
llm-baselines
None
Stars: 58
LLM-baselines is a modular codebase to experiment with transformers, inspired from NanoGPT. It provides a quick and easy way to train and evaluate transformer models on a variety of datasets. The codebase is well-documented and easy to use, making it a great resource for researchers and practitioners alike.
README:
A modular codebase to experiment with transformers, inspired from NanoGPT.
Install dependencies:
pip install -r requirements.txt
Run a simple training on the Wikitext dataset:
python ./src/main.py
The above command trains a 213.34M parameters model (see the "Results on wikitext" section for more details). The training takes a bit less than 5h on one 40GB A100. It trains for 15k iterations with a batch size of 50x4 (4 gradient accumulation steps), hence a speed of 0.84 iteration per second, or 86k tokens per second. You should reach a perplexity of around 18.5.
If you don't have so much VRAM:
python ./src/main.py --n_layer 12 --sequence_length 256
If you have very limited resources, try the shakespeare dataset and character-based tokenizer:
python ./src/main.py --n_layer=2 --n_head=4 --n_embd=128 --sequence_length=256 --dataset=shakespeare-char --device=cpu --vocab_size=96
Here are the possible parameters you can use (copypasta from config/base.py):
# General training params
parser.add_argument('--batch_size', default=50, type=int)
parser.add_argument('--acc_steps', default=4, type=int)
parser.add_argument('--seed', default=0, type=int)
parser.add_argument('--device', default='cuda:0', type=str)
parser.add_argument('--iterations', default=15000, type=int)
parser.add_argument('--lr', default=2e-3, type=float)
parser.add_argument('--warmup_percent', default=0.02, type=float)
parser.add_argument('--weight_decay', default=1e-3, type=float)
parser.add_argument('--beta1', default=0.9, type=float)
parser.add_argument('--beta2', default=0.95, type=float)
parser.add_argument('--scheduler', default='cos', choices=['linear', 'cos', 'none'])
parser.add_argument('--opt', default='adamw', choices=['adamw', 'sgd'])
parser.add_argument('--eval_freq', default=200, type=int) # in iterations
parser.add_argument('--results_base_folder', default="./exps", type=str)
# Dataset params
parser.add_argument('--dataset', default='wikitext', choices=['wikitext', "shakespeare-char", 'arxiv', "arxiv2000", "arxiv+wiki", 'openwebtext2'])
parser.add_argument('--vocab_size', default=50304, type=int)
parser.add_argument('--data_in_ram', action='store_true') # force the data to RAM, mostly useless except for openwebtext2
# Model params
parser.add_argument('--model', default='base', choices=['base', 'sparse-heads-q'])
parser.add_argument('--use_pretrained', default="none", type=str) # 'none', 'gpt-2' or a path to the pretraind model
parser.add_argument('--dropout', default=0.2, type=float)
parser.add_argument('--n_head', default=12, type=int)
parser.add_argument('--n_layer', default=24, type=int) # depths in att + ff blocks
parser.add_argument('--n_embd', default=768, type=int) # embedding size / hidden size ...
parser.add_argument('--sequence_length', default=512, type=int)
parser.add_argument('--dtype', default=torch.bfloat16, type=torch.dtype)
parser.add_argument('--bias', default=False, type=bool)
parser.add_argument('--no_compile', action='store_true') # if true then model is not compiled
# logging params (WandB)
parser.add_argument('--wandb', action='store_true') # whether to use wandb or not
parser.add_argument('--wandb_project', default="my-project", type=str)
parser.add_argument('--wandb_run_prefix', default="none", type=str) # is added before the autogenerated experiment name
parser.add_argument('--eval_seq_prefix', default="The history of Switzerland ", type=str) # prefix used to generate sequences
# Distributed args
parser.add_argument('--distributed_backend', default=None, type=str, required=False,
choices=distributed.registered_backends()) # distributed backend typeYou need to give your wandb authorize key in order to send the data to your wandb account. If you start jobs on a server without access to prompt, then you can set the WANDB_API_KEY variable within your script:
# this is a script that could be executed on a server
pip install -r requirements.txt # install req.
export WANDB_API_KEY="put your authorize key here, to find it: https://wandb.ai/authorize"
python ./src/main.py --wandb --wandb_project "my awesome project" --n_layer 7 --model base --seed 123The structure of the project is the following:
src/
main.py # pick the right data, model, and training function
config/
__init__.py # contains CONFIG_FORMAT_TO_MODULE_MAP mapping the name given to the --config_format flag with a python conf file
base.py # config for the base model
sparse.py # config for some sparsehq model
data/
utils.py # contains the get_dataset function
wikitext.py # load/process wikitext
arxiv.py # load/process arxiv
shakespeare.py # load/process the Shakespeare dataset
models/
utils.py # contains the get_model function
base.py # contains the standard transformer base architecture
sparsehq.py # a fork of base.py with a different architecture
optim/
utils.py # contains eval and get_batch functions
base.py # training function for the base model
sparse.py # training function for the sparsehq model
distributed/
# code to enable simple distributed trainingGiven the above structure, to add your own model, you can just fork the ./src/models/base.py file, do your modifications, then if necessary fork the ./src/optim/base.py in case you need some custom training loop or evaluation. You also need to fork the ./src/config/base.py file to add your own parameters, which imply adding your new config to the mapping CONFIG_FORMAT_TO_MODULE_MAP in ./src/config/__init__.py. To add a new dataset, create a new file in the data folder, check wikitext.py for the expected format.
Trying to get the best perplexity as fast as possible, I settled for using a model (213.34M parameters) with the following parameters:
- n_embd: 768
- n_head: 12
- dropout: 0.2 (0.1 also works fine)
- n_layer: 24
- sequence_length: 512
- batch_size: 50
- acc_steps: 4
- iterations: 15000
- lr: 0.002
- warmup_percent: 0.02
The training reaches convergence after a bit less than 5 hours (on one 40GB A100), with a perplexity around 18.5, which I believe to be good for a non-pretrained model. The figure below shows the evolution of perplexity for two models with and without dropout, showing the importance of dropout. It should be possiblee to reach similar perplexity without dropout with a smaller batch size but this would probably extend the duration of the training.

A lighter and faster (12 layers instead of 24) but still very good config on wikitext:
- n_embd: 768
- n_head: 12
- n_layer: 12
- batch_size: 55
- sequence_length: 512
- acc_steps: 3
- dropout: 0.2
- iterations: 15000
- lr: 0.002
- warmup_percent: 0.02
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for llm-baselines
Similar Open Source Tools
llm-baselines
LLM-baselines is a modular codebase to experiment with transformers, inspired from NanoGPT. It provides a quick and easy way to train and evaluate transformer models on a variety of datasets. The codebase is well-documented and easy to use, making it a great resource for researchers and practitioners alike.

hqq
HQQ is a fast and accurate model quantizer that skips the need for calibration data. It's super simple to implement (just a few lines of code for the optimizer). It can crunch through quantizing the Llama2-70B model in only 4 minutes! 🚀

zeta
Zeta is a tool designed to build state-of-the-art AI models faster by providing modular, high-performance, and scalable building blocks. It addresses the common issues faced while working with neural nets, such as chaotic codebases, lack of modularity, and low performance modules. Zeta emphasizes usability, modularity, and performance, and is currently used in hundreds of models across various GitHub repositories. It enables users to prototype, train, optimize, and deploy the latest SOTA neural nets into production. The tool offers various modules like FlashAttention, SwiGLUStacked, RelativePositionBias, FeedForward, BitLinear, PalmE, Unet, VisionEmbeddings, niva, FusedDenseGELUDense, FusedDropoutLayerNorm, MambaBlock, Film, hyper_optimize, DPO, and ZetaCloud for different tasks in AI model development.

ChatRex
ChatRex is a Multimodal Large Language Model (MLLM) designed to seamlessly integrate fine-grained object perception and robust language understanding. By adopting a decoupled architecture with a retrieval-based approach for object detection and leveraging high-resolution visual inputs, ChatRex addresses key challenges in perception tasks. It is powered by the Rexverse-2M dataset with diverse image-region-text annotations. ChatRex can be applied to various scenarios requiring fine-grained perception, such as object detection, grounded conversation, grounded image captioning, and region understanding.
cappr
CAPPr is a tool for text classification that does not require training or post-processing. It allows users to have their language models pick from a list of choices or compute the probability of a completion given a prompt. The tool aims to help users get more out of open source language models by simplifying the text classification process. CAPPr can be used with GGUF models, Hugging Face models, models from the OpenAI API, and for tasks like caching instructions, extracting final answers from step-by-step completions, and running predictions in batches with different sets of completions.

LightRAG
LightRAG is a PyTorch library designed for building and optimizing Retriever-Agent-Generator (RAG) pipelines. It follows principles of simplicity, quality, and optimization, offering developers maximum customizability with minimal abstraction. The library includes components for model interaction, output parsing, and structured data generation. LightRAG facilitates tasks like providing explanations and examples for concepts through a question-answering pipeline.

xlstm
xLSTM is a new Recurrent Neural Network architecture based on ideas of the original LSTM. Through Exponential Gating with appropriate normalization and stabilization techniques and a new Matrix Memory it overcomes the limitations of the original LSTM and shows promising performance on Language Modeling when compared to Transformers or State Space Models. The package is based on PyTorch and was tested for versions >=1.8. For the CUDA version of xLSTM, you need Compute Capability >= 8.0. The xLSTM tool provides two main components: xLSTMBlockStack for non-language applications or integrating in other architectures, and xLSTMLMModel for language modeling or other token-based applications.

create-million-parameter-llm-from-scratch
The 'create-million-parameter-llm-from-scratch' repository provides a detailed guide on creating a Large Language Model (LLM) with 2.3 million parameters from scratch. The blog replicates the LLaMA approach, incorporating concepts like RMSNorm for pre-normalization, SwiGLU activation function, and Rotary Embeddings. The model is trained on a basic dataset to demonstrate the ease of creating a million-parameter LLM without the need for a high-end GPU.
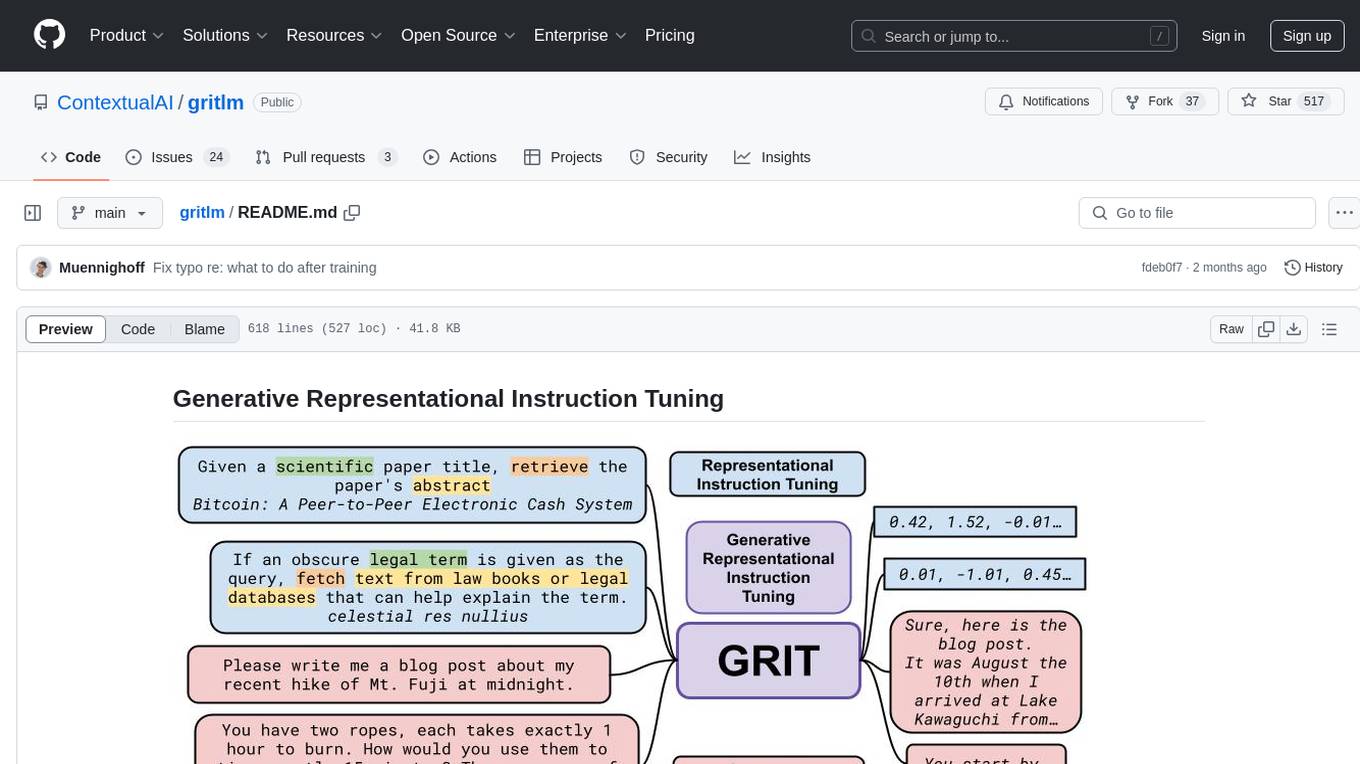
gritlm
The 'gritlm' repository provides all materials for the paper Generative Representational Instruction Tuning. It includes code for inference, training, evaluation, and known issues related to the GritLM model. The repository also offers models for embedding and generation tasks, along with instructions on how to train and evaluate the models. Additionally, it contains visualizations, acknowledgements, and a citation for referencing the work.
flow-prompt
Flow Prompt is a dynamic library for managing and optimizing prompts for large language models. It facilitates budget-aware operations, dynamic data integration, and efficient load distribution. Features include CI/CD testing, dynamic prompt development, multi-model support, real-time insights, and prompt testing and evolution.

phidata
Phidata is a framework for building AI Assistants with memory, knowledge, and tools. It enables LLMs to have long-term conversations by storing chat history in a database, provides them with business context by storing information in a vector database, and enables them to take actions like pulling data from an API, sending emails, or querying a database. Memory and knowledge make LLMs smarter, while tools make them autonomous.

FlashLearn
FlashLearn is a tool that provides a simple interface and orchestration for incorporating Agent LLMs into workflows and ETL pipelines. It allows data transformations, classifications, summarizations, rewriting, and custom multi-step tasks using LLMs. Each step and task has a compact JSON definition, making pipelines easy to understand and maintain. FlashLearn supports LiteLLM, Ollama, OpenAI, DeepSeek, and other OpenAI-compatible clients.

CEO-Agentic-AI-Framework
CEO-Agentic-AI-Framework is an ultra-lightweight Agentic AI framework based on the ReAct paradigm. It supports mainstream LLMs and is stronger than Swarm. The framework allows users to build their own agents, assign tasks, and interact with them through a set of predefined abilities. Users can customize agent personalities, grant and deprive abilities, and assign queries for specific tasks. CEO also supports multi-agent collaboration scenarios, where different agents with distinct capabilities can work together to achieve complex tasks. The framework provides a quick start guide, examples, and detailed documentation for seamless integration into research projects.
SimplerLLM
SimplerLLM is an open-source Python library that simplifies interactions with Large Language Models (LLMs) for researchers and beginners. It provides a unified interface for different LLM providers, tools for enhancing language model capabilities, and easy development of AI-powered tools and apps. The library offers features like unified LLM interface, generic text loader, RapidAPI connector, SERP integration, prompt template builder, and more. Users can easily set up environment variables, create LLM instances, use tools like SERP, generic text loader, calling RapidAPI APIs, and prompt template builder. Additionally, the library includes chunking functions to split texts into manageable chunks based on different criteria. Future updates will bring more tools, interactions with local LLMs, prompt optimization, response evaluation, GPT Trainer, document chunker, advanced document loader, integration with more providers, Simple RAG with SimplerVectors, integration with vector databases, agent builder, and LLM server.
llm-client
LLMClient is a JavaScript/TypeScript library that simplifies working with large language models (LLMs) by providing an easy-to-use interface for building and composing efficient prompts using prompt signatures. These signatures enable the automatic generation of typed prompts, allowing developers to leverage advanced capabilities like reasoning, function calling, RAG, ReAcT, and Chain of Thought. The library supports various LLMs and vector databases, making it a versatile tool for a wide range of applications.
For similar tasks
llm-baselines
LLM-baselines is a modular codebase to experiment with transformers, inspired from NanoGPT. It provides a quick and easy way to train and evaluate transformer models on a variety of datasets. The codebase is well-documented and easy to use, making it a great resource for researchers and practitioners alike.
For similar jobs

LLM-FineTuning-Large-Language-Models
This repository contains projects and notes on common practical techniques for fine-tuning Large Language Models (LLMs). It includes fine-tuning LLM notebooks, Colab links, LLM techniques and utils, and other smaller language models. The repository also provides links to YouTube videos explaining the concepts and techniques discussed in the notebooks.

lloco
LLoCO is a technique that learns documents offline through context compression and in-domain parameter-efficient finetuning using LoRA, which enables LLMs to handle long context efficiently.

camel
CAMEL is an open-source library designed for the study of autonomous and communicative agents. We believe that studying these agents on a large scale offers valuable insights into their behaviors, capabilities, and potential risks. To facilitate research in this field, we implement and support various types of agents, tasks, prompts, models, and simulated environments.
llm-baselines
LLM-baselines is a modular codebase to experiment with transformers, inspired from NanoGPT. It provides a quick and easy way to train and evaluate transformer models on a variety of datasets. The codebase is well-documented and easy to use, making it a great resource for researchers and practitioners alike.
python-tutorial-notebooks
This repository contains Jupyter-based tutorials for NLP, ML, AI in Python for classes in Computational Linguistics, Natural Language Processing (NLP), Machine Learning (ML), and Artificial Intelligence (AI) at Indiana University.
EvalAI
EvalAI is an open-source platform for evaluating and comparing machine learning (ML) and artificial intelligence (AI) algorithms at scale. It provides a central leaderboard and submission interface, making it easier for researchers to reproduce results mentioned in papers and perform reliable & accurate quantitative analysis. EvalAI also offers features such as custom evaluation protocols and phases, remote evaluation, evaluation inside environments, CLI support, portability, and faster evaluation.
Weekly-Top-LLM-Papers
This repository provides a curated list of weekly published Large Language Model (LLM) papers. It includes top important LLM papers for each week, organized by month and year. The papers are categorized into different time periods, making it easy to find the most recent and relevant research in the field of LLM.
self-llm
This project is a Chinese tutorial for domestic beginners based on the AutoDL platform, providing full-process guidance for various open-source large models, including environment configuration, local deployment, and efficient fine-tuning. It simplifies the deployment, use, and application process of open-source large models, enabling more ordinary students and researchers to better use open-source large models and helping open and free large models integrate into the lives of ordinary learners faster.