
elia
A snappy, keyboard-centric terminal user interface for interacting with large language models. Chat with ChatGPT, Claude, Llama 3, Phi 3, Mistral, Gemma and more.
Stars: 1751
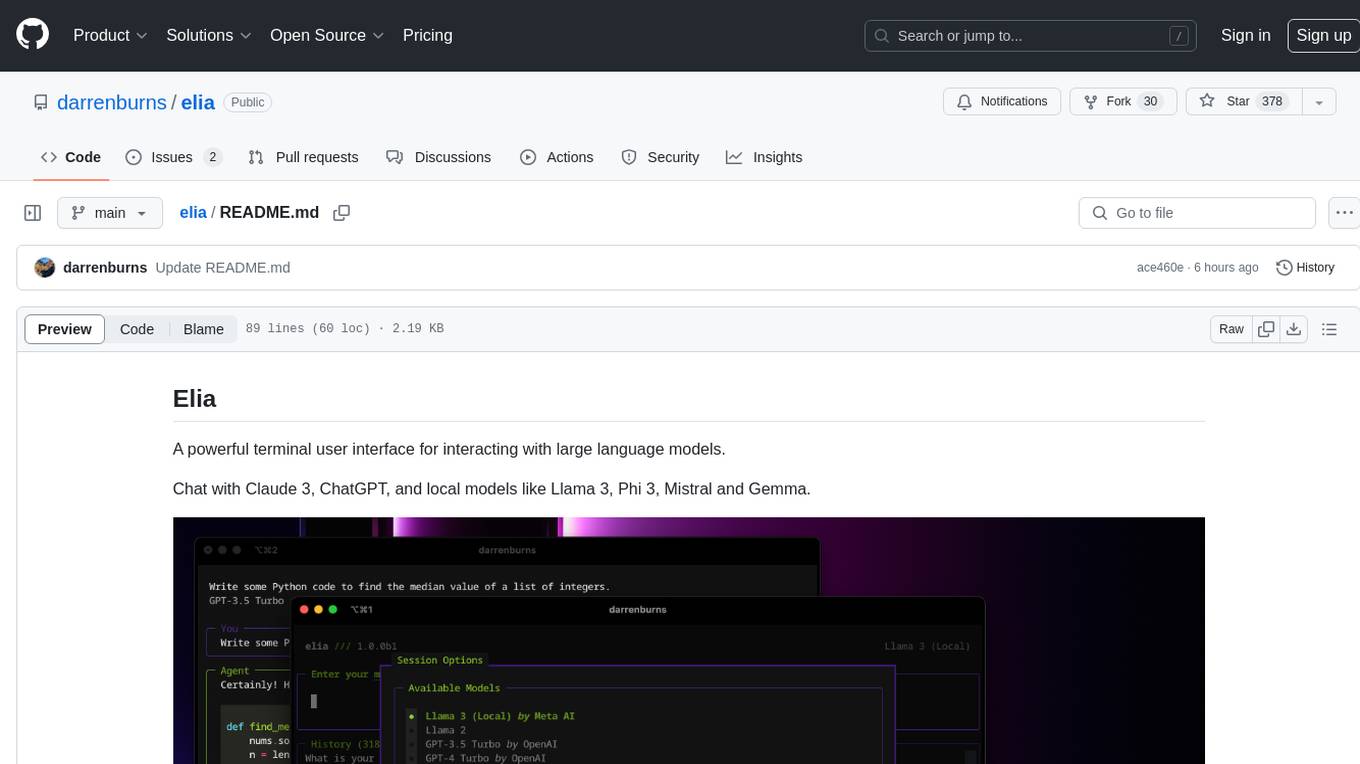
Elia is a powerful terminal user interface designed for interacting with large language models. It allows users to chat with models like Claude 3, ChatGPT, Llama 3, Phi 3, Mistral, and Gemma. Conversations are stored locally in a SQLite database, ensuring privacy. Users can run local models through 'ollama' without data leaving their machine. Elia offers easy installation with pipx and supports various environment variables for different models. It provides a quick start to launch chats and manage local models. Configuration options are available to customize default models, system prompts, and add new models. Users can import conversations from ChatGPT and wipe the database when needed. Elia aims to enhance user experience in interacting with language models through a user-friendly interface.
README:
A snappy, keyboard-centric terminal user interface for interacting with large language models.
Chat with Claude 3, ChatGPT, and local models like Llama 3, Phi 3, Mistral and Gemma.
elia is an application for interacting with LLMs which runs entirely in your terminal, and is designed to be keyboard-focused, efficient, and fun to use!
It stores your conversations in a local SQLite database, and allows you to interact with a variety of models.
Speak with proprietary models such as ChatGPT and Claude, or with local models running through ollama or LocalAI.
Install Elia with pipx:
pipx install elia-chatDepending on the model you wish to use, you may need to set one or more environment variables (e.g. OPENAI_API_KEY, ANTHROPIC_API_KEY, GEMINI_API_KEY etc).
Launch Elia from the command line:
eliaLaunch a new chat inline (under your prompt) with -i/--inline:
elia -i "What is the Zen of Python?"Launch a new chat in full-screen mode:
elia "Tell me a cool fact about lizards!"Specify a model via the command line using -m/--model:
elia -m gpt-4oOptions can be combined - here's how you launch a chat with Gemini 1.5 Flash in inline mode (requires GEMINI_API_KEY environment variable).
elia -i -m gemini/gemini-1.5-flash-latest "How do I call Rust code from Python?"- Install
ollama. - Pull the model you require, e.g.
ollama pull llama3. - Run the local ollama server:
ollama serve. - Add the model to the config file (see below).
The location of the configuration file is noted at the bottom of
the options window (ctrl+o).
The example file below shows the available options, as well as examples of how to add new models.
# the ID or name of the model that is selected by default on launch
default_model = "gpt-4o"
# the system prompt on launch
system_prompt = "You are a helpful assistant who talks like a pirate."
# choose from "nebula", "cobalt", "twilight", "hacker", "alpine", "galaxy", "nautilus", "monokai", "textual"
theme = "galaxy"
# change the syntax highlighting theme of code in messages
# choose from https://pygments.org/styles/
# defaults to "monokai"
message_code_theme = "dracula"
# example of adding local llama3 support
# only the `name` field is required here.
[[models]]
name = "ollama/llama3"
# example of a model running on a local server, e.g. LocalAI
[[models]]
name = "openai/some-model"
api_base = "http://localhost:8080/v1"
api_key = "api-key-if-required"
# example of add a groq model, showing some other fields
[[models]]
name = "groq/llama2-70b-4096"
display_name = "Llama 2 70B" # appears in UI
provider = "Groq" # appears in UI
temperature = 1.0 # high temp = high variation in output
max_retries = 0 # number of retries on failed request
# example of multiple instances of one model, e.g. you might
# have a 'work' OpenAI org and a 'personal' org.
[[models]]
id = "work-gpt-3.5-turbo"
name = "gpt-3.5-turbo"
display_name = "GPT 3.5 Turbo (Work)"
[[models]]
id = "personal-gpt-3.5-turbo"
name = "gpt-3.5-turbo"
display_name = "GPT 3.5 Turbo (Personal)"Add a custom theme YAML file to the themes directory.
You can find the themes directory location by pressing ctrl+o on the home screen and looking for the Themes directory line.
Here's an example of a theme YAML file:
name: example # use this name in your config file
primary: '#4e78c4'
secondary: '#f39c12'
accent: '#e74c3c'
background: '#0e1726'
surface: '#17202a'
error: '#e74c3c' # error messages
success: '#2ecc71' # success messages
warning: '#f1c40f' # warning messagesRight now, keybinds cannot be changed. Terminals are also rather limited in what keybinds they support. For example, pressing Cmd+Enter to send a message is not possible (although we may support a protocol to allow this in some terminals in the future).
For now, I recommend you map whatever key combo you want at the terminal emulator level to send \n.
Here's an example using iTerm:
With this mapping in place, pressing Cmd+Enter will send a message to the LLM, and pressing Enter alone will create a new line.
Export your conversations to a JSON file using the ChatGPT UI, then import them using the import command.
elia import 'path/to/conversations.json'elia resetpipx uninstall elia-chatFor Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for elia
Similar Open Source Tools
elia
Elia is a powerful terminal user interface designed for interacting with large language models. It allows users to chat with models like Claude 3, ChatGPT, Llama 3, Phi 3, Mistral, and Gemma. Conversations are stored locally in a SQLite database, ensuring privacy. Users can run local models through 'ollama' without data leaving their machine. Elia offers easy installation with pipx and supports various environment variables for different models. It provides a quick start to launch chats and manage local models. Configuration options are available to customize default models, system prompts, and add new models. Users can import conversations from ChatGPT and wipe the database when needed. Elia aims to enhance user experience in interacting with language models through a user-friendly interface.

npcsh
`npcsh` is a python-based command-line tool designed to integrate Large Language Models (LLMs) and Agents into one's daily workflow by making them available and easily configurable through the command line shell. It leverages the power of LLMs to understand natural language commands and questions, execute tasks, answer queries, and provide relevant information from local files and the web. Users can also build their own tools and call them like macros from the shell. `npcsh` allows users to take advantage of agents (i.e. NPCs) through a managed system, tailoring NPCs to specific tasks and workflows. The tool is extensible with Python, providing useful functions for interacting with LLMs, including explicit coverage for popular providers like ollama, anthropic, openai, gemini, deepseek, and openai-like providers. Users can set up a flask server to expose their NPC team for use as a backend service, run SQL models defined in their project, execute assembly lines, and verify the integrity of their NPC team's interrelations. Users can execute bash commands directly, use favorite command-line tools like VIM, Emacs, ipython, sqlite3, git, pipe the output of these commands to LLMs, or pass LLM results to bash commands.
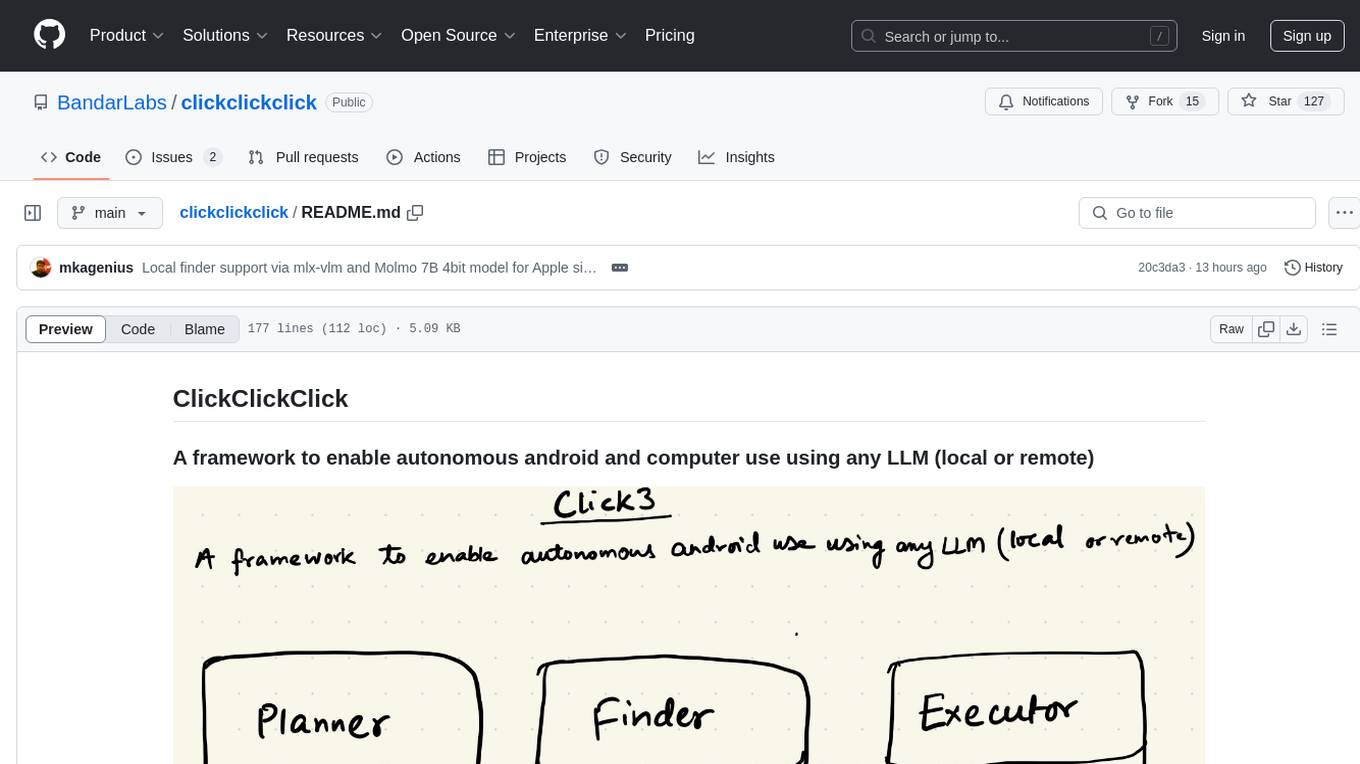
clickclickclick
ClickClickClick is a framework designed to enable autonomous Android and computer use using various LLM models, both locally and remotely. It supports tasks such as drafting emails, opening browsers, and starting games, with current support for local models via Ollama, Gemini, and GPT 4o. The tool is highly experimental and evolving, with the best results achieved using specific model combinations. Users need prerequisites like `adb` installation and USB debugging enabled on Android phones. The tool can be installed via cloning the repository, setting up a virtual environment, and installing dependencies. It can be used as a CLI tool or script, allowing users to configure planner and finder models for different tasks. Additionally, it can be used as an API to execute tasks based on provided prompts, platform, and models.

simpleAI
SimpleAI is a self-hosted alternative to the not-so-open AI API, focused on replicating main endpoints for LLM such as text completion, chat, edits, and embeddings. It allows quick experimentation with different models, creating benchmarks, and handling specific use cases without relying on external services. Users can integrate and declare models through gRPC, query endpoints using Swagger UI or API, and resolve common issues like CORS with FastAPI middleware. The project is open for contributions and welcomes PRs, issues, documentation, and more.
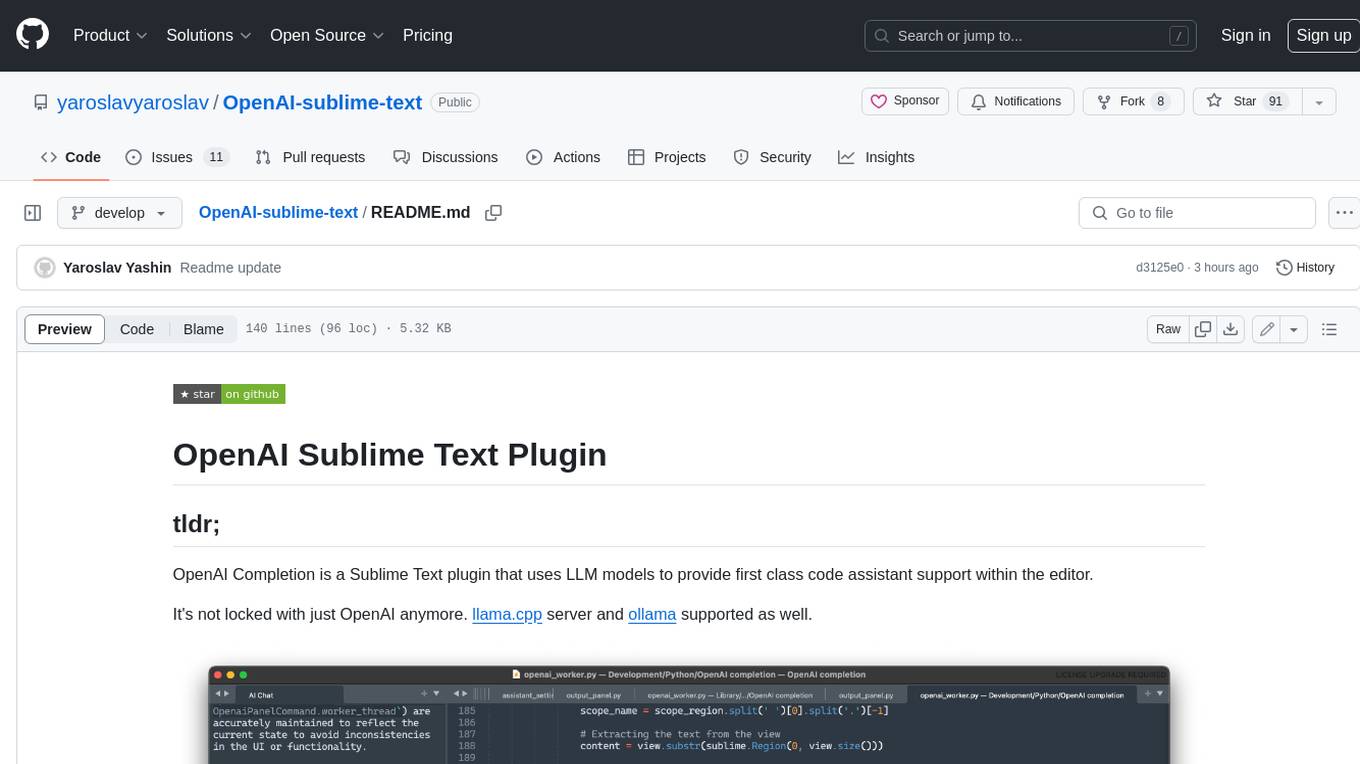
OpenAI-sublime-text
The OpenAI Completion plugin for Sublime Text provides first-class code assistant support within the editor. It utilizes LLM models to manipulate code, engage in chat mode, and perform various tasks. The plugin supports OpenAI, llama.cpp, and ollama models, allowing users to customize their AI assistant experience. It offers separated chat histories and assistant settings for different projects, enabling context-specific interactions. Additionally, the plugin supports Markdown syntax with code language syntax highlighting, server-side streaming for faster response times, and proxy support for secure connections. Users can configure the plugin's settings to set their OpenAI API key, adjust assistant modes, and manage chat history. Overall, the OpenAI Completion plugin enhances the Sublime Text editor with powerful AI capabilities, streamlining coding workflows and fostering collaboration with AI assistants.
llm-ollama
LLM-ollama is a plugin that provides access to models running on an Ollama server. It allows users to query the Ollama server for a list of models, register them with LLM, and use them for prompting, chatting, and embedding. The plugin supports image attachments, embeddings, JSON schemas, async models, model aliases, and model options. Users can interact with Ollama models through the plugin in a seamless and efficient manner.
bot-on-anything
The 'bot-on-anything' repository allows developers to integrate various AI models into messaging applications, enabling the creation of intelligent chatbots. By configuring the connections between models and applications, developers can easily switch between multiple channels within a project. The architecture is highly scalable, allowing the reuse of algorithmic capabilities for each new application and model integration. Supported models include ChatGPT, GPT-3.0, New Bing, and Google Bard, while supported applications range from terminals and web platforms to messaging apps like WeChat, Telegram, QQ, and more. The repository provides detailed instructions for setting up the environment, configuring the models and channels, and running the chatbot for various tasks across different messaging platforms.

ash_ai
Ash AI is a tool that provides a Model Context Protocol (MCP) server for exposing tool definitions to an MCP client. It allows for the installation of dev and production MCP servers, and supports features like OAuth2 flow with AshAuthentication, tool data access, tool execution callbacks, prompt-backed actions, and vectorization strategies. Users can also generate a chat feature for their Ash & Phoenix application using `ash_oban` and `ash_postgres`, and specify LLM API keys for OpenAI. The tool is designed to help developers experiment with tools and actions, monitor tool execution, and expose actions as tool calls.

vector-inference
This repository provides an easy-to-use solution for running inference servers on Slurm-managed computing clusters using vLLM. All scripts in this repository run natively on the Vector Institute cluster environment. Users can deploy models as Slurm jobs, check server status and performance metrics, and shut down models. The repository also supports launching custom models with specific configurations. Additionally, users can send inference requests and set up an SSH tunnel to run inference from a local device.

langserve
LangServe helps developers deploy `LangChain` runnables and chains as a REST API. This library is integrated with FastAPI and uses pydantic for data validation. In addition, it provides a client that can be used to call into runnables deployed on a server. A JavaScript client is available in LangChain.js.

vinagent
Vinagent is a lightweight and flexible library designed for building smart agent assistants across various industries. It provides a simple yet powerful foundation for creating AI-powered customer service bots, data analysis assistants, or domain-specific automation agents. With its modular tool system, users can easily extend their agent's capabilities by integrating a wide range of tools that are self-contained, well-documented, and can be registered dynamically. Vinagent allows users to scale and adapt their agents to new tasks or environments effortlessly.

motorhead
Motorhead is a memory and information retrieval server for LLMs. It provides three simple APIs to assist with memory handling in chat applications using LLMs. The first API, GET /sessions/:id/memory, returns messages up to a maximum window size. The second API, POST /sessions/:id/memory, allows you to send an array of messages to Motorhead for storage. The third API, DELETE /sessions/:id/memory, deletes the session's message list. Motorhead also features incremental summarization, where it processes half of the maximum window size of messages and summarizes them when the maximum is reached. Additionally, it supports searching by text query using vector search. Motorhead is configurable through environment variables, including the maximum window size, whether to enable long-term memory, the model used for incremental summarization, the server port, your OpenAI API key, and the Redis URL.

phidata
Phidata is a framework for building AI Assistants with memory, knowledge, and tools. It enables LLMs to have long-term conversations by storing chat history in a database, provides them with business context by storing information in a vector database, and enables them to take actions like pulling data from an API, sending emails, or querying a database. Memory and knowledge make LLMs smarter, while tools make them autonomous.

hordelib
horde-engine is a wrapper around ComfyUI designed to run inference pipelines visually designed in the ComfyUI GUI. It enables users to design inference pipelines in ComfyUI and then call them programmatically, maintaining compatibility with the existing horde implementation. The library provides features for processing Horde payloads, initializing the library, downloading and validating models, and generating images based on input data. It also includes custom nodes for preprocessing and tasks such as face restoration and QR code generation. The project depends on various open source projects and bundles some dependencies within the library itself. Users can design ComfyUI pipelines, convert them to the backend format, and run them using the run_image_pipeline() method in hordelib.comfy.Comfy(). The project is actively developed and tested using git, tox, and a specific model directory structure.

termax
Termax is an LLM agent in your terminal that converts natural language to commands. It is featured by: - Personalized Experience: Optimize the command generation with RAG. - Various LLMs Support: OpenAI GPT, Anthropic Claude, Google Gemini, Mistral AI, and more. - Shell Extensions: Plugin with popular shells like `zsh`, `bash` and `fish`. - Cross Platform: Able to run on Windows, macOS, and Linux.

ScandEval
ScandEval is a framework for evaluating pretrained language models on mono- or multilingual language tasks. It provides a unified interface for benchmarking models on a variety of tasks, including sentiment analysis, question answering, and machine translation. ScandEval is designed to be easy to use and extensible, making it a valuable tool for researchers and practitioners alike.
For similar tasks
elia
Elia is a powerful terminal user interface designed for interacting with large language models. It allows users to chat with models like Claude 3, ChatGPT, Llama 3, Phi 3, Mistral, and Gemma. Conversations are stored locally in a SQLite database, ensuring privacy. Users can run local models through 'ollama' without data leaving their machine. Elia offers easy installation with pipx and supports various environment variables for different models. It provides a quick start to launch chats and manage local models. Configuration options are available to customize default models, system prompts, and add new models. Users can import conversations from ChatGPT and wipe the database when needed. Elia aims to enhance user experience in interacting with language models through a user-friendly interface.

mistral-inference
Mistral Inference repository contains minimal code to run 7B, 8x7B, and 8x22B models. It provides model download links, installation instructions, and usage guidelines for running models via CLI or Python. The repository also includes information on guardrailing, model platforms, deployment, and references. Users can interact with models through commands like mistral-demo, mistral-chat, and mistral-common. Mistral AI models support function calling and chat interactions for tasks like testing models, chatting with models, and using Codestral as a coding assistant. The repository offers detailed documentation and links to blogs for further information.
LLMFlex
LLMFlex is a python package designed for developing AI applications with local Large Language Models (LLMs). It provides classes to load LLM models, embedding models, and vector databases to create AI-powered solutions with prompt engineering and RAG techniques. The package supports multiple LLMs with different generation configurations, embedding toolkits, vector databases, chat memories, prompt templates, custom tools, and a chatbot frontend interface. Users can easily create LLMs, load embeddings toolkit, use tools, chat with models in a Streamlit web app, and serve an OpenAI API with a GGUF model. LLMFlex aims to offer a simple interface for developers to work with LLMs and build private AI solutions using local resources.
minimal-chat
MinimalChat is a minimal and lightweight open-source chat application with full mobile PWA support that allows users to interact with various language models, including GPT-4 Omni, Claude Opus, and various Local/Custom Model Endpoints. It focuses on simplicity in setup and usage while being fully featured and highly responsive. The application supports features like fully voiced conversational interactions, multiple language models, markdown support, code syntax highlighting, DALL-E 3 integration, conversation importing/exporting, and responsive layout for mobile use.
chat-with-mlx
Chat with MLX is an all-in-one Chat Playground using Apple MLX on Apple Silicon Macs. It provides privacy-enhanced AI for secure conversations with various models, easy integration of HuggingFace and MLX Compatible Open-Source Models, and comes with default models like Llama-3, Phi-3, Yi, Qwen, Mistral, Codestral, Mixtral, StableLM. The tool is designed for developers and researchers working with machine learning models on Apple Silicon.

transformerlab-app
Transformer Lab is an app that allows users to experiment with Large Language Models by providing features such as one-click download of popular models, finetuning across different hardware, RLHF and Preference Optimization, working with LLMs across different operating systems, chatting with models, using different inference engines, evaluating models, building datasets for training, calculating embeddings, providing a full REST API, running in the cloud, converting models across platforms, supporting plugins, embedded Monaco code editor, prompt editing, inference logs, all through a simple cross-platform GUI.
ell
ell is a command-line interface for Language Model Models (LLMs) written in Bash. It allows users to interact with LLMs from the terminal, supports piping, context bringing, and chatting with LLMs. Users can also call functions and use templates. The tool requires bash, jq for JSON parsing, curl for HTTPS requests, and perl for PCRE. Configuration involves setting variables for different LLM models and APIs. Usage examples include asking questions, specifying models, recording input/output, running in interactive mode, and using templates. The tool is lightweight, easy to install, and pipe-friendly, making it suitable for interacting with LLMs in a terminal environment.
Ollama-SwiftUI
Ollama-SwiftUI is a user-friendly interface for Ollama.ai created in Swift. It allows seamless chatting with local Large Language Models on Mac. Users can change models mid-conversation, restart conversations, send system prompts, and use multimodal models with image + text. The app supports managing models, including downloading, deleting, and duplicating them. It offers light and dark mode, multiple conversation tabs, and a localized interface in English and Arabic.
For similar jobs

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

daily-poetry-image
Daily Chinese ancient poetry and AI-generated images powered by Bing DALL-E-3. GitHub Action triggers the process automatically. Poetry is provided by Today's Poem API. The website is built with Astro.

exif-photo-blog
EXIF Photo Blog is a full-stack photo blog application built with Next.js, Vercel, and Postgres. It features built-in authentication, photo upload with EXIF extraction, photo organization by tag, infinite scroll, light/dark mode, automatic OG image generation, a CMD-K menu with photo search, experimental support for AI-generated descriptions, and support for Fujifilm simulations. The application is easy to deploy to Vercel with just a few clicks and can be customized with a variety of environment variables.

SillyTavern
SillyTavern is a user interface you can install on your computer (and Android phones) that allows you to interact with text generation AIs and chat/roleplay with characters you or the community create. SillyTavern is a fork of TavernAI 1.2.8 which is under more active development and has added many major features. At this point, they can be thought of as completely independent programs.

Twitter-Insight-LLM
This project enables you to fetch liked tweets from Twitter (using Selenium), save it to JSON and Excel files, and perform initial data analysis and image captions. This is part of the initial steps for a larger personal project involving Large Language Models (LLMs).

AISuperDomain
Aila Desktop Application is a powerful tool that integrates multiple leading AI models into a single desktop application. It allows users to interact with various AI models simultaneously, providing diverse responses and insights to their inquiries. With its user-friendly interface and customizable features, Aila empowers users to engage with AI seamlessly and efficiently. Whether you're a researcher, student, or professional, Aila can enhance your AI interactions and streamline your workflow.

ChatGPT-On-CS
This project is an intelligent dialogue customer service tool based on a large model, which supports access to platforms such as WeChat, Qianniu, Bilibili, Douyin Enterprise, Douyin, Doudian, Weibo chat, Xiaohongshu professional account operation, Xiaohongshu, Zhihu, etc. You can choose GPT3.5/GPT4.0/ Lazy Treasure Box (more platforms will be supported in the future), which can process text, voice and pictures, and access external resources such as operating systems and the Internet through plug-ins, and support enterprise AI applications customized based on their own knowledge base.

obs-localvocal
LocalVocal is a live-streaming AI assistant plugin for OBS that allows you to transcribe audio speech into text and perform various language processing functions on the text using AI / LLMs (Large Language Models). It's privacy-first, with all data staying on your machine, and requires no GPU, cloud costs, network, or downtime.