
Twitter-Insight-LLM
Twitter data scraping and more.
Stars: 401

This project enables you to fetch liked tweets from Twitter (using Selenium), save it to JSON and Excel files, and perform initial data analysis and image captions. This is part of the initial steps for a larger personal project involving Large Language Models (LLMs).
README:
This project enables you to fetch liked tweets from Twitter (using Selenium), save it to JSON and Excel files, and perform initial data analysis and image captions.
This is part of the initial steps for a larger personal project involving Large Language Models (LLMs). Stay tuned for more updates!

Before running the code, ensure you have the following:
- Required Python libraries (listed in
requirements.txt) - Get your twitter auth token (Not API key)
- Quick text instruction:
-
- Go to your already logged-in twitter
- F12 (open dev tools) -> Application -> Cookies -> Twitter.com -> auth_key
- or follow the video demo in FAQ section.
- OpenAI API key (optional, only needed if you want to try the image captions feature)
- Clone the repository or download the project files.
- Install the required Python libraries by running the following command:
pip install -r requirements.txt
- Open the
config.pyfile and replace the placeholders with your actual API keys:
- Set
TWITTER_AUTH_TOKENto your Twitter API authentication token. - Set
OPENAI_API_KEYto your OpenAI API key.
To fetch data from Twitter and save it to JSON and Excel files, follow these steps:
- Open the
twitter_data_ingestion.pyfile. - Modify the
fetch_tweetsfunction call at the bottom of the script with your desired parameters:
- Set the URL of the Twitter page you want to fetch data from (e.g.,
https://twitter.com/ilyasut/likes). - Specify the start and end dates for the data range (in YYYY-MM-DD format).
-
Run the script by executing the following command (recommend run this in IDE directly):
python twitter_data_ingestion.py -
The script will fetch the data from Twitter, save it to a JSON file, and then export it to an Excel file.
To perform initial data analysis on the fetched data, follow these steps:
- Open the
twitter_data_initial_exploration.ipynbnotebook in Jupyter Notebook or JupyterLab. - Run the notebook cells sequentially to load the data from the JSON file and perform various data analysis tasks.
Some sample results:
- Visualizing likes by media type over time

- Creating a calendar heatmap of liked tweets per day

- The notebook also demonstrates how to use the OpenAI API to generate image captions for tweet images (with tweet metadata).

The project includes sample output files for reference:
-
sample_output_json.json: A sample JSON file containing the fetched Twitter data. -
sample_exported_excel.xlsx: A sample Excel file exported from the JSON data.
Feel free to explore and modify the code to suit your specific data analysis requirements.
-
Will I get banned? Could this affect my account?
- Selenium is one of the safest scraping methods out there, but it's still best to be cautious when using it for personal projects.
- I've been using it for quite a while without any issues.
- (Though, if you've got a spare / alt account, I'd recommend using that one's auth token instead)
-
How do I find the auth token?
- Check out this for a step-by-step guide!
Contributions to this project are welcome. If you find any issues or have suggestions for improvements, please open an issue or submit a pull request.
- Initial structure and parts of the Selenium code inspired by Twitter-Scrapper.
- The image captioning feature is powered by the OpenAI API. You should be able to achieve similar results using Gemini 1.0.
For any questions or issues, please open an issue in the repository.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for Twitter-Insight-LLM
Similar Open Source Tools
Twitter-Insight-LLM
This project enables you to fetch liked tweets from Twitter (using Selenium), save it to JSON and Excel files, and perform initial data analysis and image captions. This is part of the initial steps for a larger personal project involving Large Language Models (LLMs).
vault-ai
OP Vault is a tool that leverages the OP Stack (OpenAI + Pinecone Vector Database) to allow users to upload custom knowledgebase files and ask questions about their contents. It provides a user-friendly Golang server and React frontend for querying human-readable content like books and documents, making it valuable for knowledge extraction and question-answering. Users can upload entire libraries, receive specific answers with file and section references, and explore the power of the OP Stack in a practical interface.
characterfile
The Characterfile project aims to create a simple format for generating and transmitting character files, compatible with Eliza and other LLM agents. Users can convert their Twitter archive into a character file using the provided scripts. The project also includes examples, JSON schema, and TypeScript types for the character file. Scripts like tweets2character, folder2knowledge, and knowledge2character facilitate the conversion of tweets, documents, and knowledge files into character files for use with AI agents.
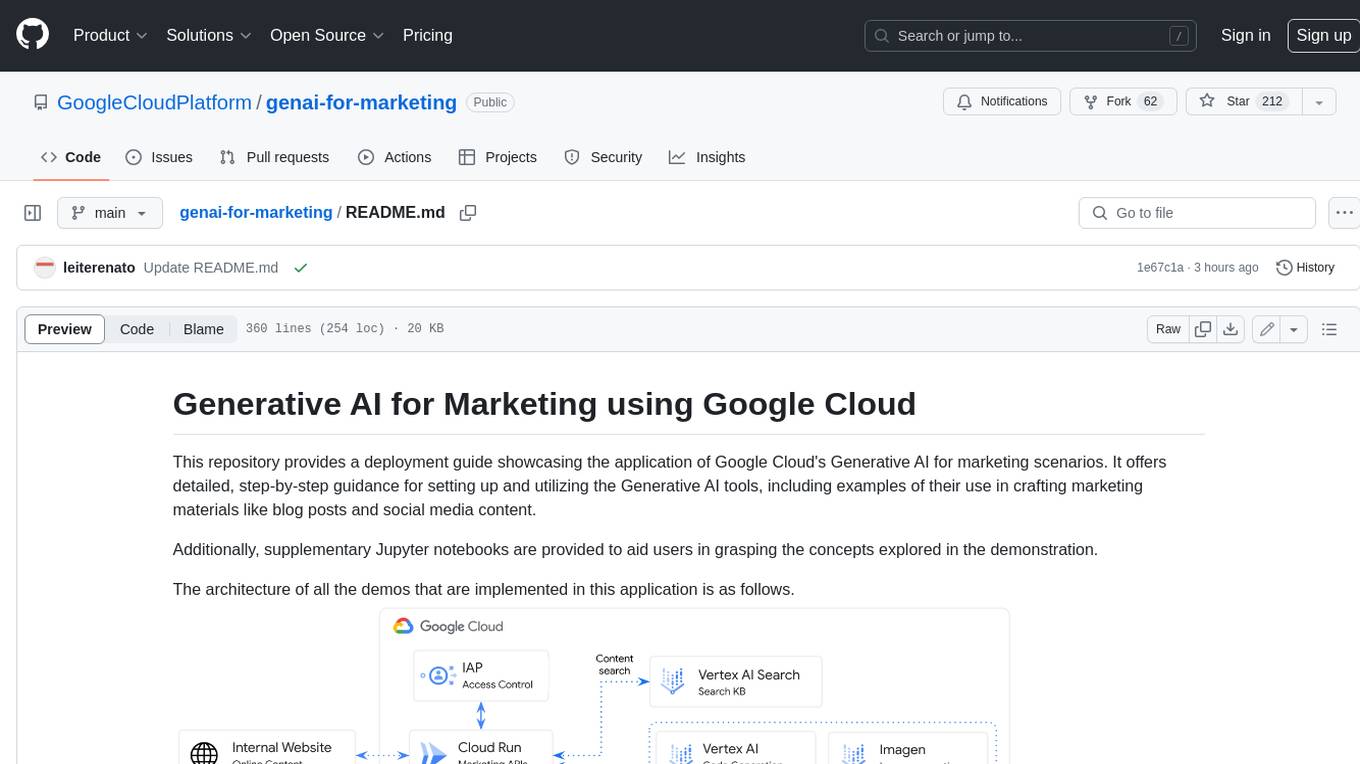
genai-for-marketing
This repository provides a deployment guide for utilizing Google Cloud's Generative AI tools in marketing scenarios. It includes step-by-step instructions, examples of crafting marketing materials, and supplementary Jupyter notebooks. The demos cover marketing insights, audience analysis, trendspotting, content search, content generation, and workspace integration. Users can access and visualize marketing data, analyze trends, improve search experience, and generate compelling content. The repository structure includes backend APIs, frontend code, sample notebooks, templates, and installation scripts.
CyberScraper-2077
CyberScraper 2077 is an advanced web scraping tool powered by AI, designed to extract data from websites with precision and style. It offers a user-friendly interface, supports multiple data export formats, operates in stealth mode to avoid detection, and promises lightning-fast scraping. The tool respects ethical scraping practices, including robots.txt and site policies. With upcoming features like proxy support and page navigation, CyberScraper 2077 is a futuristic solution for data extraction in the digital realm.
open-source-slack-ai
This repository provides a ready-to-run basic Slack AI solution that allows users to summarize threads and channels using OpenAI. Users can generate thread summaries, channel overviews, channel summaries since a specific time, and full channel summaries. The tool is powered by GPT-3.5-Turbo and an ensemble of NLP models. It requires Python 3.8 or higher, an OpenAI API key, Slack App with associated API tokens, Poetry package manager, and ngrok for local development. Users can customize channel and thread summaries, run tests with coverage using pytest, and contribute to the project for future enhancements.
reai-ida
RevEng.AI IDA Pro Plugin is a tool that integrates with the RevEng.AI platform to provide various features such as uploading binaries for analysis, downloading analysis logs, renaming function names, generating AI summaries, synchronizing functions between local analysis and the platform, and configuring plugin settings. Users can upload files for analysis, synchronize function names, rename functions, generate block summaries, and explain function behavior using this plugin. The tool requires IDA Pro v8.0 or later with Python 3.9 and higher. It relies on the 'reait' package for functionality.
Kuebiko
Kuebiko is a Twitch Chat Bot that reads twitch chat and generates text-to-speech responses using Google Cloud API and OpenAI's GPT-3 text completion model. It allows users to set up their own VTuber AI similar to 'Neuro-Sama'. The project is built with Python and requires setting up various API keys and configurations to enable the bot functionality. Users can customize the voice of their VTuber and route audio using VBAudio Cable. Kuebiko provides a unique way to interact with viewers through chat responses and captions in OBS.
reai-ghidra
The RevEng.AI Ghidra Plugin by RevEng.ai allows users to interact with their API within Ghidra for Binary Code Similarity analysis to aid in Reverse Engineering stripped binaries. Users can upload binaries, rename functions above a confidence threshold, and view similar functions for a selected function.
OrionChat
Orion is a web-based chat interface that simplifies interactions with multiple AI model providers. It provides a unified platform for chatting and exploring various large language models (LLMs) such as Ollama, OpenAI (GPT model), Cohere (Command-r models), Google (Gemini models), Anthropic (Claude models), Groq Inc., Cerebras, and SambaNova. Users can easily navigate and assess different AI models through an intuitive, user-friendly interface. Orion offers features like browser-based access, code execution with Google Gemini, text-to-speech (TTS), speech-to-text (STT), seamless integration with multiple AI models, customizable system prompts, language translation tasks, document uploads for analysis, and more. API keys are stored locally, and requests are sent directly to official providers' APIs without external proxies.

sdk
Vikit.ai SDK is a software development kit that enables easy development of video generators using generative AI and other AI models. It serves as a langchain to orchestrate AI models and video editing tools. The SDK allows users to create videos from text prompts with background music and voice-over narration. It also supports generating composite videos from multiple text prompts. The tool requires Python 3.8+, specific dependencies, and tools like FFMPEG and ImageMagick for certain functionalities. Users can contribute to the project by following the contribution guidelines and standards provided.

jaison-core
J.A.I.son is a Python project designed for generating responses using various components and applications. It requires specific plugins like STT, T2T, TTSG, and TTSC to function properly. Users can customize responses, voice, and configurations. The project provides a Discord bot, Twitch events and chat integration, and VTube Studio Animation Hotkeyer. It also offers features for managing conversation history, training AI models, and monitoring conversations.

dataline
DataLine is an AI-driven data analysis and visualization tool designed for technical and non-technical users to explore data quickly. It offers privacy-focused data storage on the user's device, supports various data sources, generates charts, executes queries, and facilitates report building. The tool aims to speed up data analysis tasks for businesses and individuals by providing a user-friendly interface and natural language querying capabilities.
pdftochat
PDFToChat is a tool that allows users to chat with their PDF documents in seconds. It is powered by Together AI and Pinecone, utilizing a tech stack including Next.js, Mixtral, M2 Bert, LangChain.js, MongoDB Atlas, Bytescale, Vercel, Clerk, and Tailwind CSS. Users can deploy the tool to Vercel or any other host by setting up Together.ai, MongoDB Atlas database, Bytescale, Clerk, and Vercel. The tool enables users to interact with PDFs through chat, with future tasks including adding features like trash icon for deleting PDFs, exploring different embedding models, implementing auto scrolling, improving replies, benchmarking accuracy, researching chunking and retrieval best practices, adding demo video, upgrading to Next.js 14, adding analytics, customizing tailwind prose, saving chats in postgres DB, compressing large PDFs, implementing custom uploader, session tracking, error handling, and support for images in PDFs.
webwhiz
WebWhiz is an open-source tool that allows users to train ChatGPT on website data to build AI chatbots for customer queries. It offers easy integration, data-specific responses, regular data updates, no-code builder, chatbot customization, fine-tuning, and offline messaging. Users can create and train chatbots in a few simple steps by entering their website URL, automatically fetching and preparing training data, training ChatGPT, and embedding the chatbot on their website. WebWhiz can crawl websites monthly, collect text data and metadata, and process text data using tokens. Users can train custom data, but bringing custom open AI keys is not yet supported. The tool has no limitations on context size but may limit the number of pages based on the chosen plan. WebWhiz SDK is available on NPM, CDNs, and GitHub, and users can self-host it using Docker or manual setup involving MongoDB, Redis, Node, Python, and environment variables setup. For any issues, users can contact [email protected].
comfyui_LLM_party
COMFYUI LLM PARTY is a node library designed for LLM workflow development in ComfyUI, an extremely minimalist UI interface primarily used for AI drawing and SD model-based workflows. The project aims to provide a complete set of nodes for constructing LLM workflows, enabling users to easily integrate them into existing SD workflows. It features various functionalities such as API integration, local large model integration, RAG support, code interpreters, online queries, conditional statements, looping links for large models, persona mask attachment, and tool invocations for weather lookup, time lookup, knowledge base, code execution, web search, and single-page search. Users can rapidly develop web applications using API + Streamlit and utilize LLM as a tool node. Additionally, the project includes an omnipotent interpreter node that allows the large model to perform any task, with recommendations to use the 'show_text' node for display output.
For similar tasks
Twitter-Insight-LLM
This project enables you to fetch liked tweets from Twitter (using Selenium), save it to JSON and Excel files, and perform initial data analysis and image captions. This is part of the initial steps for a larger personal project involving Large Language Models (LLMs).
For similar jobs

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

daily-poetry-image
Daily Chinese ancient poetry and AI-generated images powered by Bing DALL-E-3. GitHub Action triggers the process automatically. Poetry is provided by Today's Poem API. The website is built with Astro.

exif-photo-blog
EXIF Photo Blog is a full-stack photo blog application built with Next.js, Vercel, and Postgres. It features built-in authentication, photo upload with EXIF extraction, photo organization by tag, infinite scroll, light/dark mode, automatic OG image generation, a CMD-K menu with photo search, experimental support for AI-generated descriptions, and support for Fujifilm simulations. The application is easy to deploy to Vercel with just a few clicks and can be customized with a variety of environment variables.

SillyTavern
SillyTavern is a user interface you can install on your computer (and Android phones) that allows you to interact with text generation AIs and chat/roleplay with characters you or the community create. SillyTavern is a fork of TavernAI 1.2.8 which is under more active development and has added many major features. At this point, they can be thought of as completely independent programs.
Twitter-Insight-LLM
This project enables you to fetch liked tweets from Twitter (using Selenium), save it to JSON and Excel files, and perform initial data analysis and image captions. This is part of the initial steps for a larger personal project involving Large Language Models (LLMs).

AISuperDomain
Aila Desktop Application is a powerful tool that integrates multiple leading AI models into a single desktop application. It allows users to interact with various AI models simultaneously, providing diverse responses and insights to their inquiries. With its user-friendly interface and customizable features, Aila empowers users to engage with AI seamlessly and efficiently. Whether you're a researcher, student, or professional, Aila can enhance your AI interactions and streamline your workflow.

ChatGPT-On-CS
This project is an intelligent dialogue customer service tool based on a large model, which supports access to platforms such as WeChat, Qianniu, Bilibili, Douyin Enterprise, Douyin, Doudian, Weibo chat, Xiaohongshu professional account operation, Xiaohongshu, Zhihu, etc. You can choose GPT3.5/GPT4.0/ Lazy Treasure Box (more platforms will be supported in the future), which can process text, voice and pictures, and access external resources such as operating systems and the Internet through plug-ins, and support enterprise AI applications customized based on their own knowledge base.

obs-localvocal
LocalVocal is a live-streaming AI assistant plugin for OBS that allows you to transcribe audio speech into text and perform various language processing functions on the text using AI / LLMs (Large Language Models). It's privacy-first, with all data staying on your machine, and requires no GPU, cloud costs, network, or downtime.