
LLavaImageTagger
Creates an index of images, queries a local LLM and adds tags to the image metadata
Stars: 97
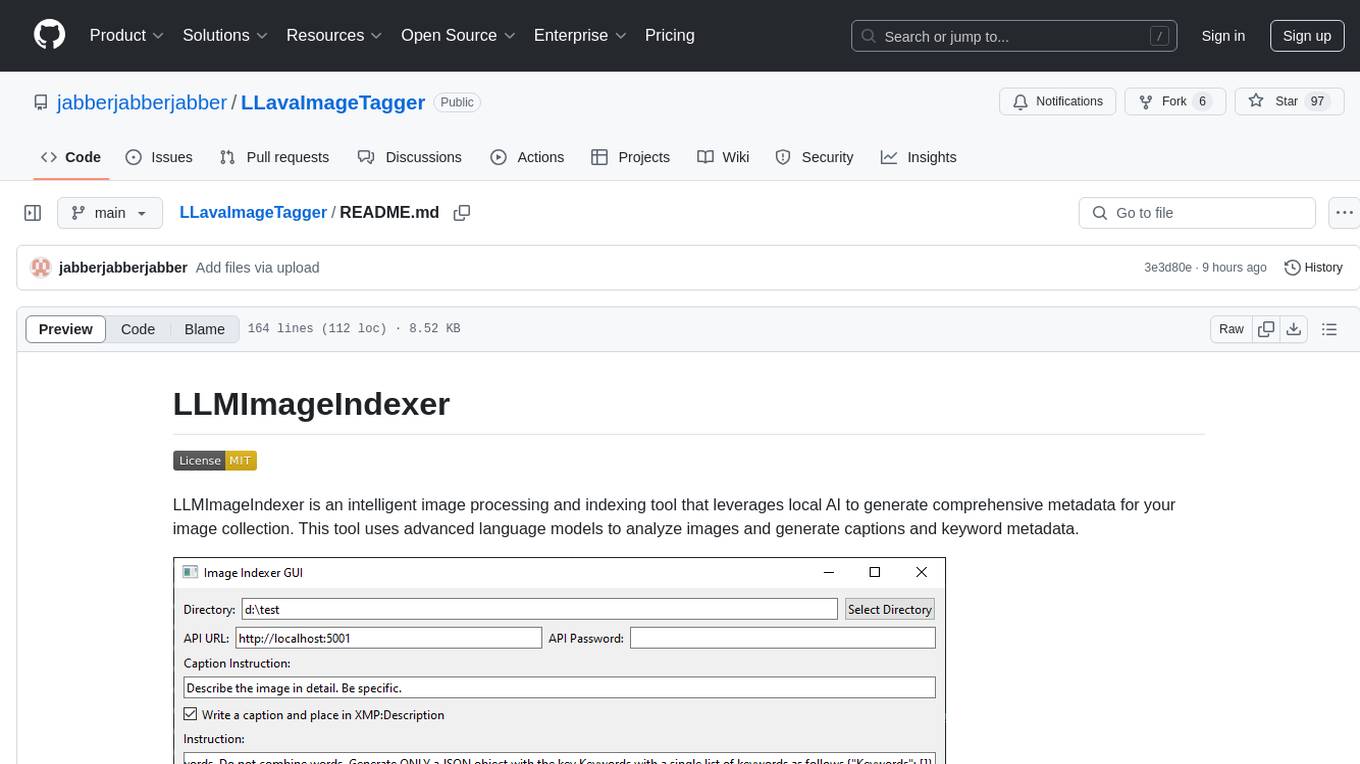
LLMImageIndexer is an intelligent image processing and indexing tool that leverages local AI to generate comprehensive metadata for your image collection. It uses advanced language models to analyze images and generate captions and keyword metadata. The tool offers features like intelligent image analysis, metadata enhancement, local processing, multi-format support, user-friendly GUI, GPU acceleration, cross-platform support, stop and start capability, and keyword post-processing. It operates directly on image file metadata, allowing users to manage files, add new files, and run the tool multiple times without reprocessing previously keyworded files. Installation instructions are provided for Windows, macOS, and Linux platforms, along with usage guidelines and configuration options.
README:
LLMImageIndexer is an intelligent image processing and indexing tool that leverages local AI to generate comprehensive metadata for your image collection. This tool uses advanced language models to analyze images and generate captions and keyword metadata.

- Intelligent Image Analysis: Utilizes a local AI model to generate a variable number of keywords and a caption for each image.
- Metadata Enhancement: Can automatically edit image metadata with generated tags.
- Local Processing: All processing is done locally on your machine.
- Multi-Format Support: Handles a wide range of image formats, including all major raw camera files.
- User-Friendly GUI: Includes a GUI and installer. Relies on Koboldcpp, a single executable, for all AI functionality.
- GPU Acceleration: Will use Apple Metal, Nvidia CUDA, or AMD (Vulkan) hardware if available to greatly speed inference.
- Cross-Platform: Supports Windows, macOS ARM, and Linux.
- Stop and Start Capability: Can stop and start without having to reprocess all the files again.
- Keyword Post-Processing: Expand keywords so all synonyms are added to every image with one of the synonyms, or deduplicate keywords by using the most frequently used synonym in place of all matching synonyms.
Before proceeding to use this script you should be aware of the following:
This tool operates directly on image file metadata. When 'pretend mode' is not checked it will write to one or more of the following fields:
-
MWG:Keywords, which may write to any of the following fields:
- DC:Subject
- IPTC: Keywords
- Composite: Keywords
-
XMP: Description, for caption
-
XMP: Status, for processing state
-
XMP:Identifier, for unique identifier
The "Status" and "Identifier" fields are used to track the processing state of images so that a database is not needed. The images may be moved between directories or even renamed, and if the "Skip images already processed but not in database" box is checked, they will not be processed again.
This means you can manage your files and add new files, and run the tool as many times as you like without worrying about reprocessing the files that were previously keyworded by the tool.
- Python 3.8 or higher
- KoboldCPP
A vision model is needed, but if you use the llmii-run.bat to open it, then the first time it is run it will download the Qwen2-VL 7B Q4_K_M gguf and F16 projector from Bartowski's repo on huggingface. If you don't want to use that, just open llmii-no-kobold.bat instead and open Koboldcpp.exe and load whatever model you like.
-
Clone the repository or download the ZIP file and extract it.
-
Install Python for Windows.
-
Download KoboldCPP.exe and place it in the LlavaImageTagger folder. If it is not named KoboldCPP.exe, rename it to KoboldCPP.exe
-
Run
llmii-run.batand wait exiftool to install. When it is complete you must start the file again. If you called it from a terminal window you will need to close the windows and reopen it. It will then create a python environment and download the model weights. The download is quite large (6GB) and there is no progress bar, but it only needs to do this once. Once it is done KoboldCPP will start and one of the terminal windows will sayPlease connect to custom endpoint at http://localhost:5001and then it is ready.
-
Clone the repository or download the ZIP file and extract it.
-
Install Python 3.7 or higher if not already installed. You can use Homebrew:
brew install python -
Install ExifTool:
brew install exiftool -
Download KoboldCPP for macOS and place it in the LLMImageIndexer folder.
-
Open a terminal in the LLMImageIndexer folder and run:
xattr -cr koboldcpp-mac-arm64 chmod +x koboldcpp-mac-arm64 ./llmii-run.sh
-
Clone the repository or download and extract the ZIP file.
-
Install Python 3.7 or higher if not already installed. Use your distribution's package manager, for example on Ubuntu:
sudo apt-get update sudo apt-get install python3 python3-pip -
Install ExifTool. On Ubuntu:
sudo apt-get install libimage-exiftool-perl -
Download the appropriate KoboldCPP binary for your Linux distribution from KoboldCPP releases and place it in the LLMImageIndexer folder.
-
Open a terminal in the LLMImageIndexer folder and run:
chmod +x koboldcpp-linux-x64 ./llmii-run.sh
For all platforms, the script will set up the Python environment, install dependencies, and download necessary model weights (6GB total). This initial setup is performed only once and will take a few minutes depending on your download speed.
-
Launch the LLMImageIndexer GUI:
- On Windows: Run
llmii-run.bat - On macOS/Linux: Run
python3 llmii-gui.py
- On Windows: Run
-
Ensure KoboldCPP is running. Wait until you see the following message in the KoboldCPP window:
Please connect to custom endpoint at http://localhost:5001 -
Configure the indexing settings in the GUI:
- Select the target image directory
- Set the API URL (default: http://localhost:5001)
- Choose metadata tags to generate (keywords, descriptions)
- Set additional options (crawl subdirectories, backup files, etc.)
-
Click "Run Image Indexer" to start the process.
-
Monitor the progress in the output area of the GUI.
- Directory: Target image directory (includes subdirectories by default)
- API URL: KoboldCPP API endpoint (change if running on another machine)
- API Password: Set if required by your KoboldCPP setup
- Caption: Have the LLM describe the image and set it in XMP:Description (doubles processing time)
- GenTokens: Amount of tokens for the LLM to generate
- Skip processed files not in database: Will not attempt to reprocess files with a UUID and keywords even if they are not in the llmii.json database
- Reprocess failed: If any files failed in the last round, it will try to process them again
- Reprocess ALL: The files that are processed already are stored in a database and skipped if you resume later, this will do them all over again
- Don't crawl subdirectories: Disable scanning of subdirectories
- Don't make backups before writing: Skip creating backup files (NOTE: this applies to processing and post-processing; if you enable post processing and leave this unchecked it will make a second backup!)
- Pretend mode: Simulate processing without writing to files or database
- Skip processing: If you want to use the keyword processing and don't want it to check every image in the directory before starting, check this box
- Keywords: Choose to clear and write new keywords or update existing ones
- Post processing keywords: Keep keywords as generated, Expand keywords by applying all synonyms to matching keywords, or Dedepe keywords by replacing matching synonyms with most frequent synonym; these option take place after the indexer has completed unless the 'skip processing' box is checked
Consult the wiki for more information and troubleshooting steps.
Contributions are welcome! Please feel free to submit a Pull Request.
This project is licensed under the MIT License - see the LICENSE file for details.
- ExifTool for metadata manipulation
- KoboldCPP for local AI processing
- PyQt6 for the GUI framework
- Fix Busted JSON and Json Repair for help with mangled JSON parsing
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for LLavaImageTagger
Similar Open Source Tools
LLavaImageTagger
LLMImageIndexer is an intelligent image processing and indexing tool that leverages local AI to generate comprehensive metadata for your image collection. It uses advanced language models to analyze images and generate captions and keyword metadata. The tool offers features like intelligent image analysis, metadata enhancement, local processing, multi-format support, user-friendly GUI, GPU acceleration, cross-platform support, stop and start capability, and keyword post-processing. It operates directly on image file metadata, allowing users to manage files, add new files, and run the tool multiple times without reprocessing previously keyworded files. Installation instructions are provided for Windows, macOS, and Linux platforms, along with usage guidelines and configuration options.
ImageIndexer
LLMII is a tool that uses a local AI model to label metadata and index images without relying on cloud services or remote APIs. It runs a visual language model on your computer to generate captions and keywords for images, enhancing their metadata for indexing, searching, and organization. The tool can be run multiple times on the same image files, allowing for adding new data, regenerating data, and discovering files with issues. It supports various image formats, offers a user-friendly GUI, and can utilize GPU acceleration for faster processing. LLMII requires Python 3.8 or higher and operates directly on image file metadata fields like MWG:Keyword and XMP:Identifier.
your-source-to-prompt.html
Your Source to Prompt is a single HTML file tool that allows users to easily select code files and combine them into a single text output. It runs entirely in the browser, ensuring local and secure operation without any external dependencies. The tool offers features like preset management, efficient file selection, context size awareness, hierarchical structure preview, minification, and user-friendly UI with dark mode. It aims to simplify the process of preparing code for Large Language Models (LLMs) by providing a well-structured prompt context.
Local-Multimodal-AI-Chat
Local Multimodal AI Chat is a multimodal chat application that integrates various AI models to manage audio, images, and PDFs seamlessly within a single interface. It offers local model processing with Ollama for data privacy, integration with OpenAI API for broader AI capabilities, audio chatting with Whisper AI for accurate voice interpretation, and PDF chatting with Chroma DB for efficient PDF interactions. The application is designed for AI enthusiasts and developers seeking a comprehensive solution for multimodal AI technologies.

CodebaseToPrompt
CodebaseToPrompt is a simple tool that converts a local directory into a structured prompt for Large Language Models (LLMs). It allows users to select specific files for code review, analysis, or documentation by exploring and filtering through the file tree in a browser-based interface. The tool generates a formatted output that can be directly used with AI tools, provides token count estimates, and supports local storage for saving selections. Users can easily copy the selected files in the desired format for further use.
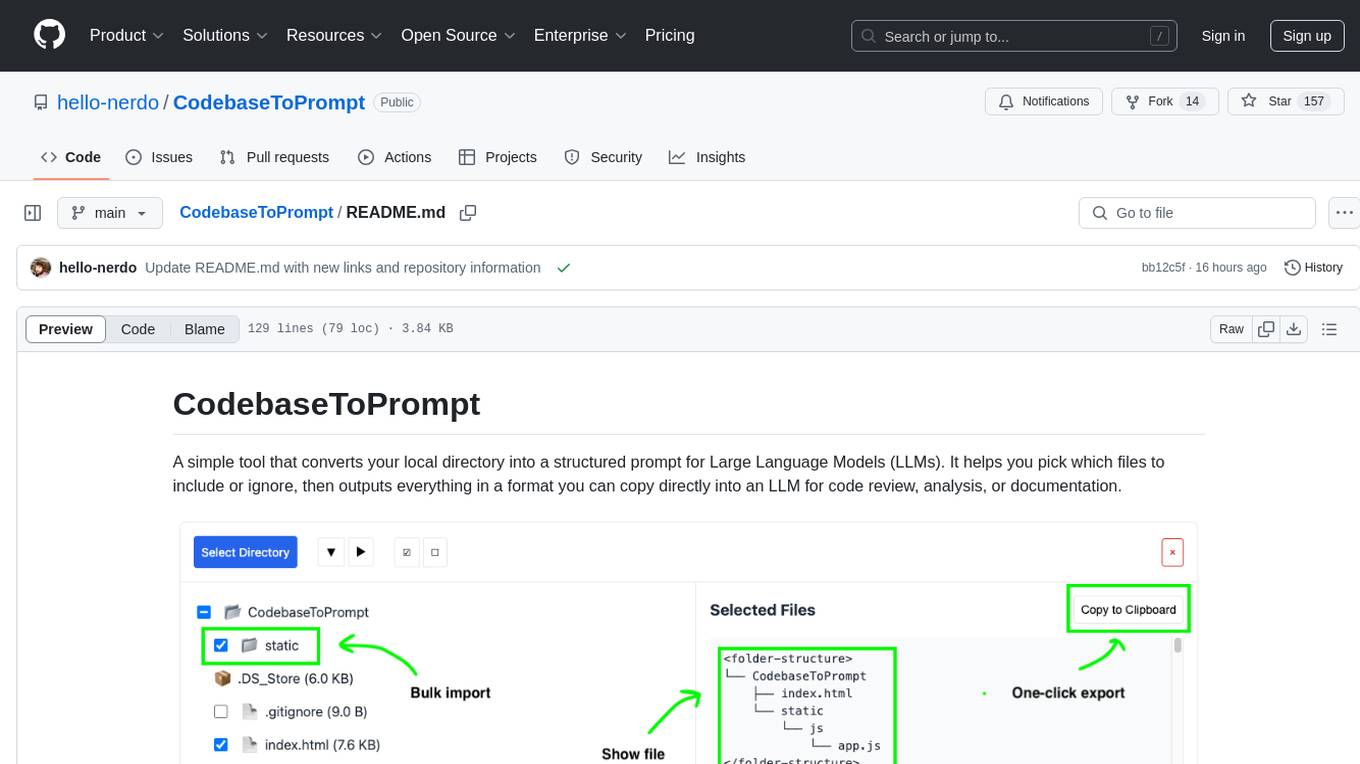
CodebaseToPrompt
CodebaseToPrompt is a tool that converts a local directory into a structured prompt for Large Language Models (LLMs). It allows users to select specific files for code review, analysis, or documentation by exploring and filtering through the file tree in an interactive interface. The tool generates a formatted output that can be directly used with LLMs, estimates token count, and supports flexible text selection. Users can deploy the tool using Docker for self-contained usage and can contribute to the project by opening issues or submitting pull requests.

crawlee-python
Crawlee-python is a web scraping and browser automation library that covers crawling and scraping end-to-end, helping users build reliable scrapers fast. It allows users to crawl the web for links, scrape data, and store it in machine-readable formats without worrying about technical details. With rich configuration options, users can customize almost any aspect of Crawlee to suit their project's needs.

CLIPPyX
CLIPPyX is a powerful system-wide image search and management tool that offers versatile search options to find images based on their content, text, and visual similarity. With advanced features, users can effortlessly locate desired images across their entire computer's disk(s), regardless of their location or file names. The tool utilizes OpenAI's CLIP for image embeddings and text-based search, along with OCR for extracting text from images. It also employs Voidtools Everything SDK to list paths of all images on the system. CLIPPyX server receives search queries and queries collections of image embeddings and text embeddings to return relevant images.
AIOLists
AIOLists is a stateless open source list management addon for Stremio that allows users to import and manage lists from various sources in one place. It offers unified search, metadata customization, Trakt integration, MDBList integration, external lists import, list sorting, customization options, watchlist updates, RPDB support, genre filtering, discovery lists, and shareable configurations. The addon aims to enhance the list management experience for Stremio users by providing a comprehensive set of features and functionalities.
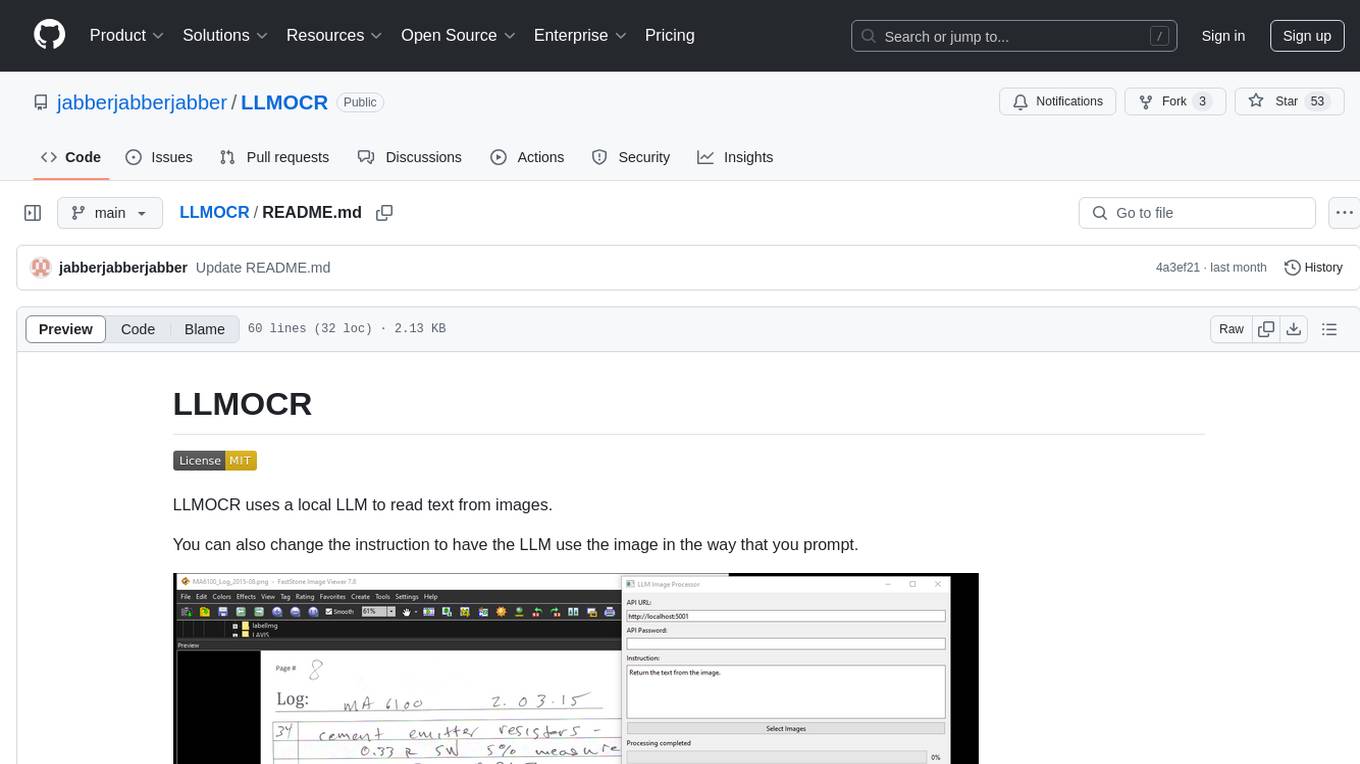
LLMOCR
LLMOCR is a tool that utilizes a local Large Language Model (LLM) to extract text from images. It offers a user-friendly GUI and supports GPU acceleration for faster inference. The tool is cross-platform, compatible with Windows, macOS ARM, and Linux. Users can prompt the LLM to process images in a customized way. The processing is done locally on the user's machine, ensuring data privacy and security. LLMOCR requires Python 3.8 or higher and KoboldCPP for installation and operation.
burpference
Burpference is an open-source extension designed to capture in-scope HTTP requests and responses from Burp's proxy history and send them to a remote LLM API in JSON format. It automates response capture, integrates with APIs, optimizes resource usage, provides color-coded findings visualization, offers comprehensive logging, supports native Burp reporting, and allows flexible configuration. Users can customize system prompts, API keys, and remote hosts, and host models locally to prevent high inference costs. The tool is ideal for offensive web application engagements to surface findings and vulnerabilities.
CyberScraper-2077
CyberScraper 2077 is an advanced web scraping tool powered by AI, designed to extract data from websites with precision and style. It offers a user-friendly interface, supports multiple data export formats, operates in stealth mode to avoid detection, and promises lightning-fast scraping. The tool respects ethical scraping practices, including robots.txt and site policies. With upcoming features like proxy support and page navigation, CyberScraper 2077 is a futuristic solution for data extraction in the digital realm.
aiCoder
aiCoder is an AI-powered tool designed to streamline the coding process by automating repetitive tasks, providing intelligent code suggestions, and facilitating the integration of new features into existing codebases. It offers a chat interface for natural language interactions, methods and stubs lists for code modification, and settings customization for project-specific prompts. Users can leverage aiCoder to enhance code quality, focus on higher-level design, and save time during development.

Pandrator
Pandrator is a GUI tool for generating audiobooks and dubbing using voice cloning and AI. It transforms text, PDF, EPUB, and SRT files into spoken audio in multiple languages. It leverages XTTS, Silero, and VoiceCraft models for text-to-speech conversion and voice cloning, with additional features like LLM-based text preprocessing and NISQA for audio quality evaluation. The tool aims to be user-friendly with a one-click installer and a graphical interface.

Open_Data_QnA
Open Data QnA is a Python library that allows users to interact with their PostgreSQL or BigQuery databases in a conversational manner, without needing to write SQL queries. The library leverages Large Language Models (LLMs) to bridge the gap between human language and database queries, enabling users to ask questions in natural language and receive informative responses. It offers features such as conversational querying with multiturn support, table grouping, multi schema/dataset support, SQL generation, query refinement, natural language responses, visualizations, and extensibility. The library is built on a modular design and supports various components like Database Connectors, Vector Stores, and Agents for SQL generation, validation, debugging, descriptions, embeddings, responses, and visualizations.
SwarmUI
SwarmUI is a modular stable diffusion web-user-interface designed to make powertools easily accessible, high performance, and extensible. It is in Beta status, offering a primary Generate tab for beginners and a Comfy Workflow tab for advanced users. The tool aims to become a full-featured one-stop-shop for all things Stable Diffusion, with plans for better mobile browser support, detailed 'Current Model' display, dynamic tab shifting, LLM-assisted prompting, and convenient direct distribution as an Electron app.
For similar tasks

HPT
Hyper-Pretrained Transformers (HPT) is a novel multimodal LLM framework from HyperGAI, trained for vision-language models capable of understanding both textual and visual inputs. The repository contains the open-source implementation of inference code to reproduce the evaluation results of HPT Air on different benchmarks. HPT has achieved competitive results with state-of-the-art models on various multimodal LLM benchmarks. It offers models like HPT 1.5 Air and HPT 1.0 Air, providing efficient solutions for vision-and-language tasks.

learnopencv
LearnOpenCV is a repository containing code for Computer Vision, Deep learning, and AI research articles shared on the blog LearnOpenCV.com. It serves as a resource for individuals looking to enhance their expertise in AI through various courses offered by OpenCV. The repository includes a wide range of topics such as image inpainting, instance segmentation, robotics, deep learning models, and more, providing practical implementations and code examples for readers to explore and learn from.

spark-free-api
Spark AI Free 服务 provides high-speed streaming output, multi-turn dialogue support, AI drawing support, long document interpretation, and image parsing. It offers zero-configuration deployment, multi-token support, and automatic session trace cleaning. It is fully compatible with the ChatGPT interface. The repository includes multiple free-api projects for various AI services. Users can access the API for tasks such as chat completions, AI drawing, document interpretation, image analysis, and ssoSessionId live checking. The project also provides guidelines for deployment using Docker, Docker-compose, Render, Vercel, and native deployment methods. It recommends using custom clients for faster and simpler access to the free-api series projects.

mlx-vlm
MLX-VLM is a package designed for running Vision LLMs on Mac systems using MLX. It provides a convenient way to install and utilize the package for processing large language models related to vision tasks. The tool simplifies the process of running LLMs on Mac computers, offering a seamless experience for users interested in leveraging MLX for vision-related projects.

clarifai-python-grpc
This is the official Clarifai gRPC Python client for interacting with their recognition API. Clarifai offers a platform for data scientists, developers, researchers, and enterprises to utilize artificial intelligence for image, video, and text analysis through computer vision and natural language processing. The client allows users to authenticate, predict concepts in images, and access various functionalities provided by the Clarifai API. It follows a versioning scheme that aligns with the backend API updates and includes specific instructions for installation and troubleshooting. Users can explore the Clarifai demo, sign up for an account, and refer to the documentation for detailed information.

horde-worker-reGen
This repository provides the latest implementation for the AI Horde Worker, allowing users to utilize their graphics card(s) to generate, post-process, or analyze images for others. It offers a platform where users can create images and earn 'kudos' in return, granting priority for their own image generations. The repository includes important details for setup, recommendations for system configurations, instructions for installation on Windows and Linux, basic usage guidelines, and information on updating the AI Horde Worker. Users can also run the worker with multiple GPUs and receive notifications for updates through Discord. Additionally, the repository contains models that are licensed under the CreativeML OpenRAIL License.

geospy
Geospy is a Python tool that utilizes Graylark's AI-powered geolocation service to determine the location where photos were taken. It allows users to analyze images and retrieve information such as country, city, explanation, coordinates, and Google Maps links. The tool provides a seamless way to integrate geolocation services into various projects and applications.

Awesome-Colorful-LLM
Awesome-Colorful-LLM is a meticulously assembled anthology of vibrant multimodal research focusing on advancements propelled by large language models (LLMs) in domains such as Vision, Audio, Agent, Robotics, and Fundamental Sciences like Mathematics. The repository contains curated collections of works, datasets, benchmarks, projects, and tools related to LLMs and multimodal learning. It serves as a comprehensive resource for researchers and practitioners interested in exploring the intersection of language models and various modalities for tasks like image understanding, video pretraining, 3D modeling, document understanding, audio analysis, agent learning, robotic applications, and mathematical research.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.