
CLIPPyX
AI Powered Image search tool offers content-based, text, and visual similarity system-wide search.
Stars: 130

CLIPPyX is a powerful system-wide image search and management tool that offers versatile search options to find images based on their content, text, and visual similarity. With advanced features, users can effortlessly locate desired images across their entire computer's disk(s), regardless of their location or file names. The tool utilizes OpenAI's CLIP for image embeddings and text-based search, along with OCR for extracting text from images. It also employs Voidtools Everything SDK to list paths of all images on the system. CLIPPyX server receives search queries and queries collections of image embeddings and text embeddings to return relevant images.
README:
CLIPPyX is a powerful system-wide image search and management tool that offers versatile search options to find images based on their content, text, and visual similarity. With its advanced features, you can effortlessly locate the desired images across your entire computer's disk(s), regardless of their location or file names.

-
Search by Image Caption: Enter descriptive text or phrases, using CLIP, CLIPPyX will return all images related to that semantic meaning or caption.
-
Search by Textual Content in Images: Provide descriptive text or phrases, and using Optical Character Recognition (OCR) and text embedding model, CLIPPyX will return all images with text semantically similar to the provided text.
-
Search by Image Similarity: Provide an existing image as a reference, and CLIPPyX will find visually similar images using CLIP.

-
Everything SDK: CLIPPyX uses Voidtools Everything SDK to list the paths of all images on the system.
-
CLIP: OpenAI's CLIP is the main component of CLIPPyX. It's to store all image embeddings in vector database to query on later.
-
OCR & Text Embedding: OCR is applied to all images to extract text from them, then these texts are embedded using a text embedding model and stored in a vector database to perfrom text-based search.
-
CLIPPyX Server: CLIPPyX server receives the search query from the UI, then it queries the collections of image embeddings and text embeddings to return the relevant images.
- Install & Run Everything in your Windows machine
- Install in your envPytorch
- Clone the repository
- in the root directory, run the command
pip install -e .
- to start CLIPPyX server, run
CLIPPyX
After some automatic downloads (Everything SDK, Models from 🤗 Transformers), you should see the indexing process starting. Then the server will be ready to receive search queries.
* Serving Flask app 'server'
* Debug mode: off
INFO:werkzeug:WARNING: This is a development server. Do not use it in a production deployment. Use a production WSGI server instead.
* Running on all addresses (0.0.0.0)
* Running on http://127.0.0.1:23107
* Running on http://172.25.97.13:23107
you can check the server is running be sending a simple request to the server using CURL or Postman.
curl -X POST -H "Content-Type: application/json" -d "{\"text\": \"Enter your query here\"}" http://localhost:23107/clip_text
For more memory efficient and faster indexing and search, there're alternative for both CLIP and Text Embedding models
Getting the Paths of all images must be done in Windows to run Everything SDK, However, running the server itself in WSL is a good alternative, especially when using Alternative Models due some issues or complex setup process on Windows
- Assuming you already have WSL installed, in a new environment, follow the same installation steps (don't start the server)
- in
config.yamlchangeserver_ostowsl - in
server_wsl.shadd path to your WSL python environmen (example provided) - in your Windows powershell or command prompt , run
CLIPPyXcommand. This will use Everything SDK in Windows, then start the server in WSL.
Having CLIPPyX server running, you can use any UI capable of sending HTTP requests to the server, you can customize any UI to do this, or use one of the provided UIs.
Check UI page to check available options.
Check Issues for future work and contributions. don't hesitate to open a new issue for any feature request or bug report.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for CLIPPyX
Similar Open Source Tools
CLIPPyX
CLIPPyX is a powerful system-wide image search and management tool that offers versatile search options to find images based on their content, text, and visual similarity. With advanced features, users can effortlessly locate desired images across their entire computer's disk(s), regardless of their location or file names. The tool utilizes OpenAI's CLIP for image embeddings and text-based search, along with OCR for extracting text from images. It also employs Voidtools Everything SDK to list paths of all images on the system. CLIPPyX server receives search queries and queries collections of image embeddings and text embeddings to return relevant images.
multimodal-chat
Yet Another Chatbot is a sophisticated multimodal chat interface powered by advanced AI models and equipped with a variety of tools. This chatbot can search and browse the web in real-time, query Wikipedia for information, perform news and map searches, execute Python code, compose long-form articles mixing text and images, generate, search, and compare images, analyze documents and images, search and download arXiv papers, save conversations as text and audio files, manage checklists, and track personal improvements. It offers tools for web interaction, Wikipedia search, Python scripting, content management, image handling, arXiv integration, conversation generation, file management, personal improvement, and checklist management.
ImageIndexer
LLMII is a tool that uses a local AI model to label metadata and index images without relying on cloud services or remote APIs. It runs a visual language model on your computer to generate captions and keywords for images, enhancing their metadata for indexing, searching, and organization. The tool can be run multiple times on the same image files, allowing for adding new data, regenerating data, and discovering files with issues. It supports various image formats, offers a user-friendly GUI, and can utilize GPU acceleration for faster processing. LLMII requires Python 3.8 or higher and operates directly on image file metadata fields like MWG:Keyword and XMP:Identifier.
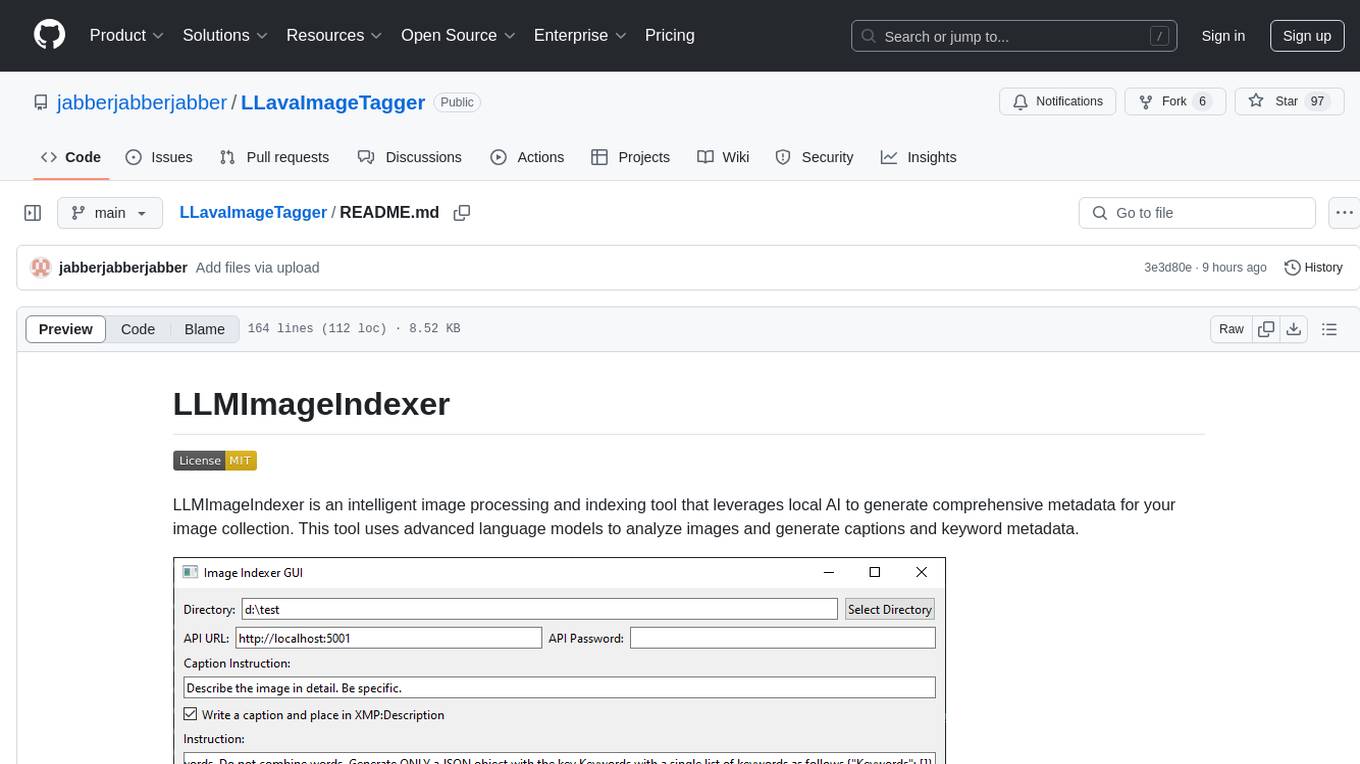
LLavaImageTagger
LLMImageIndexer is an intelligent image processing and indexing tool that leverages local AI to generate comprehensive metadata for your image collection. It uses advanced language models to analyze images and generate captions and keyword metadata. The tool offers features like intelligent image analysis, metadata enhancement, local processing, multi-format support, user-friendly GUI, GPU acceleration, cross-platform support, stop and start capability, and keyword post-processing. It operates directly on image file metadata, allowing users to manage files, add new files, and run the tool multiple times without reprocessing previously keyworded files. Installation instructions are provided for Windows, macOS, and Linux platforms, along with usage guidelines and configuration options.
Local-Multimodal-AI-Chat
Local Multimodal AI Chat is a multimodal chat application that integrates various AI models to manage audio, images, and PDFs seamlessly within a single interface. It offers local model processing with Ollama for data privacy, integration with OpenAI API for broader AI capabilities, audio chatting with Whisper AI for accurate voice interpretation, and PDF chatting with Chroma DB for efficient PDF interactions. The application is designed for AI enthusiasts and developers seeking a comprehensive solution for multimodal AI technologies.

cognita
Cognita is an open-source framework to organize your RAG codebase along with a frontend to play around with different RAG customizations. It provides a simple way to organize your codebase so that it becomes easy to test it locally while also being able to deploy it in a production ready environment. The key issues that arise while productionizing RAG system from a Jupyter Notebook are: 1. **Chunking and Embedding Job** : The chunking and embedding code usually needs to be abstracted out and deployed as a job. Sometimes the job will need to run on a schedule or be trigerred via an event to keep the data updated. 2. **Query Service** : The code that generates the answer from the query needs to be wrapped up in a api server like FastAPI and should be deployed as a service. This service should be able to handle multiple queries at the same time and also autoscale with higher traffic. 3. **LLM / Embedding Model Deployment** : Often times, if we are using open-source models, we load the model in the Jupyter notebook. This will need to be hosted as a separate service in production and model will need to be called as an API. 4. **Vector DB deployment** : Most testing happens on vector DBs in memory or on disk. However, in production, the DBs need to be deployed in a more scalable and reliable way. Cognita makes it really easy to customize and experiment everything about a RAG system and still be able to deploy it in a good way. It also ships with a UI that makes it easier to try out different RAG configurations and see the results in real time. You can use it locally or with/without using any Truefoundry components. However, using Truefoundry components makes it easier to test different models and deploy the system in a scalable way. Cognita allows you to host multiple RAG systems using one app. ### Advantages of using Cognita are: 1. A central reusable repository of parsers, loaders, embedders and retrievers. 2. Ability for non-technical users to play with UI - Upload documents and perform QnA using modules built by the development team. 3. Fully API driven - which allows integration with other systems. > If you use Cognita with Truefoundry AI Gateway, you can get logging, metrics and feedback mechanism for your user queries. ### Features: 1. Support for multiple document retrievers that use `Similarity Search`, `Query Decompostion`, `Document Reranking`, etc 2. Support for SOTA OpenSource embeddings and reranking from `mixedbread-ai` 3. Support for using LLMs using `Ollama` 4. Support for incremental indexing that ingests entire documents in batches (reduces compute burden), keeps track of already indexed documents and prevents re-indexing of those docs.
DistiLlama
DistiLlama is a Chrome extension that leverages a locally running Large Language Model (LLM) to perform various tasks, including text summarization, chat, and document analysis. It utilizes Ollama as the locally running LLM instance and LangChain for text summarization. DistiLlama provides a user-friendly interface for interacting with the LLM, allowing users to summarize web pages, chat with documents (including PDFs), and engage in text-based conversations. The extension is easy to install and use, requiring only the installation of Ollama and a few simple steps to set up the environment. DistiLlama offers a range of customization options, including the choice of LLM model and the ability to configure the summarization chain. It also supports multimodal capabilities, allowing users to interact with the LLM through text, voice, and images. DistiLlama is a valuable tool for researchers, students, and professionals who seek to leverage the power of LLMs for various tasks without compromising data privacy.
Whisper-TikTok
Discover Whisper-TikTok, an innovative AI-powered tool that leverages the prowess of Edge TTS, OpenAI-Whisper, and FFMPEG to craft captivating TikTok videos. Whisper-TikTok effortlessly generates accurate transcriptions from audio files and integrates Microsoft Edge Cloud Text-to-Speech API for vibrant voiceovers. The program orchestrates the synthesis of videos using a structured JSON dataset, generating mesmerizing TikTok content in minutes.
pdftochat
PDFToChat is a tool that allows users to chat with their PDF documents in seconds. It is powered by Together AI and Pinecone, utilizing a tech stack including Next.js, Mixtral, M2 Bert, LangChain.js, MongoDB Atlas, Bytescale, Vercel, Clerk, and Tailwind CSS. Users can deploy the tool to Vercel or any other host by setting up Together.ai, MongoDB Atlas database, Bytescale, Clerk, and Vercel. The tool enables users to interact with PDFs through chat, with future tasks including adding features like trash icon for deleting PDFs, exploring different embedding models, implementing auto scrolling, improving replies, benchmarking accuracy, researching chunking and retrieval best practices, adding demo video, upgrading to Next.js 14, adding analytics, customizing tailwind prose, saving chats in postgres DB, compressing large PDFs, implementing custom uploader, session tracking, error handling, and support for images in PDFs.

AntSK
AntSK is an AI knowledge base/agent built with .Net8+Blazor+SemanticKernel. It features a semantic kernel for accurate natural language processing, a memory kernel for continuous learning and knowledge storage, a knowledge base for importing and querying knowledge from various document formats, a text-to-image generator integrated with StableDiffusion, GPTs generation for creating personalized GPT models, API interfaces for integrating AntSK into other applications, an open API plugin system for extending functionality, a .Net plugin system for integrating business functions, real-time information retrieval from the internet, model management for adapting and managing different models from different vendors, support for domestic models and databases for operation in a trusted environment, and planned model fine-tuning based on llamafactory.

Open_Data_QnA
Open Data QnA is a Python library that allows users to interact with their PostgreSQL or BigQuery databases in a conversational manner, without needing to write SQL queries. The library leverages Large Language Models (LLMs) to bridge the gap between human language and database queries, enabling users to ask questions in natural language and receive informative responses. It offers features such as conversational querying with multiturn support, table grouping, multi schema/dataset support, SQL generation, query refinement, natural language responses, visualizations, and extensibility. The library is built on a modular design and supports various components like Database Connectors, Vector Stores, and Agents for SQL generation, validation, debugging, descriptions, embeddings, responses, and visualizations.

vector-vein
VectorVein is a no-code AI workflow software inspired by LangChain and langflow, aiming to combine the powerful capabilities of large language models and enable users to achieve intelligent and automated daily workflows through simple drag-and-drop actions. Users can create powerful workflows without the need for programming, automating all tasks with ease. The software allows users to define inputs, outputs, and processing methods to create customized workflow processes for various tasks such as translation, mind mapping, summarizing web articles, and automatic categorization of customer reviews.

bedrock-claude-chatbot
Bedrock Claude ChatBot is a Streamlit application that provides a conversational interface for users to interact with various Large Language Models (LLMs) on Amazon Bedrock. Users can ask questions, upload documents, and receive responses from the AI assistant. The app features conversational UI, document upload, caching, chat history storage, session management, model selection, cost tracking, logging, and advanced data analytics tool integration. It can be customized using a config file and is extensible for implementing specialized tools using Docker containers and AWS Lambda. The app requires access to Amazon Bedrock Anthropic Claude Model, S3 bucket, Amazon DynamoDB, Amazon Textract, and optionally Amazon Elastic Container Registry and Amazon Athena for advanced analytics features.
MiniSearch
MiniSearch is a minimalist search engine with integrated browser-based AI. It is privacy-focused, easy to use, cross-platform, integrated, time-saving, efficient, optimized, and open-source. MiniSearch can be used for a variety of tasks, including searching the web, finding files on your computer, and getting answers to questions. It is a great tool for anyone who wants a fast, private, and easy-to-use search engine.
OrionChat
Orion is a web-based chat interface that simplifies interactions with multiple AI model providers. It provides a unified platform for chatting and exploring various large language models (LLMs) such as Ollama, OpenAI (GPT model), Cohere (Command-r models), Google (Gemini models), Anthropic (Claude models), Groq Inc., Cerebras, and SambaNova. Users can easily navigate and assess different AI models through an intuitive, user-friendly interface. Orion offers features like browser-based access, code execution with Google Gemini, text-to-speech (TTS), speech-to-text (STT), seamless integration with multiple AI models, customizable system prompts, language translation tasks, document uploads for analysis, and more. API keys are stored locally, and requests are sent directly to official providers' APIs without external proxies.
AiTextDetectionBypass
ParaGenie is a script designed to automate the process of paraphrasing articles using the undetectable.ai platform. It allows users to convert lengthy content into unique paraphrased versions by splitting the input text into manageable chunks and processing each chunk individually. The script offers features such as automated paraphrasing, multi-file support for TXT, DOCX, and PDF formats, customizable chunk splitting methods, Gmail-based registration for seamless paraphrasing, purpose-specific writing support, readability level customization, anonymity features for user privacy, error handling and recovery, and output management for easy access and organization of paraphrased content.
For similar tasks
CLIPPyX
CLIPPyX is a powerful system-wide image search and management tool that offers versatile search options to find images based on their content, text, and visual similarity. With advanced features, users can effortlessly locate desired images across their entire computer's disk(s), regardless of their location or file names. The tool utilizes OpenAI's CLIP for image embeddings and text-based search, along with OCR for extracting text from images. It also employs Voidtools Everything SDK to list paths of all images on the system. CLIPPyX server receives search queries and queries collections of image embeddings and text embeddings to return relevant images.
For similar jobs

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

daily-poetry-image
Daily Chinese ancient poetry and AI-generated images powered by Bing DALL-E-3. GitHub Action triggers the process automatically. Poetry is provided by Today's Poem API. The website is built with Astro.

exif-photo-blog
EXIF Photo Blog is a full-stack photo blog application built with Next.js, Vercel, and Postgres. It features built-in authentication, photo upload with EXIF extraction, photo organization by tag, infinite scroll, light/dark mode, automatic OG image generation, a CMD-K menu with photo search, experimental support for AI-generated descriptions, and support for Fujifilm simulations. The application is easy to deploy to Vercel with just a few clicks and can be customized with a variety of environment variables.

SillyTavern
SillyTavern is a user interface you can install on your computer (and Android phones) that allows you to interact with text generation AIs and chat/roleplay with characters you or the community create. SillyTavern is a fork of TavernAI 1.2.8 which is under more active development and has added many major features. At this point, they can be thought of as completely independent programs.

Twitter-Insight-LLM
This project enables you to fetch liked tweets from Twitter (using Selenium), save it to JSON and Excel files, and perform initial data analysis and image captions. This is part of the initial steps for a larger personal project involving Large Language Models (LLMs).

AISuperDomain
Aila Desktop Application is a powerful tool that integrates multiple leading AI models into a single desktop application. It allows users to interact with various AI models simultaneously, providing diverse responses and insights to their inquiries. With its user-friendly interface and customizable features, Aila empowers users to engage with AI seamlessly and efficiently. Whether you're a researcher, student, or professional, Aila can enhance your AI interactions and streamline your workflow.

ChatGPT-On-CS
This project is an intelligent dialogue customer service tool based on a large model, which supports access to platforms such as WeChat, Qianniu, Bilibili, Douyin Enterprise, Douyin, Doudian, Weibo chat, Xiaohongshu professional account operation, Xiaohongshu, Zhihu, etc. You can choose GPT3.5/GPT4.0/ Lazy Treasure Box (more platforms will be supported in the future), which can process text, voice and pictures, and access external resources such as operating systems and the Internet through plug-ins, and support enterprise AI applications customized based on their own knowledge base.

obs-localvocal
LocalVocal is a live-streaming AI assistant plugin for OBS that allows you to transcribe audio speech into text and perform various language processing functions on the text using AI / LLMs (Large Language Models). It's privacy-first, with all data staying on your machine, and requires no GPU, cloud costs, network, or downtime.