
horde-worker-reGen
The default client software to create images for the AI-Horde
Stars: 109

This repository provides the latest implementation for the AI Horde Worker, allowing users to utilize their graphics card(s) to generate, post-process, or analyze images for others. It offers a platform where users can create images and earn 'kudos' in return, granting priority for their own image generations. The repository includes important details for setup, recommendations for system configurations, instructions for installation on Windows and Linux, basic usage guidelines, and information on updating the AI Horde Worker. Users can also run the worker with multiple GPUs and receive notifications for updates through Discord. Additionally, the repository contains models that are licensed under the CreativeML OpenRAIL License.
README:
Welcome to the AI Horde, a free and open decentralized platform for collaborative AI! The AI Horde enables people from around the world to contribute their GPU power to generate images, text, and more. By running a worker on your local machine, you can earn kudos which give you priority when making your own requests to the horde.
A worker is a piece of software that handles jobs from the AI Horde, such as generating an image from a text prompt. When your worker successfully completes a job, you are rewarded with kudos. The more kudos you have, the faster your own requests will be processed.
You can read about kudos, the reward granted to you for running a worker, including some reasons for running a worker on our detailed kudos explanation.
- AI Horde Worker reGen
Before installing the worker:
- Register an account on the AI Horde website.
- Securely store the API key you receive. Treat this key like a password.
-
Install git for Windows if you haven't already.
-
Open PowerShell or Command Prompt.
-
Navigate to the folder where you want to install the worker:
cd C:\path\to\install\folder -
Clone the repository:
git clone https://github.com/Haidra-Org/horde-worker-reGen.git cd horde-worker-reGen
- Download the zipped worker files.
- Extract to a folder of your choice.
Open a terminal and run:
git clone https://github.com/Haidra-Org/horde-worker-reGen.git
cd horde-worker-reGenAMD support is experimental, and Linux-only for now:
- Use
horde-bridge-rocm.shandupdate-runtime-rocm.shin place of the standard versions. - WSL support is highly experimental.
- Join the AMD discussion on Discord if you're interested in trying.
Experimental Support for DirectML has been added. See Running on DirectML for more information and further instructions. You can now follow this guide using update-runtime-directml.cmd and horde-bridge-directml.cmd where appropriate. Please note that DirectML is several times slower than ANY other methods of running the worker.
- Copy
bridgeData_template.yamltobridgeData.yaml. - Edit
bridgeData.yamlfollowing the instructions inside. - Set a unique
dreamer_name
- If the name is already taken, you'll get a "Wrong Credentials" error. The name must be unique across the entire horde network.
Tailor settings to your GPU, following these pointers:
-
24GB+ VRAM (e.g. 3090, 4090):
- queue_size: 1 # <32GB RAM: 0, 32GB: 1, >32GB: 2 - safety_on_gpu: true - high_memory_mode: true - high_performance_mode: true - unload_models_from_vram_often: false - max_threads: 1 # 2 is often viable for xx90 cards - post_process_job_overlap: true - queue_size: 2 # Set to 1 if max_threads: 2 - max_power: 64 # Reduce if max_threads: 2 - max_batch: 8 # Increase if max_threads: 1, decrease if max_threads: 2 - allow_sdxl_controlnet: true
-
12-16GB VRAM (e.g. 3080 Ti, 4070 Ti, 4080):
- queue_size: 1 # <32GB RAM: 0, 32GB: 1, >32GB: 2 - safety_on_gpu: true # Consider false if using Cascade/Flux - moderate_performance_mode: true - unload_models_from_vram_often: false - max_threads: 1 - max_power: 50 - max_batch: 4 # Or higher
-
8-10GB VRAM (e.g. 2080, 3060, 4060, 4060 Ti):
- queue_size: 1 # <32GB RAM: 0, 32GB: 1, >32GB: 2 - safety_on_gpu: false - max_threads: 1 - max_power: 32 # No higher - max_batch: 4 # No higher - allow_post_processing: false # If using SDXL/Flux, else can be true - allow_sdxl_controlnet: false
- Also minimize other VRAM-consuming apps while the worker runs.
-
Lower-end GPUs / Under-performing Workers:
-
extra_slow_worker: truegives more time per job, but users must opt-in. Only use if <0.3 MPS/S or <3000 kudos/hr consistently with correct config. -
limit_max_steps: truecaps total steps per job based on model. -
preload_timeout: 120allows longer model load times. Avoid misusing to prevent kudos loss or maintenance mode.
-
-
Systems with less than 32GB of System RAM:
- Be sure to only run SD15 models and queue_size: 0.
- Set
load_large_models: false - To your
models_to_skipaddALL SDXL,ALL SD21, and the 'unpruned' models (see config) to prevent running out of memory
- Set
- Be sure to only run SD15 models and queue_size: 0.
- Use an SSD, especially for multiple models. HDDs should offer one model only, loading within 60s.
- Configure 8GB (preferably 16GB+) of swap space, even on Linux.
- Keep
threads≤2 unless using a 48GB+ VRAM data center GPU. - Worker RAM usage scales with
queue_size. Use 1 for <32GB RAM, and optimize further for <16GB. - SDXL needs ~9GB free RAM consistently (32GB+ total recommended).
- Flux and Stable Cascade need ~20GB free RAM consistently (48GB+ total recommended).
- Disable sleep/power-saving modes while the worker runs.
Note: The worker is resource-intensive. Avoid gaming or other heavy tasks while it runs. Turn it off or limit to small models at reduced settings if needed.
- Install the worker as described in the Installation section.
- Run
horde-bridge.cmd(Windows) orhorde-bridge.sh(Linux).-
AMD: Use
horde-bridge-rocmversions.
-
AMD: Use
- Press
Ctrl+Cin the worker's terminal. - It will finish current jobs before exiting.
Watch the terminal for progress, completed jobs, kudos earned, stats, and errors.
Detailed logs are in the logs directory:
-
bridge*.log: All info-
bridge.logis the main window -
bridge_n.logis process-specific (nis the process number)
-
-
trace*.log: Errors and warnings only-
trace.logis the main window -
trace_n.logis process-specific
-
Future versions won't need multiple worker instances
For now, start a separate worker per GPU.
On Linux, specify the GPU for each instance:
CUDA_VISIBLE_DEVICES=0 ./horde-bridge.sh -n "Instance 1"
CUDA_VISIBLE_DEVICES=1 ./horde-bridge.sh -n "Instance 2"Warning: High RAM (32-64GB+) is needed for multiple workers. queue_size and max_threads greatly impact RAM per worker.
The worker is constantly improving. Follow development and get update notifications in our Discord.
Script names below assume Windows (.cmd) and NVIDIA. For Linux use .sh, for AMD use -rocm versions.
- Stop the worker with
Ctrl+C. - Update the files:
- If you used
git clone:- Open a terminal in the worker folder
- Run
git pull
- If you used the zip download:
- Delete the old
horde_worker_regenfolder - Download the latest zip
- Extract to the original location, overwriting existing files
- Delete the old
- If you used
- Continue with Updating the Runtime below.
Warning: Some antivirus software (e.g. Avast) may interfere with the update. If you get
CRYPT_E_NO_REVOCATION_CHECKerrors, disable antivirus, retry, then re-enable.
- Run
update-runtimefor your OS to update dependencies.- Not all updates require this, but run it if unsure
- Advanced users: see README_advanced.md for manual options
- Start the worker again
Serving custom models not in our reference requires the customizer role. Request it on Discord.
With the role:
-
Download your model files locally.
-
Reference them in
bridgeData.yaml:custom_models: - name: My Custom Model baseline: stable_diffusion_xl filepath: /path/to/model/file.safetensors
-
Add the model
nameto yourmodels_to_loadlist.
If set up correctly, custom_models.json will appear in the worker directory on startup.
Notes:
- Custom model names can't match our existing model names
- The horde will treat them as SD 1.5 for kudos rewards and safety checks
Docker images are at https://hub.docker.com/r/tazlin/horde-worker-regen/tags.
Detailed guide: Dockerfiles/README.md
Manual worker setup: README_advanced.md
Check the #local-workers Discord channel for the latest info and community support.
Common issues and fixes:
- Download failures: Check disk space and internet connection.
-
Job timeouts:
- Remove large models (Flux, Cascade, SDXL)
- Lower
max_power - Disable
allow_post_processing,allow_controlnet,allow_sdxl_controlnet, and/orallow_lora
-
Out of memory: Decrease
max_threads,max_batch, orqueue_sizeto reduce VRAM/RAM use. Close other intensive programs. - I have less kudos than I expect: As a new user, 50% of your job reward kudos and 100% of uptime kudos are held in escrow until you become trusted after ~1 week of worker uptime. You'll then receive the escrowed kudos and earn full rewards immediately going forward.
-
My worker is in maintenance mode: You can log into artbot here and use the manage workers page with the worker on and click "unpause" to take your worker out of maintenance mode.
- Note: Workers are put into maintenance mode automatically by the server when the worker is failing to perform fast enough or if it is reporting that it failed too many jobs. You should investigate the logs (search for "ERROR") to see what led to the issue. You can also open an issue or ask in the #local-workers channel in our Discord.
Open an issue to report bugs or request features. We appreciate your help!
Many bundled models use the CreativeML OpenRAIL License. Please review it before use.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for horde-worker-reGen
Similar Open Source Tools
horde-worker-reGen
This repository provides the latest implementation for the AI Horde Worker, allowing users to utilize their graphics card(s) to generate, post-process, or analyze images for others. It offers a platform where users can create images and earn 'kudos' in return, granting priority for their own image generations. The repository includes important details for setup, recommendations for system configurations, instructions for installation on Windows and Linux, basic usage guidelines, and information on updating the AI Horde Worker. Users can also run the worker with multiple GPUs and receive notifications for updates through Discord. Additionally, the repository contains models that are licensed under the CreativeML OpenRAIL License.

kwaak
Kwaak is a tool that allows users to run a team of autonomous AI agents locally from their own machine. It enables users to write code, improve test coverage, update documentation, and enhance code quality while focusing on building innovative projects. Kwaak is designed to run multiple agents in parallel, interact with codebases, answer questions about code, find examples, write and execute code, create pull requests, and more. It is free and open-source, allowing users to bring their own API keys or models via Ollama. Kwaak is part of the bosun.ai project, aiming to be a platform for autonomous code improvement.
PentestGPT
PentestGPT is a penetration testing tool empowered by ChatGPT, designed to automate the penetration testing process. It operates interactively to guide penetration testers in overall progress and specific operations. The tool supports solving easy to medium HackTheBox machines and other CTF challenges. Users can use PentestGPT to perform tasks like testing connections, using different reasoning models, discussing with the tool, searching on Google, and generating reports. It also supports local LLMs with custom parsers for advanced users.

Easy-Translate
Easy-Translate is a script designed for translating large text files with a single command. It supports various models like M2M100, NLLB200, SeamlessM4T, LLaMA, and Bloom. The tool is beginner-friendly and offers seamless and customizable features for advanced users. It allows acceleration on CPU, multi-CPU, GPU, multi-GPU, and TPU, with support for different precisions and decoding strategies. Easy-Translate also provides an evaluation script for translations. Built on HuggingFace's Transformers and Accelerate library, it supports prompt usage and loading huge models efficiently.

Fabric
Fabric is an open-source framework designed to augment humans using AI by organizing prompts by real-world tasks. It addresses the integration problem of AI by creating and organizing prompts for various tasks. Users can create, collect, and organize AI solutions in a single place for use in their favorite tools. Fabric also serves as a command-line interface for those focused on the terminal. It offers a wide range of features and capabilities, including support for multiple AI providers, internationalization, speech-to-text, AI reasoning, model management, web search, text-to-speech, desktop notifications, and more. The project aims to help humans flourish by leveraging AI technology to solve human problems and enhance creativity.

lexido
Lexido is an innovative assistant for the Linux command line, designed to boost your productivity and efficiency. Powered by Gemini Pro 1.0 and utilizing the free API, Lexido offers smart suggestions for commands based on your prompts and importantly your current environment. Whether you're installing software, managing files, or configuring system settings, Lexido streamlines the process, making it faster and more intuitive.

OpenAdapt
OpenAdapt is an open-source software adapter between Large Multimodal Models (LMMs) and traditional desktop and web Graphical User Interfaces (GUIs). It aims to automate repetitive GUI workflows by leveraging the power of LMMs. OpenAdapt records user input and screenshots, converts them into tokenized format, and generates synthetic input via transformer model completions. It also analyzes recordings to generate task trees and replay synthetic input to complete tasks. OpenAdapt is model agnostic and generates prompts automatically by learning from human demonstration, ensuring that agents are grounded in existing processes and mitigating hallucinations. It works with all types of desktop GUIs, including virtualized and web, and is open source under the MIT license.
Deep-Live-Cam
Deep-Live-Cam is a software tool designed to assist artists in tasks such as animating custom characters or using characters as models for clothing. The tool includes built-in checks to prevent unethical applications, such as working on inappropriate media. Users are expected to use the tool responsibly and adhere to local laws, especially when using real faces for deepfake content. The tool supports both CPU and GPU acceleration for faster processing and provides a user-friendly GUI for swapping faces in images or videos.
pear-landing-page
PearAI Landing Page is an open-source AI-powered code editor managed by Nang and Pan. It is built with Next.js, Vercel, Tailwind CSS, and TypeScript. The project requires setting up environment variables for proper configuration. Users can run the project locally by starting the development server and visiting the specified URL in the browser. Recommended extensions include Prettier, ESLint, and JavaScript and TypeScript Nightly. Contributions to the project are welcomed and appreciated.

allms
allms is a versatile and powerful library designed to streamline the process of querying Large Language Models (LLMs). Developed by Allegro engineers, it simplifies working with LLM applications by providing a user-friendly interface, asynchronous querying, automatic retrying mechanism, error handling, and output parsing. It supports various LLM families hosted on different platforms like OpenAI, Google, Azure, and GCP. The library offers features for configuring endpoint credentials, batch querying with symbolic variables, and forcing structured output format. It also provides documentation, quickstart guides, and instructions for local development, testing, updating documentation, and making new releases.

rclip
rclip is a command-line photo search tool powered by the OpenAI's CLIP neural network. It allows users to search for images using text queries, similar image search, and combining multiple queries. The tool extracts features from photos to enable searching and indexing, with options for previewing results in supported terminals or custom viewers. Users can install rclip on Linux, macOS, and Windows using different installation methods. The repository follows the Conventional Commits standard and welcomes contributions from the community.

AutoAgent
AutoAgent is a fully-automated and zero-code framework that enables users to create and deploy LLM agents through natural language alone. It is a top performer on the GAIA Benchmark, equipped with a native self-managing vector database, and allows for easy creation of tools, agents, and workflows without any coding. AutoAgent seamlessly integrates with a wide range of LLMs and supports both function-calling and ReAct interaction modes. It is designed to be dynamic, extensible, customized, and lightweight, serving as a personal AI assistant.
quivr
Quivr is a personal assistant powered by Generative AI, designed to be a second brain for users. It offers fast and efficient access to data, ensuring security and compatibility with various file formats. Quivr is open source and free to use, allowing users to share their brains publicly or keep them private. The marketplace feature enables users to share and utilize brains created by others, boosting productivity. Quivr's offline mode provides anytime, anywhere access to data. Key features include speed, security, OS compatibility, file compatibility, open source nature, public/private sharing options, a marketplace, and offline mode.
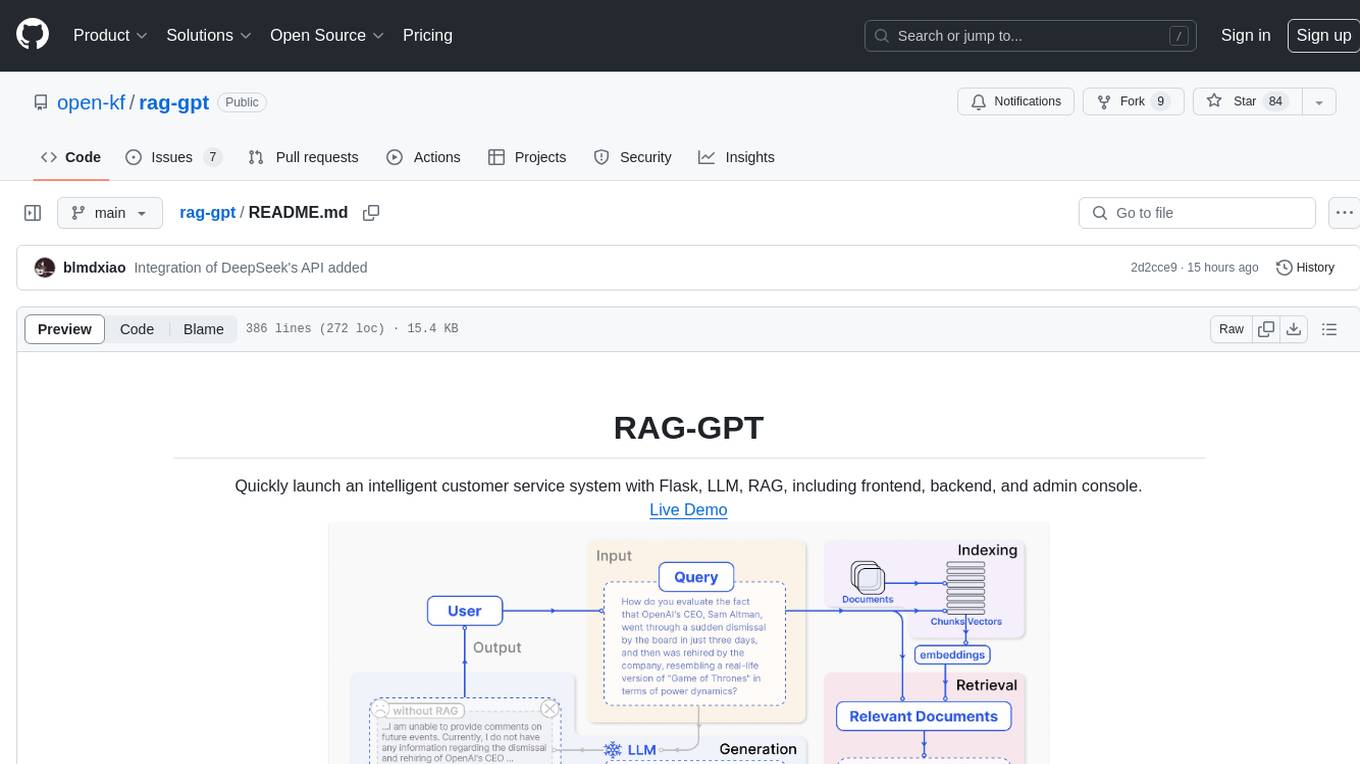
rag-gpt
RAG-GPT is a tool that allows users to quickly launch an intelligent customer service system with Flask, LLM, and RAG. It includes frontend, backend, and admin console components. The tool supports cloud-based and local LLMs, enables deployment of conversational service robots in minutes, integrates diverse knowledge bases, offers flexible configuration options, and features an attractive user interface.
node_characterai
Node.js client for the unofficial Character AI API, an awesome website which brings characters to life with AI! This repository is inspired by RichardDorian's unofficial node API. Though, I found it hard to use and it was not really stable and archived. So I remade it in javascript. This project is not affiliated with Character AI in any way! It is a community project. The purpose of this project is to bring and build projects powered by Character AI. If you like this project, please check their website.
OpenAI-sublime-text
The OpenAI Completion plugin for Sublime Text provides first-class code assistant support within the editor. It utilizes LLM models to manipulate code, engage in chat mode, and perform various tasks. The plugin supports OpenAI, llama.cpp, and ollama models, allowing users to customize their AI assistant experience. It offers separated chat histories and assistant settings for different projects, enabling context-specific interactions. Additionally, the plugin supports Markdown syntax with code language syntax highlighting, server-side streaming for faster response times, and proxy support for secure connections. Users can configure the plugin's settings to set their OpenAI API key, adjust assistant modes, and manage chat history. Overall, the OpenAI Completion plugin enhances the Sublime Text editor with powerful AI capabilities, streamlining coding workflows and fostering collaboration with AI assistants.
For similar tasks

HPT
Hyper-Pretrained Transformers (HPT) is a novel multimodal LLM framework from HyperGAI, trained for vision-language models capable of understanding both textual and visual inputs. The repository contains the open-source implementation of inference code to reproduce the evaluation results of HPT Air on different benchmarks. HPT has achieved competitive results with state-of-the-art models on various multimodal LLM benchmarks. It offers models like HPT 1.5 Air and HPT 1.0 Air, providing efficient solutions for vision-and-language tasks.

learnopencv
LearnOpenCV is a repository containing code for Computer Vision, Deep learning, and AI research articles shared on the blog LearnOpenCV.com. It serves as a resource for individuals looking to enhance their expertise in AI through various courses offered by OpenCV. The repository includes a wide range of topics such as image inpainting, instance segmentation, robotics, deep learning models, and more, providing practical implementations and code examples for readers to explore and learn from.

spark-free-api
Spark AI Free 服务 provides high-speed streaming output, multi-turn dialogue support, AI drawing support, long document interpretation, and image parsing. It offers zero-configuration deployment, multi-token support, and automatic session trace cleaning. It is fully compatible with the ChatGPT interface. The repository includes multiple free-api projects for various AI services. Users can access the API for tasks such as chat completions, AI drawing, document interpretation, image analysis, and ssoSessionId live checking. The project also provides guidelines for deployment using Docker, Docker-compose, Render, Vercel, and native deployment methods. It recommends using custom clients for faster and simpler access to the free-api series projects.

mlx-vlm
MLX-VLM is a package designed for running Vision LLMs on Mac systems using MLX. It provides a convenient way to install and utilize the package for processing large language models related to vision tasks. The tool simplifies the process of running LLMs on Mac computers, offering a seamless experience for users interested in leveraging MLX for vision-related projects.

clarifai-python-grpc
This is the official Clarifai gRPC Python client for interacting with their recognition API. Clarifai offers a platform for data scientists, developers, researchers, and enterprises to utilize artificial intelligence for image, video, and text analysis through computer vision and natural language processing. The client allows users to authenticate, predict concepts in images, and access various functionalities provided by the Clarifai API. It follows a versioning scheme that aligns with the backend API updates and includes specific instructions for installation and troubleshooting. Users can explore the Clarifai demo, sign up for an account, and refer to the documentation for detailed information.
horde-worker-reGen
This repository provides the latest implementation for the AI Horde Worker, allowing users to utilize their graphics card(s) to generate, post-process, or analyze images for others. It offers a platform where users can create images and earn 'kudos' in return, granting priority for their own image generations. The repository includes important details for setup, recommendations for system configurations, instructions for installation on Windows and Linux, basic usage guidelines, and information on updating the AI Horde Worker. Users can also run the worker with multiple GPUs and receive notifications for updates through Discord. Additionally, the repository contains models that are licensed under the CreativeML OpenRAIL License.

geospy
Geospy is a Python tool that utilizes Graylark's AI-powered geolocation service to determine the location where photos were taken. It allows users to analyze images and retrieve information such as country, city, explanation, coordinates, and Google Maps links. The tool provides a seamless way to integrate geolocation services into various projects and applications.

Awesome-Colorful-LLM
Awesome-Colorful-LLM is a meticulously assembled anthology of vibrant multimodal research focusing on advancements propelled by large language models (LLMs) in domains such as Vision, Audio, Agent, Robotics, and Fundamental Sciences like Mathematics. The repository contains curated collections of works, datasets, benchmarks, projects, and tools related to LLMs and multimodal learning. It serves as a comprehensive resource for researchers and practitioners interested in exploring the intersection of language models and various modalities for tasks like image understanding, video pretraining, 3D modeling, document understanding, audio analysis, agent learning, robotic applications, and mathematical research.
For similar jobs
horde-worker-reGen
This repository provides the latest implementation for the AI Horde Worker, allowing users to utilize their graphics card(s) to generate, post-process, or analyze images for others. It offers a platform where users can create images and earn 'kudos' in return, granting priority for their own image generations. The repository includes important details for setup, recommendations for system configurations, instructions for installation on Windows and Linux, basic usage guidelines, and information on updating the AI Horde Worker. Users can also run the worker with multiple GPUs and receive notifications for updates through Discord. Additionally, the repository contains models that are licensed under the CreativeML OpenRAIL License.

lollms-webui
LoLLMs WebUI (Lord of Large Language Multimodal Systems: One tool to rule them all) is a user-friendly interface to access and utilize various LLM (Large Language Models) and other AI models for a wide range of tasks. With over 500 AI expert conditionings across diverse domains and more than 2500 fine tuned models over multiple domains, LoLLMs WebUI provides an immediate resource for any problem, from car repair to coding assistance, legal matters, medical diagnosis, entertainment, and more. The easy-to-use UI with light and dark mode options, integration with GitHub repository, support for different personalities, and features like thumb up/down rating, copy, edit, and remove messages, local database storage, search, export, and delete multiple discussions, make LoLLMs WebUI a powerful and versatile tool.
NightshadeAntidote
Nightshade Antidote is an image forensics tool used to analyze digital images for signs of manipulation or forgery. It implements several common techniques used in image forensics including metadata analysis, copy-move forgery detection, frequency domain analysis, and JPEG compression artifacts analysis. The tool takes an input image, performs analysis using the above techniques, and outputs a report summarizing the findings.
MaterialSearch
MaterialSearch is a tool for searching local images and videos using natural language. It provides functionalities such as text search for images, image search for images, text search for videos (providing matching video clips), image search for videos (searching for the segment in a video through a screenshot), image-text similarity calculation, and Pexels video search. The tool can be deployed through the source code or Docker image, and it supports GPU acceleration. Users can configure the tool through environment variables or a .env file. The tool is still under development, and configurations may change frequently. Users can report issues or suggest improvements through issues or pull requests.

CLIPPyX
CLIPPyX is a powerful system-wide image search and management tool that offers versatile search options to find images based on their content, text, and visual similarity. With advanced features, users can effortlessly locate desired images across their entire computer's disk(s), regardless of their location or file names. The tool utilizes OpenAI's CLIP for image embeddings and text-based search, along with OCR for extracting text from images. It also employs Voidtools Everything SDK to list paths of all images on the system. CLIPPyX server receives search queries and queries collections of image embeddings and text embeddings to return relevant images.
aicsimageio
AICSImageIO is a Python tool for Image Reading, Metadata Conversion, and Image Writing for Microscopy Images. It supports various file formats like OME-TIFF, TIFF, ND2, DV, CZI, LIF, PNG, GIF, and Bio-Formats. Users can read and write metadata and imaging data, work with different file systems like local paths, HTTP URLs, s3fs, and gcsfs. The tool provides functionalities for full image reading, delayed image reading, mosaic image reading, metadata reading, xarray coordinate plane attachment, cloud IO support, and saving to OME-TIFF. It also offers benchmarking and developer resources.
DeepDanbooru
DeepDanbooru is an anime-style girl image tag estimation system written in Python. It allows users to estimate images using a live demo site. The tool requires specific packages to be installed and provides a structured dataset for training projects. Users can create training projects, download tags, filter datasets, and start training to estimate tags for images. The tool uses a specific dataset structure and project structure to facilitate the training process.
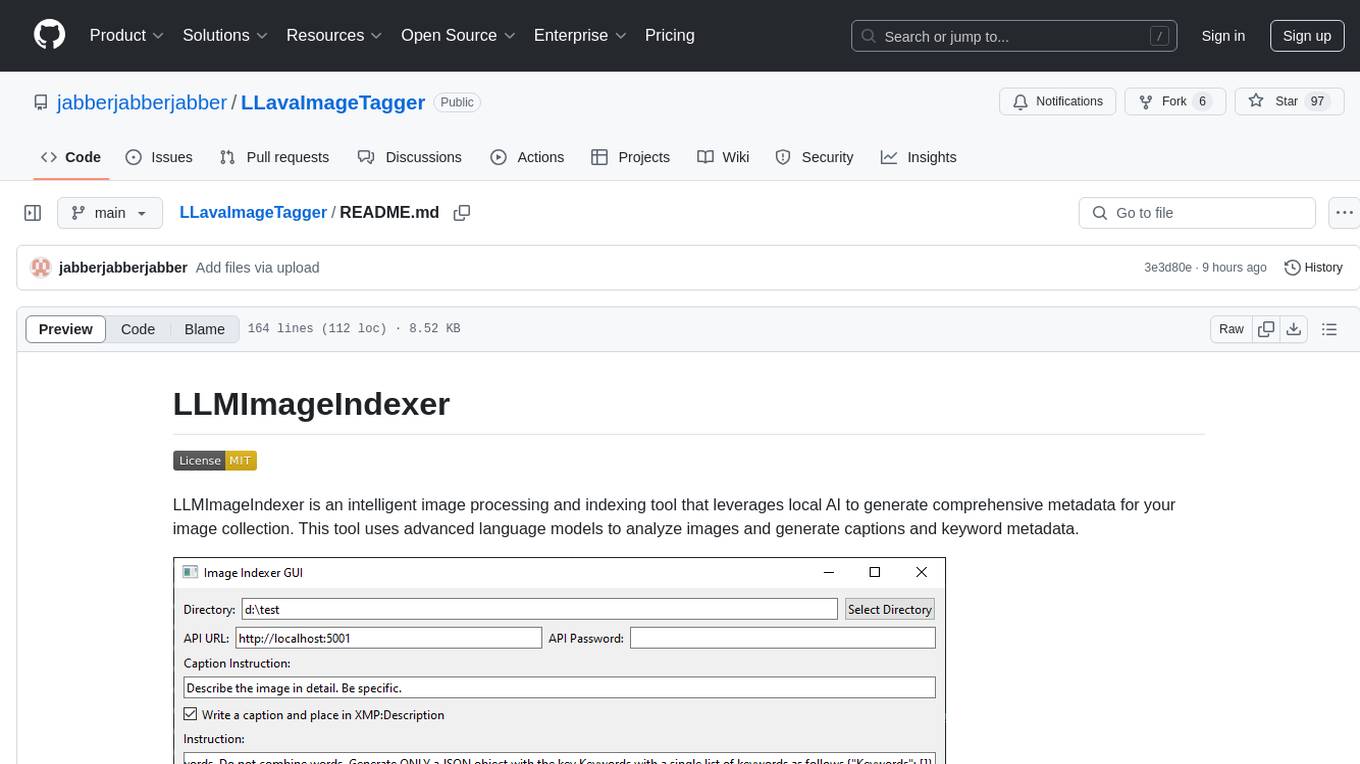
LLavaImageTagger
LLMImageIndexer is an intelligent image processing and indexing tool that leverages local AI to generate comprehensive metadata for your image collection. It uses advanced language models to analyze images and generate captions and keyword metadata. The tool offers features like intelligent image analysis, metadata enhancement, local processing, multi-format support, user-friendly GUI, GPU acceleration, cross-platform support, stop and start capability, and keyword post-processing. It operates directly on image file metadata, allowing users to manage files, add new files, and run the tool multiple times without reprocessing previously keyworded files. Installation instructions are provided for Windows, macOS, and Linux platforms, along with usage guidelines and configuration options.