-based tutorials for NLP, ML, AI in Python for classes I teach in Computational Linguistics, Natural Language Processing (NLP), Machine Learning (ML), and Artificial Intelligence (AI) at Indiana University.
If you find this material useful, please cite the author and source (that is Damir Cavar and all the sources cited in the relevant notebooks). Please let me know if you have some suggestions on how to correct the notebooks, improve them, or add some material and explanations.
The instructions below are somewhat outdated. I use just Jupyter-Lab now. Follow the instructions here to set it up on different machine types and operating systems.
To run this material in Jupyter you need to have Python 3.x and Jupyter installed. You can save yourself some trouble by using the Anaconda Python 3.x distribution.
Clone the project folder using:
git clone https://github.com/dcavar/python-tutorial-for-ipython.git
Some of the notebooks may contain code that requires various kinds of [Python] modules to be installed in specific versions. Some of the installations might be complicated and problematic. I am working on a more detailed description of installation procedures and dependencies for each notebook. Stay tuned, this is coming soon.
Jupyter is a great tool for computational publications, tutorials, and exercises. I set up my favorite components for Jupyter on Linux (for example Ubuntu) this way:
Assuming that I have some of the development tools installed, as for example gcc, make, etc., I install the packages python3-pip and python3-dev:
sudo apt install python3-pip python3-dev
After that I update the global system version of pip to the newest version:
sudo -H pip3 install -U pip
Then I install the newest Jupyter and Jupyterlab modules globally, updating any previously installed version:
sudo -H pip3 install -U jupyter jupyterlab
The module that we should not forget is plotly:
sudo -H pip3 install -U plotly
Scala, Clojure, and Groovy are extremely interesting languages as well, and I love working with Apache Spark, thus I install BeakerX as well. This requires two other [Python] modules: py4j and pandas. This presupposes that there is an existing Java JDK version 8 or newer already installed on the system. I install all the BeakerX related packages:
sudo -H pip3 install -U py4j
sudo -H pip3 install -U pandas
sudo -H pip3 install -U beakerx
To configure and install all BeakerX components I run:
sudo -H beakerx install
Some of the components I like to use require Node.js. On Ubuntu I usually add the newest Node.js as a PPA and not via Ubuntu Snap. Some instructions how to achieve that can be found here. To install Node.js on Ubuntu simply run:
sudo apt install nodejs
The following commands will add plugins and extensions to Jupyter globally:
sudo -H jupyter labextension install @jupyter-widgets/jupyterlab-manager
sudo -H jupyter labextension install @jupyterlab/plotly-extension
sudo -H jupyter labextension install beakerx-jupyterlab
Another useful package is Voilà, which allows you to turn Jupyter notebooks into standalone web applications. I install it using:
sudo -H pip3 install voila
Now the initial version of the platform is ready to go.
To start the Jupyter notebook viewer/editor on your local machine change into the notebooks folder within the cloned project folder and run the following command:
jupyter notebook
A browser window should open up that allows you full access to the notebooks.
Alternatively, check out the instructions how to launch JupyterLab, BeakerX, etc.
Enjoy!
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for python-tutorial-notebooks
Similar Open Source Tools
python-tutorial-notebooks
This repository contains Jupyter-based tutorials for NLP, ML, AI in Python for classes in Computational Linguistics, Natural Language Processing (NLP), Machine Learning (ML), and Artificial Intelligence (AI) at Indiana University.

conversational-agent-langchain
This repository contains a Rest-Backend for a Conversational Agent that allows embedding documents, semantic search, QA based on documents, and document processing with Large Language Models. It uses Aleph Alpha and OpenAI Large Language Models to generate responses to user queries, includes a vector database, and provides a REST API built with FastAPI. The project also features semantic search, secret management for API keys, installation instructions, and development guidelines for both backend and frontend components.
semantic-kernel-java
Semantic Kernel for Java is an SDK that integrates Large Language Models (LLMs) like OpenAI, Azure OpenAI, and Hugging Face with conventional programming languages like C#, Python, and Java. It allows defining plugins that can be chained together in just a few lines of code. The tool automatically orchestrates plugins with AI, enabling users to generate plans to achieve unique goals and execute them. The project welcomes contributions, bug reports, and suggestions from the community.
eShopSupport
eShopSupport is a sample .NET application showcasing common use cases and development practices for building AI solutions in .NET, specifically Generative AI. It demonstrates a customer support application for an e-commerce website using a services-based architecture with .NET Aspire. The application includes support for text classification, sentiment analysis, text summarization, synthetic data generation, and chat bot interactions. It also showcases development practices such as developing solutions locally, evaluating AI responses, leveraging Python projects, and deploying applications to the Cloud.
LangSim
LangSim is a tool developed to address the challenge of using simulation tools in computational chemistry and materials science, which typically require cryptic input files or programming experience. The tool provides a Large Language Model (LLM) extension with agents to couple the LLM to scientific simulation codes and calculate physical properties from a natural language interface. It aims to simplify the process of interacting with simulation tools by enabling users to query the large language model directly from a Python environment or a web-based interface.
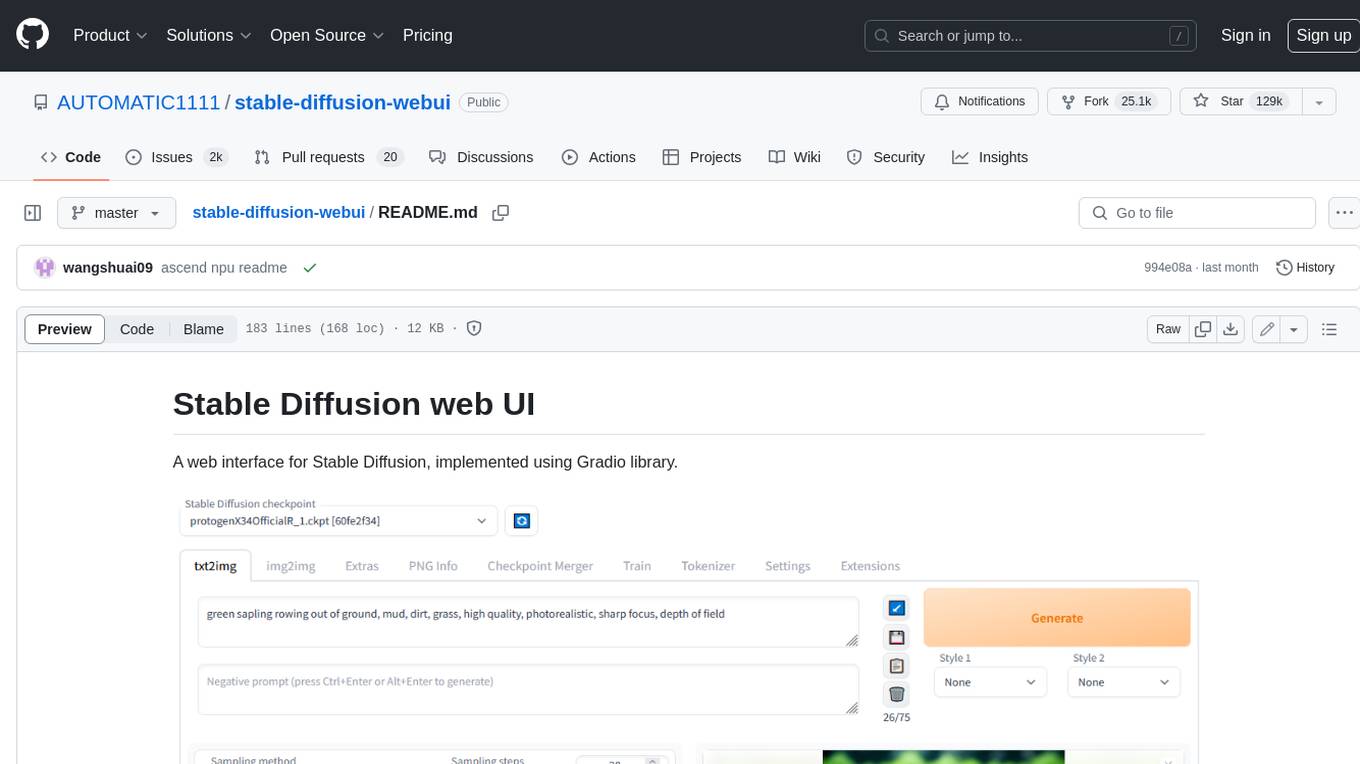
stable-diffusion-webui
Stable Diffusion web UI is a web interface for Stable Diffusion, implemented using Gradio library. It provides a user-friendly interface to access the powerful image generation capabilities of Stable Diffusion. With Stable Diffusion web UI, users can easily generate images from text prompts, edit and refine images using inpainting and outpainting, and explore different artistic styles and techniques. The web UI also includes a range of advanced features such as textual inversion, hypernetworks, and embeddings, allowing users to customize and fine-tune the image generation process. Whether you're an artist, designer, or simply curious about the possibilities of AI-generated art, Stable Diffusion web UI is a valuable tool that empowers you to create stunning and unique images.
aigt
AIGT is a repository containing scripts for deep learning in guided medical interventions, focusing on ultrasound imaging. It provides a complete workflow from formatting and annotations to real-time model deployment. Users can set up an Anaconda environment, run Slicer notebooks, acquire tracked ultrasound data, and process exported data for training. The repository includes tools for segmentation, image export, and annotation creation.

LlamaIndexTS
LlamaIndex.TS is a data framework for your LLM application. Use your own data with large language models (LLMs, OpenAI ChatGPT and others) in Typescript and Javascript.
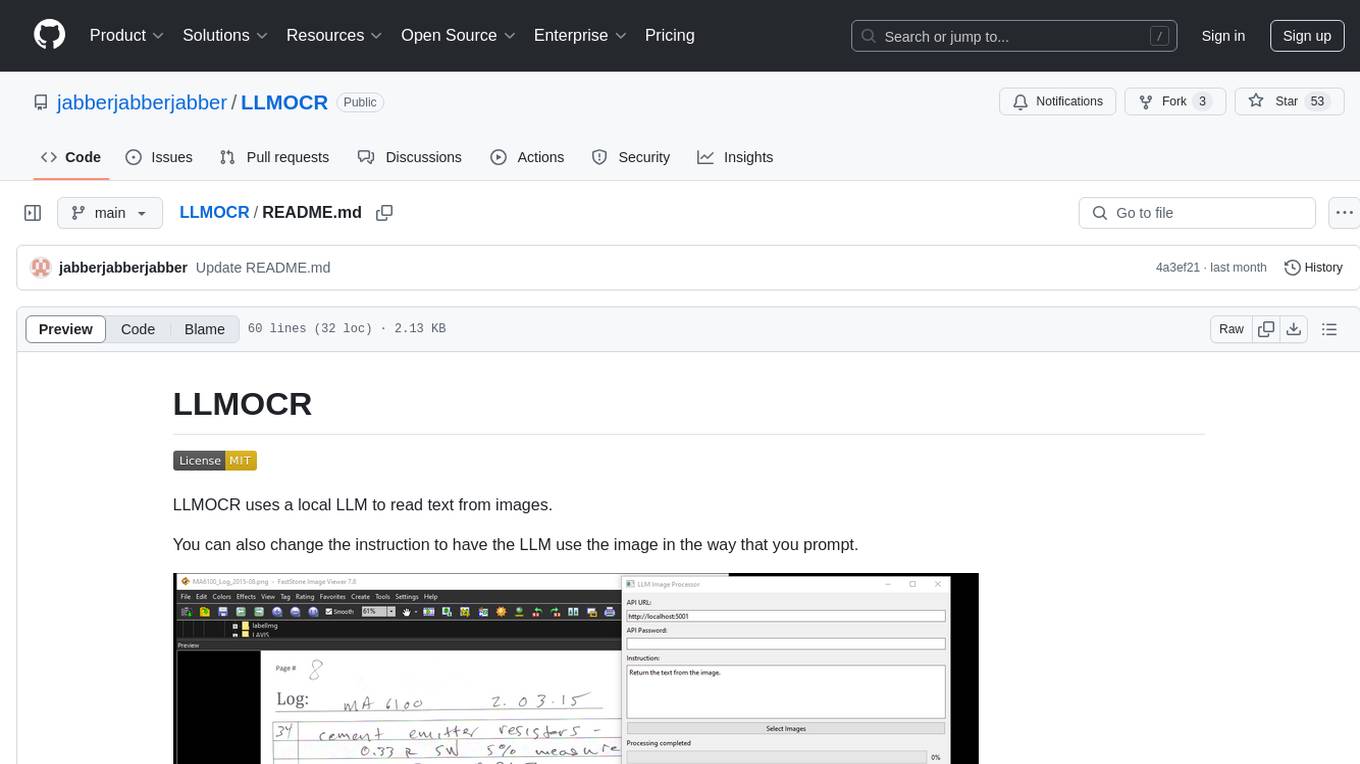
LLMOCR
LLMOCR is a tool that utilizes a local Large Language Model (LLM) to extract text from images. It offers a user-friendly GUI and supports GPU acceleration for faster inference. The tool is cross-platform, compatible with Windows, macOS ARM, and Linux. Users can prompt the LLM to process images in a customized way. The processing is done locally on the user's machine, ensuring data privacy and security. LLMOCR requires Python 3.8 or higher and KoboldCPP for installation and operation.
ctakes
Apache cTAKES is a clinical Text Analysis and Knowledge Extraction System that focuses on extracting knowledge from clinical text through Natural Language Processing (NLP) techniques. It is modular and employs rule-based and machine learning methods to extract concepts such as symptoms, procedures, diagnoses, medications, and anatomy with attributes and standard codes. cTAKES can identify temporal events, dates, and times, placing events in a patient timeline. It supports various biomedical text processing tasks and can handle different types of clinical and health-related narratives using multiple data standards. cTAKES is widely used in research initiatives and encourages contributions from professionals, researchers, doctors, and students from diverse backgrounds.
oneAPI-samples
The oneAPI-samples repository contains a collection of samples for the Intel oneAPI Toolkits. These samples cover various topics such as AI and analytics, end-to-end workloads, features and functionality, getting started samples, Jupyter notebooks, direct programming, C++, Fortran, libraries, publications, rendering toolkit, and tools. Users can find samples based on expertise, programming language, and target device. The repository structure is organized by high-level categories, and platform validation includes Ubuntu 22.04, Windows 11, and macOS. The repository provides instructions for getting samples, including cloning the repository or downloading specific tagged versions. Users can also use integrated development environments (IDEs) like Visual Studio Code. The code samples are licensed under the MIT license.

Dot
Dot is a standalone, open-source application designed for seamless interaction with documents and files using local LLMs and Retrieval Augmented Generation (RAG). It is inspired by solutions like Nvidia's Chat with RTX, providing a user-friendly interface for those without a programming background. Pre-packaged with Mistral 7B, Dot ensures accessibility and simplicity right out of the box. Dot allows you to load multiple documents into an LLM and interact with them in a fully local environment. Supported document types include PDF, DOCX, PPTX, XLSX, and Markdown. Users can also engage with Big Dot for inquiries not directly related to their documents, similar to interacting with ChatGPT. Built with Electron JS, Dot encapsulates a comprehensive Python environment that includes all necessary libraries. The application leverages libraries such as FAISS for creating local vector stores, Langchain, llama.cpp & Huggingface for setting up conversation chains, and additional tools for document management and interaction.

kdbai-samples
KDB.AI is a time-based vector database that allows developers to build scalable, reliable, and real-time applications by providing advanced search, recommendation, and personalization for Generative AI applications. It supports multiple index types, distance metrics, top-N and metadata filtered retrieval, as well as Python and REST interfaces. The repository contains samples demonstrating various use-cases such as temporal similarity search, document search, image search, recommendation systems, sentiment analysis, and more. KDB.AI integrates with platforms like ChatGPT, Langchain, and LlamaIndex. The setup steps require Unix terminal, Python 3.8+, and pip installed. Users can install necessary Python packages and run Jupyter notebooks to interact with the samples.
hof
Hof is a CLI tool that unifies data models, schemas, code generation, and a task engine. It allows users to augment data, config, and schemas with CUE to improve consistency, generate multiple Yaml and JSON files, explore data or config with a TUI, and run workflows with automatic task dependency inference. The tool uses CUE to power the DX and implementation, providing a language for specifying schemas, configuration, and writing declarative code. Hof offers core features like code generation, data model management, task engine, CUE cmds, creators, modules, TUI, and chat for better, scalable results.
SmallLanguageModel-project
This repository provides all the necessary items to build a Language Model from scratch, inspired by Karpathy's nanoGPT and Shakespeare generator. It includes data collection tools, data processing scripts, various models like BERT, GPT, and Seq-2-Seq, along with tokenizer and training files.
PyAirbyte
PyAirbyte brings the power of Airbyte to every Python developer by providing a set of utilities to use Airbyte connectors in Python. It enables users to easily manage secrets, work with various connectors like GitHub, Shopify, and Postgres, and contribute to the project. PyAirbyte is not a replacement for Airbyte but complements it, supporting data orchestration frameworks like Airflow and Snowpark. Users can develop ETL pipelines and import connectors from local directories. The tool simplifies data integration tasks for Python developers.
For similar tasks

Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.

sorrentum
Sorrentum is an open-source project that aims to combine open-source development, startups, and brilliant students to build machine learning, AI, and Web3 / DeFi protocols geared towards finance and economics. The project provides opportunities for internships, research assistantships, and development grants, as well as the chance to work on cutting-edge problems, learn about startups, write academic papers, and get internships and full-time positions at companies working on Sorrentum applications.

tidb
TiDB is an open-source distributed SQL database that supports Hybrid Transactional and Analytical Processing (HTAP) workloads. It is MySQL compatible and features horizontal scalability, strong consistency, and high availability.

zep-python
Zep is an open-source platform for building and deploying large language model (LLM) applications. It provides a suite of tools and services that make it easy to integrate LLMs into your applications, including chat history memory, embedding, vector search, and data enrichment. Zep is designed to be scalable, reliable, and easy to use, making it a great choice for developers who want to build LLM-powered applications quickly and easily.

telemetry-airflow
This repository codifies the Airflow cluster that is deployed at workflow.telemetry.mozilla.org (behind SSO) and commonly referred to as "WTMO" or simply "Airflow". Some links relevant to users and developers of WTMO: * The `dags` directory in this repository contains some custom DAG definitions * Many of the DAGs registered with WTMO don't live in this repository, but are instead generated from ETL task definitions in bigquery-etl * The Data SRE team maintains a WTMO Developer Guide (behind SSO)

mojo
Mojo is a new programming language that bridges the gap between research and production by combining Python syntax and ecosystem with systems programming and metaprogramming features. Mojo is still young, but it is designed to become a superset of Python over time.

pandas-ai
PandasAI is a Python library that makes it easy to ask questions to your data in natural language. It helps you to explore, clean, and analyze your data using generative AI.

databend
Databend is an open-source cloud data warehouse that serves as a cost-effective alternative to Snowflake. With its focus on fast query execution and data ingestion, it's designed for complex analysis of the world's largest datasets.
For similar jobs

LLM-FineTuning-Large-Language-Models
This repository contains projects and notes on common practical techniques for fine-tuning Large Language Models (LLMs). It includes fine-tuning LLM notebooks, Colab links, LLM techniques and utils, and other smaller language models. The repository also provides links to YouTube videos explaining the concepts and techniques discussed in the notebooks.

lloco
LLoCO is a technique that learns documents offline through context compression and in-domain parameter-efficient finetuning using LoRA, which enables LLMs to handle long context efficiently.

camel
CAMEL is an open-source library designed for the study of autonomous and communicative agents. We believe that studying these agents on a large scale offers valuable insights into their behaviors, capabilities, and potential risks. To facilitate research in this field, we implement and support various types of agents, tasks, prompts, models, and simulated environments.
llm-baselines
LLM-baselines is a modular codebase to experiment with transformers, inspired from NanoGPT. It provides a quick and easy way to train and evaluate transformer models on a variety of datasets. The codebase is well-documented and easy to use, making it a great resource for researchers and practitioners alike.
python-tutorial-notebooks
This repository contains Jupyter-based tutorials for NLP, ML, AI in Python for classes in Computational Linguistics, Natural Language Processing (NLP), Machine Learning (ML), and Artificial Intelligence (AI) at Indiana University.
EvalAI
EvalAI is an open-source platform for evaluating and comparing machine learning (ML) and artificial intelligence (AI) algorithms at scale. It provides a central leaderboard and submission interface, making it easier for researchers to reproduce results mentioned in papers and perform reliable & accurate quantitative analysis. EvalAI also offers features such as custom evaluation protocols and phases, remote evaluation, evaluation inside environments, CLI support, portability, and faster evaluation.
Weekly-Top-LLM-Papers
This repository provides a curated list of weekly published Large Language Model (LLM) papers. It includes top important LLM papers for each week, organized by month and year. The papers are categorized into different time periods, making it easy to find the most recent and relevant research in the field of LLM.
self-llm
This project is a Chinese tutorial for domestic beginners based on the AutoDL platform, providing full-process guidance for various open-source large models, including environment configuration, local deployment, and efficient fine-tuning. It simplifies the deployment, use, and application process of open-source large models, enabling more ordinary students and researchers to better use open-source large models and helping open and free large models integrate into the lives of ordinary learners faster.