Best AI tools for< Analyze Images >
32 - AI tool Sites
ImageBind
ImageBind by Meta AI is a groundbreaking AI tool that revolutionizes the field of computer vision by introducing a new way to 'link' AI across multiple senses. It is the first AI model capable of binding data from six different modalities simultaneously, including images, video, audio, text, depth, thermal, and inertial measurement units (IMUs). By recognizing relationships between these modalities, ImageBind enables machines to analyze various forms of information together, advancing AI capabilities significantly.
Raman Labs
Raman Labs is an AI tool that offers dedicated modules for computer vision-based tasks. It allows users to integrate machine learning functionality into their existing applications with just 2 lines of code, ensuring real-time performance even with high-resolution data on consumer-grade CPUs. The tool provides a clean and minimalistic API for easy integration, robust to large scale and resolution variations, versatile to run on various platforms, and adaptive to scale with the computing power of the system.

BuildAI.Space
BuildAI.Space is an AI application that allows users to create personalized AI-powered web apps without the need for technical skills. Users can pick and customize AI tools, upload their data, and design the app to match their brand. The platform offers a variety of AI tools for different use cases, such as nutrition, legal advice, lead generation, SEO optimization, and personalized planners. With features like Magic Builder for customization and AI Credits for advanced functionalities, BuildAI.Space empowers users to monetize their apps and engage with their audience effectively.

Visionati
Visionati is an AI-powered platform that provides image captioning, descriptions, and analysis for everyone. It offers a comprehensive toolkit for visual analysis, including intelligent tagging, content filtering, and integration with various AI technologies. Visionati helps transform complex visuals into clear, actionable insights for digital marketing, storytelling, and data analysis. Users can easily create an account, access seamless integration, and leverage advanced analysis capabilities through the Visionati API.
SwitchLight
SwitchLight is an AI tool developed by a dedicated team of AI researchers located in Seoul, South Korea. It uses state-of-the-art AI technology to analyze and composite images with optimal lighting and backgrounds. The tool offers features like Copy Light for pasting lighting from portrait images, HDRI Relight for illuminating images using HDRIs, and PBR Material Acquisition for extracting maps for 3D softwares. Users can also add light to their own apps using the SwitchLight API. The tool supports various image formats and recommends using portrait-oriented images for best results.
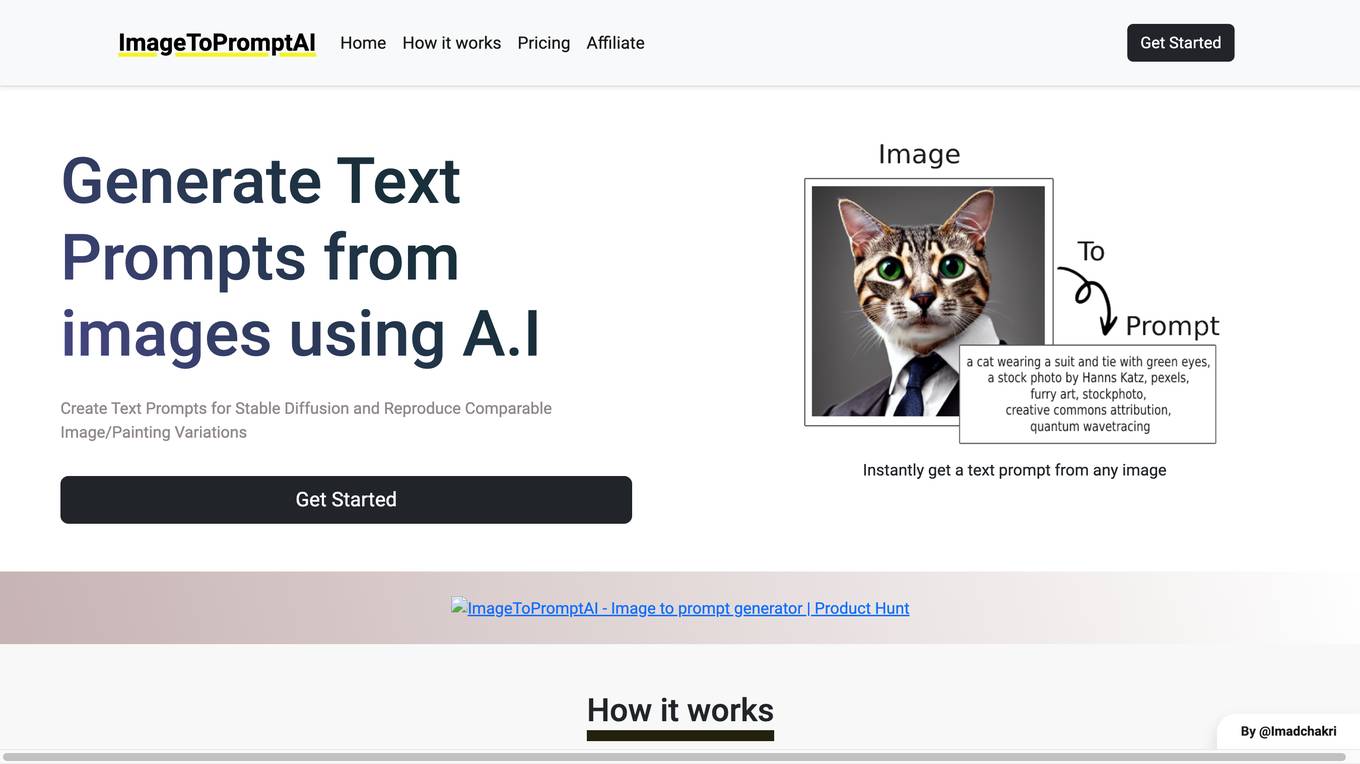
ImageToPromptAI
ImageToPromptAI is an AI tool that generates text prompts from images. Users can upload images and receive text prompts instantly. The tool aims to assist in creating stable diffusion and reproducing comparable image/painting variations. With a user-friendly interface, ImageToPromptAI offers different pricing tiers based on the number of images users want to transform into text prompts. The tool does not require any subscriptions, allowing users to pay only for what they need. Overall, ImageToPromptAI simplifies the process of generating text prompts from images using artificial intelligence.

SceneXplain
SceneXplain is a cutting-edge AI tool that specializes in generating descriptive captions for images and summarizing videos. It leverages advanced artificial intelligence algorithms to analyze visual content and provide accurate and concise textual descriptions. With SceneXplain, users can easily create engaging captions for their images and obtain quick summaries of lengthy videos. The tool is designed to streamline the process of content creation and enhance the accessibility of visual media for a wide range of applications.
Image to Caption Generator
The AI-Powered Image to Caption Generator is a revolutionary tool that utilizes artificial intelligence to analyze images and generate engaging captions tailored to each image. By recognizing key objects, scenes, and emotional tones in the image, the tool crafts captivating narratives that spark conversation and boost engagement. Users can save time, maintain brand consistency, and stay ahead of social media marketing trends with this innovative AI application.

WriteText.ai
WriteText.ai is an AI-powered product description generator designed to help e-commerce businesses create high-quality, SEO-optimized product descriptions quickly and efficiently. It offers a range of features to enhance content relevance, optimize keyword usage, and streamline the content creation workflow. With WriteText.ai, users can generate product descriptions in multiple languages, analyze product images for contextual text, and seamlessly publish content directly to their e-commerce platform.
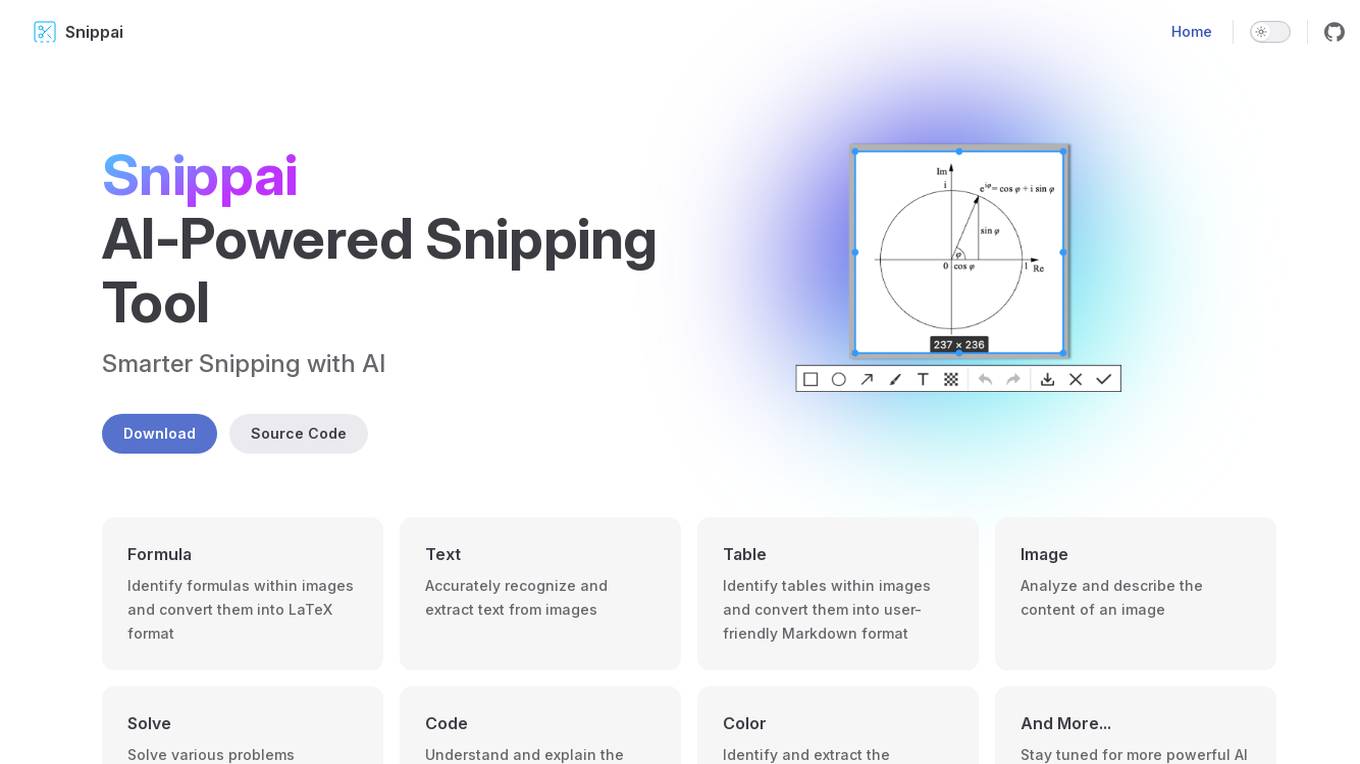
Snippai
Snippai is an AI-powered snipping tool that offers advanced features such as identifying formulas, extracting text, recognizing tables, analyzing images, solving problems, understanding code snippets, and extracting colors. It leverages artificial intelligence to enhance the snipping experience and provide users with accurate and efficient results.
CapGen
CapGen is an AI-powered image caption generator that helps users create engaging captions for their social media posts. By leveraging the power of Artificial Intelligence, CapGen generates unique captions for uploaded images, enhancing the visual storytelling experience for users. The application caters to a wide range of users, from freelance writers and photographers to social media influencers and marketing teams, offering a user-friendly platform to boost online engagement and brand reach.
Vansh
Vansh is an AI tool developed by a tech enthusiast. It specializes in Vision AI and Vispark technologies. The tool offers advanced features for image recognition, object detection, and visual data analysis. With a user-friendly interface, Vansh caters to both beginners and experts in the field of artificial intelligence.

AI Interview Copilot
AI Interview Copilot is the ultimate AI-powered job interview assistant that provides voice transcription, image and screenshot recognition, easy management, accurate answers, and algorithm problem-solving capabilities. It supports 57 languages and offers seamless integration with various devices for a stress-free interview experience. The application aims to assist users in tackling technical interview questions, providing quick responses, and generating code snippets in real-time.
SeekTop.ai
SeekTop.ai is an AI tools directory that offers a curated list of the best AI solutions for various tasks. It features a wide range of AI-powered tools and services catering to different needs, from website building and video generation to content creation and networking. SeekTop.ai aims to provide users with innovative and efficient AI tools to enhance their productivity and creativity.

JENOVA
JENOVA is an AI tool that provides users with access to the best intelligence and expertise by synthesizing advanced AI models and tools into one unified AI experience. It ensures users always get the best answers by routing queries to the most optimal model for their needs. JENOVA offers an expanding suite of useful tools and capabilities, including document reading for various formats, image comprehension powered by multi-modal AI models, and web search for up-to-date information. Privacy is a priority, as conversations and data are never used for training and are securely stored in a protected database.
PackPack
PackPack is an AI-driven bookmarking tool that allows users to save various types of content with just one click. It offers features like saving articles, social media posts, e-commerce products, videos, and audios, as well as providing relevant search results and AI-powered functions for summarizing content, analyzing images, and recognizing subtitles. Users can organize their saved content into collections and easily share them. PackPack is trusted by industry leaders and offers a distraction-free reading experience with no ads or pop-ups.
Undressing AI
Undressing AI is a cutting-edge application that utilizes AI technology to remove clothes from photos, generating realistic nude images. Users can upload a photo, select processing mode, and quickly obtain a nude image. The app prioritizes safety and ethical use, implementing strict privacy measures to secure uploaded images. Undressing AI offers various pricing plans, from a free basic plan to premium options, providing customization options for body type, age, and image quality. The application is user-friendly, accessible from any device with internet connection, and employs advanced AI technology for accurate results.
Radiology Business
Radiology Business is an AI tool designed to provide insights and solutions for professionals in the radiology field. The platform covers a wide range of topics including management, imaging, technology, and conferences. It offers news, analysis, and resources to help radiologists stay informed and make informed decisions. Radiology Business aims to leverage artificial intelligence to improve workflow efficiency and enhance the overall experience in the radiology ecosystem.
Neurahub
Neurahub is a single generative AI suite designed for daily creation tasks. It offers a central hub with essential and task-specific AI tools for tailored content creation and thinking tasks. Users can access leading AI tools, create and analyze various content and media effortlessly in seconds, generate unlimited templates and chatbot personas, and engage with a wider audience in over 30 languages. The platform also ensures data security with 256-bit SSL encryption and allows collaboration among team members to maximize AI benefits.
DigiCord
DigiCord is an AI-powered Discord bot that provides access to a wide range of large language models (LLMs) such as GPT-3.5, GPT-4, Claude, and more. It allows users to converse with AI, generate content, analyze images and data, and perform various tasks, all within the Discord server environment. DigiCord aims to democratize AI tools and technologies, making them more accessible, cost-efficient, and user-friendly for a diverse range of users, from students and digital artists to software engineers and entrepreneurs.
ImageToText.AI
ImageToText.AI is an AI-powered tool that allows users to convert images into actionable text using advanced AI technology. Users can describe image content, generate prompts, detect code, and convert to markdown in seconds. The tool offers powerful AI image analysis features such as image description, prompt generation, code recognition, and markdown conversion. With simple and transparent pricing options, users can choose between a one-time purchase or a monthly subscription plan. ImageToText.AI aims to provide users with a seamless experience in transforming images into text with the help of AI technology.
Xamun
Xamun is an AI-augmented software development platform that brings together the latest AI technologies, expert development partners, and best practices in a single platform. It offers visibility, quality, and speed throughout the entire software development lifecycle. Users can design custom software, build automated workflows, generate product ideas, and benefit from AI-powered solutions for various industries and use cases.

Molmo AI
Molmo AI is a powerful, open-source multimodal AI model revolutionizing visual understanding. It helps developers easily build tools that can understand images and interact with the world in useful ways. Molmo AI offers exceptional image understanding, efficient data usage, open and accessible features, on-device compatibility, and a new era in multimodal AI development. It closes the gap between open and closed AI models, empowers the AI community with open access, and efficiently utilizes data for superior performance.

Mixflow.AI
Mixflow.AI is an AI-powered platform designed to help users manage and enhance their files with the assistance of artificial intelligence. It offers an infinite canvas for creativity and organization, allowing users to effortlessly drop and arrange various file types. The platform integrates the latest AI models to provide features such as document enhancement, image insights, video improvements, audio analysis, and more. Mixflow.AI aims to streamline workflows, boost productivity, and revolutionize content creation through AI-driven solutions.
Tengr.ai - Image AI
Tengr.ai is an AI tool that specializes in image analysis and recognition. It uses advanced artificial intelligence algorithms to analyze images and extract valuable insights. The tool is designed to help businesses and individuals automate image processing tasks, improve accuracy, and save time. With Tengr.ai, users can easily classify images, detect objects, recognize text, and perform various image-related tasks with high precision.
CellProfiler
CellProfiler is an AI tool designed for biologists to analyze and process images automatically. It allows users to load image-processing modules, adjust settings, measure phenotypes, export data, and classify phenotypes using machine learning. The application is user-friendly and provides a seamless experience for biologists to analyze complex or subtle phenotypes in their images.
Joseph Chet Redmon's Computer Vision Platform
The website is a platform maintained by Joseph Chet Redmon, a graduate student working on computer vision. It features information on his projects, publications, talks, and teaching activities. The site also includes details about the Darknet Neural Network Framework, tactics in Coq, and research work. Visitors can learn about computer vision, object recognition, and visual question answering through the resources provided on the site.
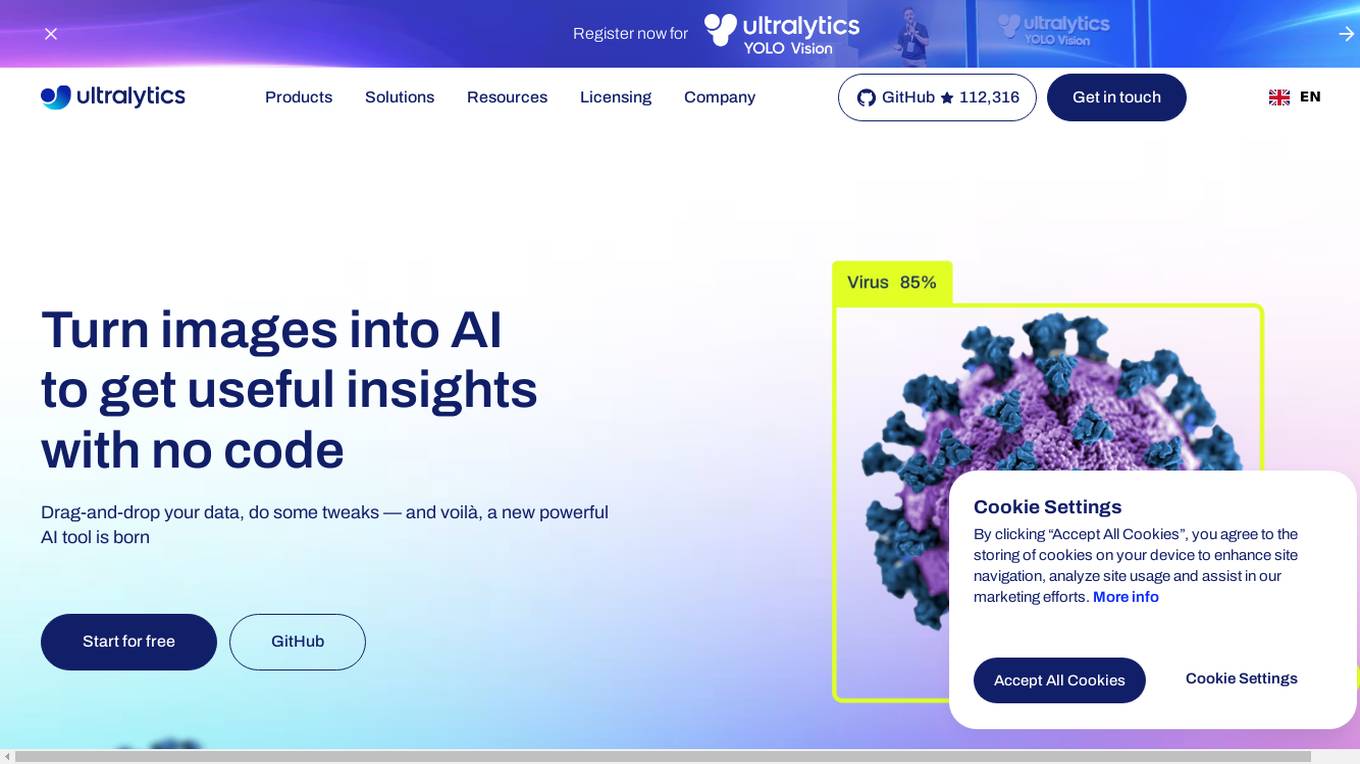
Ultralytics
Ultralytics is an AI tool that revolutionizes the world of Vision AI by enabling users to easily turn images into AI to get useful insights without writing any code. It offers a drag-and-drop interface for data input, model training, and deployment, making it accessible for startups, enterprises, data scientists, ML engineers, hobbyists, researchers, and academics. Ultralytics YOLO, the flagship tool, allows users to train machine learning models in seconds, select from pre-built models, test models on mobile devices, and deploy custom models to various formats. The tool is powered by Ultralytics Python package and is open-source, with a focus on computer vision, object detection, and image classification.
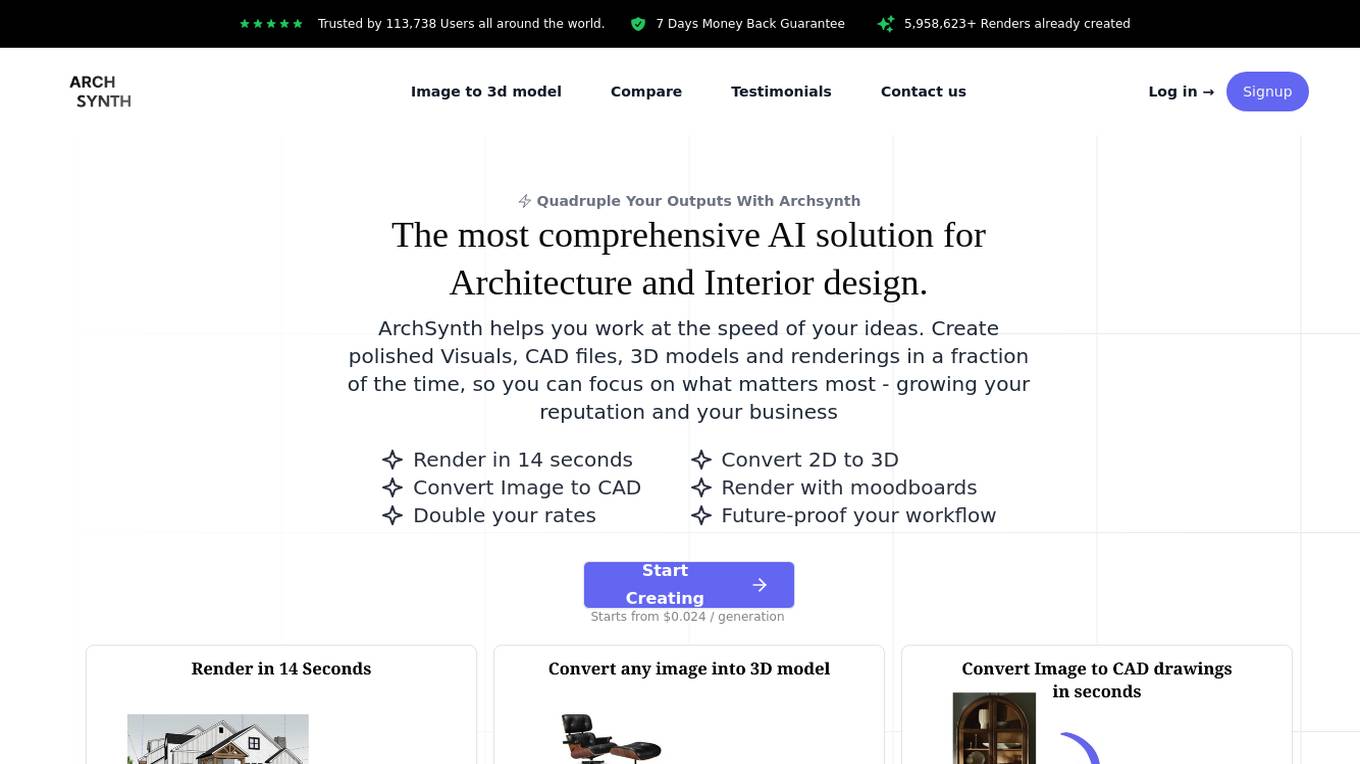
Archsynth
Archsynth is an AI-powered application that revolutionizes the architecture and interior design industry by converting sketches into high-quality renders in seconds. With features like sketch to render, text to image, background removal, and AI assistant analysis, Archsynth offers a comprehensive solution for creating polished visuals, CAD files, 3D models, and renderings efficiently. Trusted by over 113,738 users worldwide, Archsynth aims to enhance efficiency, image quality, and workflow while providing substantial cost savings to users.
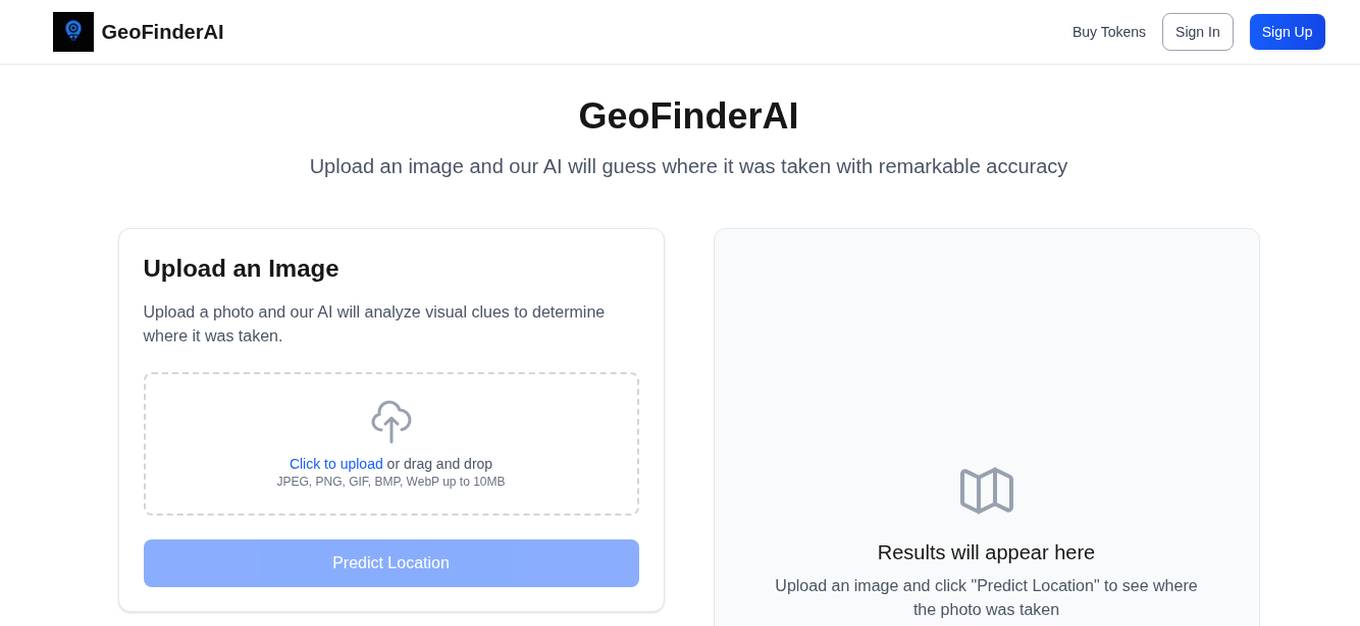
GeoFinderAI
GeoFinderAI is an AI-powered location detection tool that analyzes images to determine the location where they were taken. Users can upload photos and receive precise coordinates of the location along with a confidence radius. The tool uses visual clues such as architecture, landscapes, and signage to provide accurate results. GeoFinderAI offers 5 free uses for new users, with subsequent analyses costing 10 tokens each.
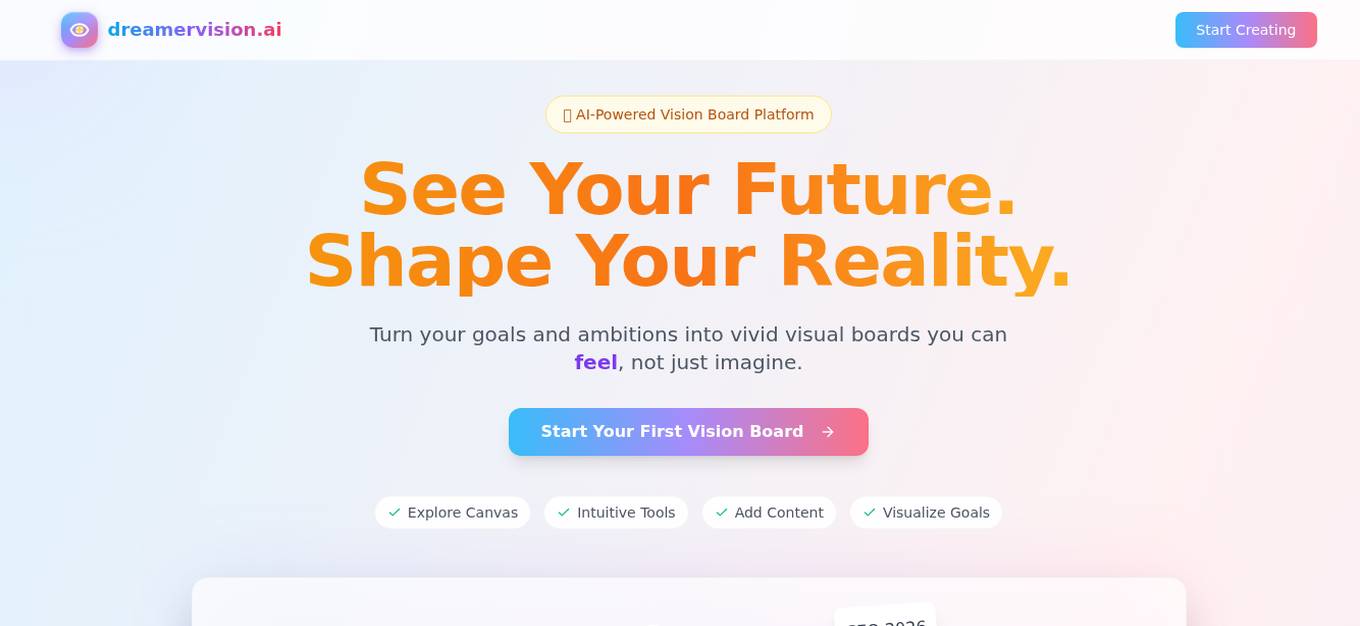
Dreamervision.ai
Dreamervision.ai is an innovative AI tool that utilizes advanced machine learning algorithms to analyze and interpret images and videos. The tool is designed to provide users with valuable insights and information based on visual content, enabling them to make informed decisions and enhance their understanding of the world around them. With its cutting-edge technology, Dreamervision.ai offers a seamless and efficient way to extract meaningful data from visual media, making it a valuable asset for professionals in various industries.
The Imaging Wire
The Imaging Wire is an AI-powered healthcare platform that provides the latest news and insights in medical imaging, radiology, and artificial intelligence applications in healthcare. The platform offers in-depth coverage of industry trends, research findings, and technological advancements, helping healthcare professionals stay informed and up-to-date with the rapidly evolving field of medical imaging. With a focus on AI-driven innovations and their impact on healthcare delivery, The Imaging Wire serves as a valuable resource for radiologists, imaging leaders, and healthcare providers seeking to enhance patient care and outcomes.
34 - Open Source AI Tools

HPT
Hyper-Pretrained Transformers (HPT) is a novel multimodal LLM framework from HyperGAI, trained for vision-language models capable of understanding both textual and visual inputs. The repository contains the open-source implementation of inference code to reproduce the evaluation results of HPT Air on different benchmarks. HPT has achieved competitive results with state-of-the-art models on various multimodal LLM benchmarks. It offers models like HPT 1.5 Air and HPT 1.0 Air, providing efficient solutions for vision-and-language tasks.

learnopencv
LearnOpenCV is a repository containing code for Computer Vision, Deep learning, and AI research articles shared on the blog LearnOpenCV.com. It serves as a resource for individuals looking to enhance their expertise in AI through various courses offered by OpenCV. The repository includes a wide range of topics such as image inpainting, instance segmentation, robotics, deep learning models, and more, providing practical implementations and code examples for readers to explore and learn from.

spark-free-api
Spark AI Free 服务 provides high-speed streaming output, multi-turn dialogue support, AI drawing support, long document interpretation, and image parsing. It offers zero-configuration deployment, multi-token support, and automatic session trace cleaning. It is fully compatible with the ChatGPT interface. The repository includes multiple free-api projects for various AI services. Users can access the API for tasks such as chat completions, AI drawing, document interpretation, image analysis, and ssoSessionId live checking. The project also provides guidelines for deployment using Docker, Docker-compose, Render, Vercel, and native deployment methods. It recommends using custom clients for faster and simpler access to the free-api series projects.

mlx-vlm
MLX-VLM is a package designed for running Vision LLMs on Mac systems using MLX. It provides a convenient way to install and utilize the package for processing large language models related to vision tasks. The tool simplifies the process of running LLMs on Mac computers, offering a seamless experience for users interested in leveraging MLX for vision-related projects.

clarifai-python-grpc
This is the official Clarifai gRPC Python client for interacting with their recognition API. Clarifai offers a platform for data scientists, developers, researchers, and enterprises to utilize artificial intelligence for image, video, and text analysis through computer vision and natural language processing. The client allows users to authenticate, predict concepts in images, and access various functionalities provided by the Clarifai API. It follows a versioning scheme that aligns with the backend API updates and includes specific instructions for installation and troubleshooting. Users can explore the Clarifai demo, sign up for an account, and refer to the documentation for detailed information.

horde-worker-reGen
This repository provides the latest implementation for the AI Horde Worker, allowing users to utilize their graphics card(s) to generate, post-process, or analyze images for others. It offers a platform where users can create images and earn 'kudos' in return, granting priority for their own image generations. The repository includes important details for setup, recommendations for system configurations, instructions for installation on Windows and Linux, basic usage guidelines, and information on updating the AI Horde Worker. Users can also run the worker with multiple GPUs and receive notifications for updates through Discord. Additionally, the repository contains models that are licensed under the CreativeML OpenRAIL License.

geospy
Geospy is a Python tool that utilizes Graylark's AI-powered geolocation service to determine the location where photos were taken. It allows users to analyze images and retrieve information such as country, city, explanation, coordinates, and Google Maps links. The tool provides a seamless way to integrate geolocation services into various projects and applications.

Awesome-Colorful-LLM
Awesome-Colorful-LLM is a meticulously assembled anthology of vibrant multimodal research focusing on advancements propelled by large language models (LLMs) in domains such as Vision, Audio, Agent, Robotics, and Fundamental Sciences like Mathematics. The repository contains curated collections of works, datasets, benchmarks, projects, and tools related to LLMs and multimodal learning. It serves as a comprehensive resource for researchers and practitioners interested in exploring the intersection of language models and various modalities for tasks like image understanding, video pretraining, 3D modeling, document understanding, audio analysis, agent learning, robotic applications, and mathematical research.
Yi-Ai
Yi-Ai is a project based on the development of nineai 2.4.2. It is for learning and reference purposes only, not for commercial use. The project includes updates to popular models like gpt-4o and claude3.5, as well as new features such as model image recognition. It also supports various functionalities like model sorting, file type extensions, and bug fixes. The project provides deployment tutorials for both integrated and compiled packages, with instructions for environment setup, configuration, dependency installation, and project startup. Additionally, it offers a management platform with different access levels and emphasizes the importance of following the steps for proper system operation.
Phi-3-Vision-MLX
Phi-3-MLX is a versatile AI framework that leverages both the Phi-3-Vision multimodal model and the Phi-3-Mini-128K language model optimized for Apple Silicon using the MLX framework. It provides an easy-to-use interface for a wide range of AI tasks, from advanced text generation to visual question answering and code execution. The project features support for batched generation, flexible agent system, custom toolchains, model quantization, LoRA fine-tuning capabilities, and API integration for extended functionality.
tiny-ai-client
Tiny AI Client is a lightweight tool designed for easy usage and switching of Language Model Models (LLMs) with support for vision and tool usage. It aims to provide a simple and intuitive interface for interacting with various LLMs, allowing users to easily set, change models, send messages, use tools, and handle vision tasks. The core logic of the tool is kept minimal and easy to understand, with separate modules for vision and tool usage utilities. Users can interact with the tool through simple Python scripts, passing model names, messages, tools, and images as required.
Vitron
Vitron is a unified pixel-level vision LLM designed for comprehensive understanding, generating, segmenting, and editing static images and dynamic videos. It addresses challenges in existing vision LLMs such as superficial instance-level understanding, lack of unified support for images and videos, and insufficient coverage across various vision tasks. The tool requires Python >= 3.8, Pytorch == 2.1.0, and CUDA Version >= 11.8 for installation. Users can deploy Gradio demo locally and fine-tune their models for specific tasks.
mslearn-ai-vision
The 'mslearn-ai-vision' repository contains lab files for Azure AI Vision modules. It provides hands-on exercises and resources for learning about AI vision capabilities on the Azure platform. The labs cover topics such as image recognition, object detection, and image classification using Azure's AI services. By following the lab exercises, users can gain practical experience in building and deploying AI vision solutions in the cloud.
AI
AI is an open-source Swift framework for interfacing with generative AI. It provides functionalities for text completions, image-to-text vision, function calling, DALLE-3 image generation, audio transcription and generation, and text embeddings. The framework supports multiple AI models from providers like OpenAI, Anthropic, Mistral, Groq, and ElevenLabs. Users can easily integrate AI capabilities into their Swift projects using AI framework.

VITA
VITA is an open-source interactive omni multimodal Large Language Model (LLM) capable of processing video, image, text, and audio inputs simultaneously. It stands out with features like Omni Multimodal Understanding, Non-awakening Interaction, and Audio Interrupt Interaction. VITA can respond to user queries without a wake-up word, track and filter external queries in real-time, and handle various query inputs effectively. The model utilizes state tokens and a duplex scheme to enhance the multimodal interactive experience.
ha-llmvision
LLM Vision is a Home Assistant integration that allows users to analyze images, videos, and camera feeds using multimodal LLMs. It supports providers such as OpenAI, Anthropic, Google Gemini, LocalAI, and Ollama. Users can input images and videos from camera entities or local files, with the option to downscale images for faster processing. The tool provides detailed instructions on setting up LLM Vision and each supported provider, along with usage examples and service call parameters.

MME-RealWorld
MME-RealWorld is a benchmark designed to address real-world applications with practical relevance, featuring 13,366 high-resolution images and 29,429 annotations across 43 tasks. It aims to provide substantial recognition challenges and overcome common barriers in existing Multimodal Large Language Model benchmarks, such as small data scale, restricted data quality, and insufficient task difficulty. The dataset offers advantages in data scale, data quality, task difficulty, and real-world utility compared to existing benchmarks. It also includes a Chinese version with additional images and QA pairs focused on Chinese scenarios.
ell
ell is a lightweight, functional prompt engineering framework that treats prompts as programs rather than strings. It provides tools for prompt versioning, monitoring, and visualization, as well as support for multimodal inputs and outputs. The framework aims to simplify the process of prompt engineering for language models.

xaitk-saliency
The `xaitk-saliency` package is an open source Explainable AI (XAI) framework for visual saliency algorithm interfaces and implementations, designed for analytics and autonomy applications. It provides saliency algorithms for various image understanding tasks such as image classification, image similarity, object detection, and reinforcement learning. The toolkit targets data scientists and developers who aim to incorporate visual saliency explanations into their workflow or product, offering both direct accessibility for experimentation and modular integration into systems and applications through Strategy and Adapter patterns. The package includes documentation, examples, and a demonstration tool for visual saliency generation in a user-interface.
yu-picture
The 'yu-picture' project is an educational project that provides complete video tutorials, text tutorials, resume writing, interview question solutions, and Q&A services to help you improve your project skills and enhance your resume. It is an enterprise-level intelligent collaborative cloud image library platform based on Vue 3 + Spring Boot + COS + WebSocket. The platform has a wide range of applications, including public image uploading and retrieval, image analysis for administrators, private image management for individual users, and real-time collaborative image editing for enterprises. The project covers file management, content retrieval, permission control, and real-time collaboration, using various programming concepts, architectural design methods, and optimization strategies to ensure high-speed iteration and stable operation.

VisionLLM
VisionLLM is a series of large language models designed for vision-centric tasks. The latest version, VisionLLM v2, is a generalist multimodal model that supports hundreds of vision-language tasks, including visual understanding, perception, and generation.

MAVIS
MAVIS (Math Visual Intelligent System) is an AI-driven application that allows users to analyze visual data such as images and generate interactive answers based on them. It can perform complex mathematical calculations, solve programming tasks, and create professional graphics. MAVIS supports Python for coding and frameworks like Matplotlib, Plotly, Seaborn, Altair, NumPy, Math, SymPy, and Pandas. It is designed to make projects more efficient and professional.
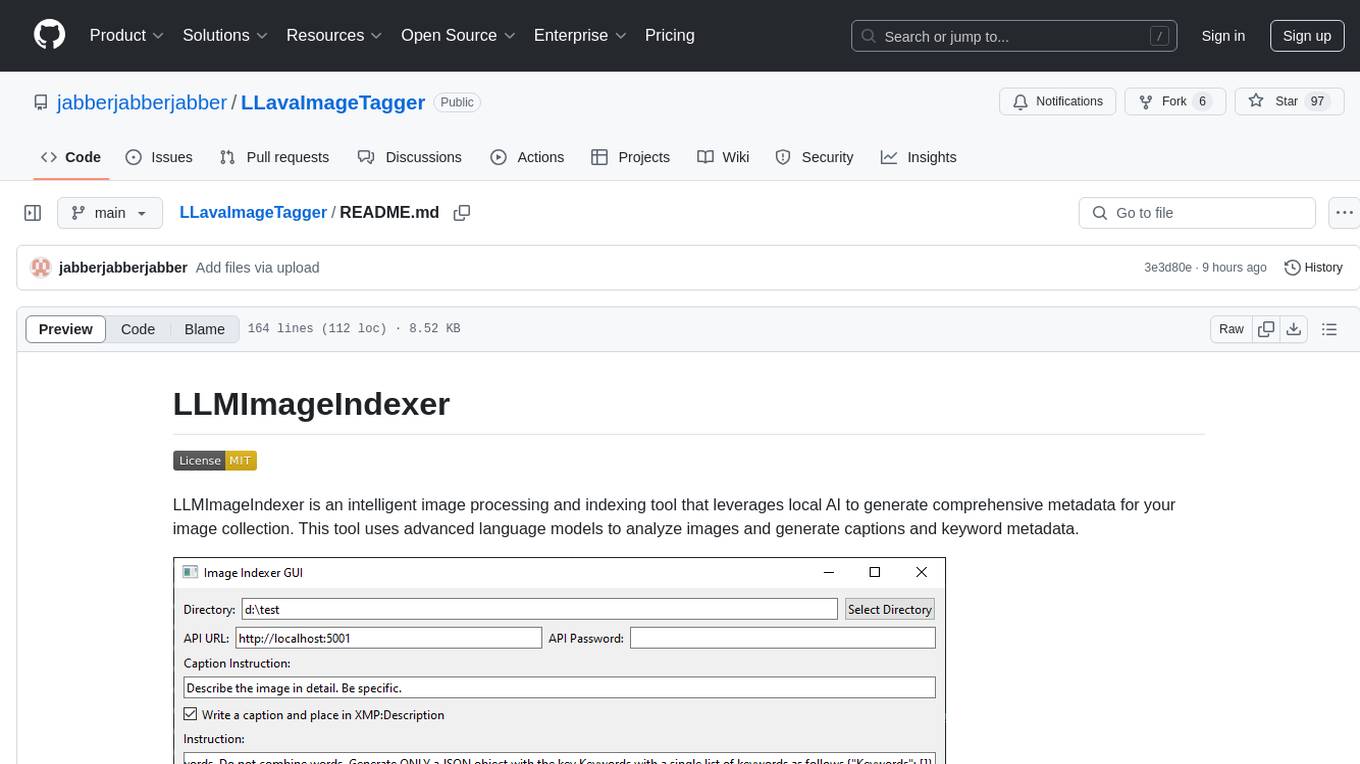
LLavaImageTagger
LLMImageIndexer is an intelligent image processing and indexing tool that leverages local AI to generate comprehensive metadata for your image collection. It uses advanced language models to analyze images and generate captions and keyword metadata. The tool offers features like intelligent image analysis, metadata enhancement, local processing, multi-format support, user-friendly GUI, GPU acceleration, cross-platform support, stop and start capability, and keyword post-processing. It operates directly on image file metadata, allowing users to manage files, add new files, and run the tool multiple times without reprocessing previously keyworded files. Installation instructions are provided for Windows, macOS, and Linux platforms, along with usage guidelines and configuration options.
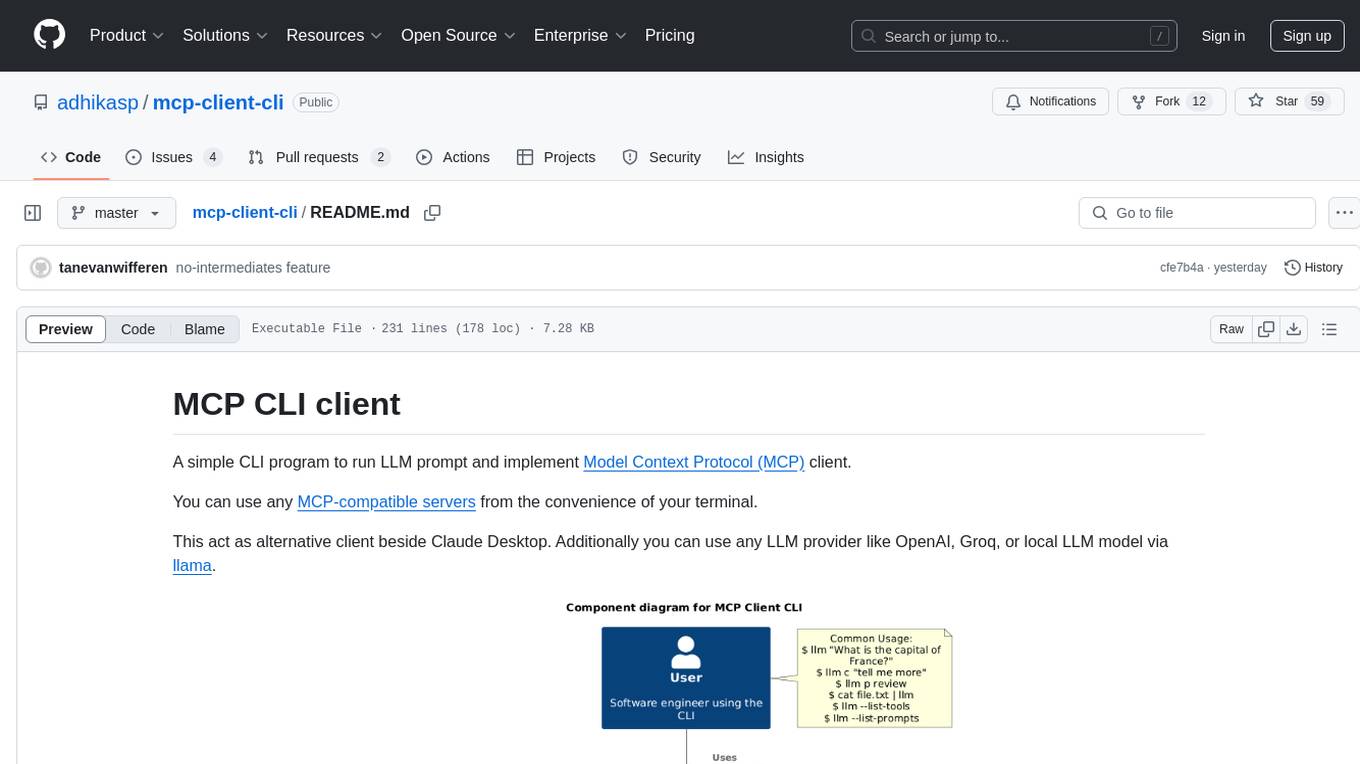
mcp-client-cli
MCP CLI client is a simple CLI program designed to run LLM prompts and act as an alternative client for Model Context Protocol (MCP). Users can interact with MCP-compatible servers from their terminal, including LLM providers like OpenAI, Groq, or local LLM models via llama. The tool supports various functionalities such as running prompt templates, analyzing image inputs, triggering tools, continuing conversations, utilizing clipboard support, and additional options like listing tools and prompts. Users can configure LLM and MCP servers via a JSON config file and contribute to the project by submitting issues and pull requests for enhancements or bug fixes.
Awesome-Embodied-AI-Job
Awesome Embodied AI Job is a curated list of resources related to jobs in the field of Embodied Artificial Intelligence. It includes job boards, companies hiring, and resources for job seekers interested in roles such as robotics engineer, computer vision specialist, AI researcher, machine learning engineer, and data scientist.

AddaxAI
AddaxAI is an application designed to streamline the work of ecologists dealing with camera trap images. It's an AI platform that allows you to analyse images with machine learning models for automatic detection, offering ecologists a way to save time and focus on conservation efforts.
vlmrun-cookbook
VLM Run Cookbook is a repository containing practical examples and tutorials for extracting structured data from images, videos, and documents using Vision Language Models (VLMs). It offers comprehensive Colab notebooks demonstrating real-world applications of VLM Run, with complete code and documentation for easy adaptation. The examples cover various domains such as financial documents and TV news analysis.
ruby_llm
RubyLLM is a delightful Ruby tool for working with AI, providing a beautiful API for various AI providers like OpenAI, Anthropic, Gemini, and DeepSeek. It simplifies AI usage by offering a consistent format, minimal dependencies, and a joyful coding experience. Users can chat, analyze images, audio, and documents, generate images, create vector embeddings, and integrate AI with Ruby code effortlessly. The tool also supports Rails integration, streaming responses, and tool creation, making AI tasks seamless and enjoyable.
Pixel-Reasoner
Pixel Reasoner is a framework that introduces reasoning in the pixel-space for Vision-Language Models (VLMs), enabling them to directly inspect, interrogate, and infer from visual evidences. This enhances reasoning fidelity for visual tasks by equipping VLMs with visual reasoning operations like zoom-in and select-frame. The framework addresses challenges like model's imbalanced competence and reluctance to adopt pixel-space operations through a two-phase training approach involving instruction tuning and curiosity-driven reinforcement learning. With these visual operations, VLMs can interact with complex visual inputs such as images or videos to gather necessary information, leading to improved performance across visual reasoning benchmarks.
agentmark
AgentMark is a tool designed to make it easy for developers to develop, test, and evaluate AI Agents. It combines Markdown syntax with JSX components to create reliable Agents. The tool seamlessly integrates with SDKs, offering comprehensive tooling such as full type safety, unified prompt configuration, syntax highlighting, loops and conditionals, custom SDK adapters, and support for text, object, image, and speech generation across multiple model providers.
datachain
DataChain is a Python-based AI-data warehouse for transforming and analyzing unstructured data like images, audio, videos, text, and PDFs. It integrates with external storage to process data efficiently without duplication and manages metadata for easy querying. Use cases include ETL, analytics, versioning, and incremental processing. Key features include multimodal dataset versioning, Python-friendly operations, data enrichment, and processing. The tool allows for generating metadata using AI models, filtering, joining, and grouping datasets, and performing high-performance vectorized operations.
claudian
Claudian is an Obsidian plugin that embeds Claude Code as an AI collaborator in your vault. It provides full agentic capabilities, including file read/write, search, bash commands, and multi-step workflows. Users can leverage Claude Code's power to interact with their vault, analyze images, edit text inline, add custom instructions, create reusable prompt templates, extend capabilities with skills and agents, connect external tools via Model Context Protocol servers, control models and thinking budget, toggle plan mode, ensure security with permission modes and vault confinement, and interact with Chrome. The plugin requires Claude Code CLI, Obsidian v1.8.9+, Claude subscription/API or custom model provider, and desktop platforms (macOS, Linux, Windows).
vllm-mlx
vLLM-MLX is a tool that brings native Apple Silicon GPU acceleration to vLLM by integrating Apple's ML framework with unified memory and Metal kernels. It offers optimized LLM inference with KV cache and quantization, vision-language models for multimodal inference, speech-to-text and text-to-speech with native voices, text embeddings for semantic search and RAG, and more. Users can benefit from features like multimodal support for text, image, video, and audio, native GPU acceleration on Apple Silicon, compatibility with OpenAI API, Anthropic Messages API, reasoning models extraction, integration with external tools via Model Context Protocol, memory-efficient caching, and high throughput for multiple concurrent users.
celeste-python
Celeste AI is a type-safe, modality/provider-agnostic tool that offers unified interface for various providers like OpenAI, Anthropic, Gemini, Mistral, and more. It supports multiple modalities including text, image, audio, video, and embeddings, with full Pydantic validation and IDE autocomplete. Users can switch providers instantly, ensuring zero lock-in and a lightweight architecture. The tool provides primitives, not frameworks, for clean I/O operations.
24 - OpenAI Gpts
Art Engineer
Analyze and reverse engineer images. Receive style descriptions and image re-creation prompts.
Historical Image Analyzer
A tool for historians to analyze and catalog historical images and documents.

Palette Pro
Analyzes images for color palettes, provides HEX codes, and suggests matching visuals.
CLIP Interrogator, Pose & Lomo Creator
Analyzes and creates lomo-style images with human pose estimation.
Product Description GPT
Generates detailed, SEO-optimized listings and product descriptions from images or text.
ImageJ Mentor
I assist biological image analysis, including ImageJ macro and Python coding.
Precision Image Authenticity Analyzer 2.0
Determines if images are AI-generated or real, and learns from feedback.
Rock Identifier GPT
I identify various rocks from images and advise consulting a geologist for certainty.
Art Market Maestro
AI expert in art authentication and valuation, analyzing images and market trends. By neuralvault
バナー画像診断
私は心理学研究者の第一人者です。主にマーケティングに使われる心理学に精通しており、バナー画像やファーストビューを送ってもらえれば、どんな心理的効果が使われているのか、またどんな心理的効果を使った方が良いのかをお答えします。


laptop Guide
Friendly, professional assistant for laptop or PC issues, with image analysis feature.

Image Analyzer
I'm an image analysis assistant, providing detailed summaries and insights.

ELARA Interior Design
I'm ELARA, an AI for interior design, analyzing images, finding products, and giving design advice.