
sdk
Vikit.ai SDK let you develop easily video generators leveraging generative AI and other AI models.
Stars: 55

Vikit.ai SDK is a software development kit that enables easy development of video generators using generative AI and other AI models. It serves as a langchain to orchestrate AI models and video editing tools. The SDK allows users to create videos from text prompts with background music and voice-over narration. It also supports generating composite videos from multiple text prompts. The tool requires Python 3.8+, specific dependencies, and tools like FFMPEG and ImageMagick for certain functionalities. Users can contribute to the project by following the contribution guidelines and standards provided.
README:
Vikit.ai SDK let you develop easily video generators leveraging generative AI and other AI models. You may see this as a langchain to orchestrate AI models and video editing tools. To see the video in full resolution, click on the GIF.



You need a personal access token, which you can easily obtain from here.
-
Vikit.ai SDK is easy to test standalone using Google Colab.
-
It is easy to develop through Dev Containers. Dev container file and instructions are available here
- Python 3.8+
-
requirements.txtcontains requirements for python environment - FFMPEG and FFPROBE (on mac, using homebrew: brew install ffmpeg and on linux, using apt-get: sudo apt-get install ffmpeg)
- ImageMagick (for subtitles only; on mac, using homebrew: brew install imagemagick and on linux, using apt-get: sudo apt-get install imagemagick)
Generating a video from simple text prompt, with background music and voice over narration:
import asyncio
from vikit.music_building_context import MusicBuildingContext
from vikit.prompt.prompt_factory import PromptFactory
from vikit.video.prompt_based_video import PromptBasedVideo
from vikit.video.video_build_settings import VideoBuildSettings
prompt = "Paris, the City of Light, is a global center of art, fashion, and culture, renowned for its iconic landmarks and romantic atmosphere. The Eiffel Tower, Louvre Museum, and Notre-Dame Cathedral are just a few of the city's must-see attractions."
video_build_settings = VideoBuildSettings(
music_building_context=MusicBuildingContext(
apply_background_music=True,
generate_background_music=True,
),
include_read_aloud_prompt=True,
)
async def create_video():
prompt = await PromptFactory().create_prompt_from_text(prompt_text)
video = PromptBasedVideo(prompt=prompt)
await video.build(build_settings=video_build_settings)
if __name__ == "__main__":
asyncio.run(create_video())You can orchestrate several videos, using CompositeVideo(). Here is an example showing how to generate two videos from texts:
import asyncio
from vikit.video.composite_video import CompositeVideo
from vikit.video.raw_text_based_video import RawTextBasedVideo
from vikit.video.video_build_settings import VideoBuildSettings
async def create_composite_video():
prompt1 = "Paris, the City of Light, is a global center of art, fashion, and culture, renowned for its iconic landmarks and romantic atmosphere."
prompt2 = "The Eiffel Tower, Louvre Museum, and Notre-Dame Cathedral are just a few of the city's must-see attractions."
video1 = RawTextBasedVideo(prompt1)
video2 = RawTextBasedVideo(prompt2)
video_composite.append_video(video1).append_video(video2)
await video_composite.build(
build_settings=VideoBuildSettings(
output_video_file_name="Composite.mp4",
)
video_composite.append_video(video1).append_video(transit).append_video(video2)
await video_composite.build(
build_settings=VideoBuildSettings(
output_video_file_name="Composite.mp4",
)
)
if __name__ == "__main__":
asyncio.run(create_composite_video())More elaborated examples can be found in script_example.py or in our Google Colab. For additional information, please refer to the Documentation.
If you've encountered a bug, have a feature request, or have any suggestions to improve the project, we encourage you to open an issue on our GitHub repository. To do so, go to the "Issues" tab in our GitHub repository and click "New Issue." Please provide a clear title and detailed description, including steps to reproduce, environment setup, and any relevant screenshots or code snippets. If you have questions, reach out to us [email protected].
Wanna help? You're very welcome! 🚀 :
- New PR: You submit your PR and explain clearly what you want to change. We will review your PR as soon as possible,
- PR validation: If the PR passes all the quality checks then Vikit.ai team assign a reviewer,
- PR review: If everything looks good, the reviewer(s) will approve the PR. Otherwise we will engage a discussion and iterate until completion,
- CI tests & Merge: Once the PR is approved, which means all the CI tests passm someone from the vikit team merge the code to the main branch.
- Fork vikit repository into your own GitHub account.
- Create a new branch and make your changes to the code.
- Commit your changes and push the branch to your forked repository.
- Open a pull request on our repository.
Please make sure your changes are consistent with these common guidelines:
- Include unit tests when you contribute new features
- Keep API compatibility in mind when you change code
- Use messages as proposed here Conventional Commits when you commit your code,
- Update the changelog: Change Log best practices
- We do use Semantic Versioning
- Please identify yourself with a valid email address as explained here: Setting your commit email address
- The content generated by the models in this repository is the sole responsibility of the user who initiates the generation. Users must ensure that their use of the generated content complies with all applicable laws, regulations, and ethical guidelines. The project contributors are not liable for any misuse, harm, or legal implications resulting from the use of the models provided. Users are encouraged to exercise caution and discretion when using generative AI tools.
- If you use the default background music, which is royalty free, you still must comply with Pixabay Content License Agreement (https://pixabay.com/fr/service/license-summary/).
- Too many parallel video generation processes might slow things down, just keep an eye on your local CPU usage. Happy coding! 🚀😊
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for sdk
Similar Open Source Tools
sdk
Vikit.ai SDK is a software development kit that enables easy development of video generators using generative AI and other AI models. It serves as a langchain to orchestrate AI models and video editing tools. The SDK allows users to create videos from text prompts with background music and voice-over narration. It also supports generating composite videos from multiple text prompts. The tool requires Python 3.8+, specific dependencies, and tools like FFMPEG and ImageMagick for certain functionalities. Users can contribute to the project by following the contribution guidelines and standards provided.
nobodywho
NobodyWho is a plugin for the Godot game engine that enables interaction with local LLMs for interactive storytelling. Users can install it from Godot editor or GitHub releases page, providing their own LLM in GGUF format. The plugin consists of `NobodyWhoModel` node for model file, `NobodyWhoChat` node for chat interaction, and `NobodyWhoEmbedding` node for generating embeddings. It offers a programming interface for sending text to LLM, receiving responses, and starting the LLM worker.

Sentient
Sentient is a personal, private, and interactive AI companion developed by Existence. The project aims to build a completely private AI companion that is deeply personalized and context-aware of the user. It utilizes automation and privacy to create a true companion for humans. The tool is designed to remember information about the user and use it to respond to queries and perform various actions. Sentient features a local and private environment, MBTI personality test, integrations with LinkedIn, Reddit, and more, self-managed graph memory, web search capabilities, multi-chat functionality, and auto-updates for the app. The project is built using technologies like ElectronJS, Next.js, TailwindCSS, FastAPI, Neo4j, and various APIs.

EdgeChains
EdgeChains is an open-source chain-of-thought engineering framework tailored for Large Language Models (LLMs)- like OpenAI GPT, LLama2, Falcon, etc. - With a focus on enterprise-grade deployability and scalability. EdgeChains is specifically designed to **orchestrate** such applications. At EdgeChains, we take a unique approach to Generative AI - we think Generative AI is a deployment and configuration management challenge rather than a UI and library design pattern challenge. We build on top of a tech that has solved this problem in a different domain - Kubernetes Config Management - and bring that to Generative AI. Edgechains is built on top of jsonnet, originally built by Google based on their experience managing a vast amount of configuration code in the Borg infrastructure.
recognize
Recognize is a smart media tagging tool for Nextcloud that automatically categorizes photos and music by recognizing faces, animals, landscapes, food, vehicles, buildings, landmarks, monuments, music genres, and human actions in videos. It uses pre-trained models for object detection, landmark recognition, face comparison, music genre classification, and video classification. The tool ensures privacy by processing images locally without sending data to cloud providers. However, it cannot process end-to-end encrypted files. Recognize is rated positively for ethical AI practices in terms of open-source software, freely available models, and training data transparency, except for music genre recognition due to limited access to training data.

morphik-core
Morphik is an AI-native toolset designed to help developers integrate context into their AI applications by providing tools to store, represent, and search unstructured data. It offers features such as multimodal search, fast metadata extraction, and integrations with existing tools. Morphik aims to address the challenges of traditional AI approaches that struggle with visually rich documents and provide a more comprehensive solution for understanding and processing complex data.
llocal
LLocal is an Electron application focused on providing a seamless and privacy-driven chatting experience using open-sourced technologies, particularly open-sourced LLM's. It allows users to store chats locally, switch between models, pull new models, upload images, perform web searches, and render responses as markdown. The tool also offers multiple themes, seamless integration with Ollama, and upcoming features like chat with images, web search improvements, retrieval augmented generation, multiple PDF chat, text to speech models, community wallpapers, lofi music, speech to text, and more. LLocal's builds are currently unsigned, requiring manual builds or using the universal build for stability.
ai-dev-gallery
The AI Dev Gallery is an app designed to help Windows developers integrate AI capabilities within their own apps and projects. It contains over 25 interactive samples powered by local AI models, allows users to explore, download, and run models from Hugging Face and GitHub, and provides the ability to view the C# source code and export a standalone Visual Studio project for each sample. The app is open-source and welcomes contributions and suggestions from the community.
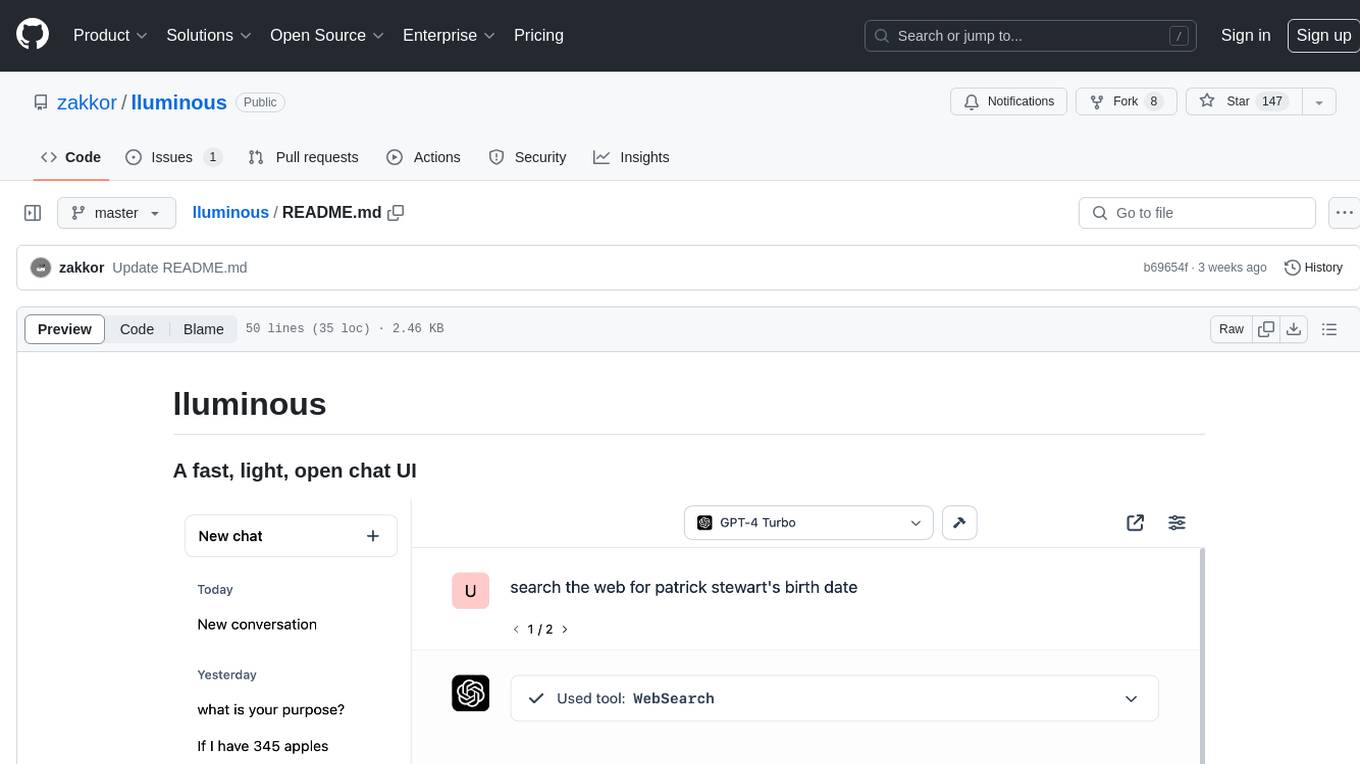
lluminous
lluminous is a fast and light open chat UI that supports multiple providers such as OpenAI, Anthropic, and Groq models. Users can easily plug in their API keys locally to access various models for tasks like multimodal input, image generation, multi-shot prompting, pre-filled responses, and more. The tool ensures privacy by storing all conversation history and keys locally on the user's device. Coming soon features include memory tool, file ingestion/embedding, embeddings-based web search, and prompt templates.

OpenDAN-Personal-AI-OS
OpenDAN is an open source Personal AI OS that consolidates various AI modules for personal use. It empowers users to create powerful AI agents like assistants, tutors, and companions. The OS allows agents to collaborate, integrate with services, and control smart devices. OpenDAN offers features like rapid installation, AI agent customization, connectivity via Telegram/Email, building a local knowledge base, distributed AI computing, and more. It aims to simplify life by putting AI in users' hands. The project is in early stages with ongoing development and future plans for user and kernel mode separation, home IoT device control, and an official OpenDAN SDK release.
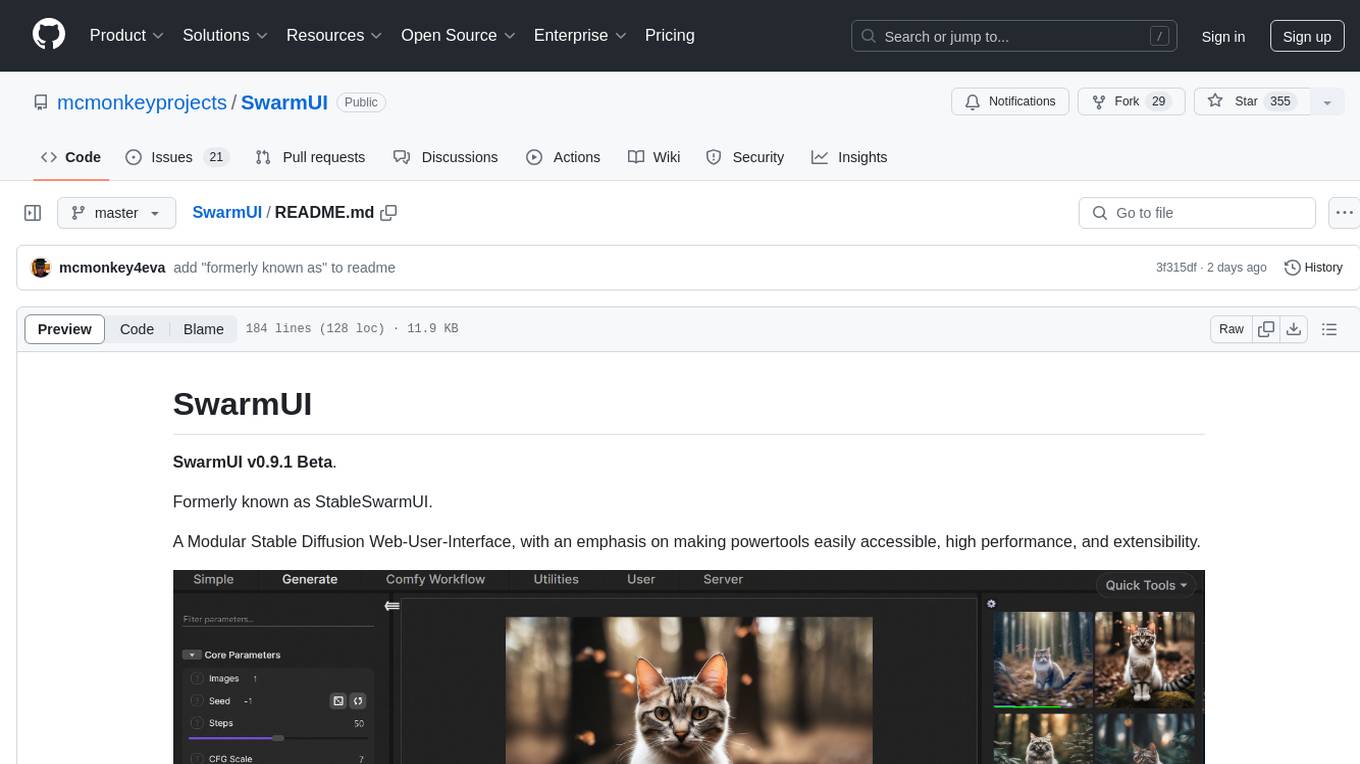
SwarmUI
SwarmUI is a modular stable diffusion web-user-interface designed to make powertools easily accessible, high performance, and extensible. It is in Beta status, offering a primary Generate tab for beginners and a Comfy Workflow tab for advanced users. The tool aims to become a full-featured one-stop-shop for all things Stable Diffusion, with plans for better mobile browser support, detailed 'Current Model' display, dynamic tab shifting, LLM-assisted prompting, and convenient direct distribution as an Electron app.

CodeProject.AI-Server
CodeProject.AI Server is a standalone, self-hosted, fast, free, and open-source Artificial Intelligence microserver designed for any platform and language. It can be installed locally without the need for off-device or out-of-network data transfer, providing an easy-to-use solution for developers interested in AI programming. The server includes a HTTP REST API server, backend analysis services, and the source code, enabling users to perform various AI tasks locally without relying on external services or cloud computing. Current capabilities include object detection, face detection, scene recognition, sentiment analysis, and more, with ongoing feature expansions planned. The project aims to promote AI development, simplify AI implementation, focus on core use-cases, and leverage the expertise of the developer community.

Dot
Dot is a standalone, open-source application designed for seamless interaction with documents and files using local LLMs and Retrieval Augmented Generation (RAG). It is inspired by solutions like Nvidia's Chat with RTX, providing a user-friendly interface for those without a programming background. Pre-packaged with Mistral 7B, Dot ensures accessibility and simplicity right out of the box. Dot allows you to load multiple documents into an LLM and interact with them in a fully local environment. Supported document types include PDF, DOCX, PPTX, XLSX, and Markdown. Users can also engage with Big Dot for inquiries not directly related to their documents, similar to interacting with ChatGPT. Built with Electron JS, Dot encapsulates a comprehensive Python environment that includes all necessary libraries. The application leverages libraries such as FAISS for creating local vector stores, Langchain, llama.cpp & Huggingface for setting up conversation chains, and additional tools for document management and interaction.

Pandrator
Pandrator is a GUI tool for generating audiobooks and dubbing using voice cloning and AI. It transforms text, PDF, EPUB, and SRT files into spoken audio in multiple languages. It leverages XTTS, Silero, and VoiceCraft models for text-to-speech conversion and voice cloning, with additional features like LLM-based text preprocessing and NISQA for audio quality evaluation. The tool aims to be user-friendly with a one-click installer and a graphical interface.
aide
Aide is an Open Source AI-native code editor that combines the powerful features of VS Code with advanced AI capabilities. It provides a combined chat + edit flow, proactive agents for fixing errors, inline editing widget, intelligent code completion, and AST navigation. Aide is designed to be an intelligent coding companion, helping users write better code faster while maintaining control over the development process.
CyberScraper-2077
CyberScraper 2077 is an advanced web scraping tool powered by AI, designed to extract data from websites with precision and style. It offers a user-friendly interface, supports multiple data export formats, operates in stealth mode to avoid detection, and promises lightning-fast scraping. The tool respects ethical scraping practices, including robots.txt and site policies. With upcoming features like proxy support and page navigation, CyberScraper 2077 is a futuristic solution for data extraction in the digital realm.
For similar tasks

hass-ollama-conversation
The Ollama Conversation integration adds a conversation agent powered by Ollama in Home Assistant. This agent can be used in automations to query information provided by Home Assistant about your house, including areas, devices, and their states. Users can install the integration via HACS and configure settings such as API timeout, model selection, context size, maximum tokens, and other parameters to fine-tune the responses generated by the AI language model. Contributions to the project are welcome, and discussions can be held on the Home Assistant Community platform.

rclip
rclip is a command-line photo search tool powered by the OpenAI's CLIP neural network. It allows users to search for images using text queries, similar image search, and combining multiple queries. The tool extracts features from photos to enable searching and indexing, with options for previewing results in supported terminals or custom viewers. Users can install rclip on Linux, macOS, and Windows using different installation methods. The repository follows the Conventional Commits standard and welcomes contributions from the community.

honcho
Honcho is a platform for creating personalized AI agents and LLM powered applications for end users. The repository is a monorepo containing the server/API for managing database interactions and storing application state, along with a Python SDK. It utilizes FastAPI for user context management and Poetry for dependency management. The API can be run using Docker or manually by setting environment variables. The client SDK can be installed using pip or Poetry. The project is open source and welcomes contributions, following a fork and PR workflow. Honcho is licensed under the AGPL-3.0 License.
core
OpenSumi is a framework designed to help users quickly build AI Native IDE products. It provides a set of tools and templates for creating Cloud IDEs, Desktop IDEs based on Electron, CodeBlitz web IDE Framework, Lite Web IDE on the Browser, and Mini-App liked IDE. The framework also offers documentation for users to refer to and a detailed guide on contributing to the project. OpenSumi encourages contributions from the community and provides a platform for users to report bugs, contribute code, or improve documentation. The project is licensed under the MIT license and contains third-party code under other open source licenses.
yolo-ios-app
The Ultralytics YOLO iOS App GitHub repository offers an advanced object detection tool leveraging YOLOv8 models for iOS devices. Users can transform their devices into intelligent detection tools to explore the world in a new and exciting way. The app provides real-time detection capabilities with multiple AI models to choose from, ranging from 'nano' to 'x-large'. Contributors are welcome to participate in this open-source project, and licensing options include AGPL-3.0 for open-source use and an Enterprise License for commercial integration. Users can easily set up the app by following the provided steps, including cloning the repository, adding YOLOv8 models, and running the app on their iOS devices.
PyAirbyte
PyAirbyte brings the power of Airbyte to every Python developer by providing a set of utilities to use Airbyte connectors in Python. It enables users to easily manage secrets, work with various connectors like GitHub, Shopify, and Postgres, and contribute to the project. PyAirbyte is not a replacement for Airbyte but complements it, supporting data orchestration frameworks like Airflow and Snowpark. Users can develop ETL pipelines and import connectors from local directories. The tool simplifies data integration tasks for Python developers.
md-agent
MD-Agent is a LLM-agent based toolset for Molecular Dynamics. It uses Langchain and a collection of tools to set up and execute molecular dynamics simulations, particularly in OpenMM. The tool assists in environment setup, installation, and usage by providing detailed steps. It also requires API keys for certain functionalities, such as OpenAI and paper-qa for literature searches. Contributions to the project are welcome, with a detailed Contributor's Guide available for interested individuals.
flowgen
FlowGen is a tool built for AutoGen, a great agent framework from Microsoft and a lot of contributors. It provides intuitive visual tools that streamline the construction and oversight of complex agent-based workflows, simplifying the process for creators and developers. Users can create Autoflows, chat with agents, and share flow templates. The tool is fully dockerized and supports deployment on Railway.app. Contributions to the project are welcome, and the platform uses semantic-release for versioning and releases.
For similar jobs

promptflow
**Prompt flow** is a suite of development tools designed to streamline the end-to-end development cycle of LLM-based AI applications, from ideation, prototyping, testing, evaluation to production deployment and monitoring. It makes prompt engineering much easier and enables you to build LLM apps with production quality.

deepeval
DeepEval is a simple-to-use, open-source LLM evaluation framework specialized for unit testing LLM outputs. It incorporates various metrics such as G-Eval, hallucination, answer relevancy, RAGAS, etc., and runs locally on your machine for evaluation. It provides a wide range of ready-to-use evaluation metrics, allows for creating custom metrics, integrates with any CI/CD environment, and enables benchmarking LLMs on popular benchmarks. DeepEval is designed for evaluating RAG and fine-tuning applications, helping users optimize hyperparameters, prevent prompt drifting, and transition from OpenAI to hosting their own Llama2 with confidence.

MegaDetector
MegaDetector is an AI model that identifies animals, people, and vehicles in camera trap images (which also makes it useful for eliminating blank images). This model is trained on several million images from a variety of ecosystems. MegaDetector is just one of many tools that aims to make conservation biologists more efficient with AI. If you want to learn about other ways to use AI to accelerate camera trap workflows, check out our of the field, affectionately titled "Everything I know about machine learning and camera traps".

leapfrogai
LeapfrogAI is a self-hosted AI platform designed to be deployed in air-gapped resource-constrained environments. It brings sophisticated AI solutions to these environments by hosting all the necessary components of an AI stack, including vector databases, model backends, API, and UI. LeapfrogAI's API closely matches that of OpenAI, allowing tools built for OpenAI/ChatGPT to function seamlessly with a LeapfrogAI backend. It provides several backends for various use cases, including llama-cpp-python, whisper, text-embeddings, and vllm. LeapfrogAI leverages Chainguard's apko to harden base python images, ensuring the latest supported Python versions are used by the other components of the stack. The LeapfrogAI SDK provides a standard set of protobuffs and python utilities for implementing backends and gRPC. LeapfrogAI offers UI options for common use-cases like chat, summarization, and transcription. It can be deployed and run locally via UDS and Kubernetes, built out using Zarf packages. LeapfrogAI is supported by a community of users and contributors, including Defense Unicorns, Beast Code, Chainguard, Exovera, Hypergiant, Pulze, SOSi, United States Navy, United States Air Force, and United States Space Force.

llava-docker
This Docker image for LLaVA (Large Language and Vision Assistant) provides a convenient way to run LLaVA locally or on RunPod. LLaVA is a powerful AI tool that combines natural language processing and computer vision capabilities. With this Docker image, you can easily access LLaVA's functionalities for various tasks, including image captioning, visual question answering, text summarization, and more. The image comes pre-installed with LLaVA v1.2.0, Torch 2.1.2, xformers 0.0.23.post1, and other necessary dependencies. You can customize the model used by setting the MODEL environment variable. The image also includes a Jupyter Lab environment for interactive development and exploration. Overall, this Docker image offers a comprehensive and user-friendly platform for leveraging LLaVA's capabilities.

carrot
The 'carrot' repository on GitHub provides a list of free and user-friendly ChatGPT mirror sites for easy access. The repository includes sponsored sites offering various GPT models and services. Users can find and share sites, report errors, and access stable and recommended sites for ChatGPT usage. The repository also includes a detailed list of ChatGPT sites, their features, and accessibility options, making it a valuable resource for ChatGPT users seeking free and unlimited GPT services.

TrustLLM
TrustLLM is a comprehensive study of trustworthiness in LLMs, including principles for different dimensions of trustworthiness, established benchmark, evaluation, and analysis of trustworthiness for mainstream LLMs, and discussion of open challenges and future directions. Specifically, we first propose a set of principles for trustworthy LLMs that span eight different dimensions. Based on these principles, we further establish a benchmark across six dimensions including truthfulness, safety, fairness, robustness, privacy, and machine ethics. We then present a study evaluating 16 mainstream LLMs in TrustLLM, consisting of over 30 datasets. The document explains how to use the trustllm python package to help you assess the performance of your LLM in trustworthiness more quickly. For more details about TrustLLM, please refer to project website.

AI-YinMei
AI-YinMei is an AI virtual anchor Vtuber development tool (N card version). It supports fastgpt knowledge base chat dialogue, a complete set of solutions for LLM large language models: [fastgpt] + [one-api] + [Xinference], supports docking bilibili live broadcast barrage reply and entering live broadcast welcome speech, supports Microsoft edge-tts speech synthesis, supports Bert-VITS2 speech synthesis, supports GPT-SoVITS speech synthesis, supports expression control Vtuber Studio, supports painting stable-diffusion-webui output OBS live broadcast room, supports painting picture pornography public-NSFW-y-distinguish, supports search and image search service duckduckgo (requires magic Internet access), supports image search service Baidu image search (no magic Internet access), supports AI reply chat box [html plug-in], supports AI singing Auto-Convert-Music, supports playlist [html plug-in], supports dancing function, supports expression video playback, supports head touching action, supports gift smashing action, supports singing automatic start dancing function, chat and singing automatic cycle swing action, supports multi scene switching, background music switching, day and night automatic switching scene, supports open singing and painting, let AI automatically judge the content.