
pandas-ai
Chat with your database or your datalake (SQL, CSV, parquet). PandasAI makes data analysis conversational using LLMs and RAG.
Stars: 17885
PandaAI is a Python platform that enables users to interact with their data in natural language, catering to both non-technical and technical users. It simplifies data querying and analysis, offering conversational data analytics capabilities with minimal code. Users can ask questions, visualize charts, and compare dataframes effortlessly. The tool aims to streamline data exploration and decision-making processes by providing a user-friendly interface for data manipulation and analysis.
README:

![]()
![]()
PandaAI is a Python platform that makes it easy to ask questions to your data in natural language. It helps non-technical users to interact with their data in a more natural way, and it helps technical users to save time, and effort when working with data.
You can find the full documentation for PandaAI here.
You can either decide to use PandaAI in your Jupyter notebooks, Streamlit apps, or use the client and server architecture from the repo.
The library can be used alongside our powerful data platform, making end-to-end conversational data analytics possible with as little as a few lines of code.
Load your data, save them as a dataframe, and push them to the platform
import pandasai as pai
pai.api_key.set("your-pai-api-key")
file = pai.read_csv("./filepath.csv")
dataset = pai.create(path="your-organization/dataset-name",
df=file,
name="dataset-name",
description="dataset-description")
dataset.push()Your team can now access and query this data using natural language through the platform.

Python version 3.8+ <3.12
You can install the PandaAI library using pip or poetry.
With pip:
pip install "pandasai>=3.0.0b2"With poetry:
poetry add "pandasai>=3.0.0b2"import pandasai as pai
# Sample DataFrame
df = pai.DataFrame({
"country": ["United States", "United Kingdom", "France", "Germany", "Italy", "Spain", "Canada", "Australia", "Japan", "China"],
"revenue": [5000, 3200, 2900, 4100, 2300, 2100, 2500, 2600, 4500, 7000]
})
# By default, unless you choose a different LLM, it will use BambooLLM.
# You can get your free API key signing up at https://app.pandabi.ai (you can also configure it in your .env file)
pai.api_key.set("your-pai-api-key")
df.chat('Which are the top 5 countries by sales?')China, United States, Japan, Germany, Australia
Or you can ask more complex questions:
df.chat(
"What is the total sales for the top 3 countries by sales?"
)The total sales for the top 3 countries by sales is 16500.
You can also ask PandaAI to generate charts for you:
df.chat(
"Plot the histogram of countries showing for each one the gd. Use different colors for each bar",
)
You can also pass in multiple dataframes to PandaAI and ask questions relating them.
import pandasai as pai
employees_data = {
'EmployeeID': [1, 2, 3, 4, 5],
'Name': ['John', 'Emma', 'Liam', 'Olivia', 'William'],
'Department': ['HR', 'Sales', 'IT', 'Marketing', 'Finance']
}
salaries_data = {
'EmployeeID': [1, 2, 3, 4, 5],
'Salary': [5000, 6000, 4500, 7000, 5500]
}
employees_df = pai.DataFrame(employees_data)
salaries_df = pai.DataFrame(salaries_data)
# By default, unless you choose a different LLM, it will use BambooLLM.
# You can get your free API key signing up at https://app.pandabi.ai (you can also configure it in your .env file)
pai.api_key.set("your-pai-api-key")
pai.chat("Who gets paid the most?", employees_df, salaries_df)Olivia gets paid the most.
You can run PandaAI in a Docker sandbox, providing a secure, isolated environment to execute code safely and mitigate the risk of malicious attacks.
pip install "pandasai-docker"import pandasai as pai
from pandasai_docker import DockerSandbox
# Initialize the sandbox
sandbox = DockerSandbox()
sandbox.start()
employees_data = {
'EmployeeID': [1, 2, 3, 4, 5],
'Name': ['John', 'Emma', 'Liam', 'Olivia', 'William'],
'Department': ['HR', 'Sales', 'IT', 'Marketing', 'Finance']
}
salaries_data = {
'EmployeeID': [1, 2, 3, 4, 5],
'Salary': [5000, 6000, 4500, 7000, 5500]
}
employees_df = pai.DataFrame(employees_data)
salaries_df = pai.DataFrame(salaries_data)
# By default, unless you choose a different LLM, it will use BambooLLM.
# You can get your free API key signing up at https://app.pandabi.ai (you can also configure it in your .env file)
pai.api_key.set("your-pai-api-key")
pai.chat("Who gets paid the most?", employees_df, salaries_df, sandbox=sandbox)
# Don't forget to stop the sandbox when done
sandbox.stop()Olivia gets paid the most.
You can find more examples in the examples directory.
PandaAI is available under the MIT expat license, except for the pandasai/ee directory of this repository, which has its license here.
If you are interested in managed PandaAI Cloud or self-hosted Enterprise Offering, contact us.
Beta Notice
Release v3 is currently in beta. The following documentation and examples reflect the features and functionality in progress and may change before the final release.
- Docs for comprehensive documentation
- Examples for example notebooks
- Discord for discussion with the community and PandaAI team
Contributions are welcome! Please check the outstanding issues and feel free to open a pull request. For more information, please check out the contributing guidelines.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for pandas-ai
Similar Open Source Tools
pandas-ai
PandaAI is a Python platform that enables users to interact with their data in natural language, catering to both non-technical and technical users. It simplifies data querying and analysis, offering conversational data analytics capabilities with minimal code. Users can ask questions, visualize charts, and compare dataframes effortlessly. The tool aims to streamline data exploration and decision-making processes by providing a user-friendly interface for data manipulation and analysis.

memobase
Memobase is a user profile-based memory system designed to enhance Generative AI applications by enabling them to remember, understand, and evolve with users. It provides structured user profiles, scalable profiling, easy integration with existing LLM stacks, batch processing for speed, and is production-ready. Users can manage users, insert data, get memory profiles, and track user preferences and behaviors. Memobase is ideal for applications that require user analysis, tracking, and personalized interactions.

vinagent
Vinagent is a lightweight and flexible library designed for building smart agent assistants across various industries. It provides a simple yet powerful foundation for creating AI-powered customer service bots, data analysis assistants, or domain-specific automation agents. With its modular tool system, users can easily extend their agent's capabilities by integrating a wide range of tools that are self-contained, well-documented, and can be registered dynamically. Vinagent allows users to scale and adapt their agents to new tasks or environments effortlessly.
perplexity-ai
Perplexity is a module that utilizes emailnator to generate new accounts, providing users with 5 pro queries per account creation. It enables the creation of new Gmail accounts with emailnator, ensuring unlimited pro queries. The tool requires specific Python libraries for installation and offers both a web interface and an API for different usage scenarios. Users can interact with the tool to perform various tasks such as account creation, query searches, and utilizing different modes for research purposes. Perplexity also supports asynchronous operations and provides guidance on obtaining cookies for account usage and account generation from emailnator.

awadb
AwaDB is an AI native database designed for embedding vectors. It simplifies database usage by eliminating the need for schema definition and manual indexing. The system ensures real-time search capabilities with millisecond-level latency. Built on 5 years of production experience with Vearch, AwaDB incorporates best practices from the community to offer stability and efficiency. Users can easily add and search for embedded sentences using the provided client libraries or RESTful API.
cappr
CAPPr is a tool for text classification that does not require training or post-processing. It allows users to have their language models pick from a list of choices or compute the probability of a completion given a prompt. The tool aims to help users get more out of open source language models by simplifying the text classification process. CAPPr can be used with GGUF models, Hugging Face models, models from the OpenAI API, and for tasks like caching instructions, extracting final answers from step-by-step completions, and running predictions in batches with different sets of completions.

LLM-Blender
LLM-Blender is a framework for ensembling large language models (LLMs) to achieve superior performance. It consists of two modules: PairRanker and GenFuser. PairRanker uses pairwise comparisons to distinguish between candidate outputs, while GenFuser merges the top-ranked candidates to create an improved output. LLM-Blender has been shown to significantly surpass the best LLMs and baseline ensembling methods across various metrics on the MixInstruct benchmark dataset.

OpenMusic
OpenMusic is a repository providing an implementation of QA-MDT, a Quality-Aware Masked Diffusion Transformer for music generation. The code integrates state-of-the-art models and offers training strategies for music generation. The repository includes implementations of AudioLDM, PixArt-alpha, MDT, AudioMAE, and Open-Sora. Users can train or fine-tune the model using different strategies and datasets. The model is well-pretrained and can be used for music generation tasks. The repository also includes instructions for preparing datasets, training the model, and performing inference. Contact information is provided for any questions or suggestions regarding the project.

qa-mdt
This repository provides an implementation of QA-MDT, integrating state-of-the-art models for music generation. It offers a Quality-Aware Masked Diffusion Transformer for enhanced music generation. The code is based on various repositories like AudioLDM, PixArt-alpha, MDT, AudioMAE, and Open-Sora. The implementation allows for training and fine-tuning the model with different strategies and datasets. The repository also includes instructions for preparing datasets in LMDB format and provides a script for creating a toy LMDB dataset. The model can be used for music generation tasks, with a focus on quality injection to enhance the musicality of generated music.

fastc
Fastc is a tool focused on CPU execution, using efficient models for embedding generation and cosine similarity classification. It allows for efficient multi-classifier execution without extra overhead. Users can easily train text classifiers, export models, publish to HuggingFace, load existing models, make class predictions, use instruct templates, and launch an inference server. The tool provides an HTTP API for text classification with JSON payloads and supports multiple languages for language identification.

comet-llm
CometLLM is a tool to log and visualize your LLM prompts and chains. Use CometLLM to identify effective prompt strategies, streamline your troubleshooting, and ensure reproducible workflows!
llm
llm.rb is a zero-dependency Ruby toolkit for Large Language Models that includes OpenAI, Gemini, Anthropic, xAI (Grok), DeepSeek, Ollama, and LlamaCpp. The toolkit provides full support for chat, streaming, tool calling, audio, images, files, and structured outputs (JSON Schema). It offers a single unified interface for multiple providers, zero dependencies outside Ruby's standard library, smart API design, and optional per-provider process-wide connection pool. Features include chat, agents, media support (text-to-speech, transcription, translation, image generation, editing), embeddings, model management, and more.

suno-api
Suno AI API is an open-source project that allows developers to integrate the music generation capabilities of Suno.ai into their own applications. The API provides a simple and convenient way to generate music, lyrics, and other audio content using Suno.ai's powerful AI models. With Suno AI API, developers can easily add music generation functionality to their apps, websites, and other projects.

openai
An open-source client package that allows developers to easily integrate the power of OpenAI's state-of-the-art AI models into their Dart/Flutter applications. The library provides simple and intuitive methods for making requests to OpenAI's various APIs, including the GPT-3 language model, DALL-E image generation, and more. It is designed to be lightweight and easy to use, enabling developers to focus on building their applications without worrying about the complexities of dealing with HTTP requests. Note that this is an unofficial library as OpenAI does not have an official Dart library.
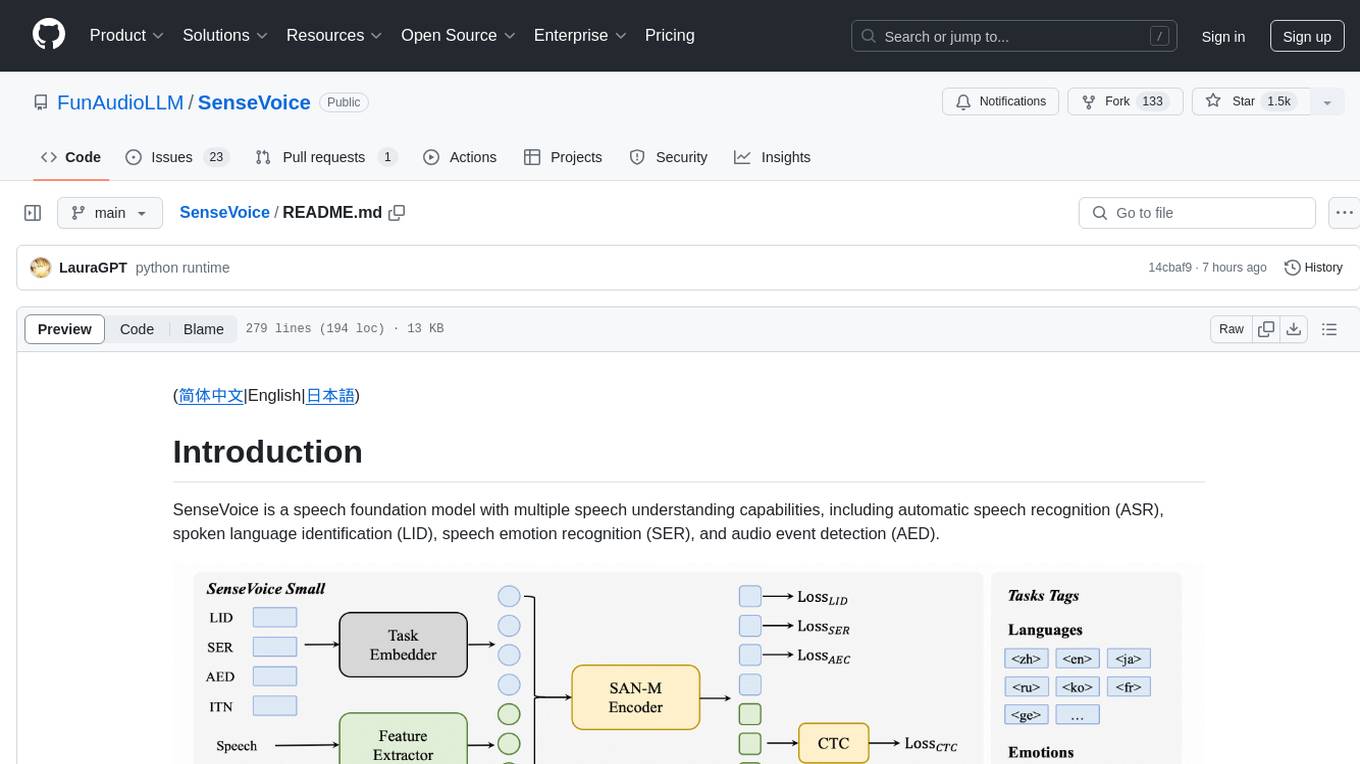
SenseVoice
SenseVoice is a speech foundation model focusing on high-accuracy multilingual speech recognition, speech emotion recognition, and audio event detection. Trained with over 400,000 hours of data, it supports more than 50 languages and excels in emotion recognition and sound event detection. The model offers efficient inference with low latency and convenient finetuning scripts. It can be deployed for service with support for multiple client-side languages. SenseVoice-Small model is open-sourced and provides capabilities for Mandarin, Cantonese, English, Japanese, and Korean. The tool also includes features for natural speech generation and fundamental speech recognition tasks.
amadeus-python
Amadeus Python SDK provides a rich set of APIs for the travel industry. It allows users to make API calls for various travel-related tasks such as flight offers search, hotel bookings, trip purpose prediction, flight delay prediction, airport on-time performance, travel recommendations, and more. The SDK conveniently maps API paths to similar paths, making it easy to interact with the Amadeus APIs. Users can initialize the client with their API key and secret, make API calls, handle responses, and enable logging for debugging purposes. The SDK documentation includes detailed information about each SDK method, arguments, and return types.
For similar tasks
aimeos-core
Aimeos is an Open Source e-commerce framework for online shops consisting of the e-commerce library, the administration interface and different front-ends. It offers a modular stack that provides flexibility and speed. Unlike other shop systems, Aimeos allows users to choose from several user front-ends and customize them according to their needs or create their own. It is suitable for medium to large businesses requiring seamless integration into existing systems like content management, customer relationship management, or enterprise resource planning systems. Aimeos also serves as a base for portals or marketplaces.
qrev
QRev is an open-source alternative to Salesforce, offering AI agents to scale sales organizations infinitely. It aims to provide digital workers for various sales roles or a superagent named Qai. The tech stack includes TypeScript for frontend, NodeJS for backend, MongoDB for app server database, ChromaDB for vector database, SQLite for AI server SQL relational database, and Langchain for LLM tooling. The tool allows users to run client app, app server, and AI server components. It requires Node.js and MongoDB to be installed, and provides detailed setup instructions in the README file.

sktime
sktime is a Python library for time series analysis that provides a unified interface for various time series learning tasks such as classification, regression, clustering, annotation, and forecasting. It offers time series algorithms and tools compatible with scikit-learn for building, tuning, and validating time series models. sktime aims to enhance the interoperability and usability of the time series analysis ecosystem by empowering users to apply algorithms across different tasks and providing interfaces to related libraries like scikit-learn, statsmodels, tsfresh, PyOD, and fbprophet.
pandas-ai
PandaAI is a Python platform that enables users to interact with their data in natural language, catering to both non-technical and technical users. It simplifies data querying and analysis, offering conversational data analytics capabilities with minimal code. Users can ask questions, visualize charts, and compare dataframes effortlessly. The tool aims to streamline data exploration and decision-making processes by providing a user-friendly interface for data manipulation and analysis.
cia
CIA is a powerful open-source tool designed for data analysis and visualization. It provides a user-friendly interface for processing large datasets and generating insightful reports. With CIA, users can easily explore data, perform statistical analysis, and create interactive visualizations to communicate findings effectively. Whether you are a data scientist, analyst, or researcher, CIA offers a comprehensive set of features to streamline your data analysis workflow and uncover valuable insights.
aimeos-headless
Aimeos headless distribution is an ultra-fast, cloud-native, and API-first headless ecommerce solution for Laravel. It offers a full-featured e-commerce package with features like JSON REST API, GraphQL API, multi-vendor support, subscriptions, block/tier pricing, admin backend, and more. The distribution is highly customizable, extensible, and suitable for multi-tenant e-commerce SaaS solutions. It supports multiple languages, AI-based text translation, and provides secure and high-quality source code. Aimeos is designed for AWS, Google, Azure, and Kubernetes based clouds, and can handle a wide range of products efficiently.

datasets
Datasets is a repository that provides a collection of various datasets for machine learning and data analysis projects. It includes datasets in different formats such as CSV, JSON, and Excel, covering a wide range of topics including finance, healthcare, marketing, and more. The repository aims to help data scientists, researchers, and students access high-quality datasets for training models, conducting experiments, and exploring data analysis techniques.

dataline
DataLine is an AI-driven data analysis and visualization tool designed for technical and non-technical users to explore data quickly. It offers privacy-focused data storage on the user's device, supports various data sources, generates charts, executes queries, and facilitates report building. The tool aims to speed up data analysis tasks for businesses and individuals by providing a user-friendly interface and natural language querying capabilities.
For similar jobs

Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.

skyvern
Skyvern automates browser-based workflows using LLMs and computer vision. It provides a simple API endpoint to fully automate manual workflows, replacing brittle or unreliable automation solutions. Traditional approaches to browser automations required writing custom scripts for websites, often relying on DOM parsing and XPath-based interactions which would break whenever the website layouts changed. Instead of only relying on code-defined XPath interactions, Skyvern adds computer vision and LLMs to the mix to parse items in the viewport in real-time, create a plan for interaction and interact with them. This approach gives us a few advantages: 1. Skyvern can operate on websites it’s never seen before, as it’s able to map visual elements to actions necessary to complete a workflow, without any customized code 2. Skyvern is resistant to website layout changes, as there are no pre-determined XPaths or other selectors our system is looking for while trying to navigate 3. Skyvern leverages LLMs to reason through interactions to ensure we can cover complex situations. Examples include: 1. If you wanted to get an auto insurance quote from Geico, the answer to a common question “Were you eligible to drive at 18?” could be inferred from the driver receiving their license at age 16 2. If you were doing competitor analysis, it’s understanding that an Arnold Palmer 22 oz can at 7/11 is almost definitely the same product as a 23 oz can at Gopuff (even though the sizes are slightly different, which could be a rounding error!) Want to see examples of Skyvern in action? Jump to #real-world-examples-of- skyvern

pandas-ai
PandasAI is a Python library that makes it easy to ask questions to your data in natural language. It helps you to explore, clean, and analyze your data using generative AI.

vanna
Vanna is an open-source Python framework for SQL generation and related functionality. It uses Retrieval-Augmented Generation (RAG) to train a model on your data, which can then be used to ask questions and get back SQL queries. Vanna is designed to be portable across different LLMs and vector databases, and it supports any SQL database. It is also secure and private, as your database contents are never sent to the LLM or the vector database.

databend
Databend is an open-source cloud data warehouse that serves as a cost-effective alternative to Snowflake. With its focus on fast query execution and data ingestion, it's designed for complex analysis of the world's largest datasets.

Avalonia-Assistant
Avalonia-Assistant is an open-source desktop intelligent assistant that aims to provide a user-friendly interactive experience based on the Avalonia UI framework and the integration of Semantic Kernel with OpenAI or other large LLM models. By utilizing Avalonia-Assistant, you can perform various desktop operations through text or voice commands, enhancing your productivity and daily office experience.

marvin
Marvin is a lightweight AI toolkit for building natural language interfaces that are reliable, scalable, and easy to trust. Each of Marvin's tools is simple and self-documenting, using AI to solve common but complex challenges like entity extraction, classification, and generating synthetic data. Each tool is independent and incrementally adoptable, so you can use them on their own or in combination with any other library. Marvin is also multi-modal, supporting both image and audio generation as well using images as inputs for extraction and classification. Marvin is for developers who care more about _using_ AI than _building_ AI, and we are focused on creating an exceptional developer experience. Marvin users should feel empowered to bring tightly-scoped "AI magic" into any traditional software project with just a few extra lines of code. Marvin aims to merge the best practices for building dependable, observable software with the best practices for building with generative AI into a single, easy-to-use library. It's a serious tool, but we hope you have fun with it. Marvin is open-source, free to use, and made with 💙 by the team at Prefect.

activepieces
Activepieces is an open source replacement for Zapier, designed to be extensible through a type-safe pieces framework written in Typescript. It features a user-friendly Workflow Builder with support for Branches, Loops, and Drag and Drop. Activepieces integrates with Google Sheets, OpenAI, Discord, and RSS, along with 80+ other integrations. The list of supported integrations continues to grow rapidly, thanks to valuable contributions from the community. Activepieces is an open ecosystem; all piece source code is available in the repository, and they are versioned and published directly to npmjs.com upon contributions. If you cannot find a specific piece on the pieces roadmap, please submit a request by visiting the following link: Request Piece Alternatively, if you are a developer, you can quickly build your own piece using our TypeScript framework. For guidance, please refer to the following guide: Contributor's Guide