
AntSK
基于.Net8+AntBlazor+SemanticKernel 和KernelMemory 打造的AI知识库/智能体,支持本地离线AI大模型。可以不联网离线运行。支持aspire观测应用数据
Stars: 1310

AntSK is an AI knowledge base/agent built with .Net8+Blazor+SemanticKernel. It features a semantic kernel for accurate natural language processing, a memory kernel for continuous learning and knowledge storage, a knowledge base for importing and querying knowledge from various document formats, a text-to-image generator integrated with StableDiffusion, GPTs generation for creating personalized GPT models, API interfaces for integrating AntSK into other applications, an open API plugin system for extending functionality, a .Net plugin system for integrating business functions, real-time information retrieval from the internet, model management for adapting and managing different models from different vendors, support for domestic models and databases for operation in a trusted environment, and planned model fine-tuning based on llamafactory.
README:
简体中文 | English
-
Semantic Kernel: Utilizes advanced natural language processing technology to accurately understand, process, and respond to complex semantic queries, providing users with precise information retrieval and recommendation services.
-
Kernel Memory: Capable of continuous learning and storing knowledge points, AntSK has long-term memory function, accumulates experience, and provides a more personalized interaction experience.
-
Knowledge Base: Import knowledge base through documents (Word, PDF, Excel, Txt, Markdown, Json, PPT) and perform knowledge base Q&A.
-
GPT Generation: This platform supports creating personalized GPT models, enabling users to build their own GPT models.
-
API Interface Publishing: Exposes internal functions in the form of APIs, enabling developers to integrate AntSK into other applications and enhance application intelligence.
-
API Plugin System: Open API plugin system that allows third-party developers or service providers to easily integrate their services into AntSK, continuously enhancing application functionality.
-
.Net Plugin System: Open dll plugin system that allows third-party developers or service providers to easily integrate their business functions by generating dll in standard format code, continuously enhancing application functionality.
-
Online Search: AntSK, real-time access to the latest information, ensuring users receive the most timely and relevant data.
-
Model Management: Adapts and manages integration of different models from different manufacturers, models offline running supported by llamafactory and ollama.
-
Domestic Innovation: AntSK supports domestic models and databases and can run under domestic innovation conditions.
-
Model Fine-Tuning: Planned based on llamafactory for model fine-tuning.
AntSK is suitable for various business scenarios, such as:
- Enterprise knowledge management system
- Automatic customer service and chatbots
- Enterprise search engine
- Personalized recommendation system
- Intelligent writing assistance
- Education and online learning platforms
- Other interesting AI Apps
Default account: test
Default password: test
Due to the low configuration of the cloud server, the local model cannot be run, so the system settings permissions have been closed. You can simply view the interface. If you want to use the local model, please download and use it on your own.
Here I am using Postgres as the data and vector storage because Semantic Kernel and Kernel Memory support it, but you can also use other options.
The model by default supports the local model of openai, azure openai, and llama. If you need to use other models, you can integrate them using one-api.
The Login configuration in the configuration file is the default login account and password.
The following configuration file needs to be configured
Provided the pg version appsettings.json and simplified version (Sqlite+disk) docker-compose.simple.yml
Download docker-compose.yml from the project root directory and place the configuration file appsettings.json in the same directory.
The pg image has already been prepared. You can modify the default username and password in docker-compose.yml, and then the database connection in your appsettings.json needs to be consistent.
Then you can execute the following command in the directory to start AntSK
docker-compose up -d
# Non-host version, do not use local proxy
version: '3.8'
services:
antsk:
container_name: antsk
image: registry.cn-hangzhou.aliyuncs.com/AIDotNet/antsk:v0.6.0
ports:
- 5000:5000
networks:
- antsk
depends_on:
- antskpg
restart: always
environment:
- ASPNETCORE_URLS=http://*:5000
volumes:
- ./appsettings.json:/app/appsettings.json # Local configuration file needs to be placed in the same directory
- D://model:/app/model
networks:
antsk:
external: true
Taking this as an example, it means mounting the local D://model folder of Windows into the container /app/model. If so, the model address in your appsettings.json should be configured as
The compact version is deployed with sqlite-disk by one click
The full version uses pg+aspire
{
"DBConnection": {
"DbType": "Sqlite",
"ConnectionStrings": "Data Source=AntSK.db;"
},
"KernelMemory": {
"VectorDb": "Disk",
"ConnectionString": "Host=;Port=;Database=antsk;Username=;Password=",
"TableNamePrefix": "km-"
},
"FileDir": {
"DirectoryPath": "D:\\git\\AntBlazor\\model"
},
"Login": {
"User": "admin",
"Password": "xuzeyu"
},
"BackgroundTaskBroker": {
"ImportKMSTask": {
"WorkerCount": 1
}
}
}
// Supports various databases, you can check SqlSugar, MySql, SqlServer, Sqlite, Oracle, PostgreSQL, Dm, Kdbndp, Oscar, MySqlConnector, Access, OpenGauss, QuestDB, HG, ClickHouse, GBase, Odbc, OceanBaseForOracle, TDengine, GaussDB, OceanBase, Tidb, Vastbase, PolarDB, Custom
DBConnection.DbType
// Connection string, need to use the corresponding string according to the different DB types
DBConnection.ConnectionStrings
//The type of vector storage, supporting Postgres, Disk, Memory, Qdrant, Redis, AzureAISearch
//Postgres and Redis require ConnectionString configuration
//The ConnectionString of Qdrant and AzureAISearch uses Endpoint | APIKey
KernelMemory.VectorDb
//Local model path, used for quick selection of models under llama, as well as saving downloaded models.
FileDir.DirectoryPath
//Default admin account password
Login
//Import asynchronous processing thread count. A higher count can be used for online API, but for local models, 1 is recommended to avoid memory overflow issues.
BackgroundTaskBroker.ImportKMSTask.WorkerCount
Run the following in AntSK/src/AntSK:
dotnet clean
dotnet build
dotnet publish "AntSK.csproj"
Then navigate to AntSK/src/AntSK/bin/Release/net8.0/publish and run:
dotnet AntSK.dll
The styles should now be applied after starting.
I'm using CodeFirst mode for the database, so as long as the database connection is properly configured, the table structure will be created automatically.
1. First, ensure that Python and pip are installed in your environment. This step is not necessary if using an image, such as version v0.2.3.2, which already includes the complete Python environment.
2. Go to the model add page and select llamafactory.
3. Click "Initialize" to check whether the 'pip install' environment setup is complete.
4. Choose a model that you like.
5. Click "Start" to begin downloading the model from the tower. This may involve a somewhat lengthy wait.
6. After the model has finished downloading, enter http://localhost:8000/ in the request address. The default port is 8000.
7. Click "Save" and start chatting.
8. Many people ask about the difference between LLamaSharp and llamafactory. In fact, LLamaSharp is a .NET implementation of llama.cpp, but only supports local gguf models, while llamafactory supports a wider variety of models and uses Python implementation. The main difference lies here. Additionally, llamafactory has the ability to fine-tune models, which is an area we will focus on integrating in the future.
This project exists thanks to all the people who contribute.
This warehouse follows the AntSK License open source protocol.
This project follows the Apache 2.0 agreement, in addition to the following additional terms
-
Free Commercial Use: Users can use the software for commercial purposes without modifying the code.
-
Commercial License Required: A commercial license is required if any of the following conditions are met:
- You modify, develop, or alter the software, including but not limited to changes to the application name, logo, code, or functionality.
- You provide multi-tenant services to enterprise customers with 10 or more users.
- You pre-install or integrate the software into hardware devices or products and bundle it for sale.
- You are engaging in large-scale procurement for government or educational institutions, especially involving security, data privacy, or other sensitive requirements.
-
If you need authorization, you can contact WeChat: xuzeyu91
If you plan to use AntSK in commercial projects, you need to ensure that you follow the following steps:
-
Copyright statement containing AntSK license. AntSK License.
-
If you modify the software source code, you need to clearly indicate these modifications in the source code.
-
Meet the above requirements
Helping enterprise AI application development, we recommend AntBlazor
If you have any questions or suggestions, please contact me through my official WeChat account. We also have a discussion group where you can send a message to join, and then I will add you to the group.
Additionally, you can also contact me via email: [email protected]

We appreciate your interest in AntSK and look forward to collaborating with you to create an intelligent future!
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for AntSK
Similar Open Source Tools
AntSK
AntSK is an AI knowledge base/agent built with .Net8+Blazor+SemanticKernel. It features a semantic kernel for accurate natural language processing, a memory kernel for continuous learning and knowledge storage, a knowledge base for importing and querying knowledge from various document formats, a text-to-image generator integrated with StableDiffusion, GPTs generation for creating personalized GPT models, API interfaces for integrating AntSK into other applications, an open API plugin system for extending functionality, a .Net plugin system for integrating business functions, real-time information retrieval from the internet, model management for adapting and managing different models from different vendors, support for domestic models and databases for operation in a trusted environment, and planned model fine-tuning based on llamafactory.

draive
draive is an open-source Python library designed to simplify and accelerate the development of LLM-based applications. It offers abstract building blocks for connecting functionalities with large language models, flexible integration with various AI solutions, and a user-friendly framework for building scalable data processing pipelines. The library follows a function-oriented design, allowing users to represent complex programs as simple functions. It also provides tools for measuring and debugging functionalities, ensuring type safety and efficient asynchronous operations for modern Python apps.

OpenDAN-Personal-AI-OS
OpenDAN is an open source Personal AI OS that consolidates various AI modules for personal use. It empowers users to create powerful AI agents like assistants, tutors, and companions. The OS allows agents to collaborate, integrate with services, and control smart devices. OpenDAN offers features like rapid installation, AI agent customization, connectivity via Telegram/Email, building a local knowledge base, distributed AI computing, and more. It aims to simplify life by putting AI in users' hands. The project is in early stages with ongoing development and future plans for user and kernel mode separation, home IoT device control, and an official OpenDAN SDK release.
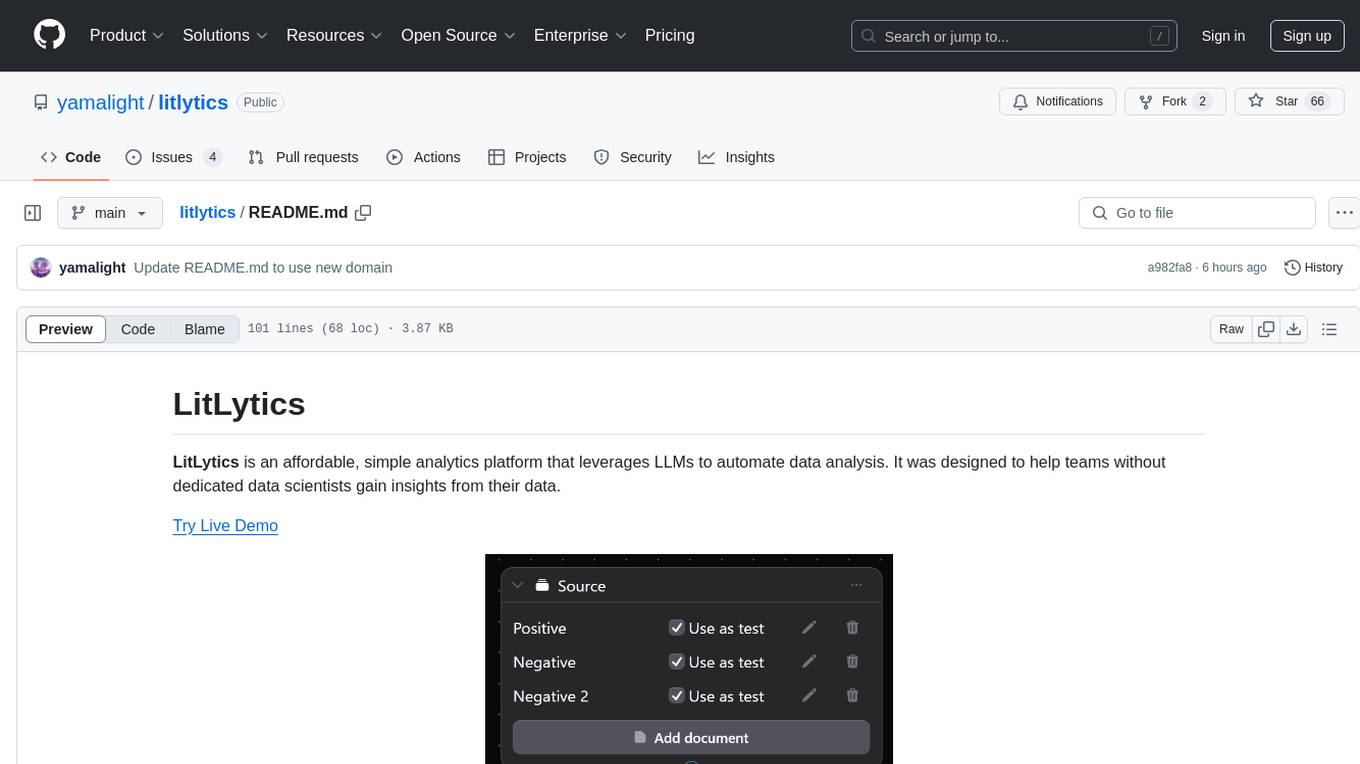
litlytics
LitLytics is an affordable analytics platform leveraging LLMs for automated data analysis. It simplifies analytics for teams without data scientists, generates custom pipelines, and allows customization. Cost-efficient with low data processing costs. Scalable and flexible, works with CSV, PDF, and plain text data formats.

project_alice
Alice is an agentic workflow framework that integrates task execution and intelligent chat capabilities. It provides a flexible environment for creating, managing, and deploying AI agents for various purposes, leveraging a microservices architecture with MongoDB for data persistence. The framework consists of components like APIs, agents, tasks, and chats that interact to produce outputs through files, messages, task results, and URL references. Users can create, test, and deploy agentic solutions in a human-language framework, making it easy to engage with by both users and agents. The tool offers an open-source option, user management, flexible model deployment, and programmatic access to tasks and chats.

reductstore
ReductStore is a high-performance time series database designed for storing and managing large amounts of unstructured blob data. It offers features such as real-time querying, batching data, and HTTP(S) API for edge computing, computer vision, and IoT applications. The database ensures data integrity, implements retention policies, and provides efficient data access, making it a cost-effective solution for applications requiring unstructured data storage and access at specific time intervals.

super-agent-party
A 3D AI desktop companion with endless possibilities! This repository provides a platform for enhancing the LLM API without code modification, supporting seamless integration of various functionalities such as knowledge bases, real-time networking, multimodal capabilities, automation, and deep thinking control. It offers one-click deployment to multiple terminals, ecological tool interconnection, standardized interface opening, and compatibility across all platforms. Users can deploy the tool on Windows, macOS, Linux, or Docker, and access features like intelligent agent deployment, VRM desktop pets, Tavern character cards, QQ bot deployment, and developer-friendly interfaces. The tool supports multi-service providers, extensive tool integration, and ComfyUI workflows. Hardware requirements are minimal, making it suitable for various deployment scenarios.
ComfyUI-Tara-LLM-Integration
Tara is a powerful node for ComfyUI that integrates Large Language Models (LLMs) to enhance and automate workflow processes. With Tara, you can create complex, intelligent workflows that refine and generate content, manage API keys, and seamlessly integrate various LLMs into your projects. It comprises nodes for handling OpenAI-compatible APIs, saving and loading API keys, composing multiple texts, and using predefined templates for OpenAI and Groq. Tara supports OpenAI and Grok models with plans to expand support to together.ai and Replicate. Users can install Tara via Git URL or ComfyUI Manager and utilize it for tasks like input guidance, saving and loading API keys, and generating text suitable for chaining in workflows.
Conversation-Knowledge-Mining-Solution-Accelerator
The Conversation Knowledge Mining Solution Accelerator enables customers to leverage intelligence to uncover insights, relationships, and patterns from conversational data. It empowers users to gain valuable knowledge and drive targeted business impact by utilizing Azure AI Foundry, Azure OpenAI, Microsoft Fabric, and Azure Search for topic modeling, key phrase extraction, speech-to-text transcription, and interactive chat experiences.

Instrukt
Instrukt is a terminal-based AI integrated environment that allows users to create and instruct modular AI agents, generate document indexes for question-answering, and attach tools to any agent. It provides a platform for users to interact with AI agents in natural language and run them inside secure containers for performing tasks. The tool supports custom AI agents, chat with code and documents, tools customization, prompt console for quick interaction, LangChain ecosystem integration, secure containers for agent execution, and developer console for debugging and introspection. Instrukt aims to make AI accessible to everyone by providing tools that empower users without relying on external APIs and services.

morphik-core
Morphik is an AI-native toolset designed to help developers integrate context into their AI applications by providing tools to store, represent, and search unstructured data. It offers features such as multimodal search, fast metadata extraction, and integrations with existing tools. Morphik aims to address the challenges of traditional AI approaches that struggle with visually rich documents and provide a more comprehensive solution for understanding and processing complex data.

lollms-webui
LoLLMs WebUI (Lord of Large Language Multimodal Systems: One tool to rule them all) is a user-friendly interface to access and utilize various LLM (Large Language Models) and other AI models for a wide range of tasks. With over 500 AI expert conditionings across diverse domains and more than 2500 fine tuned models over multiple domains, LoLLMs WebUI provides an immediate resource for any problem, from car repair to coding assistance, legal matters, medical diagnosis, entertainment, and more. The easy-to-use UI with light and dark mode options, integration with GitHub repository, support for different personalities, and features like thumb up/down rating, copy, edit, and remove messages, local database storage, search, export, and delete multiple discussions, make LoLLMs WebUI a powerful and versatile tool.

graphrag-local-ollama
GraphRAG Local Ollama is a repository that offers an adaptation of Microsoft's GraphRAG, customized to support local models downloaded using Ollama. It enables users to leverage local models with Ollama for large language models (LLMs) and embeddings, eliminating the need for costly OpenAPI models. The repository provides a simple setup process and allows users to perform question answering over private text corpora by building a graph-based text index and generating community summaries for closely-related entities. GraphRAG Local Ollama aims to improve the comprehensiveness and diversity of generated answers for global sensemaking questions over datasets.

supervisely
Supervisely is a computer vision platform that provides a range of tools and services for developing and deploying computer vision solutions. It includes a data labeling platform, a model training platform, and a marketplace for computer vision apps. Supervisely is used by a variety of organizations, including Fortune 500 companies, research institutions, and government agencies.
csghub-server
CSGHub Server is a part of the open source and reliable large model assets management platform - CSGHub. It focuses on management of models, datasets, and other LLM assets through REST API. Key features include creation and management of users and organizations, auto-tagging of model and dataset labels, search functionality, online preview of dataset files, content moderation for text and image, download of individual files, tracking of model and dataset activity data. The tool is extensible and customizable, supporting different git servers, flexible LFS storage system configuration, and content moderation options. The roadmap includes support for more Git servers, Git LFS, dataset online viewer, model/dataset auto-tag, S3 protocol support, model format conversion, and model one-click deploy. The project is licensed under Apache 2.0 and welcomes contributions.

PulsarRPA
PulsarRPA is a high-performance, distributed, open-source Robotic Process Automation (RPA) framework designed to handle large-scale RPA tasks with ease. It provides a comprehensive solution for browser automation, web content understanding, and data extraction. PulsarRPA addresses challenges of browser automation and accurate web data extraction from complex and evolving websites. It incorporates innovative technologies like browser rendering, RPA, intelligent scraping, advanced DOM parsing, and distributed architecture to ensure efficient, accurate, and scalable web data extraction. The tool is open-source, customizable, and supports cutting-edge information extraction technology, making it a preferred solution for large-scale web data extraction.
For similar tasks

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

onnxruntime-genai
ONNX Runtime Generative AI is a library that provides the generative AI loop for ONNX models, including inference with ONNX Runtime, logits processing, search and sampling, and KV cache management. Users can call a high level `generate()` method, or run each iteration of the model in a loop. It supports greedy/beam search and TopP, TopK sampling to generate token sequences, has built in logits processing like repetition penalties, and allows for easy custom scoring.

jupyter-ai
Jupyter AI connects generative AI with Jupyter notebooks. It provides a user-friendly and powerful way to explore generative AI models in notebooks and improve your productivity in JupyterLab and the Jupyter Notebook. Specifically, Jupyter AI offers: * An `%%ai` magic that turns the Jupyter notebook into a reproducible generative AI playground. This works anywhere the IPython kernel runs (JupyterLab, Jupyter Notebook, Google Colab, Kaggle, VSCode, etc.). * A native chat UI in JupyterLab that enables you to work with generative AI as a conversational assistant. * Support for a wide range of generative model providers, including AI21, Anthropic, AWS, Cohere, Gemini, Hugging Face, NVIDIA, and OpenAI. * Local model support through GPT4All, enabling use of generative AI models on consumer grade machines with ease and privacy.

khoj
Khoj is an open-source, personal AI assistant that extends your capabilities by creating always-available AI agents. You can share your notes and documents to extend your digital brain, and your AI agents have access to the internet, allowing you to incorporate real-time information. Khoj is accessible on Desktop, Emacs, Obsidian, Web, and Whatsapp, and you can share PDF, markdown, org-mode, notion files, and GitHub repositories. You'll get fast, accurate semantic search on top of your docs, and your agents can create deeply personal images and understand your speech. Khoj is self-hostable and always will be.

langchain_dart
LangChain.dart is a Dart port of the popular LangChain Python framework created by Harrison Chase. LangChain provides a set of ready-to-use components for working with language models and a standard interface for chaining them together to formulate more advanced use cases (e.g. chatbots, Q&A with RAG, agents, summarization, extraction, etc.). The components can be grouped into a few core modules: * **Model I/O:** LangChain offers a unified API for interacting with various LLM providers (e.g. OpenAI, Google, Mistral, Ollama, etc.), allowing developers to switch between them with ease. Additionally, it provides tools for managing model inputs (prompt templates and example selectors) and parsing the resulting model outputs (output parsers). * **Retrieval:** assists in loading user data (via document loaders), transforming it (with text splitters), extracting its meaning (using embedding models), storing (in vector stores) and retrieving it (through retrievers) so that it can be used to ground the model's responses (i.e. Retrieval-Augmented Generation or RAG). * **Agents:** "bots" that leverage LLMs to make informed decisions about which available tools (such as web search, calculators, database lookup, etc.) to use to accomplish the designated task. The different components can be composed together using the LangChain Expression Language (LCEL).

danswer
Danswer is an open-source Gen-AI Chat and Unified Search tool that connects to your company's docs, apps, and people. It provides a Chat interface and plugs into any LLM of your choice. Danswer can be deployed anywhere and for any scale - on a laptop, on-premise, or to cloud. Since you own the deployment, your user data and chats are fully in your own control. Danswer is MIT licensed and designed to be modular and easily extensible. The system also comes fully ready for production usage with user authentication, role management (admin/basic users), chat persistence, and a UI for configuring Personas (AI Assistants) and their Prompts. Danswer also serves as a Unified Search across all common workplace tools such as Slack, Google Drive, Confluence, etc. By combining LLMs and team specific knowledge, Danswer becomes a subject matter expert for the team. Imagine ChatGPT if it had access to your team's unique knowledge! It enables questions such as "A customer wants feature X, is this already supported?" or "Where's the pull request for feature Y?"

infinity
Infinity is an AI-native database designed for LLM applications, providing incredibly fast full-text and vector search capabilities. It supports a wide range of data types, including vectors, full-text, and structured data, and offers a fused search feature that combines multiple embeddings and full text. Infinity is easy to use, with an intuitive Python API and a single-binary architecture that simplifies deployment. It achieves high performance, with 0.1 milliseconds query latency on million-scale vector datasets and up to 15K QPS.
For similar jobs
AntSK
AntSK is an AI knowledge base/agent built with .Net8+Blazor+SemanticKernel. It features a semantic kernel for accurate natural language processing, a memory kernel for continuous learning and knowledge storage, a knowledge base for importing and querying knowledge from various document formats, a text-to-image generator integrated with StableDiffusion, GPTs generation for creating personalized GPT models, API interfaces for integrating AntSK into other applications, an open API plugin system for extending functionality, a .Net plugin system for integrating business functions, real-time information retrieval from the internet, model management for adapting and managing different models from different vendors, support for domestic models and databases for operation in a trusted environment, and planned model fine-tuning based on llamafactory.
hoarder-app
Hoarder is a self-hostable bookmark manager with a focus on privacy and customization. It features automatic link previews, full-text search, AI-based tagging, and a variety of import and export options. Hoarder is designed to be easy to use and extensible, with a plugin system that allows users to add their own features and integrations.